Steve Scott, Tesla CTO SC 11 November 15, 2011
|
|
|
- Claire Merritt
- 6 years ago
- Views:
Transcription





1 Steve Scott, Tesla CTO SC 11 November 15, 2011








2 What goal do these products have in common? Performance / W

3 Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost or power
4 The Road Ahead is Steep In the Good Old Days Leakage was not important, and voltage scaled with feature size L = L/2 V = V/2 E = CV 2 = E/8 f = 2f D = 1/L 2 = 4D P = P Halve L and get 4x the transistors and 8x the capability for the same power! MF to GF to TF and almost to PF Technology was giving us 68% per year in perf/w! Processors realized ~50% per year in perf/w (spent it on single thread performance) The New Reality Leakage has limited threshold voltage, largely ending voltage scaling Halve L and get 2x the capability for the same power. Technology will give us only 19% per year in perf/w

5 The Future Belongs to the Efficient Chips have become power (not area) constrained density increases quadratically with feature size energy/op decreases linearly with feature size

! It s getting worse: in10nm, relative cost will be 15x!")
6 Which Takes More Energy? Performing a 64-bit floating-point FMA: 893, = 39,226, = 39,226, Or moving the three 64-bit operands 18 mm across the die: This one takes over 4.2x the energy (40nm)! It s getting worse: in10nm, relative cost will be 15x! Loading the data from off chip takes >> 100x the energy. Flops are cheap. Communication is expensive.
7 Achieving Energy Efficiency Reduce overhead. Minimize data motion.






8 Multi-core CPUs Industry has gone multi-core as a first response to power issues Performance through parallelism Dial back complexity and clock rate Exploit locality But CPUs are fundamentally designed for single thread performance rather than energy efficiency Fast clock rates with deep pipelines Data and instruction caches optimized for latency Superscalar issue with out-of-order execution Dynamic conflict detection Lots of predictions and speculative execution Lots of instruction overhead per operation Less than 2% of chip power today goes to flops.






9 CPU 1690 pj/flop Optimized for Latency Caches GPU 225 pj/flop Optimized for Throughput Explicit Management of On-chip Memory Westmere 32nm Fermi 40nm

 #2 : Tianhe-1A 7168 Tesla")




10 Growing Momentum for GPUs in Supercomputing Tesla Powers 3 of 5 Top Systems (November 2011) #2 : Tianhe-1A 7168 Tesla GPUs 2.6 PFLOPS #1 : K Computer 88K Fujitsu Sparc CPUs 10.5 PFLOPS #4 : Nebulae 4650 Tesla GPUs 1.3 PFLOPS #3 : Jaguar 36K AMD Opteron CPUs 1.8 PFLOPS Titan Tesla GPUs >20 PFLOPS #5 : Tsubame Tesla GPUs 1.2 PFLOPS (most efficient PF system)















11 NVIDIA GPU Computing Uptake >300,000,000 >500,000 >100,000 >450 Compute-capable NVIDIA GPUs NVIDIA SW Development Toolkit Downloads Active NVIDIA GPU Computing Developers Universities Teaching GPU Computing Widespread adoption by HPC OEMs




12 ORNL Adopts GPUs for Next-Gen Supercomputer Titan Cray XK6 18,000 Tesla GPUs 20+ PetaFlops ~90% of flops from GPUs 2x Faster, 3x More Energy Efficient (and much smaller!) than Current #1 (K Computer)


13 NCSA Mixes GPUs into BlueWaters By incorporating a future version of the XK6 system, Blue Waters will provide a bridge to the future of scientific computing. --NCSA Director Thom Dunning Contains over 30 Cray XK cabinets With over 3000 NVIDIA Tesla GPUs

14 What About Programming?
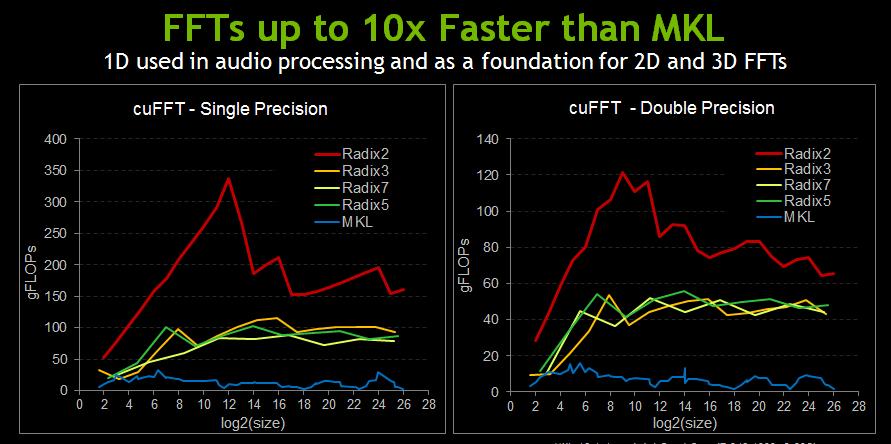
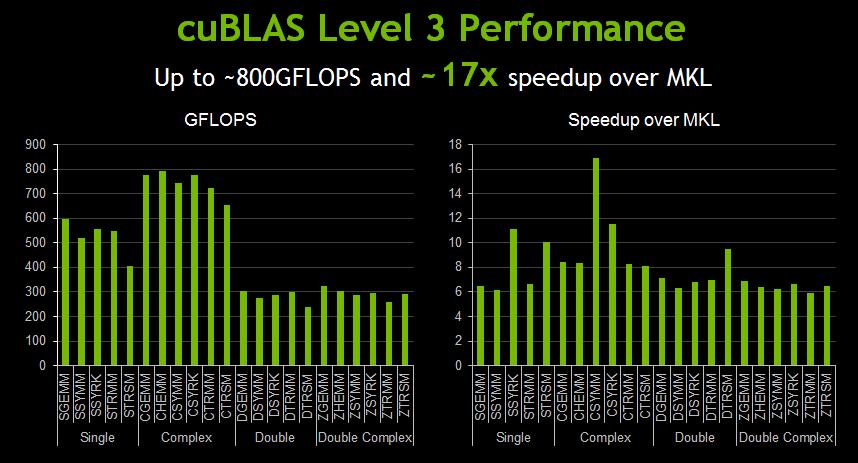
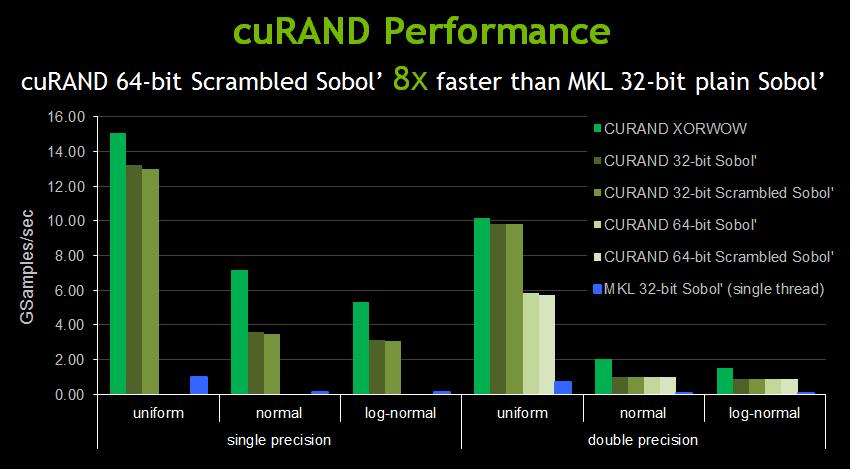
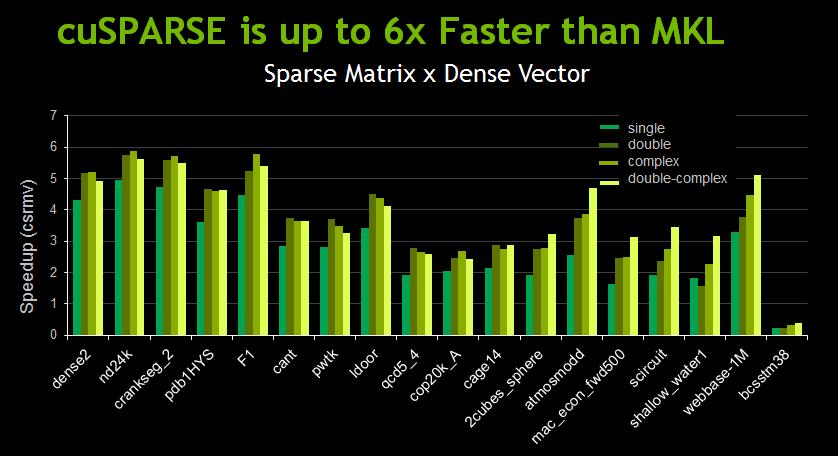



15 GPU Libraries: Plug In & Play cublas Dense Linear Algebra Parallel Algorithms QUDA Lattice QCD
 for (i=0; i<n; i++) { double t = (double)((i+0.05)/n); pi += 4.0/(1.")
16 Directives: Ease of Programming and Portability Available from PGI, CAPS, and soon Cray OpenMP Cray Directives CPU CPU GPU main() { double pi = 0.0; long i; main() { double pi = 0.0; long i; #pragma omp parallel for reduction(+:pi) for (i=0; i<n; i++) { double t = (double)((i+0.05)/n); pi += 4.0/(1.0+t*t); } printf( pi = %f\n, pi/n); } #pragma omp acc_region_loop #pragma omp parallel for reduction(+:pi) for (i=0; i<n; i++) { double t = (double)((i+0.05)/n); pi += 4.0/(1.0+t*t); } #pragma omp end acc_region_loop printf( pi = %f\n, pi/n); }




17 OpenACC: Open Parallel Programming Standard Easy, Fast, Portable OpenACC will enable programmers to easily develop portable applications that maximize the performance and power efficiency benefits of the hybrid CPU/GPU architecture of Titan. Buddy Bland Titan Project Director Oak Ridge National Lab OpenACC is a technically impressive initiative brought together by members of the OpenMP Working Group on Accelerators, as well as many others. We look forward to releasing a version of this proposal in the next release of OpenMP. Michael Wong CEO, OpenMP Directives Board


 6.")
18 Focus on Exposing Parallelism With Directives, tuning work focusses on exposing parallelism, which makes codes inherently better Example: Application tuning work using directives for new Titan system at ORNL S3D Research more efficient combustion with nextgeneration fuels CAM-SE Answer questions about specific climate change adaptation and mitigation scenarios Tuning top 3 kernels (90% of runtime) 3 to 6x faster on CPU+GPU vs. CPU+CPU But also improved all-cpu version by 50% Tuning top key kernel (50% of runtime) 6.5x faster on CPU+GPU vs. CPU+CPU Improved performance of CPU version by 100%




19 The Future of HPC is Green We re constrained by power You can t simultaneously optimize for single thread performance and power efficiency Most work must be done by cores designed for throughput and efficiency Locality is key explicit control of memory hierarchy GPUs are the path to our tightly-coupled, energyefficient, hybrid processor future
20 Thank You. Questions?
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
John Levesque Nov 16, 2001
 1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
The Future of GPU Computing
 The Future of GPU Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University November 18, 2009 The Future of Computing Bill Dally Chief Scientist
The Future of GPU Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University November 18, 2009 The Future of Computing Bill Dally Chief Scientist
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Efficiency and Programmability: Enablers for ExaScale. Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford
, EE&CS, Stanford") Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
HIGH-PERFORMANCE COMPUTING
 HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA
 OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Power Profiling of Cholesky and QR Factorizations on Distributed Memory Systems
 International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Stan Posey, NVIDIA, Santa Clara, CA, USA
 Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group
Present and Future Leadership Computers at OLCF
 Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
Present and Future Leadership Computers at OLCF Al Geist ORNL Corporate Fellow DOE Data/Viz PI Meeting January 13-15, 2015 Walnut Creek, CA ORNL is managed by UT-Battelle for the US Department of Energy
Introduction to GPU Computing. 周国峰 Wuhan University 2017/10/13
 Introduction to GPU Computing chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 GPU and Its Application 3 Ways to Develop Your GPU APP An Example to Show the Developments Add GPUs: Accelerate Science
Introduction to GPU Computing chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 GPU and Its Application 3 Ways to Develop Your GPU APP An Example to Show the Developments Add GPUs: Accelerate Science
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
THE PATH TO EXASCALE COMPUTING. Bill Dally Chief Scientist and Senior Vice President of Research
 THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Accelerating HPL on Heterogeneous GPU Clusters
 Accelerating HPL on Heterogeneous GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline
Accelerating HPL on Heterogeneous GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline
Peter Messmer Developer Technology Group Stan Posey HPC Industry and Applications
 Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU. Peng Wang HPC Developer Technology
 ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
GPU Debugging Made Easy. David Lecomber CTO, Allinea Software
 GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Motivation Goal Idea Proposition for users Study
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
HPC Algorithms and Applications
 HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
The End of Denial Architecture and The Rise of Throughput Computing
 The End of Denial Architecture and The Rise of Throughput Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University Outline! Performance = Parallelism
The End of Denial Architecture and The Rise of Throughput Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University Outline! Performance = Parallelism
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
GPU Computing with OpenACC Directives Dr. Timo Stich Developer Technology Group NVIDIA Corporation
 GPU Computing with OpenACC Directives Dr. Timo Stich Developer Technology Group NVIDIA Corporation WHAT IS GPU COMPUTING? Add GPUs: Accelerate Science Applications CPU GPU Small Changes, Big Speed-up Application
GPU Computing with OpenACC Directives Dr. Timo Stich Developer Technology Group NVIDIA Corporation WHAT IS GPU COMPUTING? Add GPUs: Accelerate Science Applications CPU GPU Small Changes, Big Speed-up Application
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
GPU Computing. Axel Koehler Sr. Solution Architect HPC
 GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Ian Buck, GM GPU Computing Software
 Ian Buck, GM GPU Computing Software History... GPGPU in 2004 GFLOPS recent trends multiplies per second (observed peak) NVIDIA NV30, 35, 40 ATI R300, 360, 420 Pentium 4 July 01 Jan 02 July 02 Jan 03 July
Ian Buck, GM GPU Computing Software History... GPGPU in 2004 GFLOPS recent trends multiplies per second (observed peak) NVIDIA NV30, 35, 40 ATI R300, 360, 420 Pentium 4 July 01 Jan 02 July 02 Jan 03 July
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
ECE 574 Cluster Computing Lecture 18
 ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
ECE 574 Cluster Computing Lecture 18 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 2 April 2019 HW#8 was posted Announcements 1 Project Topic Notes I responded to everyone s
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces. Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S.
 Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
EECS4201 Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
LLVM for the future of Supercomputing
 LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
GPU Acceleration of Matrix Algebra. Dr. Ronald C. Young Multipath Corporation. fmslib.com
 GPU Acceleration of Matrix Algebra Dr. Ronald C. Young Multipath Corporation FMS Performance History Machine Year Flops DEC VAX 1978 97,000 FPS 164 1982 11,000,000 FPS 164-MAX 1985 341,000,000 DEC VAX
GPU Acceleration of Matrix Algebra Dr. Ronald C. Young Multipath Corporation FMS Performance History Machine Year Flops DEC VAX 1978 97,000 FPS 164 1982 11,000,000 FPS 164-MAX 1985 341,000,000 DEC VAX
CUDA Update: Present & Future. Mark Ebersole, NVIDIA CUDA Educator
 CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
FUSION PROCESSORS AND HPC
 FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
FUSION PROCESSORS AND HPC Chuck Moore AMD Corporate Fellow & Technology Group CTO June 14, 2011 Fusion Processors and HPC Today: Multi-socket x86 CMPs + optional dgpu + high BW memory Fusion APUs (SPFP)
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
GPU Consideration for Next Generation Weather (and Climate) Simulations
 Simulations") GPU Consideration for Next Generation Weather (and Climate) Simulations Oliver Fuhrer 1, Tobias Gisy 2, Xavier Lapillonne 3, Will Sawyer 4, Ugo Varetto 4, Mauro Bianco 4, David Müller 2, and Thomas C.
GPU Consideration for Next Generation Weather (and Climate) Simulations Oliver Fuhrer 1, Tobias Gisy 2, Xavier Lapillonne 3, Will Sawyer 4, Ugo Varetto 4, Mauro Bianco 4, David Müller 2, and Thomas C.
Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application
 Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application John Levesque Cray s Supercomputing Center of Excellence The Target ORNL s Titan System Upgrade
Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application John Levesque Cray s Supercomputing Center of Excellence The Target ORNL s Titan System Upgrade
Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era. 11/16/2011 Many-Core Computing 2
 Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era 11/16/2011 Many-Core Computing 2 Gene M. Amdahl, Validity of the Single-Processor Approach to Achieving
Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era 11/16/2011 Many-Core Computing 2 Gene M. Amdahl, Validity of the Single-Processor Approach to Achieving
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers
 Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA