Learning to generate 3D shapes
|
|
|
- Peregrine Morton
- 5 years ago
- Views:
Transcription
1 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst August 10, Caltech

2 Creating 3D shapes is not easy Image from Autodesk 3D Maya




3 Inferring 3D shapes from images What shapes are puffins? What shapes are pumpkinseed fish? 3





4 Creating 3D shapes is not easy Many techniques for recognizing 3D data, but relatively few techniques for generating them Representations for generation? Voxels Multiview Geometry images Shape basis Set-based (points, triangles, etc.) Procedural, e.g., constructive solid geometry
5 Talk overview Generative models for 3D shapes and applications Multiview [3DV 17] Multiresolution tree networks [ECCV 18] Constructive solid geometry [CVPR 18] Learning 3D shapes with weak supervision [3DV 17]
6 Part 1 3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks Zhaoliang Lun Matheus Gadelha Evangelos Kalogerakis Subhransu Maji Rui Wang 3DV 2017
7 Part 1 3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks Zhaoliang Lun Matheus Gadelha Evangelos Kalogerakis Subhransu Maji Rui Wang 3DV 2017
8 Why line drawings? Simple & intuitive medium to convey shape! Image from Suggestive Contour Gallery, DeCarlo et al. 2003



9 Goal: 2D line drawings in, 3D shapes out! front view ShapeMVD side view 3D shape

10 Deep net architecture: U-net structure Feature representations in the decoder depend on previous layer & encoder s corresponding layer front view output view 1 side view output view 12 U-net: Ronneberger et al. 2015, Isola et al. 2016
 gt (1 n n )")

11 Training: full loss Penalize per-pixel depth reconstruction error: & per-pixel normal reconstruction error: & unreal outputs: pixels pixels d d pred log P( real) gt (1 n n ) pred gt Discriminator Network Real? Fake? front view front view Generator Network output view 1 Discriminator Network Real? Fake? side view output view 12 cgan: Isola et al. 2016




12 Training data Character 10K models Chair 10K models Airplane 3K models Models from The Models Resource & 3D Warehouse






13 Training data Synthetic line drawings 12 views Training depth and normal maps

14 Test time Predict multi-view depth and normal maps! front view output view 1 side view output view 12
15 Multi-view depth & normal map fusion Optimization problem output view 1 Depth derivatives should be consistent with normals Corresponding depths and normals across different views should agree output view 12 Multi-view depth & normal maps Consolidated point cloud
16 Surface reconstruction output view 1 output view 12 Multi-view depth & normal maps Consolidated point cloud Surface reconstruction [Kazhdan et al. 2013]
17 Surface deformation output view 1 output view 12 Multi-view depth & normal maps Consolidated point cloud Surface reconstruction [Kazhdan et al. 2013] Surface fine-tuning [Nealen et al. 2005]
18 Surface deformation output view 1 output view 12 Multi-view depth & normal maps Consolidated point cloud Surface reconstruction [Kazhdan et al. 2013] Surface fine-tuning [Nealen et al. 2005]
19 Experiments







20 Qualitative Results reference shape reference shape nearest retrieval our result volumetric net nearest retrieval our result volumetric net







21 Qualitative Results reference shape reference shape nearest retrieval our result volumetric net nearest retrieval our result volumetric net
 Hausdorff distance 0.171 0.211 0.228 Chamfer distance 0.028 0.032 0.038 normal distance 34.19 48.81 43.75 volumetric distance 0.")
22 Quantitative Results Character (human drawing) Metric Our method Volumetric NN Hausdorff distance Chamfer distance normal distance volumetric distance Man-made (human drawing) Hausdorff distance Chamfer distance normal distance volumetric distance



23 Single vs two input line drawings Single sketch Resulting shape Two sketches Resulting shape



24 More results
25 Part 2 Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha Subhransu Maji Rui Wang ECCV 18
26 Part 2 Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha Subhransu Maji Rui Wang ECCV 18

27 Point-cloud decoders Global shape basis or fully-connected decoders Requires perfect correspondence Morphable models [Figure from Booth et al., 16]

28 How important is correspondence? Gadelha et al., BMVC 17 Related work: Fan et al., CVPR 2017


29 How important is correspondence?

30 Multiresolution tree networks Addresses the lack of convolutional structure, and coarse to fine reasoning Basic idea: linearize 3D points and use 1D convolutions Points colored with kdtree sort index

31 Multiresolution tree networks Addresses the lack of convolutional structure, and coarse to fine reasoning Basic idea: linearize 3D points and use 1D convolutions Implicit mulitresolution structure

32 Multiresolution tree networks Architecture for encoding and decoding Multiresolution convolution block

33 Does multiresolution analysis help? fully-connected single-resolution multi-resolution Color indicates the position in the list

34 Other shape tasks with MRTNet

35 Single image shape reconstruction

36 Quantitative evaluation: ShapeNet dataset Chamfer distance: pred g GT / GT g pred voxel-based fully-conn. multiview Lin et al. AAAI 2018

37 Quantitative evaluation: ShapeNet dataset Chamfer distance: pred g GT / GT g pred voxel-based fully-conn. multiview
38 MRTNet summary A generic architecture for Point cloud classification (91.7% on ModelNet40) Semantic segmentation (see results in the paper) Generation Project page:

39 Part 3 CSGNet: Neural Shape Parser for Constructive Solid Geometry Gopal Sharma Rishabh Goyal Difan Liu Evangelos Kalogerakis Subhransu Maji CVPR 18 interpretable and editable
40 Constructive 2D geometry
41 Constructive solid geometry
42 Constructive solid geometry Circle1 Triangle1 - Circle2 - Triangle2 - Triangle3 - [STOP] Postfix notation CNN RNN Program

43 Learning Supervised setting: learn to predict programs directly Unsupervised setting: No ground-truth programs. Learn parameters to minimize a reconstruction error through policy gradients [REINFORCE, Willams 1992] reconstruction loss CNN RNN Program
44 CSGNet: 2D/3D a programs










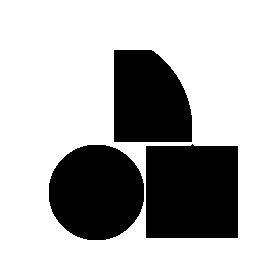








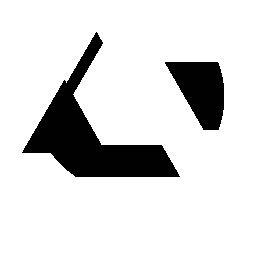


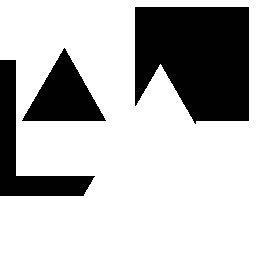










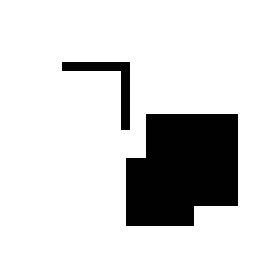




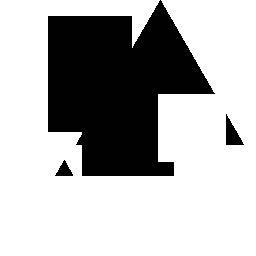




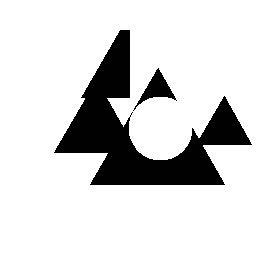



45 CSGNet: 2D/3D a programs Train on synthetic data and adapt to new domains using policy gradients Synthetic CAD shapes Logos
, 1.")
46 CSGNet: 2D/3D a programs How well does the nearest neighbor perform? Chamfer distance 1.88 (NN), 1.36 (CSGNet) with 675K training examples
, 1.")
47 CSGNet: 2D/3D a programs How well does the nearest neighbor perform? Chamfer distance 1.88 (NN), 1.36 (CSGNet) with 675K training examples
, 0.")
48 CSGNet: 2D/3D a programs CAD shapes dataset: Chamfer distance 1.94 (NN), 0.51 (CSGNet)

49 CSGNet: 2D/3D a programs Input More results in the paper: reward shaping, comparison to Faster R-CNN for primitive detection, results on 3D, etc. Preprint available:

50 Part 4 Learning 3D Shape Representations with Weak Supervision Matheus Gadelha Subhransu Maji Rui Wang 3DV 2017
51 Related Work 3D shape from collection of images Visual hull same instance, known viewpoints Photometric stereo same instance, known lighting, simple reflectance Structure from motion same instance (or 3D) Non-rigid structure from motion known shape family (e.g., faces) Our work unknown shape family, unknown viewpoints 3D shape from single image Optimization-based approaches; Recognition-based approaches;
52 A motivating example Small cubes are reddish Big cubes are bluish Hypothesis: It is easier to generate these images by reasoning in 3D
53 Approach Our goal is to learn a 3D shape generator whose projections match the provided set of the views Generator Projection
54 Approach Our goal is to learn a 3D shape generator whose projections match the provided set of the views Generator Projection How do we match distributions?
55 Approach Our goal is to learn a 3D shape generator whose projections match the provided set of the views Generator Projection generated min G How do we match distributions? true D KL(G D) =min z G E apple log G(z) D(z)
56 Approach Our goal is to learn a 3D shape generator whose projections match the provided set of the views Generator Projection How do we match distributions? generated min G true D KL(G D) =min z G E apple log G(z) D(z) estimate using logistic regression
57 Approach Our goal is to learn a 3D shape generator whose projections match the provided set of the views Generator Projection generated min G min G How do we match distributions? true D KL(G D) =min z G E max apple log G(z) D(z) E x D [log d(x)] + E z G [log(1 estimate using logistic regression d Generative adversarial networks [Goodfellow et al.] d(z))]
 =1 exp V (x + r)dr")
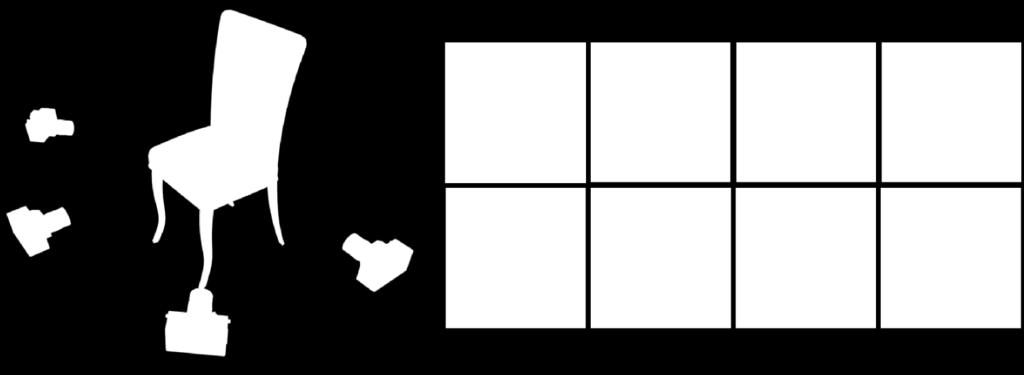
58 PrGAN Generator maps z to a voxel occupancy grid and a viewpoint Projection using line integration along the view direction Z 1 I(x) =1 exp V (x + r)dr 0


59 Dataset generation
60 Airplanes input generated
61 Airplanes input generated
62 Vases input generated
63 Vases input generated

64 Mixed categories input generated

65 MMD metric: 2D-GAN 90.1, PrGAN 88.3

66 Trained with 3D supervision MMD metric 3D-GAN PrGAN 442.9
67 Projection GAN The model is able to recover the coarse 3D structure But should use side information when available Viewpoint Landmarks / part labels Pose estimates Iterative: bootstrap 3D to estimate pose & viewpoint





68 Thank you! Collaborators: Matheus Gadelha, Zhaoliang Lun, Gopal Sharma, Rui Wang, Evangelos Kalogerakis Funding from NSF, NVIDIA, Facebook
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Deep Models for 3D Reconstruction
 Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material
 Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY
 MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks
 An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
Bilinear Models for Fine-Grained Visual Recognition
 Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
3D Shape Segmentation with Projective Convolutional Networks
 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision
 CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal * and R. Venkatesh Babu Video Analytics Lab, IISc, Bangalore, India
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal * and R. Venkatesh Babu Video Analytics Lab, IISc, Bangalore, India
Deep Learning for Visual Manipulation and Synthesis
 Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction
 GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction Li Jiang 1, Shaoshuai Shi 1, Xiaojuan Qi 1, and Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Tencent YouTu Lab {lijiang,
GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction Li Jiang 1, Shaoshuai Shi 1, Xiaojuan Qi 1, and Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Tencent YouTu Lab {lijiang,
Learning Adversarial 3D Model Generation with 2D Image Enhancer
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
Computer Vision: Making machines see
 Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
3D Deep Learning
 3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
GANs for Exploiting Unlabeled Data. Presented by: Uriya Pesso Nimrod Gilboa Markevich
 GANs for Exploiting Unlabeled Data Improved Techniques for Training GANs Learning from Simulated and Unsupervised Images through Adversarial Training Presented by: Uriya Pesso Nimrod Gilboa Markevich [
GANs for Exploiting Unlabeled Data Improved Techniques for Training GANs Learning from Simulated and Unsupervised Images through Adversarial Training Presented by: Uriya Pesso Nimrod Gilboa Markevich [
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction
 Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction Chen-Hsuan Lin Chen Kong Simon Lucey The Robotics Institute Carnegie Mellon University chlin@cmu.edu, {chenk,slucey}@cs.cmu.edu
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction Chen-Hsuan Lin Chen Kong Simon Lucey The Robotics Institute Carnegie Mellon University chlin@cmu.edu, {chenk,slucey}@cs.cmu.edu
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Multiresolution Tree Networks for 3D Point Cloud Processing
 Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
Two Routes for Image to Image Translation: Rule based vs. Learning based. Minglun Gong, Memorial Univ. Collaboration with Mr.
 Two Routes for Image to Image Translation: Rule based vs. Learning based Minglun Gong, Memorial Univ. Collaboration with Mr. Zili Yi Introduction A brief history of image processing Image to Image translation
Two Routes for Image to Image Translation: Rule based vs. Learning based Minglun Gong, Memorial Univ. Collaboration with Mr. Zili Yi Introduction A brief history of image processing Image to Image translation
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction
 Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction Daeyun Shin 1 Charless C. Fowlkes 1 Derek Hoiem 2 1 University of California, Irvine 2 University
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction Daeyun Shin 1 Charless C. Fowlkes 1 Derek Hoiem 2 1 University of California, Irvine 2 University
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
S+U Learning through ANs - Pranjit Kalita
 S+U Learning through ANs - Pranjit Kalita - (from paper) Learning from Simulated and Unsupervised Images through Adversarial Training - Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda
S+U Learning through ANs - Pranjit Kalita - (from paper) Learning from Simulated and Unsupervised Images through Adversarial Training - Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Stochastic Simulation with Generative Adversarial Networks
 Stochastic Simulation with Generative Adversarial Networks Lukas Mosser, Olivier Dubrule, Martin J. Blunt lukas.mosser15@imperial.ac.uk, o.dubrule@imperial.ac.uk, m.blunt@imperial.ac.uk (Deep) Generative
Stochastic Simulation with Generative Adversarial Networks Lukas Mosser, Olivier Dubrule, Martin J. Blunt lukas.mosser15@imperial.ac.uk, o.dubrule@imperial.ac.uk, m.blunt@imperial.ac.uk (Deep) Generative
arxiv: v1 [cs.cv] 21 Jun 2017
![arxiv: v1 [cs.cv] 21 Jun 2017](/thumbs/82/85530580.jpg "arxiv: v1 [cs.cv] 21 Jun 2017") Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction arxiv:1706.07036v1 [cs.cv] 21 Jun 2017 Chen-Hsuan Lin, Chen Kong, Simon Lucey The Robotics Institute Carnegie Mellon University
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction arxiv:1706.07036v1 [cs.cv] 21 Jun 2017 Chen-Hsuan Lin, Chen Kong, Simon Lucey The Robotics Institute Carnegie Mellon University
arxiv: v1 [cs.cv] 27 Mar 2019
![arxiv: v1 [cs.cv] 27 Mar 2019](/thumbs/96/129261901.jpg "arxiv: v1 [cs.cv] 27 Mar 2019") Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles Siddharth Srivastava 1, Frederic Jurie 2 and Gaurav Sharma 3 arxiv:1904.08494v1 [cs.cv] 27 Mar 2019 Abstract We address the
Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles Siddharth Srivastava 1, Frederic Jurie 2 and Gaurav Sharma 3 arxiv:1904.08494v1 [cs.cv] 27 Mar 2019 Abstract We address the
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
arxiv: v2 [cs.cv] 31 Mar 2018
![arxiv: v2 [cs.cv] 31 Mar 2018](/thumbs/83/87889909.jpg "arxiv: v2 [cs.cv] 31 Mar 2018") CSGNet: Neural Shape Parser for Constructive Solid Geometry Gopal Sharma Rishabh Goyal Difan Liu Evangelos Kalogerakis Subhransu Maji University of Massachusetts, Amherst {gopalsharma,risgoyal,dliu,kalo,smaji}@cs.umass.edu
CSGNet: Neural Shape Parser for Constructive Solid Geometry Gopal Sharma Rishabh Goyal Difan Liu Evangelos Kalogerakis Subhransu Maji University of Massachusetts, Amherst {gopalsharma,risgoyal,dliu,kalo,smaji}@cs.umass.edu
arxiv: v1 [cs.cv] 10 Sep 2018
![arxiv: v1 [cs.cv] 10 Sep 2018](/thumbs/93/117973766.jpg "arxiv: v1 [cs.cv] 10 Sep 2018") Deep Single-View 3D Object Reconstruction with Visual Hull Embedding Hanqing Wang 1 Jiaolong Yang 2 Wei Liang 1 Xin Tong 2 1 Beijing Institute of Technology 2 Microsoft Research {hanqingwang,liangwei}@bit.edu.cn
Deep Single-View 3D Object Reconstruction with Visual Hull Embedding Hanqing Wang 1 Jiaolong Yang 2 Wei Liang 1 Xin Tong 2 1 Beijing Institute of Technology 2 Microsoft Research {hanqingwang,liangwei}@bit.edu.cn
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018
 Qixing Huang August 29 th 2018") CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
CS 395T Numerical Optimization for Graphics and AI (3D Vision) Qixing Huang August 29 th 2018 3D Vision Understanding geometric relations between images and the 3D world between images Obtaining 3D information
CSGNet: Neural Shape Parser for Constructive Solid Geometry
 CSGNet: Neural Shape Parser for Constructive Solid Geometry Gopal Sharma Rishabh Goyal Difan Liu Evangelos Kalogerakis Subhransu Maji University of Massachusetts, Amherst {gopalsharma,risgoyal,dliu,kalo,smaji}@cs.umass.edu
CSGNet: Neural Shape Parser for Constructive Solid Geometry Gopal Sharma Rishabh Goyal Difan Liu Evangelos Kalogerakis Subhransu Maji University of Massachusetts, Amherst {gopalsharma,risgoyal,dliu,kalo,smaji}@cs.umass.edu
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform. Xintao Wang Ke Yu Chao Dong Chen Change Loy
 Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision
 CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal *, Mayank Agarwal, and R. Venkatesh Babu Video Analytics Lab, CDS, Indian
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal *, Mayank Agarwal, and R. Venkatesh Babu Video Analytics Lab, CDS, Indian
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
Multi-view 3D Models from Single Images with a Convolutional Network
 Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Unsupervised Learning of Spatiotemporally Coherent Metrics
 Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
Web-Scale Image Search and Their Applications
 Web-Scale Image Search and Their Applications Sung-Eui Yoon KAIST http://sglab.kaist.ac.kr Project Guidelines: Project Topics Any topics related to the course theme are okay You can find topics by browsing
Web-Scale Image Search and Their Applications Sung-Eui Yoon KAIST http://sglab.kaist.ac.kr Project Guidelines: Project Topics Any topics related to the course theme are okay You can find topics by browsing
What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today?
 Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
Introduction What are we trying to achieve? Why are we doing this? What do we learn from past history? What will we talk about today? What are we trying to achieve? Example from Scott Satkin 3D interpretation
DeepPose & Convolutional Pose Machines
 DeepPose & Convolutional Pose Machines Main Concepts 1. 2. 3. 4. CNN with regressor head. Object Localization. Bigger to smaller or Smaller to bigger view. Deep Supervised learning to prevent Vanishing
DeepPose & Convolutional Pose Machines Main Concepts 1. 2. 3. 4. CNN with regressor head. Object Localization. Bigger to smaller or Smaller to bigger view. Deep Supervised learning to prevent Vanishing
GAN Related Works. CVPR 2018 & Selective Works in ICML and NIPS. Zhifei Zhang
 GAN Related Works CVPR 2018 & Selective Works in ICML and NIPS Zhifei Zhang Generative Adversarial Networks (GANs) 9/12/2018 2 Generative Adversarial Networks (GANs) Feedforward Backpropagation Real? z
GAN Related Works CVPR 2018 & Selective Works in ICML and NIPS Zhifei Zhang Generative Adversarial Networks (GANs) 9/12/2018 2 Generative Adversarial Networks (GANs) Feedforward Backpropagation Real? z
Generative Adversarial Network
 Generative Adversarial Network Many slides from NIPS 2014 Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio Generative adversarial
Generative Adversarial Network Many slides from NIPS 2014 Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio Generative adversarial
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Su et al. Shape Descriptors - III
 Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
08 An Introduction to Dense Continuous Robotic Mapping
 NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction
 Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss
 UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss AAAI 2018, New Orleans, USA Simon Meister, Junhwa Hur, and Stefan Roth Department of Computer Science, TU Darmstadt 2 Deep
UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss AAAI 2018, New Orleans, USA Simon Meister, Junhwa Hur, and Stefan Roth Department of Computer Science, TU Darmstadt 2 Deep
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Visual Computing TUM
 Visual Computing Group @ TUM Visual Computing Group @ TUM BundleFusion Real-time 3D Reconstruction Scalable scene representation Global alignment and re-localization TOG 17 [Dai et al.]: BundleFusion Real-time
Visual Computing Group @ TUM Visual Computing Group @ TUM BundleFusion Real-time 3D Reconstruction Scalable scene representation Global alignment and re-localization TOG 17 [Dai et al.]: BundleFusion Real-time
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Visual Recommender System with Adversarial Generator-Encoder Networks
 Visual Recommender System with Adversarial Generator-Encoder Networks Bowen Yao Stanford University 450 Serra Mall, Stanford, CA 94305 boweny@stanford.edu Yilin Chen Stanford University 450 Serra Mall
Visual Recommender System with Adversarial Generator-Encoder Networks Bowen Yao Stanford University 450 Serra Mall, Stanford, CA 94305 boweny@stanford.edu Yilin Chen Stanford University 450 Serra Mall
Announcements. Recognition I. Gradient Space (p,q) What is the reflectance map?
 What is the reflectance map?") Announcements I HW 3 due 12 noon, tomorrow. HW 4 to be posted soon recognition Lecture plan recognition for next two lectures, then video and motion. Introduction to Computer Vision CSE 152 Lecture 17
Announcements I HW 3 due 12 noon, tomorrow. HW 4 to be posted soon recognition Lecture plan recognition for next two lectures, then video and motion. Introduction to Computer Vision CSE 152 Lecture 17
3D Object Classification via Spherical Projections
 3D Object Classification via Spherical Projections Zhangjie Cao 1,QixingHuang 2,andRamaniKarthik 3 1 School of Software Tsinghua University, China 2 Department of Computer Science University of Texas at
3D Object Classification via Spherical Projections Zhangjie Cao 1,QixingHuang 2,andRamaniKarthik 3 1 School of Software Tsinghua University, China 2 Department of Computer Science University of Texas at
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Analysis and Synthesis of 3D Shape Families via Deep Learned Generative Models of Surfaces
 Analysis and Synthesis of 3D Shape Families via Deep Learned Generative Models of Surfaces Haibin Huang, Evangelos Kalogerakis, Benjamin Marlin University of Massachusetts Amherst Given an input 3D shape
Analysis and Synthesis of 3D Shape Families via Deep Learned Generative Models of Surfaces Haibin Huang, Evangelos Kalogerakis, Benjamin Marlin University of Massachusetts Amherst Given an input 3D shape
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
arxiv: v1 [cs.cv] 19 Jul 2017
![arxiv: v1 [cs.cv] 19 Jul 2017](/thumbs/81/83678394.jpg "arxiv: v1 [cs.cv] 19 Jul 2017") GADELHA ET AL.: SHAPE GENERATION USING SPATIALLY PARTITIONED POINT CLOUDS1 arxiv:1707.06267v1 [cs.cv] 19 Jul 2017 Shape Generation using Spatially Partitioned Point Clouds Matheus Gadelha mgadelha@cs.umass.edu
GADELHA ET AL.: SHAPE GENERATION USING SPATIALLY PARTITIONED POINT CLOUDS1 arxiv:1707.06267v1 [cs.cv] 19 Jul 2017 Shape Generation using Spatially Partitioned Point Clouds Matheus Gadelha mgadelha@cs.umass.edu
Generative Adversarial Text to Image Synthesis
 Generative Adversarial Text to Image Synthesis Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, Honglak Lee Presented by: Jingyao Zhan Contents Introduction Related Work Method
Generative Adversarial Text to Image Synthesis Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, Honglak Lee Presented by: Jingyao Zhan Contents Introduction Related Work Method
arxiv: v1 [cs.cv] 17 Nov 2016
![arxiv: v1 [cs.cv] 17 Nov 2016](/thumbs/86/93859848.jpg "arxiv: v1 [cs.cv] 17 Nov 2016") Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014
 Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
GENERATIVE ADVERSARIAL NETWORKS (GAN) Presented by Omer Stein and Moran Rubin
 Presented by Omer Stein and Moran Rubin") GENERATIVE ADVERSARIAL NETWORKS (GAN) Presented by Omer Stein and Moran Rubin GENERATIVE MODEL Given a training dataset, x, try to estimate the distribution, Pdata(x) Explicitly or Implicitly (GAN) Explicitly
GENERATIVE ADVERSARIAL NETWORKS (GAN) Presented by Omer Stein and Moran Rubin GENERATIVE MODEL Given a training dataset, x, try to estimate the distribution, Pdata(x) Explicitly or Implicitly (GAN) Explicitly
Generative Modeling with Convolutional Neural Networks. Denis Dus Data Scientist at InData Labs
 Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
Unsupervised Deep Learning. James Hays slides from Carl Doersch and Richard Zhang
 Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey
 Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
Presented at the FIG Congress 2018, May 6-11, 2018 in Istanbul, Turkey Evangelos MALTEZOS, Charalabos IOANNIDIS, Anastasios DOULAMIS and Nikolaos DOULAMIS Laboratory of Photogrammetry, School of Rural
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Introduction to Deep Learning
 ENEE698A : Machine Learning Seminar Introduction to Deep Learning Raviteja Vemulapalli Image credit: [LeCun 1998] Resources Unsupervised feature learning and deep learning (UFLDL) tutorial (http://ufldl.stanford.edu/wiki/index.php/ufldl_tutorial)
ENEE698A : Machine Learning Seminar Introduction to Deep Learning Raviteja Vemulapalli Image credit: [LeCun 1998] Resources Unsupervised feature learning and deep learning (UFLDL) tutorial (http://ufldl.stanford.edu/wiki/index.php/ufldl_tutorial)
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Geometric and Semantic 3D Reconstruction: Part 4A: Volumetric Semantic 3D Reconstruction. CVPR 2017 Tutorial Christian Häne UC Berkeley
 Geometric and Semantic 3D Reconstruction: Part 4A: Volumetric Semantic 3D Reconstruction CVPR 2017 Tutorial Christian Häne UC Berkeley Dense Multi-View Reconstruction Goal: 3D Model from Images (Depth
Geometric and Semantic 3D Reconstruction: Part 4A: Volumetric Semantic 3D Reconstruction CVPR 2017 Tutorial Christian Häne UC Berkeley Dense Multi-View Reconstruction Goal: 3D Model from Images (Depth
3D Reconstruction of Dynamic Textures with Crowd Sourced Data. Dinghuang Ji, Enrique Dunn and Jan-Michael Frahm
 3D Reconstruction of Dynamic Textures with Crowd Sourced Data Dinghuang Ji, Enrique Dunn and Jan-Michael Frahm 1 Background Large scale scene reconstruction Internet imagery 3D point cloud Dense geometry
3D Reconstruction of Dynamic Textures with Crowd Sourced Data Dinghuang Ji, Enrique Dunn and Jan-Michael Frahm 1 Background Large scale scene reconstruction Internet imagery 3D point cloud Dense geometry
(University Improving of Montreal) Generative Adversarial Networks with Denoising Feature Matching / 17
 Generative Adversarial Networks with Denoising Feature Matching / 17") Improving Generative Adversarial Networks with Denoising Feature Matching David Warde-Farley 1 Yoshua Bengio 1 1 University of Montreal, ICLR,2017 Presenter: Bargav Jayaraman Outline 1 Introduction 2 Background
Improving Generative Adversarial Networks with Denoising Feature Matching David Warde-Farley 1 Yoshua Bengio 1 1 University of Montreal, ICLR,2017 Presenter: Bargav Jayaraman Outline 1 Introduction 2 Background
Learning and Recognizing Visual Object Categories Without First Detecting Features
 Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Lecture 19: Generative Adversarial Networks
 Lecture 19: Generative Adversarial Networks Roger Grosse 1 Introduction Generative modeling is a type of machine learning where the aim is to model the distribution that a given set of data (e.g. images,
Lecture 19: Generative Adversarial Networks Roger Grosse 1 Introduction Generative modeling is a type of machine learning where the aim is to model the distribution that a given set of data (e.g. images,