Unlocking FPGAs Using High- Level Synthesis Compiler Technologies
|
|
|
- Cameron Smith
- 6 years ago
- Views:
Transcription




1 Unlocking FPGAs Using High- Leel Synthesis Compiler Technologies Fernando Mar*nez Vallina, Henry Styles Xilinx Feb 22, 2015
2 Why are FPGAs Good Scalable, highly parallel and customizable compute 10s to 1000s of processing elements Processing elements can be fined tuned to specific work loads Bit leel integer and fixed point operations Custom Memory Architectures Memories sized to the application Memory elements placed next to datapath Custom Data Moement and I/O More silicon area dedicated to wires and data transport than any other deice Direct low latency connections between I/O pins and compute Page 2
3 FPGA Applications for Data Center Application Network Function Virtualization Encryption Dictionary compression (ie Deflate) Search categorization Image classification by machine learning Image transcoding Genome sequencing Key Value Store Efficient bit leel operations FPGA Benefit Customized memory hierarchy and efficient string matching Control flow dominated, thousands of actie state machines Ability to customize data moement to specific working sets Fine grained parallelism with customized memory hierarchy Thousands of parallel bit leel operations Low latency I/O FPGAs Offer Significant Speedup Potential s CPU and GPU Page 3

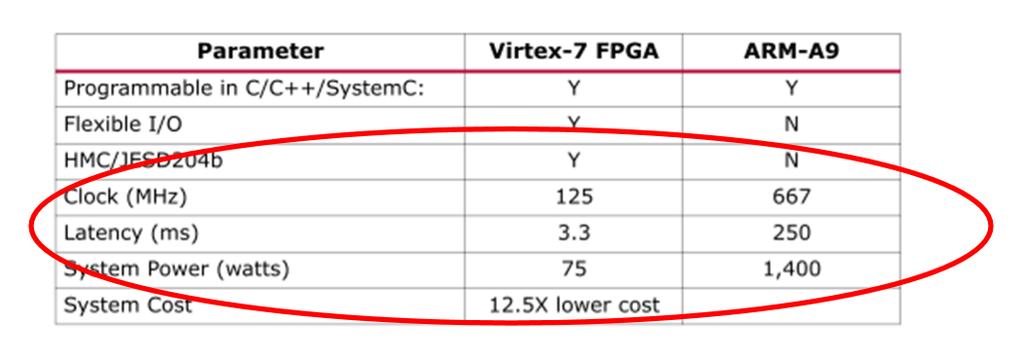
4 Key Value Store Acceleration with FPGAs Line-rate maximum achieed by Xilinx FPGA accelerator Up to 36x in performance/watt demonstrated Plus x lower latency Page 4
5 Productiity Challenges for Software (Daid Thomas, Imperial College, UK) Relatie Performance Parallelisation Clock Rate FPGA GPU CPU Initial Design Hour Day Week Month Year Design-time FPGAs proide large speed-up and power saings at a price! Days or weeks to get an initial ersion working Multiple optimisation and erification cycles to get high performance Page 5

6 Programming Flow Eolution User interface HW World Hardware Software SW World Traditional flow Viado HLS flow SDAccel flow C/C++ CPU C/C++ CPU C/C++ CPU RTL RTL C/C++ RTL Accel C/C++ Accel C/C++ Accel Multiple languages and tools Single language and tool Page 6

7 Viado HLS Raising the Abstraction for IP Creation Page 7


8 Viado High-Leel Synthesis C, C++ or SystemC Algorithmic Specification Micro Architecture Exploration VHDL or Verilog RTL Implementation System IP Integration Comprehensie Integration with the Xilinx Design Enironment Accelerates Algorithmic C to RTL IP integration Page 8






9 Viado HLS System IP Integration Flow C- based IP CreaAon System IntegraAon C, C++, SystemC Libraries Viado IP Integrator Arbitrary Precision Video Math Linear algebra IP: FFT and FIR IP Catalog VHDL or Verilog Viado RTL System Generator for DSP Viado HLS Integrates into System Flows Page 9

10 Design Decisions Decisions made by designer Functionality As implicit state machine Performance Latency, throughput Interfaces Storage architecture Memories, registers banks etc Partitioning into modules Decisions made by the tool State machine Structure, encoding Pipelining Pipeline registers allocation Scheduling Memory I/O Interface I/O Functional operations Design Exploration Page 10
 a x b c * + + 4 Restructuring for op*mized DSP48 a x")
11 Datapath Synthesis Example: y = a*x + b + c; 1 HLS begins by extrac*ng a data flow graph (DFG), a func*onal representa*on a x b c * Expression balancing for latency reduc*on Restructuring to op*mize fabric resources a x b c * + + y y 2 Accounts for target Fmax to determine minimum required pipelining (not yet the op*mal implementa*on) a x b c * Restructuring for op*mized DSP48 a x b c * + + Structured for DSP inference or leeraging floa*ng point IPs y y Page 11
12 Interface Synthesis Completing the design C function arguments become RTL interface ports f(int in[20], int out[20]) { int a,b,c,x,y; for(int i = 0; i < 20; i++) { x = in[i]; y = a*x + b + c; out[i] = y;} } in BRA M i a x b c * + + Control logic FSM y i out BRA M The State Machine Automa>cally Adapts to the Design Interface Page 12
13 Viado HLS Examples Page 13



14 MGS QRD + Weight back Substitution à STAP This is the Hardest Floating Point Problem for Hardware

15 MGS QRD+WBS RESULTS
16 HLS Simple CA- CFAR 32 Cells, 14 Left, 14 Right, 2 Guard


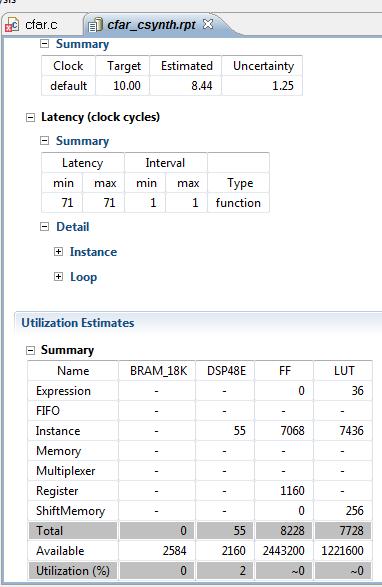
17 CFAR RESULTS
18 SDAccel Software Centric View of FPGA Programming Page 18

19 OpenCL : Technical Goals Royalty Free standard for Parallel Programming Shared IP zones Target Eerything in a Heterogeneous Platform CPU + GPU + ASIC accelerators + DSP + FPGA Cross-Vendor Functional Portability No proprietary APIs + languages to learn Enable Architecture Specific Optimization Refactor code to optimize Vendor extensions Page 19
20 Introducing SDAccel Page 20





21 Breakthrough Solution for Application Deelopers Libraries OpenCL built-ins Video, DSP, Linear Algebra OpenCV BLAS Aailability Included Included Proided by Auiz Systems Readily Aailable Boards Page 21
22 Virtex-7 OpenCL Platform Virtex-7 690T Half-length, low profile 2x 8GB DDR3 1600Mb/s, ECC Gen 3 x8 PCIe Up to 287 GFlops/W 2x SFP+ modules OpenCL COTS Platforms from Deelopment to Production Page 22 Copyright 2014 Xilinx Page 22


23 Kintex-7 OpenCL Platform M-505-K325T Kintex-7 325T 8GB DDR3 Gen 2 X8 PCI-e ISO Scalable Customizable Acceleration Page 23 Copyright 2014 Xilinx Page 23

24 Virtex7 OpenCL Platform Wolerine WX690/WX2000 WX690: V7 690T WX2000: V7 2000T 16/32/64 GB DDR3 Gen3 X16 PCI-e Highest performance acceleration at the lowest power enelope Page 24 Copyright 2014 Xilinx Page 24


25 Accelerated OpenCL Programming and Deployment CPU/GPU like programming enironment ü X86 deelopment and debug ü Cycle accurate simulation ü Platform acceleration Page 25 Xilinx Internal






26 SDAccel Kernel Compiler for FPGAs C, C++ OpenCL Leeraging Viado HLS for ü Efficiently Optimizes a Variety of Input Types ü Optimized Architectural Parallelizing and Pipelining ü Broadest Range of Compiler Optimization for Memory, Dataflow, & Loop Pipelining Performance and Resource Efficiency Page 26
 { int idx = get_global_id(0)*3 + i; op_read(idx); op_compute(idx); op_write(idx); } }")
; op_compute(idx); op_write(idx); } } execution time of loop 9 cycles loop iteration 5")
27 Pipelining OpenCL C Kernel C/C++ Kernel kernel oid foo() { attribute ((xcl_pipeline_loop)) for (int i=0; i<3; i++) { int idx = get_global_id(0)*3 + i; op_read(idx); op_compute(idx); op_write(idx); } } oid foo() { for (int i=0; i<3; i++) { #pragma HLS pipeline int idx = get_global_id(0)*3 + i; op_read(idx); op_compute(idx); op_write(idx); } } execution time of loop 9 cycles loop iteration 5 cycles Page 27
 { int idx = tid*4 + i; a[idx] = b[idx] * c[idx]; } /* ector multiply */ kernel oid mult(local int* a, local int* b, local int* c) { int")
![tid = get_global_id(0); } attribute ((unroll_loop_hint)) for (int i=0; i<4; i++) { int idx = tid*4 + i; a[idx] = b[idx] * c[idx]; } iter0 iter1 iter2 iter3](/docs-images/74/70111058/images/28-1.jpg "iter0 iter1 iter0 Automatic with heuristics User directed OpenCL attribute Expose more concurrency to the compiler s scheduler Similar to SIMD ectorization")
28 Loop Unrolling /* ector multiply */ kernel oid mult(local int* a, local int* b, local int* c) { int tid = get_global_id(0); } attribute ((unroll_loop_hint(2))) for (int i=0; i<4; i++) { int idx = tid*4 + i; a[idx] = b[idx] * c[idx]; } /* ector multiply */ kernel oid mult(local int* a, local int* b, local int* c) { int tid = get_global_id(0); } attribute ((unroll_loop_hint)) for (int i=0; i<4; i++) { int idx = tid*4 + i; a[idx] = b[idx] * c[idx]; } iter0 iter1 iter2 iter3 iter0 iter1 iter0 Automatic with heuristics User directed OpenCL attribute Expose more concurrency to the compiler s scheduler Similar to SIMD ectorization Page 28
29 Memory Specialization OpenCL C Kernel local int buffer[16] ; C/C++ Kernel int buffer[16] ; buffer Buffer implemented in 1 physical memory Buffer can sustain 2 concurrent transactions Reading all alues of buffer can take 8 clock cycles Page 29
30 Memory Specialization OpenCL C Kernel local int buffer[16] attribute ((xcl_array_partition(block,4,1))); C/C++ Kernel int buffer[16]; #pragma HLS ARRAY_PARTITION ariable=buffer block factor=4 dim=1 Buffer implemented in 4 physical memories Buffer can sustain 8 concurrent transactions Compiler handles all address translations to physical memories Reading all alues of buffer can take 2 clock cycles Page 30
31 Memory Specialization OpenCL C Kernel local int buffer[16] attribute ((xcl_array_partition(complete,1))); C/C++ Kernel int buffer[16]; #pragma HLS ARRAY_PARTITION ariable=buffer complete dim=1 Buffer implemented in 16 registers Buffer can sustain 16 concurrent transactions Compiler handles all address translations to physical memories Reading all alues of buffer can take 1 clock cycles Page 31


 ü Minimizes")
32 SDAccel Platform Model CPU Host UltraScale FPGAs PCIe Scalable Host and Base During Updates DDR Memory Software Runtime Experience ü On-demand loadable acceleration units ü Always on interfaces (Memory, Ethernet PCIe, Video) ü Minimizes compilation time Page 32
33 SDAccel Applications Page 33




34 Virtex-7 Monte-Carlo Options Pricing PCIe3 x8 DMA Interconnect DDR DDR MC Black Scholes OpenCL Compute Unit Local memory Local memory
35 FPGA Optimized Libraries Page 35 Copyright 2014 Xilinx Page 35
36 SDAccel in Action


37 SDAccel Performance/Watt Adantage Metric SDAccel with AuizCV library Nidia K20 with CUDA SDAccel Adantage HD Sobel Filter Frames/watt x HD Image Downscaling Frames/watt x Application *Data from Auiz Systems Page 37 Copyright 2014 Xilinx Page 37
38 Start Designing with SDAccel Today Page 38
39 Thank You Page 39
SDACCEL DEVELOPMENT ENVIRONMENT. The Xilinx SDAccel Development Environment. Bringing The Best Performance/Watt to the Data Center
 SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
Vivado HLx Design Entry. June 2016
 Vivado HLx Design Entry June 2016 Agenda What is the HLx Design Methodology? New & Early Access features for Connectivity Platforms Creating Differentiated Logic 2 What is the HLx Design Methodology? Page
Vivado HLx Design Entry June 2016 Agenda What is the HLx Design Methodology? New & Early Access features for Connectivity Platforms Creating Differentiated Logic 2 What is the HLx Design Methodology? Page
Altera SDK for OpenCL
 Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Higher Level Programming Abstractions for FPGAs using OpenCL
 Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
SDSoC: Session 1
 SDSoC: Session 1 ADAM@ADIUVOENGINEERING.COM What is SDSoC SDSoC is a system optimising compiler which allows us to optimise Zynq PS / PL Zynq MPSoC PS / PL MicroBlaze What does this mean? Following the
SDSoC: Session 1 ADAM@ADIUVOENGINEERING.COM What is SDSoC SDSoC is a system optimising compiler which allows us to optimise Zynq PS / PL Zynq MPSoC PS / PL MicroBlaze What does this mean? Following the
SDAccel Development Environment User Guide
 SDAccel Development Environment User Guide Features and Development Flows Revision History The following table shows the revision history for this document. Date Version Revision 05/13/2016 2016.1 Added
SDAccel Development Environment User Guide Features and Development Flows Revision History The following table shows the revision history for this document. Date Version Revision 05/13/2016 2016.1 Added
NEW FPGA DESIGN AND VERIFICATION TECHNIQUES MICHAL HUSEJKO IT-PES-ES
 NEW FPGA DESIGN AND VERIFICATION TECHNIQUES MICHAL HUSEJKO IT-PES-ES Design: Part 1 High Level Synthesis (Xilinx Vivado HLS) Part 2 SDSoC (Xilinx, HLS + ARM) Part 3 OpenCL (Altera OpenCL SDK) Verification:
NEW FPGA DESIGN AND VERIFICATION TECHNIQUES MICHAL HUSEJKO IT-PES-ES Design: Part 1 High Level Synthesis (Xilinx Vivado HLS) Part 2 SDSoC (Xilinx, HLS + ARM) Part 3 OpenCL (Altera OpenCL SDK) Verification:
High Performance Implementation of Microtubule Modeling on FPGA using Vivado HLS
 High Performance Implementation of Microtubule Modeling on FPGA using Vivado HLS Yury Rumyantsev rumyantsev@rosta.ru 1 Agenda 1. Intoducing Rosta and Hardware overview 2. Microtubule Modeling Problem 3.
High Performance Implementation of Microtubule Modeling on FPGA using Vivado HLS Yury Rumyantsev rumyantsev@rosta.ru 1 Agenda 1. Intoducing Rosta and Hardware overview 2. Microtubule Modeling Problem 3.
Cadence SystemC Design and Verification. NMI FPGA Network Meeting Jan 21, 2015
 Cadence SystemC Design and Verification NMI FPGA Network Meeting Jan 21, 2015 The High Level Synthesis Opportunity Raising Abstraction Improves Design & Verification Optimizes Power, Area and Timing for
Cadence SystemC Design and Verification NMI FPGA Network Meeting Jan 21, 2015 The High Level Synthesis Opportunity Raising Abstraction Improves Design & Verification Optimizes Power, Area and Timing for
81920**slide. 1Developing the Accelerator Using HLS
 81920**slide - 1Developing the Accelerator Using HLS - 82038**slide Objectives After completing this module, you will be able to: Describe the high-level synthesis flow Describe the capabilities of the
81920**slide - 1Developing the Accelerator Using HLS - 82038**slide Objectives After completing this module, you will be able to: Describe the high-level synthesis flow Describe the capabilities of the
"On the Capability and Achievable Performance of FPGAs for HPC Applications"
 "On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
"On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
Optimizing HW/SW Partition of a Complex Embedded Systems. Simon George November 2015.
 Optimizing HW/SW Partition of a Complex Embedded Systems Simon George November 2015 Zynq-7000 All Programmable SoC HP ACP GP Page 2 Zynq UltraScale+ MPSoC Page 3 HW/SW Optimization Challenges application()
Optimizing HW/SW Partition of a Complex Embedded Systems Simon George November 2015 Zynq-7000 All Programmable SoC HP ACP GP Page 2 Zynq UltraScale+ MPSoC Page 3 HW/SW Optimization Challenges application()
Porting Performance across GPUs and FPGAs
 Porting Performance across GPUs and FPGAs Deming Chen, ECE, University of Illinois In collaboration with Alex Papakonstantinou 1, Karthik Gururaj 2, John Stratton 1, Jason Cong 2, Wen-Mei Hwu 1 1: ECE
Porting Performance across GPUs and FPGAs Deming Chen, ECE, University of Illinois In collaboration with Alex Papakonstantinou 1, Karthik Gururaj 2, John Stratton 1, Jason Cong 2, Wen-Mei Hwu 1 1: ECE
The S6000 Family of Processors
 The S6000 Family of Processors Today s Design Challenges The advent of software configurable processors In recent years, the widespread adoption of digital technologies has revolutionized the way in which
The S6000 Family of Processors Today s Design Challenges The advent of software configurable processors In recent years, the widespread adoption of digital technologies has revolutionized the way in which
Welcome. Altera Technology Roadshow 2013
 Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
COE 561 Digital System Design & Synthesis Introduction
 1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
Versal: AI Engine & Programming Environment
 Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Hardware Design Environments. Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University
 Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Unit 2: High-Level Synthesis
 Course contents Unit 2: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 2 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Course contents Unit 2: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 2 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Early Models in Silicon with SystemC synthesis
 Early Models in Silicon with SystemC synthesis Agility Compiler summary C-based design & synthesis for SystemC Pure, standard compliant SystemC/ C++ Most widely used C-synthesis technology Structural SystemC
Early Models in Silicon with SystemC synthesis Agility Compiler summary C-based design & synthesis for SystemC Pure, standard compliant SystemC/ C++ Most widely used C-synthesis technology Structural SystemC
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
Does FPGA-based prototyping really have to be this difficult?
 Does FPGA-based prototyping really have to be this difficult? Embedded Conference Finland Andrew Marshall May 2017 What is FPGA-Based Prototyping? Primary platform for pre-silicon software development
Does FPGA-based prototyping really have to be this difficult? Embedded Conference Finland Andrew Marshall May 2017 What is FPGA-Based Prototyping? Primary platform for pre-silicon software development
MOJTABA MAHDAVI Mojtaba Mahdavi DSP Design Course, EIT Department, Lund University, Sweden
 High Level Synthesis with Catapult MOJTABA MAHDAVI 1 Outline High Level Synthesis HLS Design Flow in Catapult Data Types Project Creation Design Setup Data Flow Analysis Resource Allocation Scheduling
High Level Synthesis with Catapult MOJTABA MAHDAVI 1 Outline High Level Synthesis HLS Design Flow in Catapult Data Types Project Creation Design Setup Data Flow Analysis Resource Allocation Scheduling
Extending the Power of FPGAs
 Extending the Power of FPGAs The Journey has Begun Salil Raje Xilinx Corporate Vice President Software and IP Products Development Agenda The Evolution of FPGAs and FPGA Programming IP-Centric Design with
Extending the Power of FPGAs The Journey has Begun Salil Raje Xilinx Corporate Vice President Software and IP Products Development Agenda The Evolution of FPGAs and FPGA Programming IP-Centric Design with
Adaptable Intelligence The Next Computing Era
 Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
High Capacity and High Performance 20nm FPGAs. Steve Young, Dinesh Gaitonde August Copyright 2014 Xilinx
 High Capacity and High Performance 20nm FPGAs Steve Young, Dinesh Gaitonde August 2014 Not a Complete Product Overview Page 2 Outline Page 3 Petabytes per month Increasing Bandwidth Global IP Traffic Growth
High Capacity and High Performance 20nm FPGAs Steve Young, Dinesh Gaitonde August 2014 Not a Complete Product Overview Page 2 Outline Page 3 Petabytes per month Increasing Bandwidth Global IP Traffic Growth
SODA: Stencil with Optimized Dataflow Architecture Yuze Chi, Jason Cong, Peng Wei, Peipei Zhou
 SODA: Stencil with Optimized Dataflow Architecture Yuze Chi, Jason Cong, Peng Wei, Peipei Zhou University of California, Los Angeles 1 What is stencil computation? 2 What is Stencil Computation? A sliding
SODA: Stencil with Optimized Dataflow Architecture Yuze Chi, Jason Cong, Peng Wei, Peipei Zhou University of California, Los Angeles 1 What is stencil computation? 2 What is Stencil Computation? A sliding
Lecture 11: OpenCL and Altera OpenCL. James C. Hoe Department of ECE Carnegie Mellon University
 18 643 Lecture 11: OpenCL and Altera OpenCL James C. Hoe Department of ECE Carnegie Mellon University 18 643 F17 L11 S1, James C. Hoe, CMU/ECE/CALCM, 2017 Housekeeping Your goal today: understand Altera
18 643 Lecture 11: OpenCL and Altera OpenCL James C. Hoe Department of ECE Carnegie Mellon University 18 643 F17 L11 S1, James C. Hoe, CMU/ECE/CALCM, 2017 Housekeeping Your goal today: understand Altera
40Gbps+ Full Line Rate, Programmable Network Accelerators for Low Latency Applications SAAHPC 19 th July 2011
 40Gbps+ Full Line Rate, Programmable Network Accelerators for Low Latency Applications SAAHPC 19 th July 2011 Allan Cantle President & Founder www.nallatech.com Company Overview ISI + Nallatech + Innovative
40Gbps+ Full Line Rate, Programmable Network Accelerators for Low Latency Applications SAAHPC 19 th July 2011 Allan Cantle President & Founder www.nallatech.com Company Overview ISI + Nallatech + Innovative
Efficient Hardware Acceleration on SoC- FPGA using OpenCL
 Efficient Hardware Acceleration on SoC- FPGA using OpenCL Advisor : Dr. Benjamin Carrion Schafer Susmitha Gogineni 30 th August 17 Presentation Overview 1.Objective & Motivation 2.Configurable SoC -FPGA
Efficient Hardware Acceleration on SoC- FPGA using OpenCL Advisor : Dr. Benjamin Carrion Schafer Susmitha Gogineni 30 th August 17 Presentation Overview 1.Objective & Motivation 2.Configurable SoC -FPGA
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
100M Gate Designs in FPGAs
 100M Gate Designs in FPGAs Fact or Fiction? NMI FPGA Network 11 th October 2016 Jonathan Meadowcroft, Cadence Design Systems Why in the world, would I do that? ASIC replacement? Probably not! Cost prohibitive
100M Gate Designs in FPGAs Fact or Fiction? NMI FPGA Network 11 th October 2016 Jonathan Meadowcroft, Cadence Design Systems Why in the world, would I do that? ASIC replacement? Probably not! Cost prohibitive
FlexRIO. FPGAs Bringing Custom Functionality to Instruments. Ravichandran Raghavan Technical Marketing Engineer. ni.com
 FlexRIO FPGAs Bringing Custom Functionality to Instruments Ravichandran Raghavan Technical Marketing Engineer Electrical Test Today Acquire, Transfer, Post-Process Paradigm Fixed- Functionality Triggers
FlexRIO FPGAs Bringing Custom Functionality to Instruments Ravichandran Raghavan Technical Marketing Engineer Electrical Test Today Acquire, Transfer, Post-Process Paradigm Fixed- Functionality Triggers
Towards Optimal Custom Instruction Processors
 Towards Optimal Custom Instruction Processors Wayne Luk Kubilay Atasu, Rob Dimond and Oskar Mencer Department of Computing Imperial College London HOT CHIPS 18 Overview 1. background: extensible processors
Towards Optimal Custom Instruction Processors Wayne Luk Kubilay Atasu, Rob Dimond and Oskar Mencer Department of Computing Imperial College London HOT CHIPS 18 Overview 1. background: extensible processors
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Ten Reasons to Optimize a Processor
 By Neil Robinson SoC designs today require application-specific logic that meets exacting design requirements, yet is flexible enough to adjust to evolving industry standards. Optimizing your processor
By Neil Robinson SoC designs today require application-specific logic that meets exacting design requirements, yet is flexible enough to adjust to evolving industry standards. Optimizing your processor
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
Simplifying FPGA Design for SDR with a Network on Chip Architecture
 Simplifying FPGA Design for SDR with a Network on Chip Architecture Matt Ettus Ettus Research GRCon13 Outline 1 Introduction 2 RF NoC 3 Status and Conclusions USRP FPGA Capability Gen
Simplifying FPGA Design for SDR with a Network on Chip Architecture Matt Ettus Ettus Research GRCon13 Outline 1 Introduction 2 RF NoC 3 Status and Conclusions USRP FPGA Capability Gen
System Level Design with IBM PowerPC Models
 September 2005 System Level Design with IBM PowerPC Models A view of system level design SLE-m3 The System-Level Challenges Verification escapes cost design success There is a 45% chance of committing
September 2005 System Level Design with IBM PowerPC Models A view of system level design SLE-m3 The System-Level Challenges Verification escapes cost design success There is a 45% chance of committing
LegUp: Accelerating Memcached on Cloud FPGAs
 0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
Adaptable Computing The Future of FPGA Acceleration. Dan Gibbons, VP Software Development June 6, 2018
 Adaptable Computing The Future of FPGA Acceleration Dan Gibbons, VP Software Development June 6, 2018 Adaptable Accelerated Computing Page 2 Three Big Trends The Evolution of Computing Trend to Heterogeneous
Adaptable Computing The Future of FPGA Acceleration Dan Gibbons, VP Software Development June 6, 2018 Adaptable Accelerated Computing Page 2 Three Big Trends The Evolution of Computing Trend to Heterogeneous
Design of Transport Triggered Architecture Processor for Discrete Cosine Transform
 Design of Transport Triggered Architecture Processor for Discrete Cosine Transform by J. Heikkinen, J. Sertamo, T. Rautiainen,and J. Takala Presented by Aki Happonen Table of Content Introduction Transport
Design of Transport Triggered Architecture Processor for Discrete Cosine Transform by J. Heikkinen, J. Sertamo, T. Rautiainen,and J. Takala Presented by Aki Happonen Table of Content Introduction Transport
Pactron FPGA Accelerated Computing Solutions
 Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Overview of ROCCC 2.0
 Overview of ROCCC 2.0 Walid Najjar and Jason Villarreal SUMMARY FPGAs have been shown to be powerful platforms for hardware code acceleration. However, their poor programmability is the main impediment
Overview of ROCCC 2.0 Walid Najjar and Jason Villarreal SUMMARY FPGAs have been shown to be powerful platforms for hardware code acceleration. However, their poor programmability is the main impediment
FPGA Entering the Era of the All Programmable SoC
 FPGA Entering the Era of the All Programmable SoC Ivo Bolsens, Senior Vice President & CTO Page 1 Moore s Law: The Technology Pipeline Page 2 Industry Debates on Cost Page 3 Design Cost Estimated Chip
FPGA Entering the Era of the All Programmable SoC Ivo Bolsens, Senior Vice President & CTO Page 1 Moore s Law: The Technology Pipeline Page 2 Industry Debates on Cost Page 3 Design Cost Estimated Chip
Programmable Logic Design Grzegorz Budzyń Lecture. 15: Advanced hardware in FPGA structures
 Programmable Logic Design Grzegorz Budzyń Lecture 15: Advanced hardware in FPGA structures Plan Introduction PowerPC block RocketIO Introduction Introduction The larger the logical chip, the more additional
Programmable Logic Design Grzegorz Budzyń Lecture 15: Advanced hardware in FPGA structures Plan Introduction PowerPC block RocketIO Introduction Introduction The larger the logical chip, the more additional
Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm
 in 7nm") Engineering Director, Xilinx Silicon Architecture Group Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm Presented By Kees Vissers Fellow February 25, FPGA 2019 Technology scaling
Engineering Director, Xilinx Silicon Architecture Group Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm Presented By Kees Vissers Fellow February 25, FPGA 2019 Technology scaling
An Overview of a Compiler for Mapping MATLAB Programs onto FPGAs
 An Overview of a Compiler for Mapping MATLAB Programs onto FPGAs P. Banerjee Department of Electrical and Computer Engineering Northwestern University 2145 Sheridan Road, Evanston, IL-60208 banerjee@ece.northwestern.edu
An Overview of a Compiler for Mapping MATLAB Programs onto FPGAs P. Banerjee Department of Electrical and Computer Engineering Northwestern University 2145 Sheridan Road, Evanston, IL-60208 banerjee@ece.northwestern.edu
Upgrading XL Fortran Compilers
 Upgrading XL Fortran Compilers Oeriew Upgrading to the latest IBM XL Fortran compilers makes good business sense. Upgrading puts new capabilities into the hands of your programmers making them and your
Upgrading XL Fortran Compilers Oeriew Upgrading to the latest IBM XL Fortran compilers makes good business sense. Upgrading puts new capabilities into the hands of your programmers making them and your
INTRODUCTION TO OPENCL TM A Beginner s Tutorial. Udeepta Bordoloi AMD
 INTRODUCTION TO OPENCL TM A Beginner s Tutorial Udeepta Bordoloi AMD IT S A HETEROGENEOUS WORLD Heterogeneous computing The new normal CPU Many CPU s 2, 4, 8, Very many GPU processing elements 100 s Different
INTRODUCTION TO OPENCL TM A Beginner s Tutorial Udeepta Bordoloi AMD IT S A HETEROGENEOUS WORLD Heterogeneous computing The new normal CPU Many CPU s 2, 4, 8, Very many GPU processing elements 100 s Different
IBM XL C/C++ V2R1M1 web deliverable for z/os V2R1
 IBM XL C/C++ V2R1M1 web delierable for z/os V2R1 Enable high-performing z/os XL C/C++ programs for workload optimized business software solutions Highlights XL C/C++ V2R1M1 web delierable for z/os V2R1
IBM XL C/C++ V2R1M1 web delierable for z/os V2R1 Enable high-performing z/os XL C/C++ programs for workload optimized business software solutions Highlights XL C/C++ V2R1M1 web delierable for z/os V2R1
Zynq-7000 All Programmable SoC Product Overview
 Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
Zynq-7000 All Programmable SoC Product Overview The SW, HW and IO Programmable Platform August 2012 Copyright 2012 2009 Xilinx Introducing the Zynq -7000 All Programmable SoC Breakthrough Processing Platform
ATS-GPU Real Time Signal Processing Software
 Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
Ted N. Booth. DesignLinx Hardware Solutions
 Ted N. Booth DesignLinx Hardware Solutions September 2015 Using Vivado HLS for Video Algorithm Implementation for Demonstration and Validation Agenda Project Description HLS Lessons Learned Summary Project
Ted N. Booth DesignLinx Hardware Solutions September 2015 Using Vivado HLS for Video Algorithm Implementation for Demonstration and Validation Agenda Project Description HLS Lessons Learned Summary Project
Multi-Gigahertz Parallel FFTs for FPGA and ASIC Implementation
 Multi-Gigahertz Parallel FFTs for FPGA and ASIC Implementation Doug Johnson, Applications Consultant Chris Eddington, Technical Marketing Synopsys 2013 1 Synopsys, Inc. 700 E. Middlefield Road Mountain
Multi-Gigahertz Parallel FFTs for FPGA and ASIC Implementation Doug Johnson, Applications Consultant Chris Eddington, Technical Marketing Synopsys 2013 1 Synopsys, Inc. 700 E. Middlefield Road Mountain
Introduction to FPGA Design with Vivado High-Level Synthesis. UG998 (v1.0) July 2, 2013
 July 2, 2013") Introduction to FPGA Design with Vivado High-Level Synthesis Notice of Disclaimer The information disclosed to you hereunder (the Materials ) is provided solely for the selection and use of Xilinx products.
Introduction to FPGA Design with Vivado High-Level Synthesis Notice of Disclaimer The information disclosed to you hereunder (the Materials ) is provided solely for the selection and use of Xilinx products.
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Accelerating Data Center Workloads with FPGAs
 Accelerating Data Center Workloads with FPGAs Enno Lübbers NorCAS 2017, Linköping, Sweden Intel technologies features and benefits depend on system configuration and may require enabled hardware, software
Accelerating Data Center Workloads with FPGAs Enno Lübbers NorCAS 2017, Linköping, Sweden Intel technologies features and benefits depend on system configuration and may require enabled hardware, software
Investigation of High-Level Synthesis tools applicability to data acquisition systems design based on the CMS ECAL Data Concentrator Card example
 Journal of Physics: Conference Series PAPER OPEN ACCESS Investigation of High-Level Synthesis tools applicability to data acquisition systems design based on the CMS ECAL Data Concentrator Card example
Journal of Physics: Conference Series PAPER OPEN ACCESS Investigation of High-Level Synthesis tools applicability to data acquisition systems design based on the CMS ECAL Data Concentrator Card example
High-Level Synthesis
 High-Level Synthesis 1 High-Level Synthesis 1. Basic definition 2. A typical HLS process 3. Scheduling techniques 4. Allocation and binding techniques 5. Advanced issues High-Level Synthesis 2 Introduction
High-Level Synthesis 1 High-Level Synthesis 1. Basic definition 2. A typical HLS process 3. Scheduling techniques 4. Allocation and binding techniques 5. Advanced issues High-Level Synthesis 2 Introduction
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
Revolutionizing the Datacenter
 Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
SDA: Software-Defined Accelerator for general-purpose big data analysis system
 SDA: Software-Defined Accelerator for general-purpose big data analysis system Jian Ouyang(ouyangjian@baidu.com), Wei Qi, Yong Wang, Yichen Tu, Jing Wang, Bowen Jia Baidu is beyond a search engine Search
SDA: Software-Defined Accelerator for general-purpose big data analysis system Jian Ouyang(ouyangjian@baidu.com), Wei Qi, Yong Wang, Yichen Tu, Jing Wang, Bowen Jia Baidu is beyond a search engine Search
Introduction to Electronic Design Automation. Model of Computation. Model of Computation. Model of Computation
 Introduction to Electronic Design Automation Model of Computation Jie-Hong Roland Jiang 江介宏 Department of Electrical Engineering National Taiwan University Spring 03 Model of Computation In system design,
Introduction to Electronic Design Automation Model of Computation Jie-Hong Roland Jiang 江介宏 Department of Electrical Engineering National Taiwan University Spring 03 Model of Computation In system design,
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
ESL design with the Agility Compiler for SystemC
 ESL design with the Agility Compiler for SystemC SystemC behavioral design & synthesis Steve Chappell & Chris Sullivan Celoxica ESL design portfolio Complete ESL design environment Streaming Video Processing
ESL design with the Agility Compiler for SystemC SystemC behavioral design & synthesis Steve Chappell & Chris Sullivan Celoxica ESL design portfolio Complete ESL design environment Streaming Video Processing
Optimised OpenCL Workgroup Synthesis for Hybrid ARM-FPGA Devices
 Optimised OpenCL Workgroup Synthesis for Hybrid ARM-FPGA Devices Mohammad Hosseinabady and Jose Luis Nunez-Yanez Department of Electrical and Electronic Engineering University of Bristol, UK. Email: {m.hosseinabady,
Optimised OpenCL Workgroup Synthesis for Hybrid ARM-FPGA Devices Mohammad Hosseinabady and Jose Luis Nunez-Yanez Department of Electrical and Electronic Engineering University of Bristol, UK. Email: {m.hosseinabady,
Profiling & Tuning Applications. CUDA Course István Reguly
 Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks
 Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
Did I Just Do That on a Bunch of FPGAs?
 Did I Just Do That on a Bunch of FPGAs? Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto About the Talk Title It s the measure
Did I Just Do That on a Bunch of FPGAs? Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto About the Talk Title It s the measure
Intel HLS Compiler: Fast Design, Coding, and Hardware
 white paper Intel HLS Compiler Intel HLS Compiler: Fast Design, Coding, and Hardware The Modern FPGA Workflow Authors Melissa Sussmann HLS Product Manager Intel Corporation Tom Hill OpenCL Product Manager
white paper Intel HLS Compiler Intel HLS Compiler: Fast Design, Coding, and Hardware The Modern FPGA Workflow Authors Melissa Sussmann HLS Product Manager Intel Corporation Tom Hill OpenCL Product Manager
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Custom computing systems
 Custom computing systems difference engine: Charles Babbage 1832 - compute maths tables digital orrery: MIT 1985 - special-purpose engine, found pluto motion chaotic Splash2: Supercomputing esearch Center
Custom computing systems difference engine: Charles Babbage 1832 - compute maths tables digital orrery: MIT 1985 - special-purpose engine, found pluto motion chaotic Splash2: Supercomputing esearch Center
High-level programming tools for FPGA
 High-level programming tools for FPGA Ease of Development Smarter Systems Compute Acceleration Options CPU GPU ARM SoCs & DSPs Software-Defined All Programmable FPGAs, SoCs & MPSoCs NPU HLS FPGAs, SoCs,
High-level programming tools for FPGA Ease of Development Smarter Systems Compute Acceleration Options CPU GPU ARM SoCs & DSPs Software-Defined All Programmable FPGAs, SoCs & MPSoCs NPU HLS FPGAs, SoCs,
Lecture 7: Introduction to Co-synthesis Algorithms
 Design & Co-design of Embedded Systems Lecture 7: Introduction to Co-synthesis Algorithms Sharif University of Technology Computer Engineering Dept. Winter-Spring 2008 Mehdi Modarressi Topics for today
Design & Co-design of Embedded Systems Lecture 7: Introduction to Co-synthesis Algorithms Sharif University of Technology Computer Engineering Dept. Winter-Spring 2008 Mehdi Modarressi Topics for today
Accelerating FPGA/ASIC Design and Verification
 Accelerating FPGA/ASIC Design and Verification Tabrez Khan Senior Application Engineer Vidya Viswanathan Application Engineer 2015 The MathWorks, Inc. 1 Agenda Challeges with Traditional Implementation
Accelerating FPGA/ASIC Design and Verification Tabrez Khan Senior Application Engineer Vidya Viswanathan Application Engineer 2015 The MathWorks, Inc. 1 Agenda Challeges with Traditional Implementation
ESE532: System-on-a-Chip Architecture. Today. Message. Graph Cycles. Preclass 1. Reminder
 ESE532: System-on-a-Chip Architecture Day 8: September 26, 2018 Spatial Computations Today Graph Cycles (from Day 7) Accelerator Pipelines FPGAs Zynq Computational Capacity 1 2 Message Custom accelerators
ESE532: System-on-a-Chip Architecture Day 8: September 26, 2018 Spatial Computations Today Graph Cycles (from Day 7) Accelerator Pipelines FPGAs Zynq Computational Capacity 1 2 Message Custom accelerators
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
OpenCL on FPGAs - Creating custom accelerated solutions
 OpenCL on FPGAs - Creating custom accelerated solutions Manuel Greisinger Channel Manager, Central & Eastern Europe Oct 13 th, 2015 ESSEI Technology Day, Gilching, Germany Industry Trends Increasing product
OpenCL on FPGAs - Creating custom accelerated solutions Manuel Greisinger Channel Manager, Central & Eastern Europe Oct 13 th, 2015 ESSEI Technology Day, Gilching, Germany Industry Trends Increasing product
Accelerating Vision Processing
 Accelerating Vision Processing Neil Trevett Vice President Mobile Ecosystem at NVIDIA President of Khronos and Chair of the OpenCL Working Group SIGGRAPH, July 2016 Copyright Khronos Group 2016 - Page
Accelerating Vision Processing Neil Trevett Vice President Mobile Ecosystem at NVIDIA President of Khronos and Chair of the OpenCL Working Group SIGGRAPH, July 2016 Copyright Khronos Group 2016 - Page
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Convey Wolverine Application Accelerators. Architectural Overview. Convey White Paper
 Convey Wolverine Application Accelerators Architectural Overview Convey White Paper Convey White Paper Convey Wolverine Application Accelerators Architectural Overview Introduction Advanced computing architectures
Convey Wolverine Application Accelerators Architectural Overview Convey White Paper Convey White Paper Convey Wolverine Application Accelerators Architectural Overview Introduction Advanced computing architectures
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
OpenMP Device Offloading to FPGA Accelerators. Lukas Sommer, Jens Korinth, Andreas Koch
 OpenMP Device Offloading to FPGA Accelerators Lukas Sommer, Jens Korinth, Andreas Koch Motivation Increasing use of heterogeneous systems to overcome CPU power limitations 2017-07-12 OpenMP FPGA Device
OpenMP Device Offloading to FPGA Accelerators Lukas Sommer, Jens Korinth, Andreas Koch Motivation Increasing use of heterogeneous systems to overcome CPU power limitations 2017-07-12 OpenMP FPGA Device
FPGA architecture and design technology
 CE 435 Embedded Systems Spring 2017 FPGA architecture and design technology Nikos Bellas Computer and Communications Engineering Department University of Thessaly 1 FPGA fabric A generic island-style FPGA
CE 435 Embedded Systems Spring 2017 FPGA architecture and design technology Nikos Bellas Computer and Communications Engineering Department University of Thessaly 1 FPGA fabric A generic island-style FPGA
Kalray MPPA Manycore Challenges for the Next Generation of Professional Applications Benoît Dupont de Dinechin MPSoC 2013
 Kalray MPPA Manycore Challenges for the Next Generation of Professional Applications Benoît Dupont de Dinechin MPSoC 2013 The End of Dennard MOSFET Scaling Theory 2013 Kalray SA All Rights Reserved MPSoC
Kalray MPPA Manycore Challenges for the Next Generation of Professional Applications Benoît Dupont de Dinechin MPSoC 2013 The End of Dennard MOSFET Scaling Theory 2013 Kalray SA All Rights Reserved MPSoC
Gzip Compression Using Altera OpenCL. Mohamed Abdelfattah (University of Toronto) Andrei Hagiescu Deshanand Singh
 Andrei Hagiescu Deshanand Singh") Gzip Compression Using Altera OpenCL Mohamed Abdelfattah (University of Toronto) Andrei Hagiescu Deshanand Singh Gzip Widely-used lossless compression program Gzip = LZ77 + Huffman Big data needs fast
Gzip Compression Using Altera OpenCL Mohamed Abdelfattah (University of Toronto) Andrei Hagiescu Deshanand Singh Gzip Widely-used lossless compression program Gzip = LZ77 + Huffman Big data needs fast
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators
 Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
Fast and Flexible High-Level Synthesis from OpenCL using Reconfiguration Contexts
 Fast and Flexible High-Level Synthesis from OpenCL using Reconfiguration Contexts James Coole, Greg Stitt University of Florida Department of Electrical and Computer Engineering and NSF Center For High-Performance
Fast and Flexible High-Level Synthesis from OpenCL using Reconfiguration Contexts James Coole, Greg Stitt University of Florida Department of Electrical and Computer Engineering and NSF Center For High-Performance
Co-synthesis and Accelerator based Embedded System Design
 Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
FPGA design with National Instuments
 FPGA design with National Instuments Rémi DA SILVA Systems Engineer - Embedded and Data Acquisition Systems - MED Region ni.com The NI Approach to Flexible Hardware Processor Real-time OS Application software
FPGA design with National Instuments Rémi DA SILVA Systems Engineer - Embedded and Data Acquisition Systems - MED Region ni.com The NI Approach to Flexible Hardware Processor Real-time OS Application software
S2C K7 Prodigy Logic Module Series
 S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters
 Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA
 Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School