|
|
|
- Wesley McDonald
- 6 years ago
- Views:
Transcription

1
2

3
4

5
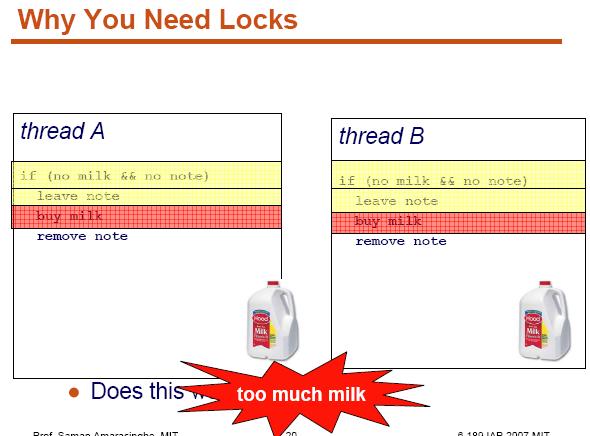
6

7
8 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3. m = e * f 1 and 2 can operate in parallel. 3 depends to 1 and 2. A superscalar processor is a CPU that implements a form of parallelism called instruction-level parallelism within a single processor. It therefore allows faster CPU throughput (the number of instructions that can be executed in a unit of time) than would otherwise be possible at a given clock rate. Source: wiki

9 Pipelining Execution: Single CPU

10 Superscalar 2-issue pipleine
11 Explicit Thread Level Parallelism or Data Level Parallelism Thread: process with own instructions and data thread may be a process part of a parallel program of multiple processes, or it may be an independent program Each thread has all the state (instructions, data, PC, register state, and so on) necessary to allow it to execute Data Level Parallelism: Perform identical operations on data, and lots of data
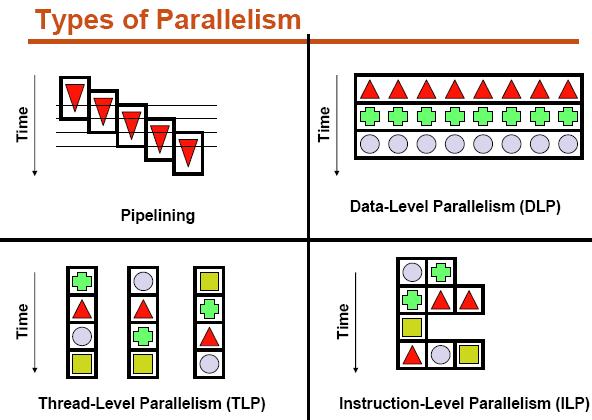
12
13 Thread Level Parallelism (TLP) ILP exploits implicit parallel operations within a loop or straight-line code segment TLP explicitly represented by the use of multiple threads of execution that are inherently parallel Goal: Use multiple instruction streams to improve 1.Throughput of computers that run many programs 2.Execution time of multi-threaded programs TLP could be more cost-effective to exploit than ILP
14 New Approach: Mulithreaded Execution Multithreading: multiple threads to share the functional units of 1 processor via overlapping processor must duplicate independent state of each thread e.g., a separate copy of register file, a separate PC, and for running independent programs, a separate page table memory shared through the virtual memory mechanisms, which already support multiple processes HW for fast thread switch; much faster than full process switch 100s to 1000s of clocks When switch? Alternate instruction per thread (fine grain) When a thread is stalled, perhaps for a cache miss, another thread can be executed (coarse grain)
15 Fine-Grained Multithreading Switches between threads on each instruction, causing the execution of multiples threads to be interleaved Usually done in a round-robin fashion, skipping any stalled threads CPU must be able to switch threads every clock Advantage is it can hide both short and long stalls, since instructions from other threads executed when one thread stalls Disadvantage is it slows down execution of individual threads, since a thread ready to execute without stalls will be delayed by instructions from other threads Used on Sun s Niagara
16 Source of Underutilization Stall or Underutilization: L1 cache miss (Data and Instruction) L2 cache miss Instruction dependency Long execution time operation, example: Divide Branch miss prediction
17 Course-Grained Multithreading Switches threads only on costly stalls, such as L2 cache misses Advantages Relieves need to have very fast thread-switching Doesn t slow down thread, since instructions from other threads issued only when the thread encounters a costly stall Disadvantage is hard to overcome throughput losses from shorter stalls, due to pipeline start-up costs Since CPU issues instructions from 1 thread, when a stall occurs, the pipeline must be emptied or frozen New thread must fill pipeline before instructions can complete Because of this start-up overhead, coarse-grained multithreading is better for reducing penalty of high cost stalls, where pipeline refill << stall time Used in IBM AS/400
18 Cycle M Simultaneous Multi-threading... One thread, 8 units M FX FX FP FP BR CC 1 1 Two threads, 8 units Cycle M M FX FX FP FP BR CC M = Load/Store, FX = Fixed Point, FP = Floating Point, BR = Branch, CC = Condition Codes
19 Bus L2 Cache and Control Without SMT, only a single thread can run at any given time L1 D-Cache D-TLB Integer Floating Point BTB Schedulers Uop queues Rename/Alloc Trace Cache Decoder ucode ROM BTB and I-TLB Thread 1: floating point
20 Bus L2 Cache and Control Without SMT, only a single thread can run at any given time L1 D-Cache D-TLB Integer Floating Point BTB Schedulers Uop queues Rename/Alloc Trace Cache Decoder ucode ROM BTB and I-TLB Thread 2: integer operation 22
21 Bus L2 Cache and Control SMT processor: both threads can run concurrently L1 D-Cache D-TLB Integer Floating Point BTB Schedulers Uop queues Rename/Alloc Trace Cache Decoder ucode ROM BTB and I-TLB Thread 2: Thread 1: floating point integer operation 23
22 Simultaneous Multithreading (SMT) Simultaneous multithreading (SMT): insight that dynamically scheduled processor already has many HW mechanisms to support multithreading Large set of virtual registers that can be used to hold the register sets of independent threads Register renaming provides unique register identifiers, so instructions from multiple threads can be mixed in datapath without confusing sources and destinations across threads Out-of-order completion allows the threads to execute out of order, and get better utilization of the HW Just adding a per thread renaming table and keeping separate PCs Independent commitment can be supported by logically keeping a separate reorder buffer for each thread Source: Micrprocessor Report, December 6, 1999 Compaq Chooses SMT for Alpha
23 Time (processor cycle) Multithreaded Categories Superscalar Fine-Grained Coarse-Grained Multiprocessing Simultaneous Multithreading Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Idle slot
24 Multi-core architectures
25 Single-core computer
26 Single-core CPU chip the single core
27 Multi-core architectures New trend in computer architecture: Replicate multiple processor cores on a single die. Core 1 Core 2 Core 3 Core 4 Multi-core CPU chip
28 Multi-core CPU chip The cores fit on a single processor socket Also called CMP (Chip Multi-Processor) c o r e c o r e c o r e c o r e
29 The cores run in parallel thread 1 thread 2 thread 3 thread 4 c o r e c o r e c o r e c o r e
30 Within each core, threads are timesliced (just like on a uniprocessor) several threads several threads several threads several threads c o r e c o r e c o r e c o r e
31 Interaction with the Operating System OS perceives each core as a separate processor OS scheduler maps threads/processes to different cores Most major OS support multi-core today: Windows, Linux, Mac OS X,

32 Why multi-core? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits: heat problems difficult design and verification large design teams necessary server farms need expensive air-conditioning Many new applications are multithreaded General trend in computer architecture (shift towards more parallelism)

33 General context: Multiprocessors Multiprocessor is any computer with several processors SIMD Single instruction, multiple data Modern graphics cards MIMD Multiple instructions, multiple data Lemieux cluster, Pittsburgh supercomputing center
34 Programming for multi-core Programmers must use threads or processes Spread the workload across multiple cores Write parallel algorithms OS will map threads/processes to cores
 { int i; for (i = 0 ; i < length ; ++i) { C[i] =")
35 As programmers, do we care? What happens if we run a program on a multi-core? void array_add(int A[], int B[], int C[], int length) { int i; for (i = 0 ; i < length ; ++i) { C[i] = A[i] + B[i]; } } #1 #2 38
36 What if we want a program to run on both processors? We have to explicitly tell the machine exactly how to do this This is called parallel programming or concurrent programming There are many parallel/concurrent programming models We will look at a relatively simple one: fork-join parallelism 39
 threads void array_add(int A[], int B[], int C[], int length) { cpu_num = fork(n-1); int i; for (i = cpu_num ; i < length ; i += N) {")
37 1.Fork N-1 threads How good is this with caches? Fork/Join Logical Example 2.Break work into N pieces (and do it) 3.Join (N-1) threads void array_add(int A[], int B[], int C[], int length) { cpu_num = fork(n-1); int i; for (i = cpu_num ; i < length ; i += N) { C[i] = A[i] + B[i]; } join(); } 40
38 How does this help performance? Parallel speedup measures improvement from parallelization: speedup(p) = time for best serial version time for version with p processors What can we realistically expect? 41
39 Reason #1: Amdahl s Law In general, the whole computation is not (easily) parallelizable In general, the whole computation is not (easily) parallelizable Serial regions 42

40 Reason #1: Amdahl s Law Suppose a program takes 1 unit of time to execute serially A fraction of the program, s, is inherently serial (unparallelizable) New Execution Time = 1-s + s P For example, consider a program that, when executing on one processor, spends 10% of its time in a non-parallelizable region. How much faster will this program run on a 3-processor system? New Execution Time =.9T 3 +.1T = Speedup = What is the maximum speedup from parallelization?
41 Reason #2: Overhead void array_add(int A[], int B[], int C[], int length) { cpu_num = fork(n-1); int i; for (i = cpu_num ; i < length ; i += N) { C[i] = A[i] + B[i]; } join(); } Forking and joining is not instantaneous Involves communicating between processors May involve calls into the operating system Depends on the implementation New Execution Time = 1-s + s + overhead(p) P
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Simultaneous Multithreading Architecture
 Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
ECSE 425 Lecture 25: Mul1- threading
 ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Announcements. Homework 4 out today Dec 7 th is the last day you can turn in Lab 4 and HW4, so plan ahead.
 Announcements Homework 4 out today Dec 7 th is the last day you can turn in Lab 4 and HW4, so plan ahead. Thread level parallelism: Multi-Core Processors Two (or more) complete processors, fabricated on
Announcements Homework 4 out today Dec 7 th is the last day you can turn in Lab 4 and HW4, so plan ahead. Thread level parallelism: Multi-Core Processors Two (or more) complete processors, fabricated on
CSE 502 Graduate Computer Architecture. Lec 11 Simultaneous Multithreading
 CSE 502 Graduate Computer Architecture Lec 11 Simultaneous Multithreading Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
CSE 502 Graduate Computer Architecture Lec 11 Simultaneous Multithreading Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
THREAD LEVEL PARALLELISM
 THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Lecture 25: Board Notes: Threads and GPUs
 Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Lectures Parallelism
 Lectures 24-25 Parallelism 1 Pipelining vs. Parallel processing In both cases, multiple things processed by multiple functional units Pipelining: each thing is broken into a sequence of pieces, where each
Lectures 24-25 Parallelism 1 Pipelining vs. Parallel processing In both cases, multiple things processed by multiple functional units Pipelining: each thing is broken into a sequence of pieces, where each
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
EECS 452 Lecture 9 TLP Thread-Level Parallelism
 EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Superscalar Processors
 Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
An Overview of MIPS Multi-Threading. White Paper
 Public Imagination Technologies An Overview of MIPS Multi-Threading White Paper Copyright Imagination Technologies Limited. All Rights Reserved. This document is Public. This publication contains proprietary
Public Imagination Technologies An Overview of MIPS Multi-Threading White Paper Copyright Imagination Technologies Limited. All Rights Reserved. This document is Public. This publication contains proprietary
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Superscalar Machines. Characteristics of superscalar processors
 Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
EECS 470. Lecture 18. Simultaneous Multithreading. Fall 2018 Jon Beaumont
 Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
Hyperthreading Technology
 Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
TDT 4260 TDT ILP Chap 2, App. C
 TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
Multi-threaded processors. Hung-Wei Tseng x Dean Tullsen
 Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
ILP Ends TLP Begins. ILP Limits via an Oracle
 ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
CSE502 Graduate Computer Architecture. Lec 22 Goodbye to Computer Architecture and Review
 CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Computer Architecture: Multithreading (I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 9: Multithreading
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Page 1. Instruction-Level Parallelism (ILP) CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism") CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Limits to ILP. Limits to ILP. Overcoming Limits. CS252 Graduate Computer Architecture Lecture 11. Conflicting studies of amount
 CS22 Graduate Computer Architecture Lecture 11 Limits to ILP / Multithreading February 28 th, 211 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs22
CS22 Graduate Computer Architecture Lecture 11 Limits to ILP / Multithreading February 28 th, 211 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs22
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
 ECE 154B Dmitri Strukov") Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK
 DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
LIMITS OF ILP. B649 Parallel Architectures and Programming
 LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
CS 1013 Advance Computer Architecture UNIT I
 CS 1013 Advance Computer Architecture UNIT I 1. What are embedded computers? List their characteristics. Embedded computers are computers that are lodged into other devices where the presence of the computer
CS 1013 Advance Computer Architecture UNIT I 1. What are embedded computers? List their characteristics. Embedded computers are computers that are lodged into other devices where the presence of the computer
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group
 Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals
Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Page 1. Review: Dynamic Branch Prediction. Lecture 18: ILP and Dynamic Execution #3: Examples (Pentium III, Pentium 4, IBM AS/400)
") CS252 Graduate Computer Architecture Lecture 18: ILP and Dynamic Execution #3: Examples (Pentium III, Pentium 4, IBM AS/400) April 4, 2001 Prof. David A. Patterson Computer Science 252 Spring 2001 Lec
CS252 Graduate Computer Architecture Lecture 18: ILP and Dynamic Execution #3: Examples (Pentium III, Pentium 4, IBM AS/400) April 4, 2001 Prof. David A. Patterson Computer Science 252 Spring 2001 Lec
 1 cycle per instruction I
1 cycle per instruction I Principles in Computer Architecture I CSE 240A (Section ) CSE 240A Homework Three. November 18, 2008
 CSE 240A Homework Three. November 18, 2008") Principles in Computer Architecture I CSE 240A (Section 631684) CSE 240A Homework Three November 18, 2008 Only Problem Set Two will be graded. Turn in only Problem Set Two before December 4, 2008, 11:00am.
Principles in Computer Architecture I CSE 240A (Section 631684) CSE 240A Homework Three November 18, 2008 Only Problem Set Two will be graded. Turn in only Problem Set Two before December 4, 2008, 11:00am.
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3, 3.9, and Appendix C) Hardware
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3, 3.9, and Appendix C) Hardware
Simultaneous Multithreading (SMT)
") Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Assuming ideal conditions (perfect pipelining and no hazards), how much time would it take to execute the same program in: b) A 5-stage pipeline?
, how much time would it take to execute the same program in: b) A 5-stage pipeline?") 1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
CS 31: Intro to Systems Threading & Parallel Applications. Kevin Webb Swarthmore College November 27, 2018
 CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
CS 31: Intro to Systems Threading & Parallel Applications Kevin Webb Swarthmore College November 27, 2018 Reading Quiz Making Programs Run Faster We all like how fast computers are In the old days (1980
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
Lecture: SMT, Cache Hierarchies. Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
CS 152 Computer Architecture and Engineering. Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction