CUDA. Sathish Vadhiyar High Performance Computing
|
|
|
- Derrick Williamson
- 5 years ago
- Views:
Transcription
1 CUDA Sathish Vadhiyar High Performance Computing
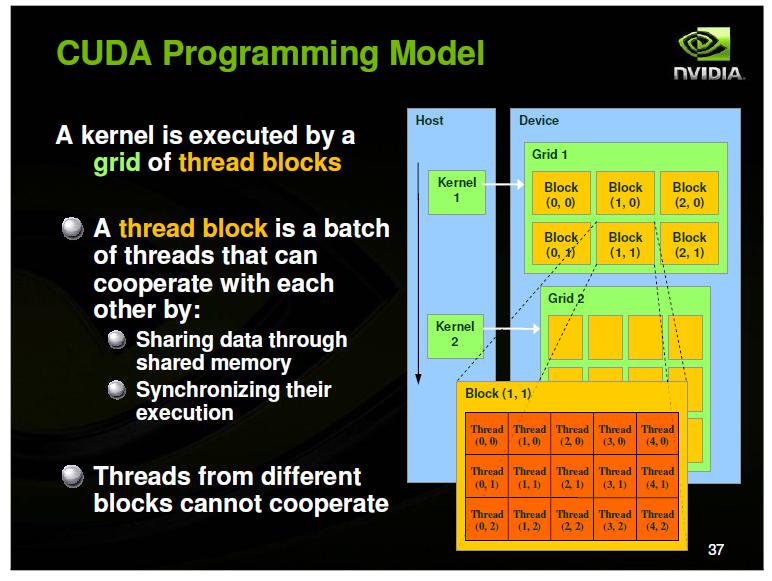
2 Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single block assigned to a single SM. Multiple blocks can be assigned to a SM. Max thread blocks executed concurrently per SM = 16
3 Hierarchical Parallelism Block consists of elements Elements computed by threads Max threads per thread block = 1024 A thread executes on a GPU core
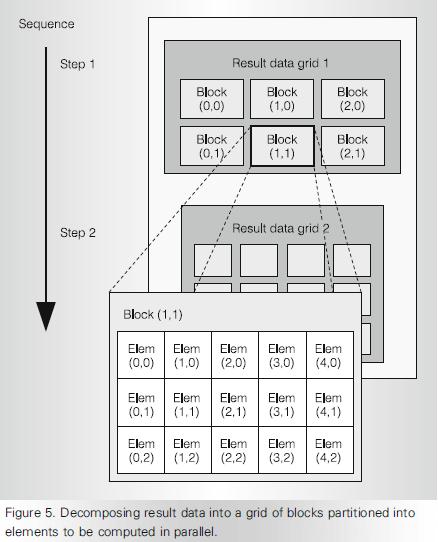
4 Hierarchical Parallelism
5 Thread Blocks Thread block an array of concurrent threads that execute the same program and can cooperate to compute the result Has shape and dimensions (1d, 2d or 3d) for threads A thread ID has corresponding 1,2 or 3d indices Threads of a thread block share memory
6

7
8
9 CUDA Programming Language Programming language for threaded parallelism for GPUs Minimal extension of C A serial program that calls parallel kernels Serial code executes on CPU Parallel kernels executed across a set of parallel threads on the GPU Programmer organizes threads into a hierarchy of thread blocks and grids

10
11 CUDA C Built-in variables: threadidx.{x,y,z} thread ID within a block blockidx.{x,y,z} block ID within a grid blockdim.{x,y,z} number of threads within a block griddim.{x,y,z} number of blocks within a grid kernel<<<nblocks,nthreads>>>(args) Invokes a parallel kernel function on a grid of nblocks where each block instantiates nthreads concurrent threads

12 Example: Summing Up kernel function grid of kernels

13
14 General CUDA Steps 1. Copy data from CPU to GPU 2. Compute on GPU 3. Copy data back from GPU to CPU By default, execution on host doesn t wait for kernel to finish General rules: Minimize data transfer between CPU & GPU Maximize number of threads on GPU
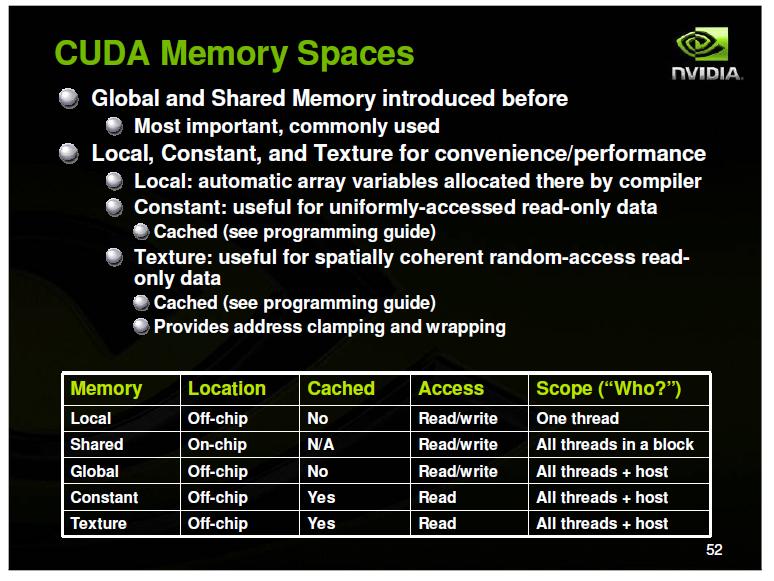
15 CUDA Elements cudamalloc for allocating memory in device cudamemcopy for copying data to allocated memory from host to device, and from device to host cudafree freeing allocated memory void syncthreads () synchronizing all threads in a block like barrier
16 EXAMPLE 1: MATRIX VECTOR MULTIPLICATION
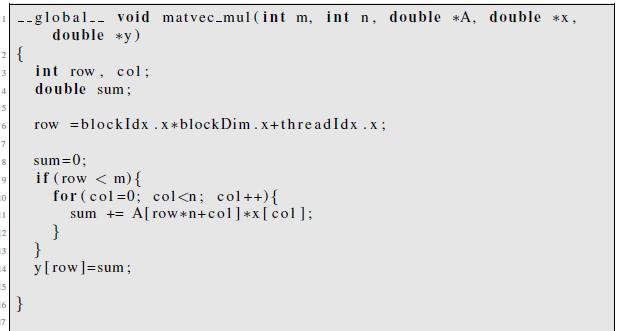
17 Kernel


18 Host Program

19 Host Program
20 EXAMPLE 1, VERSION 2: ACCESS FROM SHARED MEMORY

21
22 EXAMPLE 2: MATRIX MULTIPLICATION

23

24 Example 1: Matrix Multiplication
25 Example 1

26 Example 1
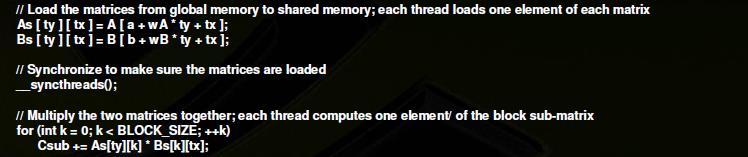
27 Example 1

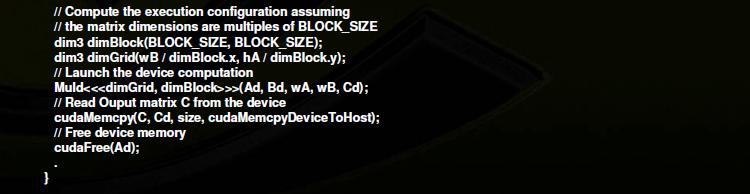
28 Example 1
29 EXAMPLE 2: REDUCTION
30 Example: Reduction Tree based approach used within each thread block In this case, partial results need to be communicated across thread blocks Hence, global synchronization needed across thread blocks
31 Reduction But CUDA does not have global synchronization expensive to build in hardware for large number of GPU cores Solution Decompose into multiple kernels Kernel launch serves as a global synchronization point
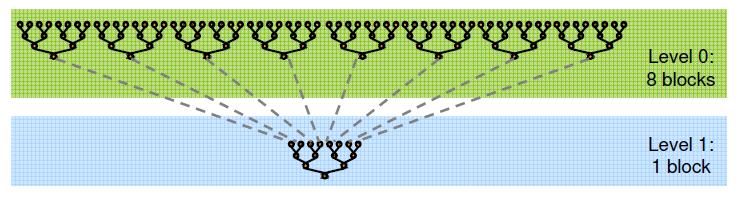
32 Illustration
33 Host Code int main(){ int* h_idata, h_odata; /* host data*/ Int *d_idata, d_odata; /* device data*/ /* copying inputs to device memory */ cudamemcpy(d_idata, h_idata, bytes, cudamemcpyhosttodevice) ; cudamemcpy(d_odata, h_idata, numblocks*sizeof(int), cudamemcpyhosttodevice) ; int numthreadsperblock = (n < maxthreadsperblock)? n : maxthreadsperblock; int numblocks = n / numthreadsperblock; dim3 dimblock(numthreads, 1, 1); dim3 dimgrid(numblocks, 1, 1); reduce<<< dimgrid, dimblock >>>(d_idata, d_odata);
34 Host Code int s=numblocks; while(s > 1) { } numthreadsperblock = (s< maxthreadsperblock)? s : maxthreadsperblock; numblocks = s / numthreadsperblock; dimblock(numthreads, 1, 1); dimgrid(numblocks, 1, 1); reduce<<< dimgrid, dimblock, smemsize >>>(d_idata, d_odata); s = s / numthreadsperblock; }
35 Device Code global void reduce(int *g_idata, int *g_odata) { extern shared int sdata[]; // load shared mem unsigned int tid = threadidx.x; unsigned int i = blockidx.x*blockdim.x + threadidx.x; sdata[tid] = g_idata[i]; syncthreads(); // do reduction in shared mem for(unsigned int s=1; s < blockdim.x; s *= 2) { } if ((tid % (2*s)) == 0) sdata[tid] += sdata[tid + s]; syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockidx.x] = sdata[0];
36 For more information CUDA SDK code samples NVIDIA - les.html
37 BACKUP
38 EXAMPLE 3: SCAN
39 Example: Scan or Parallel-prefix sum Using binary tree An upward reduction phase (reduce phase or up-sweep phase) Traversing tree from leaves to root forming partial sums at internal nodes Down-sweep phase Traversing from root to leaves using partial sums computed in reduction phase
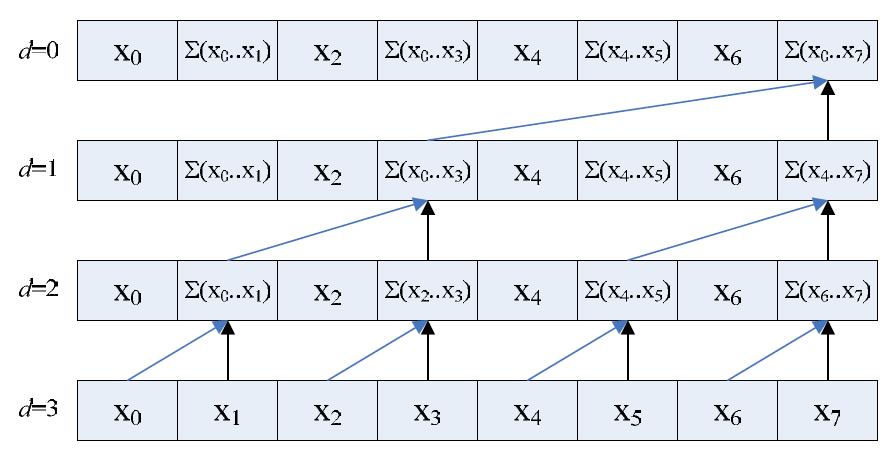
40 Up Sweep

41 Down Sweep
42 Host Code int main(){ const unsigned int num_threads = num_elements / 2; /* cudamalloc d_idata and d_odata */ cudamemcpy( d_idata, h_data, mem_size, cudamemcpyhosttodevice) ); dim3 grid(256, 1, 1); dim3 threads(num_threads, 1, 1); scan<<< grid, threads>>> (d_odata, d_idata); cudamemcpy( h_data, d_odata[i], sizeof(float) * num_elements, cudamemcpydevicetohost /* cudafree d_idata and d_odata */ }
43 Device Code global void scan_workefficient(float *g_odata, float *g_idata, int n) { // Dynamically allocated shared memory for scan kernels extern shared float temp[]; int thid = threadidx.x; int offset = 1; // Cache the computational window in shared memory temp[2*thid] = g_idata[2*thid]; temp[2*thid+1] = g_idata[2*thid+1]; // build the sum in place up the tree for (int d = n>>1; d > 0; d >>= 1) { syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; } temp[bi] += temp[ai]; } offset *= 2;
44 Device Code // scan back down the tree // clear the last element if (thid == 0) temp[n - 1] = 0; // traverse down the tree building the scan in place for (int d = 1; d < n; d *= 2) { offset >>= 1; syncthreads(); if (thid < d) { int ai = offset*(2*thid+1)-1; int bi = offset*(2*thid+2)-1; } } float t = temp[ai]; temp[ai] = temp[bi]; temp[bi] += t; syncthreads(); } // write results to global memory g_odata[2*thid] = temp[2*thid]; g_odata[2*thid+1] = temp[2*thid+1];
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
CUDA Parallel Prefix Sum (1A) Young W. Lim 4/5/14
 Young W. Lim 4/5/14") Copyright (c) 213. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software
Copyright (c) 213. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
ECE 498AL. Lecture 12: Application Lessons. When the tires hit the road
 ECE 498AL Lecture 12: Application Lessons When the tires hit the road 1 Objective Putting the CUDA performance knowledge to work Plausible strategies may or may not lead to performance enhancement Different
ECE 498AL Lecture 12: Application Lessons When the tires hit the road 1 Objective Putting the CUDA performance knowledge to work Plausible strategies may or may not lead to performance enhancement Different
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
ECE/ME/EMA/CS 759 High Performance Computing for Engineering Applications
 ECE/ME/EMA/CS 759 High Performance Computing for Engineering Applications CUDA Prefix Scan Shared Memory Issues CUDA Reduction October 23, 2015 Dan Negrut, 2015 ECE/ME/EMA/CS 759 UW-Madison Quote of the
ECE/ME/EMA/CS 759 High Performance Computing for Engineering Applications CUDA Prefix Scan Shared Memory Issues CUDA Reduction October 23, 2015 Dan Negrut, 2015 ECE/ME/EMA/CS 759 UW-Madison Quote of the
 π = 4 N in_circle N total ... // includes # define N 1000000 float uniform_rand(unsigned* seed, float lower, float upper) {... int main () { int num_in_circ = 0; float x, y, dist; #pragma omp parallel
π = 4 N in_circle N total ... // includes # define N 1000000 float uniform_rand(unsigned* seed, float lower, float upper) {... int main () { int num_in_circ = 0; float x, y, dist; #pragma omp parallel
Real-time Graphics 9. GPGPU
 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Optimizing Parallel Reduction in CUDA
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
Parallel Prefix Sum (Scan) with CUDA. Mark Harris
 with CUDA. Mark Harris") Parallel Prefix Sum (Scan) with CUDA Mark Harris mharris@nvidia.com March 2009 Document Change History Version Date Responsible Reason for Change February 14, 2007 Mark Harris Initial release March 25,
Parallel Prefix Sum (Scan) with CUDA Mark Harris mharris@nvidia.com March 2009 Document Change History Version Date Responsible Reason for Change February 14, 2007 Mark Harris Initial release March 25,
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CS671 Parallel Programming in the Many-Core Era
 CS671 Parallel Programming in the Many-Core Era Lecture 3: GPU Programming - Reduce, Scan & Sort Zheng Zhang Rutgers University Review: Programming with CUDA An Example in C Add vector A and vector B to
CS671 Parallel Programming in the Many-Core Era Lecture 3: GPU Programming - Reduce, Scan & Sort Zheng Zhang Rutgers University Review: Programming with CUDA An Example in C Add vector A and vector B to
GPU programming: CUDA. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
PPAR: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique PPAR
 PPAR: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr http://www.irisa.fr/alf/collange/ PPAR - 2018 This lecture: CUDA programming We have seen some GPU architecture
PPAR: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr http://www.irisa.fr/alf/collange/ PPAR - 2018 This lecture: CUDA programming We have seen some GPU architecture
CUDA Programming. Aiichiro Nakano
 CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Breadth-first Search in CUDA
 Assignment 3, Problem 3, Practical Parallel Computing Course Breadth-first Search in CUDA Matthias Springer Tokyo Institute of Technology matthias.springer@acm.org Abstract This work presents a number
Assignment 3, Problem 3, Practical Parallel Computing Course Breadth-first Search in CUDA Matthias Springer Tokyo Institute of Technology matthias.springer@acm.org Abstract This work presents a number
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Plan. CS : High-Performance Computing with CUDA. Matrix Transpose Characteristics (1/2) Plan
 Plan") Plan CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 1 2 Performance Optimization 3 4 Parallel Scan 5 Exercises
Plan CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 1 2 Performance Optimization 3 4 Parallel Scan 5 Exercises
CS : High-Performance Computing with CUDA
 CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 CS4402-9535: High-Performance Computing with CUDA UWO-CS4402-CS9535
CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 CS4402-9535: High-Performance Computing with CUDA UWO-CS4402-CS9535
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
ECE/ME/EMA/CS 759 High Performance Computing for Engineering Applications
 ECE/ME/EMA/CS 759 High Performance Computing for Engineering Applications CUDA Optimization Issues Case study: parallel prefix scan w/ CUDA October 21, 2015 Dan Negrut, 2015 ECE/ME/EMA/CS 759 UW-Madison
ECE/ME/EMA/CS 759 High Performance Computing for Engineering Applications CUDA Optimization Issues Case study: parallel prefix scan w/ CUDA October 21, 2015 Dan Negrut, 2015 ECE/ME/EMA/CS 759 UW-Madison
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS 314 Principles of Programming Languages
 CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CS 179: GPU Computing. Lecture 2: The Basics
 CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
CUDA. More on threads, shared memory, synchronization. cuprintf
 CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CUDA Parallel Programming Model. Scalable Parallel Programming with CUDA
 CUDA Parallel Programming Model Scalable Parallel Programming with CUDA Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of
CUDA Parallel Programming Model Scalable Parallel Programming with CUDA Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of
CUDA Parallel Programming Model Michael Garland
 CUDA Parallel Programming Model Michael Garland NVIDIA Research Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of a parallel
CUDA Parallel Programming Model Michael Garland NVIDIA Research Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of a parallel
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Blocks, Grids, and Shared Memory
 Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
Introduction to CUDA C
 Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Advanced CUDA Optimizations
 Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Card Sizes. Tesla K40: 2880 processors; 12 GB memory
 Card Sizes Tesla K40: 2880 processors; 12 GB memory Data bigger than grid Maximum grid sizes Compute capability 1.0, 1D and 2D grids supported Compute capability 2, 3, 3D grids too. Grid sizes: 65,535
Card Sizes Tesla K40: 2880 processors; 12 GB memory Data bigger than grid Maximum grid sizes Compute capability 1.0, 1D and 2D grids supported Compute capability 2, 3, 3D grids too. Grid sizes: 65,535
CUDA Technical Training
 CUDA Technical Training Volume II: CUDA Case Studies Prepared and Provided by NVIDIA Q2 2008 Table of Contents Section Slide Computational Finance in CUDA...1 Black-Scholes pricing for European options...3
CUDA Technical Training Volume II: CUDA Case Studies Prepared and Provided by NVIDIA Q2 2008 Table of Contents Section Slide Computational Finance in CUDA...1 Black-Scholes pricing for European options...3
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
Class. Windows and CUDA : Shu Guo. Program from last time: Constant memory
 Class Windows and CUDA : Shu Guo Program from last time: Constant memory Windows on CUDA Reference: NVIDIA CUDA Getting Started Guide for Microsoft Windows Whiting School has Visual Studio Cuda 5.5 Installer
Class Windows and CUDA : Shu Guo Program from last time: Constant memory Windows on CUDA Reference: NVIDIA CUDA Getting Started Guide for Microsoft Windows Whiting School has Visual Studio Cuda 5.5 Installer
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
CS377P Programming for Performance GPU Programming - I
 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Introduction to CUDA C
 NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
NVIDIA CUDA. Fermi Compatibility Guide for CUDA Applications. Version 1.1
 NVIDIA CUDA Fermi Compatibility Guide for CUDA Applications Version 1.1 4/19/2010 Table of Contents Software Requirements... 1 What Is This Document?... 1 1.1 Application Compatibility on Fermi... 1 1.2
NVIDIA CUDA Fermi Compatibility Guide for CUDA Applications Version 1.1 4/19/2010 Table of Contents Software Requirements... 1 What Is This Document?... 1 1.1 Application Compatibility on Fermi... 1 1.2
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Zero-copy. Table of Contents. Multi-GPU Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Zero-copy. Multigpu.
 Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
Massively Parallel Algorithms
 Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Evolving a CUDA Kernel from an nvidia Template
 Evolving a CUDA Kernel from an nvidia Template W. B. Langdon CREST lab, Department of Computer Science 16a.7.2010 Introduction Using genetic programming to create C source code How? Why? Proof of concept:
Evolving a CUDA Kernel from an nvidia Template W. B. Langdon CREST lab, Department of Computer Science 16a.7.2010 Introduction Using genetic programming to create C source code How? Why? Proof of concept:
Shared Memory and Synchronizations
 and Synchronizations Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Technology SM can be accessed by all threads within a block (but not across blocks) Threads within a block can
and Synchronizations Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Technology SM can be accessed by all threads within a block (but not across blocks) Threads within a block can
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Evolving a CUDA Kernel from an nvidia Template
 Evolving a CUDA Kernel from an nvidia Template W. B. Langdon CREST lab, Department of Computer Science 11.5.2011 Introduction Using genetic programming to create C source code How? Why? Proof of concept:
Evolving a CUDA Kernel from an nvidia Template W. B. Langdon CREST lab, Department of Computer Science 11.5.2011 Introduction Using genetic programming to create C source code How? Why? Proof of concept:
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
Introduction to GPU Programming
 Introduction to GPU Programming Volodymyr (Vlad) Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) Part III CUDA C and CUDA API Hands-on:
Introduction to GPU Programming Volodymyr (Vlad) Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) Part III CUDA C and CUDA API Hands-on:
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
GPU Programming. Parallel Patterns. Miaoqing Huang University of Arkansas 1 / 102
 1 / 102 GPU Programming Parallel Patterns Miaoqing Huang University of Arkansas 2 / 102 Outline Introduction Reduction All-Prefix-Sums Applications Avoiding Bank Conflicts Segmented Scan Sorting 3 / 102
1 / 102 GPU Programming Parallel Patterns Miaoqing Huang University of Arkansas 2 / 102 Outline Introduction Reduction All-Prefix-Sums Applications Avoiding Bank Conflicts Segmented Scan Sorting 3 / 102
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Zero Copy Memory and Multiple GPUs
 Zero Copy Memory and Multiple GPUs Goals Zero Copy Memory Pinned and mapped memory on the host can be read and written to from the GPU program (if the device permits this) This may result in performance
Zero Copy Memory and Multiple GPUs Goals Zero Copy Memory Pinned and mapped memory on the host can be read and written to from the GPU program (if the device permits this) This may result in performance
CS/CoE 1541 Final exam (Fall 2017). This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4
. This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4") CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Speed Up Your Codes Using GPU
 Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
Computation to Core Mapping Lessons learned from a simple application
 Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
Lessons learned from a simple application
 Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
CUDA Basics. July 6, 2016
 Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching