Compilation /17a Lecture 10. Register Allocation Noam Rinetzky
|
|
|
- Jeffrey Underwood
- 5 years ago
- Views:
Transcription

1 Compilation /17a Lecture 10 Register Allocation Noam Rinetzky 1

2 What is a Compiler? 2
3 Registers Dedicated memory locations that can be accessed quickly, can have computations performed on them, and
4 Registers Dedicated memory locations that can be accessed quickly, can have computations performed on them, and Usages Operands of instructions Store temporary results Can (should) be used as loop indexes due to frequent arithmetic operation Used to manage administrative info e.g., runtime stack
5 Register allocation Number of registers is limited Need to allocate them in a clever way Using registers intelligently is a critical step in any compiler A good register allocator can generate code orders of magnitude better than a bad register allocator
6 Register Allocation: IR Source code (program) Lexical Analysis Syntax Analysis Parsing AST Symbol Table etc. Inter. Rep. (IR) Code Generation Target code (executable) 6
, %eax mov 20(%ebp), %ebx add %ebx, %eax mov %eax, 24(%ebp) Problem: program execution very inefficient moving data back and forth between memory and")
7 Simple approach Straightforward solution: Allocate each variable in activation record At each instruction, bring values needed into registers, perform operation, then store result to memory x = y + z mov 16(%ebp), %eax mov 20(%ebp), %ebx add %ebx, %eax mov %eax, 24(%ebp) Problem: program execution very inefficient moving data back and forth between memory and registers
8 Simple code generation assume machine instructions of the form LD reg, mem ST mem, reg OP reg,reg,reg (*) assume that we have all registers available for our use Ignore registers allocated for stack management Treat all registers as general-purpose
9 simple code generation assume machine instructions of the form LD reg, mem ST mem, reg OP reg,reg,reg (*) Fixed number of Registers!
10 Register allocation In TAC, there is an unlimited number of variables (temporaries) On a physical machine there is a small number of registers: x86 has 4 general-purpose registers and a number of specialized registers MIPS has 24 general-purpose registers and 8 special-purpose registers Register allocation is the process of assigning variables to registers and managing data transfer in and out of registers
11 simple code generation assume machine instructions of the form LD reg, mem ST mem, reg OP reg,reg,reg (*) Fixed number of Registers! We will assume that we have all registers available for any usage Ignore registers allocated for stack management Treat all registers as general-purpose
12 Plan Goal: Reduce number of temporaries (registers) Machine-agnostic optimizations Assume unbounded number of registers Machine-dependent optimization Use at most K registers K is machine dependent
13 Sethi-Ullman translation Algorithm by Ravi Sethi and Jeffrey D. Ullman to emit optimal TAC Minimizes number of temporaries for a single expression
14 Generating Compound Expressions Use registers to store temporaries Why can we do it? Maintain a counter for temporaries in c Initially: c = 0 cgen(e 1 op e 2 ) = { Let A = cgen(e 1 ) c = c + 1 Let B = cgen(e 2 ) c = c + 1 Emit( _tc = A op B; ) // _tc is a register Return _tc } Why Naïve?
15 Improving cgen for expressions Observation naïve translation needlessly generates temporaries for leaf expressions Observation temporaries used exactly once Once a temporary has been read it can be reused for another sub-expression cgen(e 1 op e 2 ) = { Let _t1 = cgen(e 1 ) Let _t2 = cgen(e 2 ) Emit( _t1 =_t1 op _t2; ) Return _t1 } Temporaries cgen(e 1 ) can be reused in cgen(e 2 )
16 Register Allocation Machine-agnostic optimizations Assume unbounded number of registers Expression trees Basic blocks Machine-dependent optimization K registers Some have special purposes Control flow graphs (whole program)
17 Sethi-Ullman translation Algorithm by Ravi Sethi and Jeffrey D. Ullman to emit optimal TAC Minimizes number of temporaries for a single expression
18 Example (optimized): b*b-4*a*c 3-2 * 2 * 1 b 1 b * 1 a 1c
19 Generalizations More than two arguments for operators Function calls Multiple effected registers Multiplication Spilling Need more registers than available Register/memory operations
20 Simple Spilling Method Heavy tree Needs more registers than available A heavy tree contains a heavy subtree whose dependents are light Simple spilling Generate code for the light tree Spill the content into memory and replace subtree by temporary Generate code for the resultant tree
21 Example (optimized): b*b-4*a*c 3-2 * 2 * 1 b 1 b * 1 a 1c
22 Example (spilled): x := b*b-4*a*c 2 * 2-1 b 1 b 1 t 7 2 * * 1 a 1c t7 := b * b x := t7 4 * a * c
23 Example: b*b-4*a*c - * * b b 4 * a c
24 Example (simple): b*b-4*a*c 9-3 * 8 * 1 b 2 b * 5 a 6c
25 Example (optimized): b*b-4*a*c 3-2 * 2 * 1 b 1 b * 1 a 1c
26 Spilling Even an optimal register allocator can require more registers than available Need to generate code for every correct program The compiler can save temporary results Spill registers into temporaries Load when needed Many heuristics exist
27 Simple Spilling Method Heavy tree Needs more registers than available A `heavy tree contains a `heavy subtree whose dependents are light Generate code for the light tree Spill the content into memory and replace subtree by temporary Generate code for the resultant tree
28 Spilling Even an optimal register allocator can require more registers than available Need to generate code for every correct program The compiler can save temporary results Spill registers into temporaries Load when needed Many heuristics exist
29 Simple approach Straightforward solution: Allocate each variable in activation record At each instruction, bring values needed into registers, perform operation, then store result to memory x = y + z mov 16(%ebp), %eax mov 20(%ebp), %ebx add %ebx, %eax mov %eax, 24(%ebx) Problem: program execution very inefficient moving data back and forth between memory and registers
30 Register Allocation Machine-agnostic optimizations Assume unbounded number of registers Expression trees (tree-local) Basic blocks (block-local) Machine-dependent optimization K registers Some have special purposes Control flow graphs (global register allocation)
31 Example (optimized): b*b-4*a*c 3-2 * 2 * 1 b 1 b * 1 a 1c
32 Example (spilled): x := b*b-4*a*c 2 * 2-1 b 1 b 1 t 7 2 * * 1 a 1c t7 := b * b x := t7 4 * a * c
33 Simple Spilling Method
34 Register Memory Operations Add_Mem X, R1 Mult_Mem X, R1 Hidden Registers No need for registers to store right operands
35 Example: b*b-4*a*c 2-1 Mult_Mem 1 Mult_Mem 0 b 1 b Mult_Mem 0 a 1c
36 Can We do Better? Yes: Increase view of code Simultaneously allocate registers for multiple expressions But: Lose per expression optimality Works well in practice
37 Register Allocation Machine-agnostic optimizations Assume unbounded number of registers Expression trees Basic blocks Machine-dependent optimization K registers Some have special purposes Control flow graphs (whole program)
38 Basic Blocks basic block is a sequence of instructions with single entry (to first instruction), no jumps to the middle of the block single exit (last instruction) code execute as a sequence from first instruction to last instruction without any jumps edge from one basic block B1 to another block B2 when the last statement of B1 may jump to B2
39 control flow graph A directed graph G=(V,E) nodes V = basic blocks B1 prod := 0 i := 1 B 1 edges E = control flow B2 (B1,B2) Î E when control from B1 flows to B2 Leaders-based construction Target of jump instructions Instructions following jumps True t 1 := 4 * i t 2 := a [ t 1 ] t 3 := 4 * i t 4 := b [ t 3 ] t 5 := t 2 * t 4 t 6 := prod + t 5 prod := t 6 t 7 := i + 1 i := t 7 if i <= 20 goto B 2 B 2 False
40 control flow graph A directed graph G=(V,E) nodes V = basic blocks B1 prod := 0 i := 1 B 1 edges E = control flow (B1,B2) Î E when control from B1 flows to B2 B2 t 1 := 4 * i t 2 := a [ t 1 ] t 3 := 4 * i t 4 := b [ t 3 ] t 5 := t 2 * t 4 t 6 := prod + t 5 prod := t 6 t 7 := i + 1 i := t 7 if i <= 20 goto B 2 B 2
41 { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; AST for a Basic Block
42 { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; Dependency graph
43 { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; Simplified Data Dependency Graph
44 Pseudo Register Target Code
45 { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; Question: Why y?
46 Question: Why y? False True int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; z := y + x; y := 0;
47 Question: Why y? False True int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; y := 0; z := y + x;
48 Question: Why y? False True int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; y := 0; z := y + x;
49 y, dead or alive? False True False True int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; y := 0; z := y + x; z := y + x; y := 0;
50 x, dead or alive? False True False True int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; y := 0; z := y + x; z := y + x; y := 0;
51 Another Example B1 B1 t 1 := 4 * i t 2 := a [ t 1 ] if t 2 <= 20 goto B 3 B2 B3 B4 B2 t 3 := 4 * i t 4 := b [ t 3 ] goto B4 False B3 True t 5 := t 2 * t 4 t 6 := prod + t 5 prod := t 6 goto B 4 B4 t 7 := i + 1 i := t 2 Goto B 5
52 Creating Basic Blocks Input: A sequence of three-address statements Output: A list of basic blocks with each three-address statement in exactly one block Method Determine the set of leaders (first statement of a block) The first statement is a leader Any statement that is the target of a jump is a leader Any statement that immediately follows a jump is a leader For each leader, its basic block consists of the leader and all statements up to but not including the next leader or the end of the program
53 example IR CFG source 1) i = 1 2) j =1 3) t1 = 10*I B 1 B 2 i = 1 j = 1 for i from 1 to 10 do for j from 1 to 10 do a[i, j] = 0.0; for i from 1 to 10 do a[i, i] = 1.0; 4) t2 = t1 + j 5) t3 = 8*t2 6) t4 = t3-88 7) a[t4] = 0.0 8) j = j + 1 9) if j <= 10 goto (3) 10) i=i+1 11) if i <= 10 goto (2) 12) i=1 13) t5=i-1 14) t6=88*t5 B 3 B 4 B 5 t1 = 10*I t2 = t1 + j t3 = 8*t2 t4 = t3-88 a[t4] = 0.0 j = j + 1 if j <= 10 goto B3 i=i+1 if i <= 10 goto B2 i = 1 15) a[t6]=1.0 16) i=i+1 17) if I <=10 goto (13) B 6 t5=i-1 t6=88*t5 a[t6]=1.0 i=i+1 if I <=10 goto B6
54 Example: Code Block { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n;
55 Example: Basic Block { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n;
56 { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n; AST of the Example
57 Optimized Code (gcc) { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n;
58 Register Allocation for B.B. Dependency graphs for basic blocks Transformations on dependency graphs From dependency graphs into code Instruction selection linearizations of dependency graphs Register allocation At the basic block level
59 Dependency graphs TAC imposes an order of execution But the compiler can reorder assignments as long as the program results are not changed Define a partial order on assignments a < b Û a must be executed before b Represented as a directed graph Nodes are assignments Edges represent dependency Acyclic for basic blocks
60 Running Example { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n;
61 Sources of dependency Data flow inside expressions Operator depends on operands Assignment depends on assigned expressions Data flow between statements From assignments to their use Pointers complicate dependencies
62 Sources of dependency Order of subexpresion evaluation is immaterial As long as inside dependencies are respected The order of uses of a variable X are immaterial as long as: X is used between dependent assignments Before next assignment to X
63 Creating Dependency Graph from AST Nodes AST becomes nodes of the graph Replaces arcs of AST by dependency arrows Operator Operand Create arcs from assignments to uses Create arcs between assignments of the same variable Select output variables (roots) Remove ; nodes and their arrows
64 Running Example
65 Dependency Graph Simplifications Short-circuit assignments Connect variables to assigned expressions Connect expression to uses Eliminate nodes not reachable from roots
66 Running Example
67 Cleaned-Up Data Dependency Graph
68 Common Subexpressions Repeated subexpressions Examples x = a * a + 2 * a * b + b * b; y = a * a 2 * a * b + b * b; n[i] := n[i] +m[i] Can be eliminated by the compiler In the case of basic blocks rewrite the DAG
69 From Dependency Graph into Code Linearize the dependency graph Instructions must follow dependency Many solutions exist Select the one with small runtime cost Assume infinite number of registers Symbolic registers Assign registers later May need additional spill Possible Heuristics Late evaluation Ladders
70 Pseudo Register Target Code
71 Non optimized vs Optimized Code { } int n; n := a + 1; x := b + n * n + c; n := n + 1; y := d * n;
72 Register Allocation Maps symbolic registers into physical registers Reuse registers as much as possible Graph coloring (next) Undirected graph Nodes = Registers (Symbolic and real) Edges = Interference May require spilling
73 Register Allocation for Basic Blocks Heuristics for code generation of basic blocks Works well in practice Fits modern machine architecture Can be extended to perform other tasks Common subexpression elimination But basic blocks are small Can be generalized to a procedure
74
75 Register Allocation Machine-agnostic optimizations Assume unbounded number of registers Expression trees Basic blocks Machine-dependent optimization K registers Some have special purposes Control flow graphs (global register allocation)
76 Register Allocation: Assembly Source code (program) Lexical Analysis Syntax Analysis Parsing AST Symbol Table etc. Inter. Rep. (IR) Code Generation Target code (executable) 76
77 Register Allocation: Assembly Source code (program) Lexical Analysis Syntax Analysis Parsing AST Symbol Table etc. Inter. Rep. (IR) Code Generation Target code (executable) AST + Sym. Tab. IR Optimized IR Assembly Assembly IR (TAC) generation IR Optimization Instruction selection Global register allocation 77
78 Register Allocation: Assembly Source code (program) Lexical Analysis Syntax Analysis Parsing AST Symbol Table etc. Inter. Rep. (IR) Code Generation Target code (executable) IR (TAC) generation IR Optimization Instruction selection Global register allocation Modern compiler implementation in C Andrew A. Appel AST + Sym. Tab. IR Optimized IR Assembly Assembly 78
79 Input: Global Register Allocation Sequence of machine instructions ( assembly ) Unbounded number of temporary variables aka symbolic registers machine description Output # of registers, restrictions Sequence of machine instructions using machine registers (assembly) Some MOV instructions removed
80 Variable Liveness A statement x = y + z defines x uses y and z A variable x is live at a program point if its value (at this point) is used at a later point y = 42 z = 73 x = y + z print(x); x undef, y live, z undef x undef, y live, z live x is live, y dead, z dead x is dead, y dead, z dead (showing state after the statement)
81 Computing Liveness Information between basic blocks dataflow analysis (previous lecture) within a single basic block? idea use symbol table to record next-use information scan basic block backwards update next-use for each variable
82 Computing Liveness Information INPUT: A basic block B of three-address statements. symbol table initially shows all non-temporary variables in B as being live on exit. OUTPUT: At each statement i: x = y + z in B, liveness and next-use information of x, y, and z at i. Start at the last statement in B and scan backwards At each statement i: x = y + z in B, we do the following: 1. Attach to i the information currently found in the symbol table regarding the next use and liveness of x, y, and z. 2. In the symbol table, set x to "not live" and "no next use. 3. In the symbol table, set y and z to "live" and the next uses of y and z to i
83 Computing Liveness Information Start at the last statement in B and scan backwards At each statement i: x = y + z in B, we do the following: 1. Attach to i the information currently found in the symbol table regarding the next use and liveness of x, y, and z. 2. In the symbol table, set x to "not live" and "no next use. 3. In the symbol table, set y and z to "live" and the next uses of y and z to i x = 1 y = x + 3 z = x * 3 x = x * z can we change the order between 2 and 3?
84 simple code generation translate each TAC instruction separately For each register, a register descriptor records the variable names whose current value is in that register we use only those registers that are available for local use within a basic block, we assume that initially, all register descriptors are empty As code generation progresses, each register will hold the value of zero or more names For each program variable, an address descriptor records the location(s) where the current value of the variable can be found The location may be a register, a memory address, a stack location, or some set of more than one of these Information can be stored in the symbol-table entry for that variable
85 simple code generation For each three-address statement x := y op z, 1. Invoke getreg (x := y op z) to select registers R x, R y, and R z 2. If Ry does not contain y, issue: LD R y,y for a location y of y 3. If Rz does not contain z, issue: LD R z,z for a location z of z 4. Issue the instruction OP R x,r y,r z 5. Update the address descriptors of x, y, z, if necessary R x is the only location of x now, and R x contains only x (remove R x from other address descriptors) The function getreg is not defined yet, for now think of it as an oracle that gives us 3 registers for an instruction
86 Find a register allocation variable a b c register??? register eax ebx b = a + 2 c = b * b b = c + 1 return b * a
87 Is this a valid allocation? variable register register a b c b = a + 2 eax ebx eax eax ebx ebx = eax + 2 Overwrites previous value of a also stored in eax c = b * b eax = ebx * ebx b = c + 1 ebx = eax + 1 return b * a return ebx * eax
88 Is this a valid allocation? variable a b c register eax ebx eax register eax ebx b = a + 2 c = b * b b = c + 1 return b * a ebx = eax + 2 eax = ebx * ebx ebx = eax + 1 return ebx * eax Value of c stored in eax is not needed anymore so reuse it for b
89 Main idea For every node n in CFG, we have out[n] Set of temporaries live out of n Two variables interfere if they appear in the same out[n] of any node n Cannot be allocated to the same register Conversely, if two variables do not interfere with each other, they can be assigned the same register We say they have disjoint live ranges How to assign registers to variables?
90 Interference graph Nodes of the graph = variables Edges connect variables that interfere with one another Nodes will be assigned a color corresponding to the register assigned to the variable Two colors can t be next to one another in the graph
91 Interference graph construction b = a + 2 c = b * b b = c + 1 return b * a
92 Interference graph construction b = a + 2 c = b * b b = c + 1 return b * a {b, a}
93 Interference graph construction b = a + 2 c = b * b b = c + 1 return b * a {a, c} {b, a}
94 Interference graph construction b = a + 2 c = b * b b = c + 1 return b * a {b, a} {a, c} {b, a}
95 Interference graph construction b = a + 2 c = b * b b = c + 1 return b * a {a} {b, a} {a, c} {b, a}
96 Interference graph color register b = a + 2 c = b * b b = c + 1 return b * a {a} {b, a} {a, c} {b, a} a eax ebx b c
97 Colored graph color register b = a + 2 c = b * b b = c + 1 return b * a {a} {b, a} {a, c} {b, a} a eax ebx b c
98 Graph coloring This problem is equivalent to graphcoloring, which is NP-hard if there are at least three registers No good polynomial-time algorithms (or even good approximations!) are known for this problem We have to be content with a heuristic that is good enough for RIGs that arise in practice
99 Coloring by simplification [Kempe 1879] How to find a k-coloring of a graph Intuition: Suppose we are trying to k-color a graph and find a node with fewer than k edges If we delete this node from the graph and color what remains, we can find a color for this node if we add it back in Reason: fewer than k neighbors d some color must be left over
![Coloring by simplification [Kempe 1879] How to find a k-coloring of a graph Phase 1: Simplification](/docs-images/89/99262653/images/100-0.jpg "Repeatedly simplify graph When a variable (i.e., graph node) is removed, push it on a stack Phase 2:")

100 Coloring by simplification [Kempe 1879] How to find a k-coloring of a graph Phase 1: Simplification Repeatedly simplify graph When a variable (i.e., graph node) is removed, push it on a stack Phase 2: Coloring Unwind stack and reconstruct the graph as follows: Pop variable from the stack Add it back to the graph Color the node for that variable with a color that it doesn t interfere with simplify color
101 color register eax ebx Coloring k=2 a b c stack: d e
102 color register eax ebx Coloring k=2 a b c stack: d e c
103 color register eax ebx Coloring k=2 a b c stack: d e e c
104 color register eax ebx Coloring k=2 a d b e c stack: a e c
105 color register eax ebx Coloring k=2 a d b e c stack: b a e c
106 color register eax ebx Coloring k=2 a d b e c stack: d b a e c
107 color register eax ebx Coloring k=2 a d b e c stack: b a e c
108 color register eax ebx Coloring k=2 a b c stack: d e a e c
109 color register eax ebx Coloring k=2 a b c stack: d e e c
110 color register eax ebx Coloring k=2 a b c stack: d e c
111 color register eax ebx Coloring k=2 a b c stack: d e
112 Failure of heuristic If the graph cannot be colored, it will eventually be simplified to graph in which every node has at least K neighbors Sometimes, the graph is still K-colorable! Finding a K-coloring in all situations is an NP-complete problem We will have to approximate to make register allocators fast enough
113 color register eax ebx Coloring k=2 a b c stack: d e
114 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a d b e c stack: c b e a d
115 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a d b e c stack: b e a d
116 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a d b e c stack: e a d
117 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a d b e c stack: e a d no colors left for e!
118 Chaitin s algorithm Choose and remove an arbitrary node, marking it troublesome Use heuristics to choose which one When adding node back in, it may be possible to find a valid color Otherwise, we have to spill that node
119 Spilling Phase 3: spilling once all nodes have K or more neighbors, pick a node for spilling There are many heuristics that can be used to pick a node Try to pick node not used much, not in inner loop Storage in activation record Remove it from graph We can now repeat phases 1-2 without this node Better approach rewrite code to spill variable, recompute liveness information and try to color again
120 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a d b e c stack: e a d no colors left for e!
121 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a d b e c stack: b e a d
122 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a d b e c stack: e a d
123 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a b c stack: a d d e
124 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a b c stack: d d e
125 color register eax ebx Coloring k=2 Some graphs can t be colored in K colors: a b c stack: d e
126 Handling precolored nodes Some variables are pre-assigned to registers Eg: mul on x86/pentium uses eax; defines eax, edx Eg: call on x86/pentium Defines (trashes) caller-save registers eax, ecx, edx To properly allocate registers, treat these register uses as special temporary variables and enter into interference graph as precolored nodes
127 Handling precolored nodes Simplify. Never remove a pre-colored node it already has a color, i.e., it is a given register Coloring. Once simplified graph is all colored nodes, add other nodes back in and color them using precolored nodes as starting point
128 Optimizing move instructions Code generation produces a lot of extra mov instructions mov t5, t9 If we can assign t5 and t9 to same register, we can get rid of the mov effectively, copy elimination at the register allocation level Idea: if t5 and t9 are not connected in inference graph, coalesce them into a single variable; the move will be redundant Problem: coalescing nodes can make a graph un-colorable Conservative coalescing heuristic
129 Global Register Allocation Input: Sequence of machine code instructions (assembly) Output Unbounded number of temporary registers Sequence of machine code instructions (assembly) Machine registers Some MOVE instructions removed Missing prologue and epilogue
130 Basic Compiler Phases Source program (string) lexical analysis Tokens syntax analysis Abstract syntax tree semantic analysis Translate Frame Intermediate representation Instruction selection Assembly Global Register Allocation Fin. Assembly
131 Graph Coloring by Simplification Build: Construct the interference graph Simplify: Recursively remove nodes with less than K neighbors ; Push removed nodes into stack Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
132 Artificial Example K=2 t2 t6 t1 t5 t7 t3 t8 t4
133 Coalescing MOVs can be removed if the source and the target share the same register The source and the target of the move can be merged into a single node (unifying the sets of neighbors) May require more registers Conservative Coalescing Merge nodes only if the resulting node has fewer than K neighbors with degree ë K (in the resulting graph)
134 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y /* X, Y, Z */ X Y Y Z Z Constrained MOVs are not coalesced
135 Graph Coloring with Coalescing Build: Construct the interference graph Simplify: Recursively remove non MOVE nodes with less than K neighbors; Push removed nodes into stack Coalesce: Conservatively merge unconstrained MOV related nodes with fewer than K heavy neighbors Freeze: Give-Up Coalescing on some low-degree MOV related nodes Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
136 Pre-Colored Nodes Some registers in the intermediate language are pre-colored: correspond to real registers (stack-pointer, frame-pointer, parameters, ) Cannot be Simplified, Coalesced, or Spilled (infinite degree) Interfered with each other But normal temporaries can be coalesced into precolored registers Register allocation is completed when all the nodes are pre-colored
137 Graph Coloring with Coalescing Build: Construct the interference graph Simplify: Recursively remove non MOVE nodes with less than K neighbors; Push removed nodes into stack Coalesce: Conservatively merge unconstrained MOV related nodes with fewer that K heavy neighbors Freeze: Give-Up Coalescing on some low-degree MOV related nodes Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
138 Optimizing MOV instructions Code generation produces a lot of extra mov instructions mov t5, t9 If we can assign t5 and t9 to same register, we can get rid of the mov effectively, copy elimination at the register allocation level Idea: if t5 and t9 are not connected in inference graph, coalesce them into a single variable; the move will be redundant Problem: coalescing nodes can make a graph un-colorable Conservative coalescing heuristic
139 Coalescing MOVs can be removed if the source and the target share the same register The source and the target of the move can be merged into a single node (unifying the sets of neighbors) May require more registers Conservative Coalescing Merge nodes only if the resulting node has fewer than K neighbors with degree ë K (in the resulting graph)
140 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y Y Z X Y Z Constrained MOVs are not coalesced
141 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y X,Y Y Z Z Constrained MOVs are not coalesced
142 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y X,Y Y Z Z Constrained MOVs are not coalesced
143 Graph Coloring with Coalescing Build: Construct the interference graph Simplify: Recursively remove non-mov nodes with less than K neighbors; Push removed nodes into stack Coalesce: Conservatively merge unconstrained MOV related nodes with fewer than K heavy neighbors Freeze: Give-Up Coalescing on some MOV related nodes with low degree of interference edges Special case: merged node has less than k neighbors All non-mov related nodes are heavy Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
144 Pre-Colored Nodes Some registers in the intermediate language are precolored: correspond to real registers (stack-pointer, frame-pointer, parameters, ) Cannot be Simplified, Coalesced, or Spilled infinite degree Interfered with each other But normal temporaries can be coalesced into pre-colored registers Register allocation is completed when all the nodes are pre-colored
145 Caller-Save and Callee-Save Registers callee-save-registers (MIPS 16-23) Saved by the callee when modified Values are automatically preserved across calls caller-save-registers Saved by the caller when needed Values are not automatically preserved Usually the architecture defines caller-save and calleesave registers Separate compilation Interoperability between code produced by different compilers/languages But compilers can decide when to use caller/callee registers
146 Caller-Save vs. Callee-Save Registers int foo(int a) { int b=a+1; f1(); g1(b); return(b+2); } void bar (int y) { int x=y+1; f2(y); g2(2); }
147 Saving Callee-Save Registers enter: def(r 7 ) enter: def(r 7 ) t 231 r 7 exit: use(r 7 ) r 7 t 231 exit: use(r 7 )
148 A Complete Example Callee-saved registers Caller-saved registers
149 A Complete Example
150 A Complete Example Spill c c a & e Deg. of r1,ae,d < K c r2 & b (Alt: ae+r1) c
151 A Complete Example ae & r1 (Alt: ) c pop c freeze r 1 ae-d Simplify d (Alt: ae+r1) pop d dc c d
152 A Complete Example c1&r3, c2 &r3 a&e, b&r2
153 A Complete Example ae & r1 Simplify d Pop d d opt gen code
154 Interprocedural Allocation Allocate registers to multiple procedures Potential saving caller/callee save registers Parameter passing Return values But may increase compilation cost Function inline can help
155 Summary Two Register Allocation Methods Local of every IR tree Simultaneous instruction selection and register allocation Optimal (under certain conditions) Global of every function Missing Applied after instruction selection Performs well for machines with many registers Can handle instruction level parallelism Interprocedural allocation
156 The End
157 global register allocation idea: compute weight for each variable for each use of v in B prior to any definition of v add 1 point for each occurrence of v in a following block using v add 2 points, as we save the store/load between blocks cost(v) = S B use(v,b) + 2*live(v,B) use(v,b) is is the number of times v is used in B prior to any definition of v live(v, B) is 1 if v is live on exit from B and is assigned a value in B after computing weights, allocate registers to the heaviest values
158 Two Phase Solution Dynamic Programming Sethi & Ullman Bottom-up (labeling) Compute for every subtree The minimal number of registers needed (weight) Top-Down Generate the code using labeling by preferring heavier subtrees (larger labeling)
159 Global Register Allocation Input: Sequence of machine code instructions (assembly) Output Unbounded number of temporary registers Sequence of machine code instructions (assembly) Machine registers Some MOVE instructions removed Missing prologue and epilogue
160 Basic Compiler Phases Source program (string) lexical analysis Tokens syntax analysis Abstract syntax tree semantic analysis Translate Frame Intermediate representation Instruction selection Assembly Global Register Allocation Fin. Assembly
161 {$0, t128} l3: beq t128, use $0, l0 {t128, $0} def {} l1: or t131, $0, t128 addi t132, t128, -1 or $4, $0, t132 {$0, t128} jal nfactor use {$0} def {t129} or t130, $0, $2 or t133, $0, t131 {$0, t129} mult t133, t130 mflo t133 or t129, $0, t133 l2: or t103, $0, t129 b lend l0: addi t129, $0, 1 b l2 {$0, $2} use {} def {} {$0, t129} use {t103} def {$2} use {t128, $0} def {t131} {$0, t131, t128} use {t128} def {t132} {$0, t131, t132} use {$0, t132} def {$4} {$0, t131, $4} use {$4} def {$2} {$0, t131, $2} use {$0, $2} def {t130} {$0, t130, t131} use {$0, t131} def {t133} {$0, t133, t130} use {t133, t130} def {t133} {$0, t133} use {t133} def {t133} {$0, t133} use {$0, t133} def {t129} {$0, t129} use {$0, t129} def {t103} {$0, t103} use {} def {} {$0, t103}
162 l3: beq t128, $0, l0 /* $0, t128 */ l1: or t131, $0, t128 /* $0, t128, t131 */ addi t132, t128, -1 /* $0, t131, t132 */ or $4, $0, t132 /* $0, $4, t131 */ jal nfactor /* $0, $2, t131 */ or t130, $0, $2 /* $0, t130, t131 */ or t133, $0, t131 /* $0, t130, t133 */ mult t133, t130 /* $0, t133 */ mflo t133 /* $0, t133 */ or t129, $0, t133 /* $0, t129 */ l2: or t103, $0, t129 /* $0, t103 */ b lend /* $0, t103 */ l0: addi t129, $0, 1 /* $0, t129 */ b l2 /* $0, t129 */ t132 t130 t131 t128 t129 $0 $2 t103 t133 $4
163 t132 t130 t131 t128 t129 $0 $2 t103 t133 $4 l3: beq t128, $0, l0 l1: or t131, $0, t128 addi t132, t128, -1 or $4, $0, t132 jal nfactor or t130, $0, $2 or t133, $0, t131 mult t133, t130 mflo t133 or t129, $0, t133 l2: or t103, $0, t129 b lend l0: addi t129, $0, 1 b l2
164 Global Register Allocation Process Repeat Construct the interference graph Color graph nodes with machine registers Adjacent nodes are not colored by the same register Spill a temporary into memory Until no more spill
165 Constructing interference graphs (take 1) Compute liveness information at every statement Variables a and b interfere when there exists a control flow node n such that a, b Î Lv[n]
166 A Simple Example /* c */ L0: a := 0 /* ac */ L1: b := a + 1 /* bc */ c := c + b /* bc */ a := b * 2 /* ac */ if c < N goto L1 /* c */ return c a :=0 b := a +1 c := c +b a := b * 2 c ac bc bc c < N a c b ac c ³ N c
167 Constructing interference graphs (take 2) Compute liveness information at every statement Variables a and b interfere when there exists a control flow edge (m, n) with an assignment a := exp and b Î Lv[n]
168 Constructing interference graphs (take 3) Compute liveness information at every statement Variables a and b interfere when there exists a control flow edge (m, n) with an assignment a := exp and b Î Lv[n] and b ¹ exp
169 l3: beq t128, $0, l0 /* $0, t128 */ l1: or t131, $0, t128 /* $0, t128, t131 */ addi t132, t128, -1 /* $0, t131, t132 */ or $4, $0, t132 /* $0, $4, t131 */ jal nfactor /* $0, $2, t131 */ or t130, $0, $2 /* $0, t130, t131 */ or t133, $0, t131 /* $0, t130, t133 */ mult t133, t130 /* $0, t133 */ mflo t133 /* $0, t133 */ or t129, $0, t133 /* $0, t129 */ l2: or t103, $0, t129 /* $0, t103 */ b lend /* $0, t103 */ l0: addi t129, $0, 1 /* $0, t129 */ b l2 /* $0, t129 */ t132 t130 t131 t128 t129 $0 $2 t103 t133 $4
170 Challenges The Coloring problem is computationally hard The number of machine registers may be small Avoid too many MOVEs Handle pre-colored nodes
171 Assume: Theorem [Kempe 1879] An undirected graph G(V, E) A node v ÎV with less than K neighbors G {v} is K colorable Then, G is K colorable
172 K Coloring by Simplification [Kempe 1879] the number of machine registers G(V, E) the interference graph Consider a node v ÎV with less than K neighbors: Color G v in K colors Color v in a color different than its (colored) neighbors
173 Graph Coloring by Simplification Build: Construct the interference graph Simplify: Recursively remove nodes with less than K neighbors ; Push removed nodes into stack Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
174 Artificial Example K=2 t2 t6 t1 t5 t7 t3 t8 t4
175 Coalescing MOVs can be removed if the source and the target share the same register The source and the target of the move can be merged into a single node (unifying the sets of neighbors) May require more registers Conservative Coalescing Merge nodes only if the resulting node has fewer than K neighbors with degree ë K (in the resulting graph)
176 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y /* X, Y, Z */ X Y Y Z Z Constrained MOVs are not coalesced
177 Graph Coloring with Coalescing Build: Construct the interference graph Simplify: Recursively remove non MOVE nodes with less than K neighbors; Push removed nodes into stack Coalesce: Conservatively merge unconstrained MOV related nodes with fewer than K heavy neighbors Freeze: Give-Up Coalescing on some low-degree MOV related nodes Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
178 Spilling Many heuristics exist Maximal degree Live-ranges Number of uses in loops The whole process need to be repeated after an actual spill
179 Pre-Colored Nodes Some registers in the intermediate language are pre-colored: correspond to real registers (stack-pointer, frame-pointer, parameters, ) Cannot be Simplified, Coalesced, or Spilled (infinite degree) Interfered with each other But normal temporaries can be coalesced into precolored registers Register allocation is completed when all the nodes are pre-colored
180 Caller-Save and Callee-Save Registers callee-save-registers (MIPS 16-23) Saved by the callee when modified Values are automatically preserved across calls caller-save-registers Saved by the caller when needed Values are not automatically preserved Usually the architecture defines caller-save and callee-save registers Separate compilation Interoperability between code produced by different compilers/languages But compilers can decide when to use calller/callee registers
181 Caller-Save vs. Callee-Save Registers int foo(int a) { int b=a+1; f1(); g1(b); return(b+2); } void bar (int y) { int x=y+1; f2(y); g2(2); }
182 Saving Callee-Save Registers enter: def(r 7 ) enter: def(r 7 ) t 231 r 7 exit: use(r 7 ) r 7 t 231 exit: use(r 7 )
183 A Complete Example enter: c := r1, r3 r2 caller save r3 callee-save a := r1 b := r2 d := 0 e := a loop: d := d+b e := e-1 if e>0 goto loop r1 := d r3 := c return /* r1,r3 */
184 Graph Coloring with Coalescing Build: Construct the interference graph Simplify: Recursively remove non MOVE nodes with less than K neighbors; Push removed nodes into stack Coalesce: Conservatively merge unconstrained MOV related nodes with fewer that K heavy neighbors Freeze: Give-Up Coalescing on some low-degree MOV related nodes Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
185 A Complete Example enter: c := r1, r3 r2 caller save r3 callee-save a := r1 b := r2 d := 0 e := a loop: d := d+b e := e-1 if e>0 goto loop r1 := d r3 := c return /* r1,r3 */ use{r3} def{c} use{r1} def{a} use{r2} def{b} use{} def{d} use{a} def{e} use{d, b} def{d} {c, d, e} use{e} def{e} {c, d, e} use{e} def{} {c, d} use{d} def{r1} {r1, c} {r1, r3} use{c} def{r3}
186 enter: c := r3 a := r1 b := r2 d := 0 e := a loop: d := d+b e := e-1 if e>0 goto loop r1 := d r3 := c return /* r1,r3 */ A Complete Example use{r3} def{c} use{r1} def{a} use{r2} def{b} use{} def{d} use{a} def{e} {c, d, e, b} use{d, b} def{d} {c, d, e} use{e} def{e} {c, d, e} use{e} def{} {c, d, e, b} use{d} def{r1} {r1, c} {r1, r3} use{c} def{r3}
187 enter: c := r3 a := r1 b := r2 d := 0 e := a loop: d := d+b e := e-1 if e>0 goto loop r1 := d r3 := c return /* r1,r3 */ A Complete Example use{r3} def{c} use{r1} def{a} use{r2} def{b} use{} def{d} use{a} def{e} {c, d, e, b} use{d, b} def{d} {c, d, e} use{e} def{e} {c, d, e, b} use{e} def{} {c, d, e, b} use{d} def{r1} {r1, c} {r1, r3} use{c} def{r3}
188 enter: c := r3 a := r1 b := r2 d := 0 e := a loop: d := d+b e := e-1 if e>0 goto loop r1 := d r3 := c return /* r1,r3 */ A Complete Example { r2, r1, r3} use{r3} def{c} {c, r2, r1} use{r1} def{a} {c, a, r2} use{r2} def{b} {c, b, a} use{} def{d} {c, d, b, a} use{a} def{e} {c, d, e, b} use{d, b} def{d} {c, d, e, b} use{e} def{e} {c, d, e, b} use{e} def{} {c, d, e, b} use{d} def{r1} {r1, c} {r1, r3} use{c} def{r3}
189 Live Variables Results enter: c := r3 a := r1 b := r2 d := 0 e := a loop: d := d+b e := e-1 if e>0 goto loop r1 := d r3 := c return /* r1,r3 */ enter: /* r2, r1, r3 */ c := r3 /* c, r2, r1 */ a := r1 /* a, c, r2 */ b := r2 /* a, c, b */ d := 0 /* a, c, b, d */ e := a /* e, c, b, d */ loop: d := d+b /* e, c, b, d */ e := e-1 /* e, c, b, d */ if e>0 goto loop /* c, d */ r1 := d /* r1, c */ r3 := c /* r1, r3 */ return /* r1, r3 */
190 enter: /* r2, r1, r3 */ c := r3 /* c, r2, r1 */ a := r1 /* a, c, r2 */ b := r2 /* a, c, b */ d := 0 /* a, c, b, d */ e := a /* e, c, b, d */ loop: d := d+b /* e, c, b, d */ e := e-1 /* e, c, b, d */ if e>0 goto loop /* c, d */ r1 := d /* r1, c */ r3 := c /* r1, r3 */ return /* r1,r3 */
191 spill priority = (uo + 10 ui)/deg enter: /* r2, r1, r3 */ c := r3 /* c, r2, r1 */ a := r1 /* a, c, r2 */ b := r2 /* a, c, b */ d := 0 /* a, c, b, d */ e := a / * e, c, b, d */ loop: d := d+b /* e, c, b, d */ e := e-1 /* e, c, b, d */ if e>0 goto loop /* c, d */ r1 := d /* r1, c */ r3 := c /* r1, r3 */ return /* r1,r3 */ use+ def outside loop use+ def within loop deg spill priority a b c d e
192 Optimizing MOV instructions Code generation produces a lot of extra mov instructions mov t5, t9 If we can assign t5 and t9 to same register, we can get rid of the mov effectively, copy elimination at the register allocation level Idea: if t5 and t9 are not connected in inference graph, coalesce them into a single variable; the move will be redundant Problem: coalescing nodes can make a graph un-colorable Conservative coalescing heuristic
193 Coalescing MOVs can be removed if the source and the target share the same register The source and the target of the move can be merged into a single node (unifying the sets of neighbors) May require more registers Conservative Coalescing Merge nodes only if the resulting node has fewer than K neighbors with degree ë K (in the resulting graph)
194 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y Y Z X Y Z Constrained MOVs are not coalesced
195 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y X,Y Y Z Z Constrained MOVs are not coalesced
196 Constrained Moves A instruction T S is constrained if S and T interfere May happen after coalescing X Y X,Y Y Z Z Constrained MOVs are not coalesced
197 Graph Coloring with Coalescing Build: Construct the interference graph Simplify: Recursively remove non-mov nodes with less than K neighbors; Push removed nodes into stack Coalesce: Conservatively merge unconstrained MOV related nodes with fewer than K heavy neighbors Freeze: Give-Up Coalescing on some MOV related nodes with low degree of interference edges Special case: merged node has less than k neighbors All non-mov related nodes are heavy Potential-Spill: Spill some nodes and remove nodes Push removed nodes into stack Select: Assign actual registers (from simplify/spill stack) Actual-Spill: Spill some potential spills and repeat the process
198 Spilling Many heuristics exist Maximal degree Live-ranges Number of uses in loops The whole process need to be repeated after an actual spill
199 Pre-Colored Nodes Some registers in the intermediate language are precolored: correspond to real registers (stack-pointer, frame-pointer, parameters, ) Cannot be Simplified, Coalesced, or Spilled infinite degree Interfered with each other But normal temporaries can be coalesced into pre-colored registers Register allocation is completed when all the nodes are pre-colored
200 Caller-Save and Callee-Save Registers callee-save-registers (MIPS 16-23) Saved by the callee when modified Values are automatically preserved across calls caller-save-registers Saved by the caller when needed Values are not automatically preserved Usually the architecture defines caller-save and calleesave registers Separate compilation Interoperability between code produced by different compilers/languages But compilers can decide when to use caller/callee registers
201 Caller-Save vs. Callee-Save Registers int foo(int a) { int b=a+1; f1(); g1(b); return(b+2); } void bar (int y) { int x=y+1; f2(y); g2(2); }
202 Saving Callee-Save Registers enter: def(r 7 ) enter: def(r 7 ) t 231 r 7 exit: use(r 7 ) r 7 t 231 exit: use(r 7 )

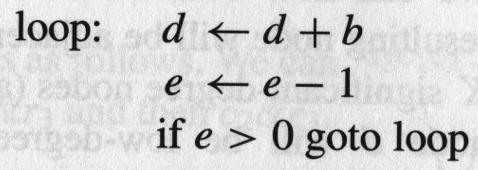
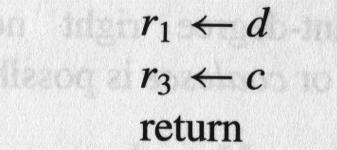
203 A Complete Example Callee-saved registers Caller-saved registers

204 A Complete Example

 c")
205 A Complete Example Spill c c a & e Deg. of r1,ae,d < K c r2 & b (Alt: ae+r1) c
 c pop c")
")
206 A Complete Example ae & r1 (Alt: ) c pop c freeze r 1 ae-d Simplify d (Alt: ae+r1) pop d dc c d



207 A Complete Example c1&r3, c2 &r3 a&e, b&r2


208 A Complete Example ae & r1 Simplify d Pop d d opt gen code
209 Interprocedural Allocation Allocate registers to multiple procedures Potential saving caller/callee save registers Parameter passing Return values But may increase compilation cost Function inline can help
210 Summary Two Register Allocation Methods Local of every IR tree Simultaneous instruction selection and register allocation Optimal (under certain conditions) Global of every function Missing Applied after instruction selection Performs well for machines with many registers Can handle instruction level parallelism Interprocedural allocation
211 The End
212 Spill C stack stack c
213 Coalescing a+e stack c stack c
214 Coalescing b+r2 stack c stack c
215 Coalescing ae+r1 stack c stack c r1ae and d are constrained
216 Simplifying d stack c stack d c
217 Pop d stack d c stack c d is assigned to r3
218 Pop c stack c c stack actual spill!
219 enter: /* r2, r1, r3 */ c := r3 /* c, r2, r1 */ a := r1 /* a, c, r2 */ b := r2 /* a, c, b */ d := 0 /* a, c, b, d */ e := a / * e, c, b, d */ loop: d := d+b /* e, c, b, d */ e := e-1 /* e, c, b, d */ if e>0 goto loop /* c, d */ r1 := d /* r1, c */ r3 := c /* r1, r3 */ return /* r1,r3 */ enter: /* r2, r1, r3 */ c1 := r3 /* c1, r2, r1 */ M[c_loc] := c1 /* r2 */ a := r1 /* a, r2 */ b := r2 /* a, b */ d := 0 /* a, b, d */ e := a / * e, b, d */ loop: d := d+b /* e, b, d */ e := e-1 /* e, b, d */ if e>0 goto loop /* d */ r1 := d /* r1 */ c2 := M[c_loc] /* r1, c2 */ r3 := c2 /* r1, r3 */ return /* r1,r3 */
220 enter: /* r2, r1, r3 */ c1 := r3 /* c1, r2, r1 */ M[c_loc] := c1 /* r2 */ a := r1 /* a, r2 */ b := r2 /* a, b */ d := 0 /* a, b, d */ e := a / * e, b, d */ loop: d := d+b /* e, b, d */ e := e-1 /* e, b, d */ if e>0 goto loop /* d */ r1 := d /* r1 */ c2 := M[c_loc] /* r1, c2 */ r3 := c2 /* r1, r3 */ return /* r1,r3 */
221 Coalescing c1+r3; c2+c1r3 stack stack
222 Coalescing a+e; b+r2 stack stack
223 Coalescing ae+r1 stack stack d r1ae and d are constrained
224 Simplify d stack stack d d
225 Pop d stack stack d d a b c1 c2 d e r1 r2 r3 r3 r3 r1
226 enter: c1 := r3 M[c_loc] := c1 a := r1 b := r2 d := 0 e := a loop: d := d+b e := e-1 if e>0 goto loop r1 := d c2 := M[c_loc] r3 := c2 return /* r1,r3 */ a b c1 c2 d e r1 r2 r3 r3 r3 r1 enter: r3 := r3 M[c_loc] := r3 r1 := r1 r2 := r2 r3 := 0 r1 := r1 loop: r3 := r3+r2 r1 := r1-1 if r1>0 goto loop r1 := r3 r3 := M[c_loc] r3 := r3 return /* r1,r3 */
227 enter: r3 := r3 M[c_loc] := r3 r1 := r1 r2 := r2 r3 := 0 r1 := r1 loop: r3 := r3+r2 r1 := r1-1 if r1>0 goto loop r1 := r3 r3 := M[c_loc] r3 := r3 return /* r1,r3 */ enter: M[c_loc] := r3 r3 := 0 loop: r3 := r3+r2 r1 := r1-1 if r1>0 goto loop r1 := r3 r3 := M[c_loc] return /* r1,r3 */
228 main: addiu $sp,$sp, -K1 nfactor: addiu $sp,$sp,-k2 L4: sw $2,0+K1($sp) L6: sw $2,0+K2($sp) or $25,$0,$31 or $25,$0,$4 sw $25,-4+K1($sp) or $24,$0,$31 addiu $25,$sp,0+K1 sw $24,-4+K2($sp) or $2,$0,$25 sw $30,-8+K2($sp) addi $25,$0,10 beq $25,$0,L0 or $4,$0,$25 L1: or $30,$0,$25 jal nfactor lw $24,0+K2 lw $25,-4+K1 or $2,$0,$24 or $31,$0,$25 addi $25,$25,-1 b L3 or $4,$0,$25 L3: addiu $sp,$sp,k1 jal nfactor j $31 or $25,$0,$2 mult $30,$25 mflo $30 L2: or $2,$0,$30 lw $30,-4+K2($sp or $31,$0,$30 lw $30,-8+K2($sp b L5 L0: addi $30,$0,1 b L2 L5: addiu $sp,$sp,k2 j $31
229 Interprocedural Allocation Allocate registers to multiple procedures Potential saving caller/callee save registers Parameter passing Return values But may increase compilation cost Function inline can help
230 Summary Two Register Allocation Methods Local of every IR tree Simultaneous instruction selection and register allocation Optimal (under certain conditions) Global of every function Missing Applied after instruction selection Performs well for machines with many registers Can handle instruction level parallelism Interprocedural allocation
231
232 Challenges in register allocation Registers are scarce Often substantially more IR variables than registers Need to find a way to reuse registers whenever possible Registers are complicated x86: Each register made of several smaller registers; can't use a register and its constituent registers at the same time x86: Certain instructions must store their results in specific registers; can't store values there if you want to use those instructions MIPS: Some registers reserved for the assembler or operating system Most architectures: Some registers must be preserved across function calls
233 The End
234 The End
Fall Compiler Principles Lecture 12: Register Allocation. Roman Manevich Ben-Gurion University
 Fall 2014-2015 Compiler Principles Lecture 12: Register Allocation Roman Manevich Ben-Gurion University Syllabus Front End Intermediate Representation Optimizations Code Generation Scanning Lowering Local
Fall 2014-2015 Compiler Principles Lecture 12: Register Allocation Roman Manevich Ben-Gurion University Syllabus Front End Intermediate Representation Optimizations Code Generation Scanning Lowering Local
Compilation Lecture 11a. Register Allocation Noam Rinetzky. Text book: Modern compiler implementation in C Andrew A.
 Compilation 0368-3133 Leture 11a Text book: Modern ompiler implementation in C Andrew A. Appel Register Alloation Noam Rinetzky 1 Registers Dediated memory loations that an be aessed quikly, an have omputations
Compilation 0368-3133 Leture 11a Text book: Modern ompiler implementation in C Andrew A. Appel Register Alloation Noam Rinetzky 1 Registers Dediated memory loations that an be aessed quikly, an have omputations
Variables vs. Registers/Memory. Simple Approach. Register Allocation. Interference Graph. Register Allocation Algorithm CS412/CS413
 Variables vs. Registers/Memory CS412/CS413 Introduction to Compilers Tim Teitelbaum Lecture 33: Register Allocation 18 Apr 07 Difference between IR and assembly code: IR (and abstract assembly) manipulate
Variables vs. Registers/Memory CS412/CS413 Introduction to Compilers Tim Teitelbaum Lecture 33: Register Allocation 18 Apr 07 Difference between IR and assembly code: IR (and abstract assembly) manipulate
Register allocation. Register allocation: ffl have value in a register when used. ffl limited resources. ffl changes instruction choices
 Register allocation IR instruction selection register allocation machine code errors Register allocation: have value in a register when used limited resources changes instruction choices can move loads
Register allocation IR instruction selection register allocation machine code errors Register allocation: have value in a register when used limited resources changes instruction choices can move loads
Liveness Analysis and Register Allocation. Xiao Jia May 3 rd, 2013
 Liveness Analysis and Register Allocation Xiao Jia May 3 rd, 2013 1 Outline Control flow graph Liveness analysis Graph coloring Linear scan 2 Basic Block The code in a basic block has: one entry point,
Liveness Analysis and Register Allocation Xiao Jia May 3 rd, 2013 1 Outline Control flow graph Liveness analysis Graph coloring Linear scan 2 Basic Block The code in a basic block has: one entry point,
Liveness Analysis and Register Allocation
 Liveness Analysis and Register Allocation Leonidas Fegaras CSE 5317/4305 L10: Liveness Analysis and Register Allocation 1 Liveness Analysis So far we assumed that we have a very large number of temporary
Liveness Analysis and Register Allocation Leonidas Fegaras CSE 5317/4305 L10: Liveness Analysis and Register Allocation 1 Liveness Analysis So far we assumed that we have a very large number of temporary
Register allocation. instruction selection. machine code. register allocation. errors
 Register allocation IR instruction selection register allocation machine code errors Register allocation: have value in a register when used limited resources changes instruction choices can move loads
Register allocation IR instruction selection register allocation machine code errors Register allocation: have value in a register when used limited resources changes instruction choices can move loads
Lecture 21 CIS 341: COMPILERS
 Lecture 21 CIS 341: COMPILERS Announcements HW6: Analysis & Optimizations Alias analysis, constant propagation, dead code elimination, register allocation Available Soon Due: Wednesday, April 25 th Zdancewic
Lecture 21 CIS 341: COMPILERS Announcements HW6: Analysis & Optimizations Alias analysis, constant propagation, dead code elimination, register allocation Available Soon Due: Wednesday, April 25 th Zdancewic
Compiler Architecture
 Code Generation 1 Compiler Architecture Source language Scanner (lexical analysis) Tokens Parser (syntax analysis) Syntactic structure Semantic Analysis (IC generator) Intermediate Language Code Optimizer
Code Generation 1 Compiler Architecture Source language Scanner (lexical analysis) Tokens Parser (syntax analysis) Syntactic structure Semantic Analysis (IC generator) Intermediate Language Code Optimizer
Topic 12: Register Allocation
 Topic 12: Register Allocation COS 320 Compiling Techniques Princeton University Spring 2016 Lennart Beringer 1 Structure of backend Register allocation assigns machine registers (finite supply!) to virtual
Topic 12: Register Allocation COS 320 Compiling Techniques Princeton University Spring 2016 Lennart Beringer 1 Structure of backend Register allocation assigns machine registers (finite supply!) to virtual
Register allocation. TDT4205 Lecture 31
 1 Register allocation TDT4205 Lecture 31 2 Variables vs. registers TAC has any number of variables Assembly code has to deal with memory and registers Compiler back end must decide how to juggle the contents
1 Register allocation TDT4205 Lecture 31 2 Variables vs. registers TAC has any number of variables Assembly code has to deal with memory and registers Compiler back end must decide how to juggle the contents
Compilation /15a Lecture 7. Activation Records Noam Rinetzky
 Compilation 0368-3133 2014/15a Lecture 7 Activation Records Noam Rinetzky 1 Code generation for procedure calls (+ a few words on the runtime system) 2 Code generation for procedure calls Compile time
Compilation 0368-3133 2014/15a Lecture 7 Activation Records Noam Rinetzky 1 Code generation for procedure calls (+ a few words on the runtime system) 2 Code generation for procedure calls Compile time
Principles of Compiler Design
 Principles of Compiler Design Code Generation Compiler Lexical Analysis Syntax Analysis Semantic Analysis Source Program Token stream Abstract Syntax tree Intermediate Code Code Generation Target Program
Principles of Compiler Design Code Generation Compiler Lexical Analysis Syntax Analysis Semantic Analysis Source Program Token stream Abstract Syntax tree Intermediate Code Code Generation Target Program
CODE GENERATION Monday, May 31, 2010
 CODE GENERATION memory management returned value actual parameters commonly placed in registers (when possible) optional control link optional access link saved machine status local data temporaries A.R.
CODE GENERATION memory management returned value actual parameters commonly placed in registers (when possible) optional control link optional access link saved machine status local data temporaries A.R.
Winter Compiler Construction T10 IR part 3 + Activation records. Today. LIR language
 Winter 2006-2007 Compiler Construction T10 IR part 3 + Activation records Mooly Sagiv and Roman Manevich School of Computer Science Tel-Aviv University Today ic IC Language Lexical Analysis Syntax Analysis
Winter 2006-2007 Compiler Construction T10 IR part 3 + Activation records Mooly Sagiv and Roman Manevich School of Computer Science Tel-Aviv University Today ic IC Language Lexical Analysis Syntax Analysis
THEORY OF COMPILATION
 Lecture 10 Code Generation THEORY OF COMPILATION EranYahav Reference: Dragon 8. MCD 4.2.4 1 You are here Compiler txt Source Lexical Analysis Syntax Analysis Parsing Semantic Analysis Inter. Rep. (IR)
Lecture 10 Code Generation THEORY OF COMPILATION EranYahav Reference: Dragon 8. MCD 4.2.4 1 You are here Compiler txt Source Lexical Analysis Syntax Analysis Parsing Semantic Analysis Inter. Rep. (IR)
CSE P 501 Compilers. Register Allocation Hal Perkins Autumn /22/ Hal Perkins & UW CSE P-1
 CSE P 501 Compilers Register Allocation Hal Perkins Autumn 2011 11/22/2011 2002-11 Hal Perkins & UW CSE P-1 Agenda Register allocation constraints Local methods Faster compile, slower code, but good enough
CSE P 501 Compilers Register Allocation Hal Perkins Autumn 2011 11/22/2011 2002-11 Hal Perkins & UW CSE P-1 Agenda Register allocation constraints Local methods Faster compile, slower code, but good enough
Register Allocation, iii. Bringing in functions & using spilling & coalescing
 Register Allocation, iii Bringing in functions & using spilling & coalescing 1 Function Calls ;; f(x) = let y = g(x) ;; in h(y+x) + y*5 (:f (x
Register Allocation, iii Bringing in functions & using spilling & coalescing 1 Function Calls ;; f(x) = let y = g(x) ;; in h(y+x) + y*5 (:f (x
Compiler construction in4303 lecture 9
 Compiler construction in4303 lecture 9 Code generation Chapter 4.2.5, 4.2.7, 4.2.11 4.3 Overview Code generation for basic blocks instruction selection:[burs] register allocation: graph coloring instruction
Compiler construction in4303 lecture 9 Code generation Chapter 4.2.5, 4.2.7, 4.2.11 4.3 Overview Code generation for basic blocks instruction selection:[burs] register allocation: graph coloring instruction
IR Optimization. May 15th, Tuesday, May 14, 13
 IR Optimization May 15th, 2013 Tuesday, May 14, 13 But before we talk about IR optimization... Wrapping up IR generation Tuesday, May 14, 13 Three-Address Code Or TAC The IR that you will be using for
IR Optimization May 15th, 2013 Tuesday, May 14, 13 But before we talk about IR optimization... Wrapping up IR generation Tuesday, May 14, 13 Three-Address Code Or TAC The IR that you will be using for
COMP 303 Computer Architecture Lecture 3. Comp 303 Computer Architecture
 COMP 303 Computer Architecture Lecture 3 Comp 303 Computer Architecture 1 Supporting procedures in computer hardware The execution of a procedure Place parameters in a place where the procedure can access
COMP 303 Computer Architecture Lecture 3 Comp 303 Computer Architecture 1 Supporting procedures in computer hardware The execution of a procedure Place parameters in a place where the procedure can access
Compilers and Code Optimization EDOARDO FUSELLA
 Compilers and Code Optimization EDOARDO FUSELLA Contents Data memory layout Instruction selection Register allocation Data memory layout Memory Hierarchy Capacity vs access speed Main memory Classes of
Compilers and Code Optimization EDOARDO FUSELLA Contents Data memory layout Instruction selection Register allocation Data memory layout Memory Hierarchy Capacity vs access speed Main memory Classes of
Compiler Optimization Techniques
 Compiler Optimization Techniques Department of Computer Science, Faculty of ICT February 5, 2014 Introduction Code optimisations usually involve the replacement (transformation) of code from one sequence
Compiler Optimization Techniques Department of Computer Science, Faculty of ICT February 5, 2014 Introduction Code optimisations usually involve the replacement (transformation) of code from one sequence
G Compiler Construction Lecture 12: Code Generation I. Mohamed Zahran (aka Z)
") G22.2130-001 Compiler Construction Lecture 12: Code Generation I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu semantically equivalent + symbol table Requirements Preserve semantic meaning of source program
G22.2130-001 Compiler Construction Lecture 12: Code Generation I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu semantically equivalent + symbol table Requirements Preserve semantic meaning of source program
Midterm II CS164, Spring 2006
 Midterm II CS164, Spring 2006 April 11, 2006 Please read all instructions (including these) carefully. Write your name, login, SID, and circle the section time. There are 10 pages in this exam and 4 questions,
Midterm II CS164, Spring 2006 April 11, 2006 Please read all instructions (including these) carefully. Write your name, login, SID, and circle the section time. There are 10 pages in this exam and 4 questions,
CS 406/534 Compiler Construction Putting It All Together
 CS 406/534 Compiler Construction Putting It All Together Prof. Li Xu Dept. of Computer Science UMass Lowell Fall 2004 Part of the course lecture notes are based on Prof. Keith Cooper, Prof. Ken Kennedy
CS 406/534 Compiler Construction Putting It All Together Prof. Li Xu Dept. of Computer Science UMass Lowell Fall 2004 Part of the course lecture notes are based on Prof. Keith Cooper, Prof. Ken Kennedy
CA Compiler Construction
 CA4003 - Compiler Construction David Sinclair When procedure A calls procedure B, we name procedure A the caller and procedure B the callee. A Runtime Environment, also called an Activation Record, is
CA4003 - Compiler Construction David Sinclair When procedure A calls procedure B, we name procedure A the caller and procedure B the callee. A Runtime Environment, also called an Activation Record, is
Compiler Passes. Optimization. The Role of the Optimizer. Optimizations. The Optimizer (or Middle End) Traditional Three-pass Compiler
 Traditional Three-pass Compiler") Compiler Passes Analysis of input program (front-end) character stream Lexical Analysis Synthesis of output program (back-end) Intermediate Code Generation Optimization Before and after generating machine
Compiler Passes Analysis of input program (front-end) character stream Lexical Analysis Synthesis of output program (back-end) Intermediate Code Generation Optimization Before and after generating machine
Intermediate Code & Local Optimizations
 Lecture Outline Intermediate Code & Local Optimizations Intermediate code Local optimizations Compiler Design I (2011) 2 Code Generation Summary We have so far discussed Runtime organization Simple stack
Lecture Outline Intermediate Code & Local Optimizations Intermediate code Local optimizations Compiler Design I (2011) 2 Code Generation Summary We have so far discussed Runtime organization Simple stack
Code Generation. CS 540 George Mason University
 Code Generation CS 540 George Mason University Compiler Architecture Intermediate Language Intermediate Language Source language Scanner (lexical analysis) tokens Parser (syntax analysis) Syntactic structure
Code Generation CS 540 George Mason University Compiler Architecture Intermediate Language Intermediate Language Source language Scanner (lexical analysis) tokens Parser (syntax analysis) Syntactic structure
CSE P 501 Compilers. Intermediate Representations Hal Perkins Spring UW CSE P 501 Spring 2018 G-1
 CSE P 501 Compilers Intermediate Representations Hal Perkins Spring 2018 UW CSE P 501 Spring 2018 G-1 Administrivia Semantics/types/symbol table project due ~2 weeks how goes it? Should be caught up on
CSE P 501 Compilers Intermediate Representations Hal Perkins Spring 2018 UW CSE P 501 Spring 2018 G-1 Administrivia Semantics/types/symbol table project due ~2 weeks how goes it? Should be caught up on
Faculty of Electrical Engineering, Mathematics, and Computer Science Delft University of Technology
 Faculty of Electrical Engineering, Mathematics, and Computer Science Delft University of Technology exam Compiler Construction in4303 April 9, 2010 14.00-15.30 This exam (6 pages) consists of 52 True/False
Faculty of Electrical Engineering, Mathematics, and Computer Science Delft University of Technology exam Compiler Construction in4303 April 9, 2010 14.00-15.30 This exam (6 pages) consists of 52 True/False
Global Register Allocation
 Global Register Allocation Y N Srikant Computer Science and Automation Indian Institute of Science Bangalore 560012 NPTEL Course on Compiler Design Outline n Issues in Global Register Allocation n The
Global Register Allocation Y N Srikant Computer Science and Automation Indian Institute of Science Bangalore 560012 NPTEL Course on Compiler Design Outline n Issues in Global Register Allocation n The
Low-Level Issues. Register Allocation. Last lecture! Liveness analysis! Register allocation. ! More register allocation. ! Instruction scheduling
 Low-Level Issues Last lecture! Liveness analysis! Register allocation!today! More register allocation!later! Instruction scheduling CS553 Lecture Register Allocation I 1 Register Allocation!Problem! Assign
Low-Level Issues Last lecture! Liveness analysis! Register allocation!today! More register allocation!later! Instruction scheduling CS553 Lecture Register Allocation I 1 Register Allocation!Problem! Assign
Calling Conventions. Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University. See P&H 2.8 and 2.12
 Calling Conventions Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University See P&H 2.8 and 2.12 Goals for Today Calling Convention for Procedure Calls Enable code to be reused by allowing
Calling Conventions Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University See P&H 2.8 and 2.12 Goals for Today Calling Convention for Procedure Calls Enable code to be reused by allowing
Prof. Kavita Bala and Prof. Hakim Weatherspoon CS 3410, Spring 2014 Computer Science Cornell University. See P&H 2.8 and 2.12, and A.
 Prof. Kavita Bala and Prof. Hakim Weatherspoon CS 3410, Spring 2014 Computer Science Cornell University See P&H 2.8 and 2.12, and A.5 6 compute jump/branch targets memory PC +4 new pc Instruction Fetch
Prof. Kavita Bala and Prof. Hakim Weatherspoon CS 3410, Spring 2014 Computer Science Cornell University See P&H 2.8 and 2.12, and A.5 6 compute jump/branch targets memory PC +4 new pc Instruction Fetch
See P&H 2.8 and 2.12, and A.5-6. Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University
 See P&H 2.8 and 2.12, and A.5-6 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University Upcoming agenda PA1 due yesterday PA2 available and discussed during lab section this week
See P&H 2.8 and 2.12, and A.5-6 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University Upcoming agenda PA1 due yesterday PA2 available and discussed during lab section this week
CS 61c: Great Ideas in Computer Architecture
 MIPS Functions July 1, 2014 Review I RISC Design Principles Smaller is faster: 32 registers, fewer instructions Keep it simple: rigid syntax, fixed instruction length MIPS Registers: $s0-$s7,$t0-$t9, $0
MIPS Functions July 1, 2014 Review I RISC Design Principles Smaller is faster: 32 registers, fewer instructions Keep it simple: rigid syntax, fixed instruction length MIPS Registers: $s0-$s7,$t0-$t9, $0
Code Generation (#')! *+%,-,.)" !"#$%! &$' (#')! 20"3)% +"#3"0- /)$)"0%#"
! *+%,-,.) !#$%! &$' (#')! 203)% +#30- /)$)0%#") Code Generation!"#$%! &$' 1$%)"-)',0%)! (#')! (#')! *+%,-,.)" 1$%)"-)',0%)! (#')! (#')! /)$)"0%#" 20"3)% +"#3"0- Memory Management returned value actual parameters commonly placed in registers (when possible)
Code Generation!"#$%! &$' 1$%)"-)',0%)! (#')! (#')! *+%,-,.)" 1$%)"-)',0%)! (#')! (#')! /)$)"0%#" 20"3)% +"#3"0- Memory Management returned value actual parameters commonly placed in registers (when possible)
Code generation and optimization
 Code generation and timization Generating assembly How do we convert from three-address code to assembly? Seems easy! But easy solutions may not be the best tion What we will cover: Peephole timizations
Code generation and timization Generating assembly How do we convert from three-address code to assembly? Seems easy! But easy solutions may not be the best tion What we will cover: Peephole timizations
Anne Bracy CS 3410 Computer Science Cornell University
 Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. See P&H 2.8 and 2.12, and
Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. See P&H 2.8 and 2.12, and
CSE 401/M501 Compilers
 CSE 401/M501 Compilers Intermediate Representations Hal Perkins Autumn 2018 UW CSE 401/M501 Autumn 2018 G-1 Agenda Survey of Intermediate Representations Graphical Concrete/Abstract Syntax Trees (ASTs)
CSE 401/M501 Compilers Intermediate Representations Hal Perkins Autumn 2018 UW CSE 401/M501 Autumn 2018 G-1 Agenda Survey of Intermediate Representations Graphical Concrete/Abstract Syntax Trees (ASTs)
Anne Bracy CS 3410 Computer Science Cornell University
 Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. See P&H 2.8 and 2.12, and
Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. See P&H 2.8 and 2.12, and
Global Register Allocation
 Global Register Allocation Lecture Outline Memory Hierarchy Management Register Allocation via Graph Coloring Register interference graph Graph coloring heuristics Spilling Cache Management 2 The Memory
Global Register Allocation Lecture Outline Memory Hierarchy Management Register Allocation via Graph Coloring Register interference graph Graph coloring heuristics Spilling Cache Management 2 The Memory
Lecture Notes on Register Allocation
 Lecture Notes on Register Allocation 15-411: Compiler Design Frank Pfenning Lecture 3 September 1, 2009 1 Introduction In this lecture we discuss register allocation, which is one of the last steps in
Lecture Notes on Register Allocation 15-411: Compiler Design Frank Pfenning Lecture 3 September 1, 2009 1 Introduction In this lecture we discuss register allocation, which is one of the last steps in
Agenda. CSE P 501 Compilers. Big Picture. Compiler Organization. Intermediate Representations. IR for Code Generation. CSE P 501 Au05 N-1
 Agenda CSE P 501 Compilers Instruction Selection Hal Perkins Autumn 2005 Compiler back-end organization Low-level intermediate representations Trees Linear Instruction selection algorithms Tree pattern
Agenda CSE P 501 Compilers Instruction Selection Hal Perkins Autumn 2005 Compiler back-end organization Low-level intermediate representations Trees Linear Instruction selection algorithms Tree pattern
Lecture Compiler Backend
 Lecture 19-23 Compiler Backend Jianwen Zhu Electrical and Computer Engineering University of Toronto Jianwen Zhu 2009 - P. 1 Backend Tasks Instruction selection Map virtual instructions To machine instructions
Lecture 19-23 Compiler Backend Jianwen Zhu Electrical and Computer Engineering University of Toronto Jianwen Zhu 2009 - P. 1 Backend Tasks Instruction selection Map virtual instructions To machine instructions
Register Allocation & Liveness Analysis
 Department of Computer Sciences Register Allocation & Liveness Analysis CS502 Purdue University is an Equal Opportunity/Equal Access institution. Department of Computer Sciences In IR tree code generation,
Department of Computer Sciences Register Allocation & Liveness Analysis CS502 Purdue University is an Equal Opportunity/Equal Access institution. Department of Computer Sciences In IR tree code generation,
Code generation and local optimization
 Code generation and local optimization Generating assembly How do we convert from three-address code to assembly? Seems easy! But easy solutions may not be the best option What we will cover: Instruction
Code generation and local optimization Generating assembly How do we convert from three-address code to assembly? Seems easy! But easy solutions may not be the best option What we will cover: Instruction
CS 316: Procedure Calls/Pipelining
 CS 316: Procedure Calls/Pipelining Kavita Bala Fall 2007 Computer Science Cornell University Announcements PA 3 IS out today Lectures on it this Fri and next Tue/Thu Due on the Friday after Fall break
CS 316: Procedure Calls/Pipelining Kavita Bala Fall 2007 Computer Science Cornell University Announcements PA 3 IS out today Lectures on it this Fri and next Tue/Thu Due on the Friday after Fall break
Code generation and local optimization
 Code generation and local optimization Generating assembly How do we convert from three-address code to assembly? Seems easy! But easy solutions may not be the best option What we will cover: Instruction
Code generation and local optimization Generating assembly How do we convert from three-address code to assembly? Seems easy! But easy solutions may not be the best option What we will cover: Instruction
Code Generation. The Main Idea of Today s Lecture. We can emit stack-machine-style code for expressions via recursion. Lecture Outline.
 The Main Idea of Today s Lecture Code Generation We can emit stack-machine-style code for expressions via recursion (We will use MIPS assembly as our target language) 2 Lecture Outline What are stack machines?
The Main Idea of Today s Lecture Code Generation We can emit stack-machine-style code for expressions via recursion (We will use MIPS assembly as our target language) 2 Lecture Outline What are stack machines?
We can emit stack-machine-style code for expressions via recursion
 Code Generation The Main Idea of Today s Lecture We can emit stack-machine-style code for expressions via recursion (We will use MIPS assembly as our target language) 2 Lecture Outline What are stack machines?
Code Generation The Main Idea of Today s Lecture We can emit stack-machine-style code for expressions via recursion (We will use MIPS assembly as our target language) 2 Lecture Outline What are stack machines?
Lec 10: Assembler. Announcements
 Lec 10: Assembler Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University Announcements HW 2 is out Due Wed after Fall Break Robot-wide paths PA 1 is due next Wed Don t use incrementor 4 times
Lec 10: Assembler Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University Announcements HW 2 is out Due Wed after Fall Break Robot-wide paths PA 1 is due next Wed Don t use incrementor 4 times
Optimization. ASU Textbook Chapter 9. Tsan-sheng Hsu.
 Optimization ASU Textbook Chapter 9 Tsan-sheng Hsu tshsu@iis.sinica.edu.tw http://www.iis.sinica.edu.tw/~tshsu 1 Introduction For some compiler, the intermediate code is a pseudo code of a virtual machine.
Optimization ASU Textbook Chapter 9 Tsan-sheng Hsu tshsu@iis.sinica.edu.tw http://www.iis.sinica.edu.tw/~tshsu 1 Introduction For some compiler, the intermediate code is a pseudo code of a virtual machine.
CSE 504: Compiler Design. Code Generation
 Code Generation Pradipta De pradipta.de@sunykorea.ac.kr Current Topic Introducing basic concepts in code generation phase Code Generation Detailed Steps The problem of generating an optimal target program
Code Generation Pradipta De pradipta.de@sunykorea.ac.kr Current Topic Introducing basic concepts in code generation phase Code Generation Detailed Steps The problem of generating an optimal target program
CS153: Compilers Lecture 8: Compiling Calls
 CS153: Compilers Lecture 8: Compiling Calls Stephen Chong https://www.seas.harvard.edu/courses/cs153 Announcements Project 2 out Due Thu Oct 4 (7 days) Project 3 out Due Tuesday Oct 9 (12 days) Reminder:
CS153: Compilers Lecture 8: Compiling Calls Stephen Chong https://www.seas.harvard.edu/courses/cs153 Announcements Project 2 out Due Thu Oct 4 (7 days) Project 3 out Due Tuesday Oct 9 (12 days) Reminder:
Introduction to Optimization, Instruction Selection and Scheduling, and Register Allocation
 Introduction to Optimization, Instruction Selection and Scheduling, and Register Allocation Copyright 2003, Keith D. Cooper, Ken Kennedy & Linda Torczon, all rights reserved. Traditional Three-pass Compiler
Introduction to Optimization, Instruction Selection and Scheduling, and Register Allocation Copyright 2003, Keith D. Cooper, Ken Kennedy & Linda Torczon, all rights reserved. Traditional Three-pass Compiler
Register Allocation. CS 502 Lecture 14 11/25/08
 Register Allocation CS 502 Lecture 14 11/25/08 Where we are... Reasonably low-level intermediate representation: sequence of simple instructions followed by a transfer of control. a representation of static
Register Allocation CS 502 Lecture 14 11/25/08 Where we are... Reasonably low-level intermediate representation: sequence of simple instructions followed by a transfer of control. a representation of static
A Bad Name. CS 2210: Optimization. Register Allocation. Optimization. Reaching Definitions. Dataflow Analyses 4/10/2013
 A Bad Name Optimization is the process by which we turn a program into a better one, for some definition of better. CS 2210: Optimization This is impossible in the general case. For instance, a fully optimizing
A Bad Name Optimization is the process by which we turn a program into a better one, for some definition of better. CS 2210: Optimization This is impossible in the general case. For instance, a fully optimizing
Where we are. Instruction selection. Abstract Assembly. CS 4120 Introduction to Compilers
 Where we are CS 420 Introduction to Compilers Andrew Myers Cornell University Lecture 8: Instruction Selection 5 Oct 20 Intermediate code Canonical intermediate code Abstract assembly code Assembly code
Where we are CS 420 Introduction to Compilers Andrew Myers Cornell University Lecture 8: Instruction Selection 5 Oct 20 Intermediate code Canonical intermediate code Abstract assembly code Assembly code
W4118: PC Hardware and x86. Junfeng Yang
 W4118: PC Hardware and x86 Junfeng Yang A PC How to make it do something useful? 2 Outline PC organization x86 instruction set gcc calling conventions PC emulation 3 PC board 4 PC organization One or more
W4118: PC Hardware and x86 Junfeng Yang A PC How to make it do something useful? 2 Outline PC organization x86 instruction set gcc calling conventions PC emulation 3 PC board 4 PC organization One or more
x86 assembly CS449 Fall 2017
 x86 assembly CS449 Fall 2017 x86 is a CISC CISC (Complex Instruction Set Computer) e.g. x86 Hundreds of (complex) instructions Only a handful of registers RISC (Reduced Instruction Set Computer) e.g. MIPS
x86 assembly CS449 Fall 2017 x86 is a CISC CISC (Complex Instruction Set Computer) e.g. x86 Hundreds of (complex) instructions Only a handful of registers RISC (Reduced Instruction Set Computer) e.g. MIPS
CS 61C: Great Ideas in Computer Architecture More MIPS, MIPS Functions
 CS 61C: Great Ideas in Computer Architecture More MIPS, MIPS Functions Instructors: John Wawrzynek & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/fa15 1 Machine Interpretation Levels of Representation/Interpretation
CS 61C: Great Ideas in Computer Architecture More MIPS, MIPS Functions Instructors: John Wawrzynek & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/fa15 1 Machine Interpretation Levels of Representation/Interpretation
Faculty of Electrical Engineering, Mathematics, and Computer Science Delft University of Technology
 Faculty of Electrical Engineering, Mathematics, and Computer Science Delft University of Technology exam Compiler Construction in4020 July 5, 2007 14.00-15.30 This exam (8 pages) consists of 60 True/False
Faculty of Electrical Engineering, Mathematics, and Computer Science Delft University of Technology exam Compiler Construction in4020 July 5, 2007 14.00-15.30 This exam (8 pages) consists of 60 True/False
Branch Addressing. Jump Addressing. Target Addressing Example. The University of Adelaide, School of Computer Science 28 September 2015
 Branch Addressing Branch instructions specify Opcode, two registers, target address Most branch targets are near branch Forward or backward op rs rt constant or address 6 bits 5 bits 5 bits 16 bits PC-relative
Branch Addressing Branch instructions specify Opcode, two registers, target address Most branch targets are near branch Forward or backward op rs rt constant or address 6 bits 5 bits 5 bits 16 bits PC-relative
MIPS Functions and Instruction Formats
 MIPS Functions and Instruction Formats 1 The Contract: The MIPS Calling Convention You write functions, your compiler writes functions, other compilers write functions And all your functions call other
MIPS Functions and Instruction Formats 1 The Contract: The MIPS Calling Convention You write functions, your compiler writes functions, other compilers write functions And all your functions call other
Compilers and computer architecture: A realistic compiler to MIPS
 1 / 1 Compilers and computer architecture: A realistic compiler to MIPS Martin Berger November 2017 Recall the function of compilers 2 / 1 3 / 1 Recall the structure of compilers Source program Lexical
1 / 1 Compilers and computer architecture: A realistic compiler to MIPS Martin Berger November 2017 Recall the function of compilers 2 / 1 3 / 1 Recall the structure of compilers Source program Lexical
Register allocation. CS Compiler Design. Liveness analysis. Register allocation. Liveness analysis and Register allocation. V.
 Register allocation CS3300 - Compiler Design Liveness analysis and Register allocation V. Krishna Nandivada IIT Madras Copyright c 2014 by Antony L. Hosking. Permission to make digital or hard copies of
Register allocation CS3300 - Compiler Design Liveness analysis and Register allocation V. Krishna Nandivada IIT Madras Copyright c 2014 by Antony L. Hosking. Permission to make digital or hard copies of
Code Generation. Lecture 30
 Code Generation Lecture 30 (based on slides by R. Bodik) 11/14/06 Prof. Hilfinger CS164 Lecture 30 1 Lecture Outline Stack machines The MIPS assembly language The x86 assembly language A simple source
Code Generation Lecture 30 (based on slides by R. Bodik) 11/14/06 Prof. Hilfinger CS164 Lecture 30 1 Lecture Outline Stack machines The MIPS assembly language The x86 assembly language A simple source
An Overview to Compiler Design. 2008/2/14 \course\cpeg421-08s\topic-1a.ppt 1
 An Overview to Compiler Design 2008/2/14 \course\cpeg421-08s\topic-1a.ppt 1 Outline An Overview of Compiler Structure Front End Middle End Back End 2008/2/14 \course\cpeg421-08s\topic-1a.ppt 2 Reading
An Overview to Compiler Design 2008/2/14 \course\cpeg421-08s\topic-1a.ppt 1 Outline An Overview of Compiler Structure Front End Middle End Back End 2008/2/14 \course\cpeg421-08s\topic-1a.ppt 2 Reading
Today More register allocation Clarifications from last time Finish improvements on basic graph coloring concept Procedure calls Interprocedural
 More Register Allocation Last time Register allocation Global allocation via graph coloring Today More register allocation Clarifications from last time Finish improvements on basic graph coloring concept
More Register Allocation Last time Register allocation Global allocation via graph coloring Today More register allocation Clarifications from last time Finish improvements on basic graph coloring concept
Redundant Computation Elimination Optimizations. Redundancy Elimination. Value Numbering CS2210
 Redundant Computation Elimination Optimizations CS2210 Lecture 20 Redundancy Elimination Several categories: Value Numbering local & global Common subexpression elimination (CSE) local & global Loop-invariant
Redundant Computation Elimination Optimizations CS2210 Lecture 20 Redundancy Elimination Several categories: Value Numbering local & global Common subexpression elimination (CSE) local & global Loop-invariant
Lecture 25: Register Allocation
 Lecture 25: Register Allocation [Adapted from notes by R. Bodik and G. Necula] Topics: Memory Hierarchy Management Register Allocation: Register interference graph Graph coloring heuristics Spilling Cache
Lecture 25: Register Allocation [Adapted from notes by R. Bodik and G. Necula] Topics: Memory Hierarchy Management Register Allocation: Register interference graph Graph coloring heuristics Spilling Cache
Anne Bracy CS 3410 Computer Science Cornell University
 Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. compute jump/branch targets
Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. compute jump/branch targets
CS 110 Computer Architecture Lecture 6: More MIPS, MIPS Functions
 CS 110 Computer Architecture Lecture 6: More MIPS, MIPS Functions Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University
CS 110 Computer Architecture Lecture 6: More MIPS, MIPS Functions Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University
Three-Address Code IR
 Three-Address Code IR Announcements Programming Project 3 due tonight at 11:59PM. OH today after lecture. Ask questions on Piazzza! Ask questions via email! Programming Project 4 out, due Wednesday, August
Three-Address Code IR Announcements Programming Project 3 due tonight at 11:59PM. OH today after lecture. Ask questions on Piazzza! Ask questions via email! Programming Project 4 out, due Wednesday, August
register allocation saves energy register allocation reduces memory accesses.
 Lesson 10 Register Allocation Full Compiler Structure Embedded systems need highly optimized code. This part of the course will focus on Back end code generation. Back end: generation of assembly instructions
Lesson 10 Register Allocation Full Compiler Structure Embedded systems need highly optimized code. This part of the course will focus on Back end code generation. Back end: generation of assembly instructions
Winter Compiler Construction T11 Activation records + Introduction to x86 assembly. Today. Tips for PA4. Today:
 Winter 2006-2007 Compiler Construction T11 Activation records + Introduction to x86 assembly Mooly Sagiv and Roman Manevich School of Computer Science Tel-Aviv University Today ic IC Language Lexical Analysis
Winter 2006-2007 Compiler Construction T11 Activation records + Introduction to x86 assembly Mooly Sagiv and Roman Manevich School of Computer Science Tel-Aviv University Today ic IC Language Lexical Analysis
CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c/su05 CS61C : Machine Structures Lecture #8: MIPS Procedures 2005-06-30 CS 61C L08 MIPS Procedures (1) Andy Carle Topic Outline Functions More Logical Operations CS 61C L08
inst.eecs.berkeley.edu/~cs61c/su05 CS61C : Machine Structures Lecture #8: MIPS Procedures 2005-06-30 CS 61C L08 MIPS Procedures (1) Andy Carle Topic Outline Functions More Logical Operations CS 61C L08
April 15, 2015 More Register Allocation 1. Problem Register values may change across procedure calls The allocator must be sensitive to this
 More Register Allocation Last time Register allocation Global allocation via graph coloring Today More register allocation Procedure calls Interprocedural April 15, 2015 More Register Allocation 1 Register
More Register Allocation Last time Register allocation Global allocation via graph coloring Today More register allocation Procedure calls Interprocedural April 15, 2015 More Register Allocation 1 Register
CS415 Compilers. Intermediate Represeation & Code Generation
 CS415 Compilers Intermediate Represeation & Code Generation These slides are based on slides copyrighted by Keith Cooper, Ken Kennedy & Linda Torczon at Rice University Review - Types of Intermediate Representations
CS415 Compilers Intermediate Represeation & Code Generation These slides are based on slides copyrighted by Keith Cooper, Ken Kennedy & Linda Torczon at Rice University Review - Types of Intermediate Representations
Lecture Outline. Code Generation. Lecture 30. Example of a Stack Machine Program. Stack Machines
 Lecture Outline Code Generation Lecture 30 (based on slides by R. Bodik) Stack machines The MIPS assembly language The x86 assembly language A simple source language Stack-machine implementation of the
Lecture Outline Code Generation Lecture 30 (based on slides by R. Bodik) Stack machines The MIPS assembly language The x86 assembly language A simple source language Stack-machine implementation of the
CS4410 : Spring 2013
 CS4410 : Spring 2013 Next PS: Map Fish code to MIPS code Issues: eliminating compound expressions eliminating variables encoding conditionals, short- circuits, loops type exp = Var of var Int of int Binop
CS4410 : Spring 2013 Next PS: Map Fish code to MIPS code Issues: eliminating compound expressions eliminating variables encoding conditionals, short- circuits, loops type exp = Var of var Int of int Binop
Data Structures and Algorithms in Compiler Optimization. Comp314 Lecture Dave Peixotto
 Data Structures and Algorithms in Compiler Optimization Comp314 Lecture Dave Peixotto 1 What is a compiler Compilers translate between program representations Interpreters evaluate their input to produce
Data Structures and Algorithms in Compiler Optimization Comp314 Lecture Dave Peixotto 1 What is a compiler Compilers translate between program representations Interpreters evaluate their input to produce
THEORY OF COMPILATION
 Lecture 10 Activation Records THEORY OF COMPILATION EranYahav www.cs.technion.ac.il/~yahave/tocs2011/compilers-lec10.pptx Reference: Dragon 7.1,7.2. MCD 6.3,6.4.2 1 You are here Compiler txt Source Lexical
Lecture 10 Activation Records THEORY OF COMPILATION EranYahav www.cs.technion.ac.il/~yahave/tocs2011/compilers-lec10.pptx Reference: Dragon 7.1,7.2. MCD 6.3,6.4.2 1 You are here Compiler txt Source Lexical
Intermediate Code & Local Optimizations. Lecture 20
 Intermediate Code & Local Optimizations Lecture 20 Lecture Outline Intermediate code Local optimizations Next time: global optimizations 2 Code Generation Summary We have discussed Runtime organization
Intermediate Code & Local Optimizations Lecture 20 Lecture Outline Intermediate code Local optimizations Next time: global optimizations 2 Code Generation Summary We have discussed Runtime organization
Group B Assignment 9. Code generation using DAG. Title of Assignment: Problem Definition: Code generation using DAG / labeled tree.
 Group B Assignment 9 Att (2) Perm(3) Oral(5) Total(10) Sign Title of Assignment: Code generation using DAG. 9.1.1 Problem Definition: Code generation using DAG / labeled tree. 9.1.2 Perquisite: Lex, Yacc,
Group B Assignment 9 Att (2) Perm(3) Oral(5) Total(10) Sign Title of Assignment: Code generation using DAG. 9.1.1 Problem Definition: Code generation using DAG / labeled tree. 9.1.2 Perquisite: Lex, Yacc,
Compilers CS S-08 Code Generation
 Compilers CS414-2017S-08 Code Generation David Galles Department of Computer Science University of San Francisco 08-0: Code Generation Next Step: Create actual assembly code. Use a tree tiling strategy:
Compilers CS414-2017S-08 Code Generation David Galles Department of Computer Science University of San Francisco 08-0: Code Generation Next Step: Create actual assembly code. Use a tree tiling strategy:
Lectures 5. Announcements: Today: Oops in Strings/pointers (example from last time) Functions in MIPS
 Functions in MIPS") Lectures 5 Announcements: Today: Oops in Strings/pointers (example from last time) Functions in MIPS 1 OOPS - What does this C code do? int foo(char *s) { int L = 0; while (*s++) { ++L; } return L; } 2
Lectures 5 Announcements: Today: Oops in Strings/pointers (example from last time) Functions in MIPS 1 OOPS - What does this C code do? int foo(char *s) { int L = 0; while (*s++) { ++L; } return L; } 2
PSD3A Principles of Compiler Design Unit : I-V. PSD3A- Principles of Compiler Design
 PSD3A Principles of Compiler Design Unit : I-V 1 UNIT I - SYLLABUS Compiler Assembler Language Processing System Phases of Compiler Lexical Analyser Finite Automata NFA DFA Compiler Tools 2 Compiler -
PSD3A Principles of Compiler Design Unit : I-V 1 UNIT I - SYLLABUS Compiler Assembler Language Processing System Phases of Compiler Lexical Analyser Finite Automata NFA DFA Compiler Tools 2 Compiler -
IR Generation. May 13, Monday, May 13, 13
 IR Generation May 13, 2013 Monday, May 13, 13 Monday, May 13, 13 Monday, May 13, 13 Midterm Results Grades already in Repeal policy Talk to TA by the end of the Tuesday reserve the right to regrade the
IR Generation May 13, 2013 Monday, May 13, 13 Monday, May 13, 13 Monday, May 13, 13 Midterm Results Grades already in Repeal policy Talk to TA by the end of the Tuesday reserve the right to regrade the
Compiling Code, Procedures and Stacks
 Compiling Code, Procedures and Stacks L03-1 RISC-V Recap Computational Instructions executed by ALU Register-Register: op dest, src1, src2 Register-Immediate: op dest, src1, const Control flow instructions
Compiling Code, Procedures and Stacks L03-1 RISC-V Recap Computational Instructions executed by ALU Register-Register: op dest, src1, src2 Register-Immediate: op dest, src1, const Control flow instructions
Control Instructions. Computer Organization Architectures for Embedded Computing. Thursday, 26 September Summary
 Control Instructions Computer Organization Architectures for Embedded Computing Thursday, 26 September 2013 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Control Instructions Computer Organization Architectures for Embedded Computing Thursday, 26 September 2013 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Control Instructions
 Control Instructions Tuesday 22 September 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Instruction Set
Control Instructions Tuesday 22 September 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary Previous Class Instruction Set
Chapter 2. Computer Abstractions and Technology. Lesson 4: MIPS (cont )
") Chapter 2 Computer Abstractions and Technology Lesson 4: MIPS (cont ) Logical Operations Instructions for bitwise manipulation Operation C Java MIPS Shift left >>> srl Bitwise
Chapter 2 Computer Abstractions and Technology Lesson 4: MIPS (cont ) Logical Operations Instructions for bitwise manipulation Operation C Java MIPS Shift left >>> srl Bitwise
Implementing Procedure Calls
 1 / 39 Implementing Procedure Calls February 18 22, 2013 2 / 39 Outline Intro to procedure calls Caller vs. callee Procedure call basics Calling conventions The stack Interacting with the stack Structure
1 / 39 Implementing Procedure Calls February 18 22, 2013 2 / 39 Outline Intro to procedure calls Caller vs. callee Procedure call basics Calling conventions The stack Interacting with the stack Structure
CS 61C: Great Ideas in Computer Architecture More RISC-V Instructions and How to Implement Functions
 CS 61C: Great Ideas in Computer Architecture More RISC-V Instructions and How to Implement Functions Instructors: Krste Asanović and Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 9/14/17 Fall
CS 61C: Great Ideas in Computer Architecture More RISC-V Instructions and How to Implement Functions Instructors: Krste Asanović and Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 9/14/17 Fall
Lecture #16: Introduction to Runtime Organization. Last modified: Fri Mar 19 00:17: CS164: Lecture #16 1
 Lecture #16: Introduction to Runtime Organization Last modified: Fri Mar 19 00:17:19 2010 CS164: Lecture #16 1 Status Lexical analysis Produces tokens Detects & eliminates illegal tokens Parsing Produces
Lecture #16: Introduction to Runtime Organization Last modified: Fri Mar 19 00:17:19 2010 CS164: Lecture #16 1 Status Lexical analysis Produces tokens Detects & eliminates illegal tokens Parsing Produces
Lecture 5. Announcements: Today: Finish up functions in MIPS
 Lecture 5 Announcements: Today: Finish up functions in MIPS 1 Control flow in C Invoking a function changes the control flow of a program twice. 1. Calling the function 2. Returning from the function In
Lecture 5 Announcements: Today: Finish up functions in MIPS 1 Control flow in C Invoking a function changes the control flow of a program twice. 1. Calling the function 2. Returning from the function In