Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
|
|
|
- Erik Campbell
- 5 years ago
- Views:
Transcription
1 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University
2 ILP Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline» Less work per stage shorter clock cycle Multiple issue» Replicate pipeline stages multiple pipelines» Start multiple instructions per clock cycle» CPI < 1, so use instructions per cycle (IPC)» E.g., g, 4GHz 4-way multiple-issue: 16 BIPS, peak CPI = 0.25, peak IPC = 4» But dependencies reduce this in practice 2
3 Multiple Issue Static multiple issue Compiler groups instructions to be issued together Packages them into issue slots Compiler detects and avoids hazards Dynamic multiple issue CPU examines instruction stream and chooses instructions to issue each cycle Compiler can help by reordering instructions CPU resolves hazards using advanced techniques at runtime 3
4 Speculation (1) Guess what to do with an instruction Start operation as soon as possible Check whether guess was right If so, complete the operation If not, roll-back and do the right thing Common to static and dynamic multiple issue Examples Speculate on branch outcome Roll back if path taken is different Speculate on load Roll back if location is updated 4
5 Speculation (2) Compiler speculation Compiler can reorder instructions E.g., move load before store Can include fix-up instructions to recover from incorrect guess Hardware speculation Hardware can look ahead for instructions to execute Buffer results until it determines they are actually needed Flush buffers on incorrect speculation 5
6 Speculation (3) Speculation and exceptions What if exception occurs on a speculatively executed instruction? E.g., speculative load before null-pointer check Static speculation Can add ISA support for deferring exceptions Dynamic speculation Can buffer exceptions until instruction i completion (which may not occur) 6
7 Static Multiple Issue (1) Compiler groups instructions into issue packets Group of instructions that can be issued on a single cycle Determined by pipeline resources required VLIW (Very Long Instruction Word) Think of an issue packet as a very long instruction Specifies multiple concurrent operations 7
8 Static Multiple Issue (2) Scheduling static multiple issue Compiler must remove some/all hazards Reorder instructions into issue packets No dependencies within a packet Possibly some dependencies between packets» Varies between ISAs; compiler must know! Pad with nop if necessary 8
9 Static Dual-Issue MIPS (1) Two-issue packets One ALU/branch instruction One load/store instruction 64-bit aligned ALU/branch, then load/store Pad an unused instruction with nop Address Instruction type Pipeline Stages n ALU/branch IF ID EX MEM WB n + 4 Load/store IF ID EX MEM WB n + 8 ALU/branch IF ID EX MEM WB n + 12 Load/store IF ID EX MEM WB n + 16 ALU/branch IF ID EX MEM WB n + 20 Load/store IF ID EX MEM WB 9
10 Static Dual-Issue MIPS (2) 10
11 Static Dual-Issue MIPS (3) Hazards in the dual-issue MIPS More instructions executing in parallel EX data hazard Forwarding avoided stalls with single-issue Now can t use ALU result in load/store in same packet Split into two packets, effectively a stall add $t0, $s0, $s1 lw $s2, 0($t0) Load-use hazard Still one cycle use latency, but now two instructions More aggressive scheduling required 11
12 Static Dual-Issue MIPS (4) Scheduling example Loop: lw $t0, 0($s1) # $t0 = array element addu $t0, $t0, $s2 # add scalar in $s2 sw $t0, 0($s1) # store result addi $s1, $s1, 4 # decrement pointer bne $s1, $zero, Loop # branch if $s1!= 0 ALU/branch Load/store cycle Loop: nop lw $t0, 0($s1) 1 addi $s1, $s1, 4 nop 2 addu $t0, $t0, $s2 nop 3 bne $s1, $zero, Loop sw $t0, 4($s1) 4 IPC = 5/4 = 1.25 (cf. Peak IPC = 2) 12
13 Static Dual-Issue MIPS (5) Loop unrolling Replicate loop body to expose more parallelism Reduces loop-control overhead Use different registers per replication Called register renaming Avoid loop-carried anti-dependencies» Store followed by a load of the same register» Aka name dependence : reuse of a register name 13
14 Static Dual-Issue MIPS (6) Loop unrolling example ALU/branch Load/store cycle Loop: addi $s1, $s1, 16 lw $t0, 0($s1) 1 nop lw $t1, 12($s1) 2 addu $t0, $t0, $s2 lw $t2, 8($s1) 3 addu $t1, $t1, $s2 lw $t3, 4($s1) 4 addu $t2, $t2, $s2 sw $t0, 16($s1) 5 addu $t3, $t3, $s2 sw $t1, 12($s1) 6 nop sw $t2, 8($s1) 7 bne $s1, $zero, Loop sw $t3, 4($s1) 8 IPC = 14/8 = 1.75 Closer to 2, but at cost of registers and code size 14
15 Dynamic Multiple Issue (1) Superscalar processors CPU decides whether to issue 0, 1, 2, each cycle Avoiding structural and data hazards Avoids the need for compiler scheduling Though it may still help Code semantics ensured by the CPU 15
16 Dynamic Multiple Issue (2) Dynamic pipeline p scheduling Allow the CPU to execute instructions out of order to avoid stalls But commit result to registers in order Example: lw $t0, 20($s2) addu $t1, $t0, $t2 sub $s4, $s4, $t3 slti $t5, $s4, 20 Can start sub while addu is waiting for lw 16




17 Dynamic Multiple Issue (3) Dynamically y scheduled CPU Preserves dependencies Hold pending operands Results also sent to any waiting reservation stations Reorders buffer for register writes Can supply operands for issued instructions 17
18 Dynamic Multiple Issue (4) Register renaming Reservation stations and reorder buffer effectively provide register renaming On instruction issue to reservation station If operand is available in register file or reorder buffer» Copied to reservation station» No longer required in the register; can be overwritten If operand is not yet available» It will be provided to the reservation station by a function unit» Register update may not be required 18
19 Dynamic Multiple Issue (5) Speculation Predict branch and continue issuing Don t commit until branch outcome determined Load speculation Avoid load and cache miss delay» Predict the effective address» Predict loaded value» Load before completing outstanding stores» Bypass stored values to load unit Don t commit load until speculation cleared 19
20 Dynamic Multiple Issue (6) Why do dynamic scheduling? Why not just let the compiler schedule code? Not all stalls are predictable E.g., cache misses Can t always schedule around branches Branch outcome is dynamically determined Different implementations of an ISA have different latencies and hazards 20
21 Dynamic Multiple Issue (7) Does multiple issue work? Yes, but not as much as we d like Programs have real dependencies that limit ILP Some dependencies are hard to eliminate E.g., pointer aliasing Some parallelism is hard to expose Limited window size during instruction issue Memory delays and limited bandwidth Hard to keep pipelines full Speculation can help if done well 21
22 Dynamic Multiple Issue (8) Power efficiency Complexity of dynamic scheduling and speculations requires power Multiple simpler cores may be better Microprocessor Year Clock Pipeline Issue OOO/ Rate Stages width Speculation Cores Power i MHz 5 1 No 1 5W Pentium MHz 5 2 No 1 10W Pentium Pro MHz 10 3 Yes 1 29W P4 Willamette MHz 22 3 Yes 1 75W P4 Prescott MHz 31 3 Yes 1 103W Core MHz 14 4 Yes 2 75W UltraSparc III MHz 14 4 No 1 90W UltraSparc T MHz 6 1 No 8 70W 22
23 i486 Microarchitecture 5-stage pipeliningp Fetch D1 D2 Ex Move 16 bytes from cache to prefetch queue About 5 instructions fetched during 16-byte cache access Main instruction decoding Determine instruction length and type 3% (Unix) ~ 6% (DOS) of instructions require two cycles Secondary instruction decoding Compute memory address 5% of instructions require two cycles Execute the instruction (ALU, memory access, ) WB Update register files 23


24 P5 Microarchitecture 2-way superscalar with 5 stages Pentium Pentium MMX 24





25 P6 Microarchitecture Dynamic execution 3-way superscalar Superpipelined pp ISA translation (μops) OOO executionecut Register renaming Pentium Pro Pentium II Pentium III 25
26 NetBurst Microarchitecture Pentium 4 26





27 Core Microarchitecture Core 2 Duo Core 2 Quad 27
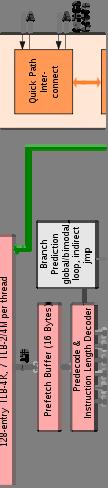
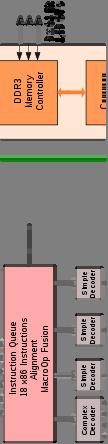
28 Nehalem Microarchitecture Core i7 Core i5 28
29 Quad-core Nehalem 29

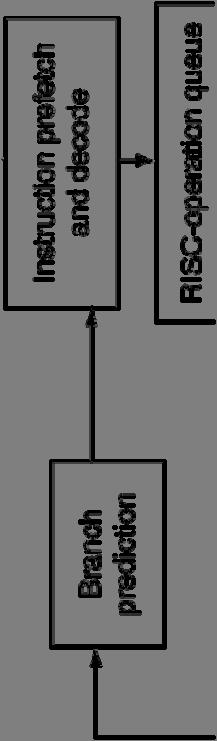
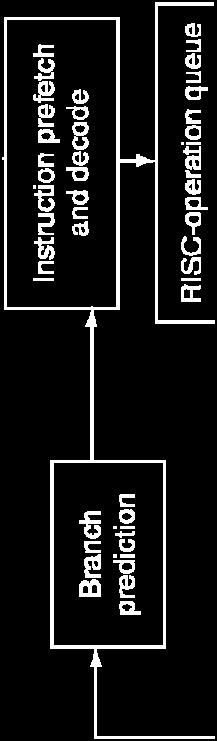


30 Opteron X4 Microarchitecture 72 physical registers 30
31 Opteron X4 Pipeline Flow For integer operations FP is 5 stages longer Up to 106 RISC-ops in progress Bottlenecks Complex instructions with long dependencies Branch mispredictions Memory access delays 31
32 Fallacies Pipelining is easy (!) The basic idea is easy The devil is in the details E.g., detecting data hazards Pipelining is independent of technology So why haven t we always done pipelining? More transistors make more advanced techniques feasible Pipelined-related ISA design needs to take account of technology trends E.g., predicated instructions 32
33 Pitfalls Poor ISA design can make pipelining p harder E.g., complex instruction sets (VAX, IA-32) Significant overhead to make pipelining work IA-32 micro-op approach E.g., complex addressing modes Register update side effects, memory indirection E.g., delayed branches Advanced d pipelines have long delay slots 33
34 Concluding Remarks ISA Datapath & control ISA influences design of datapath and control Datapath and control influence design of ISA Pipelining improves instruction throughput using parallelism More instructions completed per second Latency for each instruction not reduced Hazards: structural, data, control Multiple l issue and dynamic scheduling (ILP) Dependencies limit achievable parallelism Complexity leads to the power wall 34
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Advanced Instruction-Level Parallelism
 Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: C Multiple Issue Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Chapter 4 The Processor (Part 4)
") Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Homework 5. Start date: March 24 Due date: 11:59PM on April 10, Monday night. CSCI 402: Computer Architectures
 Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
CS 61C: Great Ideas in Computer Architecture. Multiple Instruction Issue, Virtual Memory Introduction
 CS 61C: Great Ideas in Computer Architecture Multiple Instruction Issue, Virtual Memory Introduction Instructor: Justin Hsia 7/26/2012 Summer 2012 Lecture #23 1 Parallel Requests Assigned to computer e.g.
CS 61C: Great Ideas in Computer Architecture Multiple Instruction Issue, Virtual Memory Introduction Instructor: Justin Hsia 7/26/2012 Summer 2012 Lecture #23 1 Parallel Requests Assigned to computer e.g.
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3
 Lecture 32: Pipeline Parallelism 3") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3 Instructor: Dan Garcia inst.eecs.berkeley.edu/~cs61c! Compu@ng in the News At a laboratory in São Paulo,
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3 Instructor: Dan Garcia inst.eecs.berkeley.edu/~cs61c! Compu@ng in the News At a laboratory in São Paulo,
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
5 th Edition. The Processor We will examine two MIPS implementations A simplified version A more realistic pipelined version
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Multicore and Parallel Processing
 Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. P & H Chapter 4.10, 1.7, 1.8, 5.10, 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instruction Level Parallelism: Multiple Instruction Issue
 Instruction Level Parallelism: Multiple Instruction Issue") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instruction Level Parallelism: Multiple Instruction Issue Guest Lecturer: Justin Hsia You Are Here! Software Hardware Parallel Requests
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instruction Level Parallelism: Multiple Instruction Issue Guest Lecturer: Justin Hsia You Are Here! Software Hardware Parallel Requests
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Static, multiple-issue (superscaler) pipelines
 pipelines") Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Parallelism, Multicore, and Synchronization
 Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4
![IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4](/thumbs/74/71306691.jpg "IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4") 12 1 CMPE110 Fall 2006 A. Di Blas 110 Fall 2006 CMPE pipeline concepts Advanced ffl ILP ffl Deep pipeline ffl Static multiple issue ffl Loop unrolling ffl VLIW ffl Dynamic multiple issue Textbook Edition:
12 1 CMPE110 Fall 2006 A. Di Blas 110 Fall 2006 CMPE pipeline concepts Advanced ffl ILP ffl Deep pipeline ffl Static multiple issue ffl Loop unrolling ffl VLIW ffl Dynamic multiple issue Textbook Edition:
In-order vs. Out-of-order Execution. In-order vs. Out-of-order Execution
 In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
EEC 581 Computer Architecture. Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW)
") 1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Advanced processor designs
 Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
Orange Coast College. Business Division. Computer Science Department. CS 116- Computer Architecture. Pipelining
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
EEC 581 Computer Architecture. Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW)
") EEC 581 Computer Architecture Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University
EEC 581 Computer Architecture Lec 7 Instruction Level Parallelism (2.6 Hardware-based Speculation and 2.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5
 EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Chapter 4. The Processor
 Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Pipelining and Exploiting Instruction-Level Parallelism (ILP)
") Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
CS 61C: Great Ideas in Computer Architecture. Lecture 13: Pipelining. Krste Asanović & Randy Katz
 CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
Architectural Performance. Superscalar Processing. 740 October 31, i486 Pipeline. Pipeline Stage Details. Page 1
 Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW
: Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW") Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
CS252 Graduate Computer Architecture Midterm 1 Solutions
 CS252 Graduate Computer Architecture Midterm 1 Solutions Part A: Branch Prediction (22 Points) Consider a fetch pipeline based on the UltraSparc-III processor (as seen in Lecture 5). In this part, we evaluate
CS252 Graduate Computer Architecture Midterm 1 Solutions Part A: Branch Prediction (22 Points) Consider a fetch pipeline based on the UltraSparc-III processor (as seen in Lecture 5). In this part, we evaluate
Computer Systems Architecture I. CSE 560M Lecture 10 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Complex Pipelines and Branch Prediction
 Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
Superscalar Processors Ch 14
 Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processing (5) Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?
 Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?") Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25
 CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
Lecture 9: Multiple Issue (Superscalar and VLIW)
") Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
DEE 1053 Computer Organization Lecture 6: Pipelining
 Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Dept. Electronics Engineering, National Chiao Tung University DEE 1053 Computer Organization Lecture 6: Pipelining Dr. Tian-Sheuan Chang tschang@twins.ee.nctu.edu.tw Dept. Electronics Engineering National
Multiple Issue ILP Processors. Summary of discussions
 Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Advanced Processor Architecture
 Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong
Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong