Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
|
|
|
- Marian Chase
- 6 years ago
- Views:
Transcription
1 Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
2 Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated would severely limit dynamical scheduling Loop unrolling might help somewhat
3 Solution 2: Delayed Branches If the branch hardware has been moved to the ID stage, then we can eliminate all branch stalls with delayed branches which are defined as always executing the next sequential instruction after the branch instruction the branch takes effect after that next instruction MIPS compiler moves an instruction to immediately after the branch that is not affected by the branch (a safe instruction) thereby hiding the branch delay With deeper pipelines, the branch delay grows requiring more than one delay slot Delayed branches have lost popularity compared to more expensive but more flexible (dynamic) hardware branch prediction Growth in available transistors has made hardware branch prediction relatively cheaper
4 Scheduling Branch Delay Slots A. From before branch B. From branch target C. From fall through add $1,$2,$3 if $2=0 then delay slot sub $4,$5,$6 add $1,$2,$3 if $1=0 then delay slot A is the best choice, fills delay slot and reduces IC In B and C, the sub instruction may need to be copied, increasing IC In B and C, must be okay to execute sub when branch fails add $1,$2,$3 if $1=0 then delay slot sub $4,$5,$6 becomes becomes becomes add $1,$2,$3 if $2=0 then if $1=0 then add $1,$2,$3 add $1,$2,$3 if $1=0 then sub $4,$5,$6 sub $4,$5,$6
5 Solution 3: Static Prediction Branch condition prediction only makes sense if delay for calculation condition is longer than that of target address Predict branch is always taken or always not taken Compiler can help by favoring each case Need mechanism to back off (flush pipeline when prediction is wrong) Even better solution is via profiling Run program to get branch statistics Explicitly specify direction in instruction Branches are typically bimodal
6 Dynamic Branch Prediction Change the outcome of prediction in the runtime Basic 1 and 2-bit predictors: For each branch: Predict taken or not taken If the prediction is wrong two consecutive times, change prediction Correlating or two-level predictor: Multiple 2-bit predictors for each branch One for each possible combination of outcomes of preceding n branches Local predictor: Multiple 2-bit predictors for each branch One for each possible combination of outcomes for the last n occurrences of this branch Tournament predictor: Combine correlating predictor with local predictor
7 Basic Dynamic Branch Prediction Branch History Table (BHT): Lower bits of PC address index table of 1-bit values Says whether or not branch taken last time ( T-Taken, N ) No full address check (saves HW, but may be wrong) Problem: in a loop, 1-bit BHT will cause 2 mispredictions: End of loop case, when it exits instead of looping as before First time through loop on next time through code, when it predicts exit instead of looping E.g., only 80% accuracy if 10 iterations per loop on average
8 2-bit Branch Prediction - Scheme 1 Better Solution: 2-bit scheme: Predict Taken Predict Not Taken T N T* T*N N*T T T N T N N* Predict Taken Predict Not Taken N (Jim Smith, 1981)
9 Branch History Table (BHT) Branch PC Predictor 0 Predictor 1 T N T T N T T* T*N N*T N N* N Predictor 127 BHT is a table of Predictors 2-bit, saturating counters indexed by PC address of Branch In Fetch phase of branch: Predictor from BHT used to make prediction When branch completes: Update corresponding Predictor
10 2-bit Branch Prediction - Scheme 2 Another Solution: 2-bit scheme where change prediction (in either direction) only if get misprediction twice : Predict Taken Predict Not Taken T T N T* T*N N*T T N T N* N N Predict Taken Predict Not Taken Lee & A. Smith, IEEE Computer, Jan 1984 Both schemes achieve 80-95% accuracy with only a small difference in behavior
11 Branch Correlations B1: if (x)... B2: if (y)... z=x&&y B3: if (z)... B3 can be predicted with 100% accuracy based on the outcomes of B1 and B2 Basic scheme cannot use this information 11
12 Correlating or Two-Level Branches Idea: taken/not taken of recently executed branches is related to behavior of present branch (as well as the history of that branch behavior) Then behavior of recent branches selects between, say, 4 predictions of next branch, updating just that prediction (2,2) predictor: 2-bit global, 2-bit local Branch address (4 bits) 2-bits per branch local predictors 2-bit recent global branch history (01 = not taken then taken) Prediction
13 gcc eqntott Frequency of Mispredictions Accuracy of Different Schemes 20% 18% 16% 14% 12% 10% 4096 Entries 2-bit BHT Unlimited Entries 2-bit BHT 1024 Entries (2,2) BHT 12% 11% 18% 8% 6% 4% 5% 6% 6% 4% 6% 5% 2% 0% 1% 0% 1% 4,096 entries: 2-bits per entry Unlimited entries: 2-bits/entry 1,024 entries (2,2)
14 Global vs Local History Predictors Global: BHR: A shift register for global history -Shift in latest result in each cycle - provides global context Local: BHT: keeps track of local history - select entry based on PC bits & shift in latest result in each cycle
15 Tournament Predictors Motivation for correlating branch predictors: 2-bit local predictor failed on important branches; by adding global information, performance improved Tournament predictors: use two predictors, 1 based on global information and 1 based on local information, and combine with a selector Hopes to select right predictor for right branch (or right context of branch)
16 Tournament Predictor in Alpha K 2-bit counters to choose from among a global predictor and a local predictor Global predictor also has 4K entries and is indexed by the history of the last 12 branches; each entry in the global predictor is a standard 2-bit predictor 12-bit pattern: ith bit is 0 => ith prior branch not taken; ith bit is 1 => ith prior branch taken; 00,10,11 00,01,11 Use 1 Use Use 1 Use ,11 00, K 2 bits
17 Tournament Predictor in Alpha Local predictor consists of a 2-level predictor: Top level a local history table consisting of bit entries; each 10-bit entry corresponds to the most recent 10 branch outcomes for the entry. 10-bit history allows patterns 10 branches to be discovered and predicted Next level Selected entry from the local history table is used to index a table of 1K entries consisting a 3-bit saturating counters, which provide the local prediction Total size: 4K*2 + 4K*2 + 1K*10 + 1K*3 = 29K bits! (~180K transistors) 1K 10 bits 1K 3 bits
18 % of predictions from local predictor in Tournament Prediction Scheme 0% 20% 40% 60% 80% 100% nasa7 matrix300 tomcatv doduc spice fpppp gcc espresso eqntott li 37% 55% 76% 72% 63% 69% 98% 100% 94% 90%
19 Accuracy of Branch Prediction 99% tomcatv 99% 100% doduc 84% 95% 97% fpppp li 86% 82% 88% 77% 98% 98% Profile-based 2-bit counter Tournament espresso 86% 82% 96% gcc 70% 88% 94% 0% 20% 40% 60% 80% 100% Profile: branch profile from last execution (static in that is encoded in instruction, but profile) fig 3.40
20 Conditional branch misprediction rate Accuracy v. Size (SPEC89) 10% 9% 8% 7% Local - 2 bit counters 6% 5% 4% 3% 2% Correlating - (2,2) scheme Tournament 1% 0% Total predictor size (Kbits)
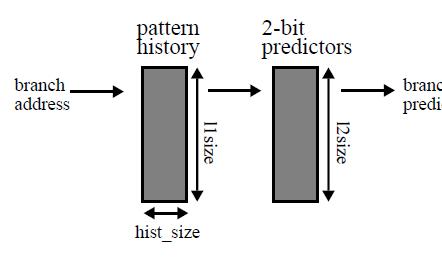
21 Lab 4
22 Need Address at the Same Time as Prediction Branch Target Buffer (BTB): Address of branch used as index to get prediction AND branch address (if taken) Note: must check for branch match now, since can t use wrong branch address PC of instruction FETCH Branch PC Predicted PC No: branch not predicted; proceed normally (PC+4) =? Yes: instruction is branch; use predicted PC as next PC (if predict Taken) Prediction state bits
23 Branch Target Cache Branch Target cache - Only predicted taken branches Cache - Content Addressable Memory (CAM) or Associative Memory (see figure) Use a big Branch History Table & a small Branch Target Cache Branch PC Predicted PC PC No: not found =? Prediction state Yes: predicted taken bits (optional) branch found
24 Steps with Branch target Buffer Send PC to memory and branch-target buffer for the 5-stage MIPS IF No Place PC+4 in PC Entry found in branchtarget buffer? Yes Place predicted target address in PC ID No Is instruction a taken branch? Yes No Taken Branch? Yes Normal instruction execution EX Enter branch instruction address and next PC into branch-target buffer. Kill fetched instruction. Restart fetch at other target. Mispredicted branch, kill fetched instruction; restart fetch at other target; delete entry from target buffer Branch correctly predicted; continue execution with no stalls. + Prediction history table should be updated for all three cases
25 Branch Prediction for Function Returns Problem: Hard to predict target for returns (15% of all branches) because of indirection (60% accuracy) In most languages, function calls are fully nested If you call A() B() C() D() Your return targets are PCc PCb PCa PCmain Solution: Return Address Stack (RAS) A FILO structure for capturing function return addresses Operation: push on function call, pop on function return 16-entry RAS is enough for the typical depth call trees RAS mispredictions: Overflows Long jumps
26 Return Address Stack 16-entry few percent of mispredictions
27 Branch Folding Supply actual instruction instead of instruction address or 0 delay branch (or branch folding)
28 Multiple Issue To achieve CPI < 1, need to complete multiple instructions per clock Solutions: Statically scheduled superscalar processors VLIW (very long instruction word) processors dynamically scheduled superscalar processors
29 Multiple Issue
30 VLIW Processors Package multiple operations into one instruction Example VLIW processor: One integer instruction (or branch) Two independent floating-point operations Two independent memory references Must be enough parallelism in code to fill the available slots

31 Example for VLIW
32 VLIW Processors Disadvantages: Statically finding parallelism Code size No hazard detection hardware Binary code compatibility
33 Dynamic Scheduling, Multiple Issue, and Speculation Modern microarchitectures: Dynamic scheduling + multiple issue + speculation Two approaches: Assign reservation stations and update pipeline control table in half clock cycles Only supports 2 instructions/clock Design logic to handle any possible dependencies between the instructions Hybrid approaches Issue logic can become bottleneck
34 Multiple Issue Limit the number of instructions of a given class that can be issued in a bundle I.e. on FP, one integer, one load, one store Examine all the dependencies among the instructions in the bundle If dependencies exist in bundle, encode them in reservation stations Also need multiple completion/commit
35 Example Loop: LD R2,0(R1) ;R2=array element DADDIU R2,R2,#1 ;increment R2 SD R2,0(R1) ;store result DADDIU R1,R1,#8 ;increment pointer BNE R2,R3,LOOP ;branch if not last element
36 Example (No Speculation) Instruction after branch can be issued but on hold until branch is resolved For simplicity branches are issued in separate bundles
37 Example (with Speculation)
38 Limitations of ILP (perfect processor) - Perfect cache - Perfect branch and jump prediction - Infinite register renaming - Perfect memory address alias analysis

39 Limitations of ILP (more realistic but still ambitious) - 64 int + 64 fp registers for renaming - Tournament predictor - Perfect memory address alias analysis
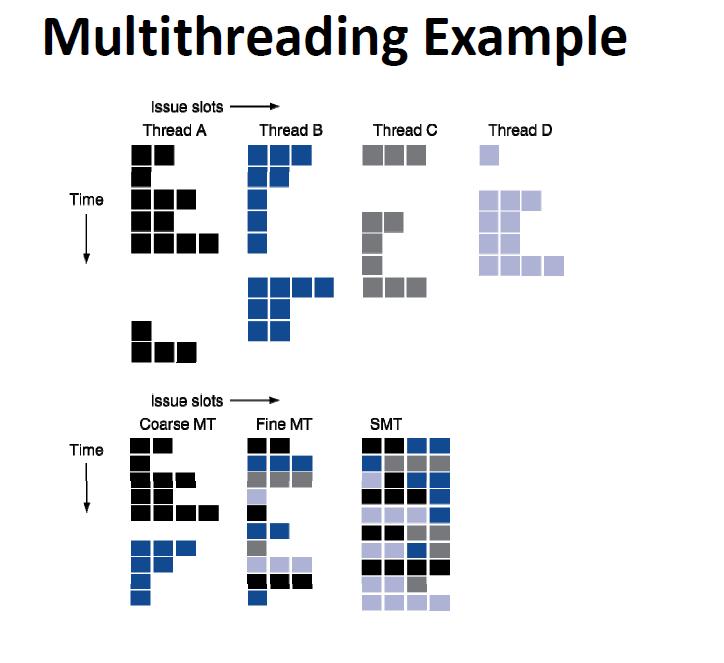
40 Motivation for Multithreaded Architectures Processors not executing code at their hardware potential late 70 s: performance lost to memory latency 90 s: performance not in line with the increasingly complex parallel hardware instruction issue bandwidth is increasing number of functional units is increasing instructions can execute out-of-order execution & complete in-order still, processor utilization was decreasing & instruction throughput not increasing in proportion to the issue width Major cause is the lack of instruction-level parallelism in a single executing thread Therefore the solution has to be more general than building a smarter cache or a more accurate branch predictor
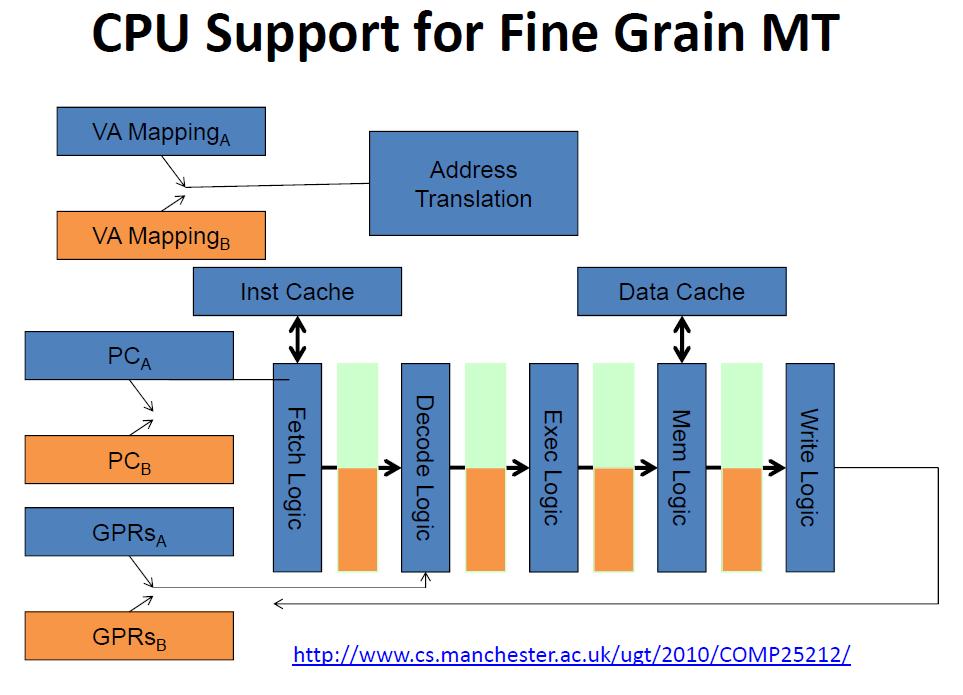
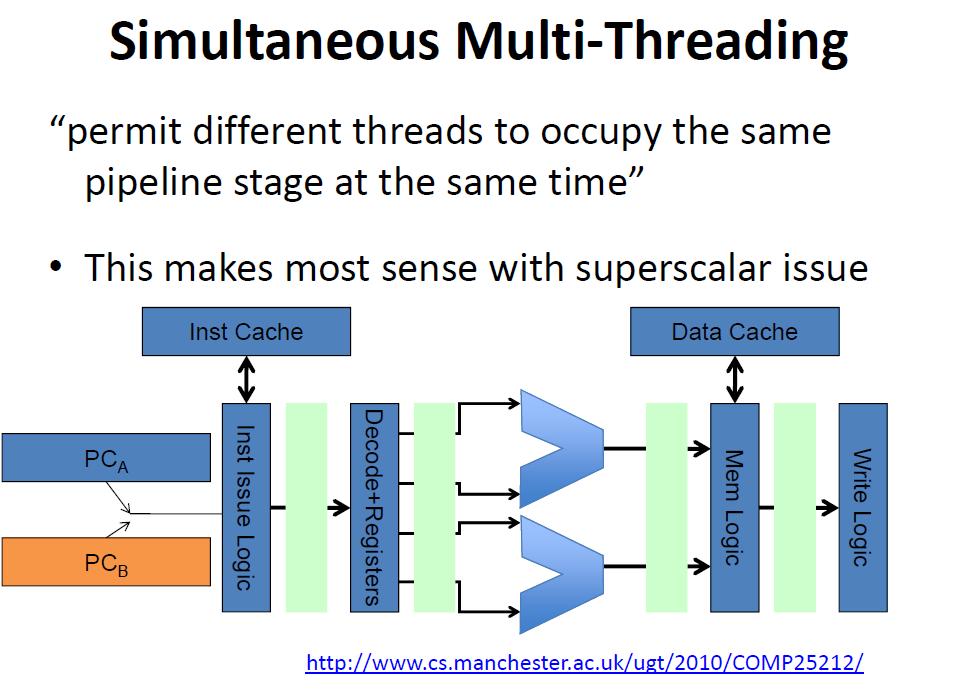
41 Multithreaded Processors Multithreaded processors can increase the pool of independent instructions & consequently address multiple causes of processor stalling holds processor state for more than one thread of execution registers PC each thread s state is a hardware context execute the instruction stream from multiple threads without software context switching utilize thread-level parallelism (TLP) to compensate for a lack in ILP 3 styles: Coarse grain, fine grain, and simultaneous multithreading
42

43 Switch CPU threads on every cycle with minimal overhead Multithreading helps hiding stalls

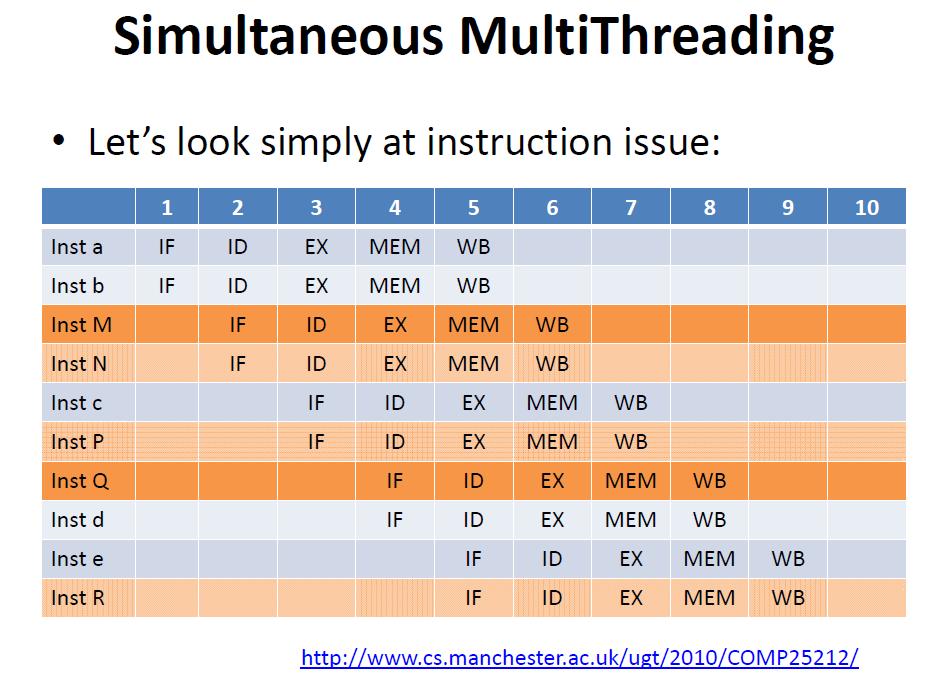
44 Inst a IF ID EX M-MEM WB Inst b IF ID EX MEM WB Inst c IF ID EX MEM WB Inst d IF ID EX MEM Inst M IF ID EXE Inst N IF ID
45
46
47 Multithreading Traditional multithreaded processors hardware switch to a different context to avoid processor stalls 1. coarse-grain multithreading switch on a long-latency operation (e.g., L2 cache miss) another thread executes while the miss is handled modest increase in instruction throughput with potentially no slowdown to the thread with the miss doesn t hide latency of short-latency operations doesn t add much to an already long stall need to fill the pipeline on a switch no switch if no long-latency operations HEP, IBM RS64 III 2. fine-grain multithreading can switch to a different thread each cycle (usually round robin) hides latencies of all kinds larger increase in instruction throughput but slows down the execution of each thread Cray (Tera) MTA, Sun Niagara 3. simultaneous multithreading (SMT) issues multiple instructions from multiple threads each cycle no hardware context switching huge boost in instruction throughput with less degradation to individual threads
48
49 Exceptions Exceptions are events that are difficult or impossible to manage in hardware alone Exceptions are usually handled by jumping into a service (software) routine Examples: I/O device request, page fault, divide by zero, memory protection violation (seg fault), hardware failure, etc.
50 Once an Exception Occurs, How Does the Processor Proceed? Non-pipelined: don t fetch from PC; save state; fetch from interrupt vector table Pipelined: depends on the exception Precise Interrupt: Must stop all instruction after the exception (squash) Save state after last instruction before exception completes (PC, regs) Fetch from interrupt vector table Imprecise interrupts for out-of-order processors Two modes of operations Precise in speculative out of order processor exceptions are not recognize until instruction is ready to commit
51 Overview of Design
52 Acknowledgements Some of the slides contain material developed and copyrighted by I. Watson (U Manchester), by Csaba Moritz (U Amherst) and D. Culler (UCB) and instructor material for the textbook 52
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Instruction Fetch and Branch Prediction. CprE 581 Computer Systems Architecture Readings: Textbook (4 th ed 2.3, 2.9); (5 th ed 3.
; (5 th ed 3.") Instruction Fetch and Branch Prediction CprE 581 Computer Systems Architecture Readings: Textbook (4 th ed 2.3, 2.9); (5 th ed 3.3) 1 Frontend and Backend Feedback: - Prediction correct or not, update
Instruction Fetch and Branch Prediction CprE 581 Computer Systems Architecture Readings: Textbook (4 th ed 2.3, 2.9); (5 th ed 3.3) 1 Frontend and Backend Feedback: - Prediction correct or not, update
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Dynamic Control Hazard Avoidance
 Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
COSC 6385 Computer Architecture. Instruction Level Parallelism
 COSC 6385 Computer Architecture Instruction Level Parallelism Spring 2013 Instruction Level Parallelism Pipelining allows for overlapping the execution of instructions Limitations on the (pipelined) execution
COSC 6385 Computer Architecture Instruction Level Parallelism Spring 2013 Instruction Level Parallelism Pipelining allows for overlapping the execution of instructions Limitations on the (pipelined) execution
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
As the amount of ILP to exploit grows, control dependences rapidly become the limiting factor.
 Hiroaki Kobayashi // As the amount of ILP to exploit grows, control dependences rapidly become the limiting factor. Branches will arrive up to n times faster in an n-issue processor, and providing an instruction
Hiroaki Kobayashi // As the amount of ILP to exploit grows, control dependences rapidly become the limiting factor. Branches will arrive up to n times faster in an n-issue processor, and providing an instruction
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Instruction Level Parallelism (ILP)
") 1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
The Processor: Improving the performance - Control Hazards
 The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary
The Processor: Improving the performance - Control Hazards Wednesday 14 October 15 Many slides adapted from: and Design, Patterson & Hennessy 5th Edition, 2014, MK and from Prof. Mary Jane Irwin, PSU Summary
Page 1. Today s Big Idea. Lecture 18: Branch Prediction + analysis resources => ILP
 CS252 Graduate Computer Architecture Lecture 18: Branch Prediction + analysis resources => ILP April 2, 2 Prof. David E. Culler Computer Science 252 Spring 2 Today s Big Idea Reactive: past actions cause
CS252 Graduate Computer Architecture Lecture 18: Branch Prediction + analysis resources => ILP April 2, 2 Prof. David E. Culler Computer Science 252 Spring 2 Today s Big Idea Reactive: past actions cause
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
Dynamic Hardware Prediction. Basic Branch Prediction Buffers. N-bit Branch Prediction Buffers
 Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
Dynamic Hardware Prediction Importance of control dependences Branches and jumps are frequent Limiting factor as ILP increases (Amdahl s law) Schemes to attack control dependences Static Basic (stall the
Review Tomasulo. Lecture 17: ILP and Dynamic Execution #2: Branch Prediction, Multiple Issue. Tomasulo Algorithm and Branch Prediction
 CS252 Graduate Computer Architecture Lecture 17: ILP and Dynamic Execution #2: Branch Prediction, Multiple Issue March 23, 01 Prof. David A. Patterson Computer Science 252 Spring 01 Review Tomasulo Reservations
CS252 Graduate Computer Architecture Lecture 17: ILP and Dynamic Execution #2: Branch Prediction, Multiple Issue March 23, 01 Prof. David A. Patterson Computer Science 252 Spring 01 Review Tomasulo Reservations
Control Hazards. Branch Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Super Scalar. Kalyan Basu March 21,
 Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
 1 cycle per instruction I
1 cycle per instruction I Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction
 Stalls with Dynamic Branch Prediction") ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
Pipelining. Ideal speedup is number of stages in the pipeline. Do we achieve this? 2. Improve performance by increasing instruction throughput ...
 CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
CHAPTER 6 1 Pipelining Instruction class Instruction memory ister read ALU Data memory ister write Total (in ps) Load word 200 100 200 200 100 800 Store word 200 100 200 200 700 R-format 200 100 200 100
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
COSC 6385 Computer Architecture Dynamic Branch Prediction
 COSC 6385 Computer Architecture Dynamic Branch Prediction Edgar Gabriel Spring 208 Pipelining Pipelining allows for overlapping the execution of instructions Limitations on the (pipelined) execution of
COSC 6385 Computer Architecture Dynamic Branch Prediction Edgar Gabriel Spring 208 Pipelining Pipelining allows for overlapping the execution of instructions Limitations on the (pipelined) execution of
Hardware Speculation Support
 Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
Tomasulo Loop Example
 Tomasulo Loop Example Loop: LD F0 0 R1 MULTD F4 F0 F2 SD F4 0 R1 SUBI R1 R1 #8 BNEZ R1 Loop This time assume Multiply takes 4 clocks Assume 1st load takes 8 clocks, 2nd load takes 1 clock Clocks for SUBI,
Tomasulo Loop Example Loop: LD F0 0 R1 MULTD F4 F0 F2 SD F4 0 R1 SUBI R1 R1 #8 BNEZ R1 Loop This time assume Multiply takes 4 clocks Assume 1st load takes 8 clocks, 2nd load takes 1 clock Clocks for SUBI,
Announcements. ECE4750/CS4420 Computer Architecture L10: Branch Prediction. Edward Suh Computer Systems Laboratory
 ECE4750/CS4420 Computer Architecture L10: Branch Prediction Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab2 and prelim grades Back to the regular office hours 2 1 Overview
ECE4750/CS4420 Computer Architecture L10: Branch Prediction Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab2 and prelim grades Back to the regular office hours 2 1 Overview
Administrivia. CMSC 411 Computer Systems Architecture Lecture 14 Instruction Level Parallelism (cont.) Control Dependencies
 Control Dependencies") Administrivia CMSC 411 Computer Systems Architecture Lecture 14 Instruction Level Parallelism (cont.) HW #3, on memory hierarchy, due Tuesday Continue reading Chapter 3 of H&P Alan Sussman als@cs.umd.edu
Administrivia CMSC 411 Computer Systems Architecture Lecture 14 Instruction Level Parallelism (cont.) HW #3, on memory hierarchy, due Tuesday Continue reading Chapter 3 of H&P Alan Sussman als@cs.umd.edu
ECE473 Computer Architecture and Organization. Pipeline: Control Hazard
 Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CS252 S05. Outline. Dynamic Branch Prediction. Static Branch Prediction. Dynamic Branch Prediction. Dynamic Branch Prediction
 Outline CMSC Computer Systems Architecture Lecture 9 Instruction Level Parallelism (Static & Dynamic Branch ion) ILP Compiler techniques to increase ILP Loop Unrolling Static Branch ion Dynamic Branch
Outline CMSC Computer Systems Architecture Lecture 9 Instruction Level Parallelism (Static & Dynamic Branch ion) ILP Compiler techniques to increase ILP Loop Unrolling Static Branch ion Dynamic Branch
HY425 Lecture 05: Branch Prediction
 HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
Lecture 8: Compiling for ILP and Branch Prediction. Advanced pipelining and instruction level parallelism
 Lecture 8: Compiling for ILP and Branch Prediction Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 Advanced pipelining and instruction level parallelism
Lecture 8: Compiling for ILP and Branch Prediction Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 Advanced pipelining and instruction level parallelism
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Multiple Instruction Issue and Hardware Based Speculation
 Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
Instruction-Level Parallelism. Instruction Level Parallelism (ILP)
") Instruction-Level Parallelism CS448 1 Pipelining Instruction Level Parallelism (ILP) Limited form of ILP Overlapping instructions, these instructions can be evaluated in parallel (to some degree) Pipeline
Instruction-Level Parallelism CS448 1 Pipelining Instruction Level Parallelism (ILP) Limited form of ILP Overlapping instructions, these instructions can be evaluated in parallel (to some degree) Pipeline
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
Control Dependence, Branch Prediction
 Control Dependence, Branch Prediction Outline Control dependences Branch evaluation delay Branch delay slot Branch prediction Static Dynamic correlating, local, global. Control Dependences Program correctness
Control Dependence, Branch Prediction Outline Control dependences Branch evaluation delay Branch delay slot Branch prediction Static Dynamic correlating, local, global. Control Dependences Program correctness
CSE4201 Instruction Level Parallelism. Branch Prediction
 CSE4201 Instruction Level Parallelism Branch Prediction Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RIT) 1 Introduction With dynamic scheduling that
CSE4201 Instruction Level Parallelism Branch Prediction Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RIT) 1 Introduction With dynamic scheduling that
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Instruction-Level Parallelism Dynamic Branch Prediction. Reducing Branch Penalties
 Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING
 DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
DYNAMIC AND SPECULATIVE INSTRUCTION SCHEDULING Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson,
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions
 CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Complex Pipelines and Branch Prediction
 Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
TDT 4260 TDT ILP Chap 2, App. C
 TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Functional Units. Registers. The Big Picture: Where are We Now? The Five Classic Components of a Computer Processor Input Control Memory
 The Big Picture: Where are We Now? CS152 Computer Architecture and Engineering Lecture 18 The Five Classic Components of a Computer Processor Input Control Dynamic Scheduling (Cont), Speculation, and ILP
The Big Picture: Where are We Now? CS152 Computer Architecture and Engineering Lecture 18 The Five Classic Components of a Computer Processor Input Control Dynamic Scheduling (Cont), Speculation, and ILP
LIMITS OF ILP. B649 Parallel Architectures and Programming
 LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Lecture 7 Instruction Level Parallelism (5) EEC 171 Parallel Architectures John Owens UC Davis
 EEC 171 Parallel Architectures John Owens UC Davis") Lecture 7 Instruction Level Parallelism (5) EEC 171 Parallel Architectures John Owens UC Davis Credits John Owens / UC Davis 2007 2009. Thanks to many sources for slide material: Computer Organization
Lecture 7 Instruction Level Parallelism (5) EEC 171 Parallel Architectures John Owens UC Davis Credits John Owens / UC Davis 2007 2009. Thanks to many sources for slide material: Computer Organization
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar, VLIW. CPE 631 Session 19 Exploiting ILP with SW Approaches
 Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Topics. Digital Systems Architecture EECE EECE Predication, Prediction, and Speculation
 Digital Systems Architecture EECE 343-01 EECE 292-02 Predication, Prediction, and Speculation Dr. William H. Robinson February 25, 2004 http://eecs.vanderbilt.edu/courses/eece343/ Topics Aha, now I see,
Digital Systems Architecture EECE 343-01 EECE 292-02 Predication, Prediction, and Speculation Dr. William H. Robinson February 25, 2004 http://eecs.vanderbilt.edu/courses/eece343/ Topics Aha, now I see,
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction Level Parallelism. Taken from
 Instruction Level Parallelism Taken from http://www.cs.utsa.edu/~dj/cs3853/lecture5.ppt Outline ILP Compiler techniques to increase ILP Loop Unrolling Static Branch Prediction Dynamic Branch Prediction
Instruction Level Parallelism Taken from http://www.cs.utsa.edu/~dj/cs3853/lecture5.ppt Outline ILP Compiler techniques to increase ILP Loop Unrolling Static Branch Prediction Dynamic Branch Prediction
CS252 Spring 2017 Graduate Computer Architecture. Lecture 8: Advanced Out-of-Order Superscalar Designs Part II
 CS252 Spring 2017 Graduate Computer Architecture Lecture 8: Advanced Out-of-Order Superscalar Designs Part II Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time
CS252 Spring 2017 Graduate Computer Architecture Lecture 8: Advanced Out-of-Order Superscalar Designs Part II Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Branch prediction ( 3.3) Dynamic Branch Prediction
 Dynamic Branch Prediction") prediction ( 3.3) Static branch prediction (built into the architecture) The default is to assume that branches are not taken May have a design which predicts that branches are taken It is reasonable to
prediction ( 3.3) Static branch prediction (built into the architecture) The default is to assume that branches are not taken May have a design which predicts that branches are taken It is reasonable to
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
CSE 490/590 Computer Architecture Homework 2
 CSE 490/590 Computer Architecture Homework 2 1. Suppose that you have the following out-of-order datapath with 1-cycle ALU, 2-cycle Mem, 3-cycle Fadd, 5-cycle Fmul, no branch prediction, and in-order fetch
CSE 490/590 Computer Architecture Homework 2 1. Suppose that you have the following out-of-order datapath with 1-cycle ALU, 2-cycle Mem, 3-cycle Fadd, 5-cycle Fmul, no branch prediction, and in-order fetch
CMSC411 Fall 2013 Midterm 2 Solutions
 CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
Lecture 5: VLIW, Software Pipelining, and Limits to ILP. Review: Tomasulo
 Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards
Lecture 5: VLIW, Software Pipelining, and Limits to ILP Professor David A. Patterson Computer Science 252 Spring 1998 DAP.F96 1 Review: Tomasulo Prevents Register as bottleneck Avoids WAR, WAW hazards
Computer Architecture: Branch Prediction. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Branch Prediction Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 11: Branch Prediction
Computer Architecture: Branch Prediction Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 11: Branch Prediction
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Topic 14: Dealing with Branches
 Topic 14: Dealing with Branches COS / ELE 375 Computer Architecture and Organization Princeton University Fall 2015 Prof. David August 1 FLASHBACK: Pipeline Hazards Control Hazards What is the next instruction?
Topic 14: Dealing with Branches COS / ELE 375 Computer Architecture and Organization Princeton University Fall 2015 Prof. David August 1 FLASHBACK: Pipeline Hazards Control Hazards What is the next instruction?
Topic 14: Dealing with Branches
 Topic 14: Dealing with Branches COS / ELE 375 FLASHBACK: Pipeline Hazards Control Hazards What is the next instruction? Branch instructions take time to compute this. Stall, Predict, or Delay: Computer
Topic 14: Dealing with Branches COS / ELE 375 FLASHBACK: Pipeline Hazards Control Hazards What is the next instruction? Branch instructions take time to compute this. Stall, Predict, or Delay: Computer