CS 475: Parallel Programming Introduction
|
|
|
- Corey Stanley
- 6 years ago
- Views:
Transcription
1 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014
2 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus. n Instructor and GTA. n The rules of the game. Grading, Tests. Progress, the heart of the course: time table. Assignments, details of Labs, Discussions and PAs. Checkin: PAs make and compile are checked
3 Why Parallel Programming n Need for speed Many applications require orders of magnitude more compute power than we have right now. Speed came for a long time from technology improvements, mainly increased clock speed and chip density. The technology improvements have slowed down, and the only way to get more speed is to exploit parallelism. All new computers are now parallel computers.
4 Technology: Moore s Law n Empirical observation (1965) by Gordon Moore: n The chip density: number of transistors that can be inexpensively placed on an integrated circuit, is increasing exponentially, doubling approximately every two years. n en.wikipedia.org/wiki/moore's_law n This has held true until now and is expected to hold until at least 2015 (news.cnet.com/new-life-for- Moores-Law/ _ html).

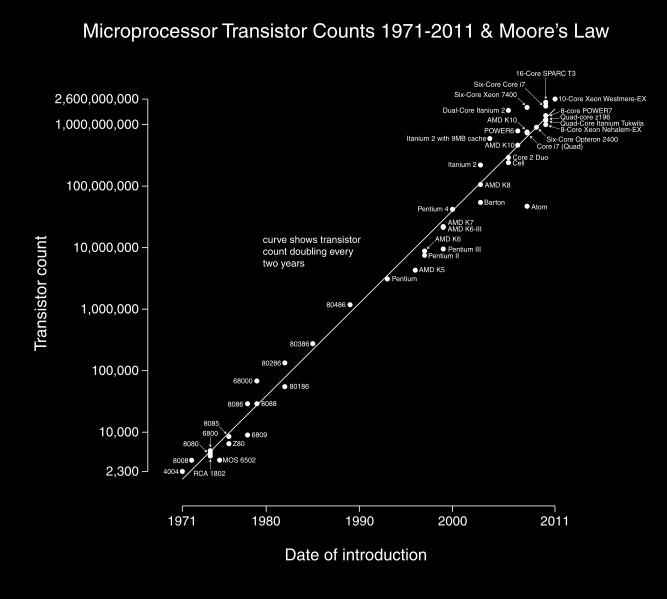
5 source: Wikipedia
6 Corollary of exponential growth n When two quantities grow exponentially, but at different rates, their ratio also grows exponentially. " y 1 = a x, and y 2 = b x for a b 1, therefore a % $ ' # b & n 1.1 n O(2 n ) or 2 n grows a lot faster than (1.1) n n Consequence for computer architecture: growth rate for e.g. memory is not as high as for processors, therefore, memory gets slower and slower (in terms of clock cycles) as compared to processors. This gives rise to so called gaps or walls x = r x, r 1
7 Gaps or walls of Moore s Law n Memory gap/wall: Memory bandwidth and latency improve much slower than processor speeds (since mid 80s, this was addressed by ever increasing on-chip caches). n (Brick) Power Wall Higher frequency means more power means more heat. Microprocessor chips are getting exceedingly hot. Consequence: We can no longer increase the clock frequency of our processors.

8 source: The Free Lunch Is Over Herb Sutter Dr. Dobbs, 2005
9 Enter Parallel Computing n The goal is to deliver performance. The only solution to the power wall is to have multiple processor cores on a chip, because we can still increase the chip density. n Nowadays, there are no more processors with one core. The processor is the new transistor. n 2005 prediction: Number of cores will continue to grow at an exponential rate (at least until 2015), has not happened as much as we thought it would. We are still in the ~16 cores / micro-processor range.
10 Implicit Parallel Programming n Let the compiler / runtime system detect parallelism, do task and data allocation, and scheduling. n This has been a holy grail of compiler and parallel computing research for a long time and, after >40 years, still requires research on automatic parallelization, languages, OS, fault tolerance, etc. n We (still) don t have a general purpose high performance implicit parallel programming language that compiles to a general purpose parallel machine.
11 Explicit Parallel Programming Let the programmer express parallelism, task and data partitioning, allocation, synchronization, and scheduling, using programming languages extended with explicit parallel programming constructs. n This makes the programming task harder, but a lot of fun and a large source of income n very large actually (VLSI = very large source of income J)
12 Explicit parallel programming n Explicit parallel programming Multi-threading: OpenMP Data parallel (multi-threaded)programming: CUDA Message Passing: MPI n Explicit Parallelism complicates programming Creation, allocation, scheduling of processes Data partitioning Synchronization ( semaphores, locks, messages )
13 Computer Architectures n Sequential: John von Neumann Stored Program, single instruction stream, single data stream n Parallel: Michael Flynn SIMD:Single instruction multiple data n data parallel MIMD: Multiple instruction multiple data
14 SIMD n One control unit n Many processing elements All executing the same instruction Local memories Conditional execution n Where ocean perform ocean step n Where land perform land step n Gives rise to idle processors (optimized in GPUs) n PE interconnection Usually a 2D mesh
15 SIMD machines n Bit level n ILLIAC IV (very early research machine, Illinois) n CM2 (Thinking Machines) n now GPU: Cartesian grid of SMs (Streaming Multiprocessors) n each SM has a collection of Processing Elements n each SM has a shared memory (shared among the PEs) and a register file one global memory
16 MIMD n Multiple Processors Each executing its own code n Distributed memory MIMD Complete PE+Memory connected to network n Cosmic Cube, N-Cube n Extreme: Network of Workstations (our labs) Data centers: racks of processors with high speed bus interconnects n Programming model: Message Passing
17 Shared memory MIMD n Shared memory CPUs or cores, bus, shared memory All our processors are now multi-core Programming model: OpenMP n NUMA: Non Uniform Memory Access Memory Hierarchy (registers, cache, local, global) Potential for better performance, but problem: memory (cache) coherence (resolved by architecture)
18 Speedup n Why do we write parallel programs again? to get speedup: go faster than sequential n What is speedup? T 1 = sequential time to execute a program sometimes called T, or S T p = time to execute the same program with p processors (cores, PEs) S p = T 1 / T p speedup for p processors
19 Ideal Speedup, linear speedup n Ideal speedup: p fold speedup: S p = p Ideal not always possible. WHY? n Certain parts of the computation are inherently sequential n Tasks are data dependent, so not all processors are always busy, and need to synchronize n Remote data needs communication Memory wall PLUS Communication wall n Linear speedup: S p = f p f usually less than 1
20 Efficiency n Speedup is usually neither ideal, nor linear n We express this in terms of efficiency E p : E p = S p / p E p defines the average utilization of p processors Range? n What does E p = 1 signify? n What does E p = f (0<f<1) signify?
21 More realistic speedups n T 1 = 1, T p = σ + (ο+π)/p n S p = 1 / T p = 1 / (σ + (ο+π)/p ) σ is sequential fraction of the program π is parallel fraction of the program σ+π = 1 ο is parallel overhead (does not occur in sequential execution) we assume here that o can be parallelised Draw speedup curves for p=1, 2, 4, 8, 16, 32 σ= ¼, ½ ο= ¼, ½ When p goes to, S p goes to?
22 Plotting speedups T 1 = 1, T p =σ+(ο+π)/p S p = 1/(σ+(ο+π)/p ) p Sp (s:1/4 o:1/4) Sp (s:1/4 o:1/2) Sp (s:1/2 o:1/4) Sp (s:1/2 o:1/2) " 3.5" 3" 2.5" Speedup&&Sp&&& 2" 1.5" 1" 0.5" Sp"(s:1/4"o:1/4)" Sp"(s:1/4"o:1/2)" Sp"(s:1/2"o:1/4)" Sp"(s:1/2"o:1/2)" 0" 0" 10" 20" 30" 40" Number&of&processors:&p&
23 This class: explicit parallel programming Class Objectives n Study the foundations of parallel programming n Write explicit parallel programs In C plus libraries Using OpenMP (shared memory), CUDA (data parallel), and MPI (message passing) Execute and measure, plot speedups, interpret / try to understand the outcomes (σ, π, ο), document performance
24 Class Format n Hands on: write efficient parallel code. This often starts with writing efficient sequential code. n four versions of a code: naïve sequential, naïve parallel, smart sequential, smart parallel n Lab covers many details, discussions follow up on what s learned in labs. n PAs: Write effective and scalable parallel programs: report and interpret their performance.
25 Parallel Programming steps n Partition: break program in (smallest possible) parallel tasks and partition the data accordingly. n Communicate: decide which tasks need to communicate (exchange data). n Agglomerate: group tasks into larger tasks reducing communication overhead taking LOCALITY into account n High Performance Computing is all about locality
26 Locality A process (running on a processor) needs to have its data as close to it as possible. Processors have non uniform memory access (NUMA): n registers 0 (extra) cycles n cache 1, 2, 3 cycles there are multiple caches on a multicore chip n local memory 50s to 100s of cycles n Process n n global memory, processor-processor interconnect, disk COARSE in OS world: a program in execution FINER GRAIN in HPC world: (a number of) loop iterations, or a function invocation
27 Exercise: summing numbers 10x10 grid of 100 processors. Add up 4000 numbers initially at the corner processor[0,0], processors can only communicate with NEWS neighbors Different cost models: Each communication event may have an arbitrarily large set of numbers (cost independent of volume). n Alternate: Communication cost is proportional to volume Cost: Communication takes 100x the time of adding n Alternate: communication and computation take the same time
28 Outline n scatter : the numbers to processors row or column wise Each processor along the edge gets a stack n Keeps whatever is needed for its row/column n Forwards the rest to the processor to south (or east) Initiates an independent scatter along its row/column n each processor adds its local set of sums n gather : sums are sent back in reverse order of scatter and added up along the way
29 Broadcast / Reduction n One processor has a value, and we want every processor to have a copy of that value. n Grid: Time for a processor to receive the value must be at least equal to its distance (number of hops in the grid graph) from the source. For the opposite corner, this is the perimeter of the grid, ~ 2sqrt(p) hops n Reduction: dual of broadcast First add n/p numbers on each processor Then do the broadcast in reverse and add along the way
30 Analysis n Scatter, add local, communicate back to the corner Intersperse with one addition operation problem size N=4000, machine size P=100, machine topology: square grid, comms cost C=100) Scatter: 18 steps (get data, keep what you need, send the rest onwards) (2(sqrt(P)-1))) Add 40 numbers Reduce the local answers: 18 steps (one send, add 2 numbers) n Is P=100 good for this problem? Which P is optimal, assuming a square grid)?
Name card info (inside)
") CS 475: Parallel Programming Introduction Sanjay Rajopadhye (with updates by Wim Bohm, Cathie Olschanowski) Colorado State University Fall 2016 Name card info (inside) n Name: Sanjay Rajopadhye n Pronunciation
CS 475: Parallel Programming Introduction Sanjay Rajopadhye (with updates by Wim Bohm, Cathie Olschanowski) Colorado State University Fall 2016 Name card info (inside) n Name: Sanjay Rajopadhye n Pronunciation
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Parallel Computing Introduction
 Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
Parallel Computing Introduction Bedřich Beneš, Ph.D. Associate Professor Department of Computer Graphics Purdue University von Neumann computer architecture CPU Hard disk Network Bus Memory GPU I/O devices
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
BlueGene/L (No. 4 in the Latest Top500 List)
") BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
Top500 Supercomputer list
 Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
High Performance Computing
 The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
The Need for Parallelism High Performance Computing David McCaughan, HPC Analyst SHARCNET, University of Guelph dbm@sharcnet.ca Scientific investigation traditionally takes two forms theoretical empirical
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Introduction. CSCI 4850/5850 High-Performance Computing Spring 2018
 Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
Test on Wednesday! Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs)
") Test on Wednesday! 50 minutes Closed notes, closed computer, closed everything Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs) Study notes and readings posted on course
Test on Wednesday! 50 minutes Closed notes, closed computer, closed everything Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs) Study notes and readings posted on course
Why Multiprocessors?
 Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
27. Parallel Programming I
 771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
Homework # 2 Due: October 6. Programming Multiprocessors: Parallelism, Communication, and Synchronization
 ECE669: Parallel Computer Architecture Fall 2 Handout #2 Homework # 2 Due: October 6 Programming Multiprocessors: Parallelism, Communication, and Synchronization 1 Introduction When developing multiprocessor
ECE669: Parallel Computer Architecture Fall 2 Handout #2 Homework # 2 Due: October 6 Programming Multiprocessors: Parallelism, Communication, and Synchronization 1 Introduction When developing multiprocessor
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Multi-core Programming - Introduction
 Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Workloads Programmierung Paralleler und Verteilter Systeme (PPV)
") Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow.
 Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
CS 31: Intro to Systems Threading & Parallel Applications. Kevin Webb Swarthmore College November 27, 2018
 CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
Parallel Computing Concepts. CSInParallel Project
 Parallel Computing Concepts CSInParallel Project July 26, 2012 CONTENTS 1 Introduction 1 1.1 Motivation................................................ 1 1.2 Some pairs of terms...........................................
Parallel Computing Concepts CSInParallel Project July 26, 2012 CONTENTS 1 Introduction 1 1.1 Motivation................................................ 1 1.2 Some pairs of terms...........................................
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Chapter 11. Introduction to Multiprocessors
 Chapter 11 Introduction to Multiprocessors 11.1 Introduction A multiple processor system consists of two or more processors that are connected in a manner that allows them to share the simultaneous (parallel)
Chapter 11 Introduction to Multiprocessors 11.1 Introduction A multiple processor system consists of two or more processors that are connected in a manner that allows them to share the simultaneous (parallel)
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Chapter 5: Thread-Level Parallelism Part 1
 Chapter 5: Thread-Level Parallelism Part 1 Introduction What is a parallel or multiprocessor system? Why parallel architecture? Performance potential Flynn classification Communication models Architectures
Chapter 5: Thread-Level Parallelism Part 1 Introduction What is a parallel or multiprocessor system? Why parallel architecture? Performance potential Flynn classification Communication models Architectures
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
1. Define algorithm complexity 2. What is called out of order in detail? 3. Define Hardware prefetching. 4. Define software prefetching. 5. Define wor
 CS6801-MULTICORE ARCHECTURES AND PROGRAMMING UN I 1. Difference between Symmetric Memory Architecture and Distributed Memory Architecture. 2. What is Vector Instruction? 3. What are the factor to increasing
CS6801-MULTICORE ARCHECTURES AND PROGRAMMING UN I 1. Difference between Symmetric Memory Architecture and Distributed Memory Architecture. 2. What is Vector Instruction? 3. What are the factor to increasing
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Chapter 1: Introduction to Parallel Computing
 Parallel and Distributed Computing Chapter 1: Introduction to Parallel Computing Jun Zhang Laboratory for High Performance Computing & Computer Simulation Department of Computer Science University of Kentucky
Parallel and Distributed Computing Chapter 1: Introduction to Parallel Computing Jun Zhang Laboratory for High Performance Computing & Computer Simulation Department of Computer Science University of Kentucky
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS
 MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS INSTRUCTOR: Dr. MUHAMMAD SHAABAN PRESENTED BY: MOHIT SATHAWANE AKSHAY YEMBARWAR WHAT IS MULTICORE SYSTEMS? Multi-core processor architecture means placing
MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS INSTRUCTOR: Dr. MUHAMMAD SHAABAN PRESENTED BY: MOHIT SATHAWANE AKSHAY YEMBARWAR WHAT IS MULTICORE SYSTEMS? Multi-core processor architecture means placing
High Performance Computing in C and C++
 High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University Announcement No change in lecture schedule: Timetable remains the same: Monday 1 to 2 Glyndwr C Friday
High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University Announcement No change in lecture schedule: Timetable remains the same: Monday 1 to 2 Glyndwr C Friday
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
CDA3101 Recitation Section 13
 CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
Introduction to Parallel Computing
 Introduction to Parallel Computing This document consists of two parts. The first part introduces basic concepts and issues that apply generally in discussions of parallel computing. The second part consists
Introduction to Parallel Computing This document consists of two parts. The first part introduces basic concepts and issues that apply generally in discussions of parallel computing. The second part consists
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Overview. Processor organizations Types of parallel machines. Real machines
 Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Advanced Parallel Architecture. Annalisa Massini /2017
 Advanced Parallel Architecture Annalisa Massini - 2016/2017 References Advanced Computer Architecture and Parallel Processing H. El-Rewini, M. Abd-El-Barr, John Wiley and Sons, 2005 Parallel computing
Advanced Parallel Architecture Annalisa Massini - 2016/2017 References Advanced Computer Architecture and Parallel Processing H. El-Rewini, M. Abd-El-Barr, John Wiley and Sons, 2005 Parallel computing
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Chapter 9 Multiprocessors
 ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
ECE200 Computer Organization Chapter 9 Multiprocessors David H. lbonesi and the University of Rochester Henk Corporaal, TU Eindhoven, Netherlands Jari Nurmi, Tampere University of Technology, Finland University
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
What is Parallel Computing?
 What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
Parallel and High Performance Computing CSE 745
 Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Parallel Computing Why & How?
 Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
Parallel Computing Why & How? Xing Cai Simula Research Laboratory Dept. of Informatics, University of Oslo Winter School on Parallel Computing Geilo January 20 25, 2008 Outline 1 Motivation 2 Parallel
10th August Part One: Introduction to Parallel Computing
 Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #4 1/24/2018 Xuehai Qian xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Announcements PA #1
EE/CSCI 451: Parallel and Distributed Computation Lecture #4 1/24/2018 Xuehai Qian xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Announcements PA #1
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Review: Creating a Parallel Program. Programming for Performance
 Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
27. Parallel Programming I
 760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Introduction to parallel computing
 Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
4. Networks. in parallel computers. Advances in Computer Architecture
 4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
BİL 542 Parallel Computing
 BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
AMSC/CMSC 662 Computer Organization and Programming for Scientific Computing Fall 2011 Introduction to Parallel Programming Dianne P.
 AMSC/CMSC 662 Computer Organization and Programming for Scientific Computing Fall 2011 Introduction to Parallel Programming Dianne P. O Leary c 2011 1 Introduction to Parallel Programming 2 Why parallel
AMSC/CMSC 662 Computer Organization and Programming for Scientific Computing Fall 2011 Introduction to Parallel Programming Dianne P. O Leary c 2011 1 Introduction to Parallel Programming 2 Why parallel
CS Computer Architecture
 CS 35101 Computer Architecture Section 600 Dr. Angela Guercio Fall 2010 Computer Systems Organization The CPU (Central Processing Unit) is the brain of the computer. Fetches instructions from main memory.
CS 35101 Computer Architecture Section 600 Dr. Angela Guercio Fall 2010 Computer Systems Organization The CPU (Central Processing Unit) is the brain of the computer. Fetches instructions from main memory.
27. Parallel Programming I
 The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Chapter 1. Introduction: Part I. Jens Saak Scientific Computing II 7/348
 Chapter 1 Introduction: Part I Jens Saak Scientific Computing II 7/348 Why Parallel Computing? 1. Problem size exceeds desktop capabilities. Jens Saak Scientific Computing II 8/348 Why Parallel Computing?
Chapter 1 Introduction: Part I Jens Saak Scientific Computing II 7/348 Why Parallel Computing? 1. Problem size exceeds desktop capabilities. Jens Saak Scientific Computing II 8/348 Why Parallel Computing?
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Outline. Distributed Shared Memory. Shared Memory. ECE574 Cluster Computing. Dichotomy of Parallel Computing Platforms (Continued)
") Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
Cluster Computing Dichotomy of Parallel Computing Platforms (Continued) Lecturer: Dr Yifeng Zhu Class Review Interconnections Crossbar» Example: myrinet Multistage» Example: Omega network Outline Flynn
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Lecture notes for CS Chapter 4 11/27/18
 Chapter 5: Thread-Level arallelism art 1 Introduction What is a parallel or multiprocessor system? Why parallel architecture? erformance potential Flynn classification Communication models Architectures
Chapter 5: Thread-Level arallelism art 1 Introduction What is a parallel or multiprocessor system? Why parallel architecture? erformance potential Flynn classification Communication models Architectures
CS671 Parallel Programming in the Many-Core Era
 CS671 Parallel Programming in the Many-Core Era Lecture 1: Introduction Zheng Zhang Rutgers University CS671 Course Information Instructor information: instructor: zheng zhang website: www.cs.rutgers.edu/~zz124/
CS671 Parallel Programming in the Many-Core Era Lecture 1: Introduction Zheng Zhang Rutgers University CS671 Course Information Instructor information: instructor: zheng zhang website: www.cs.rutgers.edu/~zz124/
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Computer and Hardware Architecture II. Benny Thörnberg Associate Professor in Electronics
 Computer and Hardware Architecture II Benny Thörnberg Associate Professor in Electronics Parallelism Microscopic vs Macroscopic Microscopic parallelism hardware solutions inside system components providing
Computer and Hardware Architecture II Benny Thörnberg Associate Professor in Electronics Parallelism Microscopic vs Macroscopic Microscopic parallelism hardware solutions inside system components providing
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Why do we care about parallel?
 Threads 11/15/16 CS31 teaches you How a computer runs a program. How the hardware performs computations How the compiler translates your code How the operating system connects hardware and software The
Threads 11/15/16 CS31 teaches you How a computer runs a program. How the hardware performs computations How the compiler translates your code How the operating system connects hardware and software The
Master Program (Laurea Magistrale) in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.
 in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.") Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
ECE/CS 250 Computer Architecture. Summer 2016
 ECE/CS 250 Computer Architecture Summer 2016 Multicore Dan Sorin and Tyler Bletsch Duke University Multicore and Multithreaded Processors Why multicore? Thread-level parallelism Multithreaded cores Multiprocessors
ECE/CS 250 Computer Architecture Summer 2016 Multicore Dan Sorin and Tyler Bletsch Duke University Multicore and Multithreaded Processors Why multicore? Thread-level parallelism Multithreaded cores Multiprocessors
Parallel Architectures
 Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
Parallel Architectures CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Parallel Architectures Spring 2018 1 / 36 Outline 1 Parallel Computer Classification Flynn s
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel