FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
|
|
|
- Violet Barber
- 5 years ago
- Views:
Transcription
1 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009
2 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs. Symposium on Application Specific Processors, July, (Best Paper Award) Overview Comparison: FPGA vs GPU vs CPU CUDA FCUDA AutoPilot Results
3 FCUDA: Overview CUDA popular language for programming Nvidia GPUs describes coarse-grained parallelism FCUDA: convert CUDA into annotated C code Use high level synthesis (AutoPilot) to convert C into RTL Synthesize RTL for an FPGA
4 Why FPGAs? FPGAs have higher computational density per Watt than GPUs and CPUs: 32-bit integer arithmetic: 6X higher 32-bit floating point arithmetic: 2X higher

5 Power: FPGA vs GPU vs CPU J. Williams et. al. Computational density of fixed and reconfigurable multi-core devices for application acceleration, RSSI, 2008.

6 Computational Density: FPGA vs GPU vs CPU J. Williams et. al. Computational density of fixed and reconfigurable multi-core devices for application acceleration, RSSI, 2008.

7 CUDA: Compute Unified Device Architecture CUDA is a C API and compiler infrastructure for Nvidia GPUs GPU is a SIMD architecture
8

9 GPU Memory Hierarchy
10 CUDA Example CCode: 1 int main () { for ( int i = 0; i < N; i++) { 4 C[ i ] = A[ i ] + B[ i ]; 5 } 6 } CUDA: 1 int main () { VecAdd<<<1, N>>>(A, B, C) ; 4 } 5 global void VecAdd( float A, float B, float C) { 6 int i = threadidx.x; 7 C[ i ] = A[ i ] + B[ i ]; 8 }
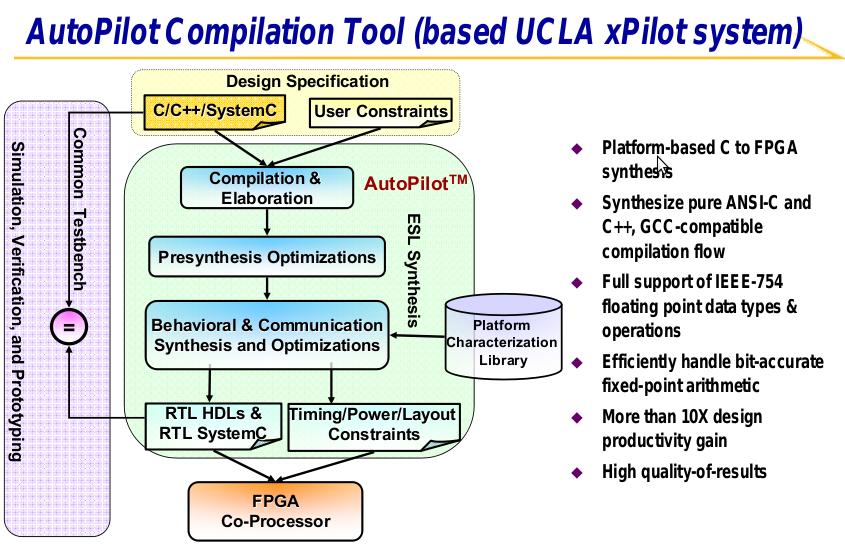
11 AutoPilot
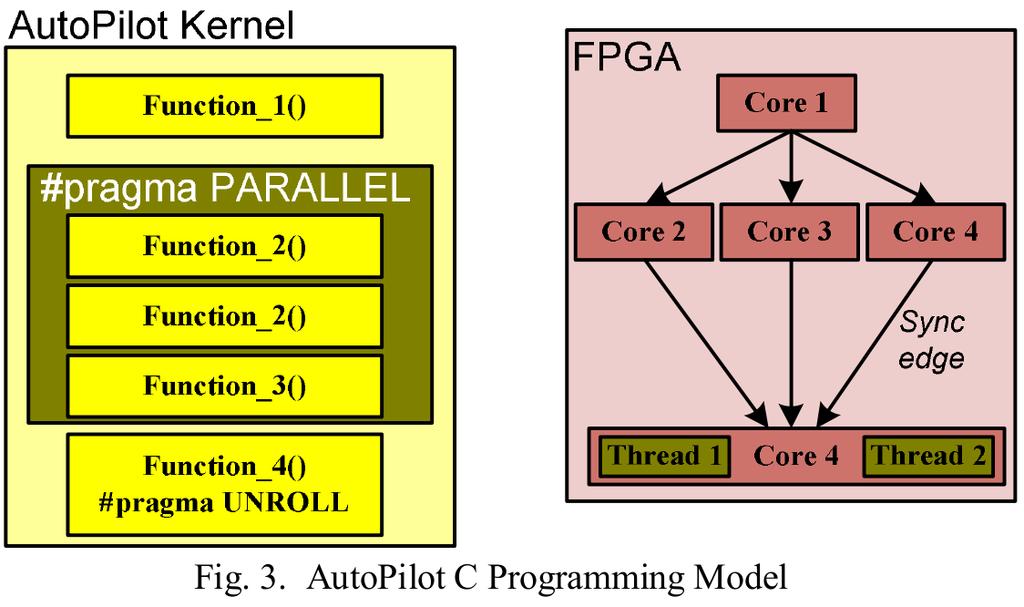
12 AutoPilot

13 FCUDA Map thread-blocks onto parallel FPGA cores Minimize inter-core communication to avoid synchronization FCUDA pragmas: COMPUTE: computation task of kernel TRANSFER: data communication task to off-chip DRAM SYNC: synchronization scheme simple DMA: serialize data communication and computation ping-pong DMA: double BRAMs to allow concurrent data communication and computation
14 Coulombic Potential (CP) CUDA kernel global void cenergy( int numatoms, int gridspacing, int energygrid) { int energyval = 0; 11 for (atomid=0; atomid<numatoms ; atomid++) { e n e r g y v a l += a t o m i n f o [ atomid ]. w r 1; 14 } e n e r g y g r i d [ o u t a d d r ] += e n e r g y v a l ; }
15 FCUDA-annotated CP kernel 1 #pragma FCUDA GRID x dim=2 y dim=1 begin name= cp grid 2 #pragma FCUDA BLOCKS s t a r t x=0 end x=128 start y=0 end y=128 3 #pragma FCUDA SYNC t y p e=s i m p l e 4 global void cenergy( int numatoms, int gridspacing, int energygrid) { int energyval = 0; 11 for (atomid=0; atomid<numatoms ; atomid++) { e n e r g y v a l += a t o m i n f o [ atomid ]. w r 1; 14 } e n e r g y g r i d [ o u t a d d r ] += e n e r g y v a l ; } 20 #pragma FCUDA GRID end name= c p grid
16 FCUDA-annotated CP kernel 1 #pragma FCUDA GRID x dim=2 y dim=1 begin name= cp grid 2 #pragma FCUDA BLOCKS s t a r t x=0 end x=128 start y=0 end y=128 3 #pragma FCUDA SYNC t y p e=s i m p l e 4 global void cenergy( int numatoms, int gridspacing, int energygrid) { #pragma FCUDA COMPUTE c o r e s =2 b e g i n name= c p block int energyval = 0; 11 for (atomid=0; atomid<numatoms ; atomid++) { e n e r g y v a l += a t o m i n f o [ atomid ]. w r 1; 14 } 15 #pragma FCUDA COMPUTE end name= c p block e n e r g y g r i d [ o u t a d d r ] += e n e r g y v a l ; } 20 #pragma FCUDA GRID end name= c p grid
17 FCUDA-annotated CP kernel 1 #pragma FCUDA GRID x dim=2 y dim=1 begin name= cp grid 2 #pragma FCUDA BLOCKS s t a r t x=0 end x=128 start y=0 end y=128 3 #pragma FCUDA SYNC t y p e=s i m p l e 4 global void cenergy( int numatoms, int gridspacing, int energygrid) { 5 #pragma FCUDA TRANSFER c o r e s =1 t y p e=b u r s t b e g i n name= f e t c h 6 #pragma FCUDA DATA t y p e=l o a d from=a t o m i n f o s t a r t =0 end= MAXATOMS 7 #pragma FCUDA TRANSFER end name= f e t c h 8 #pragma FCUDA COMPUTE c o r e s =2 b e g i n name= c p block int energyval = 0; 11 for (atomid=0; atomid<numatoms ; atomid++) { e n e r g y v a l += a t o m i n f o [ atomid ]. w r 1; 14 } 15 #pragma FCUDA COMPUTE end name= c p block 16 #pragma FCUDA TRANSFER c o r e s =1 t y p e=b u r s t b e g i n name= w r i t e 17 e n e r g y g r i d [ o u t a d d r ] += e n e r g y v a l ; 18 #pragma FCUDA TRANSFER end name= w r i t e 19 } 20 #pragma FCUDA GRID end name= c p grid
18 FCUDA compiler passes FCUDA based on Cetus source-to-source compiler Front-end transformations: Convert implicit thread execution into an explicit loop Vectorize local thread variables Back-end transformation: Split tasks into separate AutoPilot functions Wrap parallel function calls with AUTOPILOT REGION PARALLEL pragmas Create DMA burst transfers between off-chip DRAM and on-chip BRAM arrays
19 FCUDA front-end processed CP compute task 1 #pragma FCUDA COMPUTE c o r e s =2 b e g i n name= c p block int energyval = 0; 7 for (atomid=0; atomid<numatoms ; atomid++) { energyval += atominfo [ atomid ].w r 1; 10 } 11 } 12 } 13 #pragma FCUDA COMPUTE end name= c p block
20 FCUDA front-end processed CP compute task 1 #pragma FCUDA COMPUTE c o r e s =2 b e g i n name= c p block 2 int energyval []; 3 for(tidx.y=0;tidx.y<blockdim ; tidx. y++) // thread loop 4 for(tidx.x=0;tidx.x<blockdim ; tidx. x++) { energyval [ tidx ]=0.0 f ; 7 for (atomid=0; atomid<numatoms ; atomid++) { energyval [ tidx ] += atominfo [ atomid ].w r 1; 10 } 11 } 12 } 13 #pragma FCUDA COMPUTE end name= c p block
21 FCUDA-generated AutoPilot code
22 Results: CUDA kernels
23 Results: FPGA kernel characteristics
24 Results: Devices FPGA: Virtex5 XC5VFX200T device (65nm) Over 100K LUTs 2MB of on-chip BlockRAM memory 384 DSP units No specs given for off-chip DRAM Max clock: 550Mhz GPU: Nvidia GeForce 8800 GTX (90nm) 16 Streaming Multiprocessors (SM) and 128 cores. Register File: 32KB/SM = 512KB total Shared (on-chip) memory: 16KB/SM = 256KB total Global (off-chip) memory 768MB, 86.4GB/sec bandwidth Core Clock: 575Mhz,
25 Results: FPGA vs GPU Speedup

26 Results: FPGA vs GPU Power
 Future work: use OpenCL instead of CUDA OpenCL supports for both ATI and Nvidia")
27 Conclusions CUDA to FPGA flow is possible with decent performance No comparison to more recent GPUs (GTX280) Future work: use OpenCL instead of CUDA OpenCL supports for both ATI and Nvidia GPUs
28 Cetus: Source-to-source compiler Cetus is a source-to-source C compiler written in Java Maintained by Purdue University Designed for automatic parallelization Data dependence analysis Control flow graph generation Available at cetus.ecn.purdue.edu Modified Artistic License
29 Cetus: Examples
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
Porting Performance across GPUs and FPGAs
 Porting Performance across GPUs and FPGAs Deming Chen, ECE, University of Illinois In collaboration with Alex Papakonstantinou 1, Karthik Gururaj 2, John Stratton 1, Jason Cong 2, Wen-Mei Hwu 1 1: ECE
Porting Performance across GPUs and FPGAs Deming Chen, ECE, University of Illinois In collaboration with Alex Papakonstantinou 1, Karthik Gururaj 2, John Stratton 1, Jason Cong 2, Wen-Mei Hwu 1 1: ECE
Efficient Compilation of CUDA Kernels for High-Performance Computing on FPGAs
 25 Efficient Compilation of CUDA Kernels for High-Performance Computing on FPGAs ALEXANDROS PAPAKONSTANTINOU, University of Illinois at Urbana-Champaign KARTHIK GURURAJ, University of California, Los Angeles
25 Efficient Compilation of CUDA Kernels for High-Performance Computing on FPGAs ALEXANDROS PAPAKONSTANTINOU, University of Illinois at Urbana-Champaign KARTHIK GURURAJ, University of California, Los Angeles
Lecture 21: High-level Synthesis (2)
") Lecture 21: High-level Synthesis (2) Slides courtesy of Deming Chen Outline Binding for DFG Left-edge algorithm Network flow algorithm Binding to reduce interconnects Simultaneous scheduling and binding
Lecture 21: High-level Synthesis (2) Slides courtesy of Deming Chen Outline Binding for DFG Left-edge algorithm Network flow algorithm Binding to reduce interconnects Simultaneous scheduling and binding
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
FCUDA-SoC: Platform Integration for Field-Programmable SoC with the CUDAto-FPGA
 1 FCUDA-SoC: Platform Integration for Field-Programmable SoC with the CUDAto-FPGA Compiler Tan Nguyen 1, Swathi Gurumani 1, Kyle Rupnow 1, Deming Chen 2 1 Advanced Digital Sciences Center, Singapore {tan.nguyen,
1 FCUDA-SoC: Platform Integration for Field-Programmable SoC with the CUDAto-FPGA Compiler Tan Nguyen 1, Swathi Gurumani 1, Kyle Rupnow 1, Deming Chen 2 1 Advanced Digital Sciences Center, Singapore {tan.nguyen,
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
 Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Real-time Graphics 9. GPGPU
 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Multilevel Granularity Parallelism Synthesis on FPGAs
 Multilevel Granularity Parallelism Synthesis on FPGAs Alexandros Papakonstantinou, Yun Liang 2, John A. Stratton, Karthik Gururaj 3, Deming Chen, Wen-Mei W. Hwu, Jason Cong 3 Electrical & Computer Eng.
Multilevel Granularity Parallelism Synthesis on FPGAs Alexandros Papakonstantinou, Yun Liang 2, John A. Stratton, Karthik Gururaj 3, Deming Chen, Wen-Mei W. Hwu, Jason Cong 3 Electrical & Computer Eng.
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
GPU Particle-Grid Methods: Electrostatics
 GPU Particle-Grid Methods: Electrostatics John Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of Illinois at Urbana-Champaign Research/gpu/
GPU Particle-Grid Methods: Electrostatics John Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of Illinois at Urbana-Champaign Research/gpu/
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CS179 GPU Programming Introduction to CUDA. Lecture originally by Luke Durant and Tamas Szalay
 Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA
 Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
S05: High Performance Computing with CUDA. Case Study: Molecular Visualization and Analysis
 Case Study: Molecular Visualization and Analysis John Stone NIH Resource for Macromolecular Modeling and Bioinformatics http://www.ks.uiuc.edu/research/gpu/ Outline What speedups can be expected Fluorescence
Case Study: Molecular Visualization and Analysis John Stone NIH Resource for Macromolecular Modeling and Bioinformatics http://www.ks.uiuc.edu/research/gpu/ Outline What speedups can be expected Fluorescence
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Unrolling parallel loops
 Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
A Cross-Input Adaptive Framework for GPU Program Optimizations
 A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Shared Memory and Synchronizations
 and Synchronizations Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Technology SM can be accessed by all threads within a block (but not across blocks) Threads within a block can
and Synchronizations Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Technology SM can be accessed by all threads within a block (but not across blocks) Threads within a block can
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System
 Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CS 179: GPU Programming
 CS 179: GPU Programming Introduction Lecture originally written by Luke Durant, Tamas Szalay, Russell McClellan What We Will Cover Programming GPUs, of course: OpenGL Shader Language (GLSL) Compute Unified
CS 179: GPU Programming Introduction Lecture originally written by Luke Durant, Tamas Szalay, Russell McClellan What We Will Cover Programming GPUs, of course: OpenGL Shader Language (GLSL) Compute Unified
When MPPDB Meets GPU:
 When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Lecture 6. Programming with Message Passing Message Passing Interface (MPI)
") Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
Exploring OpenCL Memory Throughput on the Zynq
 Exploring OpenCL Memory Throughput on the Zynq Technical Report no. 2016:04, ISSN 1652-926X Chalmers University of Technology Bo Joel Svensson bo.joel.svensson@gmail.com Abstract The Zynq platform combines
Exploring OpenCL Memory Throughput on the Zynq Technical Report no. 2016:04, ISSN 1652-926X Chalmers University of Technology Bo Joel Svensson bo.joel.svensson@gmail.com Abstract The Zynq platform combines
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
EECS 583 Class 20 Research Topic 2: Stream Compilation, GPU Compilation
 EECS 583 Class 20 Research Topic 2: Stream Compilation, GPU Compilation University of Michigan December 3, 2012 Guest Speakers Today: Daya Khudia and Mehrzad Samadi nnouncements & Reading Material Exams
EECS 583 Class 20 Research Topic 2: Stream Compilation, GPU Compilation University of Michigan December 3, 2012 Guest Speakers Today: Daya Khudia and Mehrzad Samadi nnouncements & Reading Material Exams
Graphics Processor Acceleration and YOU
 Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Administrivia. HW0 scores, HW1 peer-review assignments out. If you re having Cython trouble with HW2, let us know.
 Administrivia HW0 scores, HW1 peer-review assignments out. HW2 out, due Nov. 2. If you re having Cython trouble with HW2, let us know. Review on Wednesday: Post questions on Piazza Introduction to GPUs
Administrivia HW0 scores, HW1 peer-review assignments out. HW2 out, due Nov. 2. If you re having Cython trouble with HW2, let us know. Review on Wednesday: Post questions on Piazza Introduction to GPUs
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
CUDA. GPU Computing. K. Cooper 1. 1 Department of Mathematics. Washington State University
 GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, DRAM Bandwidth
 Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Objective. GPU Teaching Kit. OpenACC. To understand the OpenACC programming model. Introduction to OpenACC
 GPU Teaching Kit Accelerated Computing OpenACC Introduction to OpenACC Objective To understand the OpenACC programming model basic concepts and pragma types simple examples 2 2 OpenACC The OpenACC Application
GPU Teaching Kit Accelerated Computing OpenACC Introduction to OpenACC Objective To understand the OpenACC programming model basic concepts and pragma types simple examples 2 2 OpenACC The OpenACC Application
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing