Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2015
|
|
|
- Leonard Townsend
- 5 years ago
- Views:
Transcription
1 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015
2 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest Neighbor Density Estimation Supervised: Instance-based learners Classification knn classification Weighted (or kernel) knn Regression knn regression Locally linear weighted regression 2
3 Introduction Estimation of arbitrary density functions Parametric density functions cannot usually fit the densities we encounter in practical problems. e.g., parametric densities are unimodal. Non-parametric methods don't assume that the model (from) of underlying densities is known in advance Non-parametric methods (for classification) can be categorized into Generative Estimate p(x y = i) from D i using non-parametric density estimation Discriminative Estimate p(y = i x) from D 3
4 Parametric vs. nonparametric methods Parametric methods need to find parameters from data and then use the inferred parameters to decide on new data points Learning: finding parameters from data Nonparametric methods Training examples are explicitly used for each test data classification. Training phase is not required Both supervised and unsupervised learning methods can be categorized into parametric and non-parametric methods. 4
5 Histogram approximation idea Histogram approximation of an unknown pdf P(b l ) k(b l )/n l = 1,, L k(b l ): number of samples (among n ones) lied in the bin b l k n The corresponding estimated pdf: p x = P(b l) h x x bl h 2 h Mid-point of the bin b l 5
6 Non-parametric density estimation Probability of falling in a region R: P = R p x dx We can estimate smoothed p x by estimating P: D = x i n i=1 : a set of samples drawn i.i.d. according to p x The probability that k of the n samples fall in R: P k = E k = np n k Pk 1 P n k This binomial distribution peaks sharply about the mean for large values of n: k np k as an estimate for P n More accurate for larger n 6
7 Non-parametric density estimation Assumptions: p x is continuous and the region R enclosing x is so small that p is near constant in it: P = R p x dx = p x V V = Vol R x R p x = P V k/n V Let V approach zero if we want to find p x the averaged version. instead of 7
8 Non-parametric density estimation: Main approaches Two approaches of satisfying conditions: k-nearest neighbor density estimator: fix k and determine the value of V from the data Volume grows until it contains k neighbors of x Kernel density estimator (Parzen window): fix V and determine k from the data Number of points falling inside the volume can vary from point to point 8
9 Parzen window (kernel density estimator) Extension of histogram idea: Hyper-cubes with length of side h (i.e., volume h d ) are located on the samples Hypercube as a simple window function: φ u = 1 ( u u d 1 2 ) 0 o. w. 1 1/2 1/2 1 1/2 1/2 p x = k nv = 1 nv i=1 n φ x x(i) h k = n i=1 V = h d φ x x(i) h number of samples in the hypercube around x 9
10 Window or kernel function Necessary conditions for window function to find legitimate density function: φ(x) 0 φ x dx = 1 Windows are also called kernels or potential functions. 10
11 Kernel density estimator: Example p n x = 1 n n i=1 N(x x (i), h 2 ) 1 2πh e x x (i) 2 2h σ = h p x = 1 n = 1 n i=1 n i=1 n 1 N(x x (i), σ 2 ) 2πσ e x x (i) 2 2σ 2 11 Choice of σ is crucial.

12 Kernel density estimator: Example σ = 0.02 σ = 0.1 σ = 0.5 σ =

13 Window (or kernel) function: Width parameter n p x = 1 n 1 h d i=1 φ x x(i) h Choosing h: Too large: low resolution Too small: much variability [Duda, Hurt, and Stork] For unlimited n, by letting V slowly approach zero as n increases the estimated density converges to the true one 13
14 Width parameter For a fixed n, a smaller h results in higher variance while a larger h leads to higher bias. For a fixed h, the variance decreases as the number of sample points n tends to infinity for a large enough number of samples, the smaller h leads to better the accuracy of estimate In practice, where only a finite number of samples is possible, a compromise between h and n must be made. h can be set using techniques like cross-validation where the density estimation used for learning tasks such as classification 14
15 Practical issues: Curse of dimensionality Large n is necessary to find an acceptable density estimation in high dimensional feature spaces n must grow exponentially with the dimensionality d. If n equidistant points are required to densely fill a one-dim interval, n d points are needed to fill the corresponding d-dim hypercube. We need an exponentially large quantity of training data to ensure that the cells are not empty Also complexity requirements 15 d = 1 d = 2 d = 3
16 k-nearest neighbor density estimator Cell volume is a function of the point location To estimate p(x), let the cell around x grow until it captures k samples called k nearest neighbors of x. k is a function of n Two possibilities can occur: high density near x cell will be small which provides a good resolution low density near x cell will grow large and stop until higher density regions are reached 16

17 k-nearest Neighbor Estimation: Example Discontinuities in the slopes [Bishop] 17
18 Convergence K-nearest-neighbor density estimator and the kernel density estimator converge to the true probability density in the limit n When provided V shrinks suitably with n, and k grows with n 18
19 Non-parametric density estimation: Summary Generality of distributions With enough samples, convergence to an arbitrarily complicated target density can be obtained. The number of required samples must be very large to assure convergence grows exponentially with the dimensionality of the feature space These methods are very sensitive to the choice of window width or number of nearest neighbors There may be severe requirements for computation time and storage (needed to save all training samples). training phase simply requires storage of the training set. computational cost of evaluating p(x) grows linearly with the size of the data set. 19
20 Nonparametric learners Memory-based or instance-based learners lazy learning: (almost) all the work is done at the test time. Generic description: Memorize training (x (1), y (1) ),..., (x (n), y (n) ). Given test x predict: y = f(x; x (1), y (1),..., x (n), y (n) ). f is typically expressed in terms of the similarity of the test sample x to the training samples x (1),..., x (n) 20
21 Parzen window & generative classification If 1 n1 1 h d 1 n2 1 h d x (i) D1 x (i) D2 φ x x(i) h φ x x(i) h > P(C 2) P(C 1 ) decide C 1 otherwise decide C 2 n j = D j (j = 1,2): number of training samples in class C j D j : set of training samples labels as C j For large n, it needs both high time and memory requirements 21


22 Parzen window & generative classification: Example Smaller h larger h 22 [Duda, Hurt, and Stork]
23 k-nearest neighbor estimation & generative classification If kn 2V 2 kn 1 V 1 > P(C 2) P(C 1 ) decide C 1 otherwise decide C 2 n j = D j (j = 1,2): number of training samples in class C j D j : set of training samples labels as C j V j shows the hypersphere volumes r j : the radius of the hypersphere centered at x containing k samples of the class C j (j = 1,2) k may not necessarily be the same for all classes 23
24 k-nearest-neighbor (knn) rule k-nn classifier: k > 1 nearest neighbors Label for x predicted by majority voting among its k-nn. x 2 k = 5 1? x = [x 1, x 2 ] x 1 What is the effect of k? 24
25 knn classifier Given Training data {(x 1, y 1 ),..., (x n, y n )} are simply stored. Test sample: x To classify x: Find k nearest training samples to x Out of these k samples, identify the number of samples k j belonging to class C j (j = 1,, C). Assign x to the class C j where j = argmax k j j=1,,c It can be considered as a discriminative method. 25
26 Probabilistic perspective of knn knn as a discriminative nonparametric classifier Non-parametric density estimation for P(C j x) P C j x k j k where k j shows the number of training samples among k nearest neighbors of x that are labeled C j Bayes decision rule for assigning labels 26

27 Nearest-neighbor classifier: Example Voronoi tessellation: Each cell consists of all points closer to a given training point than to any other training points All points in a cell are labeled by the category of the corresponding training point. 27 [Duda, Hurt, and Strok s Book]
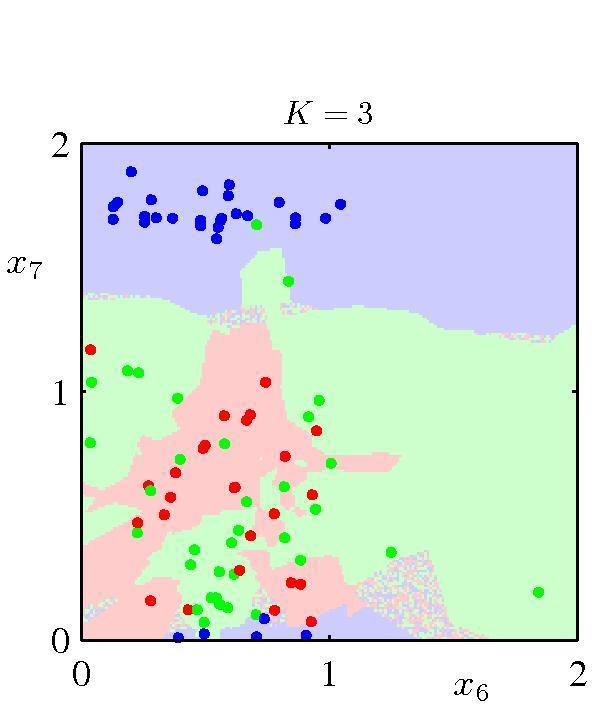
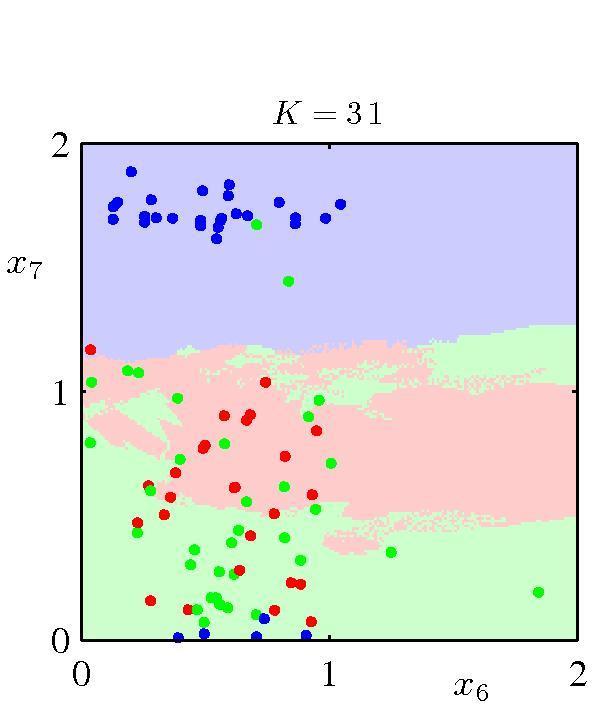
28 knn classifier: Effect of k [Bishop] 28
29 Nearest neighbor classifier: error bound Nearest-Neighbor: knn with k = 1 Decision rule: y = y NN(x) where NN(x) = argmin i=1,,n x x (i) Cover & Hart 67: asymptotic risk of NN classifier satisfies: R R NN 2R (1 R ) 2R R n : expected risk of NN classifier with n training examples drawn from p(x, y) R NN = lim n R n R : the optimal Bayes risk 29
30 k-nn classifier: error bound Devr 96: the asymptotic risk of the knn classifier R = lim n R n satisfies R R knn R + where R is the optimal Bayes risk. 2R NN k 30
31 Bound on the k-nearest Neighbor Error Rate bounds on k-nn error rate for different values of k (infinite training data) [Duda, Hurt, and Strok] As k increases, the upper bounds get closer to the lower bound (the Bayes Error rate). 31 When k, the two bounds meet and k-nn rule becomes optimal.
32 Instance-based learner Main things to construct an instance-based learner: A distance metric Number of nearest neighbors of the test data that we look at A weighting function (optional) How to find the output based on neighbors? 32
33 Distance measures Euclidean distance d x, x = x x 2 2 = x 1 x x d x d 2 Distance learning methods for this purpose Weighted Euclidean distance d w x, x = w 1 x 1 x w d x d x d 2 Mahalanobis distance d A x, x = x 1 x 1 T A x 1 x 1 Other distances: Hamming, angle, Sensitive to irrelevant features L p x, x = p d i=1 x i x i p 33
34 Distance measure: example d x, x = x 1 x x 2 x 2 2 d x, x = x 1 x x 2 x
35 Weighted knn classification Weight nearer neighbors more heavily: y = f x = argmax c=1,,c j N k (x) w j (x) I(c = y j ) w j (x) = 1 x x (j) 2 An example of weighting function In the weighted knn, we can use all training examples instead of just k (Stepard s method): 35 y = f x = argmax c=1,,c n j=1 w j (x) I(c = y j ) Weights can be found using a kernel function w j (x) = K(x, x (j) ): e.g., K(x, x (j) ) = e d(x,x(j) ) σ 2
36 Weighting functions Weighting function w.r.t. d(x, x ): 36 [Fig. has been adopted from Andrew Moore s tutorial on Instance-based learning ]
37 knn regression Simplest k-nn regression: Let x 1,, x k be the k nearest neighbors of x and y 1,, y k be their labels. y = 1 k k j=1 y j Problems of knn regression for fitting functions: Problem 1: Discontinuities in the estimated function Solution:Weighted (or kernel) regression 1NN: noise-fitting problem knn ( k > 1 ) smoothes away noise, but there are other deficiencies. flats the ends 37
38 knn regression: examples Dataset 1 Dataset 2 Dataset 3 k = 1 k = 9 38 [Figs. have been adopted from Andrew Moore s tutorial on Instance-based learning ]
39 Weighted (or kernel) knn regression Higher weights to nearer neighbors: y = f x = j N k (x) w j(x) y (j) j N k (x) w j(x) In the weighted knn regression, we can use all training examples instead of just k in the weighted form: y = f x = j=1 n w j (x) y (j) n w j (x) j=1 39
40 Kernel knn regression σ = 1 32 of x-axis width σ = 1 32 of x-axis width σ = 1 16 of x-axis width Choosing a good parameter (kernel width) is important. 40 [This slide has been adapted from Andrew Moore s tutorial on Instance-based learning ]
41 Kernel knn regression In these datasets, some regions are without samples Best kernel widths have been used Disadvantages: not capturing the simple structure of the data failure to extrapolate at edges 41 [Figs. have been adopted from Andrew Moore s tutorial on Instance-based learning ]
42 Locally weighted linear regression For each test sample, it produces linear approximation to the target function in a local region Instead of finding the output using weighted averaging (as in the kernel regression), we fit a parametric function locally: y = f x, x 1, y 1,..., x n, y n y = f x; w x = w x T x J w x = i N k (x) y i w x T x i 2 Unweighted linear 42 w is found for each test sample
43 Locally weighted linear regression y = f x, x 1, y 1,..., x n, y n J w x = y i w T x x i 2 i N k (x) J w x = K x, x i y i w T x x i 2 i N k (x) unweighted e.g, K x,x i = e x x i 2σ 2 weighted 2 J w x = n i=1 K x, x i y i w x T x i 2 Weighted on all training examples 43
44 Locally weighted linear regression: example σ = 1 16 of x-axis width σ = 1 32 of x-axis width σ = 1 8 of x-axis width More proper result than weighted knn regression 44 [Figs. have been adopted from Andrew Moore s tutorial on Instance-based learning ]
45 Instance-based regression: summary Idea 1: weighted knn regression using the weighted average on the output of x s neighbors (or on the outputs of all training data): y = i=1 k y i K(x, x (i) ) k K(x, x (j) ) j=1 Idea 2: Locally weighted parametric regression Fit a parametric model (e.g. linear function) to the neighbors of x (or on all training data). Implicit assumption: the target function is reasonably smooth. y 45 x
46 Parametric vs. nonparametric methods Is SVM classifier parametric? y = sign(w 0 + α i y i K(x, x (i) )) α i >0 In general, we can not summarize it in a simple parametric form. Need to keep around support vectors (possibly all of the training data). However, α i are kind of parameters that are found in the training phase 46
47 Instance-based learning: summary Learning is just storing the training data prediction on a new data based on the training data themselves An instance-based learner does not rely on assumption concerning the structure of the underlying density function. With large datasets, instance-based methods are slow for prediction on the test data kd-tree, Locally Sensitive Hashing (LSH), and other knn approximations can help. 47
Non-Parametric Modeling
 Non-Parametric Modeling CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Non-Parametric Density Estimation Parzen Windows Kn-Nearest Neighbor
Non-Parametric Modeling CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Non-Parametric Density Estimation Parzen Windows Kn-Nearest Neighbor
Machine Learning and Pervasive Computing
 Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques.
 . Non-Parameteric Techniques University of Cambridge Engineering Part IIB Paper 4F: Statistical Pattern Processing Handout : Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 23 Introduction
. Non-Parameteric Techniques University of Cambridge Engineering Part IIB Paper 4F: Statistical Pattern Processing Handout : Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 23 Introduction
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2015 11. Non-Parameteric Techniques
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2015 11. Non-Parameteric Techniques
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2011 11. Non-Parameteric Techniques
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2011 11. Non-Parameteric Techniques
Chapter 4: Non-Parametric Techniques
 Chapter 4: Non-Parametric Techniques Introduction Density Estimation Parzen Windows Kn-Nearest Neighbor Density Estimation K-Nearest Neighbor (KNN) Decision Rule Supervised Learning How to fit a density
Chapter 4: Non-Parametric Techniques Introduction Density Estimation Parzen Windows Kn-Nearest Neighbor Density Estimation K-Nearest Neighbor (KNN) Decision Rule Supervised Learning How to fit a density
Machine Learning. Nonparametric methods for Classification. Eric Xing , Fall Lecture 2, September 12, 2016
 Machine Learning 10-701, Fall 2016 Nonparametric methods for Classification Eric Xing Lecture 2, September 12, 2016 Reading: 1 Classification Representing data: Hypothesis (classifier) 2 Clustering 3 Supervised
Machine Learning 10-701, Fall 2016 Nonparametric methods for Classification Eric Xing Lecture 2, September 12, 2016 Reading: 1 Classification Representing data: Hypothesis (classifier) 2 Clustering 3 Supervised
These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
 course textbook Pattern Recognition and Machine Learning by Christopher Bishop") Machine Learning Algorithms (IFT6266 A7) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Machine Learning Algorithms (IFT6266 A7) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Nonparametric Methods
 Nonparametric Methods Jason Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Nonparametric Methods 1 / 49 Nonparametric Methods Overview Previously, we ve assumed that the forms of the underlying densities
Nonparametric Methods Jason Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Nonparametric Methods 1 / 49 Nonparametric Methods Overview Previously, we ve assumed that the forms of the underlying densities
Machine Learning Lecture 3
 Many slides adapted from B. Schiele Machine Learning Lecture 3 Probability Density Estimation II 26.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course
Many slides adapted from B. Schiele Machine Learning Lecture 3 Probability Density Estimation II 26.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course
Machine Learning Lecture 3
 Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 26.04.206 Discriminative Approaches (5 weeks) Linear
Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 26.04.206 Discriminative Approaches (5 weeks) Linear
Recap: Gaussian (or Normal) Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach
 Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach") Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Homework. Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression Pod-cast lecture on-line. Next lectures:
 Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
Machine Learning Lecture 3
 Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning. Supervised Learning. Manfred Huber
 Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Nonparametric Classification. Prof. Richard Zanibbi
 Nonparametric Classification Prof. Richard Zanibbi What to do when feature distributions (likelihoods) are not normal Don t Panic! While they may be suboptimal, LDC and QDC may still be applied, even though
Nonparametric Classification Prof. Richard Zanibbi What to do when feature distributions (likelihoods) are not normal Don t Panic! While they may be suboptimal, LDC and QDC may still be applied, even though
Content-based image and video analysis. Machine learning
 Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
Content-based image and video analysis Machine learning for multimedia retrieval 04.05.2009 What is machine learning? Some problems are very hard to solve by writing a computer program by hand Almost all
Statistical Learning Part 2 Nonparametric Learning: The Main Ideas. R. Moeller Hamburg University of Technology
 Statistical Learning Part 2 Nonparametric Learning: The Main Ideas R. Moeller Hamburg University of Technology Instance-Based Learning So far we saw statistical learning as parameter learning, i.e., given
Statistical Learning Part 2 Nonparametric Learning: The Main Ideas R. Moeller Hamburg University of Technology Instance-Based Learning So far we saw statistical learning as parameter learning, i.e., given
Perceptron as a graph
 Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
CS178: Machine Learning and Data Mining. Complexity & Nearest Neighbor Methods
 + CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
+ CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Nearest Neighbor Classification. Machine Learning Fall 2017
 Nearest Neighbor Classification Machine Learning Fall 2017 1 This lecture K-nearest neighbor classification The basic algorithm Different distance measures Some practical aspects Voronoi Diagrams and Decision
Nearest Neighbor Classification Machine Learning Fall 2017 1 This lecture K-nearest neighbor classification The basic algorithm Different distance measures Some practical aspects Voronoi Diagrams and Decision
Machine Learning: k-nearest Neighbors. Lecture 08. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning: k-nearest Neighbors Lecture 08 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Nonparametric Methods: k-nearest Neighbors Input: A training dataset
Machine Learning: k-nearest Neighbors Lecture 08 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Nonparametric Methods: k-nearest Neighbors Input: A training dataset
Notes and Announcements
 Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
We use non-bold capital letters for all random variables in these notes, whether they are scalar-, vector-, matrix-, or whatever-valued.
 The Bayes Classifier We have been starting to look at the supervised classification problem: we are given data (x i, y i ) for i = 1,..., n, where x i R d, and y i {1,..., K}. In this section, we suppose
The Bayes Classifier We have been starting to look at the supervised classification problem: we are given data (x i, y i ) for i = 1,..., n, where x i R d, and y i {1,..., K}. In this section, we suppose
Going nonparametric: Nearest neighbor methods for regression and classification
 Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
CSC 411: Lecture 05: Nearest Neighbors
 CSC 411: Lecture 05: Nearest Neighbors Raquel Urtasun & Rich Zemel University of Toronto Sep 28, 2015 Urtasun & Zemel (UofT) CSC 411: 05-Nearest Neighbors Sep 28, 2015 1 / 13 Today Non-parametric models
CSC 411: Lecture 05: Nearest Neighbors Raquel Urtasun & Rich Zemel University of Toronto Sep 28, 2015 Urtasun & Zemel (UofT) CSC 411: 05-Nearest Neighbors Sep 28, 2015 1 / 13 Today Non-parametric models
CS 340 Lec. 4: K-Nearest Neighbors
 CS 340 Lec. 4: K-Nearest Neighbors AD January 2011 AD () CS 340 Lec. 4: K-Nearest Neighbors January 2011 1 / 23 K-Nearest Neighbors Introduction Choice of Metric Overfitting and Underfitting Selection
CS 340 Lec. 4: K-Nearest Neighbors AD January 2011 AD () CS 340 Lec. 4: K-Nearest Neighbors January 2011 1 / 23 K-Nearest Neighbors Introduction Choice of Metric Overfitting and Underfitting Selection
Supervised Learning: Nearest Neighbors
 CS 2750: Machine Learning Supervised Learning: Nearest Neighbors Prof. Adriana Kovashka University of Pittsburgh February 1, 2016 Today: Supervised Learning Part I Basic formulation of the simplest classifier:
CS 2750: Machine Learning Supervised Learning: Nearest Neighbors Prof. Adriana Kovashka University of Pittsburgh February 1, 2016 Today: Supervised Learning Part I Basic formulation of the simplest classifier:
Generative and discriminative classification
 Generative and discriminative classification Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Classification in its simplest form Given training data labeled for two or more classes Classification
Generative and discriminative classification Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Classification in its simplest form Given training data labeled for two or more classes Classification
Classifiers and Detection. D.A. Forsyth
 Classifiers and Detection D.A. Forsyth Classifiers Take a measurement x, predict a bit (yes/no; 1/-1; 1/0; etc) Detection with a classifier Search all windows at relevant scales Prepare features Classify
Classifiers and Detection D.A. Forsyth Classifiers Take a measurement x, predict a bit (yes/no; 1/-1; 1/0; etc) Detection with a classifier Search all windows at relevant scales Prepare features Classify
COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING
 COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING Luca Bortolussi Department of Mathematics and Geosciences University of Trieste Office 238, third floor, H2bis luca@dmi.units.it Trieste, Winter Semester
COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING Luca Bortolussi Department of Mathematics and Geosciences University of Trieste Office 238, third floor, H2bis luca@dmi.units.it Trieste, Winter Semester
Data mining. Classification k-nn Classifier. Piotr Paszek. (Piotr Paszek) Data mining k-nn 1 / 20
 Data mining k-nn 1 / 20") Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Distribution-free Predictive Approaches
 Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
7. Nearest neighbors. Learning objectives. Foundations of Machine Learning École Centrale Paris Fall 2015
 Foundations of Machine Learning École Centrale Paris Fall 2015 7. Nearest neighbors Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr Learning
Foundations of Machine Learning École Centrale Paris Fall 2015 7. Nearest neighbors Chloé-Agathe Azencott Centre for Computational Biology, Mines ParisTech chloe agathe.azencott@mines paristech.fr Learning
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 15 th, 2007 2005-2007 Carlos Guestrin 1 1-Nearest Neighbor Four things make a memory based learner:
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 15 th, 2007 2005-2007 Carlos Guestrin 1 1-Nearest Neighbor Four things make a memory based learner:
Data Mining and Machine Learning: Techniques and Algorithms
 Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Voronoi Region. K-means method for Signal Compression: Vector Quantization. Compression Formula 11/20/2013
 Voronoi Region K-means method for Signal Compression: Vector Quantization Blocks of signals: A sequence of audio. A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1) A vector quantizer
Voronoi Region K-means method for Signal Compression: Vector Quantization Blocks of signals: A sequence of audio. A block of image pixels. Formally: vector example: (0.2, 0.3, 0.5, 0.1) A vector quantizer
CS6716 Pattern Recognition
 CS6716 Pattern Recognition Prototype Methods Aaron Bobick School of Interactive Computing Administrivia Problem 2b was extended to March 25. Done? PS3 will be out this real soon (tonight) due April 10.
CS6716 Pattern Recognition Prototype Methods Aaron Bobick School of Interactive Computing Administrivia Problem 2b was extended to March 25. Done? PS3 will be out this real soon (tonight) due April 10.
K-Nearest Neighbors. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 K-Nearest Neighbors Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Check out review materials Probability Linear algebra Python and NumPy Start your HW 0 On your Local machine:
K-Nearest Neighbors Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Check out review materials Probability Linear algebra Python and NumPy Start your HW 0 On your Local machine:
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Object Recognition 2015-2016 Jakob Verbeek, December 11, 2015 Course website: http://lear.inrialpes.fr/~verbeek/mlor.15.16 Classification
Generative and discriminative classification techniques Machine Learning and Object Recognition 2015-2016 Jakob Verbeek, December 11, 2015 Course website: http://lear.inrialpes.fr/~verbeek/mlor.15.16 Classification
7. Nearest neighbors. Learning objectives. Centre for Computational Biology, Mines ParisTech
 Foundations of Machine Learning CentraleSupélec Paris Fall 2016 7. Nearest neighbors Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
Foundations of Machine Learning CentraleSupélec Paris Fall 2016 7. Nearest neighbors Chloé-Agathe Azencot Centre for Computational Biology, Mines ParisTech chloe-agathe.azencott@mines-paristech.fr Learning
DATA MINING LECTURE 10B. Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines
 DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
DATA MINING LECTURE 10B Classification k-nearest neighbor classifier Naïve Bayes Logistic Regression Support Vector Machines NEAREST NEIGHBOR CLASSIFICATION 10 10 Illustrating Classification Task Tid Attrib1
Parametrizing the easiness of machine learning problems. Sanjoy Dasgupta, UC San Diego
 Parametrizing the easiness of machine learning problems Sanjoy Dasgupta, UC San Diego Outline Linear separators Mixture models Nonparametric clustering Nonparametric classification and regression Nearest
Parametrizing the easiness of machine learning problems Sanjoy Dasgupta, UC San Diego Outline Linear separators Mixture models Nonparametric clustering Nonparametric classification and regression Nearest
Problem 1: Complexity of Update Rules for Logistic Regression
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation
 Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology
 Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Classification: Linear Discriminant Functions
 Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
What is machine learning?
 Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Machine learning, pattern recognition and statistical data modelling Lecture 12. The last lecture Coryn Bailer-Jones 1 What is machine learning? Data description and interpretation finding simpler relationship
Support Vector Machines
 Support Vector Machines About the Name... A Support Vector A training sample used to define classification boundaries in SVMs located near class boundaries Support Vector Machines Binary classifiers whose
Support Vector Machines About the Name... A Support Vector A training sample used to define classification boundaries in SVMs located near class boundaries Support Vector Machines Binary classifiers whose
Data Mining Classification: Alternative Techniques. Lecture Notes for Chapter 4. Instance-Based Learning. Introduction to Data Mining, 2 nd Edition
 Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Instance Based Classifiers
Data Mining Classification: Alternative Techniques Lecture Notes for Chapter 4 Instance-Based Learning Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Instance Based Classifiers
Introduction to object recognition. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others
 Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Feature Selection. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Nearest Neighbor Classification
 Nearest Neighbor Classification Charles Elkan elkan@cs.ucsd.edu October 9, 2007 The nearest-neighbor method is perhaps the simplest of all algorithms for predicting the class of a test example. The training
Nearest Neighbor Classification Charles Elkan elkan@cs.ucsd.edu October 9, 2007 The nearest-neighbor method is perhaps the simplest of all algorithms for predicting the class of a test example. The training
MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11. Nearest Neighbour Classifier. Keywords: K Neighbours, Weighted, Nearest Neighbour
 MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11 Nearest Neighbour Classifier Keywords: K Neighbours, Weighted, Nearest Neighbour 1 Nearest neighbour classifiers This is amongst the simplest
MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11 Nearest Neighbour Classifier Keywords: K Neighbours, Weighted, Nearest Neighbour 1 Nearest neighbour classifiers This is amongst the simplest
Nearest Neighbor with KD Trees
 Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
9 Classification: KNN and SVM
 CSE4334/5334 Data Mining 9 Classification: KNN and SVM Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2017 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
CSE4334/5334 Data Mining 9 Classification: KNN and SVM Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2017 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Nearest Neighbor Predictors
 Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation
 Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Instance-Based Learning: Nearest neighbor and kernel regression and classificiation Emily Fox University of Washington February 3, 2017 Simplest approach: Nearest neighbor regression 1 Fit locally to each
Support Vector Machines + Classification for IR
 Support Vector Machines + Classification for IR Pierre Lison University of Oslo, Dep. of Informatics INF3800: Søketeknologi April 30, 2014 Outline of the lecture Recap of last week Support Vector Machines
Support Vector Machines + Classification for IR Pierre Lison University of Oslo, Dep. of Informatics INF3800: Søketeknologi April 30, 2014 Outline of the lecture Recap of last week Support Vector Machines
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
International Journal of Scientific Research & Engineering Trends Volume 4, Issue 6, Nov-Dec-2018, ISSN (Online): X
: X") Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Going nonparametric: Nearest neighbor methods for regression and classification
 Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 8, 28 Locality sensitive hashing for approximate NN
Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 8, 28 Locality sensitive hashing for approximate NN
Nearest Neighbor with KD Trees
 Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
Case Study 2: Document Retrieval Finding Similar Documents Using Nearest Neighbors Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Emily Fox January 22 nd, 2013 1 Nearest
Features: representation, normalization, selection. Chapter e-9
 Features: representation, normalization, selection Chapter e-9 1 Features Distinguish between instances (e.g. an image that you need to classify), and the features you create for an instance. Features
Features: representation, normalization, selection Chapter e-9 1 Features Distinguish between instances (e.g. an image that you need to classify), and the features you create for an instance. Features
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Classification. Slide sources:
 Classification Slide sources: Gideon Dror, Academic College of TA Yaffo Nathan Ifill, Leicester MA4102 Data Mining and Neural Networks Andrew Moore, CMU : http://www.cs.cmu.edu/~awm/tutorials 1 Outline
Classification Slide sources: Gideon Dror, Academic College of TA Yaffo Nathan Ifill, Leicester MA4102 Data Mining and Neural Networks Andrew Moore, CMU : http://www.cs.cmu.edu/~awm/tutorials 1 Outline
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Instance Based Learning. k-nearest Neighbor. Locally weighted regression. Radial basis functions. Case-based reasoning. Lazy and eager learning
 Instance Based Learning [Read Ch. 8] k-nearest Neighbor Locally weighted regression Radial basis functions Case-based reasoning Lazy and eager learning 65 lecture slides for textbook Machine Learning,
Instance Based Learning [Read Ch. 8] k-nearest Neighbor Locally weighted regression Radial basis functions Case-based reasoning Lazy and eager learning 65 lecture slides for textbook Machine Learning,
Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions
 Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551,
Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551,
CISC 4631 Data Mining
 CISC 4631 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F.
CISC 4631 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F.
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Linear Regression and K-Nearest Neighbors 3/28/18
 Linear Regression and K-Nearest Neighbors 3/28/18 Linear Regression Hypothesis Space Supervised learning For every input in the data set, we know the output Regression Outputs are continuous A number,
Linear Regression and K-Nearest Neighbors 3/28/18 Linear Regression Hypothesis Space Supervised learning For every input in the data set, we know the output Regression Outputs are continuous A number,
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
Classification Algorithms in Data Mining
 August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
August 9th, 2016 Suhas Mallesh Yash Thakkar Ashok Choudhary CIS660 Data Mining and Big Data Processing -Dr. Sunnie S. Chung Classification Algorithms in Data Mining Deciding on the classification algorithms
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
6.867 Machine Learning
 6.867 Machine Learning Problem set - solutions Thursday, October What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove. Do not
6.867 Machine Learning Problem set - solutions Thursday, October What and how to turn in? Turn in short written answers to the questions explicitly stated, and when requested to explain or prove. Do not
UVA CS 4501: Machine Learning. Lecture 10: K-nearest-neighbor Classifier / Bias-Variance Tradeoff. Dr. Yanjun Qi. University of Virginia
 UVA CS 4501: Machine Learning Lecture 10: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 1 Where are we? è Five major secfons
UVA CS 4501: Machine Learning Lecture 10: K-nearest-neighbor Classifier / Bias-Variance Tradeoff Dr. Yanjun Qi University of Virginia Department of Computer Science 1 Where are we? è Five major secfons
Performance Measures
 1 Performance Measures Classification F-Measure: (careful: similar but not the same F-measure as the F-measure we saw for clustering!) Tradeoff between classifying correctly all datapoints of the same
1 Performance Measures Classification F-Measure: (careful: similar but not the same F-measure as the F-measure we saw for clustering!) Tradeoff between classifying correctly all datapoints of the same
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
Supervised Learning: K-Nearest Neighbors and Decision Trees
 Supervised Learning: K-Nearest Neighbors and Decision Trees Piyush Rai CS5350/6350: Machine Learning August 25, 2011 (CS5350/6350) K-NN and DT August 25, 2011 1 / 20 Supervised Learning Given training
Supervised Learning: K-Nearest Neighbors and Decision Trees Piyush Rai CS5350/6350: Machine Learning August 25, 2011 (CS5350/6350) K-NN and DT August 25, 2011 1 / 20 Supervised Learning Given training
k-nearest Neighbor (knn) Sept Youn-Hee Han
 Sept Youn-Hee Han") k-nearest Neighbor (knn) Sept. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²Eager Learners Eager vs. Lazy Learning when given a set of training data, it will construct a generalization model before receiving
k-nearest Neighbor (knn) Sept. 2015 Youn-Hee Han http://link.koreatech.ac.kr ²Eager Learners Eager vs. Lazy Learning when given a set of training data, it will construct a generalization model before receiving
Object Recognition. Lecture 11, April 21 st, Lexing Xie. EE4830 Digital Image Processing
 Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
Object Recognition Lecture 11, April 21 st, 2008 Lexing Xie EE4830 Digital Image Processing http://www.ee.columbia.edu/~xlx/ee4830/ 1 Announcements 2 HW#5 due today HW#6 last HW of the semester Due May
Naïve Bayes for text classification
 Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
Road Map Basic concepts Decision tree induction Evaluation of classifiers Rule induction Classification using association rules Naïve Bayesian classification Naïve Bayes for text classification Support
The Boundary Graph Supervised Learning Algorithm for Regression and Classification
 The Boundary Graph Supervised Learning Algorithm for Regression and Classification! Jonathan Yedidia! Disney Research!! Outline Motivation Illustration using a toy classification problem Some simple refinements
The Boundary Graph Supervised Learning Algorithm for Regression and Classification! Jonathan Yedidia! Disney Research!! Outline Motivation Illustration using a toy classification problem Some simple refinements
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
Recognition Tools: Support Vector Machines
 CS 2770: Computer Vision Recognition Tools: Support Vector Machines Prof. Adriana Kovashka University of Pittsburgh January 12, 2017 Announcement TA office hours: Tuesday 4pm-6pm Wednesday 10am-12pm Matlab
CS 2770: Computer Vision Recognition Tools: Support Vector Machines Prof. Adriana Kovashka University of Pittsburgh January 12, 2017 Announcement TA office hours: Tuesday 4pm-6pm Wednesday 10am-12pm Matlab
Machine Learning. Chao Lan
 Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Data Preprocessing. Supervised Learning
 Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
Supervised Learning Regression Given the value of an input X, the output Y belongs to the set of real values R. The goal is to predict output accurately for a new input. The predictions or outputs y are
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality