Lecture 8: GPU Programming. CSE599G1: Spring 2017
|
|
|
- Jayson Patrick
- 6 years ago
- Views:
Transcription
1 Lecture 8: GPU Programming CSE599G1: Spring 2017
2 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library Infer output shapes and memory planning
3 Overview GPU architecture CUDA programming model Case study of efficient GPU kernels
4 CPU vs GPU output CPU input
5 CPU vs GPU output output CPU Write back Decode input Fetch input
6 CPU vs GPU output output CPU Write back Decode input Fetch input Too much overhead in compute resources and energy efficiency
7 CPU vs GPU output output CPU Write back Decode input Fetch input Vector operations (SSE / AVX)
8 CPU vs GPU GPU: specialized accelerator output Decode output CPU Write back Decode input Fetch input Vector operations (SSE / AVX)
9 Streaming Multiprocessor (SM) Decode and schedule the next instructions Registers SP float core DP float core Load/store memory Special function unit Multiple caches
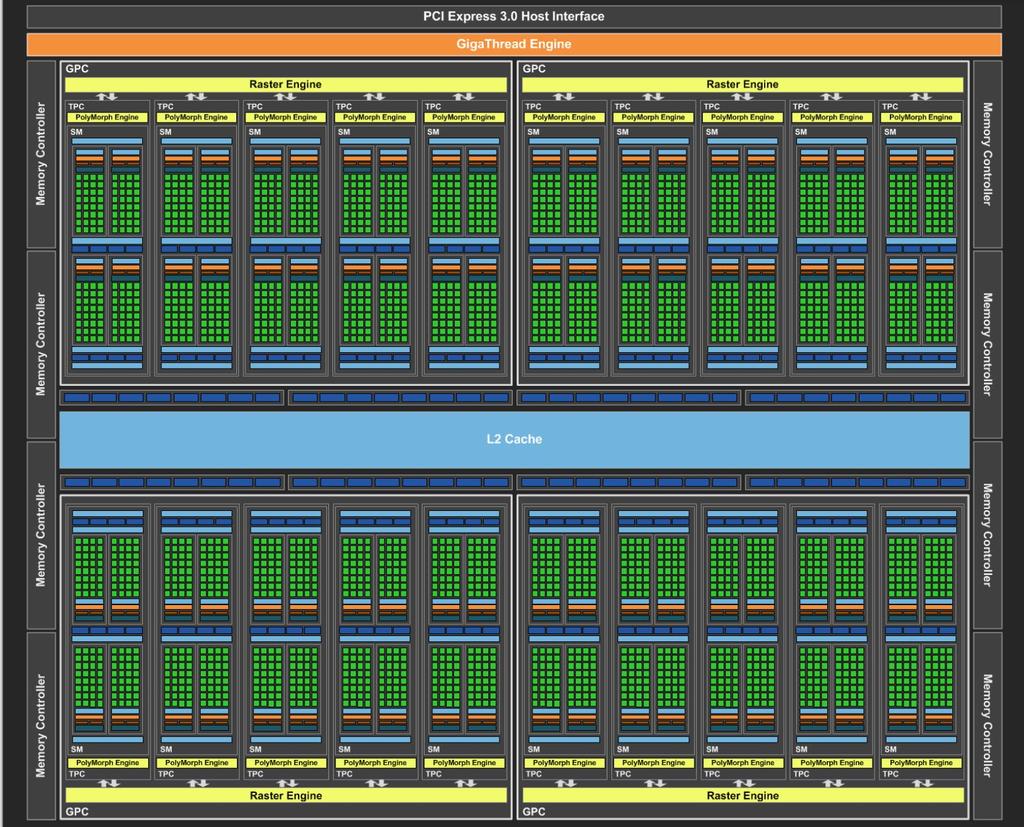
10 GPU Architecture
11 Theoretical peak FLOPS comparison *
12 Memory Hierarchy CPU memory hierarchy Core Reg L1 cache L2 cache
13 Memory Hierarchy CPU memory hierarchy Core Core Reg Reg L1 cache L1 cache L2 cache L2 cache L3 cache DRAM
14 Memory Hierarchy CPU memory hierarchy Core Core Reg Reg L1 cache L1 cache GPU memory hierarchy SM Reg L1 cache L2 cache L2 cache SM Shared memory Read-only cache L3 cache L2 cache DRAM GPU DRAM
15 Memory Hierarchy CPU memory hierarchy Core Reg L1 cache Intel Xeon E7-8870v4 Cores: 20 Reg / core:?? GPU memory hierarchy Titan X Pascal SMs: 28 Cores / SM: 128 Reg / SM: 256 KB SM Reg L1 / core: 32KB L2 cache L2 / core: 256KB L1 / SM: 48 KB Sharedmem / SM: 64 KB L3 cache L3 cache: 50MB L2 cache: 3 MB DRAM DRAM: 100s GB GPU DRAM: 12 GB Price: $12,000 Price: $1,200 L1 cache Shared memory L2 cache GPU DRAM Read-only cache
16 Memory Hierarchy CPU memory hierarchy Core Reg L1 cache Intel Xeon E7-8870v4 Cores: 20 Reg / core:?? GPU memory hierarchy Titan X Pascal SMs: 28 Cores / SM: 128 Reg / SM: 256 KB SM Reg L1 / core: 32KB L1 / SM: 48 KB Sharedmem / SM: 64 KB L2 cache L2 / core: 256KB L3 cache L3 cache: 50MB L2 cache: 3 MB DRAM DRAM: 100s GB GPU DRAM: 12 GB Price: $12,000 Price: $1,200 L1 cache Shared memory More registers than L1 cache L2 cache GPU DRAM Read-only cache
17 Memory Hierarchy CPU memory hierarchy Core Reg L1 cache L2 cache GPU memory hierarchy Intel Xeon E7-8870v4 Cores: 20 Reg / core:?? Titan X Pascal SMs: 28 Cores / SM: 128 Reg / SM: 256 KB SM Reg L1 / core: 32KB L2 / core: 256KB L1 / SM: 48 KB Sharedmem / SM: 64 KB L1 cache Shared memory L1 cache controlled by programmer L3 cache L3 cache: 50MB L2 cache: 3 MB DRAM DRAM: 100s GB GPU DRAM: 12 GB Price: $12,000 Price: $1,200 L2 cache GPU DRAM Read-only cache
 * http://lpgpu.")
18 GPU Memory Latency Registers Registers: R 0 cycle / R-after-W ~20 cycles L1/texture cache: 92 cycles Shared memory: 28 cycles Constant L1 cache: 28 cycles L2 cache: 200 cycles DRAM: 350 cycles (for Nvidia Maxwell architecture) *
19 Memory bandwidth comparison *
20 Nvidia GPU Comparison GPU Tesla K40 (2014) Titan X (2015) Titan X (2016) Architecture Kepler GK110 Maxwell GM200 Pascal GP102 Number of SMs CUDA cores 2880 (192 * 15SM) 3072 (128 * 24SM) 3584 (128 * 28SM) Max clock rate 875 MHz 1177 MHz 1531 MHz FP32 GFLOPS bit Registers / SM 64K (256KB) 64K (256KB) 64K (256KB) Shared Memory / SM 16 KB / 48 KB 96 KB 64 KB L2 Cache / SM 1.5 MB 3 MB 3 MB Global DRAM 12 GB 12 GB 12 GB Power 235 W 250 W 250 W
21 CUDA Programming Model
22 Thread Hierarchy thread Programmer writes code for a single thread in simple C program. Threads are grouped into a block. thread block block 0 block 1 block 2 block 3 grid Threads within the same block can synchronize execution. Blocks are grouped into a grid. All threads executes the same code, but can take different paths. Blocks are independently scheduled on the GPU, can be executed in any order. A kernel is executed as a grid of blocks of threads.
23 Kernel Execution Each block is executed by one SM and does not migrate. Several concurrent blocks can reside on one SM depending on block s memory requirement and the SM s memory resources. Kernel (Grid) GPU with 2 SMs SM 0 SM 1 Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 GPU with 4 SMs SM 0 SM 1 SM 2 SM 3 Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7

24 Kernel Execution A warp consists of 32 threads A warp is the basic schedule unit in kernel execution. A thread block consists of 32-thread warps. Each cycle, a warp scheduler selects one ready warps and dispatches the warps to CUDA cores to execute. SM0 Thread Block Pool thread block 1 thread block 2 warp warp thread block n
25 Thread Hierarchy & Memory Hierarchy GPU memory hierarchy thread registers & local memory SM Reg shared memory L1 cache Shared memory thread block L2 cache block 0 block 1 global memory block 2 block 3 grid GPU DRAM Read-only cache
26 Example: Vector Add // compute vector sum Void vecadd_cpu(const for (int i = 0; i C[i] = A[i] + } C = A + B float* A, const float* B, float* C, int n) { < n; ++i) B[i];
27 Example: Vector Add // compute vector sum Void vecadd_cpu(const for (int i = 0; i C[i] = A[i] + } C = A + B float* A, const float* B, float* C, int n) { < n; ++i) B[i]; global void vecaddkernel(const float* A, const float* B, float* C, int n) { int i = blockdim.x * blockidx.x + threadidx.x; if (i < n) { C[i] = A[i] + B[i]; } }
28 Example: Vector Add global index threadidx.x blockidx.x 0 1 Suppose each block only includes 4 threads: blockdim.x = 4 2 global void vecaddkernel(const float* A, const float* B, float* C, int n) { int i = blockdim.x * blockidx.x + threadidx.x; Compute the global index if (i < n) { C[i] = A[i] + B[i]; } }
29 Example: Vector Add global index threadidx.x blockidx.x 0 1 Suppose each block only includes 4 threads: blockdim.x = 4 2 global void vecaddkernel(const float* A, const float* B, float* C, int n) { int i = blockdim.x * blockidx.x + threadidx.x; if (i < n) { Each thread only performs C[i] = A[i] + B[i]; one pair-wise addition } }
30 Example: Vector Add (Host) #define THREADS_PER_BLOCK 512 void vecadd(const float* A, const float* B, float* C, int n) { float *d_a, *d_b, *d_c; int size = n * sizeof(float); cudamalloc((void **) &d_a, size); cudamemcpy(d_a, A, size, cudamemcpyhosttodevice); cudamalloc((void **) &d_b, size); cudamemcpy(d_b, B, size, cudamemcpyhosttodevice); cudamalloc((void **) &d_c, size); int nblocks = (n + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; vecaddkernel<<<nblocks, THREADS_PER_BLOCK>>>(d_A, d_b, d_c, n); cudamemcpy(c, d_c, size, cudamemcpydevicetohost); cudafree(d_a); cudafree(d_b); cudafree(d_c); }
31 Example: Vector Add (Host) #define THREADS_PER_BLOCK 512 void vecadd(const float* A, const float* B, float* C, int n) { float *d_a, *d_b, *d_c; int size = n * sizeof(float); cudamalloc((void **) &d_a, size); cudamemcpy(d_a, A, size, cudamemcpyhosttodevice); cudamalloc((void **) &d_b, size); cudamemcpy(d_b, B, size, cudamemcpyhosttodevice); cudamalloc((void **) &d_c, size); int nblocks = (n + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK; vecaddkernel<<<nblocks, THREADS_PER_BLOCK>>>(d_A, d_b, d_c, n); cudamemcpy(c, d_c, size, cudamemcpydevicetohost); Launch the GPU kernel cudafree(d_a); cudafree(d_b); cudafree(d_c); asynchronously }
32 Example: Sliding Window Sum Consider computing the sum of a sliding window over a vector Each output element is the sum of input elements within a radius Example: image blur kernel If radius is 3, each output element is sum of 7 input elements input output
33 A naive implementation #define RADIUS 3 global void windowsumnaivekernel(const float* A, float* B, int n) { int out_index = blockdim.x * blockidx.x + threadidx.x; int in_index = out_index + RADIUS; if (out_index < n) { float sum = 0.; for (int i = -RADIUS; i <= RADIUS; ++i) { sum += A[in_index + i]; } B[out_index] = sum; } }
34 A naive implementation void windowsum(const float* A, float* B, int n) { float *d_a, *d_b; int size = n * sizeof(float); cudamalloc((void **) &d_a, (n + 2 * RADIUS) * sizeof(float)); cudamemset(d_a, 0, (n + 2 * RADIUS) * sizeof(float)); cudamemcpy(d_a + RADIUS, A, size, cudamemcpyhosttodevice); cudamalloc((void **) &d_b, size); dim3 threads(threads_per_block, 1, 1); dim3 blocks((n + THREADS_PER_BLOCK - 1) / THREADS_PER_BLOCK, 1, 1); windowsumnaivekernel<<<blocks, threads>>>(d_a, d_b, n); cudamemcpy(b, d_b, size, cudamemcpydevicetohost); cudafree(d_a); cudafree(d_b); }
35 How to improve it? For each element in the input, how many times it is loaded?
36 How to improve it? For each element in the input, how many times it is read? Each input element is read 7 times! Neighboring threads read most of the same elements How can we avoid redundant reading of data? input output
37 Sharing data between threads within a block A thread block first cooperatively loads the needed input data into the shared memory. input output Computed by block 1
38 Kernel with shared memory global void windowsumkernel(const float* A, float* B, int n) { shared float temp[threads_per_block + 2 * RADIUS]; int out_index = blockdim.x * blockidx.x + threadidx.x; int in_index = out_index + RADIUS; int local_index = threadidx.x + RADIUS; if (out_index < n) { temp[local_index] = A[in_index]; if (threadidx.x < RADIUS) { temp[local_index - RADIUS] = A[in_index - RADIUS]; temp[local_index + THREADS_PER_BLOCK] = A[in_index+THREADS_PER_BLOCK]; } syncthreads();
39 Kernel with shared memory float sum = 0.; for (int i = -RADIUS; i <= RADIUS; ++i) { sum += temp[local_index + i]; } B[out_index] = sum; } }
40 Performance comparison Demo! Code:
41 Case study of efficient GPU kernels
42 C=AxB A: MxK matrix B: KxN matrix C: MxN matrix Case study: GEMM b s B K K A C s b b b M N Workload of a thread block
43 C=AxB A: MxK matrix B: KxN matrix C: MxN matrix Case study: GEMM b s B K K A C b s b b M N Workload of a thread block
44 C=AxB A: MxK matrix B: KxN matrix C: MxN matrix Case study: GEMM b B s K K A C b s b b M N Workload of a thread block
45 C=AxB A: MxK matrix B: KxN matrix C: MxN matrix Case study: GEMM b s B Cooperatively loaded by both thread 1 and 2 K Shared memory K A s C b s b Suppose each thread block has t * t threads, bt=b / t B strip b bt M b A strip Global memory C tile Registers Thread 2 b Thread 1 N s Each thread block computes a b x b area
46 Case study: GEMM pseudocode block_dim: <M / b, N / b> thread_dim: <t, t> // thread function global void SGEMM(float *A, float *B, float *C, int b, int s) { shared float sa[2][b][s], sb[2][s][b]; // shared by a thread block float rc[bt][bt] = {0}; // thread local buffer, in the registers Cooperative fetch first strip from A, B to sa[0], sb[0] sync_threads(); for (k = 0; k < K / s; k += 1) { Cooperative fetch next strip from A, B to sa[(k+1)%2], sb[(k+1)%2] sync_threads(); Run in parallel for (kk = 0; kk < s; kk += 1) { for (j = 0; j < bt; j += 1) { // unroll loop for (i = 0; i < bt; i += 1) { // unroll loop rc[j][i] += sa[k%2][threadidx.x*bt+j][kk]*sb[k%2][kk][threadidx.y*bt+i]; } }}} Write rc back to C }
47 Case study: GEMM More details see: elerated%20computing%20-%20programming%20gpus%20lecture%204. pdf Lai, Junjie, and André Seznec. "Performance upper bound analysis and optimization of SGEMM on Fermi and Kepler GPUs." Code Generation and Optimization (CGO), 2013 IEEE/ACM International Symposium on. IEEE, 2013.
48 Case study: Reduction Sum rojects/reduction/doc/reduction.pdf
49 Tips for high performance Use existing libraries, which are highly optimized, e.g. cublas, cudnn. Use nvprof or nvvp (visual profiler) to debug the performance. Use high level language to write GPU kernels.
50 References CUDA Programming Guide:
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
HPCSE II. GPU programming and CUDA
 HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
GPU programming: CUDA. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden. Computing with Graphical Processing Units CUDA Programming Matrix multiplication
 Scott B. Baden. Computing with Graphical Processing Units CUDA Programming Matrix multiplication") Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden Computing with Graphical Processing Units CUDA Programming Matrix multiplication Announcements A2 has been released: Matrix multiplication
Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden Computing with Graphical Processing Units CUDA Programming Matrix multiplication Announcements A2 has been released: Matrix multiplication
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
$ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x. Enter in the application folder Compile the source code Launch the application
 $ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x Enter in the application folder Compile the source code Launch the application --- General Information for device 0 --- Name: xxxx Compute capability:
$ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x Enter in the application folder Compile the source code Launch the application --- General Information for device 0 --- Name: xxxx Compute capability:
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
An Introduction to GPU Computing and CUDA Architecture
 An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
GPU COMPUTING. Ana Lucia Varbanescu (UvA)
") GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
CUDA. More on threads, shared memory, synchronization. cuprintf
 CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
Basics of CADA Programming - CUDA 4.0 and newer
 Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
CS377P Programming for Performance GPU Programming - I
 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
Don t reinvent the wheel. BLAS LAPACK Intel Math Kernel Library
 Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation
 CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation What is CUDA? CUDA Platform Expose GPU computing for general purpose Retain performance CUDA C/C++ Based on industry-standard C/C++ Small
CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation What is CUDA? CUDA Platform Expose GPU computing for general purpose Retain performance CUDA C/C++ Based on industry-standard C/C++ Small
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
GPU Programming with CUDA. Pedro Velho
 GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
GPU Architecture and Programming. Andrei Doncescu inspired by NVIDIA
 GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
CSE 599 I Accelerated Computing Programming GPUS. Intro to CUDA C
 CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Advanced CUDA Optimizations
 Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
Lecture 6b Introduction of CUDA programming
 CS075 1896 1920 1987 2006 Lecture 6b Introduction of CUDA programming 0 1 0, What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on
CS075 1896 1920 1987 2006 Lecture 6b Introduction of CUDA programming 0 1 0, What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on
CUDA Exercises. CUDA Programming Model Lukas Cavigelli ETZ E 9 / ETZ D Integrated Systems Laboratory
 CUDA Exercises CUDA Programming Model 05.05.2015 Lukas Cavigelli ETZ E 9 / ETZ D 61.1 Integrated Systems Laboratory Exercises 1. Enumerate GPUs 2. Hello World CUDA kernel 3. Vectors Addition Threads and
CUDA Exercises CUDA Programming Model 05.05.2015 Lukas Cavigelli ETZ E 9 / ETZ D 61.1 Integrated Systems Laboratory Exercises 1. Enumerate GPUs 2. Hello World CUDA kernel 3. Vectors Addition Threads and
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Review. Lecture 10. Today s Outline. Review. 03b.cu. 03?.cu CUDA (II) Matrix addition CUDA-C API
 Matrix addition CUDA-C API") Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
Basic CUDA workshop. Outlines. Setting Up Your Machine Architecture Getting Started Programming CUDA. Fine-Tuning. Penporn Koanantakool
 Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
A Tutorial on CUDA Performance Optimizations
 A Tutorial on CUDA Performance Optimizations Amit Kalele Prasad Pawar Parallelization & Optimization CoE TCS Pune 1 Outline Overview of GPU architecture Optimization Part I Block and Grid size Shared memory
A Tutorial on CUDA Performance Optimizations Amit Kalele Prasad Pawar Parallelization & Optimization CoE TCS Pune 1 Outline Overview of GPU architecture Optimization Part I Block and Grid size Shared memory
GPU Performance Nuggets
 GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
GPU Computing with CUDA
 GPU Computing with CUDA Hands-on: CUDA Profiling, Thrust Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison
GPU Computing with CUDA Hands-on: CUDA Profiling, Thrust Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA. Sathish Vadhiyar High Performance Computing
 CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter