arxiv: v1 [cs.cv] 10 May 2018
|
|
|
- Owen Cox
- 5 years ago
- Views:
Transcription
1 arxiv: v1 [cs.cv] 10 May 2018 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER 1 Dense and Diverse Capsule Networks: Making the Capsules Learn Better Sai Samarth R Phaye 2014csb1029@iitrpr.ac.in Apoorva Sikka apoorva.sikka@iitrpr.ac.in Abhinav Dhall abhinav@iitrpr.ac.in Deepti Bathula bathula@iitrpr.ac.in Abstract Indian Institute of Technology Ropar Punjab, India Past few years have witnessed exponential growth of interest in deep learning methodologies with rapidly improving accuracies and reduced computational complexity. In particular, architectures using Convolutional Neural Networks (CNNs) have produced state-of-the-art performances for image classification and object recognition tasks. Recently, Capsule Networks (CapsNet) achieved significant increase in performance by addressing an inherent limitation of CNNs in encoding pose and deformation. Inspired by such advancement, we asked ourselves, can we do better? We propose Dense Capsule Networks (DCNet) and Diverse Capsule Networks (DCNet++). The two proposed frameworks customize the CapsNet by replacing the standard convolutional layers with densely connected convolutions. This helps in incorporating feature maps learned by different layers in forming the primary capsules. DCNet, essentially adds a deeper convolution network, which leads to learning of discriminative feature maps. Additionally, DCNet++ uses a hierarchical architecture to learn capsules that represent spatial information in a fine-to-coarser manner, which makes it more efficient for learning complex data. Experiments on image classification task using benchmark datasets demonstrate the efficacy of the proposed architectures. DCNet achieves state-of-the-art performance (99.75%) on MNIST dataset with twenty fold decrease in total training iterations, over the conventional CapsNet. Furthermore, DCNet++ performs better than CapsNet on SVHN dataset (96.90%), and outperforms the ensemble of seven CapsNet models on CIFAR-10 by 0.31% with seven fold decrease in number of parameters. 1 Introduction In recent years, deep networks have been applied to the challenging tasks of image classification [5, 8, 13], object recognition [4, 16] and have shown substantial improvement. Many variants of CNN have been proposed by making them deeper and more complex over the time. Adding more depth in various combinations has lead to significant improvement indicates authors have contributed equally. c The copyright of this document resides with its authors. It may be distributed unchanged freely in print or electronic forms.
2 2 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER in performance [8, 13, 15]. However, increase in depth leads to vanishing gradient problem. This issue has been addressed by ResNets [5], FractalNets [9] by adding connections from the initial layers to the later layers. Another similar structure, which further simplifies the way skip connections are added was proposed by Huang et al. popularly known as the DenseNets [7]. The network adds dense connections between every other layer in a feedforward manner. Adding these dense connections leads to lesser number of parameters, when compared with the traditional CNN. Another benefit of concatenating these feature maps is better gradient flow across the network, which allows to train deeper networks. CNNs have performed really well on various computer vision and machine learning tasks, however, it has a few drawbacks, which have been highlighted by Sabour et al. [12]. One is that CNNs are not robust to affine transformations i.e. a slight shift in the position of object make CNNs change their prediction. Although this problem can be reduced to some extent by data augmentation while training, this does not make network robust to any new pose or variation that might be present in the test data. Another major drawback is that generic CNNs do not consider spatial relationships between objects in an image while making any decision. Simply explained, CNNs only use mere presence of certain local objects in an image to make a decision while actually the spatial context of objects present is equally important. The reason is mainly the pooling operation performed in the network, which gives importance to the presence of features and ignores positional information of features, which is mainly done to decrease the parameters as the network grows. To overcome these drawbacks, Sabor et al. [12] proposed a seminal architecture called the capsule networks (CapsNet). In this model, the information is stored at the vector level instead of scalar (as in the case of the simple neural networks) and these group of neurons acting together are named as capsule. Sabour et al. have used the concept of routing-byagreement and layer based squashing to achieve state-of-the-art accuracy on the MNIST dataset and detecting overlapping digits in a better way using reconstruction regularization. CapsNets are really powerful, however, at the same time, there is scope for improvement in terms of complexity as the authors did not use any pooling layers and depth, as the network is currently using only one layer of convolution and capsules. On the other hand, DenseNets have the capability to achieve very high performance by feature concatenation. We compared a Dense Convolution Network having 8 layers of convolution with feature concatenation and a simple CNN having 8 layers of convolution without concatenation and 32 kernels in each layer. Both quantitative analysis (Table 2) and visualizations (Figure 1) show that DenseNets are better at capturing diversified features. We borrow this idea of feature concatenation across layers from DenseNets [7] as it has the potential to learn diversified features, which otherwise would require a much deeper network. We use this concept as an input to the dynamic routing algorithm of Sabour et al. [12]. The motivation behind our work is to: a) improve the performance of CapsNet, in terms of faster convergence and better results; b) achieve better performance than the CapsNet on complicated datasets such as CIFAR-10; c) try to reduce the model complexity. Further, we follow the intuition behind DenseNets to design a modified decoder network with concatenated dense layers, which results in improvement in the reconstruction outputs. Our results (Table 1) are at par with state-of-art performance on the MNIST dataset [10] in 50 epochs, which required 1000 epochs to train conventional CapsNet. We also evaluate the proposed method on various classification datasets such as the FashionMNIST [19], The Street View House Numbers (SVHN) [11], AffNIST Dataset 1 and brain tumor dataset 1 Available at:
 Figure 1: Motivation for using")
 are the feature maps at the same depth from")

 presented in [1, 3, 21], and compare the")











![Highway network [14] was the first architecture](/docs-images/89/99412395/images/3-16.jpg "proposed in this direction to train deeper")



![[7] created a novel way of adding skip](/docs-images/89/99412395/images/3-20.jpg "connections by introducing connections from")

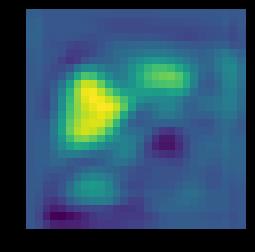







3 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER 3 (A) Figure 1: Motivation for using dense convolutions with CapsNet: Here (A) and (B) are the feature maps at the same depth from DenseNets and CNN, respectively. It is clear that DenseNets learn clearer discriminative features as compared to CNN. (B) presented in [1, 3, 21], and compare the performance of the Capsule Network and Dense- CapsNet for 50 epochs keeping learning rate, learning decay rate and number of capsule parameters same. Further, we focus on why the method was not giving promising results on CIFAR-10 dataset and propose Diverse Capsule Network to improve the same. 2 Background The literature for CNN is vast. Architectures proposed using convolutions has increased significantly due to increase in computational power. The CNN tries to learn in a hierarchical manner from lower to higher layers where lower layers learn basic features like edges and higher layers learns complex features by combination of these low level features. Although, deeper networks have lead to improvement in performance, they are much more difficult to train due to huge increase in number of parameters. Recent architectures proposed, aim to improve the performance while jointly optimizing the number of parameters. Highway network [14] was the first architecture proposed in this direction to train deeper network with large number of layers. They added bypassing paths to easily train the model. ResNet [5] model improves training by adding residual connections. Another such network proposed by Huang et. al. [7] created a novel way of adding skip connections by introducing connections from initial convolution layers to deeper layers, naming it one dense block. The capsule networks [12] have been recently introduced to overcome the drawbacks of CNNs discussed in Section 1. Capsules are group of neurons that depict properties of various entities present in an image. There could be various properties of an image which can be captured like position, size, texture. Capsules use routing-by-agreement where output is sent to all final capsules. Each capsule makes a prediction for the parent capsule, which is then compared with the actual output of parent capsule. If the outputs matches, the coupling coefficient between the two capsules is increased. Let u i be an output of a capsule i, and j be the parent capsule, the prediction is calculated as: û i j = W i j u i c i j = exp(b i j) k exp(b ik ) where W i j is the weighting matrix. Then coupling coefficients c i j are computed using a simple softmax function as shown. Here b i j is log probability of capsule i being coupled with capsule j. This value is 0 when routing is started. Input vector to parent capsule j is calculated as: s j = c i j û j i v j = s j 2 s j i 1 + s j 2 s j,
4 4 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER The output of these capsule vectors represent probability that an object represented by capsule is present in given input or not. But the output of these capsule vectors can exceed one depending on the output. Thus, a non linear squashing function defined above is used to restrict the vector length to 1, where s j is input to capsule j and v j is output. The log probabilities are updated by computing the inner product of v j and uˆ j i. If two vectors agree, the product would be larger leading to longer vector length. In the final layer, a loss value is computed for each capsule. Loss value is high when entity is absent and capsule has high instantiation parameters. Loss is defined as: L k = T k max(0, m + v k ) 2 + λ(1 T k ) max (0, v k m ) 2 Here l k is loss function for a capsule k, T k is 1 when label is true and 0 otherwise. CapsNet applies a convolution and generates 256 feature maps. It is then fed to primary capsule layer where 32, 8D capsules are formed using 9 9 kernel with stride 2 followed by squashing. Finally, a DigitCaps layer is applied which forms final capsules of 16D. A paper by Afshar et al. [1] shows that capsule networks are powerful enough to work on the images containing complex datasets. We aim to work on empowering capsules by using DenseNet. 3 Our Approach We tried to customize capsule network in two frameworks which is explained in the following subsections. Furthermore, we explain the intuition behind choosing densely connected networks and then refine it to improve the performance on complex datasets. 3.1 Dense Capsule Networks (DCNet) The feature maps learned by the first convolution layer in the baseline CapsNet model learns very basic features, which might not be enough to build capsules for complex datasets. Hence, we tried increasing the convolution layers to two and eight in the initial layer and observed that it did not lead to any improvement as shown in Table 1. In DCNet, we try to modify capsule networks to form a deeper architecture where we create an eight-layered dense convolutional subnetwork based on skip connections. Every layer is concatenated to the next layer in feed-forward manner, adding up to make a final convolution layer. This leads to better gradient flow as compared to directly stacked convolution layers. Dynamic Routing SubNetwork Dense Convolution SubNetwork Output Label Input Image Image Concat 1 st Conv BN-ReLU Conv (3x3) same padding 8x Image 8 th Conv 8 x 32x28x BN Conv (9x9) stride=2 Capsule 1 Capsule 2... Capsule x 8x10x10 Reshape PrimaryCaps (3200x8D) Squash Routing by Agreement DigitCaps (10x16D) Masking by label FC1 ReLU (512) FC1 Concat (512) FC2 ReLU (512) FC3 ReLU (1024) FC4 Sigmoid (784) Recons. Image Figure 2: The proposed prediction pipeline for MNIST (best viewed in color). Figure 2 shows the detailed pipeline of the proposed architecture for MNIST dataset. The input sample goes into 8 levels of convolutions and each of those convolution levels
. These diversified feature maps act as input to the capsule layer which applies a convolution of 9 9 with a stride of 2.")


 which further generates one-hot 10D output vector, similar to the conventional capsule network used for MNIST.")
 8 x (5 x 5) Feature Maps Image (32 x 32) 8D Primary Digit Capsule (Level 3) 8 x (5 x 5) Feature Maps (21 x 21) Image (32 x 32) Level One Level Two (A) Level Three Level 1 Capsule Level 2")



5 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER 5 generates 32 new feature maps followed by concatenation with feature maps of all previous layers which results in 257 feature maps (input image is included). These diversified feature maps act as input to the capsule layer which applies a convolution of 9 9 with a stride of 2. The feature maps obtained act as the primary capsules of the CapsNet. The work of Sabour et al. [12] mainly focuses on equivariance instead of invariance which we totally agree with, so we did not use any of the max. or average pooling layers as used in DenseNets, which results in spatial information loss. It is important to note that while Sabour et al. [12] created the primary capsules from 256 feature maps created by the same complexity level of convolution, DCNet s primary capsules are generated by combining all the features of different levels of complexity, which further improves the classification. These feature maps act as thirty-two 8D capsules, which are passed to a squash activation layer, followed by the routing algorithm. 16D final capsules are generated for each of the 10 classes (digits) which further generates one-hot 10D output vector, similar to the conventional capsule network used for MNIST. 8 x (14 x 14) Feature Maps 8D Primary Digit Capsule (Level 1) (5 x 5) 8D Primary Digit Capsule (Level 2) 8 x (14 x 14) Feature Maps (13 x 13) 8 x (2 x 2) Feature Maps 8 x (14 x 14) Feature Maps Image (32 x 32) 8 x (5 x 5) Feature Maps Image (32 x 32) 8D Primary Digit Capsule (Level 3) 8 x (5 x 5) Feature Maps (21 x 21) Image (32 x 32) Level One Level Two (A) Level Three Level 1 Capsule Level 2 Capsule Level 3 Capsule Input Sample 1 (B) Input Sample 2 Level 1 Capsule Level 2 Capsule Level 3 Capsule Figure 3: Activated image region on CIFAR-10 by corresponding capsules of different levels. Row A depicts how a primary capsule gets activated on the input image. Row B shows sample activation regions on input image from capsules of different levels in DCNet++. Inspired by the dense connections implemented by Huang et al. we also modified the reconstruction model of the capsule network. The decoder is a four-layered model with concatenation of features of first layer and second layer resulting in better reconstructions, which takes the DigitCaps layer as it s input (masked by output label during training). If the size of image is more than 32 32, the number of neurons are changed from 512 to 600 and 1024 to Our experiments show significant increase in performances over various datasets like MNIST, Fashion-MNIST, SVHN. We noticed that DCNet s performance on CIFAR-10 dataset increased over single baseline CapsNet model trained with same parameters, but it did not outperform the seven ensemble model [12] of the capsule networks having 89.40% accuracy. As the images in CIFAR-10 are quite complex when compared to MNIST dataset, it is not easy for the network to encode the part-whole relationships. We address this problem by creating DCNet++ which learns well on such complex datasets. 3.2 Diverse Capsule Networks (DCNet++) Adding skip connections to the convolutions wasn t enough to improve performance on the CIFAR-10 dataset. This might be due to the presence of simple primary capsules which are not sufficient to encode the information present in such complex images. We visualized what part of an image is activated by a 8D primary capsule of DCNet by guided back-propagation and noticed that every primary capsule is generated by a small spatial area of the input
6 6 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER image, which then act together to make a decision but these aren t enough for complex images. To overcome this, we implemented a novel way of creating primary capsules which carry information of various scales of the image, hence diversifying the capsules. This in turn helped to find connections between primary capsules of various levels of image. Figure 3 shows which part of the image is activated in the DCNet++ model. If we consider just one level, it will be similar to image activations in DCNets and baseline CapsNet, except for the fact that the activations will have no diffusion out of the square region in Capsule Network. The activated region is diffused out in DCNet and DCNet++ because of same padded convolutions in the densely connected convolution layers. The ensemble of baseline CapsNet models (by Sabour et al. [12]) give 89.40% accuracy on CIFAR-10 dataset, which is probably due to the fact that patches of are used as input, which helps to activate larger spatial area for generating each primary capsule. Although it achieves reasonably higher accuracy over a single Capsule model, ensemble of seven such models leads to a huge increase in number of parameters which can be reduced for such small sized images. We focus to reduce the number of parameters used to model the data and learn better information via creating multiple levels of capsules. In the proposed model, we pass the complete image by first down sampling it to size. A single three layered DCNet++ having 13.4M parameters achieves 89.71% test accuracy. Dense Convolution SubNetwork 1 Dense Convolution SubNetwork 2 Dense Convolution SubNetwork 3 Input Image Concat BN-ReLU Conv (3x3, same) Image Image 8x 1 st Conv 8 th Conv BN - Conv (kernel=5x5, stride=2) Level 1 Capsules Concat BN-ReLU Conv (3x3, same) 8x 1 st Conv 8 th Conv BN - Conv (kernel=5x5, stride=2) Level 3 Capsules Concat BN-ReLU Conv (3x3, same) 8x 1 st Conv 8 th Conv BN - Conv (kernel=3x3, stride=1) 8 Kernels - 8D Capsules 8 Kernels - 8D Capsules 8 Kernels - 8D Capsules Capsule 1 Capsule 2 Capsule 3... Capsule 12 Capsule 1 Capsule 2 Capsule 3... Capsule 12 Capsule 1 Capsule 2 Capsule 3... Capsule 12 Reshape Squash Reshape Squash Reshape Squash PrimaryCaps1 (2352x8) PrimaryCaps2 (300x8) PrimaryCaps3 (48x8) Dynamic Routing Routing by Agreement Concatenated Primary Capsules (2600 x 8D) Routing by Agreement DigitCaps0 (10 x 16D) DigitCaps1 (10 x 16D) DigitCaps2 (10 x 12D) DigitCaps3 (10 x 10D) Routing by Agreement Reconstruction Framework Output Label Figure 4: Pipeline of three-level DCNet++ for CIFAR-10 (best viewed in color). Figure 4 depicts the detailed pipeline of the DCNet++ model used to train the CIFAR-10 dataset. It is a hierarchical model where a DCNet model is created and it s intermediate representation is used as an input to the next DCNet which in turn generates a representation fed to the next DCNet layer. There are twelve capsules in each DCNet. A strided convolution (9 9 size and 2 stride) is applied which reduces the size of the image fed to next level which is similar to the concept of Pyramid of Gaussian [2]. This also resembles with functioning of brain which separates the information into channels. For example, there are separate pathways for high and low spatial frequency content and color information. In addition to these three DigitCaps (output) layers, we created one more DigitCaps output layer by routing the concatenation of three PrimaryCaps layers. The reason for adding this another level is to allow the model to learn combined features from various levels of capsules. We observed that in case of simple stacking of DigitCaps and joint back-propagation,



7 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER 7 the losses of last level PrimaryCaps dominate others leading to a poor learning and the former levels act as simple convolution layers. Thus, to avoid any imbalanced learning the model was jointly trained but the losses of four layers were back propagated separately. While testing, the four DigitCaps layers are concatenated to form a 54D final capsule for each of the ten classes, and the reconstructions were created for only one channel of image using these fifty-four capsules. The reconstructions for CIFAR-10 were not very good, which we believe is due to the dominance of background noise present in the samples and presence of complex information of the image which the decoder is not robust enough to recreate. Interestingly, we notice the effect of noise in DigitCaps of different levels on the reconstruction outputs over MNIST dataset by subtracting 0.2 from each digit one at a time in the 54D DigitCaps. It is observed that the effect on reconstructions decrease from first level to the last level of capsules. DigitCaps generated from the concatenation of PrimaryCaps play a major role in affecting reconstructions, which is an additive effect of different layers of capsules (shown in Figure 5). 4 Experiments We demonstrate the potential of our model on multiple datasets and compare it with the CapsNet architecture. All the experiments were performed using GeForce GTX 1080 with 8GB RAM. Due to resource constraints, we ran all our models for epochs. The initial learning rate was set to and decay rate 0.9 with Adam as optimizer. We changed multiplier factor to scale down the reconstruction loss according to the image size so that it does not dominate margin loss. We used publicly available code [17, 20] for CapsNet and DenseNet to create our models 2. The test errors were computed once for each model. Three routings were used for all the experiments. For fair comparisons, we mostly kept the parameters of the proposed DCNet model after PrimaryCaps layer, same as the conventional CapsNet. Following are the implementation details corresponding to the datasets used: Level One DigitCaps Level Two DigitCaps Input Image Level Three DigitCaps Merged DigitCaps Figure 5: Reconstruction outputs by adding noise in different digits of the DigitCaps layer of DCNet++ on MNIST. Merged DigitCaps are affected the most due to the addition of all PrimaryCaps having fine-coarse activations. MNIST Handwritten digits dataset and Fashion-MNIST dataset have 60K and 10K training and testing images with each image size being in size. We did not use any data augmentation scheme and repeated the experiment 3 times. It can be clearly seen in Table 1 that DCNet is able to learn the input data variations quickly, as compared to the CapsNet, i.e., it is able to achieve 99.75% test accuracy on MNIST and 94.64% on Fashion- MNIST dataset with 20 fold decrease in total iterations. We changed the stride from two to one in the PrimaryCaps layer of second level of DCNet++ to fit the image. We did not observe any improvement in the performance of 3-level DCNet++ on MNIST dataset which 2 We will be sharing the code after acceptance.
8 8 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER Model MNIST Fashion-MNIST SVHN SmallNORB Brain Tumor Dataset CIFAR % (50E) 89.40% [12] Baseline 93.23% (100E) 78% (10E)[1] 99.75% (1000E) [12] 93.65% (100E) 89.56% (50E) (7 model CapsNet 95.7% (> 100E) [12] 87.5% (50E) 99.65% (1000E, NR) [12] ensemble) DCNet 99.75% (50E) 99.71% (50E, NR) 99.72% (50E, BR) 94.64% (100E) 94.59% (100E, NR) DCNet % (50E) 94.65% (100E) 96.90% (50E) 95.58% (50E) 94.43% (50E) 95.34% (75E) 95.27% (75E, NR) 86.8% (10E) 93.04% (50E) 71.43% (10E) 95.03% (50E) 82.63% (single model) 89.71% (120E) 89.32% (120E, NR) Table 1: Performance of CapsNets, DCNets and DCNet++ over various datasets. NR - No Reconstruction SubNetwork, E - training epochs, BR - baseline Reconstruction SubNetwork. is as expected because we are capturing fine-to-coarse level features, due to which every tiny variation in the writing of a particular number will be captured from the training set. These fine features might be causing a problem during the testing phase. We need to invest more time into improving it. CIFAR-10 dataset is an image dataset having 50K and 10K samples for training and testing. We used channel means and standard deviations for normalizing the data. We compare our proposed model with the ensemble of four and seven capsule network models [12] for first 50 epochs. We used similar parameters for DCNet model that were used for MNIST and the test accuracy improved over the ensemble of four CapsNet models (implemented by Xi et al. [18]) to 82.68% from 71.55%. The proposed DCNet++ model resulted in 89.7% accuracy in 13.4M parameters, which is significantly less than 7 ensemble model proposed by Sabour et al. (7 14.5M, 89.40%) and DCNet (16M parameters for image). Model Description Parameters Test Acc. CapsNet (Baseline) Conv - Primary Capsules - Final Capsules 8.2M 99.67% CapsNet Variant Added one more initial convolution layer having 256 9x9 kernels with same padding, stride=1 13.5M 99.66% DCNet Variant One Used 3 convolution layers with 8 feature maps each 6.9M 99.66% DCNet Variant Two Removed the concatenations (no skip connections) acting like simple 8 layered convolutions 4M 99.68% DCNet Variant Three Used 8th convolution layer only (no concatenation in the last layer) to create Primary Capsules 7.2M 99.72% Final DCNet DenseConv - Primary Capsules - Final Capsules 11.8M 99.75% Table 2: Comparison of various model variations after 50 epochs on MNIST dataset. For details of proposed DCNet, refer to Section 3.1. Street View House Numbers (SVHN) contains 73K and 26K real-life digit images for training and testing. To compare results with the original capsule network model [12] for first 50 epochs, we modified DCNet by using 6D 16 primary capsules with 8D final capsule from four convolution layers with 18 feature maps. The results of the DCNet model improved over the replicated CapsNet model to test accuracy of 95.59% from 93.23%. The model for DCNet++ is same as what we used for CIFAR-10 dataset, resulting in 96.9% accuracy, compared to 95.70% by CapsNets (more than 50 epochs) [12]. Brain Tumor Dataset contains 3,064 MRI images of 233 patients diagnosed with one of the three brain tumor types (i.e., meningioma, glioma, and pituitary tumor). Afshar et al. [1] changed the capsule network architecture with initial convolution layer having 64 feature maps. We created an equivalent DCNet model (for uniform results) by modifying the eight initial convolution layers to four layers with 16 kernels each, totaling to 64 kernels and decreased the primary capsules to 6. We also changed the learning rate of our model to 1E 4 for effective learning. The DCNet++ is a 3-level hierarchical model of the modified
9 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER 9 CapsNet + Baseline Decoder CapsNet + Proposed Decoder Test Accuracy Decoder Loss DenseCapsNet + Proposed Decoder DenseCapsNet Model Baseline CapsNet Model Training Epochs Figure 6: Comparison of the performance of DCNet and the CapsNet model on MNIST dataset. Training Epochs Figure 7: Reconstruction MSE loss of CapsNet+Baseline Decoder, CapsNet+Proposed Decoder and DCNet+Proposed Decoder on MNIST dataset. DCNet. We trained the models on eight fold cross validation (results in Table 1). SmallNORB dataset has 24K and 24K images for training and testing. We normalized the images and add random noise and contrast to each image. The proposed model was compared with the CapsNet [12] for first 50 epochs, by modifying DCNet taking 6D 16 primary capsules with 8D final capsule from four convolution layers with 18 kernels each. The results of DCNet improved over the replicated CapsNet model to give a test accuracy of 95.58%. The DCNet++ model is same as what we used for CIFAR-10 dataset, resulting in 96.90% accuracy, compared to CapsNet [12], which achieved 95.70% in more than 50 epochs. We find that the loss of the modified decoder in the DCNet decrease by a considerable amount (shown in Figure 4), having same loss multiplier factor as that of CapsNet. Also, Figure 6 shows the test accuracy comparison of CapsNet and DCNet from which we can clearly infer that DCNet has a faster convergence rate. 5 Conclusion We proposed a modification of Capsule Network, DCNet that replaces standard convolution layers in CapsNet with densely connected convolution. Addition of direct connections between two consecutive layers help learn better feature maps, which in turn helps in forming better quality primary capsules. The effectiveness of this architecture is demonstrated by state-of-the-art performance (99.75%) on MNIST data with twenty fold decrease in total training iterations, over conventional CapsNets. Although the same DCNet model performed better (82.63%) than a single, baseline CapsNet model on CIFAR-10 data, it was below par compared to seven ensemble model of CapsNet with 89.40% accuracy. Performance of CapsNet on real-life, complex data (CIFAR-10, ImageNet, etc.) is known to be substandard compared to simpler datasets like MNIST. DCNet++, addresses this limitation by stacking multiple layers of DCNet to enhance the representational power of the network. The hierarchical structure helps learn intricate relationships between fine-to-coarse level features. A single, three-level DCNet++ achieves 89.71% accuracy on CIFAR-10,
10 10 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER which is an increase of 0.31% accuracy over seven ensemble CapsNet model with significantly less number of parameters. The proposed networks substantially improve the performance of existing Capsule Networks on other datasets such as SVHN, SmallNORB and Tumor Dataset. In future, we plan to incorporate EM routing [6] in DCNet and DCNet++ and work on reducing the computational complexity of the model even further. References [1] Parnian Afshar, Arash Mohammadi, and Konstantinos N Plataniotis. Brain tumor type classification via capsule networks. arxiv preprint arxiv: , [2] Peter J. Burt and Edward H. Adelson. Readings in computer vision: Issues, problems, principles, and paradigms. chapter The Laplacian Pyramid As a Compact Image Code, pages Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, ISBN URL [3] Jun Cheng, Wei Huang, Shuangliang Cao, Ru Yang, Wei Yang, Zhaoqiang Yun, Zhijian Wang, and Qianjin Feng. Enhanced performance of brain tumor classification via tumor region augmentation and partition. PloS one, 10(10):e , [4] Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. In International conference on machine learning, pages , [5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages , [6] Geoffrey Hinton, Sara Sabour, and Nicholas Frosst. Matrix capsules with em routing URL [7] Gao Huang, Zhuang Liu, Kilian Q Weinberger, and Laurens van der Maaten. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, volume 1, page 3, [8] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages Curran Associates, Inc., URL imagenet-classification-with-deep-convolutional-neural-ne pdf. [9] Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Fractalnet: Ultra-deep neural networks without residuals. CoRR, abs/ , URL arxiv.org/abs/ [10] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11): , 1998.
11 DCNET AND DCNET++: MAKING THE CAPSULES LEARN BETTER 11 [11] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, volume 2011, page 5, [12] Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. Dynamic routing between capsules. In Advances in Neural Information Processing Systems, pages , [13] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for largescale image recognition. CoRR, abs/ , URL abs/ [14] Rupesh Kumar Srivastava, Klaus Greff, and Jürgen Schmidhuber. Highway networks. CoRR, abs/ , URL [15] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. CoRR, abs/ , URL [16] Yaniv Taigman, Ming Yang, Marc Aurelio Ranzato, and Lior Wolf. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 14, pages , Washington, DC, USA, IEEE Computer Society. ISBN doi: /CVPR URL CVPR [17] titu1994. Dense net in keras [18] Edgar Xi, Selina Bing, and Yang Jin. Capsule network performance on complex data. arxiv preprint arxiv: , [19] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arxiv preprint arxiv: , [20] XifengGuo. Capsnet-keras. CapsNet-Keras, [21] Jie Zhao Yang, Yanqiu Feng, Qianjin Feng, and Wufan Chen. Retrieval of brain tumors by adaptive spatial pooling and fisher vector representation 2.
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Exploring Capsules. Binghui Peng Runzhou Tao Shunyu Yao IIIS, Tsinghua University {pbh15, trz15,
 Exploring Capsules Binghui Peng Runzhou Tao Shunyu Yao IIIS, Tsinghua University {pbh15, trz15, yao-sy15}@mails.tsinghua.edu.cn 1 Introduction Nowadays, convolutional neural networks (CNNs) have received
Exploring Capsules Binghui Peng Runzhou Tao Shunyu Yao IIIS, Tsinghua University {pbh15, trz15, yao-sy15}@mails.tsinghua.edu.cn 1 Introduction Nowadays, convolutional neural networks (CNNs) have received
Dynamic Routing Between Capsules. Yiting Ethan Li, Haakon Hukkelaas, and Kaushik Ram Ramasamy
 Dynamic Routing Between Capsules Yiting Ethan Li, Haakon Hukkelaas, and Kaushik Ram Ramasamy Problems & Results Object classification in images without losing information about important parts of the picture.
Dynamic Routing Between Capsules Yiting Ethan Li, Haakon Hukkelaas, and Kaushik Ram Ramasamy Problems & Results Object classification in images without losing information about important parts of the picture.
AAR-CNNs: Auto Adaptive Regularized Convolutional Neural Networks
 AAR-CNNs: Auto Adaptive Regularized Convolutional Neural Networks Yao Lu 1, Guangming Lu 1, Yuanrong Xu 1, Bob Zhang 2 1 Shenzhen Graduate School, Harbin Institute of Technology, China 2 Department of
AAR-CNNs: Auto Adaptive Regularized Convolutional Neural Networks Yao Lu 1, Guangming Lu 1, Yuanrong Xu 1, Bob Zhang 2 1 Shenzhen Graduate School, Harbin Institute of Technology, China 2 Department of
CRESCENDONET: A NEW DEEP CONVOLUTIONAL NEURAL NETWORK WITH ENSEMBLE BEHAVIOR
 CRESCENDONET: A NEW DEEP CONVOLUTIONAL NEURAL NETWORK WITH ENSEMBLE BEHAVIOR Anonymous authors Paper under double-blind review ABSTRACT We introduce a new deep convolutional neural network, CrescendoNet,
CRESCENDONET: A NEW DEEP CONVOLUTIONAL NEURAL NETWORK WITH ENSEMBLE BEHAVIOR Anonymous authors Paper under double-blind review ABSTRACT We introduce a new deep convolutional neural network, CrescendoNet,
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
arxiv: v2 [cs.cv] 20 Oct 2018
![arxiv: v2 [cs.cv] 20 Oct 2018](/thumbs/89/99412328.jpg "arxiv: v2 [cs.cv] 20 Oct 2018") CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces Liheng Zhang, Marzieh Edraki, and Guo-Jun Qi arxiv:1805.07621v2 [cs.cv] 20 Oct 2018 Laboratory for MAchine Perception
CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces Liheng Zhang, Marzieh Edraki, and Guo-Jun Qi arxiv:1805.07621v2 [cs.cv] 20 Oct 2018 Laboratory for MAchine Perception
3D Densely Convolutional Networks for Volumetric Segmentation. Toan Duc Bui, Jitae Shin, and Taesup Moon
 3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
arxiv: v2 [cs.cv] 26 Jan 2018
![arxiv: v2 [cs.cv] 26 Jan 2018](/thumbs/76/73206564.jpg "arxiv: v2 [cs.cv] 26 Jan 2018") DIRACNETS: TRAINING VERY DEEP NEURAL NET- WORKS WITHOUT SKIP-CONNECTIONS Sergey Zagoruyko, Nikos Komodakis Université Paris-Est, École des Ponts ParisTech Paris, France {sergey.zagoruyko,nikos.komodakis}@enpc.fr
DIRACNETS: TRAINING VERY DEEP NEURAL NET- WORKS WITHOUT SKIP-CONNECTIONS Sergey Zagoruyko, Nikos Komodakis Université Paris-Est, École des Ponts ParisTech Paris, France {sergey.zagoruyko,nikos.komodakis}@enpc.fr
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Elastic Neural Networks for Classification
 Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Groupout: A Way to Regularize Deep Convolutional Neural Network
 Groupout: A Way to Regularize Deep Convolutional Neural Network Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Groupout is a new technique
Groupout: A Way to Regularize Deep Convolutional Neural Network Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Groupout is a new technique
arxiv: v2 [cs.cv] 7 Nov 2017
![arxiv: v2 [cs.cv] 7 Nov 2017](/thumbs/73/68431656.jpg "arxiv: v2 [cs.cv] 7 Nov 2017") Dynamic Routing Between Capsules Sara Sabour Nicholas Frosst arxiv:1710.09829v2 [cs.cv] 7 Nov 2017 Geoffrey E. Hinton Google Brain Toronto {sasabour, frosst, geoffhinton}@google.com Abstract A capsule
Dynamic Routing Between Capsules Sara Sabour Nicholas Frosst arxiv:1710.09829v2 [cs.cv] 7 Nov 2017 Geoffrey E. Hinton Google Brain Toronto {sasabour, frosst, geoffhinton}@google.com Abstract A capsule
HENet: A Highly Efficient Convolutional Neural. Networks Optimized for Accuracy, Speed and Storage
 HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet
 1 Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet Naimish Agarwal, IIIT-Allahabad (irm2013013@iiita.ac.in) Artus Krohn-Grimberghe, University of Paderborn (artus@aisbi.de)
1 Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet Naimish Agarwal, IIIT-Allahabad (irm2013013@iiita.ac.in) Artus Krohn-Grimberghe, University of Paderborn (artus@aisbi.de)
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Capsule Networks. Eric Mintun
 Capsule Networks Eric Mintun Motivation An improvement* to regular Convolutional Neural Networks. Two goals: Replace max-pooling operation with something more intuitive. Keep more info about an activated
Capsule Networks Eric Mintun Motivation An improvement* to regular Convolutional Neural Networks. Two goals: Replace max-pooling operation with something more intuitive. Keep more info about an activated
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
arxiv: v1 [cs.cv] 22 Sep 2014
![arxiv: v1 [cs.cv] 22 Sep 2014](/thumbs/81/83157697.jpg "arxiv: v1 [cs.cv] 22 Sep 2014") Spatially-sparse convolutional neural networks arxiv:1409.6070v1 [cs.cv] 22 Sep 2014 Benjamin Graham Dept of Statistics, University of Warwick, CV4 7AL, UK b.graham@warwick.ac.uk September 23, 2014 Abstract
Spatially-sparse convolutional neural networks arxiv:1409.6070v1 [cs.cv] 22 Sep 2014 Benjamin Graham Dept of Statistics, University of Warwick, CV4 7AL, UK b.graham@warwick.ac.uk September 23, 2014 Abstract
CrescendoNet: A New Deep Convolutional Neural Network with Ensemble Behavior
 CrescendoNet: A New Deep Convolutional Neural Network with Ensemble Behavior Xiang Zhang, Nishant Vishwamitra, Hongxin Hu, Feng Luo School of Computing Clemson University xzhang7@clemson.edu Abstract We
CrescendoNet: A New Deep Convolutional Neural Network with Ensemble Behavior Xiang Zhang, Nishant Vishwamitra, Hongxin Hu, Feng Luo School of Computing Clemson University xzhang7@clemson.edu Abstract We
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Deeply Cascaded Networks
 Deeply Cascaded Networks Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu 1 Introduction After the seminal work of Viola-Jones[15] fast object
Deeply Cascaded Networks Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu 1 Introduction After the seminal work of Viola-Jones[15] fast object
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
A Novel Weight-Shared Multi-Stage Network Architecture of CNNs for Scale Invariance
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 A Novel Weight-Shared Multi-Stage Network Architecture of CNNs for Scale Invariance Ryo Takahashi, Takashi Matsubara, Member, IEEE, and Kuniaki
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 A Novel Weight-Shared Multi-Stage Network Architecture of CNNs for Scale Invariance Ryo Takahashi, Takashi Matsubara, Member, IEEE, and Kuniaki
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Progressive Neural Architecture Search
 Progressive Neural Architecture Search Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy 09/10/2018 @ECCV 1 Outline Introduction
Progressive Neural Architecture Search Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy 09/10/2018 @ECCV 1 Outline Introduction
Real-time convolutional networks for sonar image classification in low-power embedded systems
 Real-time convolutional networks for sonar image classification in low-power embedded systems Matias Valdenegro-Toro Ocean Systems Laboratory - School of Engineering & Physical Sciences Heriot-Watt University,
Real-time convolutional networks for sonar image classification in low-power embedded systems Matias Valdenegro-Toro Ocean Systems Laboratory - School of Engineering & Physical Sciences Heriot-Watt University,
Sanny: Scalable Approximate Nearest Neighbors Search System Using Partial Nearest Neighbors Sets
 Sanny: EC 1,a) 1,b) EC EC EC EC Sanny Sanny ( ) Sanny: Scalable Approximate Nearest Neighbors Search System Using Partial Nearest Neighbors Sets Yusuke Miyake 1,a) Ryosuke Matsumoto 1,b) Abstract: Building
Sanny: EC 1,a) 1,b) EC EC EC EC Sanny Sanny ( ) Sanny: Scalable Approximate Nearest Neighbors Search System Using Partial Nearest Neighbors Sets Yusuke Miyake 1,a) Ryosuke Matsumoto 1,b) Abstract: Building
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Dynamic Routing Using Inter Capsule Routing Protocol Between Capsules
 2018 UKSim-AMSS 20th International Conference on Modelling & Simulation Dynamic Routing Using Inter Capsule Routing Protocol Between Capsules Sanjib Kumar Sahu GGS Indraprastha University Delhi, India,
2018 UKSim-AMSS 20th International Conference on Modelling & Simulation Dynamic Routing Using Inter Capsule Routing Protocol Between Capsules Sanjib Kumar Sahu GGS Indraprastha University Delhi, India,
arxiv: v1 [cs.lg] 16 Nov 2018
![arxiv: v1 [cs.lg] 16 Nov 2018](/thumbs/88/115079567.jpg "arxiv: v1 [cs.lg] 16 Nov 2018") DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules arxiv:1811.06969v1 [cs.lg] 16 Nov 2018 Nicholas Frosst, Sara Sabour, Geoffrey Hinton {frosst, sasabour, geoffhinton}@google.com
DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules arxiv:1811.06969v1 [cs.lg] 16 Nov 2018 Nicholas Frosst, Sara Sabour, Geoffrey Hinton {frosst, sasabour, geoffhinton}@google.com
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network
 Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network Tianyu Wang Australia National University, Colledge of Engineering and Computer Science u@anu.edu.au Abstract. Some tasks,
Research on Pruning Convolutional Neural Network, Autoencoder and Capsule Network Tianyu Wang Australia National University, Colledge of Engineering and Computer Science u@anu.edu.au Abstract. Some tasks,
Seminars in Artifiial Intelligenie and Robotiis
 Seminars in Artifiial Intelligenie and Robotiis Computer Vision for Intelligent Robotiis Basiis and hints on CNNs Alberto Pretto What is a neural network? We start from the frst type of artifcal neuron,
Seminars in Artifiial Intelligenie and Robotiis Computer Vision for Intelligent Robotiis Basiis and hints on CNNs Alberto Pretto What is a neural network? We start from the frst type of artifcal neuron,
A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images
 A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images Marc Aurelio Ranzato Yann LeCun Courant Institute of Mathematical Sciences New York University - New York, NY 10003 Abstract
A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images Marc Aurelio Ranzato Yann LeCun Courant Institute of Mathematical Sciences New York University - New York, NY 10003 Abstract
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
RETRIEVAL OF FACES BASED ON SIMILARITIES Jonnadula Narasimha Rao, Keerthi Krishna Sai Viswanadh, Namani Sandeep, Allanki Upasana
 ISSN 2320-9194 1 Volume 5, Issue 4, April 2017, Online: ISSN 2320-9194 RETRIEVAL OF FACES BASED ON SIMILARITIES Jonnadula Narasimha Rao, Keerthi Krishna Sai Viswanadh, Namani Sandeep, Allanki Upasana ABSTRACT
ISSN 2320-9194 1 Volume 5, Issue 4, April 2017, Online: ISSN 2320-9194 RETRIEVAL OF FACES BASED ON SIMILARITIES Jonnadula Narasimha Rao, Keerthi Krishna Sai Viswanadh, Namani Sandeep, Allanki Upasana ABSTRACT
Rotation Invariance Neural Network
 Rotation Invariance Neural Network Shiyuan Li Abstract Rotation invariance and translate invariance have great values in image recognition. In this paper, we bring a new architecture in convolutional neural
Rotation Invariance Neural Network Shiyuan Li Abstract Rotation invariance and translate invariance have great values in image recognition. In this paper, we bring a new architecture in convolutional neural
Quantifying Translation-Invariance in Convolutional Neural Networks
 Quantifying Translation-Invariance in Convolutional Neural Networks Eric Kauderer-Abrams Stanford University 450 Serra Mall, Stanford, CA 94305 ekabrams@stanford.edu Abstract A fundamental problem in object
Quantifying Translation-Invariance in Convolutional Neural Networks Eric Kauderer-Abrams Stanford University 450 Serra Mall, Stanford, CA 94305 ekabrams@stanford.edu Abstract A fundamental problem in object
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
arxiv: v1 [cs.lg] 16 Jan 2013
![arxiv: v1 [cs.lg] 16 Jan 2013](/thumbs/80/80526613.jpg "arxiv: v1 [cs.lg] 16 Jan 2013") Stochastic Pooling for Regularization of Deep Convolutional Neural Networks arxiv:131.3557v1 [cs.lg] 16 Jan 213 Matthew D. Zeiler Department of Computer Science Courant Institute, New York University zeiler@cs.nyu.edu
Stochastic Pooling for Regularization of Deep Convolutional Neural Networks arxiv:131.3557v1 [cs.lg] 16 Jan 213 Matthew D. Zeiler Department of Computer Science Courant Institute, New York University zeiler@cs.nyu.edu
arxiv: v1 [cs.cv] 18 Jan 2018
![arxiv: v1 [cs.cv] 18 Jan 2018](/thumbs/74/70143455.jpg "arxiv: v1 [cs.cv] 18 Jan 2018") Sparsely Connected Convolutional Networks arxiv:1.595v1 [cs.cv] 1 Jan 1 Ligeng Zhu* lykenz@sfu.ca Greg Mori Abstract mori@sfu.ca Residual learning [] with skip connections permits training ultra-deep neural
Sparsely Connected Convolutional Networks arxiv:1.595v1 [cs.cv] 1 Jan 1 Ligeng Zhu* lykenz@sfu.ca Greg Mori Abstract mori@sfu.ca Residual learning [] with skip connections permits training ultra-deep neural
A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images
 A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images Marc Aurelio Ranzato Yann LeCun Courant Institute of Mathematical Sciences New York University - New York, NY 10003 Abstract
A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images Marc Aurelio Ranzato Yann LeCun Courant Institute of Mathematical Sciences New York University - New York, NY 10003 Abstract
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Dynamic Routing on Deep Neural Network for Thoracic Disease Classification and Sensitive Area Localization
 Dynamic Routing on Deep Neural Network for Thoracic Disease Classification and Sensitive Area Localization Yan Shen, Mingchen Gao Department of Computer Science and Engineering, University at Buffalo Abstract.
Dynamic Routing on Deep Neural Network for Thoracic Disease Classification and Sensitive Area Localization Yan Shen, Mingchen Gao Department of Computer Science and Engineering, University at Buffalo Abstract.
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
FaceNet. Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana
 FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Face Recognition A Deep Learning Approach
 Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks
 BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks Surat Teerapittayanon Harvard University Email: steerapi@seas.harvard.edu Bradley McDanel Harvard University Email: mcdanel@fas.harvard.edu
BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks Surat Teerapittayanon Harvard University Email: steerapi@seas.harvard.edu Bradley McDanel Harvard University Email: mcdanel@fas.harvard.edu
arxiv: v1 [cs.ne] 11 Jun 2018
![arxiv: v1 [cs.ne] 11 Jun 2018](/thumbs/80/80526645.jpg "arxiv: v1 [cs.ne] 11 Jun 2018") Generative Adversarial Network Architectures For Image Synthesis Using Capsule Networks arxiv:1806.03796v1 [cs.ne] 11 Jun 2018 Yash Upadhyay University of Minnesota, Twin Cities Minneapolis, MN, 55414
Generative Adversarial Network Architectures For Image Synthesis Using Capsule Networks arxiv:1806.03796v1 [cs.ne] 11 Jun 2018 Yash Upadhyay University of Minnesota, Twin Cities Minneapolis, MN, 55414
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
 Residual Networks Behave Like Ensembles of Relatively Shallow Networks Andreas Veit Michael Wilber Serge Belongie Department of Computer Science & Cornell Tech Cornell University {av443, mjw285, sjb344}@cornell.edu
Residual Networks Behave Like Ensembles of Relatively Shallow Networks Andreas Veit Michael Wilber Serge Belongie Department of Computer Science & Cornell Tech Cornell University {av443, mjw285, sjb344}@cornell.edu
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
 Residual Networks Behave Like Ensembles of Relatively Shallow Networks Andreas Veit Michael Wilber Serge Belongie Department of Computer Science & Cornell Tech Cornell University {av443, mjw285, sjb344}@cornell.edu
Residual Networks Behave Like Ensembles of Relatively Shallow Networks Andreas Veit Michael Wilber Serge Belongie Department of Computer Science & Cornell Tech Cornell University {av443, mjw285, sjb344}@cornell.edu
Introduction to Neural Networks
 Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Weighted Convolutional Neural Network. Ensemble.
 Weighted Convolutional Neural Network Ensemble Xavier Frazão and Luís A. Alexandre Dept. of Informatics, Univ. Beira Interior and Instituto de Telecomunicações Covilhã, Portugal xavierfrazao@gmail.com
Weighted Convolutional Neural Network Ensemble Xavier Frazão and Luís A. Alexandre Dept. of Informatics, Univ. Beira Interior and Instituto de Telecomunicações Covilhã, Portugal xavierfrazao@gmail.com
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
arxiv: v3 [cs.lg] 30 Dec 2016
![arxiv: v3 [cs.lg] 30 Dec 2016](/thumbs/74/70392473.jpg "arxiv: v3 [cs.lg] 30 Dec 2016") Video Ladder Networks Francesco Cricri Nokia Technologies francesco.cricri@nokia.com Xingyang Ni Tampere University of Technology xingyang.ni@tut.fi arxiv:1612.01756v3 [cs.lg] 30 Dec 2016 Mikko Honkala
Video Ladder Networks Francesco Cricri Nokia Technologies francesco.cricri@nokia.com Xingyang Ni Tampere University of Technology xingyang.ni@tut.fi arxiv:1612.01756v3 [cs.lg] 30 Dec 2016 Mikko Honkala
Scale-Invariant Recognition by Weight-Shared CNNs in Parallel
 Proceedings of Machine Learning Research 77:295 310, 2017 ACML 2017 Scale-Invariant Recognition by Weight-Shared CNNs in Parallel Ryo Takahashi takahashi@ai.cs.kobe-u.ac.jp Takashi Matsubara matsubara@phoenix.kobe-u.ac.jp
Proceedings of Machine Learning Research 77:295 310, 2017 ACML 2017 Scale-Invariant Recognition by Weight-Shared CNNs in Parallel Ryo Takahashi takahashi@ai.cs.kobe-u.ac.jp Takashi Matsubara matsubara@phoenix.kobe-u.ac.jp
Learning Deep Representations for Visual Recognition
 Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset
 Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
arxiv: v2 [cs.cv] 1 Sep 2018
![arxiv: v2 [cs.cv] 1 Sep 2018](/thumbs/87/96968609.jpg "arxiv: v2 [cs.cv] 1 Sep 2018") arxiv:1805.10807v2 [cs.cv] 1 Sep 2018 Fast Dynamic Routing Based on Weighted Kernel Density Estimation Suofei Zhang 1, Wei Zhao 2, Xiaofu Wu 1, Quan Zhou 1 1 Nanjing University of Post and Telecommunication
arxiv:1805.10807v2 [cs.cv] 1 Sep 2018 Fast Dynamic Routing Based on Weighted Kernel Density Estimation Suofei Zhang 1, Wei Zhao 2, Xiaofu Wu 1, Quan Zhou 1 1 Nanjing University of Post and Telecommunication
arxiv: v1 [cs.cv] 18 Feb 2018
![arxiv: v1 [cs.cv] 18 Feb 2018](/thumbs/94/121287278.jpg "arxiv: v1 [cs.cv] 18 Feb 2018") EFFICIENT SPARSE-WINOGRAD CONVOLUTIONAL NEURAL NETWORKS Xingyu Liu, Jeff Pool, Song Han, William J. Dally Stanford University, NVIDIA, Massachusetts Institute of Technology, Google Brain {xyl, dally}@stanford.edu
EFFICIENT SPARSE-WINOGRAD CONVOLUTIONAL NEURAL NETWORKS Xingyu Liu, Jeff Pool, Song Han, William J. Dally Stanford University, NVIDIA, Massachusetts Institute of Technology, Google Brain {xyl, dally}@stanford.edu
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Thinking Outside the Box: Spatial Anticipation of Semantic Categories
 GARBADE, GALL: SPATIAL ANTICIPATION OF SEMANTIC CATEGORIES 1 Thinking Outside the Box: Spatial Anticipation of Semantic Categories Martin Garbade garbade@iai.uni-bonn.de Juergen Gall gall@iai.uni-bonn.de
GARBADE, GALL: SPATIAL ANTICIPATION OF SEMANTIC CATEGORIES 1 Thinking Outside the Box: Spatial Anticipation of Semantic Categories Martin Garbade garbade@iai.uni-bonn.de Juergen Gall gall@iai.uni-bonn.de
arxiv: v1 [cs.cv] 25 Aug 2016
![arxiv: v1 [cs.cv] 25 Aug 2016](/thumbs/82/87019181.jpg "arxiv: v1 [cs.cv] 25 Aug 2016") DENSELY CONNECTED CONVOLUTIONAL NETWORKS Gao Huang Department of Computer Science Cornell University Ithaca, NY 14850, USA gh349@cornell.edu Zhuang Liu Institute for Interdisciplinary Information Sciences
DENSELY CONNECTED CONVOLUTIONAL NETWORKS Gao Huang Department of Computer Science Cornell University Ithaca, NY 14850, USA gh349@cornell.edu Zhuang Liu Institute for Interdisciplinary Information Sciences
Deep Convolutional Neural Networks and Noisy Images
 Deep Convolutional Neural Networks and Noisy Images Tiago S. Nazaré, Gabriel B. Paranhos da Costa, Welinton A. Contato, and Moacir Ponti Instituto de Ciências Matemáticas e de Computação Universidade de
Deep Convolutional Neural Networks and Noisy Images Tiago S. Nazaré, Gabriel B. Paranhos da Costa, Welinton A. Contato, and Moacir Ponti Instituto de Ciências Matemáticas e de Computação Universidade de
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
End-To-End Spam Classification With Neural Networks
 End-To-End Spam Classification With Neural Networks Christopher Lennan, Bastian Naber, Jan Reher, Leon Weber 1 Introduction A few years ago, the majority of the internet s network traffic was due to spam
End-To-End Spam Classification With Neural Networks Christopher Lennan, Bastian Naber, Jan Reher, Leon Weber 1 Introduction A few years ago, the majority of the internet s network traffic was due to spam
Kaggle Data Science Bowl 2017 Technical Report
 Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Classifying a specific image region using convolutional nets with an ROI mask as input
 Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
CENG 783. Special topics in. Deep Learning. AlchemyAPI. Week 11. Sinan Kalkan
 CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
arxiv: v1 [cs.cv] 29 Oct 2017
![arxiv: v1 [cs.cv] 29 Oct 2017](/thumbs/77/75355191.jpg "arxiv: v1 [cs.cv] 29 Oct 2017") A SAAK TRANSFORM APPROACH TO EFFICIENT, SCALABLE AND ROBUST HANDWRITTEN DIGITS RECOGNITION Yueru Chen, Zhuwei Xu, Shanshan Cai, Yujian Lang and C.-C. Jay Kuo Ming Hsieh Department of Electrical Engineering
A SAAK TRANSFORM APPROACH TO EFFICIENT, SCALABLE AND ROBUST HANDWRITTEN DIGITS RECOGNITION Yueru Chen, Zhuwei Xu, Shanshan Cai, Yujian Lang and C.-C. Jay Kuo Ming Hsieh Department of Electrical Engineering
On the Importance of Normalisation Layers in Deep Learning with Piecewise Linear Activation Units
 On the Importance of Normalisation Layers in Deep Learning with Piecewise Linear Activation Units Zhibin Liao Gustavo Carneiro ARC Centre of Excellence for Robotic Vision University of Adelaide, Australia
On the Importance of Normalisation Layers in Deep Learning with Piecewise Linear Activation Units Zhibin Liao Gustavo Carneiro ARC Centre of Excellence for Robotic Vision University of Adelaide, Australia
Clustering and Unsupervised Anomaly Detection with l 2 Normalized Deep Auto-Encoder Representations
 Clustering and Unsupervised Anomaly Detection with l 2 Normalized Deep Auto-Encoder Representations Caglar Aytekin, Xingyang Ni, Francesco Cricri and Emre Aksu Nokia Technologies, Tampere, Finland Corresponding
Clustering and Unsupervised Anomaly Detection with l 2 Normalized Deep Auto-Encoder Representations Caglar Aytekin, Xingyang Ni, Francesco Cricri and Emre Aksu Nokia Technologies, Tampere, Finland Corresponding
Learning Structured Sparsity in Deep Neural Networks
 Learning Structured Sparsity in Deep Neural Networks Wei Wen wew57@pitt.edu Chunpeng Wu chw127@pitt.edu Yandan Wang yaw46@pitt.edu Yiran Chen yic52@pitt.edu Hai Li hal66@pitt.edu Abstract High demand for
Learning Structured Sparsity in Deep Neural Networks Wei Wen wew57@pitt.edu Chunpeng Wu chw127@pitt.edu Yandan Wang yaw46@pitt.edu Yiran Chen yic52@pitt.edu Hai Li hal66@pitt.edu Abstract High demand for
arxiv: v1 [cs.cv] 17 Nov 2016
![arxiv: v1 [cs.cv] 17 Nov 2016](/thumbs/86/93859848.jpg "arxiv: v1 [cs.cv] 17 Nov 2016") Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Smart Parking System using Deep Learning. Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins
 Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
Layerwise Interweaving Convolutional LSTM
 Layerwise Interweaving Convolutional LSTM Tiehang Duan and Sargur N. Srihari Department of Computer Science and Engineering The State University of New York at Buffalo Buffalo, NY 14260, United States
Layerwise Interweaving Convolutional LSTM Tiehang Duan and Sargur N. Srihari Department of Computer Science and Engineering The State University of New York at Buffalo Buffalo, NY 14260, United States
Convolutional Neural Network Layer Reordering for Acceleration
 R1-15 SASIMI 2016 Proceedings Convolutional Neural Network Layer Reordering for Acceleration Vijay Daultani Subhajit Chaudhury Kazuhisa Ishizaka System Platform Labs Value Co-creation Center System Platform
R1-15 SASIMI 2016 Proceedings Convolutional Neural Network Layer Reordering for Acceleration Vijay Daultani Subhajit Chaudhury Kazuhisa Ishizaka System Platform Labs Value Co-creation Center System Platform
Introduction to Deep Learning
 ENEE698A : Machine Learning Seminar Introduction to Deep Learning Raviteja Vemulapalli Image credit: [LeCun 1998] Resources Unsupervised feature learning and deep learning (UFLDL) tutorial (http://ufldl.stanford.edu/wiki/index.php/ufldl_tutorial)
ENEE698A : Machine Learning Seminar Introduction to Deep Learning Raviteja Vemulapalli Image credit: [LeCun 1998] Resources Unsupervised feature learning and deep learning (UFLDL) tutorial (http://ufldl.stanford.edu/wiki/index.php/ufldl_tutorial)
Air Quality Measurement Based on Double-Channel. Convolutional Neural Network Ensemble Learning
 arxiv:1902.06942v2 [cs.cv] 19 Feb 2019 Air Quality Measurement Based on Double-Channel Convolutional Neural Network Ensemble Learning Zhenyu Wang, Wei Zheng, Chunfeng Song School of Control and Computer
arxiv:1902.06942v2 [cs.cv] 19 Feb 2019 Air Quality Measurement Based on Double-Channel Convolutional Neural Network Ensemble Learning Zhenyu Wang, Wei Zheng, Chunfeng Song School of Control and Computer
Convolutional Neural Networks
 Lecturer: Barnabas Poczos Introduction to Machine Learning (Lecture Notes) Convolutional Neural Networks Disclaimer: These notes have not been subjected to the usual scrutiny reserved for formal publications.
Lecturer: Barnabas Poczos Introduction to Machine Learning (Lecture Notes) Convolutional Neural Networks Disclaimer: These notes have not been subjected to the usual scrutiny reserved for formal publications.
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Pelee: A Real-Time Object Detection System on Mobile Devices
 Pelee: A Real-Time Object Detection System on Mobile Devices Robert J. Wang, Xiang Li, Charles X. Ling Department of Computer Science University of Western Ontario London, Ontario, Canada, N6A 3K7 {jwan563,lxiang2,charles.ling}@uwo.ca
Pelee: A Real-Time Object Detection System on Mobile Devices Robert J. Wang, Xiang Li, Charles X. Ling Department of Computer Science University of Western Ontario London, Ontario, Canada, N6A 3K7 {jwan563,lxiang2,charles.ling}@uwo.ca
Convolution Neural Network for Traditional Chinese Calligraphy Recognition
 Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr