What to come. There will be a few more topics we will cover on supervised learning
|
|
|
- Everett Foster
- 5 years ago
- Views:
Transcription
1 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression (linear) Decision tree (nonlinear) Nearest Neighbor (nonlinear) Generative models Bayes classifier (not really practical) Naïve bayes classifier (conditional independence between features given class label)
2 What to come There will be a few more topics we will cover on supervised learning Ensemble methods Neural nets (perhaps) But we will delay this for a couple of weeks We will talk about unsupervised learning such that you are not limited to supervised learning when thinking about your project
3 Unsupervised learning, Clustering CS434
4 Unsupervised learning and pattern discovery So far, our data has been in this form: We will be looking at unlabeled data: x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,, x 2 m x 1n,x 2n, x 3n,, x n m y 1 y 2 y n x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,, x 2 m x 1n,x 2n, x 3n,, x n m What do we expect to learn from such data? I have tons of data (web documents, gene data, etc) and need to: organize it better e.g., find subgroups understand it better e.g., understand interrelationships find regular trends in it e.g., If A and B, then C


5 Hierarchical clustering as a way to organize web pages
6 Finding association patterns in data

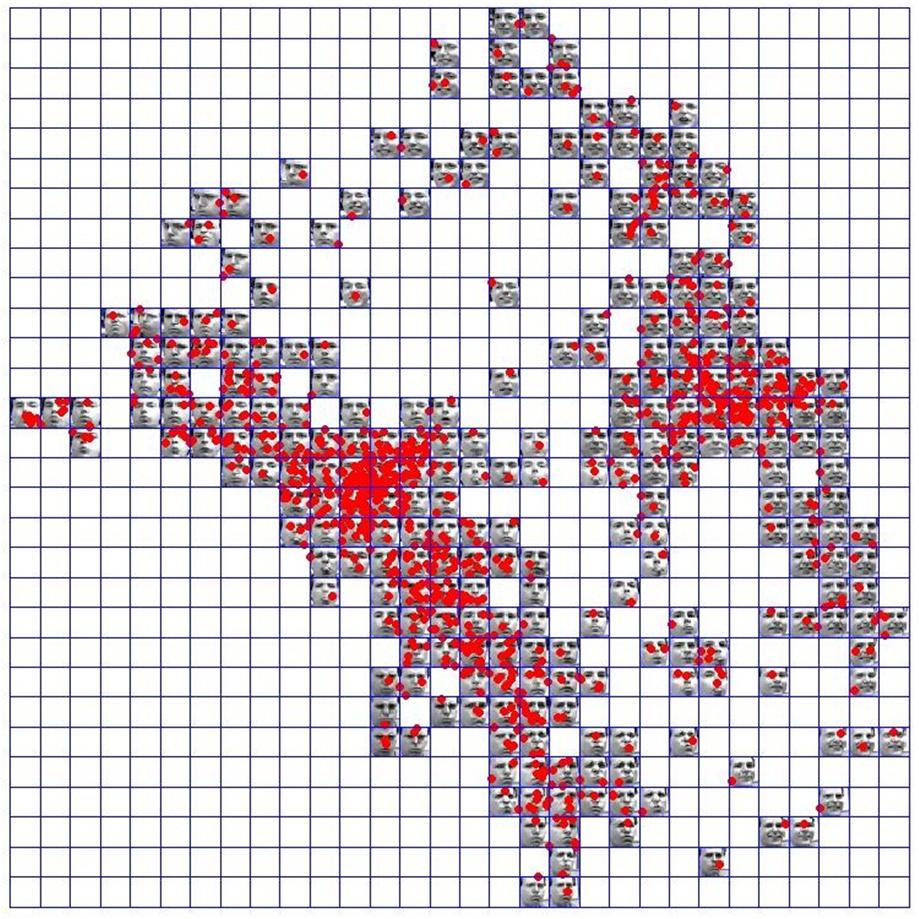
7 Dimension reduction
8 clustering
9 A hypothetical clustering example Monthly spending Each point represents a person in the database Monthly income
10 A hypothetical clustering example Monthly spending This suggests there maybe three distinct spending patterns among the group of people in our database. Monthly income
11 What is Clustering In general clustering can be viewed as an exploratory procedure for finding interesting subgroups in given data A large portion of the efforts focus on a special kind of clustering: Group all given examples (i.e., exhaustive) into disjoint clusters (i.e., partitional), such that: Examples within a cluster are (very) similar Examples in different clusters are (very) different
12 Some example applications Information retrieval: cluster retrieved documents to present more organized and understandable results Consumer market analysis: cluster consumers into different interest groups so that marketing plans can be specifically designed for each individual group Image segmentation: decompose an image into regions with coherent color and texture Vector quantization for data (i.e., image) compression: group vectors into similar groups, and use group mean to represent group members Computational biology: group gene into co-expressed families based on their expression profile using different tissue samples and different experimental conditions

13 Image compression: Vector quantization Group all pixels into self-similar groups, instead of storing all pixel values, store the means of each group 701,554 bytes 127,292 bytes
14 Important components in clustering Distance/similarity measure How to measure the similarity between two objects? Clustering algorithm How to find the clusters based on the distance/similarity measures Evaluation of results How do we know that our clustering result is good


15 Distance/similarity Measures One of the most important question in unsupervised learning, often more important than the choice of clustering algorithms What is similarity? Similarity is hard to define, but we know it when we see it More pragmatically, there are many mathematical definitions of distance/similarity
16 Common distance/similarity measures Euclidean distance Manhattan distance L d 2 2 x i x i 2 ( x, x ) ( ) i 1 Straight line distance >=0 City block distance >=0 Cosine similarity Angle between two vectors, commonly used for measuring document similarity More flexible measures: D d ( x, x ) wi ( xi xi i 1 one can learn the appropriate weights given user guidance ) 2 Scale each feature differently using w i s Note: We can always transform between distance and similarity using a monotonically decreasing function, for example
17 How to decide which to use? It is application dependent Consider your application domain, you need to ask questions such as: What does it mean for two consumers to be similar to each other? Or for two genes to be similar to each other? For example, for text domain, we typically use cosine similarity This may or may not give you the answer you want depends on your existing knowledge of the domain When domain knowledge is not enough, one could consider learning based approach

18 A learning approach Ideally we d like to learn a distance function from user s inputs Ask users to provide things like object A is similar to object B, dissimilar to object C For example, if a user want to group the marbles based on their pattern They don t belong together! They belong together! Learn a distance function to correctly reflect these relationships E.g. weigh pattern-related features more than color features This is a more advanced topic that we will not cover in this class, but nonetheless very important
19 When we can not afford to learn a distance measure, and don t have a clue about which distance function is appropriate, what should we do? Clustering is an exploratory procedure and it is important to explore i.e., try different options
20 Clustering Now we have seen different ways that one can use to measure distances or similarities among a set of unlabeled objects, how can we use them to group the objects into clusters? People have looked at many different approaches and they can be categorized into two distinct types
21 Hierarchical and non-hierarchical Clustering Hierarchical clustering builds a tree-based hierarchical taxonomy (dendrogram) animal vertebrate invertebrate fish reptile mammal worm insect A non-hierarchical (flat) clustering produces a single partition of the unlabeled data Generates a single partition of the data without resorting to the hierarchical procedure Representative example for flat clustering: K-means clustering
22 Goal of Clustering Given a data set We need to partition into disjoint clusters, such that Examples are self-similar in the same cluster How do we quantify this?
23 Objective: Sum of Squared Errors Given a partition of the data into k clusters, we can compute the center (i.e., mean, center of mass) of each cluster For a well formed cluster, its points should be close to its center. We measure this with sum of squared error (SSE): Our objective is thus to find a partition : 1 argmin,, This is a combinatorial optimization problem x x NP-hard Kmeans finds a local optimal solution using an iterative approach
24 Basic idea We assume that the number of desired clusters, k, is given Randomly choose k examples as seeds, one per cluster. Form initial clusters based on these seeds. Iterate by repeatedly reallocating instances to different clusters to improve the overall clustering. Stop when clustering converges or after a fixed number of iterations.
25 The Standard K-means algorithm Input: 1 2 and desired number of clusters Output: 1 such that D = 1 2 Let d be the distance function between examples 1. Select random samples from as centers 1 //Initialization 2. Do 3. for each example, 4. assign to such that, 1 is minimized // the Assignment step 5. for each cluster j, update its cluster center 6. 1 j x c j x c j 7. Until convergence // the update step
26 K-Means Example (K=2)
27 K-Means Example (K=2) Pick seeds
28 K-Means Example (K=2) Pick seeds Reassign clusters
29 K-Means Example (K=2) Pick seeds Reassign clusters Compute centroids x x
30 K-Means Example (K=2) Pick seeds Reassign clusters Compute centroids x x Reasssign clusters
31 K-Means Example (K=2) Pick seeds Reassign clusters Compute centroids Reasssign clusters x x x x Compute centroids
32 K-Means Example (K=2) Pick seeds Reassign clusters Compute centroids Reasssign clusters x x x x Compute centroids Reassign clusters
33 K-Means Example (K=2) Pick seeds Reassign clusters Compute centroids Reasssign clusters x x x x Compute centroids Reassign clusters Converged!
34 Monotonicity of K-means Monotonicity Property: Each iteration of K- means strictly decreases the SSE until convergence The following lemma is key to the proof: Lemma: Given a finite set C of data points the value of μ that minimizes the SSE: is: x x
35 Proof of monoticity Given a current set of clusters with their means, the SSE is given by : x x Consider the assignment step: Since each point is only reassigned if it is closer to some other cluster than its current cluster, so we know the reassignment step will only decrease SSE Consider the re-center step: From our lemma we know the updated minimizes the SSE of, which implies that the resulting SSE again is decreased. Combine the above two, we know K-means always decreases the SSE
36 K-means properties K-means always converges in a finite number of steps Typically converges very fast (in fewer iterations than n ) Time complexity: Assume computing distance between two instances is where is the dimensionality of the vectors. Reassigning clusters: distance computations, or. Computing centers: Each instance vector gets added once to some center:. Assume these two steps are each done once for iterations:. Linear in all relevant factors, assuming a fixed number of iterations
37 More Comments Highly sensitive to the initial seeds This is because SSE has many local minimal solutions, i.e., solutions that can not be improved by local reassignments of any particular points
38 Solutions Run multiple trials and choose the one with the best SSE This is typically done in practice Heuristics: try to choose initial centers to be far apart Using furthest-first traversal Start with a random initial center Set the second center to be furthest from the first center The third center to be furthest from the first two centers
39 Even more comments K-Means is exhaustive: Cluster every data point, no notion of outlier Outliers may cause problems, why? x x
40 K-medoids Outliers strongly impact the cluster centers K-medoids use the medoid for each cluster, i.e., the data point that is closest to other points in the cluster argmin x x z z K-medoids is computationally more expensive but more robust to outliers
41 Deciding k a model selection problem What if we don t know how many clusters there are in the data? Can we use SSE to decide k by choosing k that gives the smallest SSE? We will always favor larger k values Any quick solutions? Find the knee(s)
Unsupervised learning, Clustering CS434
 Unsupervised learning, Clustering CS434 Unsupervised learning and pattern discovery So far, our data has been in this form: We will be looking at unlabeled data: x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,,
Unsupervised learning, Clustering CS434 Unsupervised learning and pattern discovery So far, our data has been in this form: We will be looking at unlabeled data: x 11,x 21, x 31,, x 1 m x 12,x 22, x 32,,
Lecture 15 Clustering. Oct
 Lecture 15 Clustering Oct 31 2008 Unsupervised learning and pattern discovery So far, our data has been in this form: x 11,x 21, x 31,, x 1 m y1 x 12 22 2 2 2,x, x 3,, x m y We will be looking at unlabeled
Lecture 15 Clustering Oct 31 2008 Unsupervised learning and pattern discovery So far, our data has been in this form: x 11,x 21, x 31,, x 1 m y1 x 12 22 2 2 2,x, x 3,, x m y We will be looking at unlabeled
Clust Clus e t ring 2 Nov
 Clustering 2 Nov 3 2008 HAC Algorithm Start t with all objects in their own cluster. Until there is only one cluster: Among the current clusters, determine the two clusters, c i and c j, that are most
Clustering 2 Nov 3 2008 HAC Algorithm Start t with all objects in their own cluster. Until there is only one cluster: Among the current clusters, determine the two clusters, c i and c j, that are most
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Clustering CE-324: Modern Information Retrieval Sharif University of Technology
 Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Clustering Part 1. CSC 4510/9010: Applied Machine Learning. Dr. Paula Matuszek
 CSC 4510/9010: Applied Machine Learning 1 Clustering Part 1 Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 What is Clustering? 2 Given some instances with data:
CSC 4510/9010: Applied Machine Learning 1 Clustering Part 1 Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 What is Clustering? 2 Given some instances with data:
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Text Clustering Prof. Chris Clifton 19 October 2018 Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti Document clustering Motivations Document
CS47300: Web Information Search and Management Text Clustering Prof. Chris Clifton 19 October 2018 Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti Document clustering Motivations Document
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
CS 8520: Artificial Intelligence. Machine Learning 2. Paula Matuszek Fall, CSC 8520 Fall Paula Matuszek
 CS 8520: Artificial Intelligence Machine Learning 2 Paula Matuszek Fall, 2015!1 Regression Classifiers We said earlier that the task of a supervised learning system can be viewed as learning a function
CS 8520: Artificial Intelligence Machine Learning 2 Paula Matuszek Fall, 2015!1 Regression Classifiers We said earlier that the task of a supervised learning system can be viewed as learning a function
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Introduction to Data Mining
 Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16)
") CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Hierarchical Clustering
 Hierarchical Clustering Build a tree-based hierarchical taxonomy (dendrogram) from a set animal of documents. vertebrate invertebrate fish reptile amphib. mammal worm insect crustacean One approach: recursive
Hierarchical Clustering Build a tree-based hierarchical taxonomy (dendrogram) from a set animal of documents. vertebrate invertebrate fish reptile amphib. mammal worm insect crustacean One approach: recursive
Kapitel 4: Clustering
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases WiSe 2017/18 Kapitel 4: Clustering Vorlesung: Prof. Dr.
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Statistics 202: Statistical Aspects of Data Mining
 Statistics 202: Statistical Aspects of Data Mining Professor Rajan Patel Lecture 11 = Chapter 8 Agenda: 1)Reminder about final exam 2)Finish Chapter 5 3)Chapter 8 1 Class Project The class project is due
Statistics 202: Statistical Aspects of Data Mining Professor Rajan Patel Lecture 11 = Chapter 8 Agenda: 1)Reminder about final exam 2)Finish Chapter 5 3)Chapter 8 1 Class Project The class project is due
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
CS 8520: Artificial Intelligence
 CS 8520: Artificial Intelligence Machine Learning 2 Paula Matuszek Spring, 2013 1 Regression Classifiers We said earlier that the task of a supervised learning system can be viewed as learning a function
CS 8520: Artificial Intelligence Machine Learning 2 Paula Matuszek Spring, 2013 1 Regression Classifiers We said earlier that the task of a supervised learning system can be viewed as learning a function
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
CS 2750: Machine Learning. Clustering. Prof. Adriana Kovashka University of Pittsburgh January 17, 2017
 CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
CS 2750: Machine Learning Clustering Prof. Adriana Kovashka University of Pittsburgh January 17, 2017 What is clustering? Grouping items that belong together (i.e. have similar features) Unsupervised:
Machine Learning (CSE 446): Unsupervised Learning
: Unsupervised Learning") Machine Learning (CSE 446): Unsupervised Learning Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 19 Announcements HW2 posted. Due Feb 1. It is long. Start this week! Today:
Machine Learning (CSE 446): Unsupervised Learning Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 19 Announcements HW2 posted. Due Feb 1. It is long. Start this week! Today:
Cluster Analysis: Basic Concepts and Algorithms
 7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
7 Cluster Analysis: Basic Concepts and Algorithms Cluster analysis divides data into groups (clusters) that are meaningful, useful, or both. If meaningful groups are the goal, then the clusters should
K-Means. Oct Youn-Hee Han
 K-Means Oct. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²K-Means algorithm An unsupervised clustering algorithm K stands for number of clusters. It is typically a user input to the algorithm Some criteria
K-Means Oct. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²K-Means algorithm An unsupervised clustering algorithm K stands for number of clusters. It is typically a user input to the algorithm Some criteria
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
DD2475 Information Retrieval Lecture 10: Clustering. Document Clustering. Recap: Classification. Today
 Sec.14.1! Recap: Classification DD2475 Information Retrieval Lecture 10: Clustering Hedvig Kjellström hedvig@kth.se www.csc.kth.se/dd2475 Data points have labels Classification task: Finding good separators
Sec.14.1! Recap: Classification DD2475 Information Retrieval Lecture 10: Clustering Hedvig Kjellström hedvig@kth.se www.csc.kth.se/dd2475 Data points have labels Classification task: Finding good separators
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
CS490W. Text Clustering. Luo Si. Department of Computer Science Purdue University
 CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Unsupervised Learning I: K-Means Clustering
 Unsupervised Learning I: K-Means Clustering Reading: Chapter 8 from Introduction to Data Mining by Tan, Steinbach, and Kumar, pp. 487-515, 532-541, 546-552 (http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf)
Unsupervised Learning I: K-Means Clustering Reading: Chapter 8 from Introduction to Data Mining by Tan, Steinbach, and Kumar, pp. 487-515, 532-541, 546-552 (http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf)
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Exploratory Analysis: Clustering
 Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Chapter 6: Cluster Analysis
 Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
k-means demo Administrative Machine learning: Unsupervised learning" Assignment 5 out
 Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms
 Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
Clustering Basic Concepts and Algorithms 1
 Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Clustering Basic Concepts and Algorithms 1 Jeff Howbert Introduction to Machine Learning Winter 014 1 Machine learning tasks Supervised Classification Regression Recommender systems Reinforcement learning
Exploratory data analysis for microarrays
 Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Exploratory data analysis for microarrays Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany NGFN - Courses in Practical DNA
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Natural Language Processing
 Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
A Dendrogram. Bioinformatics (Lec 17)
") A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
A Dendrogram 3/15/05 1 Hierarchical Clustering [Johnson, SC, 1967] Given n points in R d, compute the distance between every pair of points While (not done) Pick closest pair of points s i and s j and
CSE 255 Lecture 6. Data Mining and Predictive Analytics. Community Detection
 CSE 255 Lecture 6 Data Mining and Predictive Analytics Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
CSE 255 Lecture 6 Data Mining and Predictive Analytics Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
Unsupervised Learning: Clustering
 Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Data Clustering. Danushka Bollegala
 Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Clustering and Dimensionality Reduction. Stony Brook University CSE545, Fall 2017
 Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Cluster analysis formalism, algorithms. Department of Cybernetics, Czech Technical University in Prague.
 Cluster analysis formalism, algorithms Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz poutline motivation why clustering? applications, clustering as
Cluster analysis formalism, algorithms Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz poutline motivation why clustering? applications, clustering as
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
Machine Learning - Clustering. CS102 Fall 2017
 Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
Improved Performance of Unsupervised Method by Renovated K-Means
 Improved Performance of Unsupervised Method by Renovated P.Ashok Research Scholar, Bharathiar University, Coimbatore Tamilnadu, India. ashokcutee@gmail.com Dr.G.M Kadhar Nawaz Department of Computer Application
Improved Performance of Unsupervised Method by Renovated P.Ashok Research Scholar, Bharathiar University, Coimbatore Tamilnadu, India. ashokcutee@gmail.com Dr.G.M Kadhar Nawaz Department of Computer Application
Clustering. Unsupervised Learning
 Clustering. Unsupervised Learning Maria-Florina Balcan 11/05/2018 Clustering, Informal Goals Goal: Automatically partition unlabeled data into groups of similar datapoints. Question: When and why would
Clustering. Unsupervised Learning Maria-Florina Balcan 11/05/2018 Clustering, Informal Goals Goal: Automatically partition unlabeled data into groups of similar datapoints. Question: When and why would
Introduction to Clustering
 Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of
Introduction to Clustering Ref: Chengkai Li, Department of Computer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) What is Cluster Analysis? Finding groups of