An implementation of token dependency semantics using the PETFSG grammar tool
|
|
|
- Percival O’Connor’
- 5 years ago
- Views:
Transcription
1 An implementation of token dependency semantics using the PETFSG grammar tool Mats Dahllöf Department of Linguistics, Uppsala University January 7, 2002 Work in progress! Demo, updates, and related material: matsd/tds/1/ 1 Introduction This report 1 describes an implementation of an HPSG-style formal grammar and semantics, which will be called token dependency semantics (henceforth TDS), version 1. The theoretical background is given in my article Token dependency semantics and the paratactic analysis of intensional constructions (available from the author). The relation between the presentations is fairly direct. The present report gives a technical account of the implemented grammar, whose linguistic aspects are explained and defended in the other article. The main purpose of the present document is to give the reader some help in understanding the implemented TDS grammar and the auxiliary Prolog procedures. They are listed, along with comments and explanations, in the appendices. The grammar mainly provides treatments of a number of intensional constructions, and it covers only simple examples of other kinds of phrase. The grammar as implemented here uses the system and formalism Prologembedding typed feature structure grammar (henceforth PETFSG) version 3. (See matsd/petfsg/3/ for documentation.) This system uses typed feature structures in which Prolog-terms may be embedded. Prolog procedures may be called from inside the rules. Here, Prologterms are used to represent semantic objects. Prolog is only used to append lists and to create token identifiers. Otherwise, the grammar relies on unification. The grammar associates sentences with semantic representations which (in 1 A report on a previous version of this work was given in RUUL (Reports from Uppsala University Dept of Linguistics) 34, 1999.
2 many cases) are underspecified with respect to scopal relations. Additional Prolog procedures, external to the grammar, are used to compute the possible scopal resolutions. These are applied as postparse operations, see below. The files of the implementation are available at the URL matsd/tds/3/f/. An overview is given in appendix D. 1.1 The sign type and its features The type sign is a subtype of the type aops, to be understood as absent or present sign. The only other subtype is neg s, which is used to negate the presence of a sign. (This possibility is used to prevent expressions from being associated with heads as a modifiers. See below.) A sign FS is associated with features as follows: sign features [token:prolog_term, head:head_sort, spr:list, spr_inc:boolean, comps:list, slash:list, cont:cont_sort, pm:punct_mark] The features are used as described in the background article, with the exception of spr inc, slash, and pm. The boolean feature spr inc means specifier incorporated and is used to distinguish phrases which contain a specifier constituent from those that do not (in cases where spr is the empty list). spr inc plays a role in the treatment of adjectives. The slash feature is not yet put to use. The value of the feature pm is the punctuation mark delimiting a phrase, or a value indicating the absence of a punctuation mark. (Consult the grammar code for details.) 1.2 cont(ent) features The value of the sign feature cont(ent) has a value of the type cont sort. cont_sort features [hook:hole_type, h:holes, tds:prolog_term, 2
3 glob:prolog_term, tree:prolog_term, rss:prolog_term], The features hook and tds (token dependency statements), are used as described in the background article. The hole features are collected under the feature h (see below). The features glob(al), tree, and rss (reading-specific statements) are used in the computation of scopally resolved readings (see below). The hole features are of the type hole type, defined as follows by relevant parts of the type and feature declaration: hole_type subsumes [ closed subsumes [], hole subsumes [ hole_n subsumes [], hole_v subsumes []]], hole features [ltop:prolog_term], hole_n features [key:prolog_term], hole_v features [extarg:prolog_term], The non-closed holes are of two kinds: nominal (hole n) ones, carrying ltop and key features, and verbal (hole v) ones, carrying ltop and extarg features. The feature h carries a holes value, as follows: holes subsumes [ holes_v subsumes [], holes_d subsumes []], holes features [mod_hole:hole_type], holes_v features [subj_hole:hole_type, comp_holes:list], 3
4 holes_d features [spec_hole:hole_type] So, the hole collections (of the holes type) are either verbal (holes v) or determiner-related (holes d). The holes v hole collections comprise a mod hole, a subj hole, and the complement holes, collected under comp holes (see below). The holes v structures carry a mod hole and a spec hole. The comp holes feature carry a list value. Its elements are hole objects, each associated with the corresponding element on the comps list. 2 Tense, perfectivity, and progressivity The grammar only records tense, perfectivity, and progressivity. The treatment presented should be replaced by a better one. The tense, perfectivity, and progressivity information is associated with a verbal head feature v sf (verbal semantic features). Its value is a complex term [T,P,Q] containing three features, T for basic tense, preterit being the + case. Three possible values: present ( - ), preterit ( + ), and tenseless ( n, for the case of infinitive). The P value represents perfectivity, non-perfect ( - ) and perfect ( + ) being the alternatives. Finally, Q stands for progressivity. Nonprogressive ( - ) and progressive ( + ) are the possibilities here. Examples: [-,-,-] pres, non-perf, non-progr Mary smiles. [-,-,+] pres, non-perf, progr Mary is smiling. [-,+,-] pres, perf, non-progr Mary has smiled. [-,+,+] pres, perf, progr Mary has been smiling. [+,-,-] pret, non perf, non-progr Mary smiled. [+,-,+] pret, non-perf, progr Mary was smiling. [+,+,-] pret, perf, non-progr Mary had smiled. [+,+,+] pret, perf, progr Mary had been smiling. These triples are transferred to the verb EPs, connected to the feature sf. The three features are consequently seen as properties of the main verb token. 3 Token identifier assignment The TDS grammar presupposes that the grammatical descriptions uniquely identify the tokens to which they apply. This means that each token must be assigned a unique identifier. This is done procedurally with the help of the predicate label token/3, which is called just before a lexical inactive edge is stored in the chart: 4
5 label_token(desc,n,str):- name(n,name), name(str,strn), append([116 Name],[95 StrN],NN), name(tokid,nn), path_value(desc,token,prolog_term(tokid,_)). The label token/3 arguments are the FS and the number giving the position of the word in the input string (an integer). The token identifier, assigned to the feature token, is an atom formed by t followed by the position number, an underscore character, and the ortographic form, e.g. t3 house if the token is an instance of house at position 3. 4 Inflectional morphology The following Prolog clauses define the (very simple) morphological processes used by the grammar: morphology(id,x,x). morphology(affx(a),x,y):- name(x,n), name(a,an), append(n,an,nn), name(y,nn). The identifier id represents identity and affx(a) addition of the affix A. 5 The representation of TDS information The TDS relations appear as follows: c1 : Coindexation between a quantifier and a predicate with respect to the first argument position. c2 : Coindexation between a quantifier and a predicate with respect to the second argument position. restr : Immediate outscoping between a quantifier and its restriction. body : Immediate outscoping between a quantifier and its body. 5
6 ptop : Immediate outscoping between a paratactic predicate and the scopally topmost non-quantifier node of the paratactic argument. ptop : The relation equality modulo quantifiers, due to Copestake et al. (2001). It makes it possible to state scope constraints (of lexical origin). L : This relation is three-place here. It holds of a token, the lexical expression of which it is an instance, and a term describing its logical valency, see below. parg : Holds of a paratactic relation and the whole paratactic argument subtree. anchor : Holds of a paratactic relation and its anchor argument. Ind : Is used in such a way that Ind(N,T) is the individual associated with argument position N of the token T given current bindings. Semantic valencies are represented by terms as follows: q1 : One-place quantifier (i.e. a name). q2 : Two-place quantifier (i.e. two). p([a1]) : Intransitive non-paratactic relation (i.e. smile). p([a1,a2]) : Transitive non-paratactic relation (i.e. read). p([para]) : Intransitive paratactic relation (i.e. probably). p([a1,para]) : Transitive relation with a second paratactic argument position (i.e. say). 6 Postparse operations The postparse alternatives make partial selections of information to display and compute scopal resolutions from underspecified semantic representations. The following are defined: nomod : No postparse operation is applied. cont : Only the value of the feature cont is selected for output. resl1 : The set of scopal resolutions of the cont value are computed. This version assumes that names take widest possible scope. Only the value of the feature cont is then selected for output. resl2 : The resl2 resolution is different from resl1 resolution only in allowing names to be outscoped by other quantifiers. Only the value of the feature cont is then selected for output. 6
7 6.1 Specification of readings The cont[ent] features glob(al), rss, and tree are used in the specification of scopally resolved readings. The feature glob(al) is a list of the a priori topmost quantifiers in the case of resl1 resolution. The rss (reading-specific statements) feature carries a list of additional TDS statements pertaining to the reading in question. The tree feature, which is redundant given the other features, gives us an easy to read picture of the TDS tree representing the reading. (The predicate disp prolog term/3 is responsible for displaying these tree structures in a suitable fashion.) The specification of scopally resolved readings is best explained with reference to an example. (This example also appears in appendix A.) The sentence Mary says that two students smiled receives the following underspecified TDS representation. [L(t1_Mary,Mary,q1), L(t2_says,say,p([a1,para])), c1(t1_mary,t2_says), ptop(t2_says,p0), P0 qeq t6_smiled, L(t4_two,two,q2), restr(t4_two,p1), P1 qeq t5_students, L(t5_students,student,p([a1])), c1(t4_two,t5_students), L(t6_smiled,smile,p([a1])), c1(t4_two,t6_smiled)] Here, underspecification is due to the Prolog variables P0 and P1 and to the absence of body statements. The scope resolution algorithms work by instancing variables and computing additional information. One of the (two) readings of this example given by the resl1 resolution algorithm can be characterized as follows: t1 Mary-t4 two t5 students t2 says- t6 smiled This reading corresponds to tds, glob, rss, and tree values as follows. The tds value is an instance of the corresponding underspecified tds value: [L(t1_Mary,Mary,q1), L(t2_says,say,p([a1,para])), c1(t1_mary,t2_says), 7
8 ptop(t2_says,t6_smiled), t6_smiled qeq t6_smiled, L(t4_two,two,q2), restr(t4_two,t5_students), t5_students qeq t5_students, L(t5_students,student,p([a1])), c1(t4_two,t5_students), L(t6_smiled,smile,p([a1])), c1(t4_two,t6_smiled)] The glob(al) value is the list of the only a priori topmost quantifier: [t1_mary] The rss TDS statements define a quantifier body, a paratactic argument, and an anchor: [body(t4_two,t2_says), parg(t2_says,t6_smiled), anchor(t2_says,[t(t6_smiled,1,ind(t6_smiled,1))])] The tree value gives an overview of the scopal situation and is printed as follows: [t4_two:q2n(t5_students,t2_says), [t5_students:[]], [t2_says:ptop(t6_smiled), [t6_smiled:[]]]] 7 Phrase structure rules A few comments should be made concerning the phrase structure rules. The HPSG head-complement rule is implemented with the help of two rules. One of them is for the case in which no complement is present. The other one allows a head to find a complement sister, one at a time. Due to semantics, the specifier-head construction gives us two rules. One is for the subject case, in which the (verbal) head is also the semantic head. The other rule is for the determiner specifier case, in which a determiner, which is a semantic head, is associated with syntactic (nominal) head. phrase from word: This rule covers the case when the head-complement rule applies with an empty list of complements, i.e. when the mother phrase dominates a head word without sisters. 8
9 hd comps: This rule covers the case when the head-complement rule applies with a non-empty comps list on the head. Only one complement is incorporated on each application of the rule. The complement holes in the comp holes list correspond one-by-one to the comps list items. So, the values of the two features on the mother are equal to the tails of the corresponding values on the head daughter. subj spr hd: This rule is for specifier-head constructions in which the specifier is a subject to a verbal (syntactic) head, which is also the semantic head. det spr hd: This rule is for specifier-head constructions in which the specifier is a determiner and the syntactic head a noun. The determiner is the semantic head here. mod hd: Premodifier-head rule. phr punct: Phrase-punctuation-mark rule. A phrase without a punctuation mark formally, pm:neg p combines with a punctuation mark and forms a phrase with the feature pm specifying the sister punctuation mark. The mother and daughter phrases otherwise carry the same feature values. In order to make it easier to see which rule has produced an analysis, there is a subtype to the type phrase for each phrase structure rule: phrase wp phrase hc phrase ssh phrase sph phrase mh phrase hp phrase from word construction head-complement construction subject specifier-head construction determiner specifier-head construction modifier-head construction head-punctuation-mark construction These distinctions do not play any linguistic role. References Copestake, A., D. Flickinger, I. A. Sag, & C. Pollard (1999), Minimal Recursion Semantics: An Introduction. Unpublished MS, available under URL: aac/ papers/newmrs.ps (as of December 14, 2001). Pollard, C. and I. A. Sag: 1994, Head-Driven Phrase Structure Grammar, Chicago & London, The University of Chicago Press. 9

10 Appendix A: Sample analyses The sentence Mary says that two students smiled has two readings. This is the analysis given directly by the grammar. The semantic representation is scopally underspecified: The two readings are generated by the resl1 postoperation. The name quantifier is assigned global scope. First reading: 10
11 Second reading: 11

12 These are a few examples of lexical entries. The verb form says: 12
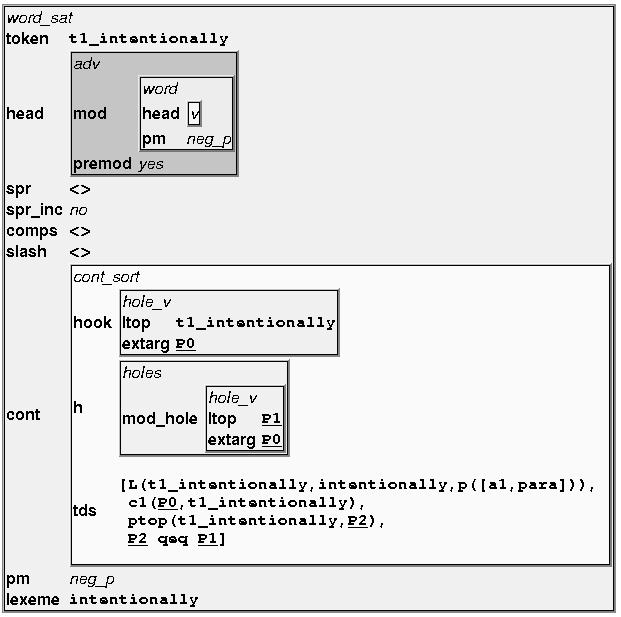
13 The adverb intentionally: 13

14 The adverb probably: 14
15 Appendix B: The grammar This appendix gives a full listing of the grammar ( gram tds.pl ) described in this report. Comments appear within boxed paragraphs. There is a file with additional lexical entries ( lex tds.pl ). grammar TDS-1. Declaration of types and features declaration [aops subsumes [ % absent or present sign neg_s subsumes [], % absent sign sign subsumes [ % present sign lexitem subsumes [ % lexical item lxm subsumes [ % lexeme infl_lxm subsumes []], % inflected lexeme word subsumes [ % word word_sat subsumes [], % saturated word_unsat subsumes []]], % unsaturated phrase subsumes [ % phrase-level signs phrase_wp subsumes [], % phrase from word phrase_hc subsumes [], % head-complement phrase_ssh subsumes [], % subject-head phrase_dsh subsumes [], % specifier-head phrase_mh subsumes [], % modifier-head phrase_hp subsumes []]]], % head-punctuation head_sort subsumes [ verb subsumes [ % verbal v subsumes [], % ordinary pos verb cplzer subsumes []], % complementizer nom subsumes [ % nominal cnnoun subsumes [], % common nouns perspron subsumes [], % personal pronoun prnoun subsumes []], % proper nouns adj subsumes [], % adjective adv subsumes [], % adverb conj subsumes [], % conjunction determin subsumes [], % determiner prep subsumes []], % preposition cont_sort subsumes [], % content structure 15
16 holes subsumes [ % hole collection holes_v subsumes [], % for verbals holes_d subsumes []], % for determiners hole_type subsumes [ % hole type closed subsumes [], % "closed" (unavailable) hole subsumes [ % "open" hole hole_n subsumes [], % for nominals hole_v subsumes []]], % for verbals boolean subsumes [ no subsumes [], yes subsumes []], number_sort subsumes [ sing subsumes [], plur subsumes []], def_sort subsumes [ def subsumes [], indef subsumes []], % true/false boolean % number % definiteness case_sort subsumes [ % case nomin subsumes [ % i.e. non-genitive subc subsumes [], % subject form objc subsumes []], % object form gen subsumes []], % genitive pers_sort subsumes [ % person: p1 subsumes [], % first p2 subsumes [], % second p3 subsumes []], % third vform_sort subsumes [ % verbal inflection finite subsumes [ present subsumes [], preterit subsumes []], infinite subsumes [ infinitive subsumes [], prp subsumes [], % present participle psp subsumes []]], % past participle 16
17 v_kind_sort subsumes [ % kind of verb aux subsumes [], % auxiliary verb notaux subsumes []], % non-auxiliary verb where punct_mark subsumes [ % punctuation marks: neg_p subsumes [], % no punctuation mark full_stop subsumes [], comma subsumes [], colon subsumes [], semi_colon subsumes [], exclam subsumes [], questnm subsumes []]] [sign features [token:prolog_term, head:head_sort, spr:list, spr_inc:boolean, comps:list, slash:list, cont:cont_sort, pm:punct_mark], % specifier incorporated lexitem features [lexeme:prolog_term], cont_sort features [hook:hole_type, h:holes, tds:prolog_term, glob:prolog_term, rss:prolog_term, tree:prolog_term], hole features [ltop:prolog_term], hole_n features [key:prolog_term], hole_v features 17
18 [extarg:prolog_term], holes features [mod_hole:hole_type], holes_v features [subj_hole:hole_type, comp_holes:list], holes_d features [spec_hole:hole_type], head_sort features [mod:aops, premod:boolean, spec:sign], nom features [num:number_sort, def:def_sort, case:case_sort, pers:pers_sort], % allowed to modify % premodifier % "specified" % (see rule det_spr_hd) % number % definiteness % case % person verb features [vform:vform_sort, v_kind:v_kind_sort, v_sf:prolog_term]]. % inflection % kind of verb % semantic features Information concerning tense, perfectivity, and progressivity is associated with a the verbal head feature v sf (verbal semantic features). Its value is a complex term [T,P,Q] containing three features, T for basic tense, preterit being the + case. Three possible values: present ( - ), preterit ( + ), and tenseless ( n, for the case of infinitive). P represents perfectivity, non-perfect ( - ) and perfect ( + ) being the alterntives. Finally, Q stands for progressivity. Non-progressive ( - ) and progressive ( + ) are the possibilities here. (This is only a tentative treatment of these features.) Initial symbol definition initial_symbol [head:[vform:finite], spr:{}, comps:{}, slash:{}]. Leaf symbol definition % I.e. sentence 18
19 leaf_symbol word. The phrase structure rules Phrase from word rule phrase_from_word rule [phrase_wp, token: <>T1, head:xhfp, comps:{}, spr:xspr, spr_inc:no, slash:{}, cont:xcont, pm:neg_p] ===> [ [word_unsat, token: <>T1, head:xhfp, comps:{}, spr:xspr, spr_inc:no, slash:{}, cont:xcont, pm:neg_p]]. The head-complement rule This version of the head-complement rule combines the head with the first complement as required by the first item on the comps list. This means that one application of this rule per complement is required. The + operator represents physical aggregation. The Prolog call computes the mother s slash and tds values. hd_comps rule [xmtr, phrase_hc, token: <>(T1+T2), head:xhfp, comps:xcomps, spr:xspr, spr_inc:xsprinc, cont:[hook:xhook, 19
20 h:[subj_hole:xsh, comp_holes:xchs, mod_hole:xmh]], pm:neg_p] ===> [ [xhead, token: <>T1, head:xhfp, spr:xspr, spr_inc:xsprinc, comps:xcompˆxcomps, cont:[hook:xhook, h:[subj_hole:xsh, comp_holes:xchˆxchs, mod_hole:xmh]], pm:neg_p], [xcomp, token: <>T2, cont:[hook:xch], pm:neg_p], prolog [mother_daughters, xmtr,xhead,xcomp]]. The specifier-head rule, subject case subj_spr_hd rule [xmtr, phrase_ssh, token: <>(T1+T2), head:xhfp, spr:{}, spr_inc:yes, comps:{}, cont:[hook:xhook, h:[subj_hole:closed, comp_holes:xchs, mod_hole:xmh]], pm:neg_p] ===> [ [xspr, token: <>T1, % Spec-principle not needed. 20
21 cont:[hook:xsh], pm:neg_p], [xhead, token: <>T2, head:xhfp, spr:{xspr}, comps:{}, cont:[hook:xhook, h:[subj_hole:xsh, comp_holes:xchs, mod_hole:xmh]], pm:neg_p], prolog [mother_daughters, xmtr,xspr,xhead]]. The specifier-head rule, determiner case Pollard s and Sag s (1994: 51) Spec Principle is hard-coded into the rule. det_spr_hd rule [xmtr, phrase_dsh, token: <>(T1+T2), head:xhfp, spr:{}, spr_inc:yes, comps:{}, cont:[hook:xhook, h:[spec_hole:closed, mod_hole:xmh]], pm:neg_p] ===> [ [xspr, token: <>T1, head:[determin, spec:xhead], cont:[hook:xhook, h:[spec_hole:xspechook, mod_hole:xmh]], pm:neg_p], 21
22 [xhead, token: <>T2, head:xhfp, spr:{xspr}, comps:{}, cont:[hook:xspechook], pm:neg_p], prolog [mother_daughters, xmtr,xspr,xhead]]. The premodifier-head rule mod_hd rule [xmtr, phrase_mh, token: <>(T1+T2), head:xhfp, spr:xspr, spr_inc:xsprinc, comps:xcomps, cont:[hook:xmodhook, h:[subj_hole:xsh, comp_holes:xchs, mod_hole:xmh]], pm:neg_p] ===> [ [xmod, token: <>T1, head:[mod:xhead, premod:yes], spr:{}, comps:{}, cont:[hook:xmodhook, h:[mod_hole:xhdhook]], pm:neg_p], [xhead, token: <>T2, head:xhfp, spr:xspr, spr_inc:xsprinc, 22
23 comps:xcomps, cont:[hook:xhdhook, h:[subj_hole:xsh, comp_holes:xchs, mod_hole:xmh]], pm:neg_p], prolog [mother_daughters, xmtr,xmod,xhead]]. Phrase-punctuation-mark rule Incorporates a punctuation mark in a phrase: A phrase with pm:neg p combines with a punctuation mark and forms a phrase with the feature pm specifying the sister punctuation mark. The mother and daughter phrases otherwise carry the same feature values. phr_punct rule [phrase_hp, token: <>Token, head:xhd, spr:{}, spr_inc:xsprinc, comps:{}, cont:xcont, pm:xpm] ===> [ [phrase, token: <>Token, head:xhd, spr:{}, spr_inc:xsprinc, comps:{}, cont:xcont, pm:neg_p], [xpm, punct_mark]]. Punctuation mark entries. >>> full_stop., >>> 23
24 comma.? >>> questnm.! >>> exclam. : >>> colon. ; >>> semi_colon. Lexical information General definitions content_lexitem is_short_for [token: <>Token, cont:[hook:[ltop: <>Token]], slash:{}, spr_inc:no, pm:neg_p]. content lexitem applies to lexical entries which contribute to semantics. The features token and cont:hook:ltop are defined. form_lexitem is_short_for [slash:{}, spr_inc:no, pm:neg_p]. form lexitem applies to lexical entries which do not contribute to semantics. The features token and cont:hook:ltop are not defined. np_subj is_short_for [head:[nom, case:subc], spr:{}, comps:{}, slash:{}, pm:neg_p]. Subject form NPs. 24
25 np_obj is_short_for [head:[nom, case:objc], spr:{}, comps:{}, slash:{}, pm:neg_p]. Object form NPs. sentence is_short_for [head:[v, vform:finite], spr:{}, spr_inc:yes, comps:{}]. Definition of sentence. inf_phrase_plain is_short_for [head:[v, vform:infinitive], comps:{}, pm:neg_p]. Infinitival phrases without a to complementizer. inf_phrase_to is_short_for [head:[cplzer, vform:infinitive], comps:{}, pm:neg_p]. Infinitival phrases with a to complementizer. prp_phrase is_short_for [head:[v, vform:prp], comps:{}, pm:neg_p]. Present participle phrases. psp_phrase is_short_for [head:[v, vform:psp], comps:{}, pm:neg_p]. 25
26 Past participle phrases. no_mod is_short_for [head:[mod:neg_s], cont:[h:[mod_hole:closed]]]. For signs which can not occur as (pre- or post-) modifiers. Proper nouns proper_noun is_short_for [nfs content_lexitem, token: <>Token, lexeme: <>Lexeme, head:[prnoun, num:sing, pers:p3], spr:{}, comps:{}, nfs no_mod, cont:[hook:[key: <>Token], tds: <>[ L (Token,Lexeme,q1)]]]. Galileo >>> [word_unsat, nfs proper_noun, lexeme: <> Galileo ]. Personal pronouns personal_pronoun is_short_for [nfs content_lexitem, token: <>Token, lexeme: <>Lexeme, head:perspron, spr:{}, comps:{}, nfs no_mod, cont:[hook:[key: <>Token], tds: <>[ L (Token,Lexeme,q1)]]]. he >>> [nfs personal_pronoun, head:[pers:p3, 26
27 num:sing], lexeme: <> he ]. Determiners determiner is_short_for [nfs form_lexitem, word_sat, token: <>Token, lexeme: <>Lexeme, head:determin, spr:{}, comps:{}, nfs no_mod, cont:[hook:[key: <>Token], h:[spec_hole:[key: <>Token, ltop: <>LTOP]], tds: <>[ L (Token,Lexeme,q2), restr(token,restr), Restr qeq LTOP]]]. many >>> [nfs determiner, head:[spec:[head:[num:plur]]], lexeme: <> many ]. the >>> [nfs determiner, head:[spec:[head:[num:sing]]], lexeme: <> the_sing ]. the >>> [nfs determiner, head:[spec:[head:[num:plur]]], lexeme: <> the_plur ]. Two senses of the, as number is reflected (lexically) in the lo value. Noun morphology lexrule sing_noun morph id input [infl_lxm, token:x0, 27
28 lexeme:x1, head:[x2, cnnoun], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7] output [word_unsat, token:x0, lexeme:x1, head:[x2, cnnoun, num:sing], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. lexrule plur_noun morph affx(s) input [infl_lxm, token:x0, lexeme:x1, head:[x2, cnnoun], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7] output [word_unsat, token:x0, lexeme:x1, head:[x2, cnnoun, num:plur], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. 28
29 The common kind of singular/plural noun inflection in English. Common nouns requiring a specifier common_noun_spr is_short_for [nfs content_lexitem, token: <>Token, lexeme: <>Lexeme, head:[cnnoun, pers:p3], spr:{[head:determin, pm:neg_p]}, comps:{}, nfs no_mod, cont:[hook:[key: <>SprKey, ltop: <>Token], h:[subj_hole:closed], tds: <>[ L (Token,Lexeme,p([a1])), c1(sprkey,token)]]]. This does not give us bare plurals. book >>> [infl_lxm, nfs common_noun_spr, lexeme: <>book]. Verbs: general aspects verb_general is_short_for [nfs content_lexitem, head:v, nfs no_mod]. Verb form abbreviations present_third_singular is_short_for [head:[vform:present, v_sf: <>[ -, -, - ]], spr:{[head:[pers:p3, num:sing]]}]. present_third_plural is_short_for [head:[vform:present, v_sf: <>[ -, -, - ]], 29
30 spr:{[head:[pers:p3, num:plur]]}]. preterit_third_singular is_short_for [head:[vform:present, v_sf: <>[ +, -, - ]], spr:{[head:[pers:p3, num:sing]]}]. preteritum is_short_for [head:[vform:preterit, v_sf: <>[ +, -, - ]]]. infinitive_form is_short_for [head:[vform:infinitive, v_sf: <>[ n, -, - ]]]. prp_form is_short_for [head:[vform:prp, v_sf: <>[_,_, + ]]]. psp_form is_short_for [head:[vform:psp, v_sf: <>[_, +, - ]]]. Verb inflection lexrule v_infl_infin morph id input [infl_lxm, token:x0, lexeme:x1, head:[x2, verb], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7] output [word_unsat, nfs infinitive_form, token:x0, lexeme:x1, head:x2, 30
31 spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. lexrule v_infl_third_plural morph id input [infl_lxm, token:x0, lexeme:x1, head:[x2, verb], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7] output [word_unsat, nfs present_third_plural, token:x0, lexeme:x1, head:x2, spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. lexrule v_infl_third_singular morph affx(s) input [infl_lxm, token:x0, lexeme:x1, head:[x2, verb], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7] output [word_unsat, nfs present_third_singular, 31
32 token:x0, lexeme:x1, head:x2, spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. lexrule v_infl_pret morph affx_ch_e(ed) input [infl_lxm, token:x0, lexeme:x1, head:[x2, verb], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7] output [word_unsat, nfs preteritum, token:x0, lexeme:x1, head:x2, spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. lexrule v_infl_psp morph affx_ch_e(ed) input [infl_lxm, token:x0, lexeme:x1, head:[x2, verb], spr:x3, spr_inc:x4, comps:x5, slash:x6, 32
33 cont:x7] output [word_unsat, nfs psp_form, token:x0, lexeme:x1, head:x2, spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. lexrule v_infl_prp morph affx_ch_e(ing) input [infl_lxm, token:x0, lexeme:x1, head:[x2, verb], spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7] output [word_unsat, nfs prp_form, token:x0, lexeme:x1, head:x2, spr:x3, spr_inc:x4, comps:x5, slash:x6, cont:x7]. Intransitive verbs verb_intransitive is_short_for [nfs verb_general, token: <>Token, lexeme: <>Lexeme, spr:{[nfs np_subj]}, comps:{}, cont:[hook:[extarg: <>SubjKey], 33
34 h:[subj_hole:[key: <>SubjKey]], tds: <>[ L (Token,Lexeme,p([a1])), c1(subjkey,token)]]]. smile >>> [infl_lxm, nfs verb_intransitive, lexeme: <>smile]. Ordinary transitive verbs verb_transitive is_short_for [nfs verb_general, token: <>Token, lexeme: <>Lexeme, spr:{[nfs np_subj]}, comps:{[nfs np_obj]}, cont:[hook:[extarg: <>SubjKey], h:[subj_hole:[key: <>SubjKey], comp_holes:{[key: <>ObjKey]}], tds: <>[ L (Token,Lexeme,p([a1,a2])), c1(subjkey,token), c2(objkey,token)]]]. The an feature is given the nil value - to indicate that anchoring is not applicable. help >>> [infl_lxm, nfs verb_transitive, lexeme: <>help]. Paratactic verbs verb_paratactic is_short_for [nfs verb_general, token: <>Token, lexeme: <>Lexeme, spr:{[nfs np_subj]}, comps:{[head:verb, comps:{}, spr:{}, pm:neg_p]}, cont:[hook:[extarg: <>SubjKey], h:[subj_hole:[key: <>SubjKey], comp_holes:{[ltop: <>LTOP]}], 34
35 tds: <>[ L (Token,Lexeme,p([a1,para])), c1(subjkey,token), ptop(token,ctt), CTT qeq LTOP]]]. claim >>> [infl_lxm, nfs verb_paratactic, lexeme: <>claim]. Raising verbs verb_subj_raising is_short_for [nfs verb_general, token: <>Token, lexeme: <>Lexeme, spr:{[xspr, nfs np_subj]}, comps:{[spr:{xspr}, pm:neg_p]}, cont:[hook:[extarg: <>SubjKey], h:[subj_hole:[key: <>SubjKey], comp_holes:{[ltop: <>LTOP, extarg: <>SubjKey]}], tds: <>[ L (Token,Lexeme,p([para])), ptop(token,ctt), CTT qeq LTOP]]]. verb_subj_raising_plain is_short_for [nfs verb_subj_raising, comps:{nfs inf_phrase_plain}]. Takes as complement an infinitival phrase without a to complementizer. would >>> [word_unsat, nfs verb_subj_raising_plain, nfs preteritum, lexeme: <>would]. verb_subj_raising_to is_short_for [nfs verb_subj_raising, comps:{nfs inf_phrase_to}]. Takes as complement an infinitival phrase with a to complementizer. 35
36 ought >>> [word_unsat, nfs verb_subj_raising_to, nfs preteritum, lexeme: <>ought]. Subject control verbs verb_subj_control is_short_for [nfs verb_general, token: <>Token, lexeme: <>Lexeme, spr:{[xspr, nfs np_subj]}, comps:{[nfs inf_phrase_to, spr:{xspr}, pm:neg_p]}, cont:[hook:[extarg: <>SubjKey], h:[subj_hole:[key: <>SubjKey], comp_holes:{[ltop: <>LTOP, extarg: <>SubjKey]}], tds: <>[ L (Token,Lexeme,p([a1,para])), c1(subjkey,token), ptop(token,ctt),ctt qeq LTOP]]]. The verb EP and the complement EP are coindexed with respect to their a1 arguments. Takes as complement an infinitival phrase with a to complementizer. intend >>> [infl_lxm, nfs verb_subj_control, lexeme: <>intend]. Object raising verbs verb_obj_raising is_short_for [nfs verb_general, token: <>Token, lexeme: <>Lexeme, spr:{[nfs np_subj]}, comps:{[nfs np_obj], [nfs inf_phrase_to, spr:{[]}]}, cont:[hook:[extarg: <>SubjKey], h:[subj_hole:[key: <>SubjKey], 36
37 comp_holes:{[key: <>ObjKey], [ltop: <>LTOP, extarg: <>ObjKey]}], tds: <>[ L (Token,Lexeme,p([a1,para])), c1(subjkey,token), ptop(token,ctt), CTT qeq LTOP]]]. expect >>> [infl_lxm, nfs verb_obj_raising, lexeme: <>expect]. Object control verbs verb_obj_control is_short_for [nfs verb_general, token: <>Token, lexeme: <>Lexeme, spr:{[nfs np_subj]}, comps:{[nfs np_obj], [nfs inf_phrase_to, spr:{[]}]}, cont:[hook:[extarg: <>SubjKey], h:[subj_hole:[key: <>SubjKey], comp_holes:{[key: <>ObjKey], [ltop: <>LTOP, extarg: <>ObjKey]}], tds: <>[ L (Token,Lexeme,p([a1,para])), c1(subjkey,token), c2(objkey,token), ptop(token,ctt), CTT qeq LTOP]]]. persuade >>> [infl_lxm, nfs verb_obj_control, lexeme: <>persuade]. Auxiliary verbs verb_aux is_short_for [word_unsat, nfs form_lexitem, 37
38 head:[v, v_kind:aux], comps:{[]}, cont:[hook:[extarg: <>SubjKey, ltop: <>LTOP], h:[subj_hole:[key: <>SubjKey], comp_holes:{[ltop: <>LTOP, extarg: <>SubjKey]}], tds: <>[]]]. These verbs only serve to specify the v sf features on the main verb. Temporal have verb_temp_have is_short_for [nfs verb_aux, spr:{[xsubj]}, comps:{[nfs psp_phrase, spr:{xsubj}]}]. have >>> [nfs verb_temp_have, nfs infinitive_form, comps:{[head:[v_sf: <>[ n,_,_]]]}]. has >>> [nfs verb_temp_have, nfs present_third_singular, comps:{[head:[v_sf: <>[ -,_,_]]]}]. have >>> [nfs verb_temp_have, nfs present_third_plural, comps:{[head:[v_sf: <>[ -,_,_]]]}]. had >>> [nfs verb_temp_have, nfs preteritum, comps:{[head:[v_sf: <>[ +,_,_]]]}]. Progressive be verb_progr_be is_short_for [word_unsat, 38
39 nfs verb_aux, spr:{[xsubj]}, comps:{[nfs prp_phrase, head:[v_kind:notaux], spr:{xsubj}]}]. Progressive be requires a v kind:notaux complement (cf. is having seen). is >>> [nfs verb_progr_be, nfs present_third_singular, comps:{[head:[v_sf: <>[ -, -,_]]]}]. was >>> [nfs verb_progr_be, nfs preterit_third_singular, comps:{[head:[v_sf: <>[ +, -,_]]]}]. be >>> [nfs verb_progr_be, nfs infinitive_form, comps:{[head:[v_sf: <>[ n, -,_]]]}]. been >>> [nfs verb_progr_be, nfs psp_form, head:[v_sf: <>[Tense,_,_]], comps:{[head:[v_sf: <>[Tense,+,_]]]}]. Adjectives (tentative treatment) adj_paratactic is_short_for [word_unsat, nfs content_lexitem, token: <>Token, lexeme: <>Lexeme, head:adj, spr:{}, comps:{}, head:[mod:[head:cnnoun, spr_inc:no, comps:{}, pm:neg_p], premod:yes], 39
40 cont:[hook:[key: <>SprKey, ltop: <>Token], h:[mod_hole:[key: <>SprKey, ltop: <>LTOP]], tds: <>[ L (Token,Lexeme,p([a1,para])), c1(sprkey,token), ptop(token,ctt), CTT qeq LTOP]]]. Gives a paratactic analysis of adjectives in attributive (modifier) position. false >>> [nfs adj_paratactic, lexeme: <>false]. Sentence adverbs adv_sent_fs is_short_for [word_sat, nfs content_lexitem, token: <>Token, lexeme: <>Lexeme, head:adv, spr:{}, comps:{}, head:[mod:[word, head:v, pm:neg_p], premod:yes], cont:[hook:[extarg: <>SprKey], h:[mod_hole:[ltop: <>LTOP, extarg: <>SprKey]], tds: <>[ L (Token,Lexeme,p([para])), ptop(token,ctt), CTT qeq LTOP]]]. Only word-level verbs are allowed to be modified. consequently >>> [nfs adv_sent_fs, lexeme: <>consequently]. Subject-relative adverbs adv_sent_subj is_short_for [word_sat, 40
41 nfs content_lexitem, token: <>Token, lexeme: <>Lexeme, head:adv, spr:{}, comps:{}, head:[mod:[word, head:v, pm:neg_p], premod:yes], cont:[hook:[extarg: <>SprKey], h:[mod_hole:[ltop: <>LTOP, extarg: <>SprKey]], tds: <>[ L (Token,Lexeme,p([a1,para])), c1(sprkey,token), ptop(token,ctt), CTT qeq LTOP]]]. Only word-level verbs are allowed to be modified. intentionally >>> [nfs adv_sent_subj, lexeme: <>intentionally]. Adjective-modifying adverbs (tentative treatment) adv_adjmod is_short_for [word_sat, nfs content_lexitem, token: <>Token, lexeme: <>Lexeme, head:adv, spr:{}, comps:{}, head:[mod:[head:adj, comps:{}, pm:neg_p], premod:yes], cont:[h:[mod_hole:[key: <>AdjKey, ltop: <>LTOP]], tds: <>[ L (Token,Lexeme,p([a1,para])), ci_a1_a1(token,adjkey), ptop(token,ctt), CTT qeq LTOP]]]. 41
42 allegedly >>> [nfs adv_adjmod, lexeme: <>allegedly]. Complementizers cplzer is_short_for [word_sat, slash:{}, head:[cplzer, vform:xvform, v_sf:xvsf], nfs no_mod, spr_inc:xsprinc, comps:{[head:[v, vform:xvform, v_sf:xvsf], spr_inc:xsprinc, comps:{}]}, cont:[hook:[xch], h:[comp_holes:{xch}], tds: <>[]]]. A complementizer is a head that only changes the head category of the complement, so to speak. that >>> [nfs cplzer, spr:{}, comps:{[head:[vform:finite], spr:{}]}]. to >>> [nfs cplzer, spr:{xspr}, comps:{[head:[vform:infinite], spr:{xspr}]}]. Interface information These pieces of information do not belong to the grammar, properly speaking, but define the resources necessary for using the grammar in a PETFSG application. Some of these clauses also define the appearance of various grammar output. postparse_options([cont,resl1,resl2]). 42
43 cont : content information only. resl1 scope resolution with one-place quantifiers (names) taking global scope. resl2 scope resolution without the constraint in the previous case. Colour specifications type_color(sign, #FFFFE0 ). type_color(word, #FAEBD7 ). type_color(lxm, #FA8072 ). type_color(infl_lxm, #FA8072 ). type_color(phrase, #FFE4B5 ). type_color(head_sort, #7FFF00 ). type_color(determin, #FFFF33 ). type_color(nom, #7FFFD4 ). type_color(cnnoun, #7FFFD4 ). type_color(prnoun, #7FFFD4 ). type_color(perspron, #7FFFD4 ). type_color(adj, #CCFF00 ). type_color(adv, #CCFF00 ). type_color(verb, #FFFFCC ). type_color(v, #FFFFCC ). type_color(cplzer, #FFC0CB ). type_color(mod_sort, #E6E6FA ). type_color(cont_sort, #F5FFFA ). Display colours associated with the various types. Resource locations saved_state_file( /home/staff/matsd/petfsg/tds1.sav ). The version-dependent file name for the Prolog saved state in which the application based on this grammar will reside. css_url( matsd/petfsg/3/css/pgt.css ). The cascading style sheet for the output pages. infotext([% An implementation of Token Dependency Grammar (TDS). See, newl, documentation <a href=" matsd/tds/1/">here</a>., newl, The PETFSG grammar tool is documented, newl, <a href=" matsd/petfsg/3/">here</a>. ]). Documentation note. End of file. 43
44 Appendix C: Auxiliary Prolog procedures This is a listing of the additional Prolog procedures of which the application makes use. (The file name is pl tds.pl.) Operator declarations :- op(300,xfy,qeq). Equality modulo quantifiers, Copestake et al style. :- op(200,xfy,@). For token numbering. Token labeling label_token(desc,n,str):- name(n,name), name(str,strn), append([116 Name],[95 StrN],NN), %%% e.g. t3_house name(tokid,nn), path_value(desc,token,prolog_term(tokid,_)). call prolog call prolog/1 provides the interface between the phrase structure rules and general Prolog computation. call_prolog([mother_daughters,mother,dghtr1,dghtr2]):- mother_daughter_relations(mother,dghtr1,dghtr2). call_prolog([list_type_append,a,b,c]):- list_type_append(a,b,c). call_prolog([append,a,b,c]):- append_w_check(a,b,c). call_prolog(x):- %%% error handling case make_html(tx( Unexpected prolog call (X))), fail. 44
45 mother_daughter_relations(mtr,d1,d2):- path_value(mtr,slash,mtrslash), path_value(d1,slash,d1slash), path_value(d2,slash,d2slash), list_type_append(d1slash,d2slash,mtrslash), empty_or_singleton(mtrslash), path_value(mtr,cont:tds,prolog_term(mtrhc,_)), path_value(d1,cont:tds,prolog_term(d1hc,_)), path_value(d2,cont:tds,prolog_term(d2hc,_)), append_w_check(d1hc,d2hc,mtrhc). Computes the cont:tds value (PETFSG list) on the mother as the union of the corresponding values on the daughters. (The predicate path value/3 is described in the PETFSG documentation.) empty_or_singleton(list_type(list_type_e<&>fttrm)). empty_or_singleton(list_type(list_type_ne<&> fttrm(_,list_type(list_type_e<&>fttrm)))). List operations list type append/3 is the append operation for PETFSG lists. list_type_append(arg1,arg2,_):- (var(arg1);var(arg2)), grammar_error( Error (variable) in list_type_append ). list_type_append(list_type(list_type_ne<&>fttrm(head,tail1)), LIST2, list_type(list_type_ne<&>fttrm(head,tail2))):- list_type_append(tail1,list2,tail2). list_type_append(list_type(list_type_e<&>fttrm),list2,list2). list type append/3 is like ordinary append/3, but with an argument check as a security measure. append_w_check(a,b,c):- is_list(a), is_list(b), append(a,b,c). 45
46 append_w_check(a,b,[]):- print( Attempt to apply append on non-list ), nl, print(a), print(b), nl. Morphological operations morphology(id,x,x). morphology(affx(a),x,y):- name(x,n), name(a,an), append(n,an,nn), name(y,nn). morphology(affx_ch_e(a),x,y):- name(x,n), name(a,an), remove_final_e(n,n2), append(n2,an,nn), name(y,nn). remove_final_e(an,an2):- reverse(an,[101 AN3]), reverse(an3,an2),!. remove_final_e(an,an). Postparse operations postparse_mod(cont,all,[sel]):- path_value(all,cont,cont), path_value(sel,cont,cont). Only cont selected for output. postparse_mod(resl1,fs,bag2):- path_value(fs,cont:tds,prolog_term(tds,_)), path_value(fs,cont:hook:ltop,prolog_term(ltop,_)), findall(p(tds,tree,immoutsc), build_tree_w_globals(tds,tree,immoutsc), 46
47 Bag), make_fs(bag,bag2,ltop). postparse_mod(resl2,fs,bag2):- path_value(fs,cont:tds,prolog_term(tds,_)), path_value(fs,cont:hook:ltop,prolog_term(ltop,_)), findall(p(tds,tree,[]), build_tree_no_globals(tds,tree), Bag), make_fs(bag,bag2,ltop). postparse_mod(op,_,[]):- make_html(txbi([ No postparse op. applied., Option ", Op, " undefined. ])). make_fs([],[],_). make_fs([p(tds,tree,immoutsc) Bag],[FS Bag2],Ltop):- collect_global_bodies(immoutsc,globals), collect_rss_info(tds,tree,anchs), path_value(fs,cont:glob,prolog_term(globals,_)), path_value(fs,cont:tds,prolog_term(tds,_)), path_value(fs,cont:tree,prolog_term(tree,_)), path_value(fs,cont:rss,prolog_term(anchs,_)), path_value(fs,cont:hook:ltop,prolog_term(ltop,_)), make_fs(bag,bag2,ltop). collect_rss_info(tds,tree,stts3):- collect_rss_info2(tds,tree,stts), split(stts,stts2), extract_body_statements(tree,bodystatements), append(bodystatements,stts2,stts3). collect_rss_info2(tds,tree,stts):- findall(paratri(tok,tokcomp,anch), (subtree_paratactic(tree,[tok:ptop(_), SubTree]), comptok(subtree,tokcomp), anchoring(tds,subtree,anch)), STTS). 47
48 split([],[]). split([paratri(tok,tokcomp,anch) Rest1], [parg(tok,tokcomp), anchor(tok,anch) Rest2]):- split(rest1,rest2). stt(tree,tok,ct):- subtree(tree,tok,subtree), comptok(subtree,ct). comptok([tok:_],tok). comptok([tok:_,tree],tok+ct):- comptok(tree,ct). comptok([tok:_,tree1,tree2],tok+ct1+ct2):- comptok(tree1,ct1), comptok(tree2,ct2). paratok([tok1:ptop(tok2),_],tok1,tok2). paratok([_,subtree],tok1,tok2):- paratok(subtree,tok1,tok2). paratok([_,subtree,_],tok1,tok2):- paratok(subtree,tok1,tok2). paratok([_,_,subtree],tok1,tok2):- paratok(subtree,tok1,tok2). anchoring([],_,[]). anchoring([c1(x,y) TDS],Subtree,[t(Y,1, Ind (Y,1)) Anch]):- relevant_for(x,y,subtree), anchoring(tds,subtree,anch). anchoring([c2(x,y) TDS],Subtree,[t(Y,2, Ind (Y,2)) Anch]):- relevant_for(x,y,subtree), anchoring(tds,subtree,anch). anchoring([c3(x,y) TDS],Subtree,[t(Y,3, Ind (Y,3)) Anch]):- 48
49 relevant_for(x,y,subtree), anchoring(tds,subtree,anch). anchoring([_ TDS],Subtree,Anch):- anchoring(tds,subtree,anch). relevant_for(x,y,subtree):- \+contains(subtree,x), contains(subtree,y). collect_global_quants([],[]). collect_global_quants([ L (Tok,_,q1) Rest],[Tok Found]):- collect_global_quants(rest,found). collect_global_quants([_ Rest],Found):- collect_global_quants(rest,found). specify_globality(tdrs,global,newbodystatms):- specify_globality2(tdrs,global), findall(body(x,global), ( member(x,global), \+memberchk(body(x,global),tdrs)), NewBodyStatms). specify_globality2([],_). specify_globality2([body(x,global) TDRS],GLOBAL):- memberchk(x,global), specify_globality2(tdrs,global). specify_globality2([_ TDRS],GLOBAL):- specify_globality2(tdrs,global). collect_global_bodies([],[]). collect_global_bodies([body(x,global) TDRS],[X Globals]):- 49
50 collect_global_bodies(tdrs,globals). collect_global_bodies([_ TDRS],Globals):- collect_global_bodies(tdrs,globals). collect_non_global_quas([],[]). collect_non_global_quas([ L (Tok,_,q1) Rest], ImmOutsc,[Tok:q1n(Body) Found]):- make_q1_node(tok,immoutsc,tok:q1n(body)), \+(Body==global), collect_non_global_quas(rest,immoutsc,found). collect_non_global_quas([ L (Tok,_,q2) Rest], ImmOutsc, [Tok:q2n(Restr,Body) Found]):- make_q2_node(tok,immoutsc,tok:q2n(restr,body)), \+(Body==global), %% This should be true. collect_non_global_quas(rest,immoutsc,found). collect_non_global_quas([ L (Tok,_,LogVal) Rest], ImmOutsc, [Tok:ptop(Para) Found]):- paratactic_predicate(logval), make_para_node(tok,immoutsc,tok:ptop(para)), \+(Para==global), %% This should be true. collect_non_global_quas(rest,immoutsc,found). collect_non_global_quas([_ Rest],ImmOutsc,Found):- collect_non_global_quas(rest,immoutsc,found). collect_non_global_quas([],_,[]). predicate(p(_)). paratactic_predicate(p(args)):- memberchk(para,args). 50
51 make_q1_node(_,[],_). make_q1_node(tok,[body(tok,body) ImmOutsc],Tok:q1n(Body)):- make_q1_node(tok,immoutsc,tok:q1n(body)). make_q1_node(tok,[_ ImmOutsc],Tok:q1n(Body)):- make_q1_node(tok,immoutsc,tok:q1n(body)). make_q2_node(_,[],_). make_q2_node(tok,[body(tok,body) ImmOutsc], Tok:q2n(Restr,Body)):- make_q2_node(tok,immoutsc,tok:q2n(restr,body)). make_q2_node(tok,[restr(tok,restr) ImmOutsc], Tok:q2n(Restr,Body)):- make_q2_node(tok,immoutsc,tok:q2n(restr,body)). make_q2_node(tok,[_ ImmOutsc],Tok:q2n(Restr,Body)):- make_q2_node(tok,immoutsc,tok:q2n(restr,body)). make_para_node(tok,[ptop(tok,para) _],Tok:ptop(Para)):-!. make_para_node(tok,[_ ImmOutsc],Tok:ptop(Para)):- make_para_node(tok,immoutsc,tok:ptop(para)). collect_leaves([],[]). collect_leaves([ L (Tok,_,LogVal) Rest],[(Tok:[]) Found]):- predicate(logval), \+paratactic_predicate(logval), collect_leaves(rest,found). collect_leaves([_ Rest],Found):- 51
52 collect_leaves(rest,found). tdr_kinds([],[],[],[],[]). tdr_kinds([ L (A,B,C) Rest],[ L (A,B,C) LOS], QEQS,ImmOutsc,CIS):- tdr_kinds(rest,los,qeqs,immoutsc,cis). tdr_kinds([a qeq B Rest],LOS, [A qeq B QEQS],ImmOutsc,CIS):- tdr_kinds(rest,los,qeqs,immoutsc,cis). tdr_kinds([ptop(a,b) Rest],LOS, QEQS,[ptop(A,B) ImmOutsc],CIS):- tdr_kinds(rest,los,qeqs,immoutsc,cis). tdr_kinds([body(a,b) Rest],LOS, QEQS,[body(A,B) ImmOutsc],CIS):- tdr_kinds(rest,los,qeqs,immoutsc,cis). tdr_kinds([restr(a,b) Rest],LOS, QEQS,[restr(A,B) ImmOutsc],CIS):- tdr_kinds(rest,los,qeqs,immoutsc,cis). tdr_kinds([c1(a,b) Rest],LOS, QEQS,ImmOutsc,[os(A,B) CIS]):- tdr_kinds(rest,los,qeqs,immoutsc,cis). tdr_kinds([c2(a,b) Rest],LOS, QEQS,ImmOutsc,[os(A,B) CIS]):- tdr_kinds(rest,los,qeqs,immoutsc,cis). tdr_kinds([c3(a,b) Rest],LOS, QEQS,ImmOutsc,[os(A,B) CIS]):- 52
53 tdr_kinds(rest,los,qeqs,immoutsc,cis). build_tree_w_globals(tdrs,tree,immoutsc2):- tdr_kinds(tdrs,los,qeqs,immoutsc,cis), collect_global_quants(los,global), specify_globality(tdrs,global,newbodystatms), append(immoutsc,newbodystatms,immoutsc2), collect_non_global_quas(los,immoutsc2,quas), collect_leaves(los,leaves), build_tree(_,tree,quas,leaves,[],[]), check_tree(tree,global,qeqs,cis). build_tree_no_globals(tdrs,tree):- tdr_kinds(tdrs,los,qeqs,immoutsc,cis), collect_non_global_quas(los,immoutsc,quas), collect_leaves(los,leaves), build_tree(_,tree,quas,leaves,[],[]), check_tree(tree,[],qeqs,cis). build_tree(t,[t:[]],quas,leaves,quas,leaves2):- select_any(t:[],leaves,leaves2). build_tree(t,[t:q1n(body),ptree],quas, LEAVES,QUAS3,LEAVES2):- select_any(t:q1n(body),quas,quas2), build_tree(body,ptree,quas2, LEAVES,QUAS3,LEAVES2). build_tree(t,[t:q2n(restr,body),rtree,btree],quas, LEAVES,QUAS4,LEAVES3):- select_any(t:q2n(restr,body),quas,quas2), build_tree(restr,rtree,quas2, LEAVES,QUAS3,LEAVES2), build_tree(body,btree,quas3, LEAVES2,QUAS4,LEAVES3). build_tree(t,[t:ptop(para),ptree],quas, LEAVES,QUAS3,LEAVES2):- select_any(t:ptop(para),quas,quas2), build_tree(para,ptree,quas2, LEAVES,QUAS3,LEAVES2). select_any(ep,[ep REST],REST). 53
54 select_any(ep,[x REST1],[X REST2]):- select_any(ep,rest1,rest2). check_tree(tree,global,qeqs,cis):- check_tree_qeqs(qeqs,tree), check_tree_cis(cis,tree,global). check_tree(tree,global,qeqs,cis,r1,r2):- check_tree_qeqs(qeqs,tree,r1), check_tree_cis(cis,tree,global,r2). check_tree_qeqs([],_). check_tree_qeqs([t1 qeq T2 QEQS],Tree):- qeq(t1,t2,tree), check_tree_qeqs(qeqs,tree). check_tree_qeqs([],_,ok). check_tree_qeqs([t1 qeq T2 QEQS],Tree,Res):- qeq(t1,t2,tree), check_tree_qeqs(qeqs,tree,res). check_tree_qeqs([t1 qeq T2 _],_,failing(t1 qeq T2)). qeq(t,t,_):-!. qeq(t1,t2,[t1:q2n(_,tx),_,body]):- qeq(tx,t2,body). qeq(t1,t2,[t1:q1n(tx),body]):- qeq(tx,t2,body). qeq(t1,t2,[_,subtree]):- qeq(t1,t2,subtree). qeq(t1,t2,[_,subtree,_]):- 54
55 qeq(t1,t2,subtree). qeq(t1,t2,[_,_,subtree]):- qeq(t1,t2,subtree). check_tree_cis([],_,_). check_tree_cis([os(t1,t2) CIS],Tree,GLOBAL):- outscopes(os(t1,t2),tree,global), check_tree_cis(cis,tree,global). check_tree_cis([],_,_,ok). check_tree_cis([os(t1,t2) CIS],Tree,GLOBAL,Res):- outscopes(os(t1,t2),tree,global), check_tree_cis(cis,tree,global,res). check_tree_cis([os(t1,t2) _],_,_,failing(os(t1,t2))):-!. outscopes(os(t1,_),_,global):- memberchk(t1,global). outscopes(os(t1,t2),tree,_):- outscopes_in_tree(t1,t2,tree). outscopes_in_tree(t1,t2,tree):- subtree(tree,t1,subtree), contains(subtree,t2). subtree([t1:x Rest],T1,[T1:X Rest]). subtree([_,restr,_],t1,subtree):- subtree(restr,t1,subtree). subtree([_,_,body],t1,subtree):- subtree(body,t1,subtree). subtree([_,para],t1,subtree):- subtree(para,t1,subtree). subtree_paratactic([t1:ptop(x) Rest],[T1:ptop(X) Rest]). 55
56 subtree_paratactic([_,restr,_],subtree):- subtree_paratactic(restr,subtree). subtree_paratactic([_,_,body],subtree):- subtree_paratactic(body,subtree). subtree_paratactic([_,para],subtree):- subtree_paratactic(para,subtree). contains([t:_ _],T). contains([_,subtree],t):- contains(subtree,t). contains([_,subtree,_],t):- contains(subtree,t). contains([_,_,subtree],t):- contains(subtree,t). extract_body_statements([q:q2n(_,body),t1,t2], [body(q,body) More]):- extract_body_statements(t1,b1), extract_body_statements(t2,b2), append(b1,b2,more). extract_body_statements([q:q1n(body),t1], [body(q,body) More]):- extract_body_statements(t1,more). extract_body_statements([_,t1],more):- extract_body_statements(t1,more). extract_body_statements([_],[]):-!. Prolog term displaying disp_prolog_term(t,provarnri,provarnro):- instantiate_vars(t,provarnri,provarnro), 56
57 print( <tt> ), print_prolog_terms(t), print( </tt> ). instantiate_vars(t,provarnri,provarnro):- var(t), make_symbol_for_var(t,provarnri,provarnro). instantiate_vars(t,provarnr,provarnr):- simple(t),!. instantiate_vars([h T],ProVarNrI,ProVarNrO):- instantiate_vars(h,provarnri,provarnrm), instantiate_vars(t,provarnrm,provarnro). instantiate_vars(t,provarnri,provarnro):- T =.. List, instantiate_vars(list,provarnri,provarnro). make_symbol_for_var(t,provarnri,provarnro):- name(provarnri,name), append([60,117,62,80 Name], [60,47,117,62],TT), name(t,tt), ProVarNrO is ProVarNrI + 1. print_prolog_terms(x):- var(x), print(x). print_prolog_terms([x:y Z]):- print_tree([x:y Z],0). This case finds cont:tree values. print_prolog_terms(x):- is_list(x), 57
Prolog-embedding typed feature structure grammar and grammar tool. Version 4.
 1 Prolog-embedding typed feature structure grammar and grammar tool. Version 4. Mats Dahllöf Department of Linguistics, Uppsala University E-mail: mats.dahllof@ling.uu.se August, 2002 Work in progress!
1 Prolog-embedding typed feature structure grammar and grammar tool. Version 4. Mats Dahllöf Department of Linguistics, Uppsala University E-mail: mats.dahllof@ling.uu.se August, 2002 Work in progress!
Wh-questions. Ling 567 May 9, 2017
 Wh-questions Ling 567 May 9, 2017 Overview Target representation The problem Solution for English Solution for pseudo-english Lab 7 overview Negative auxiliaries interactive debugging Wh-questions: Target
Wh-questions Ling 567 May 9, 2017 Overview Target representation The problem Solution for English Solution for pseudo-english Lab 7 overview Negative auxiliaries interactive debugging Wh-questions: Target
Computational Linguistics: Feature Agreement
 Computational Linguistics: Feature Agreement Raffaella Bernardi Contents 1 Admin................................................... 4 2 Formal Grammars......................................... 5 2.1 Recall:
Computational Linguistics: Feature Agreement Raffaella Bernardi Contents 1 Admin................................................... 4 2 Formal Grammars......................................... 5 2.1 Recall:
Grammar Knowledge Transfer for Building RMRSs over Dependency Parses in Bulgarian
 Grammar Knowledge Transfer for Building RMRSs over Dependency Parses in Bulgarian Kiril Simov and Petya Osenova Linguistic Modelling Department, IICT, Bulgarian Academy of Sciences DELPH-IN, Sofia, 2012
Grammar Knowledge Transfer for Building RMRSs over Dependency Parses in Bulgarian Kiril Simov and Petya Osenova Linguistic Modelling Department, IICT, Bulgarian Academy of Sciences DELPH-IN, Sofia, 2012
Dependency and (R)MRS
MRS") Dependency and (R)MRS Ann Copestake aac@cl.cam.ac.uk December 9, 2008 1 Introduction Note: for current purposes, this document lacks a proper introduction, in that it assumes readers know about MRS and
Dependency and (R)MRS Ann Copestake aac@cl.cam.ac.uk December 9, 2008 1 Introduction Note: for current purposes, this document lacks a proper introduction, in that it assumes readers know about MRS and
Ling/CSE 472: Introduction to Computational Linguistics. 5/9/17 Feature structures and unification
 Ling/CSE 472: Introduction to Computational Linguistics 5/9/17 Feature structures and unification Overview Problems with CFG Feature structures Unification Agreement Subcategorization Long-distance Dependencies
Ling/CSE 472: Introduction to Computational Linguistics 5/9/17 Feature structures and unification Overview Problems with CFG Feature structures Unification Agreement Subcategorization Long-distance Dependencies
Dependency grammar and dependency parsing
 Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2014-12-10 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Mid-course evaluation Mostly positive
Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2014-12-10 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Mid-course evaluation Mostly positive
Getting Started With Syntax October 15, 2015
 Getting Started With Syntax October 15, 2015 Introduction The Accordance Syntax feature allows both viewing and searching of certain original language texts that have both morphological tagging along with
Getting Started With Syntax October 15, 2015 Introduction The Accordance Syntax feature allows both viewing and searching of certain original language texts that have both morphological tagging along with
The Earley Parser
 The 6.863 Earley Parser 1 Introduction The 6.863 Earley parser will work with any well defined context free grammar, including recursive ones and those containing empty categories. It can use either no
The 6.863 Earley Parser 1 Introduction The 6.863 Earley parser will work with any well defined context free grammar, including recursive ones and those containing empty categories. It can use either no
Dependency grammar and dependency parsing
 Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2015-12-09 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2015-12-09 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
Dependency grammar and dependency parsing
 Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2016-12-05 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
Dependency grammar and dependency parsing Syntactic analysis (5LN455) 2016-12-05 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Activities - dependency parsing
13.1 End Marks Using Periods Rule Use a period to end a declarative sentence a statement of fact or opinion.
 13.1 End Marks Using Periods Rule 13.1.1 Use a period to end a declarative sentence a statement of fact or opinion. Rule 13.1.2 Use a period to end most imperative sentences sentences that give directions
13.1 End Marks Using Periods Rule 13.1.1 Use a period to end a declarative sentence a statement of fact or opinion. Rule 13.1.2 Use a period to end most imperative sentences sentences that give directions
Introduction to Lexical Functional Grammar. Wellformedness conditions on f- structures. Constraints on f-structures
 Introduction to Lexical Functional Grammar Session 8 f(unctional)-structure & c-structure/f-structure Mapping II & Wrap-up Summary of last week s lecture LFG-specific grammar rules (i.e. PS-rules annotated
Introduction to Lexical Functional Grammar Session 8 f(unctional)-structure & c-structure/f-structure Mapping II & Wrap-up Summary of last week s lecture LFG-specific grammar rules (i.e. PS-rules annotated
Context-Free Grammars
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 3, 2012 (CFGs) A CFG is an ordered quadruple T, N, D, P where a. T is a finite set called the terminals; b. N is a
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 3, 2012 (CFGs) A CFG is an ordered quadruple T, N, D, P where a. T is a finite set called the terminals; b. N is a
An Efficient Implementation of PATR for Categorial Unification Grammar
 An Efficient Implementation of PATR for Categorial Unification Grammar Todd Yampol Stanford University Lauri Karttunen Xerox PARC and CSLI 1 Introduction This paper describes C-PATR, a new C implementation
An Efficient Implementation of PATR for Categorial Unification Grammar Todd Yampol Stanford University Lauri Karttunen Xerox PARC and CSLI 1 Introduction This paper describes C-PATR, a new C implementation
Context-Free Grammars. Carl Pollard Ohio State University. Linguistics 680 Formal Foundations Tuesday, November 10, 2009
 Context-Free Grammars Carl Pollard Ohio State University Linguistics 680 Formal Foundations Tuesday, November 10, 2009 These slides are available at: http://www.ling.osu.edu/ scott/680 1 (1) Context-Free
Context-Free Grammars Carl Pollard Ohio State University Linguistics 680 Formal Foundations Tuesday, November 10, 2009 These slides are available at: http://www.ling.osu.edu/ scott/680 1 (1) Context-Free
L322 Syntax. Chapter 3: Structural Relations. Linguistics 322 D E F G H. Another representation is in the form of labelled brackets:
 L322 Syntax Chapter 3: Structural Relations Linguistics 322 1 The Parts of a Tree A tree structure is one of an indefinite number of ways to represent a sentence or a part of it. Consider the following
L322 Syntax Chapter 3: Structural Relations Linguistics 322 1 The Parts of a Tree A tree structure is one of an indefinite number of ways to represent a sentence or a part of it. Consider the following
Documentation and analysis of an. endangered language: aspects of. the grammar of Griko
 Documentation and analysis of an endangered language: aspects of the grammar of Griko Database and Website manual Antonis Anastasopoulos Marika Lekakou NTUA UOI December 12, 2013 Contents Introduction...............................
Documentation and analysis of an endangered language: aspects of the grammar of Griko Database and Website manual Antonis Anastasopoulos Marika Lekakou NTUA UOI December 12, 2013 Contents Introduction...............................
Computational Linguistics (INF2820 TFSs)
") S NP Det N VP V The dog barked LTOP h 1 INDEX e 2 def q rel bark v rel prpstn m rel LBL h 4 dog n rel LBL h RELS LBL h 1 ARG0 x 5 LBL h 9 8 ARG0 e MARG h 3 RSTR h 6 ARG0 x 2 5 ARG1 x BODY h 5 7 HCONS h
S NP Det N VP V The dog barked LTOP h 1 INDEX e 2 def q rel bark v rel prpstn m rel LBL h 4 dog n rel LBL h RELS LBL h 1 ARG0 x 5 LBL h 9 8 ARG0 e MARG h 3 RSTR h 6 ARG0 x 2 5 ARG1 x BODY h 5 7 HCONS h
RSL Reference Manual
 RSL Reference Manual Part No.: Date: April 6, 1990 Original Authors: Klaus Havelund, Anne Haxthausen Copyright c 1990 Computer Resources International A/S This document is issued on a restricted basis
RSL Reference Manual Part No.: Date: April 6, 1990 Original Authors: Klaus Havelund, Anne Haxthausen Copyright c 1990 Computer Resources International A/S This document is issued on a restricted basis
Context-Free Grammars
 Context-Free Grammars Carl Pollard yntax 2 (Linguistics 602.02) January 3, 2012 Context-Free Grammars (CFGs) A CFG is an ordered quadruple T, N, D, P where a. T is a finite set called the terminals; b.
Context-Free Grammars Carl Pollard yntax 2 (Linguistics 602.02) January 3, 2012 Context-Free Grammars (CFGs) A CFG is an ordered quadruple T, N, D, P where a. T is a finite set called the terminals; b.
Grammar Development with LFG and XLE. Miriam Butt University of Konstanz
 Grammar Development with LFG and XLE Miriam Butt University of Konstanz Last Time Integration of a Finite-State Morphological Analyzer - Sublexical Rules - Sublexical Entries - The -unknown entry The XLE
Grammar Development with LFG and XLE Miriam Butt University of Konstanz Last Time Integration of a Finite-State Morphological Analyzer - Sublexical Rules - Sublexical Entries - The -unknown entry The XLE
Week 2: Syntax Specification, Grammars
 CS320 Principles of Programming Languages Week 2: Syntax Specification, Grammars Jingke Li Portland State University Fall 2017 PSU CS320 Fall 17 Week 2: Syntax Specification, Grammars 1/ 62 Words and Sentences
CS320 Principles of Programming Languages Week 2: Syntax Specification, Grammars Jingke Li Portland State University Fall 2017 PSU CS320 Fall 17 Week 2: Syntax Specification, Grammars 1/ 62 Words and Sentences
Clausal Architecture and Verb Movement
 Introduction to Transformational Grammar, LINGUIST 601 October 1, 2004 Clausal Architecture and Verb Movement 1 Clausal Architecture 1.1 The Hierarchy of Projection (1) a. John must leave now. b. John
Introduction to Transformational Grammar, LINGUIST 601 October 1, 2004 Clausal Architecture and Verb Movement 1 Clausal Architecture 1.1 The Hierarchy of Projection (1) a. John must leave now. b. John
Introduction to Lexical Analysis
 Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexical analyzers (lexers) Regular
Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexical analyzers (lexers) Regular
Introduction to Lexical Analysis
 Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexers Regular expressions Examples
Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexers Regular expressions Examples
Lexical Analysis. Chapter 2
 Lexical Analysis Chapter 2 1 Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexers Regular expressions Examples
Lexical Analysis Chapter 2 1 Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexers Regular expressions Examples
Unification in Unification-based Grammar
 THE SIXTH JAPANESE-KOREAN JOINT CONFERENCE ON FORMAL LINGUISTICS,1991 Unification in Unification-based Grammar K.S.Choi, D.J.Son, and G.C.Kim Department of Computer Science Korea Advanced Institute of
THE SIXTH JAPANESE-KOREAN JOINT CONFERENCE ON FORMAL LINGUISTICS,1991 Unification in Unification-based Grammar K.S.Choi, D.J.Son, and G.C.Kim Department of Computer Science Korea Advanced Institute of
INF FALL NATURAL LANGUAGE PROCESSING. Jan Tore Lønning, Lecture 4, 10.9
 1 INF5830 2015 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning, Lecture 4, 10.9 2 Working with texts From bits to meaningful units Today: 3 Reading in texts Character encodings and Unicode Word tokenization
1 INF5830 2015 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning, Lecture 4, 10.9 2 Working with texts From bits to meaningful units Today: 3 Reading in texts Character encodings and Unicode Word tokenization
More Theories, Formal semantics
 Parts are based on slides by Carl Pollard Charles University, 2011-11-12 Optimality Theory Universal set of violable constraints: Faithfulness constraints:surface forms should be as close as to underlying
Parts are based on slides by Carl Pollard Charles University, 2011-11-12 Optimality Theory Universal set of violable constraints: Faithfulness constraints:surface forms should be as close as to underlying
COMPUTATIONAL SEMANTICS WITH FUNCTIONAL PROGRAMMING JAN VAN EIJCK AND CHRISTINA UNGER. lg Cambridge UNIVERSITY PRESS
 COMPUTATIONAL SEMANTICS WITH FUNCTIONAL PROGRAMMING JAN VAN EIJCK AND CHRISTINA UNGER lg Cambridge UNIVERSITY PRESS ^0 Contents Foreword page ix Preface xiii 1 Formal Study of Natural Language 1 1.1 The
COMPUTATIONAL SEMANTICS WITH FUNCTIONAL PROGRAMMING JAN VAN EIJCK AND CHRISTINA UNGER lg Cambridge UNIVERSITY PRESS ^0 Contents Foreword page ix Preface xiii 1 Formal Study of Natural Language 1 1.1 The
Grammar Engineering for Deep Linguistic Processing SS2012
 for Deep Linguistic Processing SS2012 Lecture 3: TDL Department of Computational Linguistics & Phonetics Saarland University Language Technology Lab German Research Center for Artificial Intelligence May,
for Deep Linguistic Processing SS2012 Lecture 3: TDL Department of Computational Linguistics & Phonetics Saarland University Language Technology Lab German Research Center for Artificial Intelligence May,
Principles of Programming Languages COMP251: Syntax and Grammars
 Principles of Programming Languages COMP251: Syntax and Grammars Prof. Dekai Wu Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong, China Fall 2006
Principles of Programming Languages COMP251: Syntax and Grammars Prof. Dekai Wu Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong, China Fall 2006
October 19, 2004 Chapter Parsing
 October 19, 2004 Chapter 10.3 10.6 Parsing 1 Overview Review: CFGs, basic top-down parser Dynamic programming Earley algorithm (how it works, how it solves the problems) Finite-state parsing 2 Last time
October 19, 2004 Chapter 10.3 10.6 Parsing 1 Overview Review: CFGs, basic top-down parser Dynamic programming Earley algorithm (how it works, how it solves the problems) Finite-state parsing 2 Last time
Paper Proof Manual. As a Student... Paper Proof Manual
 Paper Proof consists of a large whiteboard region. Along the left hand side is the buttons bar. Details on the various button bar items will be given here. Along the top of the paper proof page is a tool
Paper Proof consists of a large whiteboard region. Along the left hand side is the buttons bar. Details on the various button bar items will be given here. Along the top of the paper proof page is a tool
Chapter 4. Lexical and Syntax Analysis. Topics. Compilation. Language Implementation. Issues in Lexical and Syntax Analysis.
 Topics Chapter 4 Lexical and Syntax Analysis Introduction Lexical Analysis Syntax Analysis Recursive -Descent Parsing Bottom-Up parsing 2 Language Implementation Compilation There are three possible approaches
Topics Chapter 4 Lexical and Syntax Analysis Introduction Lexical Analysis Syntax Analysis Recursive -Descent Parsing Bottom-Up parsing 2 Language Implementation Compilation There are three possible approaches
1 Informal Motivation
 CHAPTER SEVEN: (PRE)SEMILATTICES AND TREES 1 Informal Motivation As we will illustrate presently, given a CFG T,N,D,P, a nonterminal A N, and a T-string s C A, we can use the CFG to guide us in constructing
CHAPTER SEVEN: (PRE)SEMILATTICES AND TREES 1 Informal Motivation As we will illustrate presently, given a CFG T,N,D,P, a nonterminal A N, and a T-string s C A, we can use the CFG to guide us in constructing
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Feature Structures Merkmalsstrukturen Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2018 1 / 23 Introduction (1) Non-terminals that are used in CFGs
Einführung in die Computerlinguistik Feature Structures Merkmalsstrukturen Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2018 1 / 23 Introduction (1) Non-terminals that are used in CFGs
Alphabetical Index referenced by section numbers for PUNCTUATION FOR FICTION WRITERS by Rick Taubold, PhD and Scott Gamboe
 Alphabetical Index referenced by section numbers for PUNCTUATION FOR FICTION WRITERS by Rick Taubold, PhD and Scott Gamboe?! 4.7 Abbreviations 4.1.2, 4.1.3 Abbreviations, plurals of 7.8.1 Accented letters
Alphabetical Index referenced by section numbers for PUNCTUATION FOR FICTION WRITERS by Rick Taubold, PhD and Scott Gamboe?! 4.7 Abbreviations 4.1.2, 4.1.3 Abbreviations, plurals of 7.8.1 Accented letters
Syntax 380L December 4, Wh-Movement 2. For notational convenience, I have used traces (t i,t j etc.) to indicate copies throughout this handout.
 to indicate copies throughout this handout.") Syntax 380L December 4, 2001 Wh-Movement 2 For notational convenience, I have used traces (t i,t j etc.) to indicate copies throughout this handout. 1 The Basics of wh-movement (1) Who i does John think
Syntax 380L December 4, 2001 Wh-Movement 2 For notational convenience, I have used traces (t i,t j etc.) to indicate copies throughout this handout. 1 The Basics of wh-movement (1) Who i does John think
Elementary Operations, Clausal Architecture, and Verb Movement
 Introduction to Transformational Grammar, LINGUIST 601 October 3, 2006 Elementary Operations, Clausal Architecture, and Verb Movement 1 Elementary Operations This discussion is based on?:49-52. 1.1 Merge
Introduction to Transformational Grammar, LINGUIST 601 October 3, 2006 Elementary Operations, Clausal Architecture, and Verb Movement 1 Elementary Operations This discussion is based on?:49-52. 1.1 Merge
Indexing Methods for Efficient Parsing with Typed Feature Structure Grammars
 Indexing Methods for Efficient Parsing with Typed Feature Structure Grammars Cosmin Munteanu A thesis submitted in conformity with the requirements for the degree of Master of Science Department of Computer
Indexing Methods for Efficient Parsing with Typed Feature Structure Grammars Cosmin Munteanu A thesis submitted in conformity with the requirements for the degree of Master of Science Department of Computer
Ling 571: Deep Processing for Natural Language Processing
 Ling 571: Deep Processing for Natural Language Processing Julie Medero January 14, 2013 Today s Plan Motivation for Parsing Parsing as Search Search algorithms Search Strategies Issues Two Goal of Parsing
Ling 571: Deep Processing for Natural Language Processing Julie Medero January 14, 2013 Today s Plan Motivation for Parsing Parsing as Search Search algorithms Search Strategies Issues Two Goal of Parsing
Proseminar on Semantic Theory Fall 2013 Ling 720 An Algebraic Perspective on the Syntax of First Order Logic (Without Quantification) 1
 1") An Algebraic Perspective on the Syntax of First Order Logic (Without Quantification) 1 1. Statement of the Problem, Outline of the Solution to Come (1) The Key Problem There is much to recommend an algebraic
An Algebraic Perspective on the Syntax of First Order Logic (Without Quantification) 1 1. Statement of the Problem, Outline of the Solution to Come (1) The Key Problem There is much to recommend an algebraic
CMSC 331 Final Exam Section 0201 December 18, 2000
 CMSC 331 Final Exam Section 0201 December 18, 2000 Name: Student ID#: You will have two hours to complete this closed book exam. We reserve the right to assign partial credit, and to deduct points for
CMSC 331 Final Exam Section 0201 December 18, 2000 Name: Student ID#: You will have two hours to complete this closed book exam. We reserve the right to assign partial credit, and to deduct points for
Lexical Analysis. Lecture 2-4
 Lexical Analysis Lecture 2-4 Notes by G. Necula, with additions by P. Hilfinger Prof. Hilfinger CS 164 Lecture 2 1 Administrivia Moving to 60 Evans on Wednesday HW1 available Pyth manual available on line.
Lexical Analysis Lecture 2-4 Notes by G. Necula, with additions by P. Hilfinger Prof. Hilfinger CS 164 Lecture 2 1 Administrivia Moving to 60 Evans on Wednesday HW1 available Pyth manual available on line.
CS 4240: Compilers and Interpreters Project Phase 1: Scanner and Parser Due Date: October 4 th 2015 (11:59 pm) (via T-square)
 (via T-square)") CS 4240: Compilers and Interpreters Project Phase 1: Scanner and Parser Due Date: October 4 th 2015 (11:59 pm) (via T-square) Introduction This semester, through a project split into 3 phases, we are going
CS 4240: Compilers and Interpreters Project Phase 1: Scanner and Parser Due Date: October 4 th 2015 (11:59 pm) (via T-square) Introduction This semester, through a project split into 3 phases, we are going
The CKY algorithm part 2: Probabilistic parsing
 The CKY algorithm part 2: Probabilistic parsing Syntactic analysis/parsing 2017-11-14 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Recap: The CKY algorithm The
The CKY algorithm part 2: Probabilistic parsing Syntactic analysis/parsing 2017-11-14 Sara Stymne Department of Linguistics and Philology Based on slides from Marco Kuhlmann Recap: The CKY algorithm The
Lexical Analysis. Lecture 3-4
 Lexical Analysis Lecture 3-4 Notes by G. Necula, with additions by P. Hilfinger Prof. Hilfinger CS 164 Lecture 3-4 1 Administrivia I suggest you start looking at Python (see link on class home page). Please
Lexical Analysis Lecture 3-4 Notes by G. Necula, with additions by P. Hilfinger Prof. Hilfinger CS 164 Lecture 3-4 1 Administrivia I suggest you start looking at Python (see link on class home page). Please
Syntactic Analysis. CS345H: Programming Languages. Lecture 3: Lexical Analysis. Outline. Lexical Analysis. What is a Token? Tokens
 Syntactic Analysis CS45H: Programming Languages Lecture : Lexical Analysis Thomas Dillig Main Question: How to give structure to strings Analogy: Understanding an English sentence First, we separate a
Syntactic Analysis CS45H: Programming Languages Lecture : Lexical Analysis Thomas Dillig Main Question: How to give structure to strings Analogy: Understanding an English sentence First, we separate a
AUTOMATIC LFG GENERATION
 AUTOMATIC LFG GENERATION MS Thesis for the Degree of Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science (Computer Science) at the National University of Computer and
AUTOMATIC LFG GENERATION MS Thesis for the Degree of Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science (Computer Science) at the National University of Computer and
Programming Language Concepts, cs2104 Lecture 04 ( )
") Programming Language Concepts, cs2104 Lecture 04 (2003-08-29) Seif Haridi Department of Computer Science, NUS haridi@comp.nus.edu.sg 2003-09-05 S. Haridi, CS2104, L04 (slides: C. Schulte, S. Haridi) 1
Programming Language Concepts, cs2104 Lecture 04 (2003-08-29) Seif Haridi Department of Computer Science, NUS haridi@comp.nus.edu.sg 2003-09-05 S. Haridi, CS2104, L04 (slides: C. Schulte, S. Haridi) 1
Administrivia. Lexical Analysis. Lecture 2-4. Outline. The Structure of a Compiler. Informal sketch of lexical analysis. Issues in lexical analysis
 dministrivia Lexical nalysis Lecture 2-4 Notes by G. Necula, with additions by P. Hilfinger Moving to 6 Evans on Wednesday HW available Pyth manual available on line. Please log into your account and electronically
dministrivia Lexical nalysis Lecture 2-4 Notes by G. Necula, with additions by P. Hilfinger Moving to 6 Evans on Wednesday HW available Pyth manual available on line. Please log into your account and electronically
COMP 181 Compilers. Administrative. Last time. Prelude. Compilation strategy. Translation strategy. Lecture 2 Overview
 COMP 181 Compilers Lecture 2 Overview September 7, 2006 Administrative Book? Hopefully: Compilers by Aho, Lam, Sethi, Ullman Mailing list Handouts? Programming assignments For next time, write a hello,
COMP 181 Compilers Lecture 2 Overview September 7, 2006 Administrative Book? Hopefully: Compilers by Aho, Lam, Sethi, Ullman Mailing list Handouts? Programming assignments For next time, write a hello,
Defining Program Syntax. Chapter Two Modern Programming Languages, 2nd ed. 1
 Defining Program Syntax Chapter Two Modern Programming Languages, 2nd ed. 1 Syntax And Semantics Programming language syntax: how programs look, their form and structure Syntax is defined using a kind
Defining Program Syntax Chapter Two Modern Programming Languages, 2nd ed. 1 Syntax And Semantics Programming language syntax: how programs look, their form and structure Syntax is defined using a kind
Programming Languages Third Edition
 Programming Languages Third Edition Chapter 12 Formal Semantics Objectives Become familiar with a sample small language for the purpose of semantic specification Understand operational semantics Understand
Programming Languages Third Edition Chapter 12 Formal Semantics Objectives Become familiar with a sample small language for the purpose of semantic specification Understand operational semantics Understand
Ling/CSE 472: Introduction to Computational Linguistics. 5/21/12 Unification, parsing with unification Meaning representation
 Ling/CSE 472: Introduction to Computational Linguistics 5/21/12 Unification, parsing with unification Meaning representation Overview Unification Unification algorithm Parsing with unification Representing
Ling/CSE 472: Introduction to Computational Linguistics 5/21/12 Unification, parsing with unification Meaning representation Overview Unification Unification algorithm Parsing with unification Representing
11. a b c d e. 12. a b c d e. 13. a b c d e. 14. a b c d e. 15. a b c d e
 CS-3160 Concepts of Programming Languages Spring 2015 EXAM #1 (Chapters 1-6) Name: SCORES MC: /75 PROB #1: /15 PROB #2: /10 TOTAL: /100 Multiple Choice Responses Each multiple choice question in the separate
CS-3160 Concepts of Programming Languages Spring 2015 EXAM #1 (Chapters 1-6) Name: SCORES MC: /75 PROB #1: /15 PROB #2: /10 TOTAL: /100 Multiple Choice Responses Each multiple choice question in the separate
Exam III March 17, 2010
 CIS 4930 NLP Print Your Name Exam III March 17, 2010 Total Score Your work is to be done individually. The exam is worth 106 points (six points of extra credit are available throughout the exam) and it
CIS 4930 NLP Print Your Name Exam III March 17, 2010 Total Score Your work is to be done individually. The exam is worth 106 points (six points of extra credit are available throughout the exam) and it
Prolog Introduction. Gunnar Gotshalks PI-1
 Prolog Introduction PI-1 Physical Symbol System Hypothesis A physical symbol system has the necessary and sufficient means for general intelligent action. Allen Newell and Herbert A. Simon PI-2 Physical
Prolog Introduction PI-1 Physical Symbol System Hypothesis A physical symbol system has the necessary and sufficient means for general intelligent action. Allen Newell and Herbert A. Simon PI-2 Physical
Lexical Analysis. Dragon Book Chapter 3 Formal Languages Regular Expressions Finite Automata Theory Lexical Analysis using Automata
 Lexical Analysis Dragon Book Chapter 3 Formal Languages Regular Expressions Finite Automata Theory Lexical Analysis using Automata Phase Ordering of Front-Ends Lexical analysis (lexer) Break input string
Lexical Analysis Dragon Book Chapter 3 Formal Languages Regular Expressions Finite Automata Theory Lexical Analysis using Automata Phase Ordering of Front-Ends Lexical analysis (lexer) Break input string
Introduction to Scheme
 How do you describe them Introduction to Scheme Gul Agha CS 421 Fall 2006 A language is described by specifying its syntax and semantics Syntax: The rules for writing programs. We will use Context Free
How do you describe them Introduction to Scheme Gul Agha CS 421 Fall 2006 A language is described by specifying its syntax and semantics Syntax: The rules for writing programs. We will use Context Free
By Marco V. Fabbri. Some searches in the GNT-T.Syntax require the use of the Greek Construct Window.
 Greek Syntax Search Examples from the Accordance Forums By Marco V. Fabbri The following material was compiled from the Accordance Forums. Formatting has been tweaked slightly and a few typos corrected.
Greek Syntax Search Examples from the Accordance Forums By Marco V. Fabbri The following material was compiled from the Accordance Forums. Formatting has been tweaked slightly and a few typos corrected.
Homework & NLTK. CS 181: Natural Language Processing Lecture 9: Context Free Grammars. Motivation. Formal Def of CFG. Uses of CFG.
 C 181: Natural Language Processing Lecture 9: Context Free Grammars Kim Bruce Pomona College pring 2008 Homework & NLTK Review MLE, Laplace, and Good-Turing in smoothing.py Disclaimer: lide contents borrowed
C 181: Natural Language Processing Lecture 9: Context Free Grammars Kim Bruce Pomona College pring 2008 Homework & NLTK Review MLE, Laplace, and Good-Turing in smoothing.py Disclaimer: lide contents borrowed
A Brief Incomplete Introduction to NLTK
 A Brief Incomplete Introduction to NLTK This introduction ignores and simplifies many aspects of the Natural Language TookKit, focusing on implementing and using simple context-free grammars and lexicons.
A Brief Incomplete Introduction to NLTK This introduction ignores and simplifies many aspects of the Natural Language TookKit, focusing on implementing and using simple context-free grammars and lexicons.
Lecture 5. Logic I. Statement Logic
 Ling 726: Mathematical Linguistics, Logic. Statement Logic V. Borschev and B. Partee, September 27, 2 p. Lecture 5. Logic I. Statement Logic. Statement Logic...... Goals..... Syntax of Statement Logic....2.
Ling 726: Mathematical Linguistics, Logic. Statement Logic V. Borschev and B. Partee, September 27, 2 p. Lecture 5. Logic I. Statement Logic. Statement Logic...... Goals..... Syntax of Statement Logic....2.
Ling 571: Deep Processing for Natural Language Processing
 Ling 571: Deep Processing for Natural Language Processing Julie Medero February 4, 2013 Today s Plan Assignment Check-in Project 1 Wrap-up CKY Implementations HW2 FAQs: evalb Features & Unification Project
Ling 571: Deep Processing for Natural Language Processing Julie Medero February 4, 2013 Today s Plan Assignment Check-in Project 1 Wrap-up CKY Implementations HW2 FAQs: evalb Features & Unification Project
A Minimal GB Parser. Marwan Shaban. October 26, Boston University
 A Minimal GB Parser Marwan Shaban shaban@cs.bu.edu October 26, 1993 BU-CS Tech Report # 93-013 Computer Science Department Boston University 111 Cummington Street Boston, MA 02215 Abstract: We describe
A Minimal GB Parser Marwan Shaban shaban@cs.bu.edu October 26, 1993 BU-CS Tech Report # 93-013 Computer Science Department Boston University 111 Cummington Street Boston, MA 02215 Abstract: We describe
Functional programming with Common Lisp
 Functional programming with Common Lisp Dr. C. Constantinides Department of Computer Science and Software Engineering Concordia University Montreal, Canada August 11, 2016 1 / 81 Expressions and functions
Functional programming with Common Lisp Dr. C. Constantinides Department of Computer Science and Software Engineering Concordia University Montreal, Canada August 11, 2016 1 / 81 Expressions and functions
Multiword deconstruction in AnCora dependencies and final release data
 Multiword deconstruction in AnCora dependencies and final release data TECHNICAL REPORT GLICOM 2014-1 Benjamin Kolz, Toni Badia, Roser Saurí Universitat Pompeu Fabra {benjamin.kolz, toni.badia, roser.sauri}@upf.edu
Multiword deconstruction in AnCora dependencies and final release data TECHNICAL REPORT GLICOM 2014-1 Benjamin Kolz, Toni Badia, Roser Saurí Universitat Pompeu Fabra {benjamin.kolz, toni.badia, roser.sauri}@upf.edu
Maximum Entropy based Natural Language Interface for Relational Database
 International Journal of Engineering Research and Technology. ISSN 0974-3154 Volume 7, Number 1 (2014), pp. 69-77 International Research Publication House http://www.irphouse.com Maximum Entropy based
International Journal of Engineering Research and Technology. ISSN 0974-3154 Volume 7, Number 1 (2014), pp. 69-77 International Research Publication House http://www.irphouse.com Maximum Entropy based
Briefly describe the purpose of the lexical and syntax analysis phases in a compiler.
 Name: Midterm Exam PID: This is a closed-book exam; you may not use any tools besides a pen. You have 75 minutes to answer all questions. There are a total of 75 points available. Please write legibly;
Name: Midterm Exam PID: This is a closed-book exam; you may not use any tools besides a pen. You have 75 minutes to answer all questions. There are a total of 75 points available. Please write legibly;
CSE450 Translation of Programming Languages. Lecture 4: Syntax Analysis
 CSE450 Translation of Programming Languages Lecture 4: Syntax Analysis http://xkcd.com/859 Structure of a Today! Compiler Source Language Lexical Analyzer Syntax Analyzer Semantic Analyzer Int. Code Generator
CSE450 Translation of Programming Languages Lecture 4: Syntax Analysis http://xkcd.com/859 Structure of a Today! Compiler Source Language Lexical Analyzer Syntax Analyzer Semantic Analyzer Int. Code Generator
PL Revision overview
 PL Revision overview Course topics Parsing G = (S, P, NT, T); (E)BNF; recursive descent predictive parser (RDPP) Lexical analysis; Syntax and semantic errors; type checking Programming language structure
PL Revision overview Course topics Parsing G = (S, P, NT, T); (E)BNF; recursive descent predictive parser (RDPP) Lexical analysis; Syntax and semantic errors; type checking Programming language structure
Unification encodings of grammatical notations 1
 Unification encodings of grammatical notations 1 Stephen G. Pulman SRI International Cambridge Computer Science Research Centre 2 and University of Cambridge Computer Laboratory This paper describes various
Unification encodings of grammatical notations 1 Stephen G. Pulman SRI International Cambridge Computer Science Research Centre 2 and University of Cambridge Computer Laboratory This paper describes various
Ling/CSE 472: Introduction to Computational Linguistics. 5/4/17 Parsing
 Ling/CSE 472: Introduction to Computational Linguistics 5/4/17 Parsing Reminders Revised project plan due tomorrow Assignment 4 is available Overview Syntax v. parsing Earley CKY (briefly) Chart parsing
Ling/CSE 472: Introduction to Computational Linguistics 5/4/17 Parsing Reminders Revised project plan due tomorrow Assignment 4 is available Overview Syntax v. parsing Earley CKY (briefly) Chart parsing
COSC252: Programming Languages: Semantic Specification. Jeremy Bolton, PhD Adjunct Professor
 COSC252: Programming Languages: Semantic Specification Jeremy Bolton, PhD Adjunct Professor Outline I. What happens after syntactic analysis (parsing)? II. Attribute Grammars: bridging the gap III. Semantic
COSC252: Programming Languages: Semantic Specification Jeremy Bolton, PhD Adjunct Professor Outline I. What happens after syntactic analysis (parsing)? II. Attribute Grammars: bridging the gap III. Semantic
About the Tutorial. Audience. Prerequisites. Copyright & Disclaimer. Compiler Design
 i About the Tutorial A compiler translates the codes written in one language to some other language without changing the meaning of the program. It is also expected that a compiler should make the target
i About the Tutorial A compiler translates the codes written in one language to some other language without changing the meaning of the program. It is also expected that a compiler should make the target
AVM Description Compilation using Types as Modes
 AVM Description Compilation using Types as Modes Gerald Penn Department of Computer Science University of Toronto gpenn@cs.toronto.edu Abstract This paper provides a method for generating compact and efficient
AVM Description Compilation using Types as Modes Gerald Penn Department of Computer Science University of Toronto gpenn@cs.toronto.edu Abstract This paper provides a method for generating compact and efficient
Hidden Markov Models. Natural Language Processing: Jordan Boyd-Graber. University of Colorado Boulder LECTURE 20. Adapted from material by Ray Mooney
 Hidden Markov Models Natural Language Processing: Jordan Boyd-Graber University of Colorado Boulder LECTURE 20 Adapted from material by Ray Mooney Natural Language Processing: Jordan Boyd-Graber Boulder
Hidden Markov Models Natural Language Processing: Jordan Boyd-Graber University of Colorado Boulder LECTURE 20 Adapted from material by Ray Mooney Natural Language Processing: Jordan Boyd-Graber Boulder
UNIVERSITY OF EDINBURGH COLLEGE OF SCIENCE AND ENGINEERING SCHOOL OF INFORMATICS INFR08008 INFORMATICS 2A: PROCESSING FORMAL AND NATURAL LANGUAGES
 UNIVERSITY OF EDINBURGH COLLEGE OF SCIENCE AND ENGINEERING SCHOOL OF INFORMATICS INFR08008 INFORMATICS 2A: PROCESSING FORMAL AND NATURAL LANGUAGES Saturday 10 th December 2016 09:30 to 11:30 INSTRUCTIONS
UNIVERSITY OF EDINBURGH COLLEGE OF SCIENCE AND ENGINEERING SCHOOL OF INFORMATICS INFR08008 INFORMATICS 2A: PROCESSING FORMAL AND NATURAL LANGUAGES Saturday 10 th December 2016 09:30 to 11:30 INSTRUCTIONS
1 Introduction. 2 Set-Theory Formalisms. Formal Semantics -W2: Limitations of a Set-Theoretic Model SWU LI713 Meagan Louie August 2015
 Formal Semantics -W2: Limitations of a Set-Theoretic Model SWU LI713 Meagan Louie August 2015 1 Introduction Recall from last week: The Semantic System 1. The Model/Ontology 2. Lexical Entries 3. Compositional
Formal Semantics -W2: Limitations of a Set-Theoretic Model SWU LI713 Meagan Louie August 2015 1 Introduction Recall from last week: The Semantic System 1. The Model/Ontology 2. Lexical Entries 3. Compositional
CSE6390E PROJECT REPORT HALUK MADENCIOGLU. April 20, 2010
 CSE6390E PROJECT REPORT HALUK MADENCIOGLU April 20, 2010 This report describes the design and implementation of a system of programs to deal with parsing natural language, building semantic structures
CSE6390E PROJECT REPORT HALUK MADENCIOGLU April 20, 2010 This report describes the design and implementation of a system of programs to deal with parsing natural language, building semantic structures
Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras
 Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras Lecture - 25 Tutorial 5: Analyzing text using Python NLTK Hi everyone,
Privacy and Security in Online Social Networks Department of Computer Science and Engineering Indian Institute of Technology, Madras Lecture - 25 Tutorial 5: Analyzing text using Python NLTK Hi everyone,
Scope and Situation Binding in LTAG using Semantic Unification
 Scope and Situation Binding in LTAG using Semantic Unification Laura Kallmeyer (lk@sfs.uni-tuebingen.de) SFB 441, University of Tübingen, Nauklerstr: 35, D-72074 Tübingen, Germany. Maribel Romero (romero@ling.upenn.edu)
Scope and Situation Binding in LTAG using Semantic Unification Laura Kallmeyer (lk@sfs.uni-tuebingen.de) SFB 441, University of Tübingen, Nauklerstr: 35, D-72074 Tübingen, Germany. Maribel Romero (romero@ling.upenn.edu)
A Tag For Punctuation
 A Tag For Punctuation Alexei Lavrentiev To cite this version: Alexei Lavrentiev. A Tag For Punctuation. TEI Members Meeting 2008, Nov 2008, London, United Kingdom. HAL Id: halshs-00620104
A Tag For Punctuation Alexei Lavrentiev To cite this version: Alexei Lavrentiev. A Tag For Punctuation. TEI Members Meeting 2008, Nov 2008, London, United Kingdom. HAL Id: halshs-00620104
Syntax-semantics interface and the non-trivial computation of meaning
 1 Syntax-semantics interface and the non-trivial computation of meaning APA/ASL Group Meeting GVI-2: Lambda Calculi, Type Systems, and Applications to Natural Language APA Eastern Division 108th Annual
1 Syntax-semantics interface and the non-trivial computation of meaning APA/ASL Group Meeting GVI-2: Lambda Calculi, Type Systems, and Applications to Natural Language APA Eastern Division 108th Annual
Knowledge Engineering for NLP May 1, 2005 Clausal semantics
 Knowledge Engineering for NLP May 1, 2005 Clausal semantics Overview Why clausal semantics? What s a clause? Messages in G&S, MRS, the Matrix Messages and the syntax-semantics interface Details about this
Knowledge Engineering for NLP May 1, 2005 Clausal semantics Overview Why clausal semantics? What s a clause? Messages in G&S, MRS, the Matrix Messages and the syntax-semantics interface Details about this
Optimizing Typed Feature Structure Grammar Parsing through Non-Statistical Indexing
 Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, 2004 Optimizing Typed Feature Structure Grammar Parsing through Non-Statistical Indexing Cosmin
Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, 2004 Optimizing Typed Feature Structure Grammar Parsing through Non-Statistical Indexing Cosmin
The next several pages summarize some of the best techniques to achieve these three goals.
 Writing and Reviewing Documents You are required to write the following documents in this course: 1) A description of your GPS data collection and results. 2) A technical description of a data collection
Writing and Reviewing Documents You are required to write the following documents in this course: 1) A description of your GPS data collection and results. 2) A technical description of a data collection
Principles of Programming Languages COMP251: Syntax and Grammars
 Principles of Programming Languages COMP251: Syntax and Grammars Prof. Dekai Wu Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong, China Fall 2007
Principles of Programming Languages COMP251: Syntax and Grammars Prof. Dekai Wu Department of Computer Science and Engineering The Hong Kong University of Science and Technology Hong Kong, China Fall 2007
Module Title: Informatics 2A Exam Diet (Dec/April/Aug): Aug 2016 Brief notes on answers: 1. (a) The equations are
: Aug 2016 Brief notes on answers: 1. (a) The equations are") Module Title: Informatics 2A Exam Diet (Dec/April/Aug): Aug 2016 Brief notes on answers: 1. (a) The equations are X p = 0X s + (1 9)X r + X q X q = (1 9)X r X r = ɛ + (0 9)X r X s = ɛ [2 marks for the
Module Title: Informatics 2A Exam Diet (Dec/April/Aug): Aug 2016 Brief notes on answers: 1. (a) The equations are X p = 0X s + (1 9)X r + X q X q = (1 9)X r X r = ɛ + (0 9)X r X s = ɛ [2 marks for the
1. true / false By a compiler we mean a program that translates to code that will run natively on some machine.
 1. true / false By a compiler we mean a program that translates to code that will run natively on some machine. 2. true / false ML can be compiled. 3. true / false FORTRAN can reasonably be considered
1. true / false By a compiler we mean a program that translates to code that will run natively on some machine. 2. true / false ML can be compiled. 3. true / false FORTRAN can reasonably be considered
Processing Robustly Natural Language The Chaos Experience. User s Survival Guide
 Processing Robustly Natural Language The Chaos Experience User s Survival Guide Roberto Basili Daniele Pighin Fabio Massimo Zanzotto University of Rome Tor Vergata, Department of Computer Science, Systems
Processing Robustly Natural Language The Chaos Experience User s Survival Guide Roberto Basili Daniele Pighin Fabio Massimo Zanzotto University of Rome Tor Vergata, Department of Computer Science, Systems
Parser Tools: lex and yacc-style Parsing
 Parser Tools: lex and yacc-style Parsing Version 5.0 Scott Owens June 6, 2010 This documentation assumes familiarity with lex and yacc style lexer and parser generators. 1 Contents 1 Lexers 3 1.1 Creating
Parser Tools: lex and yacc-style Parsing Version 5.0 Scott Owens June 6, 2010 This documentation assumes familiarity with lex and yacc style lexer and parser generators. 1 Contents 1 Lexers 3 1.1 Creating
Conceptual and Logical Design
 Conceptual and Logical Design Lecture 3 (Part 1) Akhtar Ali Building Conceptual Data Model To build a conceptual data model of the data requirements of the enterprise. Model comprises entity types, relationship
Conceptual and Logical Design Lecture 3 (Part 1) Akhtar Ali Building Conceptual Data Model To build a conceptual data model of the data requirements of the enterprise. Model comprises entity types, relationship
The uniform treatment of constraints, coherency and completeness in a Lexical Functional Grammar compiler
 The uniform treatment of constraints, coherency and completeness in a Lexical Functional Grammar compiler Peter Hancox School of Computer Science University of Birmingham Lexical Functional Grammar (LFG)
The uniform treatment of constraints, coherency and completeness in a Lexical Functional Grammar compiler Peter Hancox School of Computer Science University of Birmingham Lexical Functional Grammar (LFG)
Just Write: All Year Long - Grade 1
 i Just Write: All Year Long (1 st Grade) Kathryn Robinson Real-World Writing that students understand & love Where Writing Counts The student pages in this publication are designed to be used with appropriate
i Just Write: All Year Long (1 st Grade) Kathryn Robinson Real-World Writing that students understand & love Where Writing Counts The student pages in this publication are designed to be used with appropriate
Grammar Development with LFG and XLE. Miriam Butt University of Konstanz
 Grammar Development with LFG and XLE Miriam Butt University of Konstanz Last Time Verbal Complements: COMP and XCOMP - Finite Complements - Subject vs. Object Control in XCOMPs - Control Equations in lexical
Grammar Development with LFG and XLE Miriam Butt University of Konstanz Last Time Verbal Complements: COMP and XCOMP - Finite Complements - Subject vs. Object Control in XCOMPs - Control Equations in lexical
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...