CSCS Proposal writing webinar Technical review. 12th April 2015 CSCS
|
|
|
- Lester Edwards
- 5 years ago
- Views:
Transcription

1 CSCS Proposal writing webinar Technical review 12th April 2015 CSCS

2 Agenda Tips for new applicants CSCS overview Allocation process Guidelines Basic concepts Performance tools Demo Q&A open discussion 2
3 Tips for new applicants
 http://www.top500.")
4 CSCS: Overview (Nov. 2014) 4

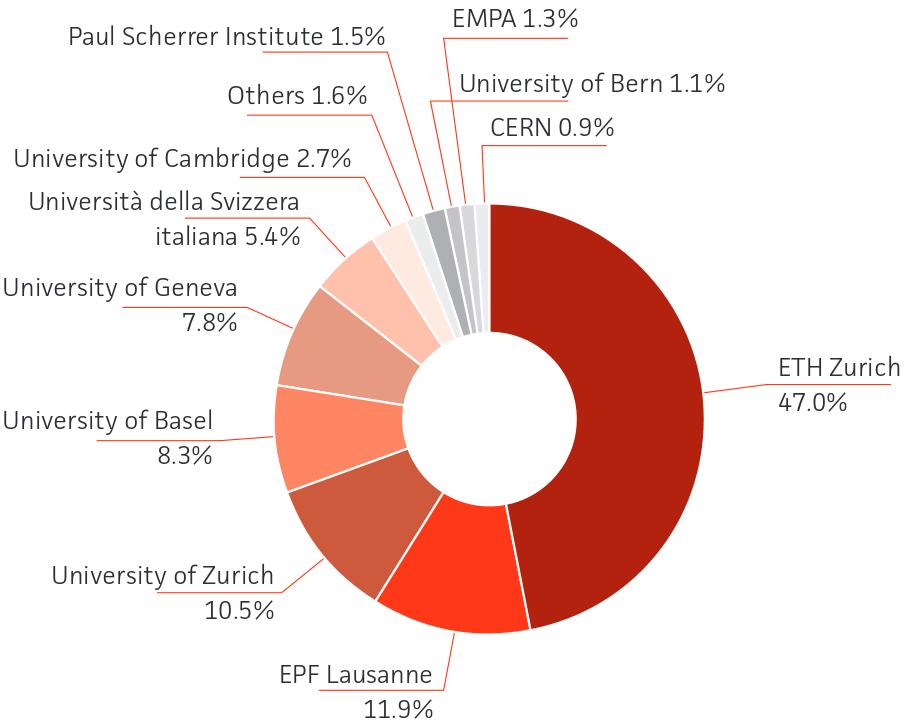
5 CSCS: Usage statistics (2013) Usage by Institution Usage by Research Field 5

6 CSCS: Piz Daint CSCS petascale system: Hybrid Cray XC30, 5272 compute nodes, connected with Aries interconnect Each compute node hosts 1 Intel SandyBridge CPU and 1 NVIDIA K20X GPU For a total of cores and 5272 GPUs, 7.8 Pflops peak performance 6

7 Submitting a project at CSCS 7
8 Guidelines: benchmarking and scaling

9 Proposal format 10
 The idea is to")
10 Benchmarking and Scalability There are many ways to measure the execution time: The most simple one is to time the aprun command and to report the real time: It is the appplicant responsibility to show the scalability of his application: A code scales if its execution time decreases when using increasing numbers of parallel processing elements (cores, processes, threads, etc ) The idea is to find the scalability limit of your application the point at which the execution time stops decreasing. 11
 -d :")
11 Typical user workflow: launching parallel jobs Batch system: The job submission system used at CSCS is SLURM. Submit your jobscript: cd $SCRATCH/ cp /project/*/$user/myinput. sbatch myjob.slurm squeue -u $USER scancel myjobid # if needed Adapt the jobscript to your needs: aprun [options] myexecutable -n : Total number of MPI tasks -N : Number of MPI tasks per compute node (<= 8) -d : Number of OpenMP threads 12
12 Cost study To run 50 steps, my code takes: 1h/6~10m on 16 nodes, 1h/40~2m on 128 nodes, 1h/200<1m on 1024 nodes. For my production job, I must run 2400 steps (x48). How many compute node hours (CNH) should I ask? User type #1: (1024nodes*1h/200)*48 Realtime = 246 CNH Human time < 15 minutes User type #2: (16nodes*1h/6)*48 Realtime = 128 CNH Human time = 8hours (>>15 min!) BUT I used only half CNH I can submit another 2400steps job! User type #3: (128nodes*1h/40)*48 Realtime = 154 CNH Human time = 1 hour 12 min Faster than 8h! I can submit another 2400steps job! 13

 should I ask?")
*48 Realtime = 246 CNH Human time < 15 minutes")
 BUT I used only half CNH I can submit another 2400steps job!")
13 Cost study To run 50 steps, my code takes: 1h/6~10m on 16 nodes, 1h/40~2m on 128 nodes, 1h/200<1m on 1024 nodes. For my production job, I must run 2400 steps (x48). How many compute node hours (CNH) should I ask? User type #0: (2048nodes*1h/100)*48 Realtime = 980 CNH! Human time = 30 minutes! User type #1: (1024nodes*1h/200)*48 Realtime = 246 CNH Human time < 15 minutes User type #2: (16nodes*1h/6)*48 Realtime = 128 CNH Human time = 8hours (>>15 min!) BUT I used only half CNH I can submit another 2400steps job! User type #3: (128nodes*1h/40)*48 Realtime = 154 CNH Human time = 1 hour 12 min Faster than 8h! I can submit another 2400steps job! 14
14 Benchmarking: Mpi+OpenMP code on PizDaint (small problem size) NASA BT C=480x320x28 15
15 Speedup and Efficiency It can sometimes be difficult to read a scaling curve It is standard to compare the execution time with a reference time Speedup is defined by the following formula: where T is the reference time, and 0 T is the execution on n compute nodes n t0 tn Linear speedup or ideal speedup is obtained when Speedupn=n. When running a code with linear speedup, doubling the number of processors doubles the speed. As this is ideal, it is considered very good scalability. Efficiency is a performance metric defined as Speedup n= Efficiency n= Codes with an efficiency > 0.5 are considered scalable. 16 Sn n
16 Scalability quiz: Mpi+OpenMP code on PizDaint (small problem size) C=480x320x28 17
17 Scalability quiz: Mpi+OpenMP code on PizDaint (small problem size) C=480x320x28 18
18 Scalability quiz: Mpi+OpenMP code on PizDaint (small problem size) C=480x320x28 19
19 Scalability quiz: Mpi+OpenMP code on PizDaint (small problem size) Use MPI&OpenMP C=480x320x28 20
 Use MPI&OpenMP Scales up to 8 CN")
20 Scalability quiz: Mpi+OpenMP code on PizDaint (small problem size) Use MPI&OpenMP Scales up to 8 CN C=480x320x28 21
21 Scalability quiz: Mpi+OpenMP code on PizDaint (medium problem size) D=1632x1216x34 22
22 Scalability quiz: Mpi+OpenMP code on PizDaint (medium problem size) D=1632x1216x34 23
23 Scalability quiz: Mpi+OpenMP code on PizDaint (medium problem size) D=1632x1216x34 24
24 Scalability quiz: Mpi+OpenMP code on PizDaint (medium problem size) D=1632x1216x34 25 Use MPI&OpenMP
 D=1632x1216x34 26 Use MPI&OpenMP Scales up to")
25 Scalability quiz: Mpi+OpenMP code on PizDaint (medium problem size) D=1632x1216x34 26 Use MPI&OpenMP Scales up to 64 CN
26 How much can you ask? Allocation units are in node hours: Projects will always be charged full node hours: Compare different job sizes (using the time command), Report in your proposal the execution timings (without tools) for each job size, Multiply the optimal job size (nodes) by the execution time (hours) to find the amount to request (compute node hours). even though not all the CPU cores are used, even though the GPU is not used. Performance data must come from jobs run on Piz Daint: For a problem similar to that proposed in the project description use a problem state that best matches your intended production runs, scaling should be measured based on the overall performance of the application, compare results from same machine, same computational model, no simplified models or preferential configurations. There are many ways for presenting mediocre performance results in the best possible light: We know them, Contact us if you need help: help@cscs.ch 32
27 Guidelines: performance report
28 Typical user workflow: compilation 0. Connect to CSCS: ssh -X ssh daint 4 compilers available: CCE GNU INTEL PGI 1. Setup your Programming Environment: module swap PrgEnv-cray PrgEnv-gnu CRAY specifics: You must use the CRAY wrappers to compile ftn (Fortran), cc (C) CC (C++) module list module avail module avail cray-netcdf module show cray-netcdf module load cray-netcdf/4.3.2 module rm cray-netcdf/4.3.2 The wrappers will detect the modules you have loaded and will automatically use the compiler and libraries that you need. 2. Compile your code: make clean make bt-mz MAIN=bt CLASS=C NPROCS=64 3. Submit your job: cd bin sbatch myjob.slurm 35
29 Typical user workflow: compilation with perftool perflite is Cray's performance tool, it provides performance statistics automatically, and supports all compilers (cce, intel, gnu, pgi). 1. Setup your Programming Environment: module swap PrgEnv-cray PrgEnv-gnu module use /project/csstaff/proposals module load perflite/622 For MPI/OpenMP codes or module load craype-accel-nvidia35 module load perflite/622cuda For MPI/OpenMP + Cuda codes module load craype-accel-nvidia35 module load perflite/622openacc For MPI/OpenMP + OpenACC codes or 2. Recompile your code with the tool: cd $SCRATCH/proposals.git/vihps/NPB3.3-MZ-MPI make clean make bt-mz MAIN=bt CLASS=C NPROCS=64 3. Submit your job: No need to modify the jobscript, Just rerun cd bin sbatch myjob.slurm 4. Read and attach the full report to your proposal: No need to modify the src code, just recompile Performance report at the end of the job cat *.rpt 36
30 Performance: Mpi+OpenMP code on PizDaint (BT CLASS=C, 50 steps) The code stops scaling above 8 nodes. Why? What can we learn from the performance reports? 8CN: aprun -n32 -N4 -d2./bt-mz_c.32+pat622 Setup your Programming Environment: module swap PrgEnv-cray PrgEnv-gnu module use /project/csstaff/proposals module load perflite/622 Recompile your code with the tool: cd $SCRATCH/proposals.git/vihps/NPB3.3-MZ-MPI make clean make bt-mz MAIN=bt CLASS=C NPROCS=64 Submit your job: cd bin sbatch myjob.slurm cat *.rpt 16CN: aprun -n64 -N4 -d2./bt-mz_c.64+pat CN: aprun -n64 -N2 -d4./bt-mz_c.64+pat622
31 Performance: Mpi+OpenMP code on PizDaint (BT CLASS=C, 50 steps) The code stops scaling above 8 nodes. Why? What can we learn from the performance reports? 8CN: aprun -n32 -N4 -d2./bt-mz_c.32+pat622 Setup your Programming Environment: module swap PrgEnv-cray PrgEnv-gnu module use /project/csstaff/proposals module load perflite/622 Recompile your code with the tool: cd $SCRATCH/proposals.git/vihps/NPB3.3-MZ-MPI make clean make bt-mz MAIN=bt CLASS=C NPROCS=64 Submit your job: cd bin sbatch myjob.slurm cat *.rpt 16CN: aprun -n64 -N4 -d2./bt-mz_c.64+pat CN: aprun -n64 -N2 -d4./bt-mz_c.64+pat622




32 Performance: Mpi+OpenMP code on PizDaint (BT CLASS=C, 50 steps) The code stops scaling above 8 nodes. Why? What can we learn from the performance reports? 8CN: aprun -n32 -N4 -d2./bt-mz_c.32+pat622 Setup your Programming Environment: module swap PrgEnv-cray PrgEnv-gnu module use /project/csstaff/proposals module load perflite/622 Recompile your code with the tool: cd $SCRATCH/proposals.git/vihps/NPB3.3-MZ-MPI make clean make bt-mz MAIN=bt CLASS=C NPROCS=64 Submit your job: cd bin sbatch myjob.slurm cat *.rpt 16CN: aprun -n64 -N4 -d2./bt-mz_c.64+pat CN: aprun -n64 -N2 -d4./bt-mz_c.64+pat622
33 Demo: MPI+OpenMP / 32CN
34 GPU codes
35 Scalability: Mpi+OpenMP+CUDA code on PizDaint 42
36 Scalability: Mpi+OpenMP+CUDA code on PizDaint 43
37 Scalability: Mpi+OpenMP+CUDA code on PizDaint 44
38 Scalability: Mpi+OpenMP+CUDA code on PizDaint 45 Scales up to <256 CN



39 Scalability: Mpi+OpenMP+CUDA code on PizDaint 46 Scales up to <256 CN What can we learn from the tool?
40 Performance: Mpi+OpenMP+CUDA code on PizDaint 128CN: aprun -n128 -N1 -d8 cp2k+pat CN: aprun -n512 -N1 -d8 cp2k+pat622 47
41 Performance: Mpi+OpenMP+CUDA code on PizDaint 128CN: aprun -n128 -N1 -d8 cp2k+pat CN: aprun -n512 -N1 -d8 cp2k+pat622 48
42 Performance: Mpi+OpenMP+CUDA code on PizDaint 128CN: aprun -n128 -N1 -d8 cp2k+pat CN: aprun -n512 -N1 -d8 cp2k+pat622 49
43 Performance: Mpi+OpenMP+CUDA code on PizDaint 128CN: aprun -n128 -N1 -d8 cp2k+pat CN: aprun -n512 -N1 -d8 cp2k+pat622 50



44 Performance: Mpi+OpenMP+CUDA code on PizDaint 128CN: aprun -n128 -N1 -d8 cp2k+pat CN: aprun -n512 -N1 -d8 cp2k+pat To allow multiple CPU cores to simultaneously utilize a single GPU, the CUDA proxy must be enabled. CRAY_CUDA_MPS=1 Performance tools are only supported with the CUDA proxy disabled CRAY_CUDA_MPS=0
45 Conclusion
? Is your resource request consistent with your scientific goals? Does the project plan fit the allocated time frame?")
46 Recipe for a successfull technical review If the answer to any of the following question is No Does your code run on Piz Daint? Did you provide scalability data from Piz Daint? Did you attach the.rpt performance report file(s)? Is your resource request consistent with your scientific goals? Does the project plan fit the allocated time frame? there is a risk that your proposal will not be accepted 53
47 Future events (2015) Orientation course (EPFL) new Jan Feb Mar Summer School (Ticino) PASC'15 (ETHZ) Apr May Jun HPC Visualisation using Python new Jul Aug Sep EuroHACKaton Orientation course (ETHZ) new Oct Nov Dec C++ for HPC new Intro Cuda/OpenACC Online registration ===> 55 new

48 Thank you for your attention. Questions?
Compiling applications for the Cray XC
 Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy.! Thomas C.
 The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
Practical: a sample code
 Practical: a sample code Alistair Hart Cray Exascale Research Initiative Europe 1 Aims The aim of this practical is to examine, compile and run a simple, pre-prepared OpenACC code The aims of this are:
Practical: a sample code Alistair Hart Cray Exascale Research Initiative Europe 1 Aims The aim of this practical is to examine, compile and run a simple, pre-prepared OpenACC code The aims of this are:
HPCF Cray Phase 2. User Test period. Cristian Simarro User Support. ECMWF April 18, 2016
 HPCF Cray Phase 2 User Test period Cristian Simarro User Support advisory@ecmwf.int ECMWF April 18, 2016 Content Introduction Upgrade timeline Changes Hardware Software Steps for the testing on CCB Possible
HPCF Cray Phase 2 User Test period Cristian Simarro User Support advisory@ecmwf.int ECMWF April 18, 2016 Content Introduction Upgrade timeline Changes Hardware Software Steps for the testing on CCB Possible
PROGRAMMING MODEL EXAMPLES
 ( Cray Inc 2015) PROGRAMMING MODEL EXAMPLES DEMONSTRATION EXAMPLES OF VARIOUS PROGRAMMING MODELS OVERVIEW Building an application to use multiple processors (cores, cpus, nodes) can be done in various
( Cray Inc 2015) PROGRAMMING MODEL EXAMPLES DEMONSTRATION EXAMPLES OF VARIOUS PROGRAMMING MODELS OVERVIEW Building an application to use multiple processors (cores, cpus, nodes) can be done in various
Graham vs legacy systems
 New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
New User Seminar Graham vs legacy systems This webinar only covers topics pertaining to graham. For the introduction to our legacy systems (Orca etc.), please check the following recorded webinar: SHARCNet
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
First steps on using an HPC service ARCHER
 First steps on using an HPC service ARCHER ARCHER Service Overview and Introduction ARCHER in a nutshell UK National Supercomputing Service Cray XC30 Hardware Nodes based on 2 Intel Ivy Bridge 12-core
First steps on using an HPC service ARCHER ARCHER Service Overview and Introduction ARCHER in a nutshell UK National Supercomputing Service Cray XC30 Hardware Nodes based on 2 Intel Ivy Bridge 12-core
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2015 Our Environment Today Your laptops or workstations: only used for portal access Blue Waters
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Heidi Poxon Cray Inc.
 Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
The Eclipse Parallel Tools Platform
 May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016
 1/18/2016") Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
Introduction to the NCAR HPC Systems. 25 May 2018 Consulting Services Group Brian Vanderwende
 Introduction to the NCAR HPC Systems 25 May 2018 Consulting Services Group Brian Vanderwende Topics to cover Overview of the NCAR cluster resources Basic tasks in the HPC environment Accessing pre-built
Introduction to the NCAR HPC Systems 25 May 2018 Consulting Services Group Brian Vanderwende Topics to cover Overview of the NCAR cluster resources Basic tasks in the HPC environment Accessing pre-built
Programming Environment 4/11/2015
 Programming Environment 4/11/2015 1 Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent interface
Programming Environment 4/11/2015 1 Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent interface
RAMSES on the GPU: An OpenACC-Based Approach
 RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
Blue Waters Programming Environment
 December 3, 2013 Blue Waters Programming Environment Blue Waters User Workshop December 3, 2013 Science and Engineering Applications Support Documentation on Portal 2 All of this information is Available
December 3, 2013 Blue Waters Programming Environment Blue Waters User Workshop December 3, 2013 Science and Engineering Applications Support Documentation on Portal 2 All of this information is Available
RHRK-Seminar. High Performance Computing with the Cluster Elwetritsch - II. Course instructor : Dr. Josef Schüle, RHRK
 RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
Running applications on the Cray XC30
 Running applications on the Cray XC30 Running on compute nodes By default, users do not access compute nodes directly. Instead they launch jobs on compute nodes using one of three available modes: 1. Extreme
Running applications on the Cray XC30 Running on compute nodes By default, users do not access compute nodes directly. Instead they launch jobs on compute nodes using one of three available modes: 1. Extreme
ReFrame: A Regression Testing Framework Enabling Continuous Integration of Large HPC Systems
 ReFrame: A Regression Testing Framework Enabling Continuous Integration of Large HPC Systems HPC Advisory Council 2018 Victor Holanda, Vasileios Karakasis, CSCS Apr. 11, 2018 ReFrame in a nutshell Regression
ReFrame: A Regression Testing Framework Enabling Continuous Integration of Large HPC Systems HPC Advisory Council 2018 Victor Holanda, Vasileios Karakasis, CSCS Apr. 11, 2018 ReFrame in a nutshell Regression
OpenACC compiling and performance tips. May 3, 2013
 OpenACC compiling and performance tips May 3, 2013 OpenACC compiler support Cray Module load PrgEnv-cray craype-accel-nvidia35 Fortran -h acc, noomp # openmp is enabled by default, be careful mixing -fpic
OpenACC compiling and performance tips May 3, 2013 OpenACC compiler support Cray Module load PrgEnv-cray craype-accel-nvidia35 Fortran -h acc, noomp # openmp is enabled by default, be careful mixing -fpic
A More Realistic Way of Stressing the End-to-end I/O System
 A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
Hands-on / Demo: Building and running NPB-MZ-MPI / BT
 Hands-on / Demo: Building and running NPB-MZ-MPI / BT Markus Geimer Jülich Supercomputing Centre What is NPB-MZ-MPI / BT? A benchmark from the NAS parallel benchmarks suite MPI + OpenMP version Implementation
Hands-on / Demo: Building and running NPB-MZ-MPI / BT Markus Geimer Jülich Supercomputing Centre What is NPB-MZ-MPI / BT? A benchmark from the NAS parallel benchmarks suite MPI + OpenMP version Implementation
TAU Performance System Hands on session
 TAU Performance System Hands on session Sameer Shende sameer@cs.uoregon.edu University of Oregon http://tau.uoregon.edu Copy the workshop tarball! Setup preferred program environment compilers! Default
TAU Performance System Hands on session Sameer Shende sameer@cs.uoregon.edu University of Oregon http://tau.uoregon.edu Copy the workshop tarball! Setup preferred program environment compilers! Default
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine
 Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Shifter and Singularity on Blue Waters
 Shifter and Singularity on Blue Waters Maxim Belkin June 7, 2018 A simplistic view of a scientific application DATA RESULTS My Application Received an allocation on Blue Waters! DATA RESULTS My Application
Shifter and Singularity on Blue Waters Maxim Belkin June 7, 2018 A simplistic view of a scientific application DATA RESULTS My Application Received an allocation on Blue Waters! DATA RESULTS My Application
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
Introduction to SahasraT. RAVITEJA K Applications Analyst, Cray inc E Mail :
 Introduction to SahasraT RAVITEJA K Applications Analyst, Cray inc E Mail : raviteja@cray.com 1 1. Introduction to SahasraT 2. Cray Software stack 3. Compile applications on XC 4. Run applications on XC
Introduction to SahasraT RAVITEJA K Applications Analyst, Cray inc E Mail : raviteja@cray.com 1 1. Introduction to SahasraT 2. Cray Software stack 3. Compile applications on XC 4. Run applications on XC
The Titan Tools Experience
 The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
User Training Cray XC40 IITM, Pune
 User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
Shifter at CSCS Docker Containers for HPC
 Shifter at CSCS Docker Containers for HPC HPC Advisory Council Swiss Conference Alberto Madonna, Lucas Benedicic, Felipe A. Cruz, Kean Mariotti - CSCS April 9 th, 2018 Table of Contents 1. Introduction
Shifter at CSCS Docker Containers for HPC HPC Advisory Council Swiss Conference Alberto Madonna, Lucas Benedicic, Felipe A. Cruz, Kean Mariotti - CSCS April 9 th, 2018 Table of Contents 1. Introduction
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
Accelerate HPC Development with Allinea Performance Tools
 Accelerate HPC Development with Allinea Performance Tools 19 April 2016 VI-HPS, LRZ Florent Lebeau / Ryan Hulguin flebeau@allinea.com / rhulguin@allinea.com Agenda 09:00 09:15 Introduction 09:15 09:45
Accelerate HPC Development with Allinea Performance Tools 19 April 2016 VI-HPS, LRZ Florent Lebeau / Ryan Hulguin flebeau@allinea.com / rhulguin@allinea.com Agenda 09:00 09:15 Introduction 09:15 09:45
OpenACC Accelerator Directives. May 3, 2013
 OpenACC Accelerator Directives May 3, 2013 OpenACC is... An API Inspired by OpenMP Implemented by Cray, PGI, CAPS Includes functions to query device(s) Evolving Plan to integrate into OpenMP Support of
OpenACC Accelerator Directives May 3, 2013 OpenACC is... An API Inspired by OpenMP Implemented by Cray, PGI, CAPS Includes functions to query device(s) Evolving Plan to integrate into OpenMP Support of
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Beginner's Guide for UK IBM systems
 Beginner's Guide for UK IBM systems This document is intended to provide some basic guidelines for those who already had certain programming knowledge with high level computer languages (e.g. Fortran,
Beginner's Guide for UK IBM systems This document is intended to provide some basic guidelines for those who already had certain programming knowledge with high level computer languages (e.g. Fortran,
Sharpen Exercise: Using HPC resources and running parallel applications
 Sharpen Exercise: Using HPC resources and running parallel applications Andrew Turner, Dominic Sloan-Murphy, David Henty, Adrian Jackson Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into
Sharpen Exercise: Using HPC resources and running parallel applications Andrew Turner, Dominic Sloan-Murphy, David Henty, Adrian Jackson Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into
Shifter: Fast and consistent HPC workflows using containers
 Shifter: Fast and consistent HPC workflows using containers CUG 2017, Redmond, Washington Lucas Benedicic, Felipe A. Cruz, Thomas C. Schulthess - CSCS May 11, 2017 Outline 1. Overview 2. Docker 3. Shifter
Shifter: Fast and consistent HPC workflows using containers CUG 2017, Redmond, Washington Lucas Benedicic, Felipe A. Cruz, Thomas C. Schulthess - CSCS May 11, 2017 Outline 1. Overview 2. Docker 3. Shifter
CALMIP : HIGH PERFORMANCE COMPUTING
 CALMIP : HIGH PERFORMANCE COMPUTING Nicolas.renon@univ-tlse3.fr Emmanuel.courcelle@inp-toulouse.fr CALMIP (UMS 3667) Espace Clément Ader www.calmip.univ-toulouse.fr CALMIP :Toulouse University Computing
CALMIP : HIGH PERFORMANCE COMPUTING Nicolas.renon@univ-tlse3.fr Emmanuel.courcelle@inp-toulouse.fr CALMIP (UMS 3667) Espace Clément Ader www.calmip.univ-toulouse.fr CALMIP :Toulouse University Computing
The Arm Technology Ecosystem: Current Products and Future Outlook
 The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
Exercise 1: Connecting to BW using ssh: NOTE: $ = command starts here, =means one space between words/characters.
 Exercise 1: Connecting to BW using ssh: NOTE: $ = command starts here, =means one space between words/characters. Before you login to the Blue Waters system, make sure you have the following information
Exercise 1: Connecting to BW using ssh: NOTE: $ = command starts here, =means one space between words/characters. Before you login to the Blue Waters system, make sure you have the following information
8/19/13. Blue Waters User Monthly Teleconference
 8/19/13 Blue Waters User Monthly Teleconference Extreme Scaling Workshop 2013 Successful workshop in Boulder. Presentations from 4 groups with allocations on Blue Waters. Industry representatives were
8/19/13 Blue Waters User Monthly Teleconference Extreme Scaling Workshop 2013 Successful workshop in Boulder. Presentations from 4 groups with allocations on Blue Waters. Industry representatives were
SCALABLE HYBRID PROTOTYPE
 SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
SCALABLE HYBRID PROTOTYPE Scalable Hybrid Prototype Part of the PRACE Technology Evaluation Objectives Enabling key applications on new architectures Familiarizing users and providing a research platform
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Cray Scientific Libraries. Overview
 Cray Scientific Libraries Overview What are libraries for? Building blocks for writing scientific applications Historically allowed the first forms of code re-use Later became ways of running optimized
Cray Scientific Libraries Overview What are libraries for? Building blocks for writing scientific applications Historically allowed the first forms of code re-use Later became ways of running optimized
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Sharpen Exercise: Using HPC resources and running parallel applications
 Sharpen Exercise: Using HPC resources and running parallel applications Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into ARCHER frontend nodes and run commands.... 3 3.2 Download and extract
Sharpen Exercise: Using HPC resources and running parallel applications Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into ARCHER frontend nodes and run commands.... 3 3.2 Download and extract
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
MPI 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
How to run a job on a Cluster?
 How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
How to run a job on a Cluster? Cluster Training Workshop Dr Samuel Kortas Computational Scientist KAUST Supercomputing Laboratory Samuel.kortas@kaust.edu.sa 17 October 2017 Outline 1. Resources available
UAntwerpen, 24 June 2016
 Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
COMPILING FOR THE ARCHER HARDWARE. Slides contributed by Cray and EPCC
 COMPILING FOR THE ARCHER HARDWARE Slides contributed by Cray and EPCC Modules The Cray Programming Environment uses the GNU modules framework to support multiple software versions and to create integrated
COMPILING FOR THE ARCHER HARDWARE Slides contributed by Cray and EPCC Modules The Cray Programming Environment uses the GNU modules framework to support multiple software versions and to create integrated
Hands-on: NPB-MZ-MPI / BT
 Hands-on: NPB-MZ-MPI / BT VI-HPS Team Tutorial exercise objectives Familiarize with usage of Score-P, Cube, Scalasca & Vampir Complementary tools capabilities & interoperability Prepare to apply tools
Hands-on: NPB-MZ-MPI / BT VI-HPS Team Tutorial exercise objectives Familiarize with usage of Score-P, Cube, Scalasca & Vampir Complementary tools capabilities & interoperability Prepare to apply tools
Opportunities for container environments on Cray XC30 with GPU devices
 Opportunities for container environments on Cray XC30 with GPU devices Cray User Group 2016, London Sadaf Alam, Lucas Benedicic, T. Schulthess, Miguel Gila May 12, 2016 Agenda Motivation Container technologies,
Opportunities for container environments on Cray XC30 with GPU devices Cray User Group 2016, London Sadaf Alam, Lucas Benedicic, T. Schulthess, Miguel Gila May 12, 2016 Agenda Motivation Container technologies,
PLAN-E Workshop Switzerland. Welcome! September 8, 2016
 PLAN-E Workshop Switzerland Welcome! September 8, 2016 The Swiss National Supercomputing Centre Driving innovation in computational research in Switzerland Michele De Lorenzi (CSCS) PLAN-E September 8,
PLAN-E Workshop Switzerland Welcome! September 8, 2016 The Swiss National Supercomputing Centre Driving innovation in computational research in Switzerland Michele De Lorenzi (CSCS) PLAN-E September 8,
Cray Scientific Libraries: Overview and Performance. Cray XE6 Performance Workshop University of Reading Nov 2012
 Cray Scientific Libraries: Overview and Performance Cray XE6 Performance Workshop University of Reading 20-22 Nov 2012 Contents LibSci overview and usage BFRAME / CrayBLAS LAPACK ScaLAPACK FFTW / CRAFFT
Cray Scientific Libraries: Overview and Performance Cray XE6 Performance Workshop University of Reading 20-22 Nov 2012 Contents LibSci overview and usage BFRAME / CrayBLAS LAPACK ScaLAPACK FFTW / CRAFFT
ECMWF Environment on the CRAY practical solutions
 ECMWF Environment on the CRAY practical solutions Xavi Abellan Xavier.Abellan@ecmwf.int User Support Section HPCF 2015 Cray ECMWF Environment ECMWF 2015 Slide 1 Let s play Start a fresh session on cca,
ECMWF Environment on the CRAY practical solutions Xavi Abellan Xavier.Abellan@ecmwf.int User Support Section HPCF 2015 Cray ECMWF Environment ECMWF 2015 Slide 1 Let s play Start a fresh session on cca,
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Introduction to the SHARCNET Environment May-25 Pre-(summer)school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology
school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology") Introduction to the SHARCNET Environment 2010-May-25 Pre-(summer)school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology available hardware and software resources our web portal
Introduction to the SHARCNET Environment 2010-May-25 Pre-(summer)school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology available hardware and software resources our web portal
CSC Summer School in HIGH-PERFORMANCE COMPUTING
 CSC Summer School in HIGH-PERFORMANCE COMPUTING June 22 July 1, 2015 Espoo, Finland Exercise assignments All material (C) 2015 by CSC IT Center for Science Ltd. and the authors. This work is licensed under
CSC Summer School in HIGH-PERFORMANCE COMPUTING June 22 July 1, 2015 Espoo, Finland Exercise assignments All material (C) 2015 by CSC IT Center for Science Ltd. and the authors. This work is licensed under
Domain Decomposition: Computational Fluid Dynamics
 Domain Decomposition: Computational Fluid Dynamics December 0, 0 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Domain Decomposition: Computational Fluid Dynamics December 0, 0 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
NCAR s Data-Centric Supercomputing Environment Yellowstone. November 28, 2011 David L. Hart, CISL
 NCAR s Data-Centric Supercomputing Environment Yellowstone November 28, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
NCAR s Data-Centric Supercomputing Environment Yellowstone November 28, 2011 David L. Hart, CISL dhart@ucar.edu Welcome to the Petascale Yellowstone hardware and software Deployment schedule Allocations
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Domain Decomposition: Computational Fluid Dynamics
 Domain Decomposition: Computational Fluid Dynamics July 11, 2016 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Domain Decomposition: Computational Fluid Dynamics July 11, 2016 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Introduction to High-Performance Computing (HPC)
") Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2. (Mouse over to the left to see thumbnails of all of the slides)
") STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
CSC Summer School in HIGH-PERFORMANCE COMPUTING
 CSC Summer School in HIGH-PERFORMANCE COMPUTING June 27 July 3, 2016 Espoo, Finland Exercise assignments All material (C) 2016 by CSC IT Center for Science Ltd. and the authors. This work is licensed under
CSC Summer School in HIGH-PERFORMANCE COMPUTING June 27 July 3, 2016 Espoo, Finland Exercise assignments All material (C) 2016 by CSC IT Center for Science Ltd. and the authors. This work is licensed under
Introduction to NCAR HPC. 25 May 2017 Consulting Services Group Brian Vanderwende
 Introduction to NCAR HPC 25 May 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical overview of our HPC systems The NCAR computing environment Accessing software on Cheyenne
Introduction to NCAR HPC 25 May 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical overview of our HPC systems The NCAR computing environment Accessing software on Cheyenne
Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU
 Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU What is Joker? NMSU s supercomputer. 238 core computer cluster. Intel E-5 Xeon CPUs and Nvidia K-40 GPUs. InfiniBand innerconnect.
Introduction to Joker Cyber Infrastructure Architecture Team CIA.NMSU.EDU What is Joker? NMSU s supercomputer. 238 core computer cluster. Intel E-5 Xeon CPUs and Nvidia K-40 GPUs. InfiniBand innerconnect.
Choosing Resources Wisely. What is Research Computing?
 Choosing Resources Wisely Scott Yockel, PhD Harvard - Research Computing What is Research Computing? Faculty of Arts and Sciences (FAS) department that handles nonenterprise IT requests from researchers.
Choosing Resources Wisely Scott Yockel, PhD Harvard - Research Computing What is Research Computing? Faculty of Arts and Sciences (FAS) department that handles nonenterprise IT requests from researchers.
An Introduction to Gauss. Paul D. Baines University of California, Davis November 20 th 2012
 An Introduction to Gauss Paul D. Baines University of California, Davis November 20 th 2012 What is Gauss? * http://wiki.cse.ucdavis.edu/support:systems:gauss * 12 node compute cluster (2 x 16 cores per
An Introduction to Gauss Paul D. Baines University of California, Davis November 20 th 2012 What is Gauss? * http://wiki.cse.ucdavis.edu/support:systems:gauss * 12 node compute cluster (2 x 16 cores per
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Agenda
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
Adrian Tate XK6 / openacc workshop Manno, Mar
 Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
PRACE Project Access Technical Guidelines - 19 th Call for Proposals
 PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
Domain Decomposition: Computational Fluid Dynamics
 Domain Decomposition: Computational Fluid Dynamics May 24, 2015 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Domain Decomposition: Computational Fluid Dynamics May 24, 2015 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0)
") PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
Introduction to HPC2N
 Introduction to HPC2N Birgitte Brydsø HPC2N, Umeå University 4 May 2017 1 / 24 Overview Kebnekaise and Abisko Using our systems The File System The Module System Overview Compiler Tool Chains Examples
Introduction to HPC2N Birgitte Brydsø HPC2N, Umeå University 4 May 2017 1 / 24 Overview Kebnekaise and Abisko Using our systems The File System The Module System Overview Compiler Tool Chains Examples
Altix Usage and Application Programming
 Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
software.sci.utah.edu (Select Visitors)
") software.sci.utah.edu (Select Visitors) Web Log Analysis Yearly Report 2002 Report Range: 02/01/2002 00:00:0-12/31/2002 23:59:59 www.webtrends.com Table of Contents Top Visitors...3 Top Visitors Over Time...5
software.sci.utah.edu (Select Visitors) Web Log Analysis Yearly Report 2002 Report Range: 02/01/2002 00:00:0-12/31/2002 23:59:59 www.webtrends.com Table of Contents Top Visitors...3 Top Visitors Over Time...5
High Performance Computing Cluster Basic course
 High Performance Computing Cluster Basic course Jeremie Vandenplas, Gwen Dawes 30 October 2017 Outline Introduction to the Agrogenomics HPC Connecting with Secure Shell to the HPC Introduction to the Unix/Linux
High Performance Computing Cluster Basic course Jeremie Vandenplas, Gwen Dawes 30 October 2017 Outline Introduction to the Agrogenomics HPC Connecting with Secure Shell to the HPC Introduction to the Unix/Linux
Batch Systems. Running your jobs on an HPC machine
 Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 FAS Research Computing
 Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 Email:plamenkrastev@fas.harvard.edu Objectives Inform you of available computational resources Help you choose appropriate computational
Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 Email:plamenkrastev@fas.harvard.edu Objectives Inform you of available computational resources Help you choose appropriate computational
Operational Robustness of Accelerator Aware MPI
 Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization
 SCV Staff Boston University Scientific Computing and Visualization") MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization 2 Glenn Bresnahan Director, SCV MGHPCC Buy-in Program Kadin Tseng HPC Programmer/Consultant
MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization 2 Glenn Bresnahan Director, SCV MGHPCC Buy-in Program Kadin Tseng HPC Programmer/Consultant
Product Life Cycle System-level Products. April, 2016
 Product Life Cycle System-level Products April, 2016 Content Overview 01 Systems 02 Touch Panel PCs 03 EOL Models Systems ULT Fanless EC700-SU Embedded System 2021, Q4 2022, Q3 Atom E3800 Series Atom D2550/N2800
Product Life Cycle System-level Products April, 2016 Content Overview 01 Systems 02 Touch Panel PCs 03 EOL Models Systems ULT Fanless EC700-SU Embedded System 2021, Q4 2022, Q3 Atom E3800 Series Atom D2550/N2800
Working with Shell Scripting. Daniel Balagué
 Working with Shell Scripting Daniel Balagué Editing Text Files We offer many text editors in the HPC cluster. Command-Line Interface (CLI) editors: vi / vim nano (very intuitive and easy to use if you
Working with Shell Scripting Daniel Balagué Editing Text Files We offer many text editors in the HPC cluster. Command-Line Interface (CLI) editors: vi / vim nano (very intuitive and easy to use if you
BANGLADESH UNIVERSITY OF PROFESSIONALS ACADEMIC CALENDAR FOR MPhil AND PHD PROGRAM 2014 (4 TH BATCH) PART I (COURSE WORK)
 PART I (COURSE WORK)") BANGLADESH UNIVERSITY OF PROFESSIONALS ACADEMIC CALENDAR FOR MPhil AND PHD PROGRAM 2014 (4 TH BATCH) DAY Soci-Economic and Political History of Bangladesh PART I (COURSE WORK) 1 ST SEMESTER 2 ND SEMESTER
BANGLADESH UNIVERSITY OF PROFESSIONALS ACADEMIC CALENDAR FOR MPhil AND PHD PROGRAM 2014 (4 TH BATCH) DAY Soci-Economic and Political History of Bangladesh PART I (COURSE WORK) 1 ST SEMESTER 2 ND SEMESTER
Introduction to GALILEO
 November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
AWP ODC QUICK START GUIDE
 AWP ODC QUICK START GUIDE 1. CPU 1.1. Prepare the code Obtain and compile the code, possibly at a path which does not purge. Use the appropriate makefile. For Bluewaters (/u/sciteam/poyraz/scratch/quick_start/cpu/src
AWP ODC QUICK START GUIDE 1. CPU 1.1. Prepare the code Obtain and compile the code, possibly at a path which does not purge. Use the appropriate makefile. For Bluewaters (/u/sciteam/poyraz/scratch/quick_start/cpu/src
High Performance Computing Cluster Advanced course
 High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
Linux process scheduling. David Morgan
 Linux process scheduling David Morgan General neediness categories realtime processes whenever they demand attention, need it immediately other processes interactive care about responsiveness demand no
Linux process scheduling David Morgan General neediness categories realtime processes whenever they demand attention, need it immediately other processes interactive care about responsiveness demand no
Cuda C Programming Guide Appendix C Table C-
 Cuda C Programming Guide Appendix C Table C-4 Professional CUDA C Programming (1118739329) cover image into the powerful world of parallel GPU programming with this down-to-earth, practical guide Table
Cuda C Programming Guide Appendix C Table C-4 Professional CUDA C Programming (1118739329) cover image into the powerful world of parallel GPU programming with this down-to-earth, practical guide Table
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks
 An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract