Parallel Programming using FastFlow
|
|
|
- Hope Palmer
- 6 years ago
- Views:
Transcription


1 Parallel Programming using FastFlow Massimo Torquati Computer Science Department, University of Pisa - Italy Karlsruhe, September 2nd, 2014
2 Outline Structured Parallel Programming FastFlow: A data-flow framework for heterogeneous many-core platforms Algorithmic Skeletons & Parallel Design Patterns In this talk we consider mainly multi-core systems Applications developed using FastFlow & Structured Parallel Programming 2
3 Structured Parallel Programming Structured parallel programming aims to provide standard (and effective) rules for composing parallel computations in a machine-independent way Goal: reducing the complexity of parallelization problems by introducing constraints i.e. restricting the computation structure Modularity portability and programmability are the keywords Parallel paradigms are the base components of parallel applications Using structured parallel programming force to think parallel 3
4 Structured Parallel Programming The parallel programmer is relieved from all concerns related to the implementation of the parallel paradigms on the target platform The parallel programmer has to concentrate only on computational aspects Separation of concerns principles 4
5 Skeletons & Patterns Parallel Design Patterns Algorithmic Skeletons From HPC community From SW engineering community From early '90 From early '00 Pre-defined parallel high-order functions provided as constructs or lib calls Recipes to handle parallelism (name, problem, algorithms, solutions,...) The same concept at different abstraction levels We use the two terms patterns and skeletons, interchangeably. We want to emphasise the similarities of these two concepts 5


6 Structured Parallel Programming using Patterns System developer Patterns Map, Reduce, Stencil,... Pipeline, Task-Farm Divide&Conquer, MDF,. Which pattern? Problem Data Parallel Stream Parallel Task Parallel run-time support ct se e l se po m co tend iate t ex tan ins High-level code App developer iterate 6
7 Structured Parallel Programming: example Problem: apply the function F to all N elements of the input array A Select the Map pattern Instantiate the Map pattern with static partitioning App developer run-time support Select the best Map implementation on the target platform with static partitioning of data Execute the code and provide the result Analyse the result: the workload is unbalanced Instantiate the Map pattern with dynamic partitioning App developer run-time support Select the best Map implementation on the target platform with dynamic partitioning of data Execute the code and provide the result 7
 Reduced development time. Lower total cost to solution.")
8 Assessment (algorithmic skeletons) Separation of concerns Inversion of control Performance Application programmer: what is computed System programmer: how the result is computed Program structure suggested by the programmer The run-time selects the optimization for the target platform Close to hand tuned code (sometimes better) Reduced development time. Lower total cost to solution. Structured Parallel Programming by Marco Danelutto Available on-line as SPM course material at M. Danelutto web page 8

 plus the feedback pattern modifier High-level patterns aim to provide flexible")
9 The FastFlow framework C++ class library Promotes structured parallel programming It aims to be flexible and efficient enough to target multi-core, manycore and distributed systems. Layered design: Building blocks minimal set of mechanisms: channels, code wrappers, combinators. Core patterns streaming patterns (pipeline and task-farm) plus the feedback pattern modifier High-level patterns aim to provide flexible reusable parametric patterns for solving specific parallel problems 9


10 FastFlow Building Blocks Minimal definition of a node : nodes are concurrent activities POSIX threads struct mynode: ff_node { void *svc(void *task) { return task; } }; arrows are shared-memory channels implemented as SPSC lock-free queues 10
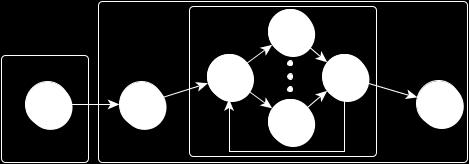
11 Stream Parallel Patterns ( core patterns) A stream is a sequence of data items having the same type pipeline ff_pipe<mytask> pipe(s1,s2,...,sn); pipe.run_and_wait_end(); task-farm ff_node std::vector<ff_node*> WorkerArray; ff_farm<> farm(workerarray, &E, &C); farm.run_and_wait_end(); Emitter: schedules input data items Collector: gathers results 11


12 FastFlow core patterns task-farm Specializations pipeline Patterns 12

13 Core Patterns Composition 13









14 Example: filtering images Time= 288s 4-stage pipeline replicating Blur & Emboss functions by using task-farm optimizing resources Time= 71s Time= 34s Time= 112s farm with pipeline workers parallelizing I/O too Time= 75s Time= 33s 14 2 Xeon 2.4GHz, 1 disk storage
 { A[i] = F(i); }); R: reduce function ParallelForReduce<double> pfr; pfr.")
 { sum += F(i); }, [](double &sum, const double v) {")
 { ; M & R: computed in pipeline n.")
15 Data Parallel Patterns (1) ParallelFor/ParallelForReduce M: map function ParallelFor pf; pf.parallel_for(0,n,[&](const long i) { A[i] = F(i); }); R: reduce function ParallelForReduce<double> pfr; pfr.parallel_reduce(sum, 0.0, M & R: computed in parallel 0,N,[&](const long i) { sum += F(i); }, [](double &sum, const double v) { ParallelForPipeReduce sum += v; }); ParallelForPipeReduce<task_t> pfr; auto MapF = [&](...ff_buffernode &n) { ; M & R: computed in pipeline n.put(task); }; Static and dynamic scheduling of tasks auto ReducdF = [&](task_t *task) { }; With or without scheduler thread (Sched) pfr.parallel_reduce_idx(0,n,step,chunk, 15 MapF, ReduceF);

16 Data Parallel Patterns (2) Map poolevolution May be used inside stream parallel patterns (pipeline and task-farm) On multi-core systems all of them are implemented on top of ParallelFor* patterns Stencil Algorithms + ParallelFor* wrappers For example, the Map pattern is a FastFlow node with inside an optimized instantiation of the ParallelForReduce pattern struct mymap: ff_map<> { void *svc(void *task) {.; ff_map<>::parallel_for(...); }}; Targeting GPGPUs: support for both CUDA and/or OpenCL available for some data-parallel patterns Work still in progress 16

17 Example: Mandelbrot set (1) Very simple data-parallel computation Each pixel can be computed independently Simple ParallelFor implementation Black-pixel requires much more computation A naïve partitioning of the images quickly leads to load unbalanced computation and poor performance Let's consider the minimum computation unit a single image line (image size 2048x2048, max 103 iterations per point) Static partitioning of lines (48 workers) MaxSpedup 14 Dynamic partitioning of lines (48 workers) MaxSpeedup 37 Data-partitioning may have a big impact on the performance 17 2 Xeon 2.4GHz, 1 disk storage




18 Example: Mandelbrot set (2) Suppose now we want to compute a number of Mandelbrot images (for example varying the computing threshold per point) We have basically two options: 1. One single parallel-for inside a sequential for iterating over all different threshold points for_each threshold values 2. A task-farm with map workers implementing two different scheduling strategies parallel_for ( Mandel(threshold)); Which one is better having limited resources? Depends on many factors, too difficult to say in advance Moving quickly between the two solutions is the key point 18
) The user has to specify data dependency using a sequential function taskgen and to generate tasks (by using the AddTask method) The run-time")
 { Param 1 = {&A, INPUT}; Param 2 = {&A, OUTPUT}; mdf->addtask(params, F, A); } ff_mdf<params> mdf(taskgen); mdf.")
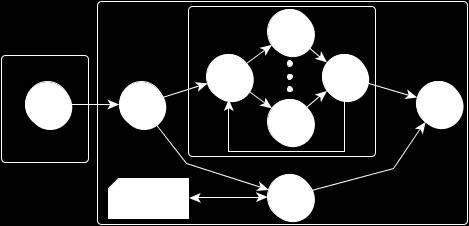
19 Task-parallel patterns Macro-Data Flow (MDF) The MDF executes data-dependency graph (DAG) Is a general approach to parallelism pipeline(taskgen, farm(ws,sched)) The user has to specify data dependency using a sequential function taskgen and to generate tasks (by using the AddTask method) The run-time automatically takes care of dependencies and then schedules ready task to Ws void taskgen( mdf...) { Param 1 = {&A, INPUT}; Param 2 = {&A, OUTPUT}; mdf->addtask(params, F, A); } ff_mdf<params> mdf(taskgen); mdf.run_and_wait_end(); Divide&Conquer Currently is a task-farm with feedback channel with specialized Emitter and Collector. 19


20 Example: Strassen's algorithm Matrix multiplication using Strassen's algorithm: A11 A12 A21 A22 X B11 B12 B21 B22 = C11 C12 C21 C22 S1 = A11 + A22 S2 = B11 + B22 P1 = S1 * S2 S3 = A21 + A22 P2 = S3 * B11 S4 = B12 B22 P3 = A11 * S4 S5 = B21 B11 P4 = A22 * S5 S6 = A11 + A12 P5 = S6 * B22 S7 = A21 A11 S8 = B11 + B12 P6 = S7 * S8 S9 = A12 A22 S10 = B21 + B22 P7 = S9*S10 C11 = P1 + P4 - P5 + P7 C12 = P3 + P5 C21 = P2 + P4 C22 = P1 - P2 + P3 + P6 The sequential function taskgen is responsible for generating instructions S1, S2, P1, S3, P2... in any order specifying INPUT and OUTPUT dependencies. Each macro instruction can be computed in parallel using a ParallelFor pattern or optimized linear algebra matrix operations (BLAS, PLASMA, Lapack...) 20

 M. Aldinucci, S. Ruggieri and M.")
21 Real applications (some) Stream Parallel Bowtie (BT) and BWA Sequence Alignment Tools Peafowl, an open-source parallel DPI framework Task Parallel YaDT-FF: fast C4.5 classifier (*) Block-based LU & Cholesky factorizations Data Parallel Two Stage Image and Video Denoiser (*) M. Aldinucci, S. Ruggieri and M. Torquati Decision Tree building on muli-core using FastFlow, Concurrency and Computations: practice and experience, Vol. 26,


22 Stream: Bowtie (BT) and DWA Sequence Alignment Tools Very widely used tools for DNA alignment Hand-tuned C/C++/SSE2 code Spin-locks + POSIX Threads Reads are streamed from memory-mapped files to worker threads Task-farm+feedback implementation in FastFlow Thread pinning + memory affinity + affinity scheduling Quite substantial improvement in performance C. Misale, G. Ferrero, M. Torquati, M. Aldinucci Sequence alignment tools: one parallel pattern to rule them all? BioMed Research International,


23 Stream: 10Gbit Deep Packet Inspection (DPI) on multi-core using Peafowl Peafowl is an open-source highperformance DPI framework with FastFlow-based run-time Task-farm + customized Emitter and Collector We developed an HTTP virus pattern matching application for 10 Gibit networks It is able to sustain the full network bandwidth using commodity HW M. Danelutto, L. Deri, D. De Sensi and M. Torquati Deep Packet Inspection on commodity hardware using FastFlow in PARCO 2013 conference, Vol. 25, pg ,
 D. Buono, M. Danelutto, T.")
24 Task-Parallel: LU & Cholesky factorizations using the MDF pattern Dense matrix, block-based algorithms Macro-Data-Flow (MDF) pattern encoding dependency graph (DAG) The DAG is generated dynamically during computation Configurable scheduling affinity scheduling of tasks, Comparable performance w.r.t. specialized multi-core dense linear algebra framework (PLASMA) D. Buono, M. Danelutto, T. De Matteis, G. Mencagli and M. Torquati A light-weight run-time support for fast dense linear algebra on multi-core in PDCN 2014 conference, 2014 DAG represents, 5 tiles, left-looking 24 version of Cholesky algorithm
 9-point stencil computation High-quality edge preserving filtering Higher computational costs w.r.t. other edge preserving")

25 Data-Parallel: Two stage image restoration Detect: adaptive median filter, produces a noise map Denoise: variational Restoration (iterative optimization algorithm) 9-point stencil computation High-quality edge preserving filtering Higher computational costs w.r.t. other edge preserving filters without parallelization, no practical use of this technique because too costly The 2 phases can be pipelined for video streaming M. Aldinucci, C. Spampinato, M. Drocco, M. Torquati and S. Palazzo A parallel edge preserving algorithm for salt and pepper image denoising IPTA 2012 conference,


26 Salt & Pepper image restoration 26

27 Stream+Data-Parallel: Video de-noising, possible parallelization options using patterns M. Aldinucci, M. Torquati, M. Drocco, G. Peretti Pezzi and C. Spampinato Combining pattern level abstractions and efficiency in GPGPUs GTC 2014 invited talk,
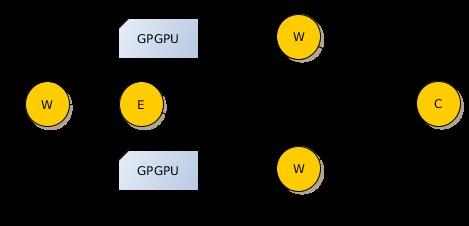
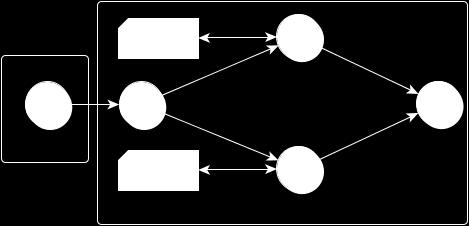
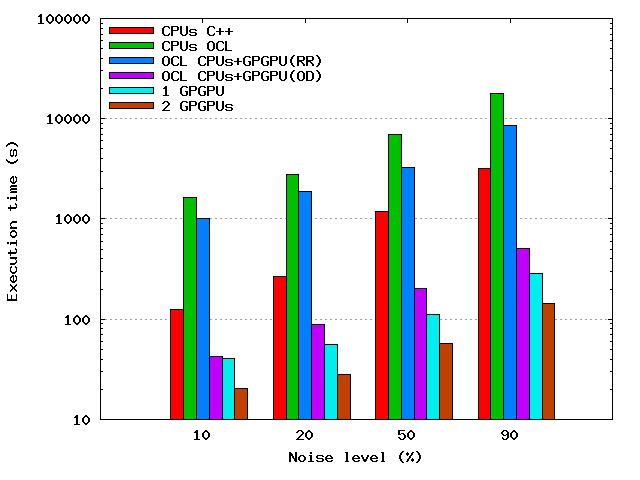


28 Video de-noising: different deployments CPU C++ only OpenCL CPU + GPGPU GPGPUs only Best option is to use all available GPGPUs 28

29 Video de-noising demo 29 Thanks to Marco Aldinucci for the demo video
30 Conclusions Structured Parallel Programming models have been here from many years It is proved they work clear semantics, enforce separation of concerns, allow rapid prototyping and portability of code, almost same performance as hand-tuned parallel code. FastFlow: a C++ class library framework Research project framework Promotes structured parallel programming Can be used at different levels, with each level providing a small number of building-blocks/patterns with clear parallel semantics 30

 Peter")




31 Thanks for your attention! Thanks to: Marco Danelutto (Pisa) Marco Aldinucci (Turin) Peter Kilpatrick (Belfast) University of Pisa FastFlow project site: University of Turin Queen's University Belfast EU-FP7 projects using FastFlow:
Introduction to FastFlow programming
 Introduction to FastFlow programming SPM lecture, November 2016 Massimo Torquati Computer Science Department, University of Pisa - Italy Data Parallel Computations In data parallel
Introduction to FastFlow programming SPM lecture, November 2016 Massimo Torquati Computer Science Department, University of Pisa - Italy Data Parallel Computations In data parallel
Introduction to FastFlow programming
 Introduction to FastFlow programming Hands-on session Massimo Torquati Computer Science Department, University of Pisa - Italy Outline The FastFlow tutorial FastFlow basic concepts
Introduction to FastFlow programming Hands-on session Massimo Torquati Computer Science Department, University of Pisa - Italy Outline The FastFlow tutorial FastFlow basic concepts
Introduction to FastFlow programming
 Introduction to FastFlow programming SPM lecture, November 2016 Massimo Torquati Computer Science Department, University of Pisa - Italy Objectives Have a good idea of the FastFlow
Introduction to FastFlow programming SPM lecture, November 2016 Massimo Torquati Computer Science Department, University of Pisa - Italy Objectives Have a good idea of the FastFlow
Efficient Smith-Waterman on multi-core with FastFlow
 BioBITs Euromicro PDP 2010 - Pisa Italy - 17th Feb 2010 Efficient Smith-Waterman on multi-core with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino - Italy Massimo Torquati Computer
BioBITs Euromicro PDP 2010 - Pisa Italy - 17th Feb 2010 Efficient Smith-Waterman on multi-core with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino - Italy Massimo Torquati Computer
Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed
 Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed Marco Aldinucci Computer Science Dept. - University of Torino - Italy Marco Danelutto, Massimiliano Meneghin,
Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed Marco Aldinucci Computer Science Dept. - University of Torino - Italy Marco Danelutto, Massimiliano Meneghin,
An efficient Unbounded Lock-Free Queue for Multi-Core Systems
 An efficient Unbounded Lock-Free Queue for Multi-Core Systems Authors: Marco Aldinucci 1, Marco Danelutto 2, Peter Kilpatrick 3, Massimiliano Meneghin 4 and Massimo Torquati 2 1 Computer Science Dept.
An efficient Unbounded Lock-Free Queue for Multi-Core Systems Authors: Marco Aldinucci 1, Marco Danelutto 2, Peter Kilpatrick 3, Massimiliano Meneghin 4 and Massimo Torquati 2 1 Computer Science Dept.
Evolution of FastFlow: C++11 extensions, distributed systems
 Evolution of FastFlow: C++11 extensions, distributed systems Massimo Torquati Computer Science Department, University of Pisa Italy torquati@di.unipi.it PARAPHRASE Summer School 2014 Dublin, Ireland, June
Evolution of FastFlow: C++11 extensions, distributed systems Massimo Torquati Computer Science Department, University of Pisa Italy torquati@di.unipi.it PARAPHRASE Summer School 2014 Dublin, Ireland, June
FastFlow: targeting distributed systems
 FastFlow: targeting distributed systems Massimo Torquati ParaPhrase project meeting, Pisa Italy 11 th July, 2012 torquati@di.unipi.it Talk outline FastFlow basic concepts two-tier parallel model From single
FastFlow: targeting distributed systems Massimo Torquati ParaPhrase project meeting, Pisa Italy 11 th July, 2012 torquati@di.unipi.it Talk outline FastFlow basic concepts two-tier parallel model From single
The Loop-of-Stencil-Reduce paradigm
 The Loop-of-Stencil-Reduce paradigm M. Aldinucci, M. Danelutto, M. Drocco, P. Kilpatrick, G. Peretti Pezzi and M. Torquati Computer Science Department, University of Turin, Italy. Computer Science Department,
The Loop-of-Stencil-Reduce paradigm M. Aldinucci, M. Danelutto, M. Drocco, P. Kilpatrick, G. Peretti Pezzi and M. Torquati Computer Science Department, University of Turin, Italy. Computer Science Department,
Marco Aldinucci Salvatore Ruggieri, Massimo Torquati
 Marco Aldinucci aldinuc@di.unito.it Computer Science Department University of Torino Italy Salvatore Ruggieri, Massimo Torquati ruggieri@di.unipi.it torquati@di.unipi.it Computer Science Department University
Marco Aldinucci aldinuc@di.unito.it Computer Science Department University of Torino Italy Salvatore Ruggieri, Massimo Torquati ruggieri@di.unipi.it torquati@di.unipi.it Computer Science Department University
Structured approaches for multi/many core targeting
 Structured approaches for multi/many core targeting Marco Danelutto M. Torquati, M. Aldinucci, M. Meneghin, P. Kilpatrick, D. Buono, S. Lametti Dept. Computer Science, Univ. of Pisa CoreGRID Programming
Structured approaches for multi/many core targeting Marco Danelutto M. Torquati, M. Aldinucci, M. Meneghin, P. Kilpatrick, D. Buono, S. Lametti Dept. Computer Science, Univ. of Pisa CoreGRID Programming
Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach
 Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach Tiziano De Matteis, Gabriele Mencagli University of Pisa Italy INTRODUCTION The recent years have
Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach Tiziano De Matteis, Gabriele Mencagli University of Pisa Italy INTRODUCTION The recent years have
FastFlow: targeting distributed systems Massimo Torquati
 FastFlow: targeting distributed systems Massimo Torquati May 17 th, 2012 torquati@di.unipi.it http://www.di.unipi.it/~torquati FastFlow node FastFlow's implementation is based on the concept of node (ff_node
FastFlow: targeting distributed systems Massimo Torquati May 17 th, 2012 torquati@di.unipi.it http://www.di.unipi.it/~torquati FastFlow node FastFlow's implementation is based on the concept of node (ff_node
A Parallel Edge Preserving Algorithm for Salt and Pepper Image Denoising
 Image Processing Theory, Tools and Applications A Parallel Edge Preserving Algorithm for Salt and Pepper Image Denoising M. Aldinucci 1, C. Spampinato 2 M. Drocco 1, M. Torquati 3, S. Palazzo 2 1 Computer
Image Processing Theory, Tools and Applications A Parallel Edge Preserving Algorithm for Salt and Pepper Image Denoising M. Aldinucci 1, C. Spampinato 2 M. Drocco 1, M. Torquati 3, S. Palazzo 2 1 Computer
Marco Danelutto. May 2011, Pisa
 Marco Danelutto Dept. of Computer Science, University of Pisa, Italy May 2011, Pisa Contents 1 2 3 4 5 6 7 Parallel computing The problem Solve a problem using n w processing resources Obtaining a (close
Marco Danelutto Dept. of Computer Science, University of Pisa, Italy May 2011, Pisa Contents 1 2 3 4 5 6 7 Parallel computing The problem Solve a problem using n w processing resources Obtaining a (close
Accelerating code on multi-cores with FastFlow
 EuroPar 2011 Bordeaux - France 1st Sept 2001 Accelerating code on multi-cores with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino (Turin) - Italy Massimo Torquati and Marco Danelutto
EuroPar 2011 Bordeaux - France 1st Sept 2001 Accelerating code on multi-cores with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino (Turin) - Italy Massimo Torquati and Marco Danelutto
Structured parallel programming
 Marco Dept. Computer Science, Univ. of Pisa DSL 2013 July 2013, Cluj, Romania Contents Introduction Structured programming Targeting HM2C Managing vs. computing Progress... Introduction Structured programming
Marco Dept. Computer Science, Univ. of Pisa DSL 2013 July 2013, Cluj, Romania Contents Introduction Structured programming Targeting HM2C Managing vs. computing Progress... Introduction Structured programming
Parallel patterns, data-centric concurrency, and heterogeneous computing
 Parallel patterns, data-centric concurrency, and heterogeneous computing Marco Aldinucci, University of Torino, Computer Science Department HPCC keynote talk, Paris, France. Aug 20, 2014 1 Outline Parallel
Parallel patterns, data-centric concurrency, and heterogeneous computing Marco Aldinucci, University of Torino, Computer Science Department HPCC keynote talk, Paris, France. Aug 20, 2014 1 Outline Parallel
Parallel video denoising on heterogeneous platforms
 Parallel video denoising on heterogeneous platforms M. Aldinucci, G. Peretti Pezzi, M. Drocco, F. Tordini Computer Science Dept. - University of Torino, Italy {aldinuc, peretti, tordini}@di.unito.it, maurizio.drocco@gmail.com
Parallel video denoising on heterogeneous platforms M. Aldinucci, G. Peretti Pezzi, M. Drocco, F. Tordini Computer Science Dept. - University of Torino, Italy {aldinuc, peretti, tordini}@di.unito.it, maurizio.drocco@gmail.com
The multi/many core challenge: a pattern based programming perspective
 The multi/many core challenge: a pattern based programming perspective Marco Dept. Computer Science, Univ. of Pisa CoreGRID Programming model Institute XXII Jornadas de Paralelismo Sept. 7-9, 2011, La
The multi/many core challenge: a pattern based programming perspective Marco Dept. Computer Science, Univ. of Pisa CoreGRID Programming model Institute XXII Jornadas de Paralelismo Sept. 7-9, 2011, La
Pool evolution: a parallel pattern for evolutionary and symbolic computing
 This is an author version of the contribution published by Springer on INTERNATIONAL JOURNAL OF PARALLEL PROGRAMMING DOI: 10.1007/s10766-013-0273-6 Pool evolution: a parallel pattern for evolutionary and
This is an author version of the contribution published by Springer on INTERNATIONAL JOURNAL OF PARALLEL PROGRAMMING DOI: 10.1007/s10766-013-0273-6 Pool evolution: a parallel pattern for evolutionary and
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ.
 An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
Marco Danelutto. October 2010, Amsterdam. Dept. of Computer Science, University of Pisa, Italy. Skeletons from grids to multicores. M.
 Marco Danelutto Dept. of Computer Science, University of Pisa, Italy October 2010, Amsterdam Contents 1 2 3 4 Structured parallel programming Structured parallel programming Algorithmic Cole 1988 common,
Marco Danelutto Dept. of Computer Science, University of Pisa, Italy October 2010, Amsterdam Contents 1 2 3 4 Structured parallel programming Structured parallel programming Algorithmic Cole 1988 common,
Autonomic QoS Control with Behavioral Skeleton
 Grid programming with components: an advanced COMPonent platform for an effective invisible grid Autonomic QoS Control with Behavioral Skeleton Marco Aldinucci, Marco Danelutto, Sonia Campa Computer Science
Grid programming with components: an advanced COMPonent platform for an effective invisible grid Autonomic QoS Control with Behavioral Skeleton Marco Aldinucci, Marco Danelutto, Sonia Campa Computer Science
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Exercising high-level parallel programming on streams: a systems biology use case
 Exercising high-level parallel programming on streams: a systems biology use case Marco Aldinucci, Maurizio Drocco, Guilherme Peretti Pezzi, Claudia Misale, Fabio Tordini Computer Science Department, University
Exercising high-level parallel programming on streams: a systems biology use case Marco Aldinucci, Maurizio Drocco, Guilherme Peretti Pezzi, Claudia Misale, Fabio Tordini Computer Science Department, University
Accelerating sequential programs using FastFlow and self-offloading
 Università di Pisa Dipartimento di Informatica Technical Report: TR-10-03 Accelerating sequential programs using FastFlow and self-offloading Marco Aldinucci Marco Danelutto Peter Kilpatrick Massimiliano
Università di Pisa Dipartimento di Informatica Technical Report: TR-10-03 Accelerating sequential programs using FastFlow and self-offloading Marco Aldinucci Marco Danelutto Peter Kilpatrick Massimiliano
Università di Pisa. Dipartimento di Informatica. Technical Report: TR FastFlow tutorial
 Università di Pisa Dipartimento di Informatica arxiv:1204.5402v1 [cs.dc] 24 Apr 2012 Technical Report: TR-12-04 FastFlow tutorial M. Aldinucci M. Danelutto M. Torquati Dip. Informatica, Univ. Torino Dip.
Università di Pisa Dipartimento di Informatica arxiv:1204.5402v1 [cs.dc] 24 Apr 2012 Technical Report: TR-12-04 FastFlow tutorial M. Aldinucci M. Danelutto M. Torquati Dip. Informatica, Univ. Torino Dip.
Intel Thread Building Blocks
 Intel Thread Building Blocks SPD course 2015-16 Massimo Coppola 08/04/2015 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
Intel Thread Building Blocks SPD course 2015-16 Massimo Coppola 08/04/2015 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
P1261R0: Supporting Pipelines in C++
 P1261R0: Supporting Pipelines in C++ Date: 2018-10-08 Project: Audience Authors: ISO JTC1/SC22/WG21: Programming Language C++ SG14, SG1 Michael Wong (Codeplay), Daniel Garcia (UC3M), Ronan Keryell (Xilinx)
P1261R0: Supporting Pipelines in C++ Date: 2018-10-08 Project: Audience Authors: ISO JTC1/SC22/WG21: Programming Language C++ SG14, SG1 Michael Wong (Codeplay), Daniel Garcia (UC3M), Ronan Keryell (Xilinx)
Intel Thread Building Blocks
 Intel Thread Building Blocks SPD course 2017-18 Massimo Coppola 23/03/2018 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
Intel Thread Building Blocks SPD course 2017-18 Massimo Coppola 23/03/2018 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
Costless Software Abstractions For Parallel Hardware System
 Costless Software Abstractions For Parallel Hardware System Joel Falcou LRI - INRIA - MetaScale SAS Maison de la Simulation - 04/03/2014 Context In Scientific Computing... there is Scientific Applications
Costless Software Abstractions For Parallel Hardware System Joel Falcou LRI - INRIA - MetaScale SAS Maison de la Simulation - 04/03/2014 Context In Scientific Computing... there is Scientific Applications
Top-down definition of Network Centric Operating System features
 Position paper submitted to the Workshop on Network Centric Operating Systems Bruxelles 16-17 march 2005 Top-down definition of Network Centric Operating System features Thesis Marco Danelutto Dept. Computer
Position paper submitted to the Workshop on Network Centric Operating Systems Bruxelles 16-17 march 2005 Top-down definition of Network Centric Operating System features Thesis Marco Danelutto Dept. Computer
High-Level and Efficient Stream Parallelism on Multi-core Systems with SPar for Data Compression Applications
 High-Level and Efficient Stream Parallelism on Multi-core Systems with SPar for Data Compression Applications Dalvan Griebler 1, Renato B. Hoffmann 1, Junior Loff 1, Marco Danelutto 2, Luiz Gustavo Fernandes
High-Level and Efficient Stream Parallelism on Multi-core Systems with SPar for Data Compression Applications Dalvan Griebler 1, Renato B. Hoffmann 1, Junior Loff 1, Marco Danelutto 2, Luiz Gustavo Fernandes
Intel Thread Building Blocks, Part II
 Intel Thread Building Blocks, Part II SPD course 2013-14 Massimo Coppola 25/03, 16/05/2014 1 TBB Recap Portable environment Based on C++11 standard compilers Extensive use of templates No vectorization
Intel Thread Building Blocks, Part II SPD course 2013-14 Massimo Coppola 25/03, 16/05/2014 1 TBB Recap Portable environment Based on C++11 standard compilers Extensive use of templates No vectorization
Supporting Advanced Patterns in GrPPI, a Generic Parallel Pattern Interface
 Supporting Advanced Patterns in GrPPI, a Generic Parallel Pattern Interface David del Rio, Manuel F. Dolz, Javier Fernández. Daniel Garcia University Carlos III of Madrid Autonomic Solutions for Parallel
Supporting Advanced Patterns in GrPPI, a Generic Parallel Pattern Interface David del Rio, Manuel F. Dolz, Javier Fernández. Daniel Garcia University Carlos III of Madrid Autonomic Solutions for Parallel
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
arxiv: v1 [cs.dc] 16 Sep 2016
![arxiv: v1 [cs.dc] 16 Sep 2016](/thumbs/92/108689363.jpg "arxiv: v1 [cs.dc] 16 Sep 2016") State access patterns in embarrassingly parallel computations Marco Danelutto & Massimo Torquati Dept. of Computer Science Univ. of Pisa {marcod,torquati}@di.unipi.it Peter Kilpatrick Dept. of Computer
State access patterns in embarrassingly parallel computations Marco Danelutto & Massimo Torquati Dept. of Computer Science Univ. of Pisa {marcod,torquati}@di.unipi.it Peter Kilpatrick Dept. of Computer
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Autonomic Features in GCM
 Autonomic Features in GCM M. Aldinucci, S. Campa, M. Danelutto Dept. of Computer Science, University of Pisa P. Dazzi, D. Laforenza, N. Tonellotto Information Science and Technologies Institute, ISTI-CNR
Autonomic Features in GCM M. Aldinucci, S. Campa, M. Danelutto Dept. of Computer Science, University of Pisa P. Dazzi, D. Laforenza, N. Tonellotto Information Science and Technologies Institute, ISTI-CNR
Predictable Timing Analysis of x86 Multicores using High-Level Parallel Patterns
 Predictable Timing Analysis of x86 Multicores using High-Level Parallel Patterns Kevin Hammond, Susmit Sarkar and Chris Brown University of St Andrews, UK T: @paraphrase_fp7 E: kh@cs.st-andrews.ac.uk W:
Predictable Timing Analysis of x86 Multicores using High-Level Parallel Patterns Kevin Hammond, Susmit Sarkar and Chris Brown University of St Andrews, UK T: @paraphrase_fp7 E: kh@cs.st-andrews.ac.uk W:
Overview of Project's Achievements
 PalDMC Parallelised Data Mining Components Final Presentation ESRIN, 12/01/2012 Overview of Project's Achievements page 1 Project Outline Project's objectives design and implement performance optimised,
PalDMC Parallelised Data Mining Components Final Presentation ESRIN, 12/01/2012 Overview of Project's Achievements page 1 Project Outline Project's objectives design and implement performance optimised,
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
Euro-Par Pisa - Italy
 Euro-Par 2004 - Pisa - Italy Accelerating farms through ad- distributed scalable object repository Marco Aldinucci, ISTI-CNR, Pisa, Italy Massimo Torquati, CS dept. Uni. Pisa, Italy Outline (Herd of Object
Euro-Par 2004 - Pisa - Italy Accelerating farms through ad- distributed scalable object repository Marco Aldinucci, ISTI-CNR, Pisa, Italy Massimo Torquati, CS dept. Uni. Pisa, Italy Outline (Herd of Object
Optimization Space Exploration of the FastFlow Parallel Skeleton Framework
 Optimization Space Exploration of the FastFlow Parallel Skeleton Framework Alexander Collins Christian Fensch Hugh Leather University of Edinburgh School of Informatics What We Did Parallel skeletons provide
Optimization Space Exploration of the FastFlow Parallel Skeleton Framework Alexander Collins Christian Fensch Hugh Leather University of Edinburgh School of Informatics What We Did Parallel skeletons provide
Accelerating sequential computer vision algorithms using commodity parallel hardware
 Accelerating sequential computer vision algorithms using commodity parallel hardware Platform Parallel Netherlands GPGPU-day, 28 June 2012 Jaap van de Loosdrecht NHL Centre of Expertise in Computer Vision
Accelerating sequential computer vision algorithms using commodity parallel hardware Platform Parallel Netherlands GPGPU-day, 28 June 2012 Jaap van de Loosdrecht NHL Centre of Expertise in Computer Vision
Skel: A Streaming Process-based Skeleton Library for Erlang (Early Draft!)
") Skel: A Streaming Process-based Skeleton Library for Erlang (Early Draft!) Archibald Elliott 1, Christopher Brown 1, Marco Danelutto 2, and Kevin Hammond 1 1 School of Computer Science, University of St
Skel: A Streaming Process-based Skeleton Library for Erlang (Early Draft!) Archibald Elliott 1, Christopher Brown 1, Marco Danelutto 2, and Kevin Hammond 1 1 School of Computer Science, University of St
Guillimin HPC Users Meeting January 13, 2017
 Guillimin HPC Users Meeting January 13, 2017 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Please be kind to your fellow user meeting attendees Limit
Guillimin HPC Users Meeting January 13, 2017 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Please be kind to your fellow user meeting attendees Limit
AperTO - Archivio Istituzionale Open Access dell'università di Torino
 AperTO - Archivio Istituzionale Open Access dell'università di Torino An hybrid linear algebra framework for engineering This is the author's manuscript Original Citation: An hybrid linear algebra framework
AperTO - Archivio Istituzionale Open Access dell'università di Torino An hybrid linear algebra framework for engineering This is the author's manuscript Original Citation: An hybrid linear algebra framework
Image Processing. Filtering. Slide 1
 Image Processing Filtering Slide 1 Preliminary Image generation Original Noise Image restoration Result Slide 2 Preliminary Classic application: denoising However: Denoising is much more than a simple
Image Processing Filtering Slide 1 Preliminary Image generation Original Noise Image restoration Result Slide 2 Preliminary Classic application: denoising However: Denoising is much more than a simple
Communicating Process Architectures in Light of Parallel Design Patterns and Skeletons
 Communicating Process Architectures in Light of Parallel Design Patterns and Skeletons Dr Kevin Chalmers School of Computing Edinburgh Napier University Edinburgh k.chalmers@napier.ac.uk Overview ˆ I started
Communicating Process Architectures in Light of Parallel Design Patterns and Skeletons Dr Kevin Chalmers School of Computing Edinburgh Napier University Edinburgh k.chalmers@napier.ac.uk Overview ˆ I started
RESEARCH ARTICLE. Performance Analysis and Structured Parallelization of the STAP Computational Kernel on Multi-core Architectures
 The International Journal of Parallel, Emergent and Distributed Systems Vol. 00, No. 00, Month 2011, 1 2 RESEARCH ARTICLE Performance Analysis and Structured Parallelization of the STAP Computational Kernel
The International Journal of Parallel, Emergent and Distributed Systems Vol. 00, No. 00, Month 2011, 1 2 RESEARCH ARTICLE Performance Analysis and Structured Parallelization of the STAP Computational Kernel
GCM Non-Functional Features Advances (Palma Mix)
") Grid programming with components: an advanced COMPonent platform for an effective invisible grid GCM Non-Functional Features Advances (Palma Mix) Marco Aldinucci & M. Danelutto, S. Campa, D. L a f o r
Grid programming with components: an advanced COMPonent platform for an effective invisible grid GCM Non-Functional Features Advances (Palma Mix) Marco Aldinucci & M. Danelutto, S. Campa, D. L a f o r
Using (Suricata over) PF_RING for NIC-Independent Acceleration
 PF_RING for NIC-Independent Acceleration") Using (Suricata over) PF_RING for NIC-Independent Acceleration Luca Deri Alfredo Cardigliano Outlook About ntop. Introduction to PF_RING. Integrating PF_RING with
Using (Suricata over) PF_RING for NIC-Independent Acceleration Luca Deri Alfredo Cardigliano Outlook About ntop. Introduction to PF_RING. Integrating PF_RING with
SNAP: Stateful Network-Wide Abstractions for Packet Processing. Collaboration of Princeton University & Pomona College
 SNAP: Stateful Network-Wide Abstractions for Packet Processing Collaboration of Princeton University & Pomona College Brief Overview: Motivation Introduction to SNAP/Example(s) of SNAP SNAP Syntax Overview
SNAP: Stateful Network-Wide Abstractions for Packet Processing Collaboration of Princeton University & Pomona College Brief Overview: Motivation Introduction to SNAP/Example(s) of SNAP SNAP Syntax Overview
19/05/2010 SPD 09/10 - M. Coppola - The ASSIST Environment 28 19/05/2010 SPD 09/10 - M. Coppola - The ASSIST Environment 29. <?xml version="1.0"?
 Overall picture Core technologies Deployment, Heterogeneity and Dynamic Adaptation ALDL Application description GEA based deployment Support of Heterogeneity Support for Dynamic Adaptive behaviour Reconfiguration
Overall picture Core technologies Deployment, Heterogeneity and Dynamic Adaptation ALDL Application description GEA based deployment Support of Heterogeneity Support for Dynamic Adaptive behaviour Reconfiguration
The MPI Message-passing Standard Lab Time Hands-on. SPD Course Massimo Coppola
 The MPI Message-passing Standard Lab Time Hands-on SPD Course 2016-2017 Massimo Coppola Remember! Simplest programs do not need much beyond Send and Recv, still... Each process lives in a separate memory
The MPI Message-passing Standard Lab Time Hands-on SPD Course 2016-2017 Massimo Coppola Remember! Simplest programs do not need much beyond Send and Recv, still... Each process lives in a separate memory
The ASSIST Programming Environment
 The ASSIST Programming Environment Massimo Coppola 06/07/2007 - Pisa, Dipartimento di Informatica Within the Ph.D. course Advanced Parallel Programming by M. Danelutto With contributions from the whole
The ASSIST Programming Environment Massimo Coppola 06/07/2007 - Pisa, Dipartimento di Informatica Within the Ph.D. course Advanced Parallel Programming by M. Danelutto With contributions from the whole
Using peer to peer. Marco Danelutto Dept. Computer Science University of Pisa
 Using peer to peer Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year 2009-2010 Rationale Two common paradigms
Using peer to peer Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year 2009-2010 Rationale Two common paradigms
Parallelism paradigms
 Parallelism paradigms Intro part of course in Parallel Image Analysis Elias Rudberg elias.rudberg@it.uu.se March 23, 2011 Outline 1 Parallelization strategies 2 Shared memory 3 Distributed memory 4 Parallelization
Parallelism paradigms Intro part of course in Parallel Image Analysis Elias Rudberg elias.rudberg@it.uu.se March 23, 2011 Outline 1 Parallelization strategies 2 Shared memory 3 Distributed memory 4 Parallelization
State Access Patterns in Stream Parallel Computations
 State Access Patterns in Stream Parallel Computations M. Danelutto, P. Kilpatrick, G. Mencagli M. Torquati Dept. of Computer Science Univ. of Pisa Dept. of Computer Science Queen s Univ. Belfast Abstract
State Access Patterns in Stream Parallel Computations M. Danelutto, P. Kilpatrick, G. Mencagli M. Torquati Dept. of Computer Science Univ. of Pisa Dept. of Computer Science Queen s Univ. Belfast Abstract
Exploiting High-Performance Heterogeneous Hardware for Java Programs using Graal
 Exploiting High-Performance Heterogeneous Hardware for Java Programs using Graal James Clarkson ±, Juan Fumero, Michalis Papadimitriou, Foivos S. Zakkak, Christos Kotselidis and Mikel Luján ± Dyson, The
Exploiting High-Performance Heterogeneous Hardware for Java Programs using Graal James Clarkson ±, Juan Fumero, Michalis Papadimitriou, Foivos S. Zakkak, Christos Kotselidis and Mikel Luján ± Dyson, The
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
High-Performance Data Loading and Augmentation for Deep Neural Network Training
 High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
Investigation of System Timing Concerns in Embedded Systems: Tool-based Analysis of AADL Models
 Investigation of System Timing Concerns in Embedded Systems: Tool-based Analysis of AADL Models Peter Feiler Software Engineering Institute phf@sei.cmu.edu 412-268-7790 2004 by Carnegie Mellon University
Investigation of System Timing Concerns in Embedded Systems: Tool-based Analysis of AADL Models Peter Feiler Software Engineering Institute phf@sei.cmu.edu 412-268-7790 2004 by Carnegie Mellon University
Background: I/O Concurrency
 Background: I/O Concurrency Brad Karp UCL Computer Science CS GZ03 / M030 5 th October 2011 Outline Worse Is Better and Distributed Systems Problem: Naïve single-process server leaves system resources
Background: I/O Concurrency Brad Karp UCL Computer Science CS GZ03 / M030 5 th October 2011 Outline Worse Is Better and Distributed Systems Problem: Naïve single-process server leaves system resources
Native Offload of Haskell Repa Programs to Integrated GPUs
 Native Offload of Haskell Repa Programs to Integrated GPUs Hai (Paul) Liu with Laurence Day, Neal Glew, Todd Anderson, Rajkishore Barik Intel Labs. September 28, 2016 General purpose computing on integrated
Native Offload of Haskell Repa Programs to Integrated GPUs Hai (Paul) Liu with Laurence Day, Neal Glew, Todd Anderson, Rajkishore Barik Intel Labs. September 28, 2016 General purpose computing on integrated
European Network on New Sensing Technologies for Air Pollution Control and Environmental Sustainability - EuNetAir COST Action TD1105
 European Network on New Sensing Technologies for Air Pollution Control and Environmental Sustainability - EuNetAir COST Action TD1105 A Holistic Approach in the Development and Deployment of WSN-based
European Network on New Sensing Technologies for Air Pollution Control and Environmental Sustainability - EuNetAir COST Action TD1105 A Holistic Approach in the Development and Deployment of WSN-based
Hierarchical DAG Scheduling for Hybrid Distributed Systems
 June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
Expressing Heterogeneous Parallelism in C++ with Intel Threading Building Blocks A full-day tutorial proposal for SC17
 Expressing Heterogeneous Parallelism in C++ with Intel Threading Building Blocks A full-day tutorial proposal for SC17 Tutorial Instructors [James Reinders, Michael J. Voss, Pablo Reble, Rafael Asenjo]
Expressing Heterogeneous Parallelism in C++ with Intel Threading Building Blocks A full-day tutorial proposal for SC17 Tutorial Instructors [James Reinders, Michael J. Voss, Pablo Reble, Rafael Asenjo]
Master Program (Laurea Magistrale) in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.
 in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.") Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Design patterns percolating to parallel programming framework implementation
 International Journal of Parallel Programming - ISSN 0885-7458 DOI: 10.1007/s10766-013-0273-6 The final publication is available at link.springer.com Design patterns percolating to parallel programming
International Journal of Parallel Programming - ISSN 0885-7458 DOI: 10.1007/s10766-013-0273-6 The final publication is available at link.springer.com Design patterns percolating to parallel programming
Distributed Dense Linear Algebra on Heterogeneous Architectures. George Bosilca
 Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO
 F. Bodin, CTO") How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
Parallel Programming Patterns Overview CS 472 Concurrent & Parallel Programming University of Evansville
 Parallel Programming Patterns Overview CS 472 Concurrent & Parallel Programming of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information
Parallel Programming Patterns Overview CS 472 Concurrent & Parallel Programming of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information
FastFlow: high-level programming patterns with non-blocking lock-free run-time support
 UPMARC Workshop on Task-Based Parallel Programming Uppsala 2012 September 28, 2012 Uppsala, Sweden FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci
UPMARC Workshop on Task-Based Parallel Programming Uppsala 2012 September 28, 2012 Uppsala, Sweden FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci
Distributed systems: paradigms and models Motivations
 Distributed systems: paradigms and models Motivations Prof. Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year
Distributed systems: paradigms and models Motivations Prof. Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
Copperhead: Data Parallel Python Bryan Catanzaro, NVIDIA Research 1/19
 Copperhead: Data Parallel Python Bryan Catanzaro, NVIDIA Research 1/19 Motivation Not everyone wants to write C++ or Fortran How can we broaden the use of parallel computing? All of us want higher programmer
Copperhead: Data Parallel Python Bryan Catanzaro, NVIDIA Research 1/19 Motivation Not everyone wants to write C++ or Fortran How can we broaden the use of parallel computing? All of us want higher programmer
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive. Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center
 Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Task based parallelization of recursive linear algebra routines using Kaapi
 Task based parallelization of recursive linear algebra routines using Kaapi Clément PERNET joint work with Jean-Guillaume DUMAS and Ziad SULTAN Université Grenoble Alpes, LJK-CASYS January 20, 2017 Journée
Task based parallelization of recursive linear algebra routines using Kaapi Clément PERNET joint work with Jean-Guillaume DUMAS and Ziad SULTAN Université Grenoble Alpes, LJK-CASYS January 20, 2017 Journée
Metadata for Component Optimisation
 Metadata for Component Optimisation Olav Beckmann, Paul H J Kelly and John Darlington ob3@doc.ic.ac.uk Department of Computing, Imperial College London 80 Queen s Gate, London SW7 2BZ United Kingdom Metadata
Metadata for Component Optimisation Olav Beckmann, Paul H J Kelly and John Darlington ob3@doc.ic.ac.uk Department of Computing, Imperial College London 80 Queen s Gate, London SW7 2BZ United Kingdom Metadata
libcppa Now: High-Level Distributed Programming Without Sacrificing Performance
 libcppa Now: High-Level Distributed Programming Without Sacrificing Performance Matthias Vallentin matthias@bro.org University of California, Berkeley C ++ Now May 14, 2013 Outline 1. Example Application:
libcppa Now: High-Level Distributed Programming Without Sacrificing Performance Matthias Vallentin matthias@bro.org University of California, Berkeley C ++ Now May 14, 2013 Outline 1. Example Application:
Computing on GPUs. Prof. Dr. Uli Göhner. DYNAmore GmbH. Stuttgart, Germany
 Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
arxiv: v1 [cs.dc] 16 Jun 2016
![arxiv: v1 [cs.dc] 16 Jun 2016](/thumbs/82/87028555.jpg "arxiv: v1 [cs.dc] 16 Jun 2016") Proc. of the 9th Intl Symposium on High-Level Parallel Programming and Applications (HLPP) July 4-5 2016, Muenster, Germany A Comparison of Big Data Frameworks on a Layered Dataflow Model Claudia Misale
Proc. of the 9th Intl Symposium on High-Level Parallel Programming and Applications (HLPP) July 4-5 2016, Muenster, Germany A Comparison of Big Data Frameworks on a Layered Dataflow Model Claudia Misale
Transactum Business Process Manager with High-Performance Elastic Scaling. November 2011 Ivan Klianev
 Transactum Business Process Manager with High-Performance Elastic Scaling November 2011 Ivan Klianev Transactum BPM serves three primary objectives: To make it possible for developers unfamiliar with distributed
Transactum Business Process Manager with High-Performance Elastic Scaling November 2011 Ivan Klianev Transactum BPM serves three primary objectives: To make it possible for developers unfamiliar with distributed
M. Danelutto. University of Pisa. IFIP 10.3 Nov 1, 2003
 M. Danelutto University of Pisa IFIP 10.3 Nov 1, 2003 GRID: current status A RISC grid core Current experiments Conclusions M. Danelutto IFIP WG10.3 -- Nov.1st 2003 2 GRID: current status A RISC grid core
M. Danelutto University of Pisa IFIP 10.3 Nov 1, 2003 GRID: current status A RISC grid core Current experiments Conclusions M. Danelutto IFIP WG10.3 -- Nov.1st 2003 2 GRID: current status A RISC grid core
Thinking Outside of the Tera-Scale Box. Piotr Luszczek
 Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Overview: Emerging Parallel Programming Models
 Overview: Emerging Parallel Programming Models the partitioned global address space paradigm the HPCS initiative; basic idea of PGAS the Chapel language: design principles, task and data parallelism, sum
Overview: Emerging Parallel Programming Models the partitioned global address space paradigm the HPCS initiative; basic idea of PGAS the Chapel language: design principles, task and data parallelism, sum
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
Design Pattern. CMPSC 487 Lecture 10 Topics: Design Patterns: Elements of Reusable Object-Oriented Software (Gamma, et al.)
") Design Pattern CMPSC 487 Lecture 10 Topics: Design Patterns: Elements of Reusable Object-Oriented Software (Gamma, et al.) A. Design Pattern Design patterns represent the best practices used by experienced
Design Pattern CMPSC 487 Lecture 10 Topics: Design Patterns: Elements of Reusable Object-Oriented Software (Gamma, et al.) A. Design Pattern Design patterns represent the best practices used by experienced
Implementing Modern Short Read DNA Alignment Algorithms in CUDA. Jonathan Cohen Senior Manager, CUDA Libraries and Algorithms
 Implementing Modern Short Read DNA Alignment Algorithms in CUDA Jonathan Cohen Senior Manager, CUDA Libraries and Algorithms Next-Gen DNA Sequencing In 4 slides DNA Sample Replication C A T G Sensing Circuitry
Implementing Modern Short Read DNA Alignment Algorithms in CUDA Jonathan Cohen Senior Manager, CUDA Libraries and Algorithms Next-Gen DNA Sequencing In 4 slides DNA Sample Replication C A T G Sensing Circuitry
High-level parallel programming: (few) ideas for challenges in formal methods
 ideas for challenges in formal methods") COST Action IC701 Limerick - Republic of Ireland 21st June 2011 High-level parallel programming: (few) ideas for challenges in formal methods Marco Aldinucci Computer Science Dept. - University of Torino
COST Action IC701 Limerick - Republic of Ireland 21st June 2011 High-level parallel programming: (few) ideas for challenges in formal methods Marco Aldinucci Computer Science Dept. - University of Torino
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Pattern-Based Analysis of an Embedded Real-Time System Architecture
 Pattern-Based Analysis of an Embedded Real-Time System Architecture Peter Feiler Software Engineering Institute phf@sei.cmu.edu 412-268-7790 Outline Introduction to SAE AADL Standard The case study Towards
Pattern-Based Analysis of an Embedded Real-Time System Architecture Peter Feiler Software Engineering Institute phf@sei.cmu.edu 412-268-7790 Outline Introduction to SAE AADL Standard The case study Towards
FastFlow: high-level programming patterns with non-blocking lock-free run-time support
 International Summer School in Parallel Patterns!! June 10, 2014! Dublin, Ireland FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci! Parallel programming
International Summer School in Parallel Patterns!! June 10, 2014! Dublin, Ireland FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci! Parallel programming
Consistent Rollback Protocols for Autonomic ASSISTANT Applications
 Consistent Rollback Protocols for Autonomic ASSISTANT Applications Carlo Bertolli 1, Gabriele Mencagli 2, and Marco Vanneschi 2 1 Department of Computing, Imperial College London 180 Queens Gate, London,
Consistent Rollback Protocols for Autonomic ASSISTANT Applications Carlo Bertolli 1, Gabriele Mencagli 2, and Marco Vanneschi 2 1 Department of Computing, Imperial College London 180 Queens Gate, London,
Lift: a Functional Approach to Generating High Performance GPU Code using Rewrite Rules
 Lift: a Functional Approach to Generating High Performance GPU Code using Rewrite Rules Toomas Remmelg Michel Steuwer Christophe Dubach The 4th South of England Regional Programming Language Seminar 27th
Lift: a Functional Approach to Generating High Performance GPU Code using Rewrite Rules Toomas Remmelg Michel Steuwer Christophe Dubach The 4th South of England Regional Programming Language Seminar 27th
Parallel stochastic simulators in systems biology: the evolution of the species
 FACOLTÀ Università degli Studi di Torino DI SCIENZE MATEMATICHE, FISICHE E NATURALI Corso di Laurea in Informatica Tesi di Laurea Magistrale Parallel stochastic simulators in systems biology: the evolution
FACOLTÀ Università degli Studi di Torino DI SCIENZE MATEMATICHE, FISICHE E NATURALI Corso di Laurea in Informatica Tesi di Laurea Magistrale Parallel stochastic simulators in systems biology: the evolution
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento