ECE260: Fundamentals of Computer Engineering
|
|
|
- Lesley Richard
- 5 years ago
- Views:
Transcription

1 Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy

2 What is Pipelining? Pipelining is an implementation technique in which multiple instructions are overlapped in execution Pipeline has multiple stages where each stage performs a specific task Single-cycle datapath is divided into smaller combinational logic elements separated by sequential storage elements Instructions pass through each stage of a pipeline one stage at a time Allows multiple instructions to be worked on concurrently Reduces time to complete multiple instructions Does not reduce time to finish any one single instruction A processor pipeline behaves similarly to an assembly line

3 Pipelining Analogy Pipelined laundry overlapping execution of different stages Parallelism improves performance Non-pipelined version 8 hours Non-pipelined version Wash, then dry, then fold, then store Pipelined version Wash, then dry AND start next wash, etc. Allows tasks to be done on multiple loads of laundry concurrently, reducing time to finish all laundry (improves throughput) Pipelined version 3.5 hours Each load of laundry still takes the same amount of time 3
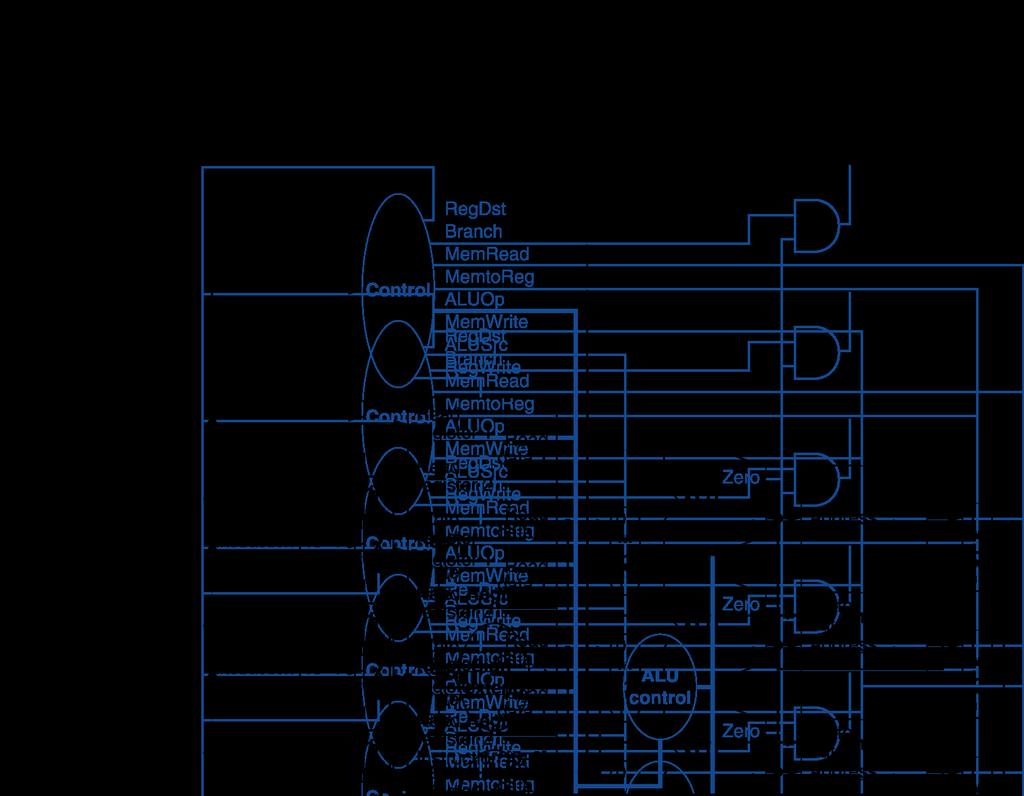
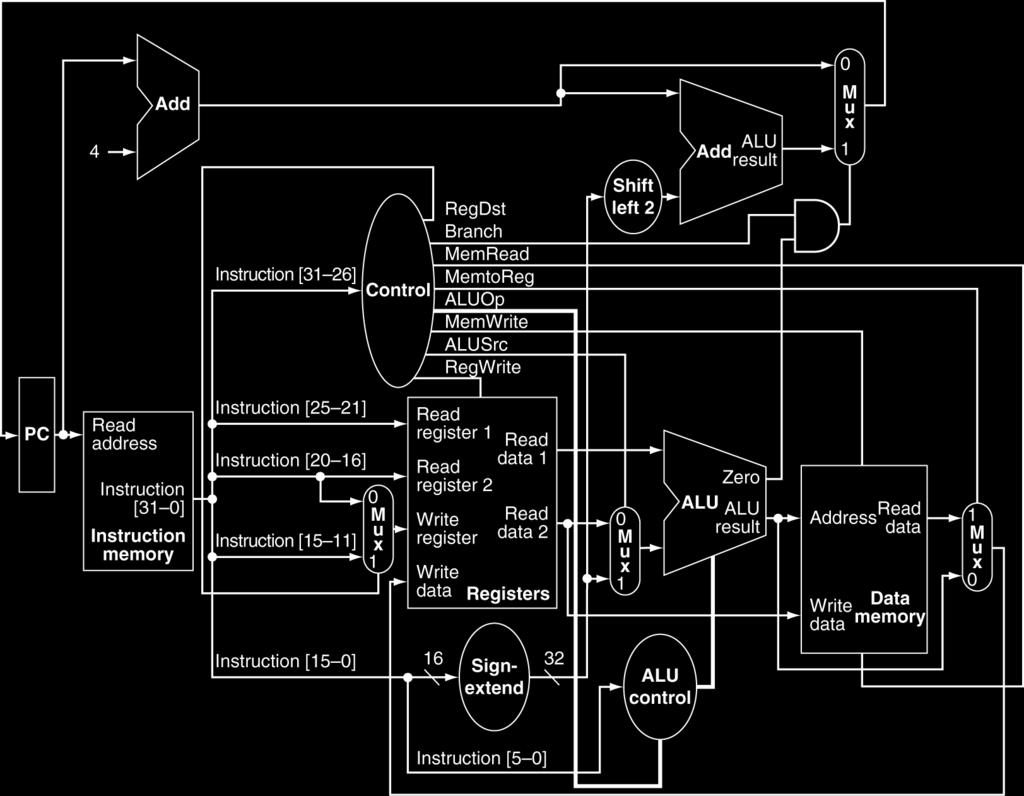
4 MIPS Single-Cycle Datapath (not pipelined yet) 4
 MEM: Data Memory Access WB:")

5 MIPS Pipelined Datapath Single-cycle MIPS datapath can be divided into the classic 5-stage pipeline IF: Instruction Fetch ID: Instruction Decode and Register Read EX: Execution (or address calculation) MEM: Data Memory Access WB: Write Back Divide single-cycle datapath to reduce the amount of combinational logic between sequential elements Place registers between each stage Single-cycle datapath with dashed lines to indicate where stages will be separated 5
6 The MIPS Pipeline a Classic 5-Stage Pipeline Five stages, one step per stage 1) IF: Instruction Fetch from memory Uses PC to address instruction memory and retrieve instruction 2) ID: Instruction decode & register read Controller decodes the instruction while values are retrieved from register file 3) EX: Execute arithmetic operation or calculate address Sometimes referred to as the ALU Stage 4) MEM: Access memory Retrieves value from data memory (if necessary) 5) WB: Write result back to register file Result of arithmetic and load instructions are written back to destination register 6
7 Pipeline Performance Assume time for pipeline stages is as follows: 100 ps for ID and WB; 200 ps for others (IF, EX, MEM) Example Instructions Pipeline Stage Latency (ps) IF ID EX MEM WB Total Latency (ps) lw sw R-Type beq The lw instruction uses all stages of the pipeline If implemented in a single-cycle datapath, requires an 800 ps clock period (1.25 GHz) If implemented in a pipelined datapath, the longest stage of the pipeline determines the clock period 200 ps in the example shown here (5 GHz) Longest stage of the pipeline is the critical path 7

8 Pipeline Performance (continued) Three lw instructions in a single-cycle datapath IF ID EX MEM WB IF ID EX MEM WB Clock period of 800 ps IF Three lw instructions in a pipelined datapath IF ID EX MEM WB IF ID EX MEM WB Clock period of 200 ps IF ID EX MEM WB 8
9 Pipeline Speedup Measured as the time between instructions The amount of time between starting instruction x and starting instruction x+1 If all pipeline stages are balanced (i.e. they all take the same amount of time) Time Between Instructions pipelined = Time Between Instructions nonpipelined Number of Pipeline Stages If pipelined stages are not balanced, then speedup is less Pipeline speedup is due to increased throughput i.e. less time between instructions i.e. more instructions executed per unit time Time to execute each individual instruction does not decrease 9
10 Hazards Situations that prevent starting the next instruction on the next clock cycle Three main types of hazards Structural hazard Next instruction cannot execute because a required hardware resource is busy Data hazard Next instruction needs to wait for previous instruction to complete its data read/write (data dependent) Control hazard Next instruction depends on a control action of previous instruction 10
11 Structural Hazards Next instruction cannot execute because a required hardware resource is busy Conflict for use of a resource Example: if MIPS had only a single memory shared as instruction and data memory Could not read the next instruction while also performing the MEM stage of a load/store instruction Load/store instructions require access to memory Instruction fetch would have to stall for the cycle that load/store accesses memory Stalling instruction fetch would cause a pipeline bubble Pipelined datapaths require separate instruction/data memories Or separate instruction/data caches 11



12 Data Hazards Next instruction needs to wait for previous instruction to complete its data read/write A data dependency exists between the result of one instruction and the next add $s0, $t0, $t1 sub $t2, $s0, $t3 sub instruction requires $s0 as input add instruction will not yet have executed WB stage! Register file will contain stale data for $s0 when sub requests it A naive solution might just stall the pipeline by inserting bubbles, thereby allowing WB of add to happen before ID of sub (there s a better way ) 12
13 Forwarding (a.k.a. Bypassing) (a.k.a. the Better Way) Use the result of an instruction immediately after it is computed Don t wait for it to be stored in a register Requires extra hardware in the datapath (i.e. some wires and control) The result of instruction x is forwarded to instruction x+1 (bypassing the WB stage) The add instruction still completes normally and writes the register file during its WB stage 13

 14")
14 Load-Use Data Hazard Forwarding works very well in many cases, but not all Consider when a lw instruction precedes an instruction that uses the value being loaded Cannot forward data backwards in time!!! Must stall the pipeline and insert a bubble so the output of the MEM stage can be forwarded to the input of the EX stage of the next instruction Stalling the pipeline reduces instruction throughput (i.e. decreases performance) 14
15 Code Scheduling to Avoid Stalls Be a clever programmer and avoid stalls Reorder code to avoid the use of load result in the next instruction Two implementations of the same C code that take different number of clock cycles to complete Sample C Code: a = b + e; c = b + f; Stalls will be required and inserted before these add instructions 5 clock cycles for sw instruction to complete Implementation #1: lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t2 sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1, $t4 sw $t5, 16($t0) Requires 13 clock cycles (Two stalls required) Implementation #2: lw $t1, 0($t0) lw $t2, 4($t0) lw $t4, 8($t0) add $t3, $t1, $t2 sw $t3, 12($t0) add $t5, $t1, $t4 sw $t5, 16($t0) Requires 11 clock cycles (No stalls required) 15
 A branch instruction determines the flow of control in a program The next instruction to fetch and execute after a branch instruction depends on the branch outcome Don t")
16 Control Hazards (a.k.a. Branch Hazard) A branch instruction determines the flow of control in a program The next instruction to fetch and execute after a branch instruction depends on the branch outcome Don t actually know the outcome of a branch instruction until EX stage Pipeline can t always fetch correct instruction (don t really know which instruction to get yet) Pipeline is attempting to fetch next instruction while the branch instruction is still in the ID stage Multiple solutions: Stall until result of branch is determined NYEH HEH HEH Guessing (more common that you d guess) Use a branch delay slot 16

17 Stall on Branch Wait until branch outcome is determined before fetching the next instruction Without any additional hardware, would require a stall of 3 clock cycles for each branch Very inefficient looping behavior! Could add some additional hardware to get result of branch after ID stage of pipeline Would still require a cycle of stalling (see below) 17
 If stall penalty is unacceptable, try to predict the result of a branch before")



18 Branch Prediction (Yes, Guessing!) If stall penalty is unacceptable, try to predict the result of a branch before actual result is available Many implementations will always assume that the branch is NOT taken and fetch the instruction that immediately follows the branch (this is the common case) No stalls are inserted, pipeline continues full speed ahead If the prediction was correct, then no penalty Sometimes prediction will be wrong Stall will need to be inserted if prediction was wrong Result of wrongly fetched/executed instruction discarded In MIPS pipeline Can predict branches not taken Fetches instruction after branch, with no delay 18
 19")
19 MIPS with Predict Not Taken MIPS predict branch not taken behavior when prediction is correct (i.e. branch was not taken and didn t need to be) MIPS predict branch not taken behavior when prediction is incorrect (i.e. branch was not taken but should have been) 19




20 Branch Delay Slots Rearrange instructions and put an arbitrary instruction after the branch instruction Instruction following the branch is always executed Pick an instruction that would have been executed regardless of branch taken/not taken A suitable choice for an instruction to insert into a branch delay slot is the instruction that immediately precedes the branch instruction (assembler can swap the two instructions) Branch instruction cannot depend on result of preceding instruction add $t0, $t0, $t0 beq $s0, $s1, label or $t1, $t0, $t2... beq $s0, $s1, label add $t0, $t0, $t0 or $t1, $t0, $t2... The assembler can swap the add and beq instructions without affecting the programs results. After the assembler rearranges instructions. The add instruction is in the branch delay slot and will always execute. 20
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining: Overview. CPSC 252 Computer Organization Ellen Walker, Hiram College
 Pipelining: Overview CPSC 252 Computer Organization Ellen Walker, Hiram College Pipelining the Wash Divide into 4 steps: Wash, Dry, Fold, Put Away Perform the steps in parallel Wash 1 Wash 2, Dry 1 Wash
Pipelining: Overview CPSC 252 Computer Organization Ellen Walker, Hiram College Pipelining the Wash Divide into 4 steps: Wash, Dry, Fold, Put Away Perform the steps in parallel Wash 1 Wash 2, Dry 1 Wash
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Midnight Laundry. IC220 Set #19: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Return to Chapter 4
 Life. Return to Chapter 4") IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
ECE260: Fundamentals of Computer Engineering
 ECE260: Fundamentals of Computer Engineering Pipelined Datapath and Control James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania ECE260: Fundamentals of Computer Engineering
ECE260: Fundamentals of Computer Engineering Pipelined Datapath and Control James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania ECE260: Fundamentals of Computer Engineering
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
The Processor Pipeline. Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes.
 The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
ECEC 355: Pipelining
 ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
CENG 3531 Computer Architecture Spring a. T / F A processor can have different CPIs for different programs.
 Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
COMPUTER ORGANIZATION AND DESIGN
 ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
ECE260: Fundamentals of Computer Engineering
 Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Data Hazards in a Pipelined Datapath James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Data
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CS 61C: Great Ideas in Computer Architecture. Lecture 13: Pipelining. Krste Asanović & Randy Katz
 CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
Basic Instruction Timings. Pipelining 1. How long would it take to execute the following sequence of instructions?
 Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
Basic Instruction Timings Pipelining 1 Making some assumptions regarding the operation times for some of the basic hardware units in our datapath, we have the following timings: Instruction class Instruction
Lecture 15: Pipelining. Spring 2018 Jason Tang
 Lecture 15: Pipelining Spring 2018 Jason Tang 1 Topics Overview of pipelining Pipeline performance Pipeline hazards 2 Sequential Laundry 6 PM 7 8 9 10 11 Midnight Time T a s k O r d e r A B C D 30 40 20
Lecture 15: Pipelining Spring 2018 Jason Tang 1 Topics Overview of pipelining Pipeline performance Pipeline hazards 2 Sequential Laundry 6 PM 7 8 9 10 11 Midnight Time T a s k O r d e r A B C D 30 40 20
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
COMP2611: Computer Organization. The Pipelined Processor
 COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
ECE 154A Introduction to. Fall 2012
 ECE 154A Introduction to Computer Architecture Fall 2012 Dmitri Strukov Lecture 10 Floating point review Pipelined design IEEE Floating Point Format single: 8 bits double: 11 bits single: 23 bits double:
ECE 154A Introduction to Computer Architecture Fall 2012 Dmitri Strukov Lecture 10 Floating point review Pipelined design IEEE Floating Point Format single: 8 bits double: 11 bits single: 23 bits double:
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Chapter 6 ADMIN. Reading for Chapter 6: 6.1,
 Life. Chapter 6 ADMIN. Reading for Chapter 6: 6.1,") SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Chapter 6 ADMIN ing for Chapter 6: 6., 6.9-6.2 2 Midnight Laundry Task order A 6 PM 7 8 9 0 2 2 AM B C D 3 Smarty
SI232 Set #20: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Chapter 6 ADMIN ing for Chapter 6: 6., 6.9-6.2 2 Midnight Laundry Task order A 6 PM 7 8 9 0 2 2 AM B C D 3 Smarty
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
5 th Edition. The Processor We will examine two MIPS implementations A simplified version A more realistic pipelined version
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
Computer Architecture Review. Jo, Heeseung
 Computer Architecture Review Jo, Heeseung Computer Abstractions and Technology Jo, Heeseung Below Your Program Application software Written in high-level language System software Compiler: translates HLL
Computer Architecture Review Jo, Heeseung Computer Abstractions and Technology Jo, Heeseung Below Your Program Application software Written in high-level language System software Compiler: translates HLL
Pipelining. Maurizio Palesi
 * Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
* Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
Final Exam Fall 2007
 ICS 233 - Computer Architecture & Assembly Language Final Exam Fall 2007 Wednesday, January 23, 2007 7:30 am 10:00 am Computer Engineering Department College of Computer Sciences & Engineering King Fahd
ICS 233 - Computer Architecture & Assembly Language Final Exam Fall 2007 Wednesday, January 23, 2007 7:30 am 10:00 am Computer Engineering Department College of Computer Sciences & Engineering King Fahd
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
Page 1. Pipelining: Its Natural! Chapter 3. Pipelining. Pipelined Laundry Start work ASAP. Sequential Laundry A B C D. 6 PM Midnight
 Pipelining: Its Natural! Chapter 3 Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Pipelining: Its Natural! Chapter 3 Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
What is Pipelining? Time per instruction on unpipelined machine Number of pipe stages
 What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
ECE260: Fundamentals of Computer Engineering
 Datapath for a Simplified Processor James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Introduction
Datapath for a Simplified Processor James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Introduction
Computer Architecture. Lecture 6.1: Fundamentals of
 CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
Chapter 4 (Part II) Sequential Laundry
 Sequential Laundry") Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Improving Performance: Pipelining
 Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Orange Coast College. Business Division. Computer Science Department. CS 116- Computer Architecture. Pipelining
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture Pipelining Recall Pipelining is parallelizing execution Key to speedups in processors Split instruction
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
What is Pipelining? RISC remainder (our assumptions)
") What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
Appendix C: Pipelining: Basic and Intermediate Concepts
 Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
CSCI 402: Computer Architectures. Fengguang Song Department of Computer & Information Science IUPUI. Today s Content
 3/6/8 CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Today s Content We have looked at how to design a Data Path. 4.4, 4.5 We will design
3/6/8 CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Today s Content We have looked at how to design a Data Path. 4.4, 4.5 We will design
Pipeline Review. Review
 Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
These actions may use different parts of the CPU. Pipelining is when the parts run simultaneously on different instructions.
 MIPS Pipe Line 2 Introduction Pipelining To complete an instruction a computer needs to perform a number of actions. These actions may use different parts of the CPU. Pipelining is when the parts run simultaneously
MIPS Pipe Line 2 Introduction Pipelining To complete an instruction a computer needs to perform a number of actions. These actions may use different parts of the CPU. Pipelining is when the parts run simultaneously
Pipeline: Introduction
 Pipeline: Introduction These slides are derived from: CSCE430/830 Computer Architecture course by Prof. Hong Jiang and Dave Patterson UCB Some figures and tables have been derived from : Computer System
Pipeline: Introduction These slides are derived from: CSCE430/830 Computer Architecture course by Prof. Hong Jiang and Dave Patterson UCB Some figures and tables have been derived from : Computer System
CSE Lecture 13/14 In Class Handout For all of these problems: HAS NOT CANNOT Add Add Add must wait until $5 written by previous add;
 CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
CSE 30321 Lecture 13/14 In Class Handout For the sequence of instructions shown below, show how they would progress through the pipeline. For all of these problems: - Stalls are indicated by placing the
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE154A Introduction to Computer Architecture. Homework 4 solution
 ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
ECE473 Computer Architecture and Organization. Pipeline: Control Hazard
 Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Full Datapath. CSCI 402: Computer Architectures. The Processor (2) 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI
 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI") CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
4. What is the average CPI of a 1.4 GHz machine that executes 12.5 million instructions in 12 seconds?
 Chapter 4: Assessing and Understanding Performance 1. Define response (execution) time. 2. Define throughput. 3. Describe why using the clock rate of a processor is a bad way to measure performance. Provide
Chapter 4: Assessing and Understanding Performance 1. Define response (execution) time. 2. Define throughput. 3. Describe why using the clock rate of a processor is a bad way to measure performance. Provide
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Pipelining and Vector Processing
 Chapter 8 Pipelining and Vector Processing 8 1 If the pipeline stages are heterogeneous, the slowest stage determines the flow rate of the entire pipeline. This leads to other stages idling. 8 2 Pipeline
Chapter 8 Pipelining and Vector Processing 8 1 If the pipeline stages are heterogeneous, the slowest stage determines the flow rate of the entire pipeline. This leads to other stages idling. 8 2 Pipeline
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Advanced Instruction-Level Parallelism
 Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Chapter 8. Pipelining
 Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
CS252 Prerequisite Quiz. Solutions Fall 2007
 CS252 Prerequisite Quiz Krste Asanovic Solutions Fall 2007 Problem 1 (29 points) The followings are two code segments written in MIPS64 assembly language: Segment A: Loop: LD r5, 0(r1) # r5 Mem[r1+0] LD
CS252 Prerequisite Quiz Krste Asanovic Solutions Fall 2007 Problem 1 (29 points) The followings are two code segments written in MIPS64 assembly language: Segment A: Loop: LD r5, 0(r1) # r5 Mem[r1+0] LD