Fall 2011 Prof. Hyesoon Kim. Thanks to Prof. Loh & Prof. Prvulovic
|
|
|
- Emery Wright
- 6 years ago
- Views:
Transcription

1 Fall 2011 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic
2 Flynn s Taxonomy of Parallel Machines How many Instruction streams? How many Data streams? SISD: Single I Stream, Single D Stream A uniprocessor SIMD: Single I, Multiple D Streams Each processor works on its own data But all execute the same instrs in lockstep E.g. a vector processor or MMX, CUDA
3 MISD: Multiple I, Single D Stream Not used much Stream processors are closest to MISD MIMD: Multiple I, Multiple D Streams Each processor executes its own instructions and operates on its own data This is your typical off-the-shelf multiprocessor (made using a bunch of normal processors) Includes multi-core processors
4 SISD Single Instruction, Singe Data SIMD Single Instruction, Multiple Data MISD Multiple Instruction, Single Data MIMD Multiple Instruction, Multiple Data

5 Why do we need multiprocessors? Uniprocessor speed keeps improving But there are things that need even more speed Wait for a few years for Moore s law to catch up? Or use multiple processors and do it now? Multiprocessor software problem Most code is sequential (for uniprocessors) MUCH easier to write and debug Correct parallel code very, very difficult to write Efficient and correct is even harder Debugging even more difficult (Heisenbugs) ILP limits reached?
6 Centralized Shared Memory Distributed Memory
7 Also Symmetric Multiprocessors (SMP) Uniform Memory Access (UMA) All memory locations have similar latencies Data sharing through memory reads/writes P1 can write data to a physical address A, P2 can then read physical address A to get that data Problem: Memory Contention All processor share the one memory Memory bandwidth becomes bottleneck Used only for smaller machines Most often 2,4, or 8 processors
8 Two kinds Distributed Shared-Memory (DSM) All processors can address all memory locations Data sharing like in SMP Also called NUMA (non-uniform memory access) Latencies of different memory locations can differ (local access faster than remote access) Message-Passing A processor can directly address only local memory To communicate with other processors, must explicitly send/receive messages Also called multicomputers or clusters Most accesses local, so less memory contention (can scale to well over 1000 processors)
9 A cluster of computers Each with its own processor and memory An interconnect to pass messages between them Producer-Consumer Scenario: P1 produces data D, uses a SEND to send it to P2 The network routes the message to P2 P2 then calls a RECEIVE to get the message Two types of send primitives Synchronous: P1 stops until P2 confirms receipt of message Asynchronous: P1 sends its message and continues Standard libraries for message passing: Most common is MPI Message Passing Interface

10 Master Slave Slave
11 Calculating the sum of array elements #define ASIZE 1024 #define NUMPROC 4 double myarray[asize/numproc]; double mysum=0; for(int i=0;i<asize/numproc;i++) mysum+=myarray[i]; if(mypid=0){ for(int p=1;p<numproc;p++){ int psum; recv(p,psum); mysum+=psum; } printf( Sum: %lf\n,mysum); }else send(0,mysum); Must manually split the array Master processor adds up partial sums and prints the result Slave processors send their partial results to master
12 Pros Simpler and cheaper hardware Explicit communication makes programmers aware of costly (communication) operations Cons Explicit communication is painful to program Requires manual optimization If you want a variable to be local and accessible via LD/ST, you must declare it as such If other processes need to read or write this variable, you must explicitly code the needed sends and receives to do this
13 Metrics for Communication Performance Communication Bandwidth Communication Latency Sender overhead + transfer time + receiver overhead Communication latency hiding Characterizing Applications Communication to Computation Ratio Work done vs. bytes sent over network Example: 146 bytes per 1000 instructions
14
15 Calculating the sum of array elements #define ASIZE 1024 #define NUMPROC 4 shared double array[asize]; shared double allsum=0; shared mutex sumlock; double mysum=0; for(int i=mypid*asize/numproc;i<(mypid+1)*asize/numproc;i++) mysum+=array[i]; lock(sumlock); allsum+=mysum; unlock(sumlock); if(mypid=0) printf( Sum: %lf\n,allsum); Array is shared Each processor sums up its part of the array Each processor adds its partial sums to the final result Master processor prints the result
16 Pros Communication happens automatically More natural way of programming Easier to write correct programs and gradually optimize them No need to manually distribute data (but can help if you do) Cons Needs more hardware support Easy to write correct, but inefficient programs (remote accesses look the same as local ones)
17




18 One approach: add sockets to your MOBO minimal changes to existing CPUs power delivery, heat removal and I/O not too bad since each chip has own set of pins and cooling CPU 0 CPU 1 CPU 2 CPU 3 Pictures found from google images


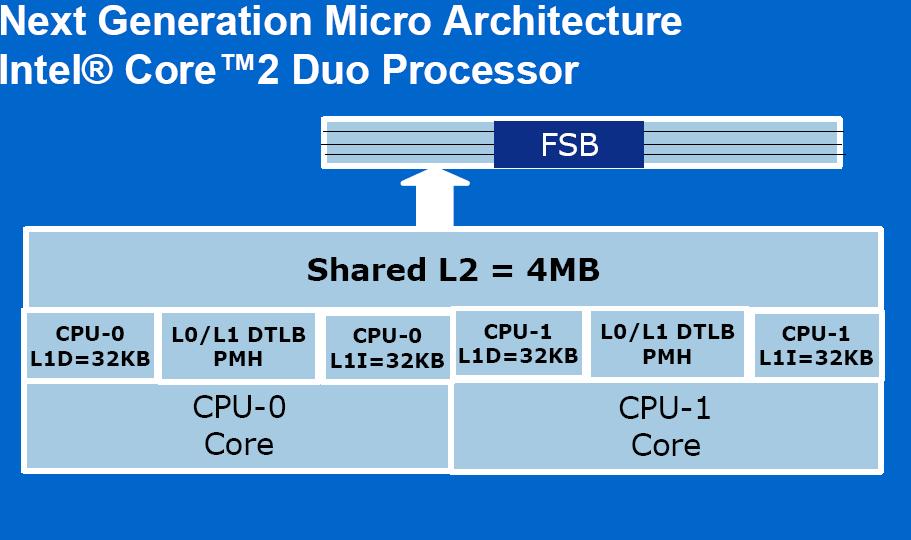
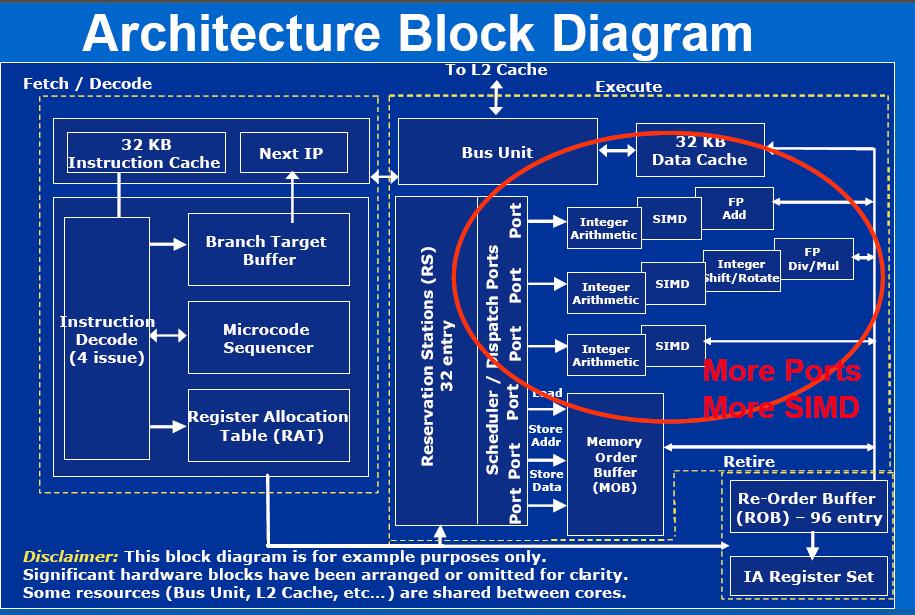
19 Simple SMP on the same chip Intel Smithfield Block Diagram AMD Dual-Core Athlon FX Pictures found from google images
 L3 cache is also")
20 CPU 0 CPU 1 Resources can be shared between CPUs ex. IBM Power 5 L2 cache shared between both CPUs (no need to keep two copies coherent) L3 cache is also shared (only tags are on-chip; data are off-chip)
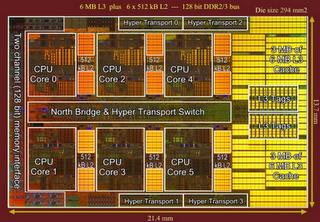

21
22 Cheaper than mobo-based SMP all/most interface logic integrated on to main chip (fewer total chips, single CPU socket, single interface to main memory) less power than mobo-based SMP as well (communication on-die is more power-efficient than chip-to-chip communication) Performance on-chip communication is faster Efficiency potentially better use of hardware resources than trying to make wider/more OOO single-threaded CPU


23 2x CPUs not necessarily equal to 2x performance 2x CPUs à ½ power for each maybe a little better than ½ if resources can be shared Back-of-the-Envelope calculation: 3.8 GHz CPU at 100W Dual-core: 50W per CPU Benefit of SMP: Full power budget per socket! P V 3 : V orig3 /V CMP 3 = 100W/50W à V CMP = 0.8 V orig f V: f CMP = 3.0GHz
24 So what s better? One 3.8 GHz CPU? Or a dual-core running at 3.0 GHz? Depends on workloads If you have one program to run, the 3.8GHz CPU will run it in 79% of the time If you have two programs to run, then: 3.8GHz CPU: 79% for one, or 158% for both Dual 3.0GHz CPU: 100% for both in parallel


25 Dual Core: total power 200W frequency: 2GHz With the same power budget if we have 4 cores, what should be the frequency of each core? Assume that the power is equally distributed P V 3 : V dual3 /V quad 3 = 100W/50W à V quad = 0.8 V dual f V: f quad = 1.6GHz
26 Single thread in superscalar execution: dependences cause most of stalls Idea: when one thread stalled, other can go Different granularities of multithreading Coarse MT: can change thread every few cycles Fine MT: can change thread every cycle Simultaneous Multithreading (SMT) Instrs from different threads even in the same cycle AKA Hyperthreading
27 Uni-Processor: 4-6 wide, lucky if you get 1-2 IPC poor utilization SMP: 2-4 CPUs, but need independent tasks else poor utilization as well SMT: Idea is to use a single large uni-processor as a multi-processor

")


28 Regular CPU SMT (4 threads) CMP 2x HW Cost Approx 1x HW Cost
29 For an N-way (N threads) SMT, we need: Ability to fetch from N threads N sets of architectural registers (including PCs) N rename tables (RATs) N virtual memory spaces Front-end: branch predictor?: no, RAS? :yes But we don t need to replicate the entire OOO execution engine (schedulers, execution units, bypass networks, ROBs, etc.) 29






30 Multiplex the Fetch Logic RS PC 0 PC 1 PC 2 I$ fetch Decode, etc. cycle % N Can do simple round-robin between active threads, or favor some over the others based on how much each is stalling relative to the others 30


31 Thread #1 s R12!= Thread #2 s R12 separate name spaces need to disambiguate Thread 0 Register # RAT 0 PRF Thread 1 Register # RAT 1 31
![No change needed After Renaming Thread 0: Add R1 = R2 + R3 Sub R4 = R1 R5 Xor R3 = R1 ^ R4 Load R2 = 0[R3] Thread 1: Add R1 = R2 + R3 Sub R4 = R1 R5 Xor R3 = R1 ^ R4 Load R2 = 0[R3] Thread 0: Add T12](/docs-images/71/65600505/images/32-3.jpg "= T20 + T8 Sub T19 = T12 T16 Xor T14 = T12 ^ T19 Load T23 = 0[T14] Thread 1: Add T17 = T29 + T3 Sub T5 = T17 T2 Xor T31 = T17 ^ T5 Load T25 = 0[T31] Shared RS Entries Sub T5 = T17 T2 Add T12 = T20 +")
32 No change needed After Renaming Thread 0: Add R1 = R2 + R3 Sub R4 = R1 R5 Xor R3 = R1 ^ R4 Load R2 = 0[R3] Thread 1: Add R1 = R2 + R3 Sub R4 = R1 R5 Xor R3 = R1 ^ R4 Load R2 = 0[R3] Thread 0: Add T12 = T20 + T8 Sub T19 = T12 T16 Xor T14 = T12 ^ T19 Load T23 = 0[T14] Thread 1: Add T17 = T29 + T3 Sub T5 = T17 T2 Xor T31 = T17 ^ T5 Load T25 = 0[T31] Shared RS Entries Sub T5 = T17 T2 Add T12 = T20 + T8 Load T25 = 0[T31] Xor T14 = T12 ^ T19 Load T23 = 0[T14] Sub T19 = T12 T16 Xor T31 = T17 ^ T5 Add T17 = T29 + T3 32
33 Each process has own virtual address space TLB must be thread-aware translate (thread-id,virtual page) à physical page Virtual portion of caches must also be threadaware VIVT cache must now be (virtual addr, thread-id)- indexed, (virtual addr, thread-id)-tagged Similar for VIPT cache No changes needed if using PIPT cache (like L2) 33
34 Register File Management ARF/PRF organization need one ARF per thread Need to maintain interrupts, exceptions, faults on a per-thread basis like OOO needs to appear to outside world that it is in-order, SMT needs to appear as if it is actually N CPUs 34
35 When it works, it fills idle issue slots with work from other threads; throughput improves But sometimes it can cause performance degradation! Time( ) < Time( ) Finish one task, then do the other Do both at same time using SMT 35

36 Cache thrashing I$ D$ Thread 0 just fits in the Level-1 Caches Context switch to Thread 1 I$ D$ Thread 1 also fits nicely in the caches Executes reasonably quickly due to high cache hit rates L2 I$ D$ Caches were just big enough to hold one thread s data, but not two thread s worth Now both threads have significantly higher cache miss rates 36

37 Intel s Nehalemn Each core is 2-way SMT demos/turboboost/demo.htm?iid=tech_tb +demo


38
39 Texas C62xx, IA32 (SSE), AMD K6, CUDA, Xbox.. Early SIMD machines: e.g.) CM-2 (large distributed system) Lack of vector register files and efficient transposition support in the memory system. Lack of irregular indexed memory accesses Modern SIMD machines: SIMD engine is in the same die
40 Source 1 X3 X2 X1 X0 Source 2 Y3 Y2 Y1 Y0 OP OP OP OP Destination X3 OP Y3 X2 OP Y2 X1 OP Y1 X0 OP Y0 for (ii = 0; ii < 4; ii++) x[ii] = y[ii]+z[ii]; SIMD_ADD(X, Y, Z)
41 New data type 128-bit packed single-precision floating-point data type Packed/Scalar singe-precision floating-point instruction 64-bit SIMD integer instruction State management instructions Cacheability control, prefetch, and memory ordering instructions
42 Add new data types Add more complex SIMD instructions Additional vector registers Additional cacheability-control and instruction-ordering instructions.
![for (i = 1; i < 12; i++) x[i] =](/docs-images/71/65600505/images/43-1.jpg "j[i]+1; for (i = 1; i < 12; i=i+4) {")
![x[i] = j[i]+1; x[i+1] = j[i+1]+1;](/docs-images/71/65600505/images/43-2.jpg "x[i+2] = j[i+2]+1; x[i+3] = j[i+3]+1;")
43 for (i = 1; i < 12; i++) x[i] = j[i]+1; for (i = 1; i < 12; i=i+4) { x[i] = j[i]+1; x[i+1] = j[i+1]+1; x[i+2] = j[i+2]+1; x[i+3] = j[i+3]+1; } SSE ADD
44 Which code can be vectorized? Case1: for (i = 0; i < 1024; i++) C[i] = A[i]*B[i]; Case 2: for (i=0;i<1024;i++) a[i] = a[i+k]-1; k=3 Case 3: for (i=0;i<1024;i++) a[i] = a[i-k]-1; k=3
45
46
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 11: Multiprocessors CSC 631: High-Performance Computer Architecture 1 Multiprocessing Flynn s Taxonomy of Parallel Machines How many
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 11: Multiprocessors CSC 631: High-Performance Computer Architecture 1 Multiprocessing Flynn s Taxonomy of Parallel Machines How many
Multiprocessors 1. Outline
 Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
COSC4201. Multiprocessors and Thread Level Parallelism. Prof. Mokhtar Aboelaze York University
 COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
COSC4201 Multiprocessors
 COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Spring 2010 Prof. Hyesoon Kim. Thanks to Prof. Loh & Prof. Prvulovic
 Spring 2010 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic C/C++ program Compiler Assembly Code (binary) Processor 0010101010101011110 Memory MAR MDR INPUT Processing Unit OUTPUT ALU TEMP PC Control
Spring 2010 Prof. Hyesoon Kim Thanks to Prof. Loh & Prof. Prvulovic C/C++ program Compiler Assembly Code (binary) Processor 0010101010101011110 Memory MAR MDR INPUT Processing Unit OUTPUT ALU TEMP PC Control
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
THREAD LEVEL PARALLELISM
 THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Lecture 28 Introduction to Parallel Processing and some Architectural Ramifications. Flynn s Taxonomy. Multiprocessing.
 1 2 Lecture 28 Introduction to arallel rocessing and some Architectural Ramifications 3 4 ultiprocessing Flynn s Taxonomy Flynn s Taxonomy of arallel achines How many Instruction streams? How many Data
1 2 Lecture 28 Introduction to arallel rocessing and some Architectural Ramifications 3 4 ultiprocessing Flynn s Taxonomy Flynn s Taxonomy of arallel achines How many Instruction streams? How many Data
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Introduction to parallel computing
 Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
SMD149 - Operating Systems - Multiprocessing
 SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
Overview. SMD149 - Operating Systems - Multiprocessing. Multiprocessing architecture. Introduction SISD. Flynn s taxonomy
 Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core. Prof. Onur Mutlu Carnegie Mellon University
 18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Parallel Computer Architecture Spring Shared Memory Multiprocessors Memory Coherence
 Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Lecture 24: Virtual Memory, Multiprocessors
 Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
27. Parallel Programming I
 771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
771 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
18-447: Computer Architecture Lecture 30B: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013
 18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Parallelism, Multicore, and Synchronization
 Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
High-Performance Processors Design Choices
 High-Performance Processors Design Choices Ramon Canal PD Fall 2013 1 High-Performance Processors Design Choices 1 Motivation 2 Multiprocessors 3 Multithreading 4 VLIW 2 Motivation Multiprocessors Outline
High-Performance Processors Design Choices Ramon Canal PD Fall 2013 1 High-Performance Processors Design Choices 1 Motivation 2 Multiprocessors 3 Multithreading 4 VLIW 2 Motivation Multiprocessors Outline
Chapter 2 Parallel Computer Architecture
 Chapter 2 Parallel Computer Architecture The possibility for a parallel execution of computations strongly depends on the architecture of the execution platform. This chapter gives an overview of the general
Chapter 2 Parallel Computer Architecture The possibility for a parallel execution of computations strongly depends on the architecture of the execution platform. This chapter gives an overview of the general
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
27. Parallel Programming I
 760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
760 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism, Scheduling
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Chapter 5 Thread-Level Parallelism. Abdullah Muzahid
 Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Chapter 5 Thread-Level Parallelism Abdullah Muzahid 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors is saturating + Modern multiple issue processors are becoming very complex
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
ILP Ends TLP Begins. ILP Limits via an Oracle
 ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Chapter 5. Thread-Level Parallelism
 Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
27. Parallel Programming I
 The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
The Free Lunch 27. Parallel Programming I Moore s Law and the Free Lunch, Hardware Architectures, Parallel Execution, Flynn s Taxonomy, Scalability: Amdahl and Gustafson, Data-parallelism, Task-parallelism,
Lecture 24: Memory, VM, Multiproc
 Lecture 24: Memory, VM, Multiproc Today s topics: Security wrap-up Off-chip Memory Virtual memory Multiprocessors, cache coherence 1 Spectre: Variant 1 x is controlled by attacker Thanks to bpred, x can
Lecture 24: Memory, VM, Multiproc Today s topics: Security wrap-up Off-chip Memory Virtual memory Multiprocessors, cache coherence 1 Spectre: Variant 1 x is controlled by attacker Thanks to bpred, x can
Chapter 1: Perspectives
 Chapter 1: Perspectives Copyright @ 2005-2008 Yan Solihin Copyright notice: No part of this publication may be reproduced, stored in a retrieval system, or transmitted by any means (electronic, mechanical,
Chapter 1: Perspectives Copyright @ 2005-2008 Yan Solihin Copyright notice: No part of this publication may be reproduced, stored in a retrieval system, or transmitted by any means (electronic, mechanical,
High Performance Computing in C and C++
 High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University Announcement No change in lecture schedule: Timetable remains the same: Monday 1 to 2 Glyndwr C Friday
High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University Announcement No change in lecture schedule: Timetable remains the same: Monday 1 to 2 Glyndwr C Friday
Parallel Processing. Computer Architecture. Computer Architecture. Outline. Multiple Processor Organization
 Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Parallel Computer Architectures. Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam
 Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Computer Architecture: Parallel Processing Basics. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
Computer Architecture: Parallel Processing Basics Prof. Onur Mutlu Carnegie Mellon University Readings Required Hill, Jouppi, Sohi, Multiprocessors and Multicomputers, pp. 551-560 in Readings in Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
A Multiprocessor system generally means that more than one instruction stream is being executed in parallel.
 Multiprocessor Systems A Multiprocessor system generally means that more than one instruction stream is being executed in parallel. However, Flynn s SIMD machine classification, also called an array processor,
Multiprocessor Systems A Multiprocessor system generally means that more than one instruction stream is being executed in parallel. However, Flynn s SIMD machine classification, also called an array processor,
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
CDA3101 Recitation Section 13
 CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
ECE 588/688 Advanced Computer Architecture II
 ECE 588/688 Advanced Computer Architecture II Instructor: Alaa Alameldeen alaa@ece.pdx.edu Fall 2009 Portland State University Copyright by Alaa Alameldeen and Haitham Akkary 2009 1 When and Where? When:
ECE 588/688 Advanced Computer Architecture II Instructor: Alaa Alameldeen alaa@ece.pdx.edu Fall 2009 Portland State University Copyright by Alaa Alameldeen and Haitham Akkary 2009 1 When and Where? When:
Moore s Law. Computer architect goal Software developer assumption
 Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer