Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA
|
|
|
- Alvin Rodgers
- 6 years ago
- Views:
Transcription



1 Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle, J. Ryan Acks.: CEA/DIF, IDRIS, GENCI, NVIDIA, Région Lorraine.


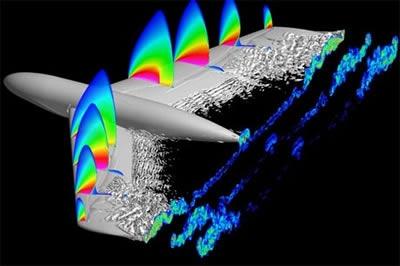
2 CFD at ONERA One simulation = thousands of CPU hours From 1
3 Why optimize? Cost of a CPU hour ~$0.05 $0.10 [Walker (2009)]. Example: 1000 cores for 1 month ~$36,000 $72,000. Dividing application runtime allows to: be more cost-efficient, get faster results, increase the problem size. 2
4 CPU-GPU differences CPU: few # of cores, vector machines, hard to manage registers, GPU: huge # of cores, vector machines, easy to manage registers (--ptxas-options=-v with nvcc). Question: Due to vector approaches, could GPU and CPU be considered as similar devices? Could the GPU be used to optimize the CPU code? 3

5 A prototype flow Yee's vortex with the full Navier-Stokes equations, 2 dimensional structured mesh, Numerical method: Space: 2nd order Discontinuous Galerkin, Time: 3rd order TVD Runge-Kutta, Boundaries: X and Y-periodic. 4
6 Test case configuration 2001x2001 mesh, 100 time-steps. CPU: Intel Xeon E5-1650v3 (6 cores), Compiler: icc 2016, -O3 -march=native GPU: K20Xm (2688 CUDA cores) Compilers: nvcc CUDA-8.0, -O3 pgc , -O3 -acc -ta=tesla:cuda8.0,nollvm,nordc 5
7 Experimental protocol Developments with the full CUDA version GPU-CUDA int tidx=threadidx.x+...; int tidy=threadidx.y+...; if(tidx<nx && tidy<ny) { } Copy 6 CPU-OpenMP #pragma omp for for(int tidy=0;tidy<ny;tidy++) { #pragma simd for(int tidx=0;tidx<nx;tidx++) { } Paste }
8 Experimental protocol Developments with the full CUDA version GPU-CUDA int tidx=threadidx.x+...; int tidy=threadidx.y+...; if(tidx<nx && tidy<ny) { } Copy 7 GPU-OpenACC #pragma acc parallel { #pragma acc loop gang independent for(int tidy=0;tidy<ny;tidy++){ #pragma acc loop vector independent for(int tidx=0;tidx<nx;tidx++) { } Paste } }
9 Step 0: Code adaptation GPU-CUDA CPU-OpenMP GPU-OpenACC Host Device transfers cudamemcpy(...) #pragma omp parallel { Time loop +CUDA kernels Time loop +omp pragmas Time loop +acc pragmas Device Host transfers cudamemcpy(...) }//end of the omp region }//end of the acc region 8 #pragma acc data\ copy(...)\ copyin(...)\ create(...) {
=#of points x number of it.")
10 Step 0: Code adaptation P(cell updt. per sec. [cus])=#of points x number of it. / time (sec) CPU: E5-1650v3 (6 cores) GPU: K20Xm 9
11 Step 1: Reduce remote accesses Load reused remote variables in registers (time locality), Use restrict keyword on pointers. global void func(double *results, int N) { int tidx=threadidx.x+...; for(int i=0;i<n;i++) { results[tidx]+=... } } 10 global void func(double * restrict results, int N) { int tidx=threadidx.x+...; double loc_result=results[tidx]; for(int i=0;i<n;i++) { loc_result+=... } results[tidx]=loc_result; }
=#of points x number of it.")
12 Step 1: Reduce remote accesses P(cell updt. per sec. [cus])=#of points x number of it. / time (sec) CPU: E5-1650v3 (6 cores) GPU: K20Xm 11
13 Step 2: Merge similar kernels Merge kernels which share similar memory patterns. 1. Compute the time-step 1. Compute the time-step 2. For s Runge-Kutta step: 2. For s Runge-Kutta step: a. Convective fluxes in X, b. Convective fluxes in Y, c. Convective integral, d. Compute local viscosity, e. Viscous fluxes in X, f. Viscous fluxes in Y, g. Viscous integral, h. Runge-Kutta propagation. 12 a. Compute local viscosity, b. Fluxes in X, c. Fluxes in Y, d. Integral+Runge-Kutta.
=#of points x number of it.")
14 Step 2: Merge similar kernels P(cell updt. per sec. [cus])=#of points x number of it. / time (sec) CPU: E5-1650v3 (6 cores) GPU: K20Xm 13
15 Step 3: Factor computations Transform divisions into multiplications, Control whether or not a loop should be unrolled. #pragma unroll for(int i=0;i<size;i++) { double val=... double c0=1/(sqrt(0.5)*val)*... double c1=1/(3*val)* } 14 double isqrt0p5=1/sqrt(0.5); double inv3=1/3; #pragma unroll //Keep it? for(int i=0;i<size;i++) { double val=... double ival=1/val; double c0=isqrt0p5*ival*... double c1=inv3*ival* }
=#of points x number of it.")
16 Step 3: Factor computations P(cell updt. per sec. [cus])=#of points x number of it. / time (sec) CPU: E5-1650v3 (6 cores) GPU: K20Xm 15
 algorithm + fixed block size. Tiling algorithm for OpenMP threads.")
17 Step 4: Align data (+tiling for CPU) GPU: Align data on the size of a warp coalescence. CPU: Tiling (Block) algorithm + fixed block size. Tiling algorithm for OpenMP threads. 16
18 Step 4: Align data (+tiling for CPU) P(cell updt. per sec. [cus])=#of points x number of it. / time (sec) CPU: E5-1650v3 (6 cores) GPU: K20Xm 17
19 Step 5: Miscellaneous OpenACC PGI 16.10: -O1 / O2 / O3 / O4 compilation registers overflow. -O0 = +82% performances (corrected in v17). CPU: Introduce MPI to support several nodes and to improve data locality on each one. #pragma simd on huge loops creates huge register pressure: not suitable for CPU vectorization. split SIMD loops into smaller loops adjust vectorization with #pragma vector always. 18
=#of points x number of it.")
20 Step 5: Miscellaneous P(cell updt. per sec. [cus])=#of points x number of it. / time (sec) CPU: E5-1650v3 (6 cores) GPU: K20Xm 19
=#of points x number of it.")
21 Running on various devices P(cell updt. per sec. [cus])=#of points x number of it. / time (sec) { Xeon Phi 20 *TDP evaluated from constructor's documentations
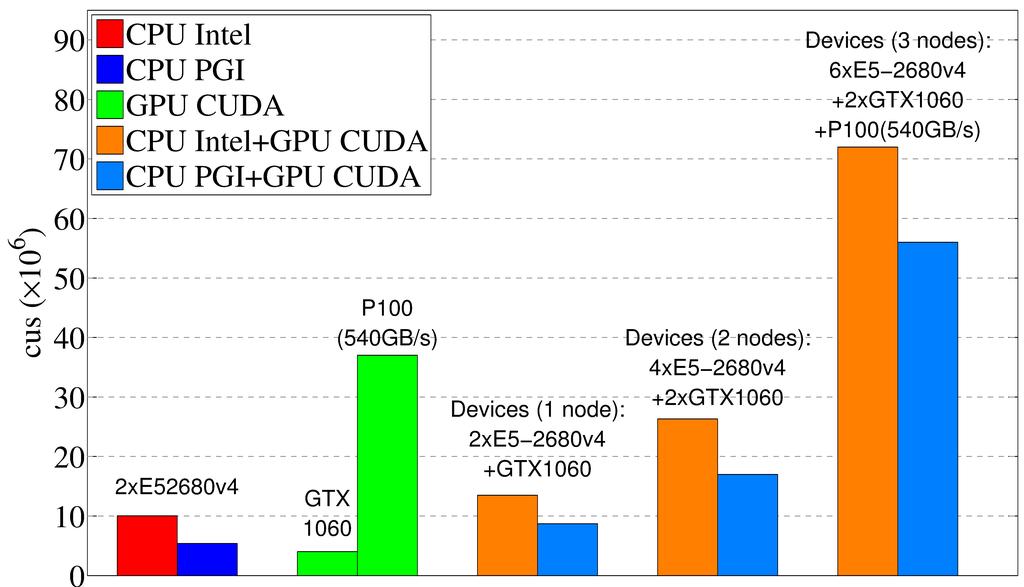
22 Vectorized OpenACC code Run on 2xE52680v4 (CPU): OpenACC code for GPU with pgc++ and -ta=multicore -tp=x64 (CPU execution) 2.72 x 106 cus ~25% performances of the Intel version. CPU code with pgc++ and -ta=multicore -tp=x64 (CPU execution) 5.4 x 106 cus ~50% performances of the Intel version. Therefore: OpenACC for CPUs must be developed on smaller loops than GPU kernels. Add tiling algorithms to improve CPU cache efficiency. 21
23 What's next? GPUs can be used to efficiently optimize CPU codes this optimization strategy leads to highly similar kernels. Could it be possible to use the same kernels for both CPU and GPU within a single version of the code? 22
24 A unified development approach Use C++ templates and pre-compilation variables to define which version should be used. Compiler directives (ignored when not using the right compiler), Template parameter to control the vector size (VSIZ=1 for GPU, VSIZ 1 for CPU), Inline keyword to avoid conflicts in function names. 23
25 Sketch of the hybridized code GPU PART managed by MPI process 0 of the node. 24 CPU PART for all other MPI processes of the node.
26 Work-balancing Poor balance between performances of CPUs and GPUs. Micro-benchmark inside the code to balance work between processes: Performances of MPI process i with the actual work-balance. Work for MPI process i. Total work to be done. Sum of performances with the actual work-balance. 25
27 Performances 26

28 Strong scalability Efficiency (%) = (effective performance/max. performance)*100 27
29 Conclusion GPUs can be used to efficiently optimize CPU codes, 4 steps to optimize: Reduce access to remote memories, Merge kernels with similar data access pattern, Factor your computations, Align your data. Future work: move to unstructured meshes ranking on engine's performances may change. To go deeper into GPU optimization: [Woolley (2013)]. 28
30 Thank you for your attention. Contact:
31 Cache roofline (Intel Advisor 2017) Single threaded E5-2680v4 Performances of the application ~11 GFlops Storage function

32 Optimization steps Ref. Case: 4785s
A Simple Guideline for Code Optimizations on Modern Architectures with OpenACC and CUDA
 A Simple Guideline for Code Optimizations on Modern Architectures with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle, J. Ryan Acks.: CEA/DIFF, IDRIS, GENCI, NVIDIA, Région
A Simple Guideline for Code Optimizations on Modern Architectures with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle, J. Ryan Acks.: CEA/DIFF, IDRIS, GENCI, NVIDIA, Région
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
John Levesque Nov 16, 2001
 1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
An Introduction to OpenACC. Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel
 An Introduction to OpenACC Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel Chapter 1 Introduction OpenACC is a software accelerator that uses the host and the device. It uses compiler
An Introduction to OpenACC Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel Chapter 1 Introduction OpenACC is a software accelerator that uses the host and the device. It uses compiler
Hybrid Implementation of 3D Kirchhoff Migration
 Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015
 Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
SENSEI / SENSEI-Lite / SENEI-LDC Updates
 SENSEI / SENSEI-Lite / SENEI-LDC Updates Chris Roy and Brent Pickering Aerospace and Ocean Engineering Dept. Virginia Tech July 23, 2014 Collaborations with Math Collaboration on the implicit SENSEI-LDC
SENSEI / SENSEI-Lite / SENEI-LDC Updates Chris Roy and Brent Pickering Aerospace and Ocean Engineering Dept. Virginia Tech July 23, 2014 Collaborations with Math Collaboration on the implicit SENSEI-LDC
An Extension of XcalableMP PGAS Lanaguage for Multi-node GPU Clusters
 An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids
 A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Directive-based Programming for Highly-scalable Nodes
 Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015
 Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
OpenACC (Open Accelerators - Introduced in 2012)
") OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
EXPOSING PARTICLE PARALLELISM IN THE XGC PIC CODE BY EXPLOITING GPU MEMORY HIERARCHY. Stephen Abbott, March
 EXPOSING PARTICLE PARALLELISM IN THE XGC PIC CODE BY EXPLOITING GPU MEMORY HIERARCHY Stephen Abbott, March 26 2018 ACKNOWLEDGEMENTS Collaborators: Oak Ridge Nation Laboratory- Ed D Azevedo NVIDIA - Peng
EXPOSING PARTICLE PARALLELISM IN THE XGC PIC CODE BY EXPLOITING GPU MEMORY HIERARCHY Stephen Abbott, March 26 2018 ACKNOWLEDGEMENTS Collaborators: Oak Ridge Nation Laboratory- Ed D Azevedo NVIDIA - Peng
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
A case study of performance portability with OpenMP 4.5
 A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
Code optimization in a 3D diffusion model
 Code optimization in a 3D diffusion model Roger Philp Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 18 th 2016, Barcelona Agenda Background Diffusion
Code optimization in a 3D diffusion model Roger Philp Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 18 th 2016, Barcelona Agenda Background Diffusion
Pragma-based GPU Programming and HMPP Workbench. Scott Grauer-Gray
 Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster
 First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede
 Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators
 Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
GPU GPU CPU. Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3
 /CPU,a),2,2 2,2 Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3 XMP XMP-dev CPU XMP-dev/StarPU XMP-dev XMP CPU StarPU CPU /CPU XMP-dev/StarPU N /CPU CPU. Graphics Processing Unit GP General-Purpose
/CPU,a),2,2 2,2 Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3 XMP XMP-dev CPU XMP-dev/StarPU XMP-dev XMP CPU StarPU CPU /CPU XMP-dev/StarPU N /CPU CPU. Graphics Processing Unit GP General-Purpose
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
OpenACC 2.5 and Beyond. Michael Wolfe PGI compiler engineer
 OpenACC 2.5 and Beyond Michael Wolfe PGI compiler engineer michael.wolfe@pgroup.com OpenACC Timeline 2008 PGI Accelerator Model (targeting NVIDIA GPUs) 2011 OpenACC 1.0 (targeting NVIDIA GPUs, AMD GPUs)
OpenACC 2.5 and Beyond Michael Wolfe PGI compiler engineer michael.wolfe@pgroup.com OpenACC Timeline 2008 PGI Accelerator Model (targeting NVIDIA GPUs) 2011 OpenACC 1.0 (targeting NVIDIA GPUs, AMD GPUs)
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Data Parallel Algorithmic Skeletons with Accelerator Support
 MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support Steffen Ernsting and Herbert Kuchen July 2, 2015 Agenda WESTFÄLISCHE MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support
MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support Steffen Ernsting and Herbert Kuchen July 2, 2015 Agenda WESTFÄLISCHE MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Lecture 2: Introduction to OpenMP with application to a simple PDE solver
 Lecture 2: Introduction to OpenMP with application to a simple PDE solver Mike Giles Mathematical Institute Mike Giles Lecture 2: Introduction to OpenMP 1 / 24 Hardware and software Hardware: a processor
Lecture 2: Introduction to OpenMP with application to a simple PDE solver Mike Giles Mathematical Institute Mike Giles Lecture 2: Introduction to OpenMP 1 / 24 Hardware and software Hardware: a processor
Porting COSMO to Hybrid Architectures
 Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2018
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
OpenACC Fundamentals. Steve Abbott November 15, 2017
 OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2017
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Parallelization, OpenMP
 ~ Parallelization, OpenMP Scientific Computing Winter 2016/2017 Lecture 26 Jürgen Fuhrmann juergen.fuhrmann@wias-berlin.de made wit pandoc 1 / 18 Why parallelization? Computers became faster and faster
~ Parallelization, OpenMP Scientific Computing Winter 2016/2017 Lecture 26 Jürgen Fuhrmann juergen.fuhrmann@wias-berlin.de made wit pandoc 1 / 18 Why parallelization? Computers became faster and faster
SIMD Exploitation in (JIT) Compilers
 Compilers") SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
OpenACC2 vs.openmp4. James Lin 1,2 and Satoshi Matsuoka 2
 2014@San Jose Shanghai Jiao Tong University Tokyo Institute of Technology OpenACC2 vs.openmp4 he Strong, the Weak, and the Missing to Develop Performance Portable Applica>ons on GPU and Xeon Phi James
2014@San Jose Shanghai Jiao Tong University Tokyo Institute of Technology OpenACC2 vs.openmp4 he Strong, the Weak, and the Missing to Develop Performance Portable Applica>ons on GPU and Xeon Phi James
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
AutoTuneTMP: Auto-Tuning in C++ With Runtime Template Metaprogramming
 AutoTuneTMP: Auto-Tuning in C++ With Runtime Template Metaprogramming David Pfander, Malte Brunn, Dirk Pflüger University of Stuttgart, Germany May 25, 2018 Vancouver, Canada, iwapt18 May 25, 2018 Vancouver,
AutoTuneTMP: Auto-Tuning in C++ With Runtime Template Metaprogramming David Pfander, Malte Brunn, Dirk Pflüger University of Stuttgart, Germany May 25, 2018 Vancouver, Canada, iwapt18 May 25, 2018 Vancouver,
Auto-tuning a High-Level Language Targeted to GPU Codes. By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos
 Auto-tuning a High-Level Language Targeted to GPU Codes By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos GPU Computing Utilization of GPU gives speedup on many algorithms
Auto-tuning a High-Level Language Targeted to GPU Codes By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos GPU Computing Utilization of GPU gives speedup on many algorithms
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature. Intel Software Developer Conference London, 2017
 Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Porting The Spectral Element Community Atmosphere Model (CAM-SE) To Hybrid GPU Platforms
 To Hybrid GPU Platforms") Porting The Spectral Element Community Atmosphere Model (CAM-SE) To Hybrid GPU Platforms http://www.scidacreview.org/0902/images/esg13.jpg Matthew Norman Jeffrey Larkin Richard Archibald Valentine Anantharaj
Porting The Spectral Element Community Atmosphere Model (CAM-SE) To Hybrid GPU Platforms http://www.scidacreview.org/0902/images/esg13.jpg Matthew Norman Jeffrey Larkin Richard Archibald Valentine Anantharaj
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION. Julien Demouth, NVIDIA Cliff Woolley, NVIDIA
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
Compiling for GPUs. Adarsh Yoga Madhav Ramesh
 Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2016
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
PyFR: Heterogeneous Computing on Mixed Unstructured Grids with Python. F.D. Witherden, M. Klemm, P.E. Vincent
 PyFR: Heterogeneous Computing on Mixed Unstructured Grids with Python F.D. Witherden, M. Klemm, P.E. Vincent 1 Overview Motivation. Accelerators and Modern Hardware Python and PyFR. Summary. Motivation
PyFR: Heterogeneous Computing on Mixed Unstructured Grids with Python F.D. Witherden, M. Klemm, P.E. Vincent 1 Overview Motivation. Accelerators and Modern Hardware Python and PyFR. Summary. Motivation
Overview: Graphics Processing Units
 advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
Tri-Hybrid Computational Fluid Dynamics on DOE s Cray XK7, Titan.
 Tri-Hybrid Computational Fluid Dynamics on DOE s Cray XK7, Titan. Aaron Vose, Brian Mitchell, and John Levesque. Cray User Group, May 2014. GE Global Research: mitchellb@ge.com Cray Inc.: avose@cray.com,
Tri-Hybrid Computational Fluid Dynamics on DOE s Cray XK7, Titan. Aaron Vose, Brian Mitchell, and John Levesque. Cray User Group, May 2014. GE Global Research: mitchellb@ge.com Cray Inc.: avose@cray.com,
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
An Introduction to OpenAcc
 An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
OpenACC. Part 2. Ned Nedialkov. McMaster University Canada. CS/SE 4F03 March 2016
 OpenACC. Part 2 Ned Nedialkov McMaster University Canada CS/SE 4F03 March 2016 Outline parallel construct Gang loop Worker loop Vector loop kernels construct kernels vs. parallel Data directives c 2013
OpenACC. Part 2 Ned Nedialkov McMaster University Canada CS/SE 4F03 March 2016 Outline parallel construct Gang loop Worker loop Vector loop kernels construct kernels vs. parallel Data directives c 2013
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
S4289: Efficient solution of multiple scalar and block-tridiagonal equations
 S4289: Efficient solution of multiple scalar and block-tridiagonal equations Endre László endre.laszlo [at] oerc.ox.ac.uk Oxford e-research Centre, University of Oxford, UK Pázmány Péter Catholic University,
S4289: Efficient solution of multiple scalar and block-tridiagonal equations Endre László endre.laszlo [at] oerc.ox.ac.uk Oxford e-research Centre, University of Oxford, UK Pázmány Péter Catholic University,
Ronald Rahaman, David Medina, Amanda Lund, John Tramm, Tim Warburton, Andrew Siegel
 Ronald Rahaman, David Medina, Amanda Lund, John Tramm, Tim Warburton, Andrew Siegel Codesign In Action Center for Exascale Simulation of Advanced Reactors (CESAR) Contributions from specialists in entire
Ronald Rahaman, David Medina, Amanda Lund, John Tramm, Tim Warburton, Andrew Siegel Codesign In Action Center for Exascale Simulation of Advanced Reactors (CESAR) Contributions from specialists in entire
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
A Compiler Framework for Optimization of Affine Loop Nests for General Purpose Computations on GPUs
 A Compiler Framework for Optimization of Affine Loop Nests for General Purpose Computations on GPUs Muthu Manikandan Baskaran 1 Uday Bondhugula 1 Sriram Krishnamoorthy 1 J. Ramanujam 2 Atanas Rountev 1
A Compiler Framework for Optimization of Affine Loop Nests for General Purpose Computations on GPUs Muthu Manikandan Baskaran 1 Uday Bondhugula 1 Sriram Krishnamoorthy 1 J. Ramanujam 2 Atanas Rountev 1
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
HPC with PGI and Scalasca
 HPC with PGI and Scalasca Stefan Rosenberger Supervisor: Univ.-Prof. Dipl.-Ing. Dr. Gundolf Haase Institut für Mathematik und wissenschaftliches Rechnen Universität Graz May 28, 2015 Stefan Rosenberger
HPC with PGI and Scalasca Stefan Rosenberger Supervisor: Univ.-Prof. Dipl.-Ing. Dr. Gundolf Haase Institut für Mathematik und wissenschaftliches Rechnen Universität Graz May 28, 2015 Stefan Rosenberger
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Intel Xeon Phi Coprocessor
 Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Intel Xeon Phi Coprocessor A guide to using it on the Cray XC40 Terminology Warning: may also be referred to as MIC or KNC in what follows! What are Intel Xeon Phi Coprocessors? Hardware designed to accelerate
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Generic Refinement and Block Partitioning enabling efficient GPU CFD on Unstructured Grids
 Generic Refinement and Block Partitioning enabling efficient GPU CFD on Unstructured Grids Matthieu Lefebvre 1, Jean-Marie Le Gouez 2 1 PhD at Onera, now post-doc at Princeton, department of Geosciences,
Generic Refinement and Block Partitioning enabling efficient GPU CFD on Unstructured Grids Matthieu Lefebvre 1, Jean-Marie Le Gouez 2 1 PhD at Onera, now post-doc at Princeton, department of Geosciences,
Programming NVIDIA GPUs with OpenACC Directives
 Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe michael.wolfe@pgroup.com http://www.pgroup.com/accelerate Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe mwolfe@nvidia.com http://www.pgroup.com/accelerate
Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe michael.wolfe@pgroup.com http://www.pgroup.com/accelerate Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe mwolfe@nvidia.com http://www.pgroup.com/accelerate