One instruction specifies multiple operations All scheduling of execution units is static
|
|
|
- Walter Walker
- 6 years ago
- Views:
Transcription
1 VLIW Architectures Very Long Instruction Word Architecture One instruction specifies multiple operations All scheduling of execution units is static Done by compiler Static scheduling should mean less control, higher clock speed. Less control means more room for execution units. Currently very popular architecture in embedded applications DSP, Multimedia applications No compiled legacy code to support, all code libraries in some form of high level language
2 Keeping Execution Units Busy Execution units are 2-input, 1-output blocks (typically) Each clock cycle, need to read 2N operands, write N results for N Execution Units EU Register File EU EU EU
3 Multi-Ported Register File Design has Limits Area of the register file grows approximately with the square of the number of ports Typically routing limited, each new port requires adding new routing in both X and Y direction Write1 Bit Cell Write1 Bit Cell Read1A Read1A Read1B Read1B Write2 1 write Port 2 Read Ports Dout1A Dout1B Read2A Read2B 2 write Ports 4 Read Ports Dout2A Dout2B Dout1A Dout1B
4 Multiported Register Files (cont) Read Access time of a register file grows approximately linearly with the number of ports Internal Bit Cell loading becomes larger Larger area of register file causes longer wire delays What is reasonable today in terms of number of ports? Changes with technology, ports is currently about the maximum (read ports + write ports) Will support 5-7 execution units simultaneous operand accesses from register file
5 Solving the Register File Bottleneck Create partitioned register files connected to small numbers of Executions units (perhaps as many as one register file per EU) Global Bus Register File Register File Register File EU EU EU
6 Register File Communication Architecturally Invisible Partitioned RFs appear as one large register file to the compiler Copying between RFs is done by control Detection of when copying is needed can be complicated; goes against VLIW philosophy of minimal control overhead Architecturally Visible, have Remote and Local versions of instructions Remote instructions have one or operands in non-local RF Copying of remote operands to local RFs takes clock cycles Because copying is atomic part of remote instruction, execution unit is idle while copying is done => performance loss.
7 Register File Communication (cont). Architecturally Visible, have explicit copy operations Separation of copy and execution allows more flexible scheduling by compiler move r1, r60 (r60 in another RF) independent instr a (cycles for copy to complete) independent instr b (cycles for copy to complete) add r2, r1, r3
8 Instruction Compression Embedded Processors often put a premium on code size Uncompressed VLIW instructions are wide (of course!) Opc Dst Src1 Src2 Opc Dst Src1 Src2 Opc Dst Src1 Src2 Opc Dst Src1 Src2 Operation 1 Operation 2 Operation 3 Operation 4 How we reduce word length? NOPs are common, use only a few bits (2-3) to represent a NOP
9 When are instructions decompressed? On Instruction Cache (ICache) fill Cache fill is a slow operation to begin with; limited by speed of external memory bus Compression algorithm can be more complicated because have more time to perform the operation ICache has to hold uncompressed instructions - limits cache size On instruction fetch ICache holds compressed instructions Decompression in critical path of fetch stage, may have to add one or more pipeline stages just for decompression
10 Importance of the Compiler The quality of the compiler will determine how much of the potential performance of a VLIW architecture is actually realized. When MFLOP figures are specified for VLIW architectures, these are usually for the theoretical performance of the architecture. Actual performance can be quite lower. Because of the dependence of the compiler on the hardware, new versions of the architectures can force major rewrites of the compiler - very costly Often the user has to place hints in the high-level code ( pragmas ) that help the compiler produce more optimal code.
11 TMS320C6X CPU 8 Independent Execution units Split into two identical datapaths, each contains the same four units (L, S, D, M) Execution unit types: L : Integer adder, Logical, Bit Counting, FP adder, FP conversion S : Integer adder, Logical, Bit Manipulation, Shifting, Constant, Branch/Control, FP compare, FP conversion, FP seed generation (for software division algorithm) D : Integer adder, Load-Store M : Integer Multiplier, FP multiplier Note that Integer additions can be done on 6 of 8 units! Integer addition/subtraction is a very common operation!
12 TMS320C6X CPU (cont). Max clock speed of 200 Mhz Not too impressive compared to Intel - my guess is process limitations rather than design limitations Each datapath has a 16 x 32 Register file 10 Read ports, six Write ports Can transfer values between the two register files Global Bus 16 x 32 RF 16 x 32 RF L S M D L S M D
13 Instruction Encoding Internal Execution path is 256 bits Each operation is 32 bits wide => 8 operations per clock A fetch packet is a group of instructions fetched simultaneously. Fetch packet has 8 instructions. A execute packet is a group of instructions beginning execution in parallel. Execute packet has 8 instructions. Instructions in ICache have an associated P-bit (Parallel-bit). Fetch packet expanded to 1 to 8 Execute packets depending on P-bits
14 Fetch Packet to Execute Packet Expansion Fetch Packet A B C D E F G H P-bits, A-H executed serially 8 instructions Execute Packet n n A n n n n n n B n n n n n n n n n n n C n n n n n n n D n n n n n E n n n n F n n n n n n n n n n n n n G n n n n n n n n H 64 instructions
15 Fetch Packet to Execute Packet Expansion (cont.) Fetch Packet A B C D E F G H P-bits A B C, D E, F, G H P-bit String of 1 s followed by 0 means those execute in parallel. String starting with 0 indicates sequential execution. Execute Packet n B A n n C n n n n n E n D n n F n n n n n n n n n n n n n G H 40 instructions
16 Fetch Packet to Execute Packet Expansion (cont.) Fetch Packet Execute Packet A B C D E F G H P-bits A B C D E F G H A B C D E F G H 8 instructions P-bit String of 1 s followed by 0 means those execute in parallel. String starting with 0 indicates sequential execution.
17 Pipeline Fetch - four phases PG - program address generate PS - program address send PW - program access ready ( cache access) - Memory stall is the only stall case in the pipeline PR - program fetch packet receive Decode - two phases DP - instruction dispatch, convert fetch packet to execute packet expansion, routed to decode of functional units (functional units do multiple operations) DC - instruction decode
18 Pipeline (cont) Execute - maximum of 10 phases 90% of the instructions only use first 5 double precision FP add/mults use last 5 Result Latency: number of execute phases used by an operation (most only use 1) Delay slots: Result Latency minus 1. If zero, then result is available for next execute packet. If non-zero, then independent operations must scheduled in the delay slots Functional Unit Latency (repetition rate of Functional Unit) Either 1, 2 or 4. (1 for common operations and LD/Stores)
19
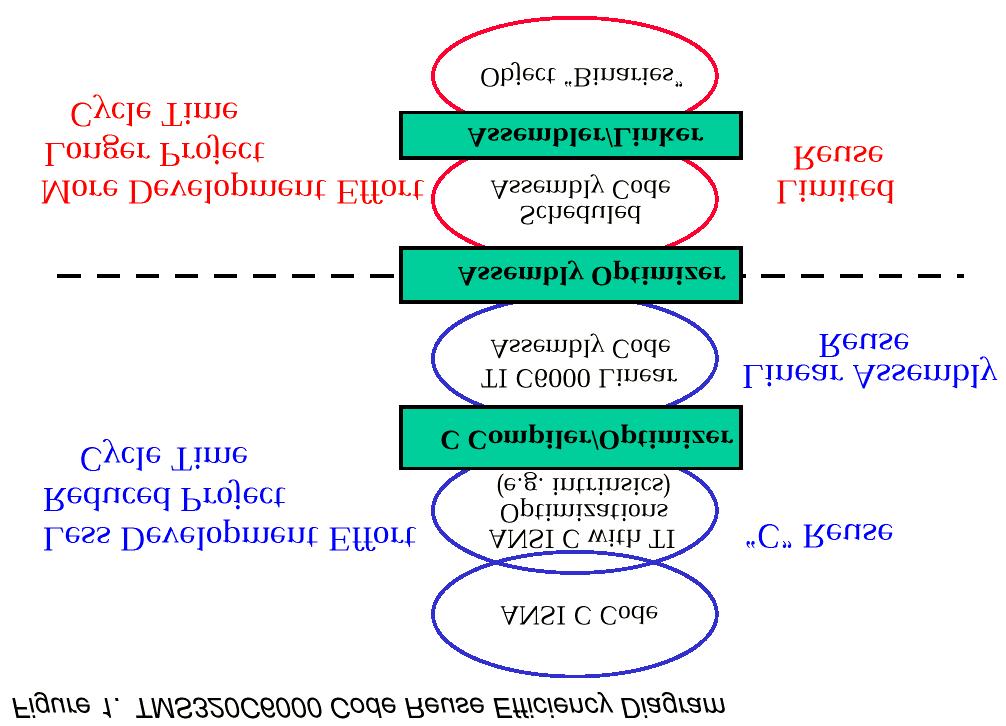
20 Guidelines for Software Development Efficiency on the TMS320C6000 VelociTI Architecture Because the C6000 is highly parallel and flexible, the task of scheduling code in an efficient way is best completed by the TI code generation tools (compiler and assembly optimizer) and not by hand. This results in a convenient C framework to maintain code development on current products as well as reuse the same code on future products (C code, C with TI C6000 Language Extensions, and the Linear Assembly source can all be reused on future TI C6000 DSPs). The final territory of programming is the hand-scheduled assembly language. At this level, the programmer is literally scheduling the assembly code to the DSP pipeline. Depending on the programmer's ability, she may achieve results similar to those achieved by the C6000 tools; however, she risks man-made pipeline scheduling errors that can cause functional errors and performance degradation. In addition, scheduled code may not be reusable on future C6000 family members, unlike the three levels of C6000 source code. Consequently, avoid the hand-coded assembly level Limited Reuse programming if at all possible.
21
22
23 Phillips TM 1000 Multimedia Processor
24 Trimedia TM-1000 (cont) Pipeline Basic Stages => Fetch, Decompression, Register-Read, Execute, Write-Back All instruction types share fetch, decompress, reg.read Alu, Shift, Fcomp Exe, Reg.Write DSPAlu Exe1, Exe2, Write FPAlu, FPMul Exe1, Exe2, Exe3, Write Load/Store Address Compute, Data Fetch, Align/Sign Ext or Store update, write Jump Jmp Addr compute and condition check, fetch
25 Trimedia TM-1000 Multimedia processor with a VLIW CPU core Five Execution Units, each EU is multi-function 27 functions total Five Execution Units => Five operations per clock issued 15 Read and 5 Write Ports on register File Need 15 read ports for 5 Execution Units because each operation requires two operands and a guard operand. Guard operand makes each operation conditional based upon value of LSB of the guard operand Guard operand reduces number of branches needed, helps fill up branch delay slots. 128 Registers (r0, r1 always 0)
26 Trimedia TM-1000 (cont) Data fetched one cache line at a time (64 bytes), concatenated with left over data from previous fetch Multiple instruction sizes 2 bits for NOP, 26 bits, 34 bits, and 44 bits. The current instruction actually has some bit information about the next instruction in order to simply decompression.
27
28 More Operations
D. Richard Brown III Associate Professor Worcester Polytechnic Institute Electrical and Computer Engineering Department
 D. Richard Brown III Associate Professor Worcester Polytechnic Institute Electrical and Computer Engineering Department drb@ece.wpi.edu 12-November-2012 Efficient Real-Time DSP Data types Memory usage
D. Richard Brown III Associate Professor Worcester Polytechnic Institute Electrical and Computer Engineering Department drb@ece.wpi.edu 12-November-2012 Efficient Real-Time DSP Data types Memory usage
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Architectures & instruction sets R_B_T_C_. von Neumann architecture. Computer architecture taxonomy. Assembly language.
 Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Parallelism. Execution Cycle. Dual Bus Simple CPU. Pipelining COMP375 1
 Pipelining COMP375 Computer Architecture and dorganization Parallelism The most common method of making computers faster is to increase parallelism. There are many levels of parallelism Macro Multiple
Pipelining COMP375 Computer Architecture and dorganization Parallelism The most common method of making computers faster is to increase parallelism. There are many levels of parallelism Macro Multiple
Processor (I) - datapath & control. Hwansoo Han
 - datapath & control. Hwansoo Han") Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
CS152 Computer Architecture and Engineering. Complex Pipelines
 CS152 Computer Architecture and Engineering Complex Pipelines Assigned March 6 Problem Set #3 Due March 20 http://inst.eecs.berkeley.edu/~cs152/sp12 The problem sets are intended to help you learn the
CS152 Computer Architecture and Engineering Complex Pipelines Assigned March 6 Problem Set #3 Due March 20 http://inst.eecs.berkeley.edu/~cs152/sp12 The problem sets are intended to help you learn the
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25
 CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
Lecture 15: Pipelining. Spring 2018 Jason Tang
 Lecture 15: Pipelining Spring 2018 Jason Tang 1 Topics Overview of pipelining Pipeline performance Pipeline hazards 2 Sequential Laundry 6 PM 7 8 9 10 11 Midnight Time T a s k O r d e r A B C D 30 40 20
Lecture 15: Pipelining Spring 2018 Jason Tang 1 Topics Overview of pipelining Pipeline performance Pipeline hazards 2 Sequential Laundry 6 PM 7 8 9 10 11 Midnight Time T a s k O r d e r A B C D 30 40 20
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
Advanced processor designs
 Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
Advanced processor designs We ve only scratched the surface of CPU design. Today we ll briefly introduce some of the big ideas and big words behind modern processors by looking at two example CPUs. The
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
An introduction to DSP s. Examples of DSP applications Why a DSP? Characteristics of a DSP Architectures
 An introduction to DSP s Examples of DSP applications Why a DSP? Characteristics of a DSP Architectures DSP example: mobile phone DSP example: mobile phone with video camera DSP: applications Why a DSP?
An introduction to DSP s Examples of DSP applications Why a DSP? Characteristics of a DSP Architectures DSP example: mobile phone DSP example: mobile phone with video camera DSP: applications Why a DSP?
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
ROB: head/tail. exercise: result of processing rest? 2. rename map (for next rename) log. phys. free list: X11, X3. PC log. reg prev.
 log. phys. free list: X11, X3. PC log. reg prev.") Exam Review 2 1 ROB: head/tail PC log. reg prev. phys. store? except? ready? A R3 X3 no none yes old tail B R1 X1 no none yes tail C R1 X6 no none yes D R4 X4 no none yes E --- --- yes none yes F --- ---
Exam Review 2 1 ROB: head/tail PC log. reg prev. phys. store? except? ready? A R3 X3 no none yes old tail B R1 X1 no none yes tail C R1 X6 no none yes D R4 X4 no none yes E --- --- yes none yes F --- ---
Lecture 5: Instruction Pipelining. Pipeline hazards. Sequential execution of an N-stage task: N Task 2
 Lecture 5: Instruction Pipelining Basic concepts Pipeline hazards Branch handling and prediction Zebo Peng, IDA, LiTH Sequential execution of an N-stage task: 3 N Task 3 N Task Production time: N time
Lecture 5: Instruction Pipelining Basic concepts Pipeline hazards Branch handling and prediction Zebo Peng, IDA, LiTH Sequential execution of an N-stage task: 3 N Task 3 N Task Production time: N time
CS 3510 Comp&Net Arch
 CS 3510 Comp&Net Arch Pipeline Dr. Ken Hoganson 2010 Enhancing Performance We observed that we can obtain better performance in executing instructions, if a single cycle accomplishes multiple operations:
CS 3510 Comp&Net Arch Pipeline Dr. Ken Hoganson 2010 Enhancing Performance We observed that we can obtain better performance in executing instructions, if a single cycle accomplishes multiple operations:
Pipelining and Vector Processing
 Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
The Processor (1) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (1) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (1) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
Advance CPU Design. MMX technology. Computer Architectures. Tien-Fu Chen. National Chung Cheng Univ. ! Basic concepts
 Computer Architectures Advance CPU Design Tien-Fu Chen National Chung Cheng Univ. Adv CPU-0 MMX technology! Basic concepts " small native data types " compute-intensive operations " a lot of inherent parallelism
Computer Architectures Advance CPU Design Tien-Fu Chen National Chung Cheng Univ. Adv CPU-0 MMX technology! Basic concepts " small native data types " compute-intensive operations " a lot of inherent parallelism
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
General Purpose Signal Processors
 General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
Single Instructions Can Execute Several Low Level
 We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing it on your computer, you have convenient answers with single instructions
We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing it on your computer, you have convenient answers with single instructions
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Instruction Set Principles and Examples. Appendix B
 Instruction Set Principles and Examples Appendix B Outline What is Instruction Set Architecture? Classifying ISA Elements of ISA Programming Registers Type and Size of Operands Addressing Modes Types of
Instruction Set Principles and Examples Appendix B Outline What is Instruction Set Architecture? Classifying ISA Elements of ISA Programming Registers Type and Size of Operands Addressing Modes Types of
Novel Multimedia Instruction Capabilities in VLIW Media Processors. Contents
 Novel Multimedia Instruction Capabilities in VLIW Media Processors J. T. J. van Eijndhoven 1,2 F. W. Sijstermans 1 (1) Philips Research Eindhoven (2) Eindhoven University of Technology The Netherlands
Novel Multimedia Instruction Capabilities in VLIW Media Processors J. T. J. van Eijndhoven 1,2 F. W. Sijstermans 1 (1) Philips Research Eindhoven (2) Eindhoven University of Technology The Netherlands
6.823 Computer System Architecture Datapath for DLX Problem Set #2
 6.823 Computer System Architecture Datapath for DLX Problem Set #2 Spring 2002 Students are allowed to collaborate in groups of up to 3 people. A group hands in only one copy of the solution to a problem
6.823 Computer System Architecture Datapath for DLX Problem Set #2 Spring 2002 Students are allowed to collaborate in groups of up to 3 people. A group hands in only one copy of the solution to a problem
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
Lecture 6 MIPS R4000 and Instruction Level Parallelism. Computer Architectures S
 Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Several Common Compiler Strategies. Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining
 Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Latches. IT 3123 Hardware and Software Concepts. Registers. The Little Man has Registers. Data Registers. Program Counter
 IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
Novel Multimedia Instruction Capabilities in VLIW Media Processors
 Novel Multimedia Instruction Capabilities in VLIW Media Processors J. T. J. van Eijndhoven 1,2 F. W. Sijstermans 1 (1) Philips Research Eindhoven (2) Eindhoven University of Technology The Netherlands
Novel Multimedia Instruction Capabilities in VLIW Media Processors J. T. J. van Eijndhoven 1,2 F. W. Sijstermans 1 (1) Philips Research Eindhoven (2) Eindhoven University of Technology The Netherlands
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
ECE 313 Computer Organization FINAL EXAM December 13, 2000
 This exam is open book and open notes. You have until 11:00AM. Credit for problems requiring calculation will be given only if you show your work. 1. Floating Point Representation / MIPS Assembly Language
This exam is open book and open notes. You have until 11:00AM. Credit for problems requiring calculation will be given only if you show your work. 1. Floating Point Representation / MIPS Assembly Language
Pipeline Architecture RISC
 Pipeline Architecture RISC Independent tasks with independent hardware serial No repetitions during the process pipelined Pipelined vs Serial Processing Instruction Machine Cycle Every instruction must
Pipeline Architecture RISC Independent tasks with independent hardware serial No repetitions during the process pipelined Pipelined vs Serial Processing Instruction Machine Cycle Every instruction must
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Implementation of DSP Algorithms
 Implementation of DSP Algorithms Main frame computers Dedicated (application specific) architectures Programmable digital signal processors voice band data modem speech codec 1 PDSP and General-Purpose
Implementation of DSP Algorithms Main frame computers Dedicated (application specific) architectures Programmable digital signal processors voice band data modem speech codec 1 PDSP and General-Purpose
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Pipelined Processors. Ideal Pipelining. Example: FP Multiplier. 55:132/22C:160 Spring Jon Kuhl 1
 55:3/C:60 Spring 00 Pipelined Design Motivation: Increase processor throughput with modest increase in hardware. Bandwidth or Throughput = Performance Pipelined Processors Chapter Bandwidth (BW) = no.
55:3/C:60 Spring 00 Pipelined Design Motivation: Increase processor throughput with modest increase in hardware. Bandwidth or Throughput = Performance Pipelined Processors Chapter Bandwidth (BW) = no.
Leveraging DSP: Basic Optimization for C6000 Digital Signal Processors
 Leveraging DSP: Basic Optimization for C6000 Digital Signal Processors Agenda C6000 VLIW Architecture Hardware Pipeline Software Pipeline Optimization Estimating performance Ui Using CCS to optimize i
Leveraging DSP: Basic Optimization for C6000 Digital Signal Processors Agenda C6000 VLIW Architecture Hardware Pipeline Software Pipeline Optimization Estimating performance Ui Using CCS to optimize i
C66x CorePac: Achieving High Performance
 C66x CorePac: Achieving High Performance Agenda 1. CorePac Architecture 2. Single Instruction Multiple Data (SIMD) 3. Memory Access 4. Pipeline Concept CorePac Architecture 1. CorePac Architecture 2. Single
C66x CorePac: Achieving High Performance Agenda 1. CorePac Architecture 2. Single Instruction Multiple Data (SIMD) 3. Memory Access 4. Pipeline Concept CorePac Architecture 1. CorePac Architecture 2. Single
General Purpose Processors
 Calcolatori Elettronici e Sistemi Operativi Specifications Device that executes a program General Purpose Processors Program list of instructions Instructions are stored in an external memory Stored program
Calcolatori Elettronici e Sistemi Operativi Specifications Device that executes a program General Purpose Processors Program list of instructions Instructions are stored in an external memory Stored program
CPE 335 Computer Organization. Basic MIPS Architecture Part I
 CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
Processor Architecture V! Wrap-Up!
 Processor Architecture V! Wrap-Up! Lecture 7, April 28 th 2011 Alexandre David Slides by Randal E. Bryant! Carnegie Mellon University! Overview! Wrap-Up of PIPE Design! n Performance analysis! n Fetch
Processor Architecture V! Wrap-Up! Lecture 7, April 28 th 2011 Alexandre David Slides by Randal E. Bryant! Carnegie Mellon University! Overview! Wrap-Up of PIPE Design! n Performance analysis! n Fetch
Chapter 4. The Processor. Computer Architecture and IC Design Lab
 Chapter 4 The Processor Introduction CPU performance factors CPI Clock Cycle Time Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS
Chapter 4 The Processor Introduction CPU performance factors CPI Clock Cycle Time Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: A Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Modern Processors. RISC Architectures
 Modern Processors RISC Architectures Figures used from: Manolis Katevenis, RISC Architectures, Ch. 20 in Zomaya, A.Y.H. (ed), Parallel and Distributed Computing Handbook, McGraw-Hill, 1996 RISC Characteristics
Modern Processors RISC Architectures Figures used from: Manolis Katevenis, RISC Architectures, Ch. 20 in Zomaya, A.Y.H. (ed), Parallel and Distributed Computing Handbook, McGraw-Hill, 1996 RISC Characteristics
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
Math 230 Assembly Programming (AKA Computer Organization) Spring MIPS Intro
 Spring MIPS Intro") Math 230 Assembly Programming (AKA Computer Organization) Spring 2008 MIPS Intro Adapted from slides developed for: Mary J. Irwin PSU CSE331 Dave Patterson s UCB CS152 M230 L09.1 Smith Spring 2008 MIPS
Math 230 Assembly Programming (AKA Computer Organization) Spring 2008 MIPS Intro Adapted from slides developed for: Mary J. Irwin PSU CSE331 Dave Patterson s UCB CS152 M230 L09.1 Smith Spring 2008 MIPS
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor. David Johnson Systems Technology Division Hewlett-Packard Company
 Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Chapter 03. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
The Processor: Datapath and Control. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 The Processor: Datapath and Control Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Introduction CPU performance factors Instruction count Determined
The Processor: Datapath and Control Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Introduction CPU performance factors Instruction count Determined
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Pipelined Processor Design
 Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
Pipelined Processor Design Pipelined Implementation: MIPS Virendra Singh Computer Design and Test Lab. Indian Institute of Science (IISc) Bangalore virendra@computer.org Advance Computer Architecture http://www.serc.iisc.ernet.in/~viren/courses/aca/aca.htm
VIII. DSP Processors. Digital Signal Processing 8 December 24, 2009
 Digital Signal Processing 8 December 24, 2009 VIII. DSP Processors 2007 Syllabus: Introduction to programmable DSPs: Multiplier and Multiplier-Accumulator (MAC), Modified bus structures and memory access
Digital Signal Processing 8 December 24, 2009 VIII. DSP Processors 2007 Syllabus: Introduction to programmable DSPs: Multiplier and Multiplier-Accumulator (MAC), Modified bus structures and memory access
Lecture: Static ILP. Topics: compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2)
") Lecture: Static ILP Topics: compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Static vs Dynamic Scheduling Arguments against dynamic scheduling: requires complex structures
Lecture: Static ILP Topics: compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Static vs Dynamic Scheduling Arguments against dynamic scheduling: requires complex structures
INSTRUCTION LEVEL PARALLELISM
 INSTRUCTION LEVEL PARALLELISM Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix H, John L. Hennessy and David A. Patterson,
INSTRUCTION LEVEL PARALLELISM Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix H, John L. Hennessy and David A. Patterson,
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
ECE 3056: Architecture, Concurrency, and Energy of Computation. Sample Problem Sets: Pipelining
 ECE 3056: Architecture, Concurrency, and Energy of Computation Sample Problem Sets: Pipelining 1. Consider the following code sequence used often in block copies. This produces a special form of the load
ECE 3056: Architecture, Concurrency, and Energy of Computation Sample Problem Sets: Pipelining 1. Consider the following code sequence used often in block copies. This produces a special form of the load
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
SUPERSCALAR AND VLIW PROCESSORS
 Datorarkitektur I Fö 10-1 Datorarkitektur I Fö 10-2 What is a Superscalar Architecture? SUPERSCALAR AND VLIW PROCESSORS A superscalar architecture is one in which several instructions can be initiated
Datorarkitektur I Fö 10-1 Datorarkitektur I Fö 10-2 What is a Superscalar Architecture? SUPERSCALAR AND VLIW PROCESSORS A superscalar architecture is one in which several instructions can be initiated
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
ECE 313 Computer Organization FINAL EXAM December 14, This exam is open book and open notes. You have 2 hours.
 This exam is open book and open notes. You have 2 hours. Problems 1-4 refer to a proposed MIPS instruction lwu (load word - update) which implements update addressing an addressing mode that is used in
This exam is open book and open notes. You have 2 hours. Problems 1-4 refer to a proposed MIPS instruction lwu (load word - update) which implements update addressing an addressing mode that is used in
Introduction Architecture overview. Multi-cluster architecture Addressing modes. Single-cluster Pipeline. architecture Instruction folding
 ST20 icore and architectures D Albis Tiziano 707766 Architectures for multimedia systems Politecnico di Milano A.A. 2006/2007 Outline ST20-iCore Introduction Introduction Architecture overview Multi-cluster
ST20 icore and architectures D Albis Tiziano 707766 Architectures for multimedia systems Politecnico di Milano A.A. 2006/2007 Outline ST20-iCore Introduction Introduction Architecture overview Multi-cluster
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation.
 UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation. July 14) (June 2013) (June 2015)(Jan 2016)(June 2016) H/W Support : Conditional Execution Also known
UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation. July 14) (June 2013) (June 2015)(Jan 2016)(June 2016) H/W Support : Conditional Execution Also known
Structure of Computer Systems
 288 between this new matrix and the initial collision matrix M A, because the original forbidden latencies for functional unit A still have to be considered in later initiations. Figure 5.37. State diagram
288 between this new matrix and the initial collision matrix M A, because the original forbidden latencies for functional unit A still have to be considered in later initiations. Figure 5.37. State diagram
Lecture: Pipeline Wrap-Up and Static ILP
 Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Chapter 8. Pipelining
 Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
Lecture 4 - Number Representations, DSK Hardware, Assembly Programming
 Lecture 4 - Number Representations, DSK Hardware, Assembly Programming James Barnes (James.Barnes@colostate.edu) Spring 2014 Colorado State University Dept of Electrical and Computer Engineering ECE423
Lecture 4 - Number Representations, DSK Hardware, Assembly Programming James Barnes (James.Barnes@colostate.edu) Spring 2014 Colorado State University Dept of Electrical and Computer Engineering ECE423
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Perfect Student CS 343 Final Exam May 19, 2011 Student ID: 9999 Exam ID: 9636 Instructions Use pencil, if you have one. For multiple choice
 Instructions Page 1 of 7 Use pencil, if you have one. For multiple choice questions, circle the letter of the one best choice unless the question specifically says to select all correct choices. There
Instructions Page 1 of 7 Use pencil, if you have one. For multiple choice questions, circle the letter of the one best choice unless the question specifically says to select all correct choices. There
Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]
![Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]](/thumbs/93/113797768.jpg "Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]") Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number