HO #13 Fall 2015 Gary Chan. Hashing (N:12)
|
|
|
- Samantha Tucker
- 5 years ago
- Views:
Transcription
1 HO #13 Fall 2015 Gary Chan Hashing (N:12)
2 Outline Motivation Hashing Algorithms and Improving the Hash Functions Collisions Strategies Open addressing and linear probing Separate chaining COMP2012H (Hashing) 2
3 Breaking the lower bound on comparison-based search 3
4 Re-thinking Keys Again Tree structures discussed so far assume that we can only use the number (key) for comparisons, no other operations on the keys are considered In practice, however, the keys can be decomposed into smaller units, for example: 1. Integers consists of digits: can be used as array index 2. Strings consist of letters: We may even perform arithmetic operations on the letters COMP2012H (Hashing) 4
5 5

6 Reducing Space with a Hash Table 6
7 Hashing Concept Given a key in the key universe, compute an index into a hash table Index is computed using a hash function Index = hash_function( Key ) This is an ultra-fast way to search! Time complexity O(1). What are the things we need to consider? 1. What is a good hash function for the key. 2. Table size is limited, some keys may map to the same location! (We call this a collision) Need to resolve collisions. Hash Table COMP2012H (Hashing) 7
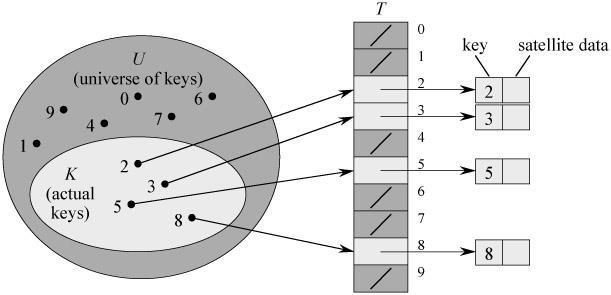
8 General Terms and Conditions Universe U = {u 0, u 1,..., u n-1 } It is relatively easy or efficient to compute some index given a key Hash support operations: Find() Insert() Delete() Deletions may be unnecessary in some apps COMP2012H (Hashing) 8
9 Hash Tables vs. Trees Hash tables are only for problems that require fast search Unlike trees No notion of order remember a tree is sorted if we visit the nodes in-order No notion of successor or predecessor in the data structure Not efficient to find the range min() and max() elements Hash tables are generally implemented using an array structure with fixed size. COMP2012H (Hashing) 9
10 Example Applications Compilers use hash tables to keep track of declared variables On-line spell checkers We can hash an entire dictionary (or the most common words) Allows us to quickly check if words are spelled correctly in constant time COMP2012H (Hashing) 10
11 Bit Vector Representation for O(1) Operations N-2 N-1 entry = 0 if key u i is absent; otherwise entry = 1 Find: test entry Insert: Set entry to 1 Delete: Set entry to 0 Constant time each, independent of the number of keys! COMP2012H (Hashing) 11
12 Strengths and Weaknesses Advantages Simple implementation Operation can be translated into machine instruction Disadvantages Need a bit vector as large as the key space Wastes too much space in general, especially when the number of actual keys is much smaller than the universe E.g., in a dictionary with words of at most 10 characters, we need a bit vector size of ~ 1.4 x bits = 17.6 Tbytes --- This is very large, too large to be held in memory for efficient indexing! In reality, the number of words (keys) is much much smaller than that, i.e., about 200,000 words, and hence we really do not need so much memory to index all the words. COMP2012H (Hashing) 12
13 Hashing Let {K 0, K 1,...K N } be the universe of keys Let T[0..m-1] be an array representing the hash table, where m is much smaller than N. The most important part of hashing is the hash function: h: Key universe -> [0..m-1] For each key K, h(k) is called the hash value of K and K is supposed to be stored at T[h(K)] COMP2012H (Hashing) 13
14 Hashing There are two aspects to the hashing We should design the hash function such that it spreads the keys uniformly among the entries of T. This will decrease the likelihood that two keys have the same hash values Need a solution when the keys do collide COMP2012H (Hashing) 14
15 Example of a Hash Function Suppose a dictionary of words, and that our keys are a string of letters. Let s consider a letter equals its ASCII value Key = c n-1 c n-2... c o For example: A = 65, Z = 90, a = 97, z = 122 Our hash function: h( c n n 1 i c0) ( ci )% m (This simply adds the string s characters values up and takes the modulus by m, where m is the size of the hash table.) COMP2012H (Hashing) 15
16 Why is This a Bad Hash Function? Hash function: This hash function yields the same results for any permutation of the string h( c n h( CAT ) = h( ACT ) = h( TAC ) n 1 i c0) ( ci )% m English words have many examples of valid permutations similar to the above Need a way to consider the position of the characters in the string COMP2012H (Hashing) 16
17 Improving the Hash Function We can improve the hash function so that the letters contribute differently according to their positions. h( c n n 1 i0 i 1... c0) ( ci * r )% m r is the radix Integers: r = 10 Bit strings: r = 2 Strings: r = 128 Weight by the i th position COMP2012H (Hashing) 17
18 Computing the Hash value Need to be careful about overflows in summing up the terms, since we may add up to a large number We can do all computations in modulo arithmetic by taking modulus at each step For example: sum = 0; for (int j=0; j < n-1; i++) sum = (sum + (c_j * r^j) % m ) % m; Take modulus at each step. Also for the values r^j, you can pre-compute a table to store these values. COMP2012H (Hashing) 18
19 Rule of Thumbs on Hash Functions Hash table size is generally prime Reduces collision due to the modulus operator (% m) Example: m = 10 (not prime) m=13 (prime) 100 % 10 -> % 13 -> % 10 -> % 13 -> % 10 -> % 13 -> 1 m should not divide, for some small integral values of k or a. As a counter example, if one makes m=r-1 (i.e., m divides r -1), then all permutations of the same character string have the same hash value When we compute hash functions of strings For speed, we often only use a fixed number of elements Such as the first 5 characters of the string example Brown Schwarzenegger Fong r k a -> h( Brown ) -> h( Schwa ) -> h( FongX ) For short words, we could use dummy character (like X), or 0, COMP2012H (Hashing) 19
20 Linear Open Addressing When the key range is too large to use the ideal method, we use a hash table whose size is smaller than the range and a hash function that maps several keys into the same position of the hash table The hash function has the form h(k) = x(k) % D where x(k) is the computed value based on key k D is the size (i.e., number of positions) of the hash table Each position is called a bucket h(k) is the home bucket COMP2012H (Hashing) 20
21 Linear Open Addressing In case of collision, search for the next available bucket The search for the next available bucket is made by regarding the table as circular The choice of D has a significant effect on the performance of hashing Best results are obtained when D is either a prime number or has no prime factors less than 20 COMP2012H (Hashing) 21
22 Open Addressing via Linear Probing: Insertion Compute the home bucket L = h(k) if T[L] is not empty, consider the hash table as circular: for( i = 0; i < m; i++ ) compute L = ( h(k) + i ) % m; if T[L] is empty, put K there and stop If we can t find a position (the table is completely full), return an error message COMP2012H (Hashing) 22
23 An Example D = 11 Add 58: Collision with 80 Add 24 Add 35: Collision with 24 Insertion of 13 will join two clusters COMP2012H (Hashing) 23
24 Searching Search begins at the home bucket h(k) for the key k Continues by examining successive buckets in the table by regarding the table as circular until one of the following happens 1. A bucket containing the element with key k is reached; in this case, we found the element; 2. An empty bucket is reached; in which case, the element is not found 3. We return to the home bucket; in which case, the element is not found COMP2012H (Hashing) 24
25 Hash Functions Strategies for improved performance: 1. Increase table capacity (less collisions) 2. Use a different collision resolution technique (e.g., hierarchical hashing where hashing the second time on the home bucket) 3. Use a different hash function Hash table capacity Size of table is better to be at least1.5 to 2 times the size of the number of items to be stored Otherwise probability of collisions is too high COMP2012H (Hashing) 25
26 Clustering in Linear Probing We call a block of contiguously occupied table entries a cluster Linear probing becomes slow when large clusters begin to form (primary clustering) For example: Once h(k) falls into a cluster, the cluster will definitely grow in size by 1 Larger clusters are easier targets for collision in the future If two clusters are only separated by one entry, then inserting one key into a cluster can merge the two clusters COMP2012H (Hashing) 26
27 Deletion May require several movement: we cannot simply make the position empty. E.g., consider deleting Move begins just after the bucket vacated by the deleted element. We need to rehash buckets one by one in the remainder of the cluster. Clearly, it may lead to a lot of movements involving at worst the whole table (of O(m), where m is the size of the table) To reduce rehashing overhead, we can simply mark the entry empty, which means treating it belonging to the cluster but skipping it in a cluster inspection We need to distinguish it from the never-used bucket at the cluster boundary COMP2012H (Hashing) 27
28 Introduction of a NeverUsed Field A more efficient alternative to reduce move Introduce the field NeverUsed in each bucket Lazy moving or lazy rehashing NeverUsed can have only 3 values: {true, false, empty} If the entry has never been occupied, NeverUsed is true NeverUsed is set to true initially When an element is inserted/placed in the bucket, NeverUsed is set to false Meaning that the bucket has a valid element When an element is deleted We simply mark the deleted space as empty An empty slot belongs to a cluster but search can simply skip those empty buckets in a cluster An element can be inserted into the empty slot later, turning the NeverUsed to false Therefore, deletion may be accomplished by simply setting the position empty without any data rehashing NeverUsed field is never reset to true, and hence over time NeverUsed field of the buckets will be either false or empty COMP2012H (Hashing) 28
29 Introduction of a NeverUsed Field A new element may be inserted into the first empty or true bucket encountered after the home bucket true (start) insertion false insertion deletion empty For an unsuccessful search, the condition for search to terminate is when the NeverUsed field equals to true (not empty as it belongs to the cluster) Which is a bucket never been used before After a while, almost all buckets have this NeverUsed field equal to false or empty, and unsuccessful searches examine all buckets To improve performance, we must reorganize the table by, for example, rehashing into a new fresh table COMP2012H (Hashing) 29
30 Hash ADT (No NeverUsed and Deletion) (1/6) // file hash.h #ifndef HashTable_ #define HashTable_ #include <iostream.h> #include <stdlib.h> #include "xcept.h" // E is the record // K is the key template<class E, class K> class HashTable { public: HashTable(int divisor = 11); // constructor ~HashTable() {delete [] ht; delete [] empty;} bool Search(const K& k, E& e) const; HashTable<E,K>& Insert(const E& e); void Output();// output the hash table // rehashing needs to be done everytime a record is deleted private: int hsearch(const K& k) const; // helper function for Search and Insert int D; // hash function divisor; hash table size E *ht; // hash table array bool *empty; // 1D array on whether the entry is empty or not }; COMP2012H (Hashing) 30
31 Hash ADT (No Deletion Method) (2/6) // constructor template<class E, class K> HashTable<E,K>::HashTable(int divisor) {// Constructor. D = divisor; // allocate hash table arrays ht = new E [D]; // holding records empty = new bool [D]; // set all buckets to state true for (int i = 0; i < D; i++) empty[i] = true; // no keys/records there } COMP2012H (Hashing) 31
32 Hash ADT (No Deletion Method) (3/6) // Intermediate function for Search and Insert // Search an open addressed table. // Return an array index corresponding to ONE of the following 3 cases: // Case 1. If no match, return the next empty bucket from home bucket of k // Case 2. If matched, return the matched bucket of k // Case 3. If no match and a full hash table, its non-empty home bucket template<class E, class K> int HashTable<E,K>::hSearch(const K& k) const { int i = k % D; // home bucket int j = i; // start at home bucket do { // if end of a cluster or a match, return j // Should overload key casting for ht[j] == k if (empty[j] ht[j] == k) return j; // Case 1 or 2 j = (j + 1) % D; // linearly probe the next bucket } while (j!= i); // returned to home? } return j; // Case 3: wrapped around, table is full, i.e., j == i COMP2012H (Hashing) 32
33 Hash ADT (No Deletion Method) (4/6) template<class E, class K> bool HashTable<E,K>::Search(const K& k, E& e) const { // Put element that matches k in e. // Return false if no match. int b = hsearch(k); } if (empty[b] ht[b]!= k) // implicit cast on ht[b] return false; // not found e = ht[b]; // need assignment operator return true; COMP2012H (Hashing) 33
34 Hash ADT (No Deletion Method) (5/6) template<class E, class K> HashTable<E,K>& HashTable<E,K>::Insert(const E& e) { // Hash table insert. K k = e; // extract key by casting int b = hsearch(k); // check if insert is to be done if (empty[b]) { // Case 1: not found empty[b] = false; ht[b] = e; return *this;} } // no insert, check if duplicate or full if (ht[b] == k) throw BadInput(); // Case 2: duplicate throw NoMem(); // Case 3: table full, cannot insert COMP2012H (Hashing) 34
35 Hash ADT (No Deletion Method) (6/6) template<class E, class K> void HashTable<E,K>::Output() { for (int i = 0; i< D; i++) { if (empty[i]) cout << "empty" << endl; else cout << ht[i] << endl; // need << overloading } } #endif COMP2012H (Hashing) 35
36 Open Addressing: Linear Probing Vulnerable to clustering Contiguous occupied positions are easy targets for collisions Cluster grows as collision occurs Clusters may merge with each other This results in increased expected search time Need to spread out the clusters COMP2012H (Hashing) 36
37 Performance Let b be the number of buckets in the hash table n elements are present in the table Worst case search and insert time is Θ(n) (all n keys have the same home bucket) Average performance: U n and S n be the average number of buckets examined during an unsuccessful and successful search, respectively, and α = n/b be the load factor: U n α 2 S n α COMP2012H (Hashing) 37
38 An Application Example A hash table is to store up to 1,000 elements. Need to find its hash table size. Successful searches should require no more than 4 bucket examination on average and unsuccessful searches should examine no more than 50.5 buckets on average i.e., S n <= 4 α <= 6/7 i.e., U n <= 50.5 α <= 0.9 We hence require α = min(6/7, 0.9) = 6/7 and therefore b >= 1167 We choose D to be = 1369 (no prime factors less than 20) COMP2012H (Hashing) 38
39 Quadratic Probing Insertion Compute L = h(k) Quadric jump away from its home bucket If T[L] is not empty: for( i = 0; i < m; i++ ) compute L = ( h(k) + i*i ) % m; if T[L] is empty, put K there and stop Helps to eliminate primary clustering However, if the table gets too full, this approach is not guaranteed of finding an empty slot! It may also never visit the home bucket again. COMP2012H (Hashing) 39
40 Double Hashing To alleviate the problem of primary clustering Use a second hash function h 2 when collision occurs Resolve collision by choosing the subsequent positions with a constant offset independent of the primary position Incrementally jump away from its home bucket in constant step size depending on the key H(K i, 0) = h(ki) H(K i, 1) = (H(K i, 0) + h 2 (K i )) mod m H(K i, 2) = (H(K i, 1) + h 2 (K i )) mod m... H(K i,m) = (H(K i,m 1) +h 2 (K i )) mod m COMP2012H (Hashing) 40
41 Choice of h 2 For any key K, h 2 (K) must be relatively prime to the table size m Otherwise, we will only be able to examine a fraction of the table entries For example, if h 2 (K) = m/2 (not relatively prime to m), then for h(k) = 0 we can only examine the entries T[0] and T[m/2] and nothing else! The only solution is to make m prime, and choose r to be a prime smaller than m, and set h 2 (K) = r (K mod r) E.g., if m = 37, we may pick r = 23 and hence h 2 (K) = 23 K mod 23 We may as well use r = 11, and hence h 2 (K) = 11 K mod 11 COMP2012H (Hashing) 41
42 Analysis of Open Addressing for Uniform Hashing 42
43 Analysis of Open Addressing for Uniform Hashing (Cont.) 43

44 Collision Resolution by Chaining 44
45 Hashing With Chains: Separate Chaining Maintaining chains of elements that have the same home bucket As each insert is preceded by a search, it is more efficient to maintain the chains in ascending order of the key values One needs to check two conditions: while ( (node!= NULL) && (node -> key < search_key)) 0 1 / 2 / 3 4 / / / / COMP2012H (Hashing) 45
46 Improved Implementation Adding a tail node to the end of each chain with key at least as large as any element to be inserted into the table Make comparisons more efficient as no NULL comparison is needed (while (node->key < search_key) ) / / / / / / COMP2012H (Hashing) 46
47 Space Requirement: Linear Probing vs. Separate Chaining n records of size s bytes; pointer of size p bytes; int takes q bytes Hash table has b>=n buckets Space requirement Chaining: bp + n(s+p) Open linear addressing: b(s + q) (empty is an integer array) Chaining takes less space than linear addressing whenever n < b(s+q-p)/(s+p) The expected performance is superior to that of linear open addressing COMP2012H (Hashing) 47
48 Dynamic Hash Tables 48
49 Chaining Analysis 49
50 Comparison between BST and hash tables BST Hash tables Comparison-based Non-comparison-based Keys stored in sorted order More operations are supported: min, max, neighbor, traversal Can be augmented to support range queries In C++: std::map Keys stored in arbitrary order Only search, insert, delete Do not support range queries In C++: std::unordered_map 50
51 Remarks on Hashing Ultra-fast searching method Best case O(1) (constant time) to find a key Very useful algorithm that requires intensive searching Like spell-checker Some database applications will build temporary hash tables for quickaccess to data Limited operations as compared to trees Only provides insert, search, and possibly delete No notion of order, min, max, etc. COMP2012H (Hashing) 51
Hash Table and Hashing
 Hash Table and Hashing The tree structures discussed so far assume that we can only work with the input keys by comparing them. No other operation is considered. In practice, it is often true that an input
Hash Table and Hashing The tree structures discussed so far assume that we can only work with the input keys by comparing them. No other operation is considered. In practice, it is often true that an input
COMP171. Hashing.
 COMP171 Hashing Hashing 2 Hashing Again, a (dynamic) set of elements in which we do search, insert, and delete Linear ones: lists, stacks, queues, Nonlinear ones: trees, graphs (relations between elements
COMP171 Hashing Hashing 2 Hashing Again, a (dynamic) set of elements in which we do search, insert, and delete Linear ones: lists, stacks, queues, Nonlinear ones: trees, graphs (relations between elements
Hashing. Hashing Procedures
 Hashing Hashing Procedures Let us denote the set of all possible key values (i.e., the universe of keys) used in a dictionary application by U. Suppose an application requires a dictionary in which elements
Hashing Hashing Procedures Let us denote the set of all possible key values (i.e., the universe of keys) used in a dictionary application by U. Suppose an application requires a dictionary in which elements
Topic HashTable and Table ADT
 Topic HashTable and Table ADT Hashing, Hash Function & Hashtable Search, Insertion & Deletion of elements based on Keys So far, By comparing keys! Linear data structures Non-linear data structures Time
Topic HashTable and Table ADT Hashing, Hash Function & Hashtable Search, Insertion & Deletion of elements based on Keys So far, By comparing keys! Linear data structures Non-linear data structures Time
Hash Table. A hash function h maps keys of a given type into integers in a fixed interval [0,m-1]
![Hash Table. A hash function h maps keys of a given type into integers in a fixed interval [0,m-1]](/thumbs/82/85322795.jpg "Hash Table. A hash function h maps keys of a given type into integers in a fixed interval [0,m-1]") Exercise # 8- Hash Tables Hash Tables Hash Function Uniform Hash Hash Table Direct Addressing A hash function h maps keys of a given type into integers in a fixed interval [0,m-1] 1 Pr h( key) i, where
Exercise # 8- Hash Tables Hash Tables Hash Function Uniform Hash Hash Table Direct Addressing A hash function h maps keys of a given type into integers in a fixed interval [0,m-1] 1 Pr h( key) i, where
Cpt S 223. School of EECS, WSU
 Hashing & Hash Tables 1 Overview Hash Table Data Structure : Purpose To support insertion, deletion and search in average-case constant t time Assumption: Order of elements irrelevant ==> data structure
Hashing & Hash Tables 1 Overview Hash Table Data Structure : Purpose To support insertion, deletion and search in average-case constant t time Assumption: Order of elements irrelevant ==> data structure
Hash[ string key ] ==> integer value
![Hash[ string key ] ==> integer value](/thumbs/92/108296526.jpg "Hash[ string key ] ==> integer value") Hashing 1 Overview Hash[ string key ] ==> integer value Hash Table Data Structure : Use-case To support insertion, deletion and search in average-case constant time Assumption: Order of elements irrelevant
Hashing 1 Overview Hash[ string key ] ==> integer value Hash Table Data Structure : Use-case To support insertion, deletion and search in average-case constant time Assumption: Order of elements irrelevant
Chapter 20 Hash Tables
 Chapter 20 Hash Tables Dictionary All elements have a unique key. Operations: o Insert element with a specified key. o Search for element by key. o Delete element by key. Random vs. sequential access.
Chapter 20 Hash Tables Dictionary All elements have a unique key. Operations: o Insert element with a specified key. o Search for element by key. o Delete element by key. Random vs. sequential access.
General Idea. Key could be an integer, a string, etc e.g. a name or Id that is a part of a large employee structure
 Hashing 1 Hash Tables We ll discuss the hash table ADT which supports only a subset of the operations allowed by binary search trees. The implementation of hash tables is called hashing. Hashing is a technique
Hashing 1 Hash Tables We ll discuss the hash table ADT which supports only a subset of the operations allowed by binary search trees. The implementation of hash tables is called hashing. Hashing is a technique
Hashing. CptS 223 Advanced Data Structures. Larry Holder School of Electrical Engineering and Computer Science Washington State University
 Hashing CptS 223 Advanced Data Structures Larry Holder School of Electrical Engineering and Computer Science Washington State University 1 Overview Hashing Technique supporting insertion, deletion and
Hashing CptS 223 Advanced Data Structures Larry Holder School of Electrical Engineering and Computer Science Washington State University 1 Overview Hashing Technique supporting insertion, deletion and
AAL 217: DATA STRUCTURES
 Chapter # 4: Hashing AAL 217: DATA STRUCTURES The implementation of hash tables is frequently called hashing. Hashing is a technique used for performing insertions, deletions, and finds in constant average
Chapter # 4: Hashing AAL 217: DATA STRUCTURES The implementation of hash tables is frequently called hashing. Hashing is a technique used for performing insertions, deletions, and finds in constant average
Successful vs. Unsuccessful
 Hashing Search Given: Distinct keys k 1, k 2,, k n and collection T of n records of the form (k 1, I 1 ), (k 2, I 2 ),, (k n, I n ) where I j is the information associated with key k j for 1
Hashing Search Given: Distinct keys k 1, k 2,, k n and collection T of n records of the form (k 1, I 1 ), (k 2, I 2 ),, (k n, I n ) where I j is the information associated with key k j for 1
Hashing Techniques. Material based on slides by George Bebis
 Hashing Techniques Material based on slides by George Bebis https://www.cse.unr.edu/~bebis/cs477/lect/hashing.ppt The Search Problem Find items with keys matching a given search key Given an array A, containing
Hashing Techniques Material based on slides by George Bebis https://www.cse.unr.edu/~bebis/cs477/lect/hashing.ppt The Search Problem Find items with keys matching a given search key Given an array A, containing
Data Structures and Algorithms. Roberto Sebastiani
 Data Structures and Algorithms Roberto Sebastiani roberto.sebastiani@disi.unitn.it http://www.disi.unitn.it/~rseba - Week 07 - B.S. In Applied Computer Science Free University of Bozen/Bolzano academic
Data Structures and Algorithms Roberto Sebastiani roberto.sebastiani@disi.unitn.it http://www.disi.unitn.it/~rseba - Week 07 - B.S. In Applied Computer Science Free University of Bozen/Bolzano academic
Data Structures and Algorithms. Chapter 7. Hashing
 1 Data Structures and Algorithms Chapter 7 Werner Nutt 2 Acknowledgments The course follows the book Introduction to Algorithms, by Cormen, Leiserson, Rivest and Stein, MIT Press [CLRST]. Many examples
1 Data Structures and Algorithms Chapter 7 Werner Nutt 2 Acknowledgments The course follows the book Introduction to Algorithms, by Cormen, Leiserson, Rivest and Stein, MIT Press [CLRST]. Many examples
CMSC 341 Hashing (Continued) Based on slides from previous iterations of this course
 Based on slides from previous iterations of this course") CMSC 341 Hashing (Continued) Based on slides from previous iterations of this course Today s Topics Review Uses and motivations of hash tables Major concerns with hash tables Properties Hash function Hash
CMSC 341 Hashing (Continued) Based on slides from previous iterations of this course Today s Topics Review Uses and motivations of hash tables Major concerns with hash tables Properties Hash function Hash
Fundamental Algorithms
 Fundamental Algorithms Chapter 7: Hash Tables Michael Bader Winter 2011/12 Chapter 7: Hash Tables, Winter 2011/12 1 Generalised Search Problem Definition (Search Problem) Input: a sequence or set A of
Fundamental Algorithms Chapter 7: Hash Tables Michael Bader Winter 2011/12 Chapter 7: Hash Tables, Winter 2011/12 1 Generalised Search Problem Definition (Search Problem) Input: a sequence or set A of
Worst-case running time for RANDOMIZED-SELECT
 Worst-case running time for RANDOMIZED-SELECT is ), even to nd the minimum The algorithm has a linear expected running time, though, and because it is randomized, no particular input elicits the worst-case
Worst-case running time for RANDOMIZED-SELECT is ), even to nd the minimum The algorithm has a linear expected running time, though, and because it is randomized, no particular input elicits the worst-case
CSE100. Advanced Data Structures. Lecture 21. (Based on Paul Kube course materials)
") CSE100 Advanced Data Structures Lecture 21 (Based on Paul Kube course materials) CSE 100 Collision resolution strategies: linear probing, double hashing, random hashing, separate chaining Hash table cost
CSE100 Advanced Data Structures Lecture 21 (Based on Paul Kube course materials) CSE 100 Collision resolution strategies: linear probing, double hashing, random hashing, separate chaining Hash table cost
Introducing Hashing. Chapter 21. Copyright 2012 by Pearson Education, Inc. All rights reserved
 Introducing Hashing Chapter 21 Contents What Is Hashing? Hash Functions Computing Hash Codes Compressing a Hash Code into an Index for the Hash Table A demo of hashing (after) ARRAY insert hash index =
Introducing Hashing Chapter 21 Contents What Is Hashing? Hash Functions Computing Hash Codes Compressing a Hash Code into an Index for the Hash Table A demo of hashing (after) ARRAY insert hash index =
Lecture 16. Reading: Weiss Ch. 5 CSE 100, UCSD: LEC 16. Page 1 of 40
 Lecture 16 Hashing Hash table and hash function design Hash functions for integers and strings Collision resolution strategies: linear probing, double hashing, random hashing, separate chaining Hash table
Lecture 16 Hashing Hash table and hash function design Hash functions for integers and strings Collision resolution strategies: linear probing, double hashing, random hashing, separate chaining Hash table
Practical Session 8- Hash Tables
 Practical Session 8- Hash Tables Hash Function Uniform Hash Hash Table Direct Addressing A hash function h maps keys of a given type into integers in a fixed interval [0,m-1] 1 Pr h( key) i, where m is
Practical Session 8- Hash Tables Hash Function Uniform Hash Hash Table Direct Addressing A hash function h maps keys of a given type into integers in a fixed interval [0,m-1] 1 Pr h( key) i, where m is
HashTable CISC5835, Computer Algorithms CIS, Fordham Univ. Instructor: X. Zhang Fall 2018
 HashTable CISC5835, Computer Algorithms CIS, Fordham Univ. Instructor: X. Zhang Fall 2018 Acknowledgement The set of slides have used materials from the following resources Slides for textbook by Dr. Y.
HashTable CISC5835, Computer Algorithms CIS, Fordham Univ. Instructor: X. Zhang Fall 2018 Acknowledgement The set of slides have used materials from the following resources Slides for textbook by Dr. Y.
Hashing. October 19, CMPE 250 Hashing October 19, / 25
 Hashing October 19, 2016 CMPE 250 Hashing October 19, 2016 1 / 25 Dictionary ADT Data structure with just three basic operations: finditem (i): find item with key (identifier) i insert (i): insert i into
Hashing October 19, 2016 CMPE 250 Hashing October 19, 2016 1 / 25 Dictionary ADT Data structure with just three basic operations: finditem (i): find item with key (identifier) i insert (i): insert i into
TABLES AND HASHING. Chapter 13
 Data Structures Dr Ahmed Rafat Abas Computer Science Dept, Faculty of Computer and Information, Zagazig University arabas@zu.edu.eg http://www.arsaliem.faculty.zu.edu.eg/ TABLES AND HASHING Chapter 13
Data Structures Dr Ahmed Rafat Abas Computer Science Dept, Faculty of Computer and Information, Zagazig University arabas@zu.edu.eg http://www.arsaliem.faculty.zu.edu.eg/ TABLES AND HASHING Chapter 13
! A Hash Table is used to implement a set, ! The table uses a function that maps an. ! The function is called a hash function.
 Hash Tables Chapter 20 CS 3358 Summer II 2013 Jill Seaman Sections 201, 202, 203, 204 (not 2042), 205 1 What are hash tables?! A Hash Table is used to implement a set, providing basic operations in constant
Hash Tables Chapter 20 CS 3358 Summer II 2013 Jill Seaman Sections 201, 202, 203, 204 (not 2042), 205 1 What are hash tables?! A Hash Table is used to implement a set, providing basic operations in constant
Hashing. Manolis Koubarakis. Data Structures and Programming Techniques
 Hashing Manolis Koubarakis 1 The Symbol Table ADT A symbol table T is an abstract storage that contains table entries that are either empty or are pairs of the form (K, I) where K is a key and I is some
Hashing Manolis Koubarakis 1 The Symbol Table ADT A symbol table T is an abstract storage that contains table entries that are either empty or are pairs of the form (K, I) where K is a key and I is some
III Data Structures. Dynamic sets
 III Data Structures Elementary Data Structures Hash Tables Binary Search Trees Red-Black Trees Dynamic sets Sets are fundamental to computer science Algorithms may require several different types of operations
III Data Structures Elementary Data Structures Hash Tables Binary Search Trees Red-Black Trees Dynamic sets Sets are fundamental to computer science Algorithms may require several different types of operations
Hash Tables Outline. Definition Hash functions Open hashing Closed hashing. Efficiency. collision resolution techniques. EECS 268 Programming II 1
 Hash Tables Outline Definition Hash functions Open hashing Closed hashing collision resolution techniques Efficiency EECS 268 Programming II 1 Overview Implementation style for the Table ADT that is good
Hash Tables Outline Definition Hash functions Open hashing Closed hashing collision resolution techniques Efficiency EECS 268 Programming II 1 Overview Implementation style for the Table ADT that is good
Introduction hashing: a technique used for storing and retrieving information as quickly as possible.
 Lecture IX: Hashing Introduction hashing: a technique used for storing and retrieving information as quickly as possible. used to perform optimal searches and is useful in implementing symbol tables. Why
Lecture IX: Hashing Introduction hashing: a technique used for storing and retrieving information as quickly as possible. used to perform optimal searches and is useful in implementing symbol tables. Why
HASH TABLES. Hash Tables Page 1
 HASH TABLES TABLE OF CONTENTS 1. Introduction to Hashing 2. Java Implementation of Linear Probing 3. Maurer s Quadratic Probing 4. Double Hashing 5. Separate Chaining 6. Hash Functions 7. Alphanumeric
HASH TABLES TABLE OF CONTENTS 1. Introduction to Hashing 2. Java Implementation of Linear Probing 3. Maurer s Quadratic Probing 4. Double Hashing 5. Separate Chaining 6. Hash Functions 7. Alphanumeric
Hashing. 1. Introduction. 2. Direct-address tables. CmSc 250 Introduction to Algorithms
 Hashing CmSc 250 Introduction to Algorithms 1. Introduction Hashing is a method of storing elements in a table in a way that reduces the time for search. Elements are assumed to be records with several
Hashing CmSc 250 Introduction to Algorithms 1. Introduction Hashing is a method of storing elements in a table in a way that reduces the time for search. Elements are assumed to be records with several
Algorithms with numbers (2) CISC4080, Computer Algorithms CIS, Fordham Univ.! Instructor: X. Zhang Spring 2017
 CISC4080, Computer Algorithms CIS, Fordham Univ.! Instructor: X. Zhang Spring 2017") Algorithms with numbers (2) CISC4080, Computer Algorithms CIS, Fordham Univ.! Instructor: X. Zhang Spring 2017 Acknowledgement The set of slides have used materials from the following resources Slides
Algorithms with numbers (2) CISC4080, Computer Algorithms CIS, Fordham Univ.! Instructor: X. Zhang Spring 2017 Acknowledgement The set of slides have used materials from the following resources Slides
Algorithms with numbers (2) CISC4080, Computer Algorithms CIS, Fordham Univ. Acknowledgement. Support for Dictionary
 CISC4080, Computer Algorithms CIS, Fordham Univ. Acknowledgement. Support for Dictionary") Algorithms with numbers (2) CISC4080, Computer Algorithms CIS, Fordham Univ. Instructor: X. Zhang Spring 2017 Acknowledgement The set of slides have used materials from the following resources Slides for
Algorithms with numbers (2) CISC4080, Computer Algorithms CIS, Fordham Univ. Instructor: X. Zhang Spring 2017 Acknowledgement The set of slides have used materials from the following resources Slides for
DATA STRUCTURES/UNIT 3
 UNIT III SORTING AND SEARCHING 9 General Background Exchange sorts Selection and Tree Sorting Insertion Sorts Merge and Radix Sorts Basic Search Techniques Tree Searching General Search Trees- Hashing.
UNIT III SORTING AND SEARCHING 9 General Background Exchange sorts Selection and Tree Sorting Insertion Sorts Merge and Radix Sorts Basic Search Techniques Tree Searching General Search Trees- Hashing.
CMSC 341 Lecture 16/17 Hashing, Parts 1 & 2
 CMSC 341 Lecture 16/17 Hashing, Parts 1 & 2 Prof. John Park Based on slides from previous iterations of this course Today s Topics Overview Uses and motivations of hash tables Major concerns with hash
CMSC 341 Lecture 16/17 Hashing, Parts 1 & 2 Prof. John Park Based on slides from previous iterations of this course Today s Topics Overview Uses and motivations of hash tables Major concerns with hash
Data Structure Lecture#22: Searching 3 (Chapter 9) U Kang Seoul National University
 U Kang Seoul National University") Data Structure Lecture#22: Searching 3 (Chapter 9) U Kang Seoul National University U Kang 1 In This Lecture Motivation of collision resolution policy Open hashing for collision resolution Closed hashing
Data Structure Lecture#22: Searching 3 (Chapter 9) U Kang Seoul National University U Kang 1 In This Lecture Motivation of collision resolution policy Open hashing for collision resolution Closed hashing
Algorithms and Data Structures
 Lesson 4: Sets, Dictionaries and Hash Tables Luciano Bononi http://www.cs.unibo.it/~bononi/ (slide credits: these slides are a revised version of slides created by Dr. Gabriele D Angelo)
Lesson 4: Sets, Dictionaries and Hash Tables Luciano Bononi http://www.cs.unibo.it/~bononi/ (slide credits: these slides are a revised version of slides created by Dr. Gabriele D Angelo)
Algorithms and Data Structures
 Algorithms and Data Structures Open Hashing Ulf Leser Open Hashing Open Hashing: Store all values inside hash table A General framework No collision: Business as usual Collision: Chose another index and
Algorithms and Data Structures Open Hashing Ulf Leser Open Hashing Open Hashing: Store all values inside hash table A General framework No collision: Business as usual Collision: Chose another index and
Comp 335 File Structures. Hashing
 Comp 335 File Structures Hashing What is Hashing? A process used with record files that will try to achieve O(1) (i.e. constant) access to a record s location in the file. An algorithm, called a hash function
Comp 335 File Structures Hashing What is Hashing? A process used with record files that will try to achieve O(1) (i.e. constant) access to a record s location in the file. An algorithm, called a hash function
Today s Outline. CS 561, Lecture 8. Direct Addressing Problem. Hash Tables. Hash Tables Trees. Jared Saia University of New Mexico
 Today s Outline CS 561, Lecture 8 Jared Saia University of New Mexico Hash Tables Trees 1 Direct Addressing Problem Hash Tables If universe U is large, storing the array T may be impractical Also much
Today s Outline CS 561, Lecture 8 Jared Saia University of New Mexico Hash Tables Trees 1 Direct Addressing Problem Hash Tables If universe U is large, storing the array T may be impractical Also much
BBM371& Data*Management. Lecture 6: Hash Tables
 BBM371& Data*Management Lecture 6: Hash Tables 8.11.2018 Purpose of using hashes A generalization of ordinary arrays: Direct access to an array index is O(1), can we generalize direct access to any key
BBM371& Data*Management Lecture 6: Hash Tables 8.11.2018 Purpose of using hashes A generalization of ordinary arrays: Direct access to an array index is O(1), can we generalize direct access to any key
Understand how to deal with collisions
 Understand the basic structure of a hash table and its associated hash function Understand what makes a good (and a bad) hash function Understand how to deal with collisions Open addressing Separate chaining
Understand the basic structure of a hash table and its associated hash function Understand what makes a good (and a bad) hash function Understand how to deal with collisions Open addressing Separate chaining
CS 270 Algorithms. Oliver Kullmann. Generalising arrays. Direct addressing. Hashing in general. Hashing through chaining. Reading from CLRS for week 7
 Week 9 General remarks tables 1 2 3 We continue data structures by discussing hash tables. Reading from CLRS for week 7 1 Chapter 11, Sections 11.1, 11.2, 11.3. 4 5 6 Recall: Dictionaries Applications
Week 9 General remarks tables 1 2 3 We continue data structures by discussing hash tables. Reading from CLRS for week 7 1 Chapter 11, Sections 11.1, 11.2, 11.3. 4 5 6 Recall: Dictionaries Applications
CITS2200 Data Structures and Algorithms. Topic 15. Hash Tables
 CITS2200 Data Structures and Algorithms Topic 15 Hash Tables Introduction to hashing basic ideas Hash functions properties, 2-universal functions, hashing non-integers Collision resolution bucketing and
CITS2200 Data Structures and Algorithms Topic 15 Hash Tables Introduction to hashing basic ideas Hash functions properties, 2-universal functions, hashing non-integers Collision resolution bucketing and
Fast Lookup: Hash tables
 CSE 100: HASHING Operations: Find (key based look up) Insert Delete Fast Lookup: Hash tables Consider the 2-sum problem: Given an unsorted array of N integers, find all pairs of elements that sum to a
CSE 100: HASHING Operations: Find (key based look up) Insert Delete Fast Lookup: Hash tables Consider the 2-sum problem: Given an unsorted array of N integers, find all pairs of elements that sum to a
CS 241 Analysis of Algorithms
 CS 241 Analysis of Algorithms Professor Eric Aaron Lecture T Th 9:00am Lecture Meeting Location: OLB 205 Business HW5 extended, due November 19 HW6 to be out Nov. 14, due November 26 Make-up lecture: Wed,
CS 241 Analysis of Algorithms Professor Eric Aaron Lecture T Th 9:00am Lecture Meeting Location: OLB 205 Business HW5 extended, due November 19 HW6 to be out Nov. 14, due November 26 Make-up lecture: Wed,
ECE 242 Data Structures and Algorithms. Hash Tables II. Lecture 25. Prof.
 ECE 242 Data Structures and Algorithms http://www.ecs.umass.edu/~polizzi/teaching/ece242/ Hash Tables II Lecture 25 Prof. Eric Polizzi Summary previous lecture Hash Tables Motivation: optimal insertion
ECE 242 Data Structures and Algorithms http://www.ecs.umass.edu/~polizzi/teaching/ece242/ Hash Tables II Lecture 25 Prof. Eric Polizzi Summary previous lecture Hash Tables Motivation: optimal insertion
CS 310 Hash Tables, Page 1. Hash Tables. CS 310 Hash Tables, Page 2
 CS 310 Hash Tables, Page 1 Hash Tables key value key value Hashing Function CS 310 Hash Tables, Page 2 The hash-table data structure achieves (near) constant time searching by wasting memory space. the
CS 310 Hash Tables, Page 1 Hash Tables key value key value Hashing Function CS 310 Hash Tables, Page 2 The hash-table data structure achieves (near) constant time searching by wasting memory space. the
Hashing. Introduction to Data Structures Kyuseok Shim SoEECS, SNU.
 Hashing Introduction to Data Structures Kyuseok Shim SoEECS, SNU. 1 8.1 INTRODUCTION Binary search tree (Chapter 5) GET, INSERT, DELETE O(n) Balanced binary search tree (Chapter 10) GET, INSERT, DELETE
Hashing Introduction to Data Structures Kyuseok Shim SoEECS, SNU. 1 8.1 INTRODUCTION Binary search tree (Chapter 5) GET, INSERT, DELETE O(n) Balanced binary search tree (Chapter 10) GET, INSERT, DELETE
Hash Tables. Hashing Probing Separate Chaining Hash Function
 Hash Tables Hashing Probing Separate Chaining Hash Function Introduction In Chapter 4 we saw: linear search O( n ) binary search O( log n ) Can we improve the search operation to achieve better than O(
Hash Tables Hashing Probing Separate Chaining Hash Function Introduction In Chapter 4 we saw: linear search O( n ) binary search O( log n ) Can we improve the search operation to achieve better than O(
Introduction. hashing performs basic operations, such as insertion, better than other ADTs we ve seen so far
 Chapter 5 Hashing 2 Introduction hashing performs basic operations, such as insertion, deletion, and finds in average time better than other ADTs we ve seen so far 3 Hashing a hash table is merely an hashing
Chapter 5 Hashing 2 Introduction hashing performs basic operations, such as insertion, deletion, and finds in average time better than other ADTs we ve seen so far 3 Hashing a hash table is merely an hashing
DATA STRUCTURES AND ALGORITHMS
 LECTURE 11 Babeş - Bolyai University Computer Science and Mathematics Faculty 2017-2018 In Lecture 9-10... Hash tables ADT Stack ADT Queue ADT Deque ADT Priority Queue Hash tables Today Hash tables 1 Hash
LECTURE 11 Babeş - Bolyai University Computer Science and Mathematics Faculty 2017-2018 In Lecture 9-10... Hash tables ADT Stack ADT Queue ADT Deque ADT Priority Queue Hash tables Today Hash tables 1 Hash
Symbol Table. Symbol table is used widely in many applications. dictionary is a kind of symbol table data dictionary is database management
 Hashing Symbol Table Symbol table is used widely in many applications. dictionary is a kind of symbol table data dictionary is database management In general, the following operations are performed on
Hashing Symbol Table Symbol table is used widely in many applications. dictionary is a kind of symbol table data dictionary is database management In general, the following operations are performed on
Dictionary. Dictionary. stores key-value pairs. Find(k) Insert(k, v) Delete(k) List O(n) O(1) O(n) Sorted Array O(log n) O(n) O(n)
 Insert(k, v) Delete(k) List O(n) O(1) O(n) Sorted Array O(log n) O(n) O(n)") Hash-Tables Introduction Dictionary Dictionary stores key-value pairs Find(k) Insert(k, v) Delete(k) List O(n) O(1) O(n) Sorted Array O(log n) O(n) O(n) Balanced BST O(log n) O(log n) O(log n) Dictionary
Hash-Tables Introduction Dictionary Dictionary stores key-value pairs Find(k) Insert(k, v) Delete(k) List O(n) O(1) O(n) Sorted Array O(log n) O(n) O(n) Balanced BST O(log n) O(log n) O(log n) Dictionary
Week 9. Hash tables. 1 Generalising arrays. 2 Direct addressing. 3 Hashing in general. 4 Hashing through chaining. 5 Hash functions.
 Week 9 tables 1 2 3 ing in ing in ing 4 ing 5 6 General remarks We continue data structures by discussing hash tables. For this year, we only consider the first four sections (not sections and ). Only
Week 9 tables 1 2 3 ing in ing in ing 4 ing 5 6 General remarks We continue data structures by discussing hash tables. For this year, we only consider the first four sections (not sections and ). Only
Lecture 10 March 4. Goals: hashing. hash functions. closed hashing. application of hashing
 Lecture 10 March 4 Goals: hashing hash functions chaining closed hashing application of hashing Computing hash function for a string Horner s rule: (( (a 0 x + a 1 ) x + a 2 ) x + + a n-2 )x + a n-1 )
Lecture 10 March 4 Goals: hashing hash functions chaining closed hashing application of hashing Computing hash function for a string Horner s rule: (( (a 0 x + a 1 ) x + a 2 ) x + + a n-2 )x + a n-1 )
5. Hashing. 5.1 General Idea. 5.2 Hash Function. 5.3 Separate Chaining. 5.4 Open Addressing. 5.5 Rehashing. 5.6 Extendible Hashing. 5.
 5. Hashing 5.1 General Idea 5.2 Hash Function 5.3 Separate Chaining 5.4 Open Addressing 5.5 Rehashing 5.6 Extendible Hashing Malek Mouhoub, CS340 Fall 2004 1 5. Hashing Sequential access : O(n). Binary
5. Hashing 5.1 General Idea 5.2 Hash Function 5.3 Separate Chaining 5.4 Open Addressing 5.5 Rehashing 5.6 Extendible Hashing Malek Mouhoub, CS340 Fall 2004 1 5. Hashing Sequential access : O(n). Binary
COSC160: Data Structures Hashing Structures. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Data Structures Hashing Structures Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Hashing Structures I. Motivation and Review II. Hash Functions III. HashTables I. Implementations
COSC160: Data Structures Hashing Structures Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Hashing Structures I. Motivation and Review II. Hash Functions III. HashTables I. Implementations
Acknowledgement HashTable CISC4080, Computer Algorithms CIS, Fordham Univ.
 Acknowledgement HashTable CISC4080, Computer Algorithms CIS, Fordham Univ. Instructor: X. Zhang Spring 2018 The set of slides have used materials from the following resources Slides for textbook by Dr.
Acknowledgement HashTable CISC4080, Computer Algorithms CIS, Fordham Univ. Instructor: X. Zhang Spring 2018 The set of slides have used materials from the following resources Slides for textbook by Dr.
HASH TABLES. Goal is to store elements k,v at index i = h k
 CH 9.2 : HASH TABLES 1 ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN C++, GOODRICH, TAMASSIA AND MOUNT (WILEY 2004) AND SLIDES FROM JORY DENNY AND
CH 9.2 : HASH TABLES 1 ACKNOWLEDGEMENT: THESE SLIDES ARE ADAPTED FROM SLIDES PROVIDED WITH DATA STRUCTURES AND ALGORITHMS IN C++, GOODRICH, TAMASSIA AND MOUNT (WILEY 2004) AND SLIDES FROM JORY DENNY AND
Hash Tables. Computer Science S-111 Harvard University David G. Sullivan, Ph.D. Data Dictionary Revisited
 Unit 9, Part 4 Hash Tables Computer Science S-111 Harvard University David G. Sullivan, Ph.D. Data Dictionary Revisited We've considered several data structures that allow us to store and search for data
Unit 9, Part 4 Hash Tables Computer Science S-111 Harvard University David G. Sullivan, Ph.D. Data Dictionary Revisited We've considered several data structures that allow us to store and search for data
CSE 214 Computer Science II Searching
 CSE 214 Computer Science II Searching Fall 2017 Stony Brook University Instructor: Shebuti Rayana shebuti.rayana@stonybrook.edu http://www3.cs.stonybrook.edu/~cse214/sec02/ Introduction Searching in a
CSE 214 Computer Science II Searching Fall 2017 Stony Brook University Instructor: Shebuti Rayana shebuti.rayana@stonybrook.edu http://www3.cs.stonybrook.edu/~cse214/sec02/ Introduction Searching in a
Unit #5: Hash Functions and the Pigeonhole Principle
 Unit #5: Hash Functions and the Pigeonhole Principle CPSC 221: Basic Algorithms and Data Structures Jan Manuch 217S1: May June 217 Unit Outline Constant-Time Dictionaries? Hash Table Outline Hash Functions
Unit #5: Hash Functions and the Pigeonhole Principle CPSC 221: Basic Algorithms and Data Structures Jan Manuch 217S1: May June 217 Unit Outline Constant-Time Dictionaries? Hash Table Outline Hash Functions
Hashing Algorithms. Hash functions Separate Chaining Linear Probing Double Hashing
 Hashing Algorithms Hash functions Separate Chaining Linear Probing Double Hashing Symbol-Table ADT Records with keys (priorities) basic operations insert search create test if empty destroy copy generic
Hashing Algorithms Hash functions Separate Chaining Linear Probing Double Hashing Symbol-Table ADT Records with keys (priorities) basic operations insert search create test if empty destroy copy generic
DS ,21. L11-12: Hashmap
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-16,21 L11-12: Hashmap Yogesh Simmhan s i m m h a n @ c d s.
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-16,21 L11-12: Hashmap Yogesh Simmhan s i m m h a n @ c d s.
Design Patterns for Data Structures. Chapter 9.5. Hash Tables
 Hash Tables Binary information representation 0 0000 8 1000 1 0001 9 1001 2 0010 A 1010 3 0011 B 1011 4 0100 C 1100 5 0101 D 1101 6 0110 E 1110 7 0111 F 1111 (a) Hexadecimal abbreviation for binary values.
Hash Tables Binary information representation 0 0000 8 1000 1 0001 9 1001 2 0010 A 1010 3 0011 B 1011 4 0100 C 1100 5 0101 D 1101 6 0110 E 1110 7 0111 F 1111 (a) Hexadecimal abbreviation for binary values.
9/24/ Hash functions
 11.3 Hash functions A good hash function satis es (approximately) the assumption of SUH: each key is equally likely to hash to any of the slots, independently of the other keys We typically have no way
11.3 Hash functions A good hash function satis es (approximately) the assumption of SUH: each key is equally likely to hash to any of the slots, independently of the other keys We typically have no way
stacks operation array/vector linked list push amortized O(1) Θ(1) pop Θ(1) Θ(1) top Θ(1) Θ(1) isempty Θ(1) Θ(1)
 Θ(1) pop Θ(1) Θ(1) top Θ(1) Θ(1) isempty Θ(1) Θ(1)") Hashes 1 lists 2 operation array/vector linked list find (by value) Θ(n) Θ(n) insert (end) amortized O(1) Θ(1) insert (beginning/middle) Θ(n) Θ(1) remove (by value) Θ(n) Θ(n) find (by index) Θ(1) Θ(1)
Hashes 1 lists 2 operation array/vector linked list find (by value) Θ(n) Θ(n) insert (end) amortized O(1) Θ(1) insert (beginning/middle) Θ(n) Θ(1) remove (by value) Θ(n) Θ(n) find (by index) Θ(1) Θ(1)
CS1020 Data Structures and Algorithms I Lecture Note #15. Hashing. For efficient look-up in a table
 CS1020 Data Structures and Algorithms I Lecture Note #15 Hashing For efficient look-up in a table Objectives 1 To understand how hashing is used to accelerate table lookup 2 To study the issue of collision
CS1020 Data Structures and Algorithms I Lecture Note #15 Hashing For efficient look-up in a table Objectives 1 To understand how hashing is used to accelerate table lookup 2 To study the issue of collision
Tirgul 7. Hash Tables. In a hash table, we allocate an array of size m, which is much smaller than U (the set of keys).
.") Tirgul 7 Find an efficient implementation of a dynamic collection of elements with unique keys Supported Operations: Insert, Search and Delete. The keys belong to a universal group of keys, U = {1... M}.
Tirgul 7 Find an efficient implementation of a dynamic collection of elements with unique keys Supported Operations: Insert, Search and Delete. The keys belong to a universal group of keys, U = {1... M}.
CMSC 341 Hashing. Based on slides from previous iterations of this course
 CMSC 341 Hashing Based on slides from previous iterations of this course Hashing Searching n Consider the problem of searching an array for a given value q If the array is not sorted, the search requires
CMSC 341 Hashing Based on slides from previous iterations of this course Hashing Searching n Consider the problem of searching an array for a given value q If the array is not sorted, the search requires
Chapter 5 Hashing. Introduction. Hashing. Hashing Functions. hashing performs basic operations, such as insertion,
 Introduction Chapter 5 Hashing hashing performs basic operations, such as insertion, deletion, and finds in average time 2 Hashing a hash table is merely an of some fixed size hashing converts into locations
Introduction Chapter 5 Hashing hashing performs basic operations, such as insertion, deletion, and finds in average time 2 Hashing a hash table is merely an of some fixed size hashing converts into locations
Hashing. mapping data to tables hashing integers and strings. aclasshash_table inserting and locating strings. inserting and locating strings
 Hashing 1 Hash Functions mapping data to tables hashing integers and strings 2 Open Addressing aclasshash_table inserting and locating strings 3 Chaining aclasshash_table inserting and locating strings
Hashing 1 Hash Functions mapping data to tables hashing integers and strings 2 Open Addressing aclasshash_table inserting and locating strings 3 Chaining aclasshash_table inserting and locating strings
Hash Open Indexing. Data Structures and Algorithms CSE 373 SP 18 - KASEY CHAMPION 1
 Hash Open Indexing Data Structures and Algorithms CSE 373 SP 18 - KASEY CHAMPION 1 Warm Up Consider a StringDictionary using separate chaining with an internal capacity of 10. Assume our buckets are implemented
Hash Open Indexing Data Structures and Algorithms CSE 373 SP 18 - KASEY CHAMPION 1 Warm Up Consider a StringDictionary using separate chaining with an internal capacity of 10. Assume our buckets are implemented
Algorithms in Systems Engineering ISE 172. Lecture 12. Dr. Ted Ralphs
 Algorithms in Systems Engineering ISE 172 Lecture 12 Dr. Ted Ralphs ISE 172 Lecture 12 1 References for Today s Lecture Required reading Chapter 5 References CLRS Chapter 11 D.E. Knuth, The Art of Computer
Algorithms in Systems Engineering ISE 172 Lecture 12 Dr. Ted Ralphs ISE 172 Lecture 12 1 References for Today s Lecture Required reading Chapter 5 References CLRS Chapter 11 D.E. Knuth, The Art of Computer
Table ADT and Sorting. Algorithm topics continuing (or reviewing?) CS 24 curriculum
 CS 24 curriculum") Table ADT and Sorting Algorithm topics continuing (or reviewing?) CS 24 curriculum A table ADT (a.k.a. Dictionary, Map) Table public interface: // Put information in the table, and a unique key to identify
Table ADT and Sorting Algorithm topics continuing (or reviewing?) CS 24 curriculum A table ADT (a.k.a. Dictionary, Map) Table public interface: // Put information in the table, and a unique key to identify
Hashing. Dr. Ronaldo Menezes Hugo Serrano. Ronaldo Menezes, Florida Tech
 Hashing Dr. Ronaldo Menezes Hugo Serrano Agenda Motivation Prehash Hashing Hash Functions Collisions Separate Chaining Open Addressing Motivation Hash Table Its one of the most important data structures
Hashing Dr. Ronaldo Menezes Hugo Serrano Agenda Motivation Prehash Hashing Hash Functions Collisions Separate Chaining Open Addressing Motivation Hash Table Its one of the most important data structures
Introduction to Hashing
 Lecture 11 Hashing Introduction to Hashing We have learned that the run-time of the most efficient search in a sorted list can be performed in order O(lg 2 n) and that the most efficient sort by key comparison
Lecture 11 Hashing Introduction to Hashing We have learned that the run-time of the most efficient search in a sorted list can be performed in order O(lg 2 n) and that the most efficient sort by key comparison
Lecture 7: Efficient Collections via Hashing
 Lecture 7: Efficient Collections via Hashing These slides include material originally prepared by Dr. Ron Cytron, Dr. Jeremy Buhler, and Dr. Steve Cole. 1 Announcements Lab 6 due Friday Lab 7 out tomorrow
Lecture 7: Efficient Collections via Hashing These slides include material originally prepared by Dr. Ron Cytron, Dr. Jeremy Buhler, and Dr. Steve Cole. 1 Announcements Lab 6 due Friday Lab 7 out tomorrow
CS/COE 1501
 CS/COE 1501 www.cs.pitt.edu/~lipschultz/cs1501/ Hashing Wouldn t it be wonderful if... Search through a collection could be accomplished in Θ(1) with relatively small memory needs? Lets try this: Assume
CS/COE 1501 www.cs.pitt.edu/~lipschultz/cs1501/ Hashing Wouldn t it be wonderful if... Search through a collection could be accomplished in Θ(1) with relatively small memory needs? Lets try this: Assume
Data Structures - CSCI 102. CS102 Hash Tables. Prof. Tejada. Copyright Sheila Tejada
 CS102 Hash Tables Prof. Tejada 1 Vectors, Linked Lists, Stack, Queues, Deques Can t provide fast insertion/removal and fast lookup at the same time The Limitations of Data Structure Binary Search Trees,
CS102 Hash Tables Prof. Tejada 1 Vectors, Linked Lists, Stack, Queues, Deques Can t provide fast insertion/removal and fast lookup at the same time The Limitations of Data Structure Binary Search Trees,
HASH TABLES.
 1 HASH TABLES http://en.wikipedia.org/wiki/hash_table 2 Hash Table A hash table (or hash map) is a data structure that maps keys (identifiers) into a certain location (bucket) A hash function changes the
1 HASH TABLES http://en.wikipedia.org/wiki/hash_table 2 Hash Table A hash table (or hash map) is a data structure that maps keys (identifiers) into a certain location (bucket) A hash function changes the
This lecture. Iterators ( 5.4) Maps. Maps. The Map ADT ( 8.1) Comparison to java.util.map
 Maps. Maps. The Map ADT ( 8.1) Comparison to java.util.map") This lecture Iterators Hash tables Formal coursework Iterators ( 5.4) An iterator abstracts the process of scanning through a collection of elements Methods of the ObjectIterator ADT: object object() boolean
This lecture Iterators Hash tables Formal coursework Iterators ( 5.4) An iterator abstracts the process of scanning through a collection of elements Methods of the ObjectIterator ADT: object object() boolean
Lecture 6: Hashing Steven Skiena
 Lecture 6: Hashing Steven Skiena Department of Computer Science State University of New York Stony Brook, NY 11794 4400 http://www.cs.stonybrook.edu/ skiena Dictionary / Dynamic Set Operations Perhaps
Lecture 6: Hashing Steven Skiena Department of Computer Science State University of New York Stony Brook, NY 11794 4400 http://www.cs.stonybrook.edu/ skiena Dictionary / Dynamic Set Operations Perhaps
1. [1 pt] What is the solution to the recurrence T(n) = 2T(n-1) + 1, T(1) = 1
![1. [1 pt] What is the solution to the recurrence T(n) = 2T(n-1) + 1, T(1) = 1](/thumbs/85/92778785.jpg "1. [1 pt] What is the solution to the recurrence T(n) = 2T(n-1) + 1, T(1) = 1") Asymptotics, Recurrence and Basic Algorithms 1. [1 pt] What is the solution to the recurrence T(n) = 2T(n-1) + 1, T(1) = 1 2. O(n) 2. [1 pt] What is the solution to the recurrence T(n) = T(n/2) + n, T(1)
Asymptotics, Recurrence and Basic Algorithms 1. [1 pt] What is the solution to the recurrence T(n) = 2T(n-1) + 1, T(1) = 1 2. O(n) 2. [1 pt] What is the solution to the recurrence T(n) = T(n/2) + n, T(1)
Module 2: Classical Algorithm Design Techniques
 Module 2: Classical Algorithm Design Techniques Dr. Natarajan Meghanathan Associate Professor of Computer Science Jackson State University Jackson, MS 39217 E-mail: natarajan.meghanathan@jsums.edu Module
Module 2: Classical Algorithm Design Techniques Dr. Natarajan Meghanathan Associate Professor of Computer Science Jackson State University Jackson, MS 39217 E-mail: natarajan.meghanathan@jsums.edu Module
CS 3114 Data Structures and Algorithms READ THIS NOW!
 READ THIS NOW! Print your name in the space provided below. There are 7 short-answer questions, priced as marked. The maximum score is 100. This examination is closed book and closed notes, aside from
READ THIS NOW! Print your name in the space provided below. There are 7 short-answer questions, priced as marked. The maximum score is 100. This examination is closed book and closed notes, aside from
Hash Tables. Johns Hopkins Department of Computer Science Course : Data Structures, Professor: Greg Hager
 Hash Tables What is a Dictionary? Container class Stores key-element pairs Allows look-up (find) operation Allows insertion/removal of elements May be unordered or ordered Dictionary Keys Must support
Hash Tables What is a Dictionary? Container class Stores key-element pairs Allows look-up (find) operation Allows insertion/removal of elements May be unordered or ordered Dictionary Keys Must support
Dictionaries and Hash Tables
 Dictionaries and Hash Tables 0 1 2 3 025-612-0001 981-101-0002 4 451-229-0004 Dictionaries and Hash Tables 1 Dictionary ADT The dictionary ADT models a searchable collection of keyelement items The main
Dictionaries and Hash Tables 0 1 2 3 025-612-0001 981-101-0002 4 451-229-0004 Dictionaries and Hash Tables 1 Dictionary ADT The dictionary ADT models a searchable collection of keyelement items The main
csci 210: Data Structures Maps and Hash Tables
 csci 210: Data Structures Maps and Hash Tables Summary Topics the Map ADT Map vs Dictionary implementation of Map: hash tables READING: GT textbook chapter 9.1 and 9.2 Map ADT A Map is an abstract data
csci 210: Data Structures Maps and Hash Tables Summary Topics the Map ADT Map vs Dictionary implementation of Map: hash tables READING: GT textbook chapter 9.1 and 9.2 Map ADT A Map is an abstract data
Standard ADTs. Lecture 19 CS2110 Summer 2009
 Standard ADTs Lecture 19 CS2110 Summer 2009 Past Java Collections Framework How to use a few interfaces and implementations of abstract data types: Collection List Set Iterator Comparable Comparator 2
Standard ADTs Lecture 19 CS2110 Summer 2009 Past Java Collections Framework How to use a few interfaces and implementations of abstract data types: Collection List Set Iterator Comparable Comparator 2
The dictionary problem
 6 Hashing The dictionary problem Different approaches to the dictionary problem: previously: Structuring the set of currently stored keys: lists, trees, graphs,... structuring the complete universe of
6 Hashing The dictionary problem Different approaches to the dictionary problem: previously: Structuring the set of currently stored keys: lists, trees, graphs,... structuring the complete universe of
Hashing. inserting and locating strings. MCS 360 Lecture 28 Introduction to Data Structures Jan Verschelde, 27 October 2010.
 ing 1 2 3 MCS 360 Lecture 28 Introduction to Data Structures Jan Verschelde, 27 October 2010 ing 1 2 3 We covered STL sets and maps for a frequency table. The STL implementation uses a balanced search
ing 1 2 3 MCS 360 Lecture 28 Introduction to Data Structures Jan Verschelde, 27 October 2010 ing 1 2 3 We covered STL sets and maps for a frequency table. The STL implementation uses a balanced search
Access Methods. Basic Concepts. Index Evaluation Metrics. search key pointer. record. value. Value
 Access Methods This is a modified version of Prof. Hector Garcia Molina s slides. All copy rights belong to the original author. Basic Concepts search key pointer Value record? value Search Key - set of
Access Methods This is a modified version of Prof. Hector Garcia Molina s slides. All copy rights belong to the original author. Basic Concepts search key pointer Value record? value Search Key - set of
Question Bank Subject: Advanced Data Structures Class: SE Computer
 Question Bank Subject: Advanced Data Structures Class: SE Computer Question1: Write a non recursive pseudo code for post order traversal of binary tree Answer: Pseudo Code: 1. Push root into Stack_One.
Question Bank Subject: Advanced Data Structures Class: SE Computer Question1: Write a non recursive pseudo code for post order traversal of binary tree Answer: Pseudo Code: 1. Push root into Stack_One.
ECE 242 Data Structures and Algorithms. Hash Tables I. Lecture 24. Prof.
 ECE 242 Data Structures and Algorithms http//www.ecs.umass.edu/~polizzi/teaching/ece242/ Hash Tables I Lecture 24 Prof. Eric Polizzi Motivations We have to store some records and perform the following
ECE 242 Data Structures and Algorithms http//www.ecs.umass.edu/~polizzi/teaching/ece242/ Hash Tables I Lecture 24 Prof. Eric Polizzi Motivations We have to store some records and perform the following
Part I Anton Gerdelan
 Hash Part I Anton Gerdelan Review labs - pointers and pointers to pointers memory allocation easier if you remember char* and char** are just basic ptr variables that hold an address
Hash Part I Anton Gerdelan Review labs - pointers and pointers to pointers memory allocation easier if you remember char* and char** are just basic ptr variables that hold an address
CS 261 Data Structures
 CS 261 Data Structures Hash Tables Open Address Hashing ADT Dictionaries computer kəәmˈpyoōtəәr noun an electronic device for storing and processing data... a person who makes calculations, esp. with a
CS 261 Data Structures Hash Tables Open Address Hashing ADT Dictionaries computer kəәmˈpyoōtəәr noun an electronic device for storing and processing data... a person who makes calculations, esp. with a
Hash Tables and Hash Functions
 Hash Tables and Hash Functions We have seen that with a balanced binary tree we can guarantee worst-case time for insert, search and delete operations. Our challenge now is to try to improve on that...
Hash Tables and Hash Functions We have seen that with a balanced binary tree we can guarantee worst-case time for insert, search and delete operations. Our challenge now is to try to improve on that...