Cartoon parallel architectures; CPUs and GPUs
|
|
|
- Corey Ellis
- 6 years ago
- Views:
Transcription
 for a big assist 1")
1 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
11 11
12 12
13 13
14 14
15 ~ socket 14
16 ~ core 14
17 ~ HWMT+SIMD ( SIMT ) 14
18 Intel E5-2687W vs. NVIDIA K20X Sandy Bridge-EP vs. Kepler 14
19 ~ 500 GF/s (single) Intel E5-2687W vs. NVIDIA K20X Sandy Bridge-EP vs. Kepler 14
20 ~ 4 TF/s (single) ~ 500 GF/s (single) Intel E5-2687W vs. NVIDIA K20X Sandy Bridge-EP vs. Kepler 14
21 Intel E5-2687W vs. NVIDIA K20X Sandy Bridge-EP vs. Kepler 15
22 ~ 50 GB/s Intel E5-2687W vs. NVIDIA K20X Sandy Bridge-EP vs. Kepler 15
23 ~ 50 GB/s ~ 250 GB/s Intel E5-2687W vs. NVIDIA K20X Sandy Bridge-EP vs. Kepler 15
24 ~ 50 GB/s ~ 250 GB/s 6 GB/s Intel E5-2687W vs. NVIDIA K20X Sandy Bridge-EP vs. Kepler 15
25 System Comparison Intel Xeon NVIDIA Difference E5-2687W K20X # Cores/SMX Clock frequency (max) SIMD Width Thread processors 3.8 GHz 735 MHz bits 2688 SP DP Performance 8 cores 3.8 GHz MHz 8.12 (single precision) (8 Add + 8 Mul) = 2 (FMA) = Performance 8 cores 3.8 GHz MHz 5.42 (double precision) (4 Add + 4 Mul) = 2 (FMA) = Memory bandwidth 51.2 GB/s 250 GB/s 4.88 TDP 150 W 235 W 1.57
26 17
27 17
28 6 GB/s 17
29 18
30 19
31 20
32 21
33 22
34 23
35 24
36 CUDA is NVIDIA s implementation of this execution model

37 Thread hierarchy Single instruction multiple (SIMT)
38 An example to compare models Naïve: for (i=0; i<n; i++) A[i] += 2; OpenMP: #pragma omp parallel for for (i=0; i<n; i++) A[i] += 2; CUDA, with N s: int i = f(global ID); A[i] += 2;
39 Global IDs blockidx.x Idx.x global ID
40 Global IDs blockidx.x Idx.x A global ID
41 Thread hierarchy Given a 3-D grid of blocks there are (griddim.x*griddim.y*griddim.z) blocks in the grid each block s position is identified by blockidx.x, blockidx.y, and blockidx.z Similarly for a 3-D block blockdim.x, blockdim.y, blockdim.z Idx.x, Idx.y, Idx.z Thread-to-data mapping depends on how the work is divided amongst the s
42 Memory hierarchy variables local memory block shared memory grid global memory constant memory (read-only) texture memory (read-only)
43 CUDA by example Basic CUDA code global void test (int* in, int* out, int N) { int gid = Idx.x + blockdim.x * blockidx.x; out[gid] = in[gid]; }! int main (int argc, char** argv) { int N = ; in tbsize = 256;! int nblocks = N / tbsize;! dim3 grid (nblocks); dim3 block (tbsize);! test <<<grid, block>>> (d_in, d_out, N); cudathreadsynchronize (); }
44 CUDA by example Basic CUDA code int main (int argc, char** argv) { /* allocate memory for host and device */ int* h_in, h_out, d_in, d_out; h_in = (int*) malloc (N * sizeof (int)); h_out = (int*) malloc (N * sizeof (int)); cudamalloc ((void**) &d_in, N * sizeof (int)); cudamalloc ((void**) &d_out, N * sizeof (int));! /* copy data from device to host */ cudamemcpy (d_in, h_in, N * sizeof (int), cudamemcpyhosttodevice);! /* body of the problem here */... /* copy data back to host */ cudamemcpy (h_out, d_out, N * sizeof (int), cudamemcpydevicetohost); allocate memory on device Copy data from CPU to GPU Copy data from GPU to CPU } /* free memory */ free (h_in); free (h_out) cudafree (d_in); cudafree (d_out); free memory
45 CUDA by example What is this code doing? global mysteryfunction (int* in) { int tidx, tidy, gidx, gidy; tidx = Idx.x; tidy = Idx.y; gidx = tidx + blockdim.x * blockidx.x; gidy = tidy + blockdim.y * blockidx.y;! shared buffer[16][16];! buffer[tidx][tidy] = in[gidx + gidy * blockdim.x * griddim.x]; syncs();! if(tidx > 0 && tidy > 0) { int temp = (buffer[tidx][tidy - 1] + (buffer[tidx][tidy + 1] + (buffer[tidx - 1][tidy] + (buffer[tidx + 1][tidy] + (buffer[tidx][tidy]) / 5; } else { /* take care of boundary conditions */ } in[gidx + gidy * blockdim.x * griddim.x] = temp; }
46 CUDA by example What is this code doing? global mysteryfunction (int* in) { int tidx, tidy, gidx, gidy; tidx = Idx.x; tidy = Idx.y; gidx = tidx + blockdim.x * blockidx.x; gidy = tidy + blockdim.y * blockidx.y;! shared buffer[16][16];! buffer[tidx][tidy] = in[gidx + gidy * blockdim.x * griddim.x]; syncs();! if(tidx > 0 && tidy > 0) { int temp = (buffer[tidx][tidy - 1] + (buffer[tidx][tidy + 1] + (buffer[tidx - 1][tidy] + (buffer[tidx + 1][tidy] + (buffer[tidx][tidy]) / 5; } else { /* take care of boundary conditions */ } in[gidx + gidy * blockdim.x * griddim.x] = temp; } shared memory why do we need this?
47 Synchronization Within a block via syncs (); Global synchronization implicit synchronization between kernels only way to synchronize globally is to finish the grid and start another grid
48 Scheduling Each block gets scheduled on a multiprocessor (SMX) there is no guarantee in the order in which they get scheduled blocks run independently to each other Multiple blocks can reside on a single SMX simultaneously (occupancy) the number of blocks is determined by the resource usage and availability (shared memory and registers) Once scheduled, each blocks runs to completion
49 Execution Minimum unit of execution: warp typically 32 s At any given time, multiple warps will be executing could be from the same or different blocks A warp of s could be either executing waiting (for data or their turn) When a warp gets stalled, they could be switched out instantaneously so that another warp can start executing hardware multi-ing
50 Performance Notes Thread Divergence On a branch, s in a warp can diverge execution is serialized s taking one branch executes while others idle Avoid divergence!!! use bitwise operation when possible diverge at granularity of warps (no penalty)
51 Performance Notes Occupancy Occupancy = # resident warps / max # warps # resident warps is determined by per- register and per-block shared memory usage max # warps is specific to the hardware generation More warps means more s with which to hide latency increases the chance of keeping the GPU busy at all times does not necessarily mean better performance
52 Performance Notes Bandwidth Utilization Reading from the DRAM occurs at the granularity of 128 Byte transactions requests are further decomposed to aligned cache lines read-only cache:128 Bytes L2 cache: 32 Bytes Minimize loading redundant cache lines to maximize bandwidth utilization aligned access to memory sequential access pattern
53 Performance Notes Bandwidth Utilization
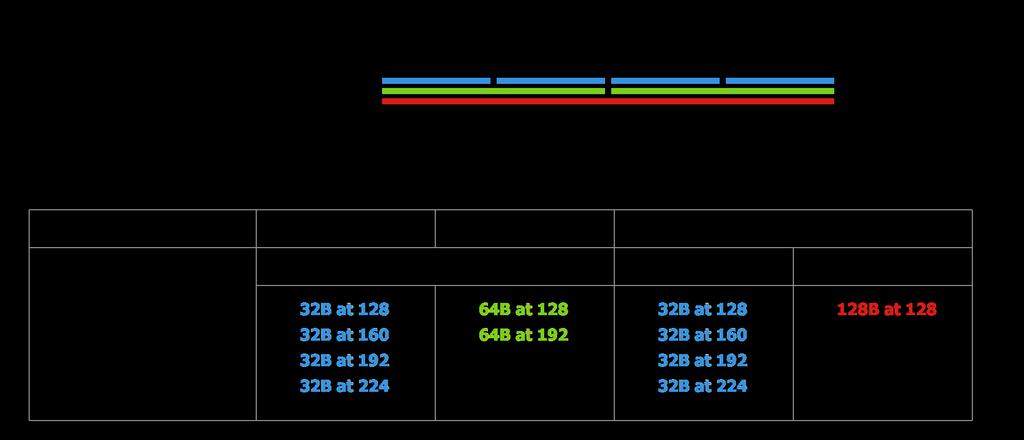

54 Performance Notes Bandwidth Utilization
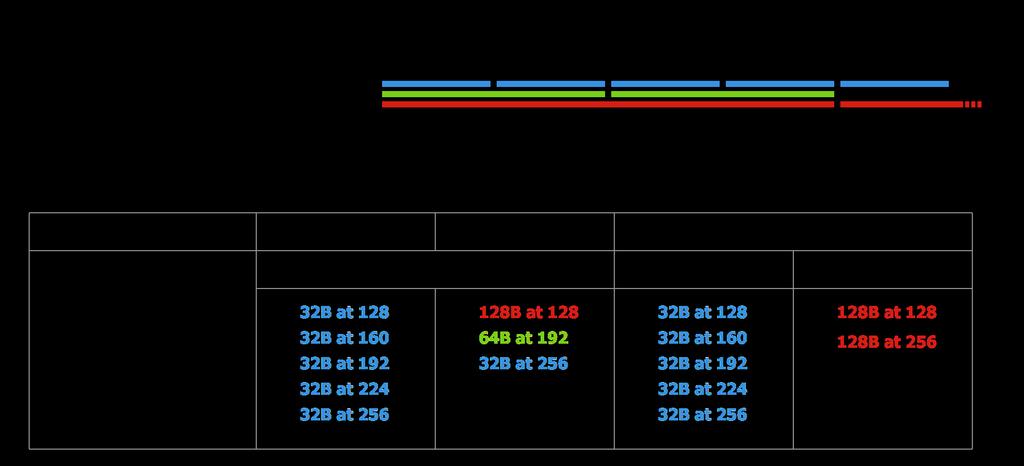

55 Performance Notes Bandwidth Utilization
56 Backup 44
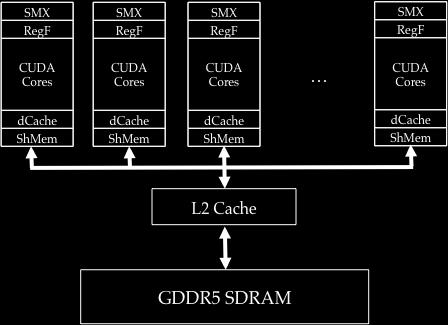
57 GPU Architecture
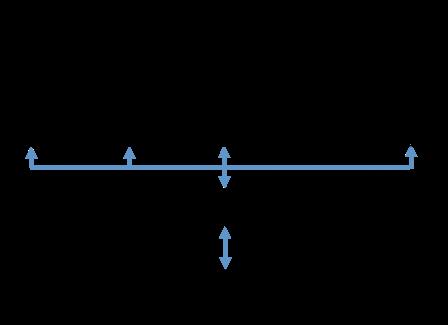
58 Performance Notes Bandwidth Utilization II Little s Law L = λw L = average number of customers in a store λ = arrival rate W = average time spent
59 Performance Notes Bandwidth Utilization II Little s Law L = λw L = average number of customers in a store λ = arrival rate W = average time spent Memory Bandwidth Bandwidth (λ) Latency (W)
60 Performance Notes Bandwidth Utilization II Little s Law L = λw L = average number of customers in a store λ = arrival rate W = average time spent Memory Bandwidth tens of thousands of in-flight requests!!! Bandwidth (λ) Latency (W)
61 In summary Use as many cheap s as possible maximizes occupancy increases the number of memory requests Avoid divergence if unavoidable, diverge at the warp level Use aligned and sequential data access pattern minimize redundant data loads
62 CUDA by example Quicksort Let s now consider quicksort on a GPU Step 1 Partition the initial list how do we partition the list amongst blocks? recall that blocks CANNOT co-operate and blocks can go in ANY order however, we need to have MANY s and blocks in order to see good performance
63 CUDA by example Quicksort block 0 block 1 block 2 block 3
64 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3
65 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3 < pivot (5) >= pivot (5)
66 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3 < pivot >= pivot Do a cumulative sum on < pivot and >= pivot This should be done in shared memory in parallel
67 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3 < pivot >= pivot This tells us how much space and where each block needs to store its values
68 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3 < pivot 2 3 >= pivot 0 1 temporary array start end
69 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3 < pivot 2 3 atomic fetch-and-add (FAA) >= pivot 0 1 temporary array start end
70 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3 < pivot 2 3 atomic fetch-and-add (FAA) >= pivot 0 1 temporary array start end
71 CUDA by example Quicksort thr 0 thr 1 thr 0 thr 1 thr 0 thr 1 thr 0 thr block 0 block 1 block 2 block 3 < pivot 2 3 atomic fetch-and-add (FAA) >= pivot 0 1 temporary array start end
72 CUDA by example Quicksort Phew. That was the first part. This is repeated until there are enough independent partitions that can be assigned to blocks In the next part, each block will do something similar minus the FAA When sequences become small enough, you can sort it using an alternative sorting algorithm (e.g., bitonic sort)
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
CS/CoE 1541 Final exam (Fall 2017). This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4
. This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4") CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
Experiences Porting Real Time Signal Processing Pipeline CUDA Kernels from Kepler to Maxwell
 NVIDIA GPU Technology Conference March 20, 2015 San José, California Experiences Porting Real Time Signal Processing Pipeline CUDA Kernels from Kepler to Maxwell Ismayil Güracar Senior Key Expert Siemens
NVIDIA GPU Technology Conference March 20, 2015 San José, California Experiences Porting Real Time Signal Processing Pipeline CUDA Kernels from Kepler to Maxwell Ismayil Güracar Senior Key Expert Siemens
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Programming. Rupesh Nasre.
 GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 Hello World. #include int main() { printf("hello World.\n"); return 0; Compile: nvcc hello.cu Run: a.out GPU
GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 Hello World. #include int main() { printf("hello World.\n"); return 0; Compile: nvcc hello.cu Run: a.out GPU
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
Programming with CUDA, WS09
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
CS377P Programming for Performance GPU Programming - I
 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Overview: Graphics Processing Units
 advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
Multi Agent Navigation on GPU. Avi Bleiweiss
 Multi Agent Navigation on GPU Avi Bleiweiss Reasoning Explicit Implicit Script, storytelling State machine, serial Compute intensive Fits SIMT architecture well Navigation planning Collision avoidance
Multi Agent Navigation on GPU Avi Bleiweiss Reasoning Explicit Implicit Script, storytelling State machine, serial Compute intensive Fits SIMT architecture well Navigation planning Collision avoidance
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Image convolution with CUDA
 Image convolution with CUDA Lecture Alexey Abramov abramov _at_ physik3.gwdg.de Georg-August University, Bernstein Center for Computational Neuroscience, III Physikalisches Institut, Göttingen, Germany
Image convolution with CUDA Lecture Alexey Abramov abramov _at_ physik3.gwdg.de Georg-August University, Bernstein Center for Computational Neuroscience, III Physikalisches Institut, Göttingen, Germany
COSC 462. CUDA Basics: Blocks, Grids, and Threads. Piotr Luszczek. November 1, /10
 COSC 462 CUDA Basics: Blocks, Grids, and Threads Piotr Luszczek November 1, 2017 1/10 Minimal CUDA Code Example global void sum(double x, double y, double *z) { *z = x + y; } int main(void) { double *device_z,
COSC 462 CUDA Basics: Blocks, Grids, and Threads Piotr Luszczek November 1, 2017 1/10 Minimal CUDA Code Example global void sum(double x, double y, double *z) { *z = x + y; } int main(void) { double *device_z,
CS 179: GPU Computing. Lecture 2: The Basics
 CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Review. Lecture 10. Today s Outline. Review. 03b.cu. 03?.cu CUDA (II) Matrix addition CUDA-C API
 Matrix addition CUDA-C API") Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
COSC 462 Parallel Programming
 November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
CUDA. More on threads, shared memory, synchronization. cuprintf
 CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Inter-Block GPU Communication via Fast Barrier Synchronization
 CS 3580 - Advanced Topics in Parallel Computing Inter-Block GPU Communication via Fast Barrier Synchronization Mohammad Hasanzadeh-Mofrad University of Pittsburgh September 12, 2017 1 General Purpose Graphics
CS 3580 - Advanced Topics in Parallel Computing Inter-Block GPU Communication via Fast Barrier Synchronization Mohammad Hasanzadeh-Mofrad University of Pittsburgh September 12, 2017 1 General Purpose Graphics
CSE 591: GPU Programming. Using CUDA in Practice. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Using CUDA in Practice Klaus Mueller Computer Science Department Stony Brook University Code examples from Shane Cook CUDA Programming Related to: score boarding load and store
CSE 591: GPU Programming Using CUDA in Practice Klaus Mueller Computer Science Department Stony Brook University Code examples from Shane Cook CUDA Programming Related to: score boarding load and store
Information Coding / Computer Graphics, ISY, LiTH. CUDA memory! ! Coalescing!! Constant memory!! Texture memory!! Pinned memory 26(86)
") 26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
Don t reinvent the wheel. BLAS LAPACK Intel Math Kernel Library
 Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
GPU Computing Workshop CSU Getting Started. Garland Durham Quantos Analytics
 1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
CE 431 Parallel Computer Architecture Spring Graphics Processor Units (GPU) Architecture
 Architecture") CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
CUDA Kenjiro Taura 1 / 36
 CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CUDA Basics. July 6, 2016
 Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching