Exploratory Analysis: Clustering
|
|
|
- Marlene Ferguson
- 5 years ago
- Views:
Transcription
 Heejun Kim June 26,")
1 Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018
2 Clustering objective Grouping documents or instances into subsets or clusters Documents in the same cluster should be similar Documents in different clusters should be dissimilar A common form of unsupervised learning Unsupervised = no human-produced labels The goal is to discover structure from the data
3 Clustering vs. Classification Classification: the input to the system is a set of labeled data the algorithm learns a model for predicting the label on new examples Clustering: the input to the system is a set of unlabeled data the algorithm infers the labels from the data and assigns a label to each input instance
4 Clustering applications Search engine results clustering: grouping search engine results by topic the user can identify the relevant clusters and ignore the non-relevant ones Collection clustering: grouping documents by topic to support navigation and exploration Data analytics: grouping instances to identify popular trends (big clusters) and outliers (small clusters)
5 Clustering Applications search engine results clustering

6 Clustering Applications collection clustering

7 Clustering Applications collection clustering
8 Clustering objective Grouping documents or instances into subsets or clusters Documents within a the same cluster should be similar Documents from different clusters should be dissimilar
9 Clustering basics What does it mean for documents to be similar or dissimilar? We need a computational way of modeling similarity One solution: model similarity using distance in a vector space representation of the collection or dataset small distance = high similarity long distance = low similarity
10 Vector Space Representation review A vector space is defined by a set of linearly independent basis vectors The basis vectors correspond to the dimensions or directions of the vector space Y Y basis vectors for 2- dimensional space X basis vectors for 3- dimensional space X Z
11 Vector Space Representation review A vector is a point in a vector space Y Y X X Z
12 Vector Space Representation review A 2-dimensional vector can be written as [x,y] A 3-dimensional vector can be written as [x,y,z] Y Y x y X x y z X Z
13 Vector Space Representation review w_1 w_2 w_3 w_4 w_5 w_6 w_7 w_8 w_9 w_
14 Vector Space Representation review w_1 w_2 w_3 w_4 w_5 w_6 w_7 w_8 w_9 w_ We can represent this document as a vector in a 10- dimensional vector space
15 Vector Space Representation review w_1 w_2 w_3 w_4 w_5 w_6 w_7 w_8 w_9 w_ This representation assumes binary term-weights. Are there other term-weighting schemes?
16 Vector Space Representation review Similarity = Euclidean Distance:
17 Vector Space Representation review Y (50.60, 61.90) Y (101.80, 43.33) (96.72, 30.95) X
18 Clustering What would we expect a clustering algorithm to do with this dataset?
19 Clustering What would we expect a clustering algorithm to do with this dataset?
20 Clustering Propose an algorithm that might be able to do this!
21 Clustering Input: number of desired clusters K Output: assignment of documents to K clusters Algorithm: randomly select K documents (seeds) assign each remaining document to its nearest seed and so on.
22 Clustering Could this work?
23 K-Means Clustering
24 K-means Clustering cluster centroid The key to understanding K-means clustering is to understand the idea of a cluster centroid Given a cluster, you can think of its centroid as a point (or vector) that corresponds to its center of mass
25 K-means Clustering cluster centroid The key to understanding K-means clustering is to understand the idea of a cluster centroid Given a cluster, you can think of its centroid as a point (or vector) that corresponds to its center of mass
26 K-means Clustering cluster centroid The key to understanding K-means clustering is to understand the idea of a cluster centroid Given a cluster, you can think of its centroid as a point (or vector) that corresponds to its center of mass
27 K-means Clustering cluster centroid The key to understanding K-means clustering is to understand the idea of a cluster centroid Given a cluster, you can think of its centroid as a point (or vector) that corresponds to its center of mass
28 K-means Clustering cluster centroid The key to understanding K-means clustering is to understand the idea of a cluster centroid Given a cluster, you can think of its centroid as a point (or vector) that corresponds to its center of mass
29 K-means Clustering cluster centroid The key to understanding K-means clustering is to understand the idea of a cluster centroid Given a cluster, you can think of its centroid as a point (or vector) that corresponds to its center of mass
30 K-means Clustering cluster centroid w_1 w_2 w_3 w_4 w_5 w_6 w_7 w_8 w_9 w_ docs assigned to cluster cluster 1 centroid w_1 w_2 w_3 w_4 w_5 w_6 w_7 w_8 w_9 w_10??????????
31 K-means Clustering cluster centroid w_1 w_2 w_3 w_4 w_5 w_6 w_7 w_8 w_9 w_ docs assigned to cluster cluster 1 centroid (average!) w_1 w_2 w_3 w_4 w_5 w_6 w_7 w_8 w_9 w_
32 K-means Clustering cluster centroid For each dimension i, set:
33 K-means Clustering Input: number of desired clusters K Output: assignment of documents to K clusters Algorithm: Step 1: randomly select K documents (seeds) Step 2: assign each document to its nearest seed Step 3: compute all K cluster centroids Step 4: re-assign each document to its nearest centroid Step 5: re-compute all K cluster centroids Step 6: repeat steps 4 and 5 until terminating condition
34 K-means Clustering Step 1: randomly select K documents (seeds)
35 K-means Clustering Step 2: assign each document to its nearest seed
36 K-means Clustering Step 3: compute all K cluster centroids x x
37 K-means Clustering Step 4: re-assign each document to its nearest centroid x x
38 K-means Clustering Step 4: re-compute all K cluster centroids x x
39 K-means Clustering Step 5: re-assign each document to its nearest centroid x x
40 K-means Clustering Step 4: re-compute all K cluster centroids x x
41 K-means Clustering Step 5: re-assign each document to its nearest centroid x x
42 K-means Clustering Input: number of desired clusters K Output: assignment of documents to K clusters Algorithm: Step 1: randomly select K documents (seeds) Step 2: assign each document to its nearest seed Step 3: compute all K cluster centroids Step 4: re-assign each document to its nearest centroid Step 5: re-compute all K cluster centroids Step 6: repeat steps 4 and 5 until terminating condition
43 K-means Clustering potential drawback The quality of the output clustering depends on the choice of K and on the initial seeds In many cases, the choice of K is pre-determined by the application Search engine results clustering: grouping search engine results by topic Collection clustering: grouping documents by topic to support navigation and exploration Later we ll see ways of setting K dynamically
44 K-means Clustering bad seeds?
45 K-means Clustering bad seeds?
46 K-means Clustering bad seeds?
47 K-means Clustering bad seeds? x x
48 K-means Clustering bad seeds? x x
49 K-means Clustering bad seeds? x x
50 K-means Clustering bad seeds? x x
51 K-means Clustering bad seeds It s difficult to know which seeds will yield a high-quality clustering However, it s usually a good idea to avoid seeds that are outliers How would you detect outliers?
52 K-means Clustering clustering evaluation What does it mean for a clustering to be high quality anyway? What is the goal of clustering again?
53 K-means Clustering internal evaluation In theory, a good clustering should have: Similar documents in the same clusters Different documents in different clusters
54 K-means Clustering internal evaluation Clustering Quality Average distance between all pairs of documents in different clusters Average distance between all pairs of documents in the same cluster = ( ) - ( ) Inter-cluster distance Intra-cluster distance
55 K-means Clustering improved k-means Given a set of documents and a value K, run K-means clustering N times and keep the clustering that produces the greatest difference between the inter-cluster distance and the intra-cluster distance
56 Bottom-up Agglomerative Clustering
57 Bottom-up Clustering While K-means requires setting K, bottom-up clustering groups the data in a hierarchical fashion We can then set K after the clustering is done or use a distance threshold to set K dynamically (more on this later)
58 Bottom-up Clustering Input: data Output: cluster hierarchy Algorithm: Step 1: consider every document its own cluster Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one Step 4: repeat steps 2 and 3 until every document is in one cluster
59 Bottom-up Clustering Input: data Output: cluster hierarchy Algorithm: Step 1: consider every document its own cluster Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one Step 4: repeat steps 2 and 3 until every document is in one cluster
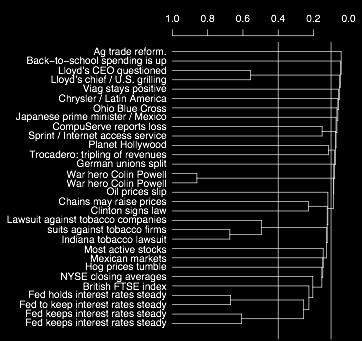
60 Bottom-up Clustering
61 Bottom-up Clustering Computing the distance between two clusters Single-Link: the distance between the two nearest documents Complete-Link: the distance between the two documents that are farthest apart Average-Link: the average distance between all document pairs in the two different clusters this is equivalent to using the distance between the two cluster centroids
62 Bottom-up Clustering single-link Step 1: consider each document its own cluster
63 Bottom-up Clustering single-link Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one
64 Bottom-up Clustering single-link Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one
65 Bottom-up Clustering single-link Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one
66 Bottom-up Clustering single-link Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one
67 Bottom-up Clustering single-link Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one
68 Bottom-up Clustering single-link Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one
69 Bottom-up Clustering single-link Step 2: compute the distance between all cluster pairs Step 3: merge/combine the nearest two clusters into one
70 Bottom-up Clustering Setting K dynamically Instead of setting K, we could set a distance threshold T Stop merging/combining clusters when the distance between the two nearest clusters > T Using a distance threshold can help prevent concept drift (especially with single-link clustering) text mining --> HiDAV --> unc --> basketball
71 Labeling Clusters

72 Clustering Applications collection clustering How can we name clusters to inform someone about the kind of information they contain?
73 Labeling Clusters A simple solution Construct a vocabulary of terms and/or phrases (n-grams) that are frequent in the data Assign each cluster the term(s) or phrase(s) with the highest mutual information
74 Mutual Information P(w,c): the probability that a document contains word w and belongs to cluster c P(w): the probability that word w occurs in a document from any cluster P(c): the probability that a document belongs to cluster c
75 Mutual Information If P(w,c) = P(w) P(c), it means that the word w is independent of cluster c If P(w,c) > P(w) P(c), it means that the word w is not independent of of cluster c
76 Mutual Information Every document falls under one of these quadrants belongs to cluster c does not belong to cluster c total # of instances N = a + b + c + d P(w, c) = a / N contains word w does not contains word w a c b d P(c) = P(w) = (a + c) / N (a + b) / N
77 Summary Clustering: grouping similar documents (or instances) into subsets Exploratory analysis: the goal is to discover common and uncommon properties of the data K-means and Agglomerative Bottom-up Clustering (there are many, many others) Labeling clusters

78 The Future of Text Mining Link

79 Too Many Barriers? It really Matter Where to Apply and How to Start. Link

80 Challenge with Something You Really Like What is Data Analytics? (An Analogy)
81 Any Questions?
82 No More Next Class
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Clustering and Dimensionality Reduction. Stony Brook University CSE545, Fall 2017
 Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Machine Learning: Symbol-based
 10d Machine Learning: Symbol-based More clustering examples 10.5 Knowledge and Learning 10.6 Unsupervised Learning 10.7 Reinforcement Learning 10.8 Epilogue and References 10.9 Exercises Additional references
10d Machine Learning: Symbol-based More clustering examples 10.5 Knowledge and Learning 10.6 Unsupervised Learning 10.7 Reinforcement Learning 10.8 Epilogue and References 10.9 Exercises Additional references
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Today s topic CS347. Results list clustering example. Why cluster documents. Clustering documents. Lecture 8 May 7, 2001 Prabhakar Raghavan
 Today s topic CS347 Clustering documents Lecture 8 May 7, 2001 Prabhakar Raghavan Why cluster documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics
Today s topic CS347 Clustering documents Lecture 8 May 7, 2001 Prabhakar Raghavan Why cluster documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Chapter 9. Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Infographics and Visualisation (or: Beyond the Pie Chart) LSS: ITNPBD4, 1 November 2016
 LSS: ITNPBD4, 1 November 2016") Infographics and Visualisation (or: Beyond the Pie Chart) LSS: ITNPBD4, 1 November 2016 Overview Overview (short: we covered most of this in the tutorial) Why infographics and visualisation What s the
Infographics and Visualisation (or: Beyond the Pie Chart) LSS: ITNPBD4, 1 November 2016 Overview Overview (short: we covered most of this in the tutorial) Why infographics and visualisation What s the
A Comparative study of Clustering Algorithms using MapReduce in Hadoop
 A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
A Comparative study of Clustering Algorithms using MapReduce in Hadoop Dweepna Garg 1, Khushboo Trivedi 2, B.B.Panchal 3 1 Department of Computer Science and Engineering, Parul Institute of Engineering
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Introduction to Data Mining
 Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Unsupervised Learning I: K-Means Clustering
 Unsupervised Learning I: K-Means Clustering Reading: Chapter 8 from Introduction to Data Mining by Tan, Steinbach, and Kumar, pp. 487-515, 532-541, 546-552 (http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf)
Unsupervised Learning I: K-Means Clustering Reading: Chapter 8 from Introduction to Data Mining by Tan, Steinbach, and Kumar, pp. 487-515, 532-541, 546-552 (http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf)
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Lecture 8 May 7, Prabhakar Raghavan
 Lecture 8 May 7, 2001 Prabhakar Raghavan Clustering documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics Given the set of docs from the results of
Lecture 8 May 7, 2001 Prabhakar Raghavan Clustering documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics Given the set of docs from the results of
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16)
") CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Text Documents clustering using K Means Algorithm
 Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
CS490W. Text Clustering. Luo Si. Department of Computer Science Purdue University
 CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
CLUSTERING. CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16
 CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
CLUSTERING CSE 634 Data Mining Prof. Anita Wasilewska TEAM 16 1. K-medoids: REFERENCES https://www.coursera.org/learn/cluster-analysis/lecture/nj0sb/3-4-the-k-medoids-clustering-method https://anuradhasrinivas.files.wordpress.com/2013/04/lesson8-clustering.pdf
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
CHAPTER 4 K-MEANS AND UCAM CLUSTERING ALGORITHM
 CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
CHAPTER 4 K-MEANS AND UCAM CLUSTERING 4.1 Introduction ALGORITHM Clustering has been used in a number of applications such as engineering, biology, medicine and data mining. The most popular clustering
Big Data Analytics! Special Topics for Computer Science CSE CSE Feb 9
 Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Clustering & Classification (chapter 15)
") Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
Clustering & Classification (chapter 5) Kai Goebel Bill Cheetham RPI/GE Global Research goebel@cs.rpi.edu cheetham@cs.rpi.edu Outline k-means Fuzzy c-means Mountain Clustering knn Fuzzy knn Hierarchical
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE
 BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE") APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
APPLICATION OF MULTIPLE RANDOM CENTROID (MRC) BASED K-MEANS CLUSTERING ALGORITHM IN INSURANCE A REVIEW ARTICLE Sundari NallamReddy, Samarandra Behera, Sanjeev Karadagi, Dr. Anantha Desik ABSTRACT: Tata
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Feature Extractors. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. The Perceptron Update Rule.
 CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Workload Characterization Techniques
 Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
Workload Characterization Techniques Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides are available on-line at: http://www.cse.wustl.edu/~jain/cse567-08/
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
What is Unsupervised Learning?
 Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
Clustering What is Unsupervised Learning? Unlike in supervised learning, in unsupervised learning, there are no labels We simply a search for patterns in the data Examples Clustering Density Estimation
An Unsupervised Technique for Statistical Data Analysis Using Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 5, Number 1 (2013), pp. 11-20 International Research Publication House http://www.irphouse.com An Unsupervised Technique
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Data Mining. Dr. Raed Ibraheem Hamed. University of Human Development, College of Science and Technology Department of Computer Science
 Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Data Mining Dr. Raed Ibraheem Hamed University of Human Development, College of Science and Technology Department of Computer Science 2016 201 Road map What is Cluster Analysis? Characteristics of Clustering
Machine Learning - Clustering. CS102 Fall 2017
 Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
Machine Learning - Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Data Mining Looking for
Statistics 202: Data Mining. c Jonathan Taylor. Clustering Based in part on slides from textbook, slides of Susan Holmes.
 Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group will be similar (or
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Natural Language Processing
 Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Introduction to Artificial Intelligence COMP307 Machine Learning 2: 3-K Techniques Yi Mei yi.mei@ecs.vuw.ac.nz 1 Outline K-Nearest Neighbour method Classification (Supervised learning) Basic NN (1-NN)
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Clustering Clustering Algorithms Contents K-means Hierarchical algorithms Linkage functions Vector quantization SOM Clustering Formulation
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Jarek Szlichta
 Jarek Szlichta http://data.science.uoit.ca/ Approximate terminology, though there is some overlap: Data(base) operations Executing specific operations or queries over data Data mining Looking for patterns
Jarek Szlichta http://data.science.uoit.ca/ Approximate terminology, though there is some overlap: Data(base) operations Executing specific operations or queries over data Data mining Looking for patterns
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Mining Social Media Users Interest
 Mining Social Media Users Interest Presenters: Heng Wang,Man Yuan April, 4 th, 2016 Agenda Introduction to Text Mining Tool & Dataset Data Pre-processing Text Mining on Twitter Summary & Future Improvement
Mining Social Media Users Interest Presenters: Heng Wang,Man Yuan April, 4 th, 2016 Agenda Introduction to Text Mining Tool & Dataset Data Pre-processing Text Mining on Twitter Summary & Future Improvement
Clustering CE-324: Modern Information Retrieval Sharif University of Technology
 Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Mining di Dati Web. Lezione 3 - Clustering and Classification
 Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
Mining di Dati Web Lezione 3 - Clustering and Classification Introduction Clustering and classification are both learning techniques They learn functions describing data Clustering is also known as Unsupervised
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Chapter 18 Clustering
 Chapter 18 Clustering CS4811 Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University 1 Outline Examples Centroid approaches Hierarchical approaches 2 Example:
Chapter 18 Clustering CS4811 Artificial Intelligence Nilufer Onder Department of Computer Science Michigan Technological University 1 Outline Examples Centroid approaches Hierarchical approaches 2 Example:
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
International Journal of Advanced Research in Computer Science and Software Engineering
 Volume 3, Issue 3, March 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue:
Volume 3, Issue 3, March 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue:
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008
 CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
CS4445 Data Mining and Knowledge Discovery in Databases. A Term 2008 Exam 2 October 14, 2008 Prof. Carolina Ruiz Department of Computer Science Worcester Polytechnic Institute NAME: Prof. Ruiz Problem
Iteration Reduction K Means Clustering Algorithm
 Iteration Reduction K Means Clustering Algorithm Kedar Sawant 1 and Snehal Bhogan 2 1 Department of Computer Engineering, Agnel Institute of Technology and Design, Assagao, Goa 403507, India 2 Department
Iteration Reduction K Means Clustering Algorithm Kedar Sawant 1 and Snehal Bhogan 2 1 Department of Computer Engineering, Agnel Institute of Technology and Design, Assagao, Goa 403507, India 2 Department
Comparative Study of Clustering Algorithms using R
 Comparative Study of Clustering Algorithms using R Debayan Das 1 and D. Peter Augustine 2 1 ( M.Sc Computer Science Student, Christ University, Bangalore, India) 2 (Associate Professor, Department of Computer
Comparative Study of Clustering Algorithms using R Debayan Das 1 and D. Peter Augustine 2 1 ( M.Sc Computer Science Student, Christ University, Bangalore, India) 2 (Associate Professor, Department of Computer
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Redefining and Enhancing K-means Algorithm
 Redefining and Enhancing K-means Algorithm Nimrat Kaur Sidhu 1, Rajneet kaur 2 Research Scholar, Department of Computer Science Engineering, SGGSWU, Fatehgarh Sahib, Punjab, India 1 Assistant Professor,
Redefining and Enhancing K-means Algorithm Nimrat Kaur Sidhu 1, Rajneet kaur 2 Research Scholar, Department of Computer Science Engineering, SGGSWU, Fatehgarh Sahib, Punjab, India 1 Assistant Professor,
Clustering (COSC 416) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Overview. Non-Parametrics Models Definitions KNN. Ensemble Methods Definitions, Examples Random Forests. Clustering. k-means Clustering 2 / 8
 Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
Tutorial 3 1 / 8 Overview Non-Parametrics Models Definitions KNN Ensemble Methods Definitions, Examples Random Forests Clustering Definitions, Examples k-means Clustering 2 / 8 Non-Parametrics Models Definitions
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin