Multi-Processors and GPU
|
|
|
- Coleen Sparks
- 6 years ago
- Views:
Transcription
1 Multi-Processors and GPU Philipp Koehn 7 December 2016

2 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005)

3 Actual CPU Clock Speed 2 Clock speed 2016: 3 GHz

4 Why? 3 Intel estimate, around 2000: 1MW by 2016?
5 Moore s Law 4 Number of transitors per chip still exponential
6 What to do with the Transitors? 5 More parallelism faster execution of instructions More processors on a chip
7 6 multi-processors

8 Intel Core i7: Quad-Core 7
")
9 Intel Xeon Phi: 72 cores (2016) 8
10 Handling Multiple Processes 9 Kernel can keep multiple processes running Each process is assigned to a core each core has a local cache all cores share a common cache, common memory Synchronization between cores not trivial e.g., cache coherence
11 More Parallelism 10 Multiple processes not always the best way to parallelize Often, within a process parallel execution would be helpful Example: matrix multiplication loops over different parts of the data instructions highly independent can be executed in parallel
12 Multi-Threading 11 Parallel execution within process No switching of process context (e.g., virtual address space) Supported by various libraries pthread in C++ thread in C++11 thread in Python Programmer has to take care of conflicts
13 12 computer graphics

14 Computer Graphics 13

15 Computer Graphics 14
16 tl;dr 15 Given 3d models of objects lighting, textures ray tracing Lots of vector and matrix operations Color value for each pixel on the screen has to be computed
17 High Demand 16 Computer games on regular PCs Game consoles Atari ( ) Nintendo/Wii (since 1977) Playstation (since 1994) X-Box (since 2001) 100s of millions sold
18 17 history
19 VGA Controller 18
20 GPU 19
21 Co-Processor 20 CPU handles the bulk of the complexity GPU focuses on specific problems
22 Graphics Pipeline 21 Intitially: dedicated hardware for core steps

23 Unified GPU Architecture 22
24 23 gpu
 Thread is handled by scalar processor (SP) Special function units")
25 Streaming Multiprocessor (SM) 24 Fetches instruction (I-Cache) Has to apply it over a vector of data Each vector element is processed in one thread (MT Issue) Thread is handled by scalar processor (SP) Special function units (SFU)
26 Taxonomy 25 SISD (single instruction, single data) uni-processors (6502, Intel until 1990s) MIMD (multi instruction, multiple data) Intel Core i7 multiple cores on a chip each core runs instructions that operate on their own data SIMD (single instruction, multiple data) Streaming Multi-Processors multiple cores on a chip same instruction executed on different data
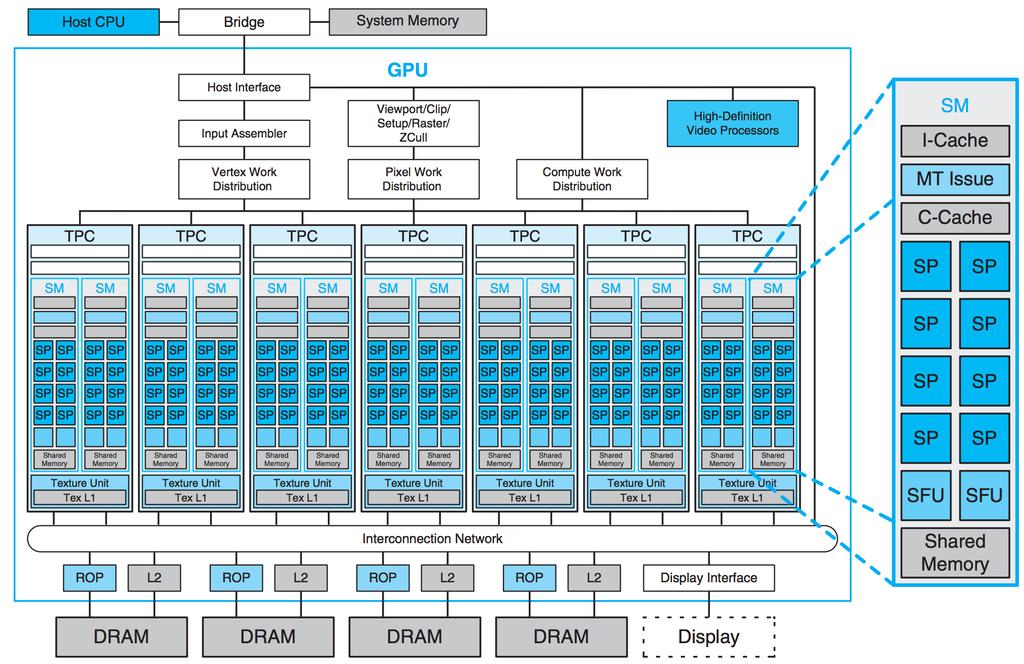
27 GPU Architecture 26
28 Graphics Programming 27 Libraries that support all steps of graphics pipeline Open standard: OpenGL Microsoft: Direct3D Libraries handle mapping to GPU hardware

29 Direct3D Pipeline 28
30 29 more uses for gpus

31 Deep Learning 30
32 Deep Learning 31 The latest machine learning hype Computationally lots of matrix multiplications lots of vector operations massive data sets Just what GPUs are good at
33 CUDA 32 Extension of C++ to support general GPU programming Fairly low-level identify parts of program to be handled by GPU define function to be executed by a thread define how many threads are used Key concepts kernel = function to be executed by a thread thread block = set of threads to be executed in parallel thread grid = set of thread blocks
34 Example 33 Serial loop void example(int n, float alpha, float *x, float *y) { for( int i=0; i<n; n++) y[i] = alpha * x[i] + y[i] } example(n, 2.0, x, y); Parallel with CUDA #define THREADS 256 void cuda_example(int n, float alpha, float *x, float *y) { int i = blockidx.x * blockdim.x + threadidx.x; if (i < n) y[i] = alpha*x[i] + y[i]; } int nblocks = (n + THREADS - 1) / THREADS; cuda_example<<< nblocks, THREADS >>>(n, 2.0, x, y);

35 Memory Levels 34
36 35 multiprocessor architecture

37 Nvidia Titan X streaming multiprocessors, 3584 cores Clock speed 1.4 GHz Memory size 12 GB, bandwidth 320 GB/sec Retail price $1200 Philipp Koehn Computer Systems Fundamentals: Multi-Processors and GPU 7 December 2016

38 Multithreaded Multiprocessor 37

39 Single Instruction, Multiple Thread 38 Each scalar processors executes same instruction on different data has own register file Branch synchroization if threads diverge on conditional branches execute different paths separately Shared memory
40 39 instructions
41 Basics 40 Design more similar to MIPS than x86 Various data types - each of different sizes untyped bit arrays (8, 16, 32, 64 bits) unsigned integers (8, 16, 32, 64 bits) signed integers (8, 16, 32, 64 bits) floating points (16, 32, 64 bits)
42 Basic Instructions 41 Arithmetic instructions operate on registers add d, a, b d = a+b mul d, a, b d = a*b mad d, a, b, c d = a*b+c mov d, a d = a Special functions handled by SFU processors square root (sqrt) sine (sin) cosine (cos) binary logarithm (lg2)
43 Memory Access 42 Different memory spaces (global, shared, local, const) Different data sizes (8, 16, 32, 64 bits) Load (ld) and store (st) Atomic memory read, write, add, min, max, and,...
44 Control Flow 43 Branch (conditional on register value = 0) Subroutine call: call, ret Synchronization: bar.sync forces all threads to synchronize Terminate thread: exit
45 44 memory
46 Overview 45 Memory has to be very fast Graphic card has several DRAM outside GPU (fast access, high bandwidth, lots of pins) Cache on chip: L2 cache associated with each DRAM chip Virtual memory addresses handled by memory management unit (MMU)
47 Levels 46 Global: external DRAM (not on chip) Shared: per streaming multiprocessor Local: in DRAM, but cached on chip Constant: read-only, in DRAM
48 Graphics-Related Optimizations 47 Texture memory for read-only texture maps There are also special instructions to deal with textures
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
CE 431 Parallel Computer Architecture Spring Graphics Processor Units (GPU) Architecture
 Architecture") CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University. * slides thanks to Kavita Bala & many others
 What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University * slides thanks to Kavita Bala & many others Final Project Demo Sign-Up: Will be posted outside my office after lecture today.
What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University * slides thanks to Kavita Bala & many others Final Project Demo Sign-Up: Will be posted outside my office after lecture today.
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
NVIDIA Fermi Architecture
 Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Advanced and parallel architectures
 Cognome Nome Advanced and parallel architectures Prof. A. Massini June 11, 2015 Exercise 1a (2 points) Exercise 1b (2 points) Exercise 2 (5 points) Exercise 3 (3 points) Exercise 4a (3 points) Exercise
Cognome Nome Advanced and parallel architectures Prof. A. Massini June 11, 2015 Exercise 1a (2 points) Exercise 1b (2 points) Exercise 2 (5 points) Exercise 3 (3 points) Exercise 4a (3 points) Exercise
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Vector Processors and Graphics Processing Units (GPUs)
") Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
GPU & Reproductibility, predictability, Repetability, Determinism.
 GPU & Reproductibility, predictability, Repetability, Determinism. David Defour DALI/LIRMM, UPVD Phd Thesis proposal Subject Study the {numerical} predictability of GPUs Why?... fuzzy definition but useful
GPU & Reproductibility, predictability, Repetability, Determinism. David Defour DALI/LIRMM, UPVD Phd Thesis proposal Subject Study the {numerical} predictability of GPUs Why?... fuzzy definition but useful
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
CUDA. GPU Computing. K. Cooper 1. 1 Department of Mathematics. Washington State University
 GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
Parallel computing and GPU introduction
 國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Real-time Graphics 9. GPGPU
 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
GPU Programming Using NVIDIA CUDA
 GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
GPU 101. Mike Bailey. Oregon State University. Oregon State University. Computer Graphics gpu101.pptx. mjb April 23, 2017
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
GPU 101. Mike Bailey. Oregon State University
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
Understanding Shaders and WebGL. Chris Dalton & Olli Etuaho
 Understanding Shaders and WebGL Chris Dalton & Olli Etuaho Agenda Introduction: Accessible shader development with WebGL Understanding WebGL shader execution: from JS to GPU Common shader bugs Accessible
Understanding Shaders and WebGL Chris Dalton & Olli Etuaho Agenda Introduction: Accessible shader development with WebGL Understanding WebGL shader execution: from JS to GPU Common shader bugs Accessible
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
GPU Basics. Introduction to GPU. S. Sundar and M. Panchatcharam. GPU Basics. S. Sundar & M. Panchatcharam. Super Computing GPU.
 Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Analysis Report. Number of Multiprocessors 3 Multiprocessor Clock Rate Concurrent Kernel Max IPC 6 Threads per Warp 32 Global Memory Bandwidth
 Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Computer Organization and Design, 5th Edition: The Hardware/Software Interface
 Computer Organization and Design, 5th Edition: The Hardware/Software Interface 1 Computer Abstractions and Technology 1.1 Introduction 1.2 Eight Great Ideas in Computer Architecture 1.3 Below Your Program
Computer Organization and Design, 5th Edition: The Hardware/Software Interface 1 Computer Abstractions and Technology 1.1 Introduction 1.2 Eight Great Ideas in Computer Architecture 1.3 Below Your Program
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CS/EE 217 Midterm. Question Possible Points Points Scored Total 100
 CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
CDA3101 Recitation Section 13
 CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
Graphics Processing Unit Architecture (GPU Arch)
") Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Lecture 6. Programming with Message Passing Message Passing Interface (MPI)
") Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
CS/CoE 1541 Final exam (Fall 2017). This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4
. This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4") CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
GPU Architecture. Michael Doggett Department of Computer Science Lund university
 GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs)
") CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
CONSOLE ARCHITECTURE
 CONSOLE ARCHITECTURE Introduction Part 1 What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design What
CONSOLE ARCHITECTURE Introduction Part 1 What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design What
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2)
") 1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures