Deep Learning on Point Sets for 3D Classification and Segmentation
|
|
|
- Horace Lynch
- 5 years ago
- Views:
Transcription



1 Deep Learning on Point Sets for 3D Classification and Segmentation Charles Ruizhongtai Qi Stanford University Abstract Point cloud is an important type of geometric data structure. Due to its irregular format, most researchers transform such data to regular 3D voxel grids or collections of images. This, however, renders data unnecessarily voluminous and causes issues. In this paper, we design a novel type of neural network that directly consumes point clouds and well respects the permutation invariance of points in the input. Our network, named PointNet, provides a unified architecture for applications ranging from object classification, part segmentation, to scene semantic parsing. Though simple, PointNet is highly efficient and effective. Empirically, it shows strong performance on par or even better than state of the art. We also provide analysis towards understanding of what the network has learnt and why the network is robust with respect to input perturbation and corruption. 1. Introduction In this paper we explore deep learning architectures capable of reasoning about 3D geometric data such as point clouds or meshes. Typical convolutional architectures require highly regular input data formats, like those of image grids or 3D voxels, in order to perform weight sharing and other kernel optimizations. Since point clouds or meshes are not in a regular format, most researchers typically transform such data to regular 3D voxel grids or collections of images (e.g, views) before feeding them to a deep net architecture. This data representation transformation, however, renders the resulting data unnecessarily voluminous while also introducing quantization artifacts that can obscure natural invariances of the data. For this reason we focus on a different input representation for 3D geometry using simply point clouds and name our resulting deep nets PointNets. Point clouds are simple and unified structures that avoid the combinatorial irregularities and complexities of meshes, This project is a joint work with Hao Su, Kaichun Mo and Leo Guibas for CVPR 2017 submission. mug? table? car? Classification PointNet Part Segmentation Semantic Segmentation Figure 1. Applications of PointNet. We propose a novel deep net architecture that consumes raw point cloud (set of points) without voxelization or rendering. It is a unified architecture that learns both global and local point features, providing a simple, efficient and effective approach for a number of 3D recognition tasks. and thus are easier to learn from. The PointNet, however, still has to respect the fact that a point cloud is just a set of points and therefore invariant to permutations of its members, necessitating certain symmetrizations in the net computation. Further invariances to rigid motions also need to be considered. Our PointNet is a unified architecture that directly takes point clouds as input and outputs either class labels for the entire input or per point segment/part labels for each point of the input. The basic architecture of our network is surprisingly simple as in the initial stages each point is processed identically and independently. In the basic setting each point is represented by just its three coordinates (x, y, z). Additional dimensions may be added by computing normals and other local or global features. Key to our approach is the use of a single symmetric function, max pooling. Effectively the network learns a set of optimization functions/criteria that select interesting or informative points of the point cloud and encode the reason for their selection. The final fully connected layers of the network aggregate these learnt optimal values into the global descriptor for the entire shape as mentioned above (shape classification) or are used to predict per point labels (shape segmentation). Our input format is easy to apply rigid or affine transformations to, as each point transforms independently. Thus we can add a data-dependent spatial transformer network 1
2 that attempts to canonicalize the data before the PointNet processes them, so as to further improve the results. We provide both a theoretical analysis and an experimental evaluation of our approach. We show that our network can approximate any set function that is continuous. More interestingly, it turns out that our network learns to summarize an input point cloud by a sparse set of key points, which roughly corresponds to the skeleton of objects according to visualization. The theoretical analysis provides an understanding why our PointNet is highly robust to small perturbation of input points as well as to corruption through point insertion (outliers) or deletion (missing data). On a number of benchmark datasets ranging from shape classification, part segmentation to scene segmentation, we experimentally compare our PointNet with state-ofthe-art approaches based upon multi-view and volumetric representations. Under a unified architecture, not only is our PointNet much faster in speed, but it also exhibits strong performance on par or even better than state of the art. The key contributions of our work are as follows: We design a novel deep net architecture suitable for consuming unordered point sets in 3D; We show how such a net can be trained to perform 3D shape classification, shape part segmentation and scene semantic parsing tasks; We provide thorough empirical and theoretical analysis on the stability and efficiency of our method; We illustrate the 3D features computed by the selected neurons in the net and develop intuitive explanations for its performance. The problem of processing unordered sets by neural nets is a very general and fundamental problem we expect that our ideas can be transferred to other domains as well. 2. Related Work Point Cloud Features Most existing features for point cloud are handcrafted towards specific tasks. Point features often encode certain statistical properties of points and are designed to be invariant to certain transformations, which are typically classified as intrinsic [2, 21, 3] or extrinsic [18, 17, 13, 10, 5]. They can also be categorized as local features and global features. For a specific task, it is not trivial to find the optimal feature combination. Deep Learning on 3D Data 3D data has multiple popular representations, leading to various approaches for learning. Volumetric CNNs: [25, 15, 16] are the pioneers applying 3D convolutional neural networks on voxelized shapes. However, volumetric representation is constrained by its resolution due to data sparsity and computation cost of 3D convolution. FPNN [12] and Vote3D [23] proposed special methods to deal with the sparsity problem; however, their operations are still on sparse volumes, it s challenging for them to process very large point clouds. Multiview CNNs: [20, 16] have tried to render 3D point cloud or shapes into 2D images and then apply 2D conv nets to classify them. With well engineered image CNNs, this line of methods have achieved dominating performance on shape classification and retrieval tasks [19]. However, it s nontrivial to extend them to scene understanding or other 3D tasks such as point classification and shape completion. Spectral CNNs: Some latest works [4, 14] use spectral CNNs on meshes. However, these methods are currently constrained on manifold meshes such as organic objects and it s not obvious how to extend them to non-isometric shapes such as furniture. Feature-based DNNs: [6, 8] firstly convert the 3D data into a vector, by extracting traditional shape features and then use a fully connected net to classify the shape. We think they are constrained by the representation power of the features extracted. Deep Learning on Unordered Sets From a data structure point of view, a point cloud is an unordered set of vectors. While most works in deep learning focus on regular input representations like sequences (in speech and language processing), images and volumes (video or 3D data), not much work has been done in deep learning on point sets. One recent work from Oriol Vinyals et al [22] looks into this problem. They use a read-process-write network with attention mechanism to consume unordered input sets and show that their network has the ability to sort numbers. However, since their work focuses on generic sets and NLP applications, there lacks the role of geometry in the sets. 3. Problem Statement We design a deep learning framework that directly consumes unordered point sets as inputs. A point cloud is represented as a set of 3D points {P i i =1,...,n}, where each point P i is a vector of its (x, y, z) coordinate plus extra feature channels such as color, normal etc. For simplicity and clarity, unless otherwise noted, we only use the (x, y, z) coordinate as our point s channels. For the object classification task, the input point cloud is either directly sampled from a shape or pre-segmented from a scene point cloud. Our proposed deep network outputs k scores for all the k candidate classes. For semantic segmentation, the input can be a single object for part region segmentation, or a sub-volume from a 3D scene for object region segmentation. Our model will output n m scores for each of the n points and each of the m semantic subcategories.
3 input points Classification Network nx3 input transform T-Net matrix multiply nx3 3x3 transform mlp (64,64) feature mlp (64,128,1024) transform shared T-Net nx64 64x64 transform matrix multiply nx64 n x 1088 shared Segmentation Network nx1024 shared mlp (512,256) max pool 1024 point features nx128 global feature shared mlp (128,m) mlp (512,256,k) output scores nxm k output scores Figure 2. PointNet Architecture. The classification network takes n points as input, applies input and feature transformations, and then aggregates point features by max pooling. The output is classification score for k classes. The segmentation network is an extension to the classification net. It concatenates global and local features and outputs per point scores. mlp stands for multi-layer perceptron, the numbers in brackets are its layer sizes. Batchnorm is used for all layers with ReLU. Dropout layers are used for the last mlp in classification net. 4. Deep Learning on Point Sets The architecture of our network (Sec 4.2) is inspired by the properties of point sets in R n (Sec 4.1) Properties of Point Sets in R n Our input is a subset of points from an Euclidean space. It has three main properties: Unordered. Unlike pixel arrays in images or voxel arrays in volumetric grids, point cloud is a set of points without specific order in the points. In other words, a network that consumes N 3D point sets needs to be invariant to N! permutations of the input set in data feeding order. Interaction among points. The points are from a space with a distance metric. It means that points are not isolated, and neighboring points form a meaningful subset. Therefore, the model needs to be able to capture local structures from nearby points, and the combinatorial interactions among local structures. Invariance under transformations. As a geometric object, the learned representation of the point set should be invariant to certain transformations. For example, rotating and translating points all together should not modify the global point cloud category nor the segmentation of the points PointNet Architecture Our full network architecture is visualized in Fig 2, where the classification network and the segmentation network share a great portion of structures. Please read the caption of Fig 2 for the pipeline. Our network has three key modules: the max pooling layer as a symmetric function to aggregate information from all the points, a local and global information combination structure, and two joint alignment networks that align both input points and point features. We will discuss our reason behind these design choices in separate paragraphs below. Symmetry Function for Unordered Input In order to make a model invariant to input permutation, three strategies exist: 1) sorting input into a canonical order; 2) treat the input as a sequence to train an RNN, but augment the training data by all kinds of permutations; 3) use a simple symmetric function to aggregate the information from each point. Here, a symmetric function takes n vectors as input and outputs a new vector that is invariant to the input order. For example, + and operators are symmetric binary functions. While sorting sounds like a simple solution, in high dimensional space there in fact does not exist an ordering that is stable w.r.t. point perturbations in the general sense. This can be easily shown by contradiction. If such an ordering strategy exists, it defines a bijection map between a high-dimensional space and a 1d real line. It is not hard to see, to require an ordering to be stable w.r.t point perturbations is equivalent to requiring that this map preserves spatial proximity as the dimension reduces, a task that cannot be achieved in the general case. Therefore, sorting does not fully resolve the ordering issue, and it s hard for a network to learn a consistent mapping from input to output as the ordering issue persists. As shown in experiments (Fig 5), we find that applying a directly
4 on the sorted point set performs poorly, though slightly better than directly processing an unsorted input. The idea to use RNN considers the point set as a sequential signal and hopes that by training the RNN with randomly permuted sequences, the RNN will become invariant to input order. However in OrderMatters [22] the authors have shown that order does matter and cannot be totally omitted. While RNN has relatively good robustness to input ordering for sequences with small length (dozens), it s hard to scale to thousands of input elements, which is the common size for point sets. Empirically, we have also shown that model based on RNN does not perform as well as our proposed method (Fig 5). Our idea is to approximate a general function defined on a point set by applying a symmetric function on transformed elements in the set: f({x 1,...,x n }) g(h(x 1 ),...,h(x n )), (1) where f : 2 RN! R, h : R N! R K and g : R K R {z K! R is a symmetric function. } n Empirically, our basic module is very simple: we approximate h by a multi-layer perceptron network and g by a composition of a single variable function and a max pooling function. This is found to work well by experiments. Through a collection of h, we can learn a number of f s to capture different properties of the set. While our key module seems simple, it has interesting properties (see Sec 5.3) and can achieve strong performace (see Sec 5.1) in a few different applications. Local and Global Information Aggregation The output from the above section forms a vector [f 1,...,f K ], which is a global signature of the input set. We can easily train a SVM or multi-layer perceptron classifier on the shape global features for classification. However, point segmentation requires a combination of local and global knowledge. We can achieve this in a simple yet highly effective manner. Our solution can be seen in Fig 2 (Segmentation Network). After computing the global point cloud feature vector, we feed it back to per point features by concatenating the global feature with each of the point features. Then we extract new per point features based on the combined point features - this time the per point feature is aware of both the local and global information. With this modification our network is able to predict per point quantities that rely on both local geometry and global semantics. For example we can accurately predict per-point normals, validating that the network is able to summarize information from the point s local neighborhood. In Sec 5.1, we also show that our model can achieve state-ofthe-art performance on shape part segmentation and scene segmentation. Joint Alignment Network The semantic labeling of a point cloud has to be invariant if the point cloud undergoes certain geometric transformations, such as rigid transformation. We therefore expect that the learnt representation by our point set is invariant to these transformations. A natural solution is to align all input set to a canonical space before feature extraction. Jaderberg et al. [9] introduces the idea of spatial transformer to align 2D images through sampling and interpolation, achieved by a specifically tailored layer implemented on GPU. Our input form of point clouds allows us to achieve this goal in a much simpler way compared with [9]. We do not need to invent any new layers and no alias is introduced as in the image case. We predict an affine transformation matrix by a mini-network and directly apply this transformation to the coordinates of input points. The mini-network itself resembles the big network and is composed of basic modules of point independent feature extraction, max pooling and fully connected layers. This idea can be further extended to the alignment of feature space as well. We can insert another alignment network on point features and predict a feature transformation matrix to align features from different input point clouds. However, transformation matrix in the feature space has much higher dimension than the spatial transform matrix (e.g. from 3 3 to 64 64), which greatly increase the difficulty of optimization. We therefore add a regularization term to our softmax training loss. We constraint the feature transformation matrix to be close to orthogonal matrix: L reg = ki AA T k 2 F, (2) where A is the feature alignment matrix predicted by a mini-network. An orthogonal transformation will not lose information in the input, thus is desired. We find that by adding the regularization term, the optimization becomes more stable and our model achieves better performance. 5. Experiment Experiments are divided into three parts. First, we show PointNets can be applied to multiple 3D recognition tasks (Sec 5.1). Second, we provide detailed experiments to validate our network design (Sec 5.2). Third, we visualize what the network learns (Sec 5.3) Applications In this section we show how our network can be trained to perform 3D object classification, object part segmentation and semantic scene segmentation. Even though we are working on a brand new data representation
![table mug bag skateboard gap between our method and multi-view based method (MVCNN [20]), which we think is due to the loss of fine geometry details that](/docs-images/87/95255692/images/5-0.jpg "can be captured by rendered images. motorbike airplane car lamp Partial Inputs guitar chair knife cap pistol rocket Complete Inputs earphone Figure 3.")
 and complete ShapeNet CAD models (right block). input #views accuracy accuracy avg.")
![class overall SPH [11] mesh - 68.2-3DShapeNets [25] volume 1 77.3 84.7 VoxNet [15] volume 12 83.0 85.9 Subvolume [16] volume 20 86.0 89.](/docs-images/87/95255692/images/5-2.jpg "2 LFD [25] image 10 75.5 - MVCNN [20] image 80 90.1 - Ours baseline point - 72.6 77.4 Ours PointNet point 1 86.2 89.2 Table 1.")
, we are able to achieve comparable or even better performance on benchmarks for several tasks.")





 to each point or face.")
![We evaluate on ShapeNet part data set from [26], which contains 16,881 shapes from 16 categories, annotated with 50 parts in total.](/docs-images/87/95255692/images/5-10.jpg "Most object categories are labeled with two to five parts. Ground truth annotations are labeled on sampled points on the shapes.")

![In this section, we compare our segmentation version PointNet (Fig 2, Segmentation Network) with two traditional methods [24] and [26] that both take](/docs-images/87/95255692/images/5-12.jpg "advantage of point-wise geometric features and correspondences between shapes, as well as our volumetric deep learning baseline (3DCNN).")
 scores.")

![For every CAD model in the ShapeNet part data set, we use Blensor Kinect Simulator [7] to generate incomplete point clouds from six random viewpoints.](/docs-images/87/95255692/images/5-15.jpg "We train our PointNet on the complete shapes and partial scans with the same network architecture and training setting. Results show that we lose only 5.")
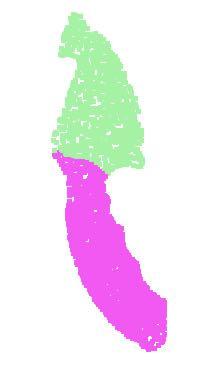
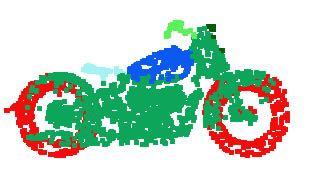
5 table mug bag skateboard gap between our method and multi-view based method (MVCNN [20]), which we think is due to the loss of fine geometry details that can be captured by rendered images. motorbike airplane car lamp Partial Inputs guitar chair knife cap pistol rocket Complete Inputs earphone Figure 3. Qualitative results for part segmentation. We visualize the CAD part segmentation results across all 16 object categories. We show both results for partial simulated Kinect scans (left block) and complete ShapeNet CAD models (right block). input #views accuracy accuracy avg. class overall SPH [11] mesh DShapeNets [25] volume VoxNet [15] volume Subvolume [16] volume LFD [25] image MVCNN [20] image Ours baseline point Ours PointNet point Table 1. Classification results on ModelNet40. Our net achieves state-of-the-art among deep nets on 3D input. (point sets), we are able to achieve comparable or even better performance on benchmarks for several tasks. 3D Object Classification Our network learns global point cloud feature that can be used for object classification. We evaluate our model on the ModelNet40 [25] shape classification benchmark. There are 12,311 CAD models from 40 object categories, split into 9,843 for training and 2,468 for testing. While previous methods focus on volumetric and mult-view image representations, we are the first to directly work on raw point cloud. We uniformly sample 1024 points on mesh faces according to face area. Points are normalized into a unit sphere. During training we augment the point cloud on-the-fly by randomly rotating the object along the up-axis and jittering the position of each point by a Gaussian noise with zero mean and 0.02 standard deviation. In Table 1, we compare our model with previous works as well as our baseline using on traditional features extracted from point cloud (point density, D2, shape contour etc.). Our model achieved state-of-the-art performance among methods based on 3D input (volumetric and point cloud). With only fully connected layers and max pooling, our net gains a strong lead in inference speed and can be easily parallelized in CPU as well. There is still a small laptop 3D Object Part Segmentation Part segmentation is a challenging fine-grained 3D recognition task. Given a 3D scan or a mesh model, the task is to assign part category label (e.g. chair leg, cup handle) to each point or face. We evaluate on ShapeNet part data set from [26], which contains 16,881 shapes from 16 categories, annotated with 50 parts in total. Most object categories are labeled with two to five parts. Ground truth annotations are labeled on sampled points on the shapes. We formulate part segmentation task as a per-point classification problem. Evaluation metric is IoU on points for every part on a shape and mean IoU across shapes. In this section, we compare our segmentation version PointNet (Fig 2, Segmentation Network) with two traditional methods [24] and [26] that both take advantage of point-wise geometric features and correspondences between shapes, as well as our volumetric deep learning baseline (3DCNN). We design the segmentation 3D CNN architecture as a fully convolutional one that keeps volume size through all layers. In the end each voxel has a receptive field of 19 voxels with spatial resolution of 32. In Table 2, we report per-category and mean IoU(%) scores. We observe a 2.3% mean IoU improvement and our net beats the baseline methods in most categories. We also perform experiments on simulated Kinect scans to test the robustness of these methods. For every CAD model in the ShapeNet part data set, we use Blensor Kinect Simulator [7] to generate incomplete point clouds from six random viewpoints. We train our PointNet on the complete shapes and partial scans with the same network architecture and training setting. Results show that we lose only 5.3% mean IoU. In Fig 3, we present qualitative results on both complete and partial data. One can see that though partial data is fairly challenging, our predictions are reasonable. Semantic Segmentation in Scenes Our network on part segmentation can be easily extended to semantic scene segmentation, where point labels become semantic object classes instead of object part labels. We experiment on the Stanford 3D semantic parsing data set [1]. The dataset contains 3D scans from Matterport scanners in 6 areas including 271 rooms. Each point in the scan is annotated with one of the semantic labels from 13 categories (chair, table, floor, wall etc. plus clutter). To prepare training data, we firstly split points by room, and then split rooms into blocks with area 1m by 1m. We train our segmentation version of PointNet to predict per point class in each block. Each point is represented by a 9-dim vector of (x, y, z), RGB and normalized position
![mean aero bag cap car chair ear guitar knife lamp laptop motor mug pistol rocket skate table phone board # shapes 2690 76 55 898 3758 69 787 392 1547 451 202 184 283 66 152 5271 Wu [24] - 63.](/docs-images/87/95255692/images/6-0.jpg "2 - - - 73.5 - - - 74.4 - - - - - - 74.8 Yi [26] 81.4 81.0 78.4 77.7 75.7 87.6 61.9 92.0 85.4 82.5 95.7 70.6 91.9 85.9 53.1 69.8 75.3 3DCNN 79.4 75.1 72.8 73.3 70.0 87.2 63.5 88.4 79.6 74.4 93.9 58.")
 across shapes. We compare with two traditional methods [24] and [26] and a 3D fully convolutional network baseline proposed by us.")



 with SVMs trained on local geometric features and global room context feature in voxel grids.")
6 mean aero bag cap car chair ear guitar knife lamp laptop motor mug pistol rocket skate table phone board # shapes Wu [24] Yi [26] DCNN Ours Table 2. Segmentation results on ShapeNet part dataset. Metric is mean IoU(%) across shapes. We compare with two traditional methods [24] and [26] and a 3D fully convolutional network baseline proposed by us. Our PointNet method achieved the state-of-the-art in miou. (x 0,y 0,z 0 ) as to the room (from 0 to 1). At training time, we randomly sample 4096 points in each block on-the-fly. At test time, we test on all the points. We follow the same protocol as [1] to use k-fold strategy for train and test. We compare our method with a baseline using handcrafted point features. The baseline extracts the same 9- dim local features and three additional ones: local point density, local curvature and normal. We use standard as the classifier. Results are shown in Table 3, where our PointNet method significantly outperforms the baseline method. In Fig 4, we show qualitative segmentation results. Our network is able to output smooth predictions and is robust to missing points and occlusions. Based on the semantic segmentation output from our network, we further build a 3D object detection system using connected component for object proposal. We compare with previous state-of-the-art method in Table 4. The previous method is based on a sliding shape method (with CRF post processing) with SVMs trained on local geometric features and global room context feature in voxel grids. Our method outperforms it by a large margin on mean IoU of the four furniture categories Architecture Design Analysis In this section we validate our design choices by control experiments. We also show the effects of our network s hyperparameters. mean IoU overall accuracy Ours baseline Ours PointNet Table 3. Results on semantic segmentation in scenes. Metric is average IoU over 13 classes (structural and furniture elements plus clutter) and classification accuracy calculated on points. table chair sofa board mean # instance Armeni et al. [1] Ours Table 4. Results on 3D object detection in scenes. Metric is average precision with threshold IoU 0.5 computed in 3D volumes. Input Output Figure 4. Qualitative results for semantic segmentation. Top row is input point cloud with color. Bottom row is output semantic segmentation result (on points) displayed in the same camera viewpoint as input. Comparison with Alternative Order-invariant Methods As mentioned in Sec 4.2, there are at least three options for consuming unordered set inputs. We use the ModelNet40 shape classification problem as a test bed for comparisons of those options, the following two control experiments will be on this task. The methods (illustrated in Fig 5) we compared with include multi-layer perceptron on unsorted and sorted points as n 3 arrays, RNN model that considers input points as a sequence, and models based on symmetry functions. The symmetry operations we experimented include max pooling, average pooling and an attention based weighted sum. The attention method is similar to that in [22], where a scalar score is predicted from each point feature, then the score is normalized across points by computing a softmax. The weighted sum of point features is then computed based on the normalized scores. As shown in Fig 5, max-pooling operation achieves the best performance by a large winning margin, which validates our choice. Effectiveness of Input and Feature Transformations In Table 5 we demonstrate the positive effects of our input and feature transformations (for alignment). It s interesting to see that the most basic architecture already achieves quite reasonable results. Using input transformation results in a 0.8% performance boost. The regularization loss is necessary for the higher dimension transform to work.
 applied on points consists of 5 hidden layers with neuron sizes 64,64,64,128,1024, all points share a single copy of.")
 100 90 80 70 60 50 40 30 Furthest Random 0 0.2 0.4 0.6 0.8 1 Missing data ratio 100 90 80 70 60 50 XYZ 40 30 XYZ+density 20 0.1 0.2 0.3 0.")




 in Eq 1, which demonstrates that our network learns a family of optimization criteria that selects informative points from the")
 dimension point features for each point and aggregates all the per-point local features via a max pooling layer into a single K-dim")
 in Fig 7.")
 with")
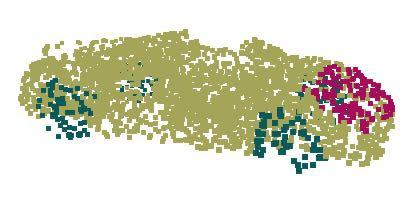
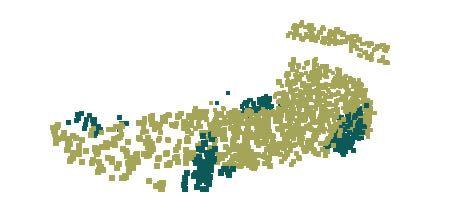
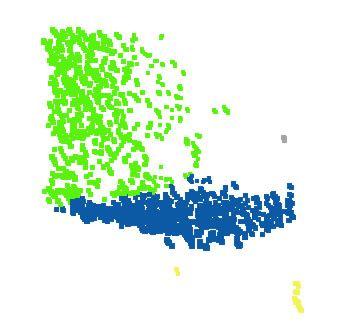
7 rnn cell rnn cell rnn cell (1,2,3) (2,3,4) (1,3,1) (b) sequential model sorted (1,2,3) (1,3,1)... (2,3,4) (a) sorting (1,2,3) (2,3,4)... (1,3,1) (c) symmetry function (a) (b) (c) (c) (c) Figure 5. Three approaches to achieve order invariance. Multilayer perceptron () applied on points consists of 5 hidden layers with neuron sizes 64,64,64,128,1024, all points share a single copy of. The close to the output consists of two layers with sizes 256. All fully connected layers are using ReLU and batch normalization (except the output layer). Two dropouts with keep prob 0.8 are applied to each hidden layer of the output. Accuracy (%) Furthest Random Missing data ratio XYZ XYZ+density Outlier ratio Accuracy (%) Accuracy (%) Perturbation noise std Figure 6. PointNet robustness test. The metric is overall classification accuracy on ModelNet40 test set. Left: Delete points. Furthest means the original 1024 points are sampled with furthest sampling. Middle: Insertion. Outliers uniformly scattered in the unit sphere. Right: Perturbation. Add Gaussian noise to each point independently. By combining both transformations and the regularization term, we achieve the best performance. Robustness Test We show our PointNet, while simple and effective, is robust to various kinds of input corruptions. We use the same architecture as in Fig 5 s max pooling network. Input points are normalized into a unit sphere. Results are in Fig 6. As to missing points, when there are 50% points missing, the accuracy only drops by 2.4% and 3.8% w.r.t. furthest and random input sampling. Our net is also robust to outlier points, if it has seen those during training. We evaluate two models: one trained on points with (x, y, z) coordinates; the other on (x, y, z) plus point density. The net has more than 80% accuracy even when 20% of the points are outliers. Fig 6 right shows the net is robust to point perturbations Visualizing PointNet We design two experiments to visualize what has been learnt by the PointNet. In the first experiment, we visualize the learnt point function h(x) in Eq 1, which demonstrates that our network learns a family of optimization criteria that selects informative points from the cloud. Our second experiment illustrates the robustness of our network. Point Function Visualization As discussed in Sec 4.2, our network computes K (we take K = 1024 in this experiment) dimension point features for each point and aggregates all the per-point local features via a max pooling layer into a single K-dim vector, which forms the global shape descriptor. To gain more insights on what the learnt per-point functions h s detect, we visualize the points p i s that give high per-point function value f(p i ) in Fig 7. This visualization clearly shows that different point functions learn to detect for points in different regions with various shapes scattered in the whole space. Global Feature Visualization We visualize the shape family including all the shapes between the critical point set C S and the upper-bound shape N S that gives the same global feature f(s) with respect to a given shape S. Fig 8 shows the critical point sets C S and upper-bound shapes N S for four selected shapes. The original input point clouds are rendered in the first row while the C S and N S for them are shown in the second and third rows respectively. The C S for a given shape S includes the points from the original point cloud that activates some per-point function h i s the most. The N S is constructed by pushing all the points in a diameter-2 cube through the network and selecting the points p whose per-point function values Transform accuracy none 87.1 input (3x3) 87.9 feature (64x64) 86.9 feature (64x64) + reg both 89.2 Table 5. Effects of input feature transforms. Metric is overall classification accuracy on ModelNet40 test set. Figure 7. Point function visualization. For each per-point function h, we calculate the values h(p) for all the points p in a cube of diameter two located at the origin, which spatially covers the unit sphere to which our input shapes are normalized when training our PointNet. In this figure, we visualize all the points p that give h(p) > 0.5 with function values color-coded by the brightness of the voxel. We randomly pick 15 point functions and visualize the activation regions for them.
 and the upper bound shapes (the third row) for four query shapes listed in the first row.")
,h 2 (p),,h K (p)) are no larger than the global shape descriptor.")


![state of the arts on standard benchmarks. We also provide visualizations towards understanding of our network. References [1] I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M.](/docs-images/87/95255692/images/8-6.jpg "Fischer, and S. Savarese. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, 2016. [2] M. Aubry, U.")
, 2011 IEEE International Conference on, pages 1626 1633. IEEE, 2011. [3] M. M. Bronstein and I. Kokkinos.")
![Scale-invariant heat kernel signatures for non-rigid shape recognition. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 1704 1711. IEEE, 2010. [4] J. Bruna, W.](/docs-images/87/95255692/images/8-8.jpg "Zaremba, A. Szlam, and Y. LeCun. Spectral networks and locally connected networks on graphs. arxiv preprint arxiv:1312.6203, 2013. [5] D.-Y. Chen, X.-P. Tian, Y.-T. Shen, and M. Ouhyoung.")
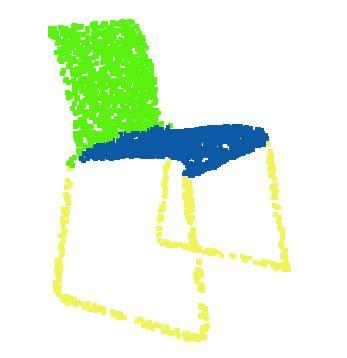
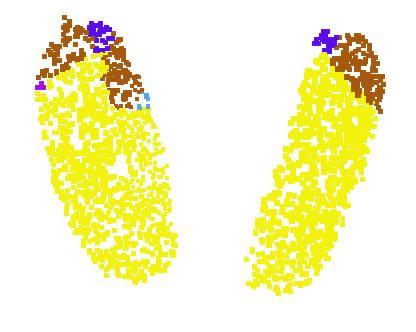
8 Original Shape Critical Points Upper Bounds Figure 8. Critical points and upper bound shape. We visualize the critical points sets (the second row) and the upper bound shapes (the third row) for four query shapes listed in the first row. While the critical points jointly determine the global shape feature for the given shape, any point cloud that falls between the critical points set and the upper bound shape gives the exactly same feature. We colorcode all figures to show the depth information. (h 1 (p),h 2 (p),,h K (p)) are no larger than the global shape descriptor. It is not hard to see that all the shapes S 0 that cover C S and are contained by N S give the exactly same global feature f(s 0 )=f(s). The transition shape family entails the robustness of the our PointNet, meaning that adding noisy jitterings or losing some non-critical points do not change the learnt shape signature and thus do not affect our classification or segmentation results. 6. Conclusion In this work, we propose a novel deep neural network PointNet that directly consumes point cloud. Our network provides a unified approach to a number of 3D recognition tasks including object classification, part segmentation and semantic segmentation, while obtaining on par or better results than state of the arts on standard benchmarks. We also provide visualizations towards understanding of our network. References [1] I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, and S. Savarese. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, [2] M. Aubry, U. Schlickewei, and D. Cremers. The wave kernel signature: A quantum mechanical approach to shape analysis. In Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on, pages IEEE, [3] M. M. Bronstein and I. Kokkinos. Scale-invariant heat kernel signatures for non-rigid shape recognition. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages IEEE, [4] J. Bruna, W. Zaremba, A. Szlam, and Y. LeCun. Spectral networks and locally connected networks on graphs. arxiv preprint arxiv: , [5] D.-Y. Chen, X.-P. Tian, Y.-T. Shen, and M. Ouhyoung. On visual similarity based 3d model retrieval. In Computer graphics forum, volume 22, pages Wiley Online Library, [6] Y. Fang, J. Xie, G. Dai, M. Wang, F. Zhu, T. Xu, and E. Wong. 3d deep shape descriptor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [7] M. Gschwandtner, R. Kwitt, A. Uhl, and W. Pree. BlenSor: Blender Sensor Simulation Toolbox Advances in Visual Computing. volume 6939 of Lecture Notes in Computer Science, chapter 20, pages Springer Berlin / Heidelberg, Berlin, Heidelberg, [8] K. Guo, D. Zou, and X. Chen. 3d mesh labeling via deep convolutional neural networks. ACM Transactions on Graphics (TOG), 35(1):3, [9] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In NIPS [10] A. E. Johnson and M. Hebert. Using spin images for efficient object recognition in cluttered 3d scenes. IEEE Transactions on pattern analysis and machine intelligence, 21(5): , [11] M. Kazhdan, T. Funkhouser, and S. Rusinkiewicz. Rotation invariant spherical harmonic representation of 3 d shape descriptors. In Symposium on geometry processing, volume 6, pages , [12] Y. Li, S. Pirk, H. Su, C. R. Qi, and L. J. Guibas. Fpnn: Field probing neural networks for 3d data. arxiv preprint arxiv: , [13] H. Ling and D. W. Jacobs. Shape classification using the inner-distance. IEEE transactions on pattern analysis and machine intelligence, 29(2): , [14] J. Masci, D. Boscaini, M. Bronstein, and P. Vandergheynst. Geodesic convolutional neural networks on riemannian manifolds. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 37 45, [15] D. Maturana and S. Scherer. Voxnet: A 3d convolutional neural network for real-time object recognition. In IEEE/RSJ International Conference on Intelligent Robots and Systems, September [16] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. Guibas. Volumetric and multi-view cnns for object classification on 3d data. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, [17] R. B. Rusu, N. Blodow, and M. Beetz. Fast point feature histograms (fpfh) for 3d registration. In Robotics and Automation, ICRA 09. IEEE International Conference on, pages IEEE, [18] R. B. Rusu, N. Blodow, Z. C. Marton, and M. Beetz. Aligning point cloud views using persistent feature histograms. In 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages IEEE, [19] M. Savva, F. Yu, H. Su, M. Aono, B. Chen, D. Cohen-Or, W. Deng, H. Su, S. Bai, X. Bai, et al. Shrec16 track largescale 3d shape retrieval from shapenet core55.
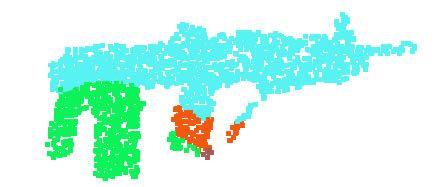
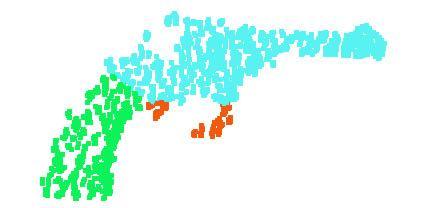
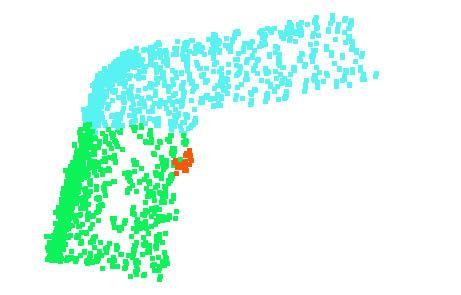
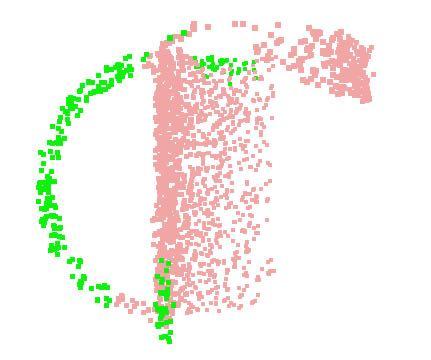
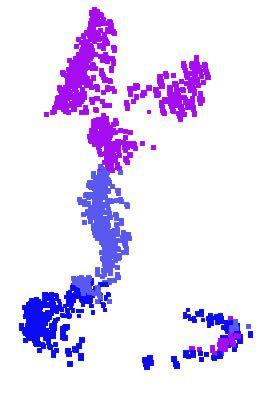
9 Figure 9. 2D embedding of learnt shape global features. We use t-sne technique to visualize the learnt global shape features for the shapes in ModelNet40 test split. [20] H. Su, S. Maji, E. Kalogerakis, and E. G. Learned-Miller. Multi-view convolutional neural networks for 3d shape recognition. In Proc. ICCV, to appear, [21] J. Sun, M. Ovsjanikov, and L. Guibas. A concise and provably informative multi-scale signature based on heat diffusion. In Computer graphics forum, volume 28, pages Wiley Online Library, [22] O. Vinyals, S. Bengio, and M. Kudlur. Order matters: Sequence to sequence for sets. arxiv preprint arxiv: , [23] D. Z. Wang and I. Posner. Voting for voting in online point cloud object detection. Proceedings of the Robotics: Science and Systems, Rome, Italy, 1317, [24] Z. Wu, R. Shou, Y. Wang, and X. Liu. Interactive shape cosegmentation via label propagation. Computers Graphics, 38: , [25] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [26] L. Yi, V. G. Kim, D. Ceylan, I.-C. Shen, M. Yan, H. Su, C. Lu, Q. Huang, A. Sheffer, and L. Guibas. A scalable active framework for region annotation in 3d shape collections. SIGGRAPH Asia, 2016.





















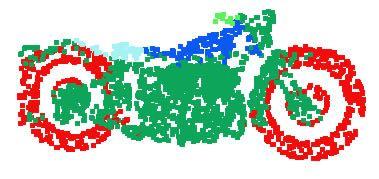
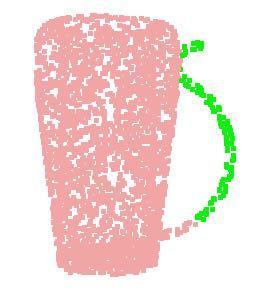






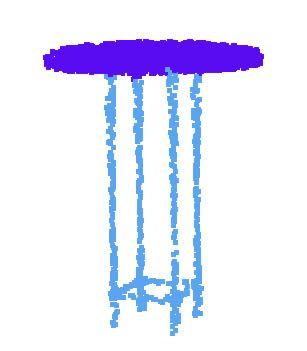









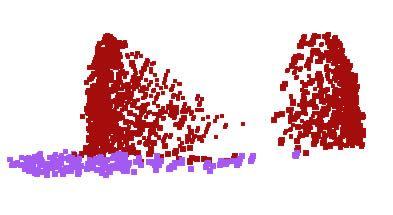







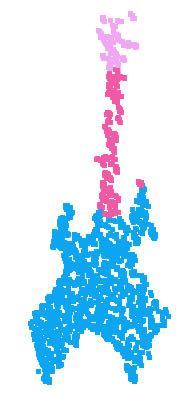
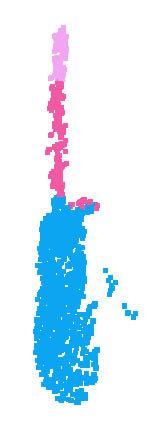
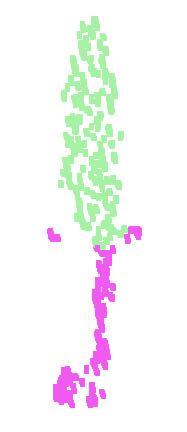

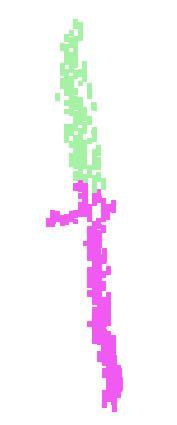










10 lamp knife laptop guitar mug motor bike earphone chair skate board car table cap pistol rocket bag airplane Figure 10. PointNet segmentation results on complete CAD models. Figure 11. PointNet segmentation results on simulated Kinect partial scans. lamp knife laptop guitar mug motor bike earphone chair skate board car table cap pistol rocket bag airplane
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
arxiv: v1 [cs.cv] 28 Nov 2018
![arxiv: v1 [cs.cv] 28 Nov 2018](/thumbs/91/104803963.jpg "arxiv: v1 [cs.cv] 28 Nov 2018") MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Sikai Zhong February 14, 2018 COMPUTER SCIENCE Table of contents 1. PointNet 2. PointNet++ 3. Experiments 1 PointNet Property
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
arxiv: v1 [cs.cv] 13 Feb 2018
![arxiv: v1 [cs.cv] 13 Feb 2018](/thumbs/85/92549074.jpg "arxiv: v1 [cs.cv] 13 Feb 2018") Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
arxiv: v1 [cs.cv] 27 Nov 2018 Abstract
![arxiv: v1 [cs.cv] 27 Nov 2018 Abstract](/thumbs/91/105025156.jpg "arxiv: v1 [cs.cv] 27 Nov 2018 Abstract") Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval
 Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
3D Object Classification using Shape Distributions and Deep Learning
 3D Object Classification using Shape Distributions and Deep Learning Melvin Low Stanford University mwlow@cs.stanford.edu Abstract This paper shows that the Absolute Angle shape distribution (AAD) feature
3D Object Classification using Shape Distributions and Deep Learning Melvin Low Stanford University mwlow@cs.stanford.edu Abstract This paper shows that the Absolute Angle shape distribution (AAD) feature
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
3D Shape Segmentation with Projective Convolutional Networks
 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
AI Ukraine Point cloud labeling using machine learning
 AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
AI Ukraine - 2017 Point cloud labeling using machine learning Andrii Babii apratster@gmail.com Data sources 1. LIDAR 2. 3D IR cameras 3. Generated from 2D sources 3D dataset: http://kos.informatik.uni-osnabrueck.de/3dscans/
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network
 Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
Learning Adversarial 3D Model Generation with 2D Image Enhancer
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
CS233: The Shape of Data Handout # 3 Geometric and Topological Data Analysis Stanford University Wednesday, 9 May 2018
 CS233: The Shape of Data Handout # 3 Geometric and Topological Data Analysis Stanford University Wednesday, 9 May 2018 Homework #3 v4: Shape correspondences, shape matching, multi-way alignments. [100
CS233: The Shape of Data Handout # 3 Geometric and Topological Data Analysis Stanford University Wednesday, 9 May 2018 Homework #3 v4: Shape correspondences, shape matching, multi-way alignments. [100
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation
 SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong Abstract In this paper, we study the problem
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong Abstract In this paper, we study the problem
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
 PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Charles R. Qi Li Yi Hao Su Leonidas J. Guibas Stanford University Abstract Few prior works study deep learning on point sets.
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space Charles R. Qi Li Yi Hao Su Leonidas J. Guibas Stanford University Abstract Few prior works study deep learning on point sets.
Cross-domain Deep Encoding for 3D Voxels and 2D Images
 Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
Structure-oriented Networks of Shape Collections
 Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Su et al. Shape Descriptors - III
 Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Su et al. Shape Descriptors - III Siddhartha Chaudhuri http://www.cse.iitb.ac.in/~cs749 Funkhouser; Feng, Liu, Gong Recap Global A shape descriptor is a set of numbers that describes a shape in a way that
Deep Learning on Graphs
 Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
Deep Learning on Graphs with Graph Convolutional Networks Hidden layer Hidden layer Input Output ReLU ReLU, 22 March 2017 joint work with Max Welling (University of Amsterdam) BDL Workshop @ NIPS 2016
Beam Search for Learning a Deep Convolutional Neural Network of 3D Shapes
 Beam Search for Learning a Deep Convolutional Neural Network of 3D Shapes Xu Xu and Sinisa Todorovic School of Electrical Engineering and Computer Science Oregon State University, Corvallis, Oregon 97330
Beam Search for Learning a Deep Convolutional Neural Network of 3D Shapes Xu Xu and Sinisa Todorovic School of Electrical Engineering and Computer Science Oregon State University, Corvallis, Oregon 97330
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR
 3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
arxiv: v1 [cs.cv] 2 Dec 2016
![arxiv: v1 [cs.cv] 2 Dec 2016](/thumbs/89/98281292.jpg "arxiv: v1 [cs.cv] 2 Dec 2016") SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong arxiv:1612.00606v1 [cs.cv] 2 Dec 2016 Abstract
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation Li Yi1 Hao Su1 Xingwen Guo2 Leonidas Guibas1 1 2 Stanford University The University of Hong Kong arxiv:1612.00606v1 [cs.cv] 2 Dec 2016 Abstract
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY
 MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
3D Deep Learning
 3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
3D Deep Learning Tutorial@CVPR2017 Hao Su (UCSD) Leonidas Guibas (Stanford) Michael Bronstein (Università della Svizzera Italiana) Evangelos Kalogerakis (UMass) Jimei Yang (Adobe Research) Charles Qi (Stanford)
SO-Net: Self-Organizing Network for Point Cloud Analysis
 SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore Abstract This paper presents SO-Net, a permutation invariant architecture for
SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore Abstract This paper presents SO-Net, a permutation invariant architecture for
Supplementary Material for Ensemble Diffusion for Retrieval
 Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network
 Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network Marko Filipović, Petra Ðurović and Robert Cupec Faculty of Electrical Engineering, Computer Science and Information
Experimental Evaluation of Point Cloud Classification using the PointNet Neural Network Marko Filipović, Petra Ðurović and Robert Cupec Faculty of Electrical Engineering, Computer Science and Information
Stable and Multiscale Topological Signatures
 Stable and Multiscale Topological Signatures Mathieu Carrière, Steve Oudot, Maks Ovsjanikov Inria Saclay Geometrica April 21, 2015 1 / 31 Shape = point cloud in R d (d = 3) 2 / 31 Signature = mathematical
Stable and Multiscale Topological Signatures Mathieu Carrière, Steve Oudot, Maks Ovsjanikov Inria Saclay Geometrica April 21, 2015 1 / 31 Shape = point cloud in R d (d = 3) 2 / 31 Signature = mathematical
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
End-To-End Spam Classification With Neural Networks
 End-To-End Spam Classification With Neural Networks Christopher Lennan, Bastian Naber, Jan Reher, Leon Weber 1 Introduction A few years ago, the majority of the internet s network traffic was due to spam
End-To-End Spam Classification With Neural Networks Christopher Lennan, Bastian Naber, Jan Reher, Leon Weber 1 Introduction A few years ago, the majority of the internet s network traffic was due to spam
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
arxiv: v4 [cs.cv] 27 Mar 2018
![arxiv: v4 [cs.cv] 27 Mar 2018](/thumbs/96/128983416.jpg "arxiv: v4 [cs.cv] 27 Mar 2018") SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore arxiv:1803.04249v4 [cs.cv] 27 Mar 2018 Abstract This paper presents SO-Net, a
SO-Net: Self-Organizing Network for Point Cloud Analysis Jiaxin Li Ben M. Chen Gim Hee Lee National University of Singapore arxiv:1803.04249v4 [cs.cv] 27 Mar 2018 Abstract This paper presents SO-Net, a
3D Point Cloud Object Detection with Multi-View Convolutional Neural Network
 3D Point Cloud Object Detection with Multi-View Convolutional Neural Network Guan Pang Department of Computer Science University of Southern California Los Angeles, CA 90089 Email: gpang@usc.edu Ulrich
3D Point Cloud Object Detection with Multi-View Convolutional Neural Network Guan Pang Department of Computer Science University of Southern California Los Angeles, CA 90089 Email: gpang@usc.edu Ulrich
Correspondence. CS 468 Geometry Processing Algorithms. Maks Ovsjanikov
 Shape Matching & Correspondence CS 468 Geometry Processing Algorithms Maks Ovsjanikov Wednesday, October 27 th 2010 Overall Goal Given two shapes, find correspondences between them. Overall Goal Given
Shape Matching & Correspondence CS 468 Geometry Processing Algorithms Maks Ovsjanikov Wednesday, October 27 th 2010 Overall Goal Given two shapes, find correspondences between them. Overall Goal Given
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material
 SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
Where s Waldo? A Deep Learning approach to Template Matching
 Where s Waldo? A Deep Learning approach to Template Matching Thomas Hossler Department of Geological Sciences Stanford University thossler@stanford.edu Abstract We propose a new approach to Template Matching
Where s Waldo? A Deep Learning approach to Template Matching Thomas Hossler Department of Geological Sciences Stanford University thossler@stanford.edu Abstract We propose a new approach to Template Matching
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Pose estimation using a variety of techniques
 Pose estimation using a variety of techniques Keegan Go Stanford University keegango@stanford.edu Abstract Vision is an integral part robotic systems a component that is needed for robots to interact robustly
Pose estimation using a variety of techniques Keegan Go Stanford University keegango@stanford.edu Abstract Vision is an integral part robotic systems a component that is needed for robots to interact robustly
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Nov 30 th 3:30 PM 4:45 PM Grading Three senior graders (30%)
Using Faster-RCNN to Improve Shape Detection in LIDAR
 Using Faster-RCNN to Improve Shape Detection in LIDAR TJ Melanson Stanford University Stanford, CA 94305 melanson@stanford.edu Abstract In this paper, I propose a method for extracting objects from unordered
Using Faster-RCNN to Improve Shape Detection in LIDAR TJ Melanson Stanford University Stanford, CA 94305 melanson@stanford.edu Abstract In this paper, I propose a method for extracting objects from unordered
A Keypoint Descriptor Inspired by Retinal Computation
 A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Paper Motivation. Fixed geometric structures of CNN models. CNNs are inherently limited to model geometric transformations
 Paper Motivation Fixed geometric structures of CNN models CNNs are inherently limited to model geometric transformations Higher-level features combine lower-level features at fixed positions as a weighted
Paper Motivation Fixed geometric structures of CNN models CNNs are inherently limited to model geometric transformations Higher-level features combine lower-level features at fixed positions as a weighted
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
Matching and Recognition in 3D. Based on slides by Tom Funkhouser and Misha Kazhdan
 Matching and Recognition in 3D Based on slides by Tom Funkhouser and Misha Kazhdan From 2D to 3D: Some Things Easier No occlusion (but sometimes missing data instead) Segmenting objects often simpler From
Matching and Recognition in 3D Based on slides by Tom Funkhouser and Misha Kazhdan From 2D to 3D: Some Things Easier No occlusion (but sometimes missing data instead) Segmenting objects often simpler From
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Preparation Meeting. Recent Advances in the Analysis of 3D Shapes. Emanuele Rodolà Matthias Vestner Thomas Windheuser Daniel Cremers
 Preparation Meeting Recent Advances in the Analysis of 3D Shapes Emanuele Rodolà Matthias Vestner Thomas Windheuser Daniel Cremers What You Will Learn in the Seminar Get an overview on state of the art
Preparation Meeting Recent Advances in the Analysis of 3D Shapes Emanuele Rodolà Matthias Vestner Thomas Windheuser Daniel Cremers What You Will Learn in the Seminar Get an overview on state of the art
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material
 Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material Ameesh Makadia Google New York, NY 10011 makadia@google.com Mehmet Ersin Yumer Carnegie Mellon University Pittsburgh, PA 15213
Learning 3D Part Detection from Sparsely Labeled Data: Supplemental Material Ameesh Makadia Google New York, NY 10011 makadia@google.com Mehmet Ersin Yumer Carnegie Mellon University Pittsburgh, PA 15213
3D CONVOLUTIONAL NEURAL NETWORKS BY MODAL FUSION
 3D CONVOLUTIONAL NEURAL NETWORKS BY MODAL FUSION Yusuke Yoshiyasu, Eiichi Yoshida AIST Soeren Pirk, Leonidas Guibas Stanford University ABSTRACT We propose multi-view and volumetric convolutional neural
3D CONVOLUTIONAL NEURAL NETWORKS BY MODAL FUSION Yusuke Yoshiyasu, Eiichi Yoshida AIST Soeren Pirk, Leonidas Guibas Stanford University ABSTRACT We propose multi-view and volumetric convolutional neural
arxiv: v4 [cs.cv] 29 Mar 2019
![arxiv: v4 [cs.cv] 29 Mar 2019](/thumbs/96/128038877.jpg "arxiv: v4 [cs.cv] 29 Mar 2019") PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks
 An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Deep Aggregation of Local 3D Geometric Features for 3D Model Retrieval
 FURUYA AND OHBUCHI: DEEP AGGREGATION OF LOCAL 3D FEATURES 1 Deep Aggregation of Local 3D Geometric Features for 3D Model Retrieval Takahiko Furuya 1 takahikof AT yamanashi.ac.jp Ryutarou Ohbuchi 1 ohbuchi
FURUYA AND OHBUCHI: DEEP AGGREGATION OF LOCAL 3D FEATURES 1 Deep Aggregation of Local 3D Geometric Features for 3D Model Retrieval Takahiko Furuya 1 takahikof AT yamanashi.ac.jp Ryutarou Ohbuchi 1 ohbuchi
... arxiv: v2 [cs.cv] 5 Sep Learning local shape descriptors from part correspondences with multi-view convolutional networks
![... arxiv: v2 [cs.cv] 5 Sep Learning local shape descriptors from part correspondences with multi-view convolutional networks](/thumbs/75/72009962.jpg "... arxiv: v2 [cs.cv] 5 Sep Learning local shape descriptors from part correspondences with multi-view convolutional networks") Learning local shape descriptors from part correspondences with multi-view convolutional networks HAIBIN HUANG, University of Massachusetts Amherst EVANGELOS KALOGERAKIS, University of Massachusetts Amherst
Learning local shape descriptors from part correspondences with multi-view convolutional networks HAIBIN HUANG, University of Massachusetts Amherst EVANGELOS KALOGERAKIS, University of Massachusetts Amherst
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues
 Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues Ludovico Minto, Pietro Zanuttigh and Giampaolo Pagnutti Department of Information Engineering, University
Deep Learning for 3D Shape Classification Based on Volumetric Density and Surface Approximation Clues Ludovico Minto, Pietro Zanuttigh and Giampaolo Pagnutti Department of Information Engineering, University
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Indoor Object Recognition of 3D Kinect Dataset with RNNs
 Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
arxiv: v4 [cs.cv] 27 Nov 2016
![arxiv: v4 [cs.cv] 27 Nov 2016](/thumbs/76/73516444.jpg "arxiv: v4 [cs.cv] 27 Nov 2016") FusionNet: 3D Object Classification Using Multiple Data Representations Vishakh Hegde Stanford and Matroid vishakh@matroid.com Reza Zadeh Stanford and Matroid reza@matroid.com arxiv:1607.05695v4 [cs.cv]
FusionNet: 3D Object Classification Using Multiple Data Representations Vishakh Hegde Stanford and Matroid vishakh@matroid.com Reza Zadeh Stanford and Matroid reza@matroid.com arxiv:1607.05695v4 [cs.cv]
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
Urban Scene Segmentation, Recognition and Remodeling. Part III. Jinglu Wang 11/24/2016 ACCV 2016 TUTORIAL
 Part III Jinglu Wang Urban Scene Segmentation, Recognition and Remodeling 102 Outline Introduction Related work Approaches Conclusion and future work o o - - ) 11/7/16 103 Introduction Motivation Motivation
Part III Jinglu Wang Urban Scene Segmentation, Recognition and Remodeling 102 Outline Introduction Related work Approaches Conclusion and future work o o - - ) 11/7/16 103 Introduction Motivation Motivation
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
arxiv:submit/ [cs.cv] 13 Jan 2018
![arxiv:submit/ [cs.cv] 13 Jan 2018](/thumbs/91/104718543.jpg "arxiv:submit/ [cs.cv] 13 Jan 2018") Benchmark Visual Question Answer Models by using Focus Map Wenda Qiu Yueyang Xianzang Zhekai Zhang Shanghai Jiaotong University arxiv:submit/2130661 [cs.cv] 13 Jan 2018 Abstract Inferring and Executing
Benchmark Visual Question Answer Models by using Focus Map Wenda Qiu Yueyang Xianzang Zhekai Zhang Shanghai Jiaotong University arxiv:submit/2130661 [cs.cv] 13 Jan 2018 Abstract Inferring and Executing
Attentional ShapeContextNet for Point Cloud Recognition
 Attentional ShapeContextNet for Point Cloud Recognition Saining Xie Sainan Liu Zeyu Chen Zhuowen Tu University of California, San Diego {s9xie, sal131, zec003, ztu}@ucsd.edu Abstract We tackle the problem
Attentional ShapeContextNet for Point Cloud Recognition Saining Xie Sainan Liu Zeyu Chen Zhuowen Tu University of California, San Diego {s9xie, sal131, zec003, ztu}@ucsd.edu Abstract We tackle the problem
GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition
 GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition Yifan Feng, Zizhao Zhang, Xibin Zhao, Rongrong Ji, Yue Gao KLISS, School of Software, Tsinghua University Beijing National Research
GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition Yifan Feng, Zizhao Zhang, Xibin Zhao, Rongrong Ji, Yue Gao KLISS, School of Software, Tsinghua University Beijing National Research
Contexts and 3D Scenes
 Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Contexts and 3D Scenes Computer Vision Jia-Bin Huang, Virginia Tech Many slides from D. Hoiem Administrative stuffs Final project presentation Dec 1 st 3:30 PM 4:45 PM Goodwin Hall Atrium Grading Three
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies