ECE 4750 Computer Architecture, Fall 2014 T05 FSM and Pipelined Cache Memories
|
|
|
- Blaze Bryant
- 6 years ago
- Views:
Transcription
1 ECE 4750 Computer Architecture, Fall 2014 T05 FSM and Pipelined Cache Memories School of Electrical and Computer Engineering Cornell University revision: FSM Set-Associative Cache Memory 2 2 Impact of Associativity on Microarchitecture 5 3 Pipelined Cache Microcarchitecture 7 4 Integrating Processors and Caches 12 5 Multi-Bank Cache Microarchitecture 15 6 Cache Optimizations 18 7 Cache Examples 24 1
2 1 FSM Set-Associative Cache Memory 1. FSM Set-Associative Cache Memory Hit Cache Miss Main Memory Average Memory Access Latency (AMAL) AMAL = ( Hit Time + ( Miss Rate Miss Penalty ) ) Cycle Time Microarchitecture Hit Time Cycle Time Topic 04 Single-Cycle Cache 1 long this topic FSM Cache >1 short this topic Pipelined Cache 1 short Technology Constraints Cache hit and main memory access will now take multiple cycles Assume more realistic technology with only single-ported SRAMs for tag and data array creq Control Datapath Tag Array 32b Control Unit cresp Data Array Status Change write policy from write-through, no allocate on write miss to write-back, allocate on write miss Memory mreq 128b mresp >1 cycle combinational 2
3 1 FSM Set-Associative Cache Memory Steps involved in executing transactions Check Tag Array hit READ Transactions Choose Victim Line clean miss dirty Read Victim from Data Array Check Tag Array hit WRITE Transactions Choose Victim Line clean miss dirty Read Victim from Data Array Write Victim to Main Mem Write Victim to Main Mem Read Line from Main Mem Read Line from Main Mem Write Line to Data Array Write Line to Data Array Read Word from Data Array Write Word to Data Array Return Word 3
4 1 FSM Set-Associative Cache Memory FSM Control Unit 4
5 2 Impact of Associativity on Microarchitecture 2. Impact of Associativity on Microarchitecture Direct Mapped Cache Microarchitecture addr tag idx off tag idx off 00 26b 2b 2b v tag Set 0 Set 1 Set 2 Set 3 = word enable hit? rd/wr ram enable wdata rdata Tag Check Data Access Tag Check Data Access Set Associative Cache Microarchitecture addr tag idx off tag idx off 00 27b 1b 2b v tag = = Set 0 Set 1 Set 0 Set 1 word enable 1b hit? rd/wr Way 0 Way 1 ram enable wdata rdata Tag Check Data Access Tag Check Data Access 5
6 2 Impact of Associativity on Microarchitecture Fully Associative Cache Microarchitecture addr tag off tag off 00 28b 2b v tag Set 0 Set 0 Set 0 Set 0 = = = = word enable 2b hit? rd/wr Way 0 Way 1 Way 2 Way 3 ram enable wdata rdata Tag Check Data Access Tag Check Data Access 6
7 3 Pipelined Cache Microcarchitecture 3. Pipelined Cache Microcarchitecture Given a sequence of three memory transactions: READ, WRITE, READ, draw a transaction vs. time diagram illustrating how these transactions execute on three different microarchitectures. Only consider hits, and assume each microarchitecture must perform two steps: MT = cache memory tag check, and MD = cache memory data access. Use Y to indicate cycle before cache access. Single-cycle cache memory (1-cycle hit latency) We do both MT and MD in a single cycle write FSM cache memory (2-cycle hit latency) We do both MT in the first state, and MD in the second state write Pipelined cache memory (2-cycle hit latency) We do both MT in the first stage, and MD in the second stage write 7
8 3 Pipelined Cache Microcarchitecture Direct-Mapped Parallel Read Hit Path addr tag idx off tag idx off 00 26b 2b 2b v tag Set 0 Set 1 Set 2 Set 3 = word enable hit? rd/wr wdata rdata Tag Check Tag Data CheckRead Access Access Tag Check Data Access Direct-Mapped Pipelined Write Hit Path addr tag idx off tag idx off 00 26b 2b 2b v tag Set 0 Set 1 Set 2 Set 3 = word enable hit? rd/wr write en wdata rdata Tag Check Tag Data CheckRead Access Access Write Access Tag Check Data Access 8
9 3 Pipelined Cache Microcarchitecture Set-Associative Parallel Read Hit Path addr tag idx off tag idx off 00 27b 1b 2b v tag = = Set 0 Set 1 Set 0 Set 1 Way 0 Way 1 1b hit? rdata Tag Check Read Access Tag Check Way 0 Way 1 Data Access Pipelined diagrams for parallel, pipelined write write 9
10 3 Pipelined Cache Microcarchitecture Resolving structural hazard with software scheduling write nop Resolving structural hazard with hardware stalling write stall_y = ( type_y == RD ) && ( type_m0 == WR ) Resolving structural hazard with hardware duplication write Resolving RAW data hazard with software scheduling Software scheduling: hazard depends on memory address, so difficult to know at compile time! Resolving RAW data hazard with hardware stalling stall_y = ( type_y == RD ) && ( type_m0 == WR ) && ( addr_y == addr_m0 ) 10
11 3 Pipelined Cache Microcarchitecture Resolving RAW data hazard with hardware bypassing We could use the previous stall signal as our bypass signal, but we will also need a new bypass path in our datapath. Draw this new bypass path on the following datapath diagram. addr tag idx off tag idx off 00 26b 2b 2b v tag Set 0 Set 1 Set 2 Set 3 = word enable hit? rd/wr write en wdata rdata Tag Check Tag Data CheckRead Access Access Write Access Tag Check Data Access 11
12 4 Integrating Processors and Caches 4. Integrating Processors and Caches Zero-Cycle Hit Latency with Tightly Coupled Interface decode cs_x cs_m cs_w br_targ jr j_targ pc_plus4 pc_f pc_sel_p stall_f addr +4 imem rdata nop pc_plus4_d kill_f stall_d ir_d stall_d ir[25:0] ir[15:0] ir[10:6] ir[25:21] ir[20:16] ir[15:0] ir[15:0] j_tgen br_tgen regfile () zext sext 16 op0 _sel_d br_targ _X op0_x op1_x sd_x op1 _sel_d bypass_from_x1 bypass_from_m bypass_from_w alu _func_x alu branch _cond result_m sd_m dmem _wen_m addr rdata wdata dmem wb_sel_m result_w Tag Check Data Access regfile _waddr_w regfile _wen_w regfile (write) Fetch (F) Decode & Reg Read (D) Execute (X) Memory (M) Writeback (W) Two-Cycle Hit Latency with Val/Rdy Interface decode cs_x cs_m0 cs_m1 cs_w br_targ jr j_targ pc_plus4 pc_sel_p!rdy pc_f0 stall_f0 memreq valrdy pc_plus4_f1 pc_plus4_d +4 imem memresp val kill_f1 ir_d nop stall_d stall_d ir[25:0] ir[15:0] ir[10:6] ir[25:21] ir[20:16] ir[15:0] ir[15:0] j_tgen br_tgen regfile () zext sext 16 op0 _sel_d br_targ _X op0_x op1_x sd_x op1 _sel_d alu _func_x alu!rdy branch _cond result_m0 result_m1 result_w memreq valrdy memresp val wb_sel_m dmem regfile _waddr_w regfile _wen_w regfile (write) bypass_from_x1 bypass_from_m bypass_from_w Tag Check Data Access Fetch (F0/F1) Decode & Reg Read (D) Execute (X) Memory (M0/M1) Writeback (W) 12
13 4 Integrating Processors and Caches Parallel Read, Pipelined Write Hit Path decode cs_x cs_m cs_w br_targ jr j_targ pc_plus4 pc_sel_p!rdy pc_f stall_f memreq valrdy +4 imem memresp val nop pc_plus4_d kill_f stall_d ir_d stall_d ir[25:0] ir[15:0] ir[10:6] ir[25:21] ir[20:16] ir[15:0] ir[15:0] j_tgen br_tgen regfile () zext sext 16 op0 _sel_d br_targ _X op0_x op1_x sd_x op1 _sel_d bypass_from_x1 bypass_from_m bypass_from_w alu _func_x alu branch _cond result_m memreq valrdy dmem _wen_m memresp val dmem wb_sel_m result_w regfile _waddr_w regfile _wen_w regfile (write) Fetch (F) Decode & Reg Read (D) Execute (X) Memory (M) Writeback (W)!rdy Tag Check Read Access New Hazards? Write Access Estimating execution time How long in cycles will it take to execute the vvadd example assuming n is 64? Assume cache is initially empty, parallel-/pipelined-write, four-way set-associative, and miss penalty is two cycles. loop: lw r12, 0(r4) lw r13, 0(r5) addu r14, r12, r13 sw r14, 0(r6) addiu r4, r4, 4 addiu r5, r5, 4 addiu r6, r6, 4 addiu r7, r7, -1 bne r7, r0, loop jr r31 13
14 4 Integrating Processors and Caches lw lw + sw +i +i +i +i bne opa opb lw lw + sw +i +i +i +i bne opa opb lw 14
15 5 Multi-Bank Cache Microarchitecture 5. Multi-Bank Cache Microarchitecture 15

16 5 Multi-Bank Cache Microarchitecture 16
17 5 Multi-Bank Cache Microarchitecture 17
 ) Cycle Time Reduce hit time Small and simple caches Reduce miss penalty Multi-level cache")
18 6 Cache Optimizations 6. Cache Optimizations Hit Cache Miss Main Memory AMAL = ( Hit Time + ( Miss Rate Miss Penalty ) ) Cycle Time Reduce hit time Small and simple caches Reduce miss penalty Multi-level cache hierarchy Prioritize s Reduce miss rate Large block size Large cache size High associativity Compiler optimizations Reduce Cycle Time: Small & Simple Caches 18


19 6 Cache Optimizations Reduce Miss Rate: Large Block Size Less tag overhead Exploit fast burst transfers from DRAM and over wide on-chip busses Can waste bandwidth if data is not used Fewer blocks more conflicts Reduce Miss Rate: Large Cache Size or High Associativity If cache size is doubled, miss rate usually drops by about 2 Direct-mapped cache of size N has about the same miss rate as a two-way set-associative cache of size N/2 19
20 6 Cache Optimizations Reduce Miss Rate: Compiler Optimizations Restructuring code affects the data block access sequence Group data accesses together to improve spatial locality Re-order data accesses to improve temporal locality Prevent data from entering the cache Useful for variales that will only be accessed once before eviction Needs mechanism for software to tell hardware not to cache data ( no-allocate instruction hits or page table bits) Kill data that will never be used again Streaming data exploits spatial locality but not temporal locality Replace into dead-cache locations Loop Interchange and Fusion What type of locality does each optimization improve? for(j=0; j < N; j++) { for(i=0; i < M; i++) { x[i][j] = 2 * x[i][j]; } } for(i=0; i < N; i++) a[i] = b[i] * c[i]; for(i=0; i < N; i++) d[i] = a[i] * c[i]; for(i=0; i < M; i++) { for(j=0; j < N; j++) { x[i][j] = 2 * x[i][j]; } } What type of locality does this improve? for(i=0; i < N; i++) { a[i] = b[i] * c[i]; d[i] = a[i] * c[i]; } What type of locality does this impro 20
21 6 Cache Optimizations Matrix Multiply with Naive Code for(i=0; i < N; i++) for(j=0; j < N; j++) { r = 0; for(k=0; k < N; k++) r = r + y[i][k] * z[k][j]; x[i][j] = r; } z k j y k x j i i Not touched Old access New access Matrix Multiply with Cache Tiling for(jj=0; jj < N; jj=jj+b) for(kk=0; kk < N; kk=kk+b) for(i=0; i < N; i++) for(j=jj; j < min(jj+b,n); j++) { r = 0; for(k=kk; k < min(kk+b,n); k++) r = r + y[i][k] * z[k][j]; x[i][j] = x[i][j] + r; } y k z k x j j i i 21
22 6 Cache Optimizations Reduce Miss Penalty: Multi-Level Caches Hit Processor L1 Cache L2 Cache L1 Miss -- L2 Hit Main Memory AMAL L1 = Hit Time of L1 + ( Miss Rate of L1 AMAL L2 ) AMAL L2 = Hit Time of L2 + ( Miss Rate of L2 Miss Penalty of L2 ) Local miss rate = misses in cache / accesses to cache Global miss rate = misses in cache / processor memory accesses Misses per instruction = misses in cache / number of instructions Reduce Miss Penalty: Multi-Level Caches Use smaller L1 is there is also a L2 Trade increased L1 miss rate for reduced L1 hit time & L1 miss penalty Reduces average access energy Use simpler write-through L1 with on-chip L2 Write-back L2 cahce absorbs write traffic, doesn t go off-chip Simplifies processor pipeline Simplifies on-chip coherence issues Inclusive Multilevel Cache Inner cache holds copy of data in outer cache External coherence is simpler Exclusive Multilevel Cache Inner cache may hold data in outer cache Swap lines between inner/outer cache on miss 22
23 6 Cache Optimizations Reduce Miss Penalty: Prioritize Reads Processor Hit Cache Write Buffer Main Memory Miss Processor not stalled on writes, and misses can go ahead of writes to main memory Write buffer may hold updated value of location needed by miss On miss, wait for write buffer to be empty Check write buffer addresses and bypass Cache Optimizations Impact on Average Memory Access Latency Hit Miss Miss Technique Time Rate Penalty HW Parallel hit 0 Pipelined write hit 1 Smaller caches ++ 0 Large block size + 0 Large cache size ++ 1 High associativity ++ 1 Compiler optimizations 0 Multi-level cache 2 Prioritize s 1 23
, five cycle latency Level 3: 3MB, 12-way s.a., 128B line, single 32B port, twelve cycle latency February 9, 2/17/2009 2010")
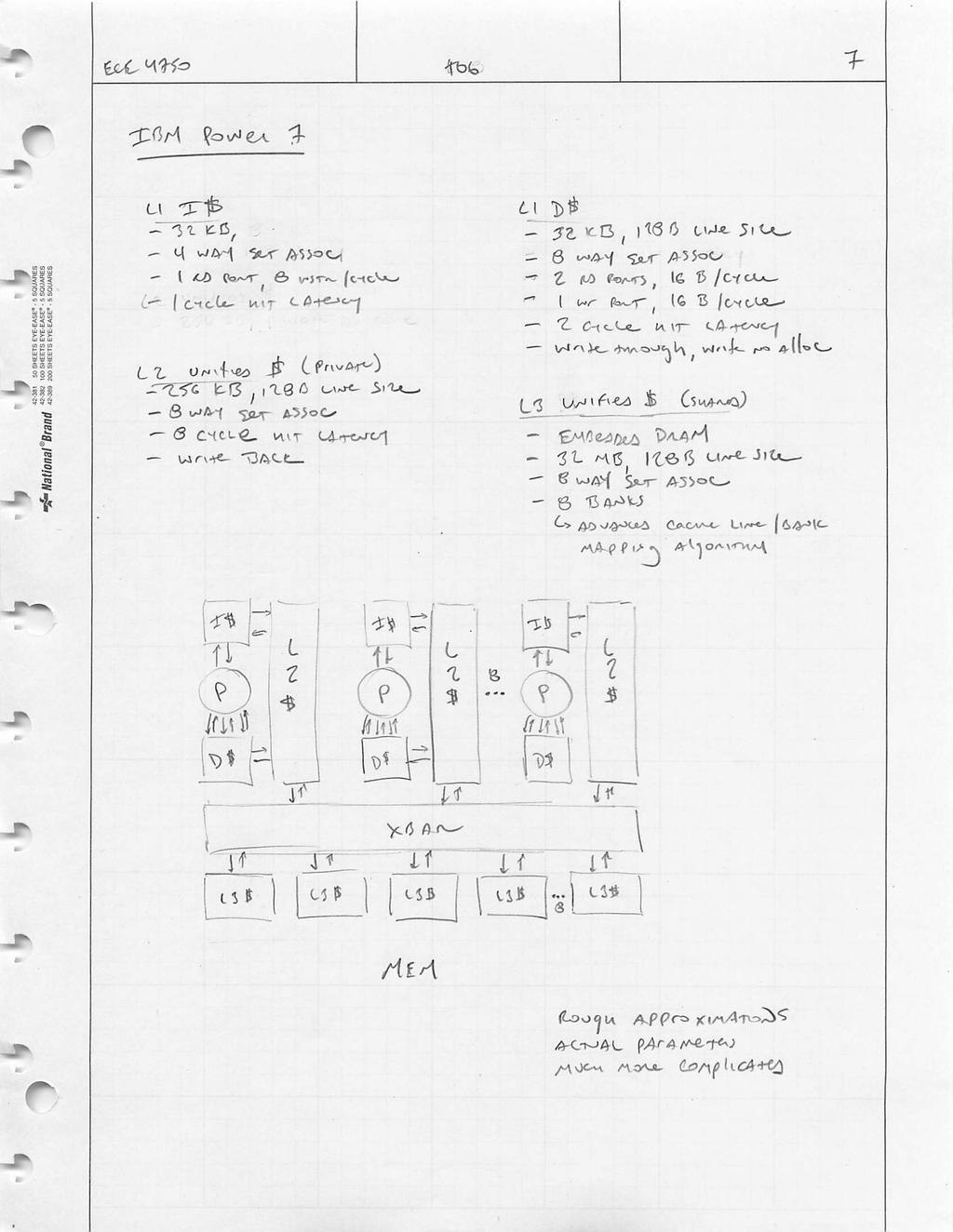
![CS152, Spring 2010 24 IBM Power-7 On-Chip Caches Power 7 On-Chip Caches [IBM 2009] 32KB L1 I$/core 32KB L1 D$/core 3-cycle latency 256KB Unified L2$/core 8-cycle](/docs-images/74/70159653/images/24-1.jpg "latency 32MB Unified Shared L3$ Embedded DRAM 25-cycle latency to local slice February 9, 2010 CS152, Spring 2010 24 25")
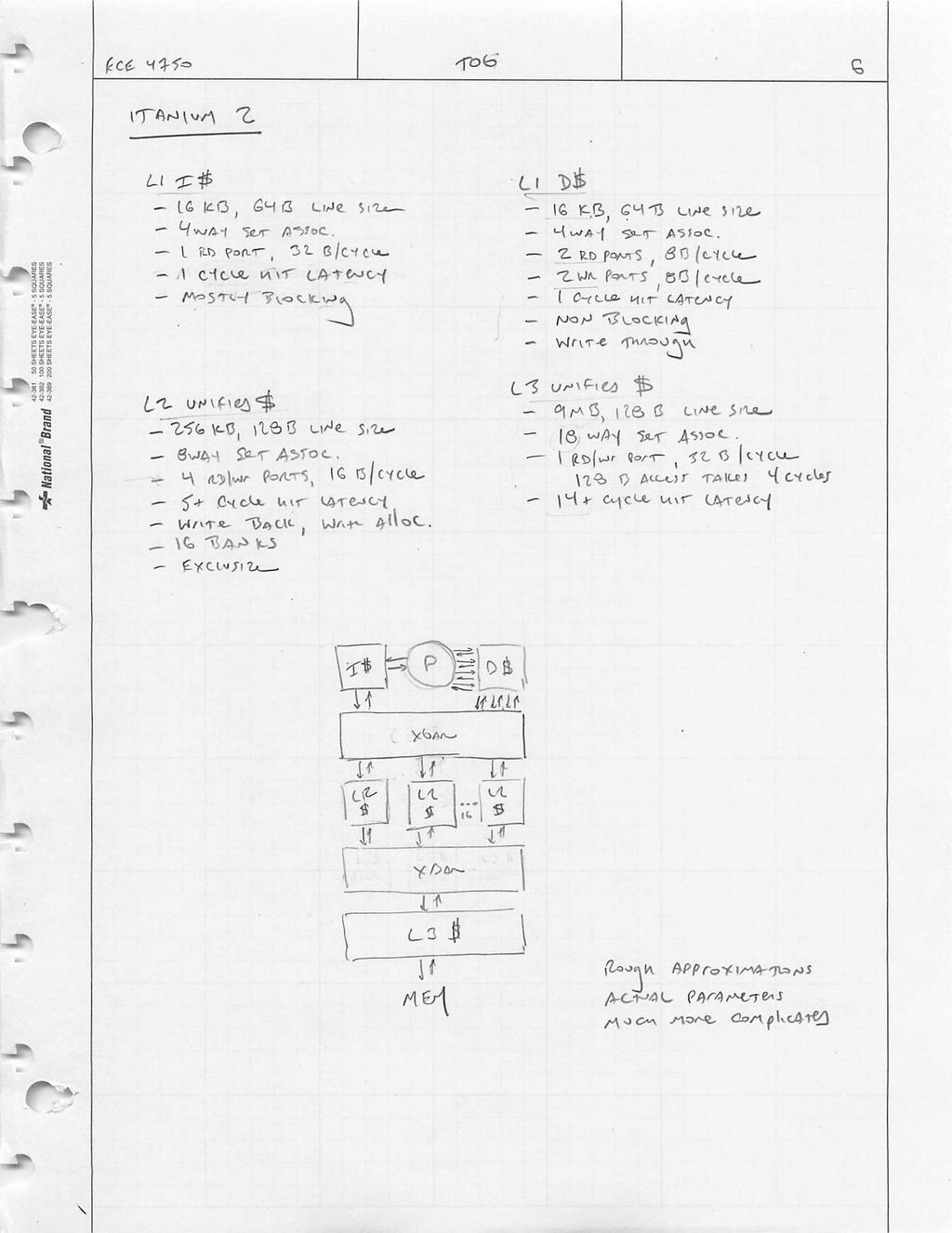
24 7 Cache Examples 7. Cache Examples Itanium-2 On-Chip Caches Intel Itanium-2 On-Chip Caches (Intel/HP, 2002) Level 1: 16KB, 4-way s.a., 64B line, quad-port (2 load+2 store), single cycle latency Level 2: 256KB, 4-way s.a, 128B line, quad-port (4 load or 4 store), five cycle latency Level 3: 3MB, 12-way s.a., 128B line, single 32B port, twelve cycle latency February 9, 2/17/ CS152, Spring IBM Power-7 On-Chip Caches Power 7 On-Chip Caches [IBM 2009] 32KB L1 I$/core 32KB L1 D$/core 3-cycle latency 256KB Unified L2$/core 8-cycle latency 32MB Unified Shared L3$ Embedded DRAM 25-cycle latency to local slice February 9, 2010 CS152, Spring
25
26
EE 660: Computer Architecture Advanced Caches
 EE 660: Computer Architecture Advanced Caches Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Based on the slides of Prof. David Wentzlaff Agenda Review Three C s Basic Cache
EE 660: Computer Architecture Advanced Caches Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa Based on the slides of Prof. David Wentzlaff Agenda Review Three C s Basic Cache
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
ECE 252 / CPS 220 Advanced Computer Architecture I. Lecture 13 Memory Part 2
 ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 13 Memory Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
ECE 252 / CPS 220 Advanced Computer Architecture I Lecture 13 Memory Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall11.html
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste!
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
ECE 4750 Computer Architecture, Fall 2018 T04 Fundamental Memory Microarchitecture
 ECE 4750 Computer Arcecture, Fall 2018 T04 Fundamental Memory Microarcecture School of Electrical and Computer Engineering Cornell University revision: 2018-10-15-16-41 1 Memory Microarcectural Design
ECE 4750 Computer Arcecture, Fall 2018 T04 Fundamental Memory Microarcecture School of Electrical and Computer Engineering Cornell University revision: 2018-10-15-16-41 1 Memory Microarcectural Design
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 13 Memory Part 2
 ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 13 Memory Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 13 Memory Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. Lecture 7 Memory III
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 7 Memory III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 7 Memory III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 3410 Computer System Organization and Programming Guest Lecture: I/O Devices
 CS 3410 Computer System Organization and Programming Guest Lecture: I/O Devices Christopher Batten Computer Systems Laboratory School of Electrical and Computer Engineering Cornell University Spring 2012
CS 3410 Computer System Organization and Programming Guest Lecture: I/O Devices Christopher Batten Computer Systems Laboratory School of Electrical and Computer Engineering Cornell University Spring 2012
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
Announcements. ECE4750/CS4420 Computer Architecture L6: Advanced Memory Hierarchy. Edward Suh Computer Systems Laboratory
 ECE4750/CS4420 Computer Architecture L6: Advanced Memory Hierarchy Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab 1 due today Reading: Chapter 5.1 5.3 2 1 Overview How to
ECE4750/CS4420 Computer Architecture L6: Advanced Memory Hierarchy Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcements Lab 1 due today Reading: Chapter 5.1 5.3 2 1 Overview How to
ECE 4750 Computer Architecture, Fall 2014 T03 Pipelined Processors
 ECE 4750 Computer Architecture, Fall 2014 T03 Pipelined Processors School of Electrical and Computer Engineering Cornell University revision: 2014-09-24-12-26 1 Pipelined Processors 3 2 RAW Data Hazards
ECE 4750 Computer Architecture, Fall 2014 T03 Pipelined Processors School of Electrical and Computer Engineering Cornell University revision: 2014-09-24-12-26 1 Pipelined Processors 3 2 RAW Data Hazards
Lecture 11 Cache. Peng Liu.
 Lecture 11 Cache Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Associative Cache Example 3 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative
Lecture 11 Cache Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Associative Cache Example 3 Associativity Example Compare 4-block caches Direct mapped, 2-way set associative, fully associative
Advanced Caching Techniques
 Advanced Caching Approaches to improving memory system performance eliminate memory accesses/operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide
Advanced Caching Approaches to improving memory system performance eliminate memory accesses/operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Memory Hierarchy. 2/18/2016 CS 152 Sec6on 5 Colin Schmidt
 Memory Hierarchy 2/18/2016 CS 152 Sec6on 5 Colin Schmidt Agenda Review Memory Hierarchy Lab 2 Ques6ons Return Quiz 1 Latencies Comparison Numbers L1 Cache 0.5 ns L2 Cache 7 ns 14x L1 cache Main Memory
Memory Hierarchy 2/18/2016 CS 152 Sec6on 5 Colin Schmidt Agenda Review Memory Hierarchy Lab 2 Ques6ons Return Quiz 1 Latencies Comparison Numbers L1 Cache 0.5 ns L2 Cache 7 ns 14x L1 cache Main Memory
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
L2 cache provides additional on-chip caching space. L2 cache captures misses from L1 cache. Summary
 HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
ECE 4750 Computer Architecture, Fall 2014 T01 Single-Cycle Processors
 ECE 4750 Computer Architecture, Fall 2014 T01 Single-Cycle Processors School of Electrical and Computer Engineering Cornell University revision: 2014-09-03-17-21 1 Instruction Set Architecture 2 1.1. IBM
ECE 4750 Computer Architecture, Fall 2014 T01 Single-Cycle Processors School of Electrical and Computer Engineering Cornell University revision: 2014-09-03-17-21 1 Instruction Set Architecture 2 1.1. IBM
10/16/2017. Miss Rate: ABC. Classifying Misses: 3C Model (Hill) Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache
 Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache") Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
Advanced Caching Techniques
 Advanced Caching Approaches to improving memory system performance eliminate memory operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide memory
Advanced Caching Approaches to improving memory system performance eliminate memory operations decrease the number of misses decrease the miss penalty decrease the cache/memory access times hide memory
Inside out of your computer memories (III) Hung-Wei Tseng
 Hung-Wei Tseng") Inside out of your computer memories (III) Hung-Wei Tseng Why memory hierarchy? CPU main memory lw $t2, 0($a0) add $t3, $t2, $a1 addi $a0, $a0, 4 subi $a1, $a1, 1 bne $a1, LOOP lw $t2, 0($a0) add $t3,
Inside out of your computer memories (III) Hung-Wei Tseng Why memory hierarchy? CPU main memory lw $t2, 0($a0) add $t3, $t2, $a1 addi $a0, $a0, 4 subi $a1, $a1, 1 bne $a1, LOOP lw $t2, 0($a0) add $t3,
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science CPUtime = IC CPI Execution + Memory accesses Instruction
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science CPUtime = IC CPI Execution + Memory accesses Instruction
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Cache Performance (H&P 5.3; 5.5; 5.6)
") Cache Performance (H&P 5.3; 5.5; 5.6) Memory system and processor performance: CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st
Cache Performance (H&P 5.3; 5.5; 5.6) Memory system and processor performance: CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st
EC 513 Computer Architecture
 EC 513 Computer Architecture Cache Organization Prof. Michel A. Kinsy The course has 4 modules Module 1 Instruction Set Architecture (ISA) Simple Pipelining and Hazards Module 2 Superscalar Architectures
EC 513 Computer Architecture Cache Organization Prof. Michel A. Kinsy The course has 4 modules Module 1 Instruction Set Architecture (ISA) Simple Pipelining and Hazards Module 2 Superscalar Architectures
Announcements. ! Previous lecture. Caches. Inf3 Computer Architecture
 Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
Announcements! Previous lecture Caches Inf3 Computer Architecture - 2016-2017 1 Recap: Memory Hierarchy Issues! Block size: smallest unit that is managed at each level E.g., 64B for cache lines, 4KB for
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 08: Caches III Shuai Wang Department of Computer Science and Technology Nanjing University Improve Cache Performance Average memory access time (AMAT): AMAT =
Computer Architecture Spring 2016 Lecture 08: Caches III Shuai Wang Department of Computer Science and Technology Nanjing University Improve Cache Performance Average memory access time (AMAT): AMAT =
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
COSC 6385 Computer Architecture. - Memory Hierarchies (II)
") COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3
 Caches Part 3") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Bernhard Boser & Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/ 10/24/16 Fall 2016 - Lecture #16 1 Software
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Bernhard Boser & Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/ 10/24/16 Fall 2016 - Lecture #16 1 Software
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Why memory hierarchy? Memory hierarchy. Memory hierarchy goals. CS2410: Computer Architecture. L1 cache design. Sangyeun Cho
 Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Cache Memory COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
EECS151/251A Spring 2018 Digital Design and Integrated Circuits. Instructors: John Wawrzynek and Nick Weaver. Lecture 19: Caches EE141
 EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
EECS151/251A Spring 2018 Digital Design and Integrated Circuits Instructors: John Wawrzynek and Nick Weaver Lecture 19: Caches Cache Introduction 40% of this ARM CPU is devoted to SRAM cache. But the role
CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]
![CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]](/thumbs/73/69213006.jpg "CSF Cache Introduction. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]") CSF Cache Introduction [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user with as much
CSF Cache Introduction [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user with as much
EITF20: Computer Architecture Part 5.1.1: Virtual Memory
 EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
Cache Performance! ! Memory system and processor performance:! ! Improving memory hierarchy performance:! CPU time = IC x CPI x Clock time
 Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
Cache Performance!! Memory system and processor performance:! CPU time = IC x CPI x Clock time CPU performance eqn. CPI = CPI ld/st x IC ld/st IC + CPI others x IC others IC CPI ld/st = Pipeline time +
ECE 4750 Computer Architecture, Fall 2017 T05 Integrating Processors and Memories
 ECE 4750 Computer Architecture, Fall 2017 T05 Integrating Processors and Memories School of Electrical and Computer Engineering Cornell University revision: 2017-10-17-12-06 1 Processor and L1 Cache Interface
ECE 4750 Computer Architecture, Fall 2017 T05 Integrating Processors and Memories School of Electrical and Computer Engineering Cornell University revision: 2017-10-17-12-06 1 Processor and L1 Cache Interface
Mo Money, No Problems: Caches #2...
 Mo Money, No Problems: Caches #2... 1 Reminder: Cache Terms... Cache: A small and fast memory used to increase the performance of accessing a big and slow memory Uses temporal locality: The tendency to
Mo Money, No Problems: Caches #2... 1 Reminder: Cache Terms... Cache: A small and fast memory used to increase the performance of accessing a big and slow memory Uses temporal locality: The tendency to
Chapter 5. Topics in Memory Hierachy. Computer Architectures. Tien-Fu Chen. National Chung Cheng Univ.
 Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
In-order vs. Out-of-order Execution. In-order vs. Out-of-order Execution
 In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
Realistic Memories and Caches
 Realistic Memories and Caches Li-Shiuan Peh Computer Science & Artificial Intelligence Lab. Massachusetts Institute of Technology L13-1 Three-Stage SMIPS Epoch Register File stall? PC +4 fr Decode Execute
Realistic Memories and Caches Li-Shiuan Peh Computer Science & Artificial Intelligence Lab. Massachusetts Institute of Technology L13-1 Three-Stage SMIPS Epoch Register File stall? PC +4 fr Decode Execute
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
MEMORY HIERARCHY DESIGN. B649 Parallel Architectures and Programming
 MEMORY HIERARCHY DESIGN B649 Parallel Architectures and Programming Basic Optimizations Average memory access time = Hit time + Miss rate Miss penalty Larger block size to reduce miss rate Larger caches
MEMORY HIERARCHY DESIGN B649 Parallel Architectures and Programming Basic Optimizations Average memory access time = Hit time + Miss rate Miss penalty Larger block size to reduce miss rate Larger caches
Lecture 9: Improving Cache Performance: Reduce miss rate Reduce miss penalty Reduce hit time
 Lecture 9: Improving Cache Performance: Reduce miss rate Reduce miss penalty Reduce hit time Review ABC of Cache: Associativity Block size Capacity Cache organization Direct-mapped cache : A =, S = C/B
Lecture 9: Improving Cache Performance: Reduce miss rate Reduce miss penalty Reduce hit time Review ABC of Cache: Associativity Block size Capacity Cache organization Direct-mapped cache : A =, S = C/B
CS/ECE 250 Computer Architecture
 Computer Architecture Caches and Memory Hierarchies Benjamin Lee Duke University Some slides derived from work by Amir Roth (Penn), Alvin Lebeck (Duke), Dan Sorin (Duke) 2013 Alvin R. Lebeck from Roth
Computer Architecture Caches and Memory Hierarchies Benjamin Lee Duke University Some slides derived from work by Amir Roth (Penn), Alvin Lebeck (Duke), Dan Sorin (Duke) 2013 Alvin R. Lebeck from Roth
Why Care About Memory Hierarchy?
 98 98 98 98 98 98 98 98 988 989 99 99 99 99 99 99 99 99 998 999 Performance EEC 8 Computer Architecture Memory Hierarchy Design (I) Department of Electrical Engineering and Computer Science Cleveland State
98 98 98 98 98 98 98 98 988 989 99 99 99 99 99 99 99 99 998 999 Performance EEC 8 Computer Architecture Memory Hierarchy Design (I) Department of Electrical Engineering and Computer Science Cleveland State
What is Cache Memory? EE 352 Unit 11. Motivation for Cache Memory. Memory Hierarchy. Cache Definitions Cache Address Mapping Cache Performance
 What is EE 352 Unit 11 Definitions Address Mapping Performance memory is a small, fast memory used to hold of data that the processor will likely need to access in the near future sits between the processor
What is EE 352 Unit 11 Definitions Address Mapping Performance memory is a small, fast memory used to hold of data that the processor will likely need to access in the near future sits between the processor
CS24: INTRODUCTION TO COMPUTING SYSTEMS. Spring 2015 Lecture 15
 CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2015 Lecture 15 LAST TIME! Discussed concepts of locality and stride Spatial locality: programs tend to access values near values they have already accessed
CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2015 Lecture 15 LAST TIME! Discussed concepts of locality and stride Spatial locality: programs tend to access values near values they have already accessed
CS422 Computer Architecture
 CS422 Computer Architecture Spring 2004 Lecture 19, 04 Mar 2004 Bhaskaran Raman Department of CSE IIT Kanpur http://web.cse.iitk.ac.in/~cs422/index.html Topics for Today Cache Performance Cache Misses:
CS422 Computer Architecture Spring 2004 Lecture 19, 04 Mar 2004 Bhaskaran Raman Department of CSE IIT Kanpur http://web.cse.iitk.ac.in/~cs422/index.html Topics for Today Cache Performance Cache Misses:
Lecture 16: Cache in Context (Uniprocessor) James C. Hoe Department of ECE Carnegie Mellon University
 James C. Hoe Department of ECE Carnegie Mellon University") 18 447 Lecture 16: Cache in Context (Uniprocessor) James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L16 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Your goal today Housekeeping understand
18 447 Lecture 16: Cache in Context (Uniprocessor) James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L16 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Your goal today Housekeeping understand
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007
 CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
Improving Cache Performance. Dr. Yitzhak Birk Electrical Engineering Department, Technion
 Improving Cache Performance Dr. Yitzhak Birk Electrical Engineering Department, Technion 1 Cache Performance CPU time = (CPU execution clock cycles + Memory stall clock cycles) x clock cycle time Memory
Improving Cache Performance Dr. Yitzhak Birk Electrical Engineering Department, Technion 1 Cache Performance CPU time = (CPU execution clock cycles + Memory stall clock cycles) x clock cycle time Memory
CS3350B Computer Architecture
 CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
14:332:331. Week 13 Basics of Cache
 14:332:331 Computer Architecture and Assembly Language Fall 2003 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Lec20.1 Fall 2003 Head
14:332:331 Computer Architecture and Assembly Language Fall 2003 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Lec20.1 Fall 2003 Head
Lecture: Large Caches, Virtual Memory. Topics: cache innovations (Sections 2.4, B.4, B.5)
") Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 More Cache Basics caches are split as instruction and data; L2 and L3 are unified The /L2 hierarchy can be inclusive,
Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 More Cache Basics caches are split as instruction and data; L2 and L3 are unified The /L2 hierarchy can be inclusive,
14:332:331. Week 13 Basics of Cache
 14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
14:332:331 Computer Architecture and Assembly Language Spring 2006 Week 13 Basics of Cache [Adapted from Dave Patterson s UCB CS152 slides and Mary Jane Irwin s PSU CSE331 slides] 331 Week131 Spring 2006
Caches Part 1. Instructor: Sören Schwertfeger. School of Information Science and Technology SIST
 CS 110 Computer Architecture Caches Part 1 Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's
CS 110 Computer Architecture Caches Part 1 Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's
ECE 2300 Digital Logic & Computer Organization. Caches
 ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
EEC 170 Computer Architecture Fall Cache Introduction Review. Review: The Memory Hierarchy. The Memory Hierarchy: Why Does it Work?
 EEC 17 Computer Architecture Fall 25 Introduction Review Review: The Hierarchy Take advantage of the principle of locality to present the user with as much memory as is available in the cheapest technology
EEC 17 Computer Architecture Fall 25 Introduction Review Review: The Hierarchy Take advantage of the principle of locality to present the user with as much memory as is available in the cheapest technology
SOLUTION. Midterm #1 February 26th, 2018 Professor Krste Asanovic Name:
 SOLUTION Notes: CS 152 Computer Architecture and Engineering CS 252 Graduate Computer Architecture Midterm #1 February 26th, 2018 Professor Krste Asanovic Name: I am taking CS152 / CS252 This is a closed
SOLUTION Notes: CS 152 Computer Architecture and Engineering CS 252 Graduate Computer Architecture Midterm #1 February 26th, 2018 Professor Krste Asanovic Name: I am taking CS152 / CS252 This is a closed
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3
 Caches Part 3") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/ 10/19/17 Fall 2017 - Lecture #16 1 Parallel
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H. Katz http://inst.eecs.berkeley.edu/~cs61c/ 10/19/17 Fall 2017 - Lecture #16 1 Parallel
CS24: INTRODUCTION TO COMPUTING SYSTEMS. Spring 2017 Lecture 15
 CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2017 Lecture 15 LAST TIME: CACHE ORGANIZATION Caches have several important parameters B = 2 b bytes to store the block in each cache line S = 2 s cache sets
CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2017 Lecture 15 LAST TIME: CACHE ORGANIZATION Caches have several important parameters B = 2 b bytes to store the block in each cache line S = 2 s cache sets
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 6A: Cache Design Avinash Kodi, kodi@ohioedu Agenda 2 Review: Memory Hierarchy Review: Cache Organization Direct-mapped Set- Associative Fully-Associative 1 Major
Caches and Memory Hierarchy: Review. UCSB CS240A, Winter 2016
 Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
10/19/17. You Are Here! Review: Direct-Mapped Cache. Typical Memory Hierarchy
 CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H Katz http://insteecsberkeleyedu/~cs6c/ Parallel Requests Assigned to computer eg, Search
CS 6C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 3 Instructors: Krste Asanović & Randy H Katz http://insteecsberkeleyedu/~cs6c/ Parallel Requests Assigned to computer eg, Search
Caches and Memory Hierarchy: Review. UCSB CS240A, Fall 2017
 Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
ECE 4750 Computer Architecture, Fall 2017 T03 Fundamental Memory Concepts
 ECE 4750 Computer Architecture, Fall 2017 T03 Fundamental Memory Concepts School of Electrical and Computer Engineering Cornell University revision: 2017-09-26-15-52 1 Memory/Library Analogy 2 1.1. Three
ECE 4750 Computer Architecture, Fall 2017 T03 Fundamental Memory Concepts School of Electrical and Computer Engineering Cornell University revision: 2017-09-26-15-52 1 Memory/Library Analogy 2 1.1. Three
Classification Steady-State Cache Misses: Techniques To Improve Cache Performance:
 #1 Lec # 9 Winter 2003 1-21-2004 Classification Steady-State Cache Misses: The Three C s of cache Misses: Compulsory Misses Capacity Misses Conflict Misses Techniques To Improve Cache Performance: Reduce
#1 Lec # 9 Winter 2003 1-21-2004 Classification Steady-State Cache Misses: The Three C s of cache Misses: Compulsory Misses Capacity Misses Conflict Misses Techniques To Improve Cache Performance: Reduce
Lecture: Cache Hierarchies. Topics: cache innovations (Sections B.1-B.3, 2.1)
") Lecture: Cache Hierarchies Topics: cache innovations (Sections B.1-B.3, 2.1) 1 Types of Cache Misses Compulsory misses: happens the first time a memory word is accessed the misses for an infinite cache
Lecture: Cache Hierarchies Topics: cache innovations (Sections B.1-B.3, 2.1) 1 Types of Cache Misses Compulsory misses: happens the first time a memory word is accessed the misses for an infinite cache
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 1
 Caches Part 1") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 1 Instructors: Nicholas Weaver & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/ Components of a Computer Processor
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Caches Part 1 Instructors: Nicholas Weaver & Vladimir Stojanovic http://inst.eecs.berkeley.edu/~cs61c/ Components of a Computer Processor
ECE 4750 Computer Architecture, Fall 2016 T02 Fundamental Processor Microarchitecture
 ECE 4750 Computer Architecture, Fall 2016 T02 Fundamental Processor Microarchitecture School of Electrical and Computer Engineering Cornell University revision: 2016-10-12-21-32 1 Processor Microarchitectural
ECE 4750 Computer Architecture, Fall 2016 T02 Fundamental Processor Microarchitecture School of Electrical and Computer Engineering Cornell University revision: 2016-10-12-21-32 1 Processor Microarchitectural
Advanced Computer Architecture
 ECE 563 Advanced Computer Architecture Fall 2009 Lecture 3: Memory Hierarchy Review: Caches 563 L03.1 Fall 2010 Since 1980, CPU has outpaced DRAM... Four-issue 2GHz superscalar accessing 100ns DRAM could
ECE 563 Advanced Computer Architecture Fall 2009 Lecture 3: Memory Hierarchy Review: Caches 563 L03.1 Fall 2010 Since 1980, CPU has outpaced DRAM... Four-issue 2GHz superscalar accessing 100ns DRAM could
Lec 13: Linking and Memory. Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University. Announcements
 Lec 13: Linking and Memory Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University PA 2 is out Due on Oct 22 nd Announcements Prelim Oct 23 rd, 7:30-9:30/10:00 All content up to Lecture on Oct
Lec 13: Linking and Memory Kavita Bala CS 3410, Fall 2008 Computer Science Cornell University PA 2 is out Due on Oct 22 nd Announcements Prelim Oct 23 rd, 7:30-9:30/10:00 All content up to Lecture on Oct
Agenda. EE 260: Introduction to Digital Design Memory. Naive Register File. Agenda. Memory Arrays: SRAM. Memory Arrays: Register File
 EE 260: Introduction to Digital Design Technology Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa 2 Technology Naive Register File Write Read clk Decoder Read Write 3 4 Arrays:
EE 260: Introduction to Digital Design Technology Yao Zheng Department of Electrical Engineering University of Hawaiʻi at Mānoa 2 Technology Naive Register File Write Read clk Decoder Read Write 3 4 Arrays:
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
CSE 431 Computer Architecture Fall Chapter 5A: Exploiting the Memory Hierarchy, Part 1
 CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
A Cache Hierarchy in a Computer System
 A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
Show Me the $... Performance And Caches
 Show Me the $... Performance And Caches 1 CPU-Cache Interaction (5-stage pipeline) PCen 0x4 Add bubble PC addr inst hit? Primary Instruction Cache IR D To Memory Control Decode, Register Fetch E A B MD1
Show Me the $... Performance And Caches 1 CPU-Cache Interaction (5-stage pipeline) PCen 0x4 Add bubble PC addr inst hit? Primary Instruction Cache IR D To Memory Control Decode, Register Fetch E A B MD1
Lecture 11 Cache and Virtual Memory
 Lecture 11 Cache and Virtual Memory Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Tag & Index with Set-Associative Caches Assume a 2 n -byte cache with 2 m -byte blocks that is 2 a set-associative
Lecture 11 Cache and Virtual Memory Peng Liu liupeng@zju.edu.cn 1 Associative Cache Example 2 Tag & Index with Set-Associative Caches Assume a 2 n -byte cache with 2 m -byte blocks that is 2 a set-associative
MEMORY HIERARCHY BASICS. B649 Parallel Architectures and Programming
 MEMORY HIERARCHY BASICS B649 Parallel Architectures and Programming BASICS Why Do We Need Caches? 3 Overview 4 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address
MEMORY HIERARCHY BASICS B649 Parallel Architectures and Programming BASICS Why Do We Need Caches? 3 Overview 4 Terminology cache virtual memory memory stall cycles direct mapped valid bit block address
6.823 Computer System Architecture Datapath for DLX Problem Set #2
 6.823 Computer System Architecture Datapath for DLX Problem Set #2 Spring 2002 Students are allowed to collaborate in groups of up to 3 people. A group hands in only one copy of the solution to a problem
6.823 Computer System Architecture Datapath for DLX Problem Set #2 Spring 2002 Students are allowed to collaborate in groups of up to 3 people. A group hands in only one copy of the solution to a problem
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
DECstation 5000 Miss Rates. Cache Performance Measures. Example. Cache Performance Improvements. Types of Cache Misses. Cache Performance Equations
 DECstation 5 Miss Rates Cache Performance Measures % 3 5 5 5 KB KB KB 8 KB 6 KB 3 KB KB 8 KB Cache size Direct-mapped cache with 3-byte blocks Percentage of instruction references is 75% Instr. Cache Data
DECstation 5 Miss Rates Cache Performance Measures % 3 5 5 5 KB KB KB 8 KB 6 KB 3 KB KB 8 KB Cache size Direct-mapped cache with 3-byte blocks Percentage of instruction references is 75% Instr. Cache Data
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
ECE 2300 Digital Logic & Computer Organization. More Caches Measuring Performance
 ECE 23 Digital Logic & Computer Organization Spring 28 More s Measuring Performance Announcements HW7 due tomorrow :59pm Prelab 5(c) due Saturday 3pm Lab 6 (last one) released HW8 (last one) to be released
ECE 23 Digital Logic & Computer Organization Spring 28 More s Measuring Performance Announcements HW7 due tomorrow :59pm Prelab 5(c) due Saturday 3pm Lab 6 (last one) released HW8 (last one) to be released
ECE 4750 Computer Architecture, Fall 2015 T16 Advanced Processors: VLIW Processors
 ECE 4750 Computer Architecture, Fall 2015 T16 Advanced Processors: VLIW Processors School of Electrical and Computer Engineering Cornell University revision: 2015-11-30-13-42 1 Motivating VLIW Processors
ECE 4750 Computer Architecture, Fall 2015 T16 Advanced Processors: VLIW Processors School of Electrical and Computer Engineering Cornell University revision: 2015-11-30-13-42 1 Motivating VLIW Processors
SE-292 High Performance Computing. Memory Hierarchy. R. Govindarajan Memory Hierarchy
 SE-292 High Performance Computing Memory Hierarchy R. Govindarajan govind@serc Memory Hierarchy 2 1 Memory Organization Memory hierarchy CPU registers few in number (typically 16/32/128) subcycle access
SE-292 High Performance Computing Memory Hierarchy R. Govindarajan govind@serc Memory Hierarchy 2 1 Memory Organization Memory hierarchy CPU registers few in number (typically 16/32/128) subcycle access
Cache performance Outline
 Cache performance 1 Outline Metrics Performance characterization Cache optimization techniques 2 Page 1 Cache Performance metrics (1) Miss rate: Neglects cycle time implications Average memory access time
Cache performance 1 Outline Metrics Performance characterization Cache optimization techniques 2 Page 1 Cache Performance metrics (1) Miss rate: Neglects cycle time implications Average memory access time
Lecture 12. Memory Design & Caches, part 2. Christos Kozyrakis Stanford University
 Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
CS 61C: Great Ideas in Computer Architecture. Lecture 13: Pipelining. Krste Asanović & Randy Katz
 CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS252 Prerequisite Quiz. Solutions Fall 2007
 CS252 Prerequisite Quiz Krste Asanovic Solutions Fall 2007 Problem 1 (29 points) The followings are two code segments written in MIPS64 assembly language: Segment A: Loop: LD r5, 0(r1) # r5 Mem[r1+0] LD
CS252 Prerequisite Quiz Krste Asanovic Solutions Fall 2007 Problem 1 (29 points) The followings are two code segments written in MIPS64 assembly language: Segment A: Loop: LD r5, 0(r1) # r5 Mem[r1+0] LD
COSC 6385 Computer Architecture - Memory Hierarchy Design (III)
") COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses