Numerical Modelling in Fortran: day 7. Paul Tackley, 2017
|
|
|
- Dorthy Freeman
- 6 years ago
- Views:
Transcription

1 Numerical Modelling in Fortran: day 7 Paul Tackley, 2017
2 Today s Goals 1. Makefiles 2. Intrinsic functions 3. Optimisation: Making your code run as fast as possible 4. Combine advection-diffusion and Poisson solvers to make a convection simulation program
3 Projects: start thinking about Agree topic with me before final lecture
4 Makefiles If your programs are split over several files, it may be easiest to write instructions for compiling them in a makefile (this applies mainly to unix-like systems) This also makes sure that the various options you use remain the same The makefile defines dependencies, so it only recompiles source files that have changed since the last compilation See manual pages for full information
5 Example makefile FFLAGS lists flags to be used when compiling fortran : gives dependencies USAGE: Just type in make or make myproject
6 Intrinsic functions There are many more intrinsic functions than we have used! It is good to browse a list so that you know what is available, for example at ml This doesn t list cpu_time(), which is useful for checking how long parts of the code take
7 Speed and optimization Running large simulations can take a long time => speed is important. Optimization=making it run as fast as possible First consideration: use the most efficient algorithm, e.g., multigrid Then: get code working using code that is easyto-read and debug Finally: Find out which part(s) of the code are taking the most time, and rewrite those to optimize speed Code written for maximum speed may not be the most legible or compact!
8 Manual versus automatic optimisation Many steps can be done automatically by the compiler. Use appropriate compiler options (see documentation), e.g., -O2, -O3: selects a bunch of optimisations -unroll unroll loops etc. (see compiler documentation) Some need to be done manually. In general, try to write code in such a way that the compiler can optimise it!
9 Example of compiler optimisation Solution convection code (this week), test case, 32-bit, gfortran, macbook pro Options Time (s) None O O O O2 ffast-math O2 ffast-math ftree-vectorize
10 Manual optimization step 1: Identify bottlenecks The 90/10 law: 90% of the time is spent in 10% of the code. Find this 10% and work on that! e.g., Use a profiler. Or put cpu_time() statements in to time different subroutines or loops Usually, most of the time is spent in loops. In our multigrid code it is probably the loops that update the field and calculate the residue. Optimization of loops is the most important consideration.
11 To understand optimization it is important to understand how the CPU works Two aspects are particularly important: Cache Pipelining
12 Cache memory Fast, small memory close to a CPU that stores copies of data in the main memory Substantially reduces latency of memory accesses. Designing code such that data fits in cache can greatly improve speed. Good design includes memory locality, and not-too-large size of arrays.
13 Athlon64 multiple caches
14 Tips to improve cache usage Memory locality: data within each block should be close together (small stride). Appropriate data structures and ordering of nested loops. (see later) Arrays shouldn t be too large. e.g., for a matrix*matrix multiply, split each matrix into blocks and treat blocks separately
 Executing an instruction takes several steps.")
15 CPU architecture and pipelining (images from Executing an instruction takes several steps. In the simplest case these are done sequentially, e.g., 15 cycles to perform 3 instructions!

16 Pipelining If each step can be done independently, then up to 1 instruction/cycle can be sustained => 5* faster Basic 5-stage pipline. Like an assembly line. Several cycles are needed to start and end the pipeline.

17 Superscalar pipeline More than 1 instruction per cycle (2 in the example below)
18 Pipelining in practice Done by the compiler, but must write code to maximize success Branches (e.g., if ) cause the pipeline to flush and have to restart Avoid branching inside loops! Helps if data is in cache
19 Summary Goal is to maximize use of cache and pipelining. Design code to reuse data in cache as much as possible, and to stream data efficiently through the CPU (pipeline / vectorisation)
20 More information Wikipedia pages ence) l ETH course How to write fast numerical code (Frühjahrssemester)
21 Time taken for various operations Slowest: sin, cos, **, etc. sqrt / * fastest: + - Simplify equations in loops to minimize number of operators, particularly slow ones!
 Remove")

22 Loop optimization (1) Remove conditional statements from loops! SLOW FAST

23 Loop optimization (2) Data locality: fastest if processing nearby (e.g., consecutive) locations in memory Fortran arrays: first index accesses consecutive locations (opposite in C) Order loops such that first index loop is innermost, 2nd index loop is next, etc. SLOW FAST

24 Loop optimization (3) Unrolling: eliminate loop overhead by writing loops as lots of separate operations Partial unrolling: reduces number of cycles, reducing loop overhead Original Unrolled by factor 4 This can be done automatically by the compiler


25 Loop optimization (4) fusing + unrolling: see below Original loop Partial unrolling +fusion (reduces number of writes by factor 2)
26 Loop optimization (5): other things simplify calculated indices use registers for temporary results Put invariant expressions (things that don t change each iteration) outside the loop Loop blocking/tiling: splitting a big loop or nested loops into smaller ones in order to fit into cache.
27 Other Optimizations Use binary I/O not ascii Avoid splitting code into excessive procedures. Overhead associated with calling functions/subroutines Reduces ability of compiler to do global optimizations Use procedure inlining (done by compiler): compiler inserts a copy of the function/subroutine each time it is called Use simple data structures in major loops to aid compiler optimizations (defined types may slow things down)
28 Now back to iterative solvers
29 Goal for today s exercise: Calculate velocity field from temperature field =>convection e.g., for highly viscous flow (e.g., Earth s mantle) with constant viscosity (P=pressure, Ra=Rayleigh number): P + 2 v = Ra.Tŷ Substituting the streamfunction for velocity, we get: ( v x,v ) y = ψ ψ, y x writing as 2 Poisson equations: 2 ψ = ω 4 ψ = Ra T x the streamfunction-vorticity formulation 2 ω = Ra T x (y points up)

30 Example of convection (in 3-D)
31 P + 2 v = Ra.Tŷ P x + 2 v x = 0 Take Mathematical aside Is a vector equation with x and y parts: P y + 2 v y = Ra.T (1) (2) (1) y (2) x v 2 x y v y x = Ra T x Use streamfunction: 2 ψ 2 y + 2 ψ 2 x 2 = 2 2 ψ = Ra T x This is the z-component of the curl of the momentum equation: F = F z y F y z ˆx + F x z F z x ŷ + F y x F x y ẑ
32 Combine advection-diffusion and Poisson solver routines Initialise T=random or spike or... S, W=0 grid spacing h=1/(ny-1) and diffusive timestep Timestep until desired time is reached calculate right-hand side=ra*dt/dx Poisson solve to get W from rhs Poisson solve to get S from W calculate V from S calculate advective timestep and min(adv,diff) take advection and diffusion time step t=t+dt: have we finished? If not, loop again. Use multigrid solver Use existing adv-diff routines
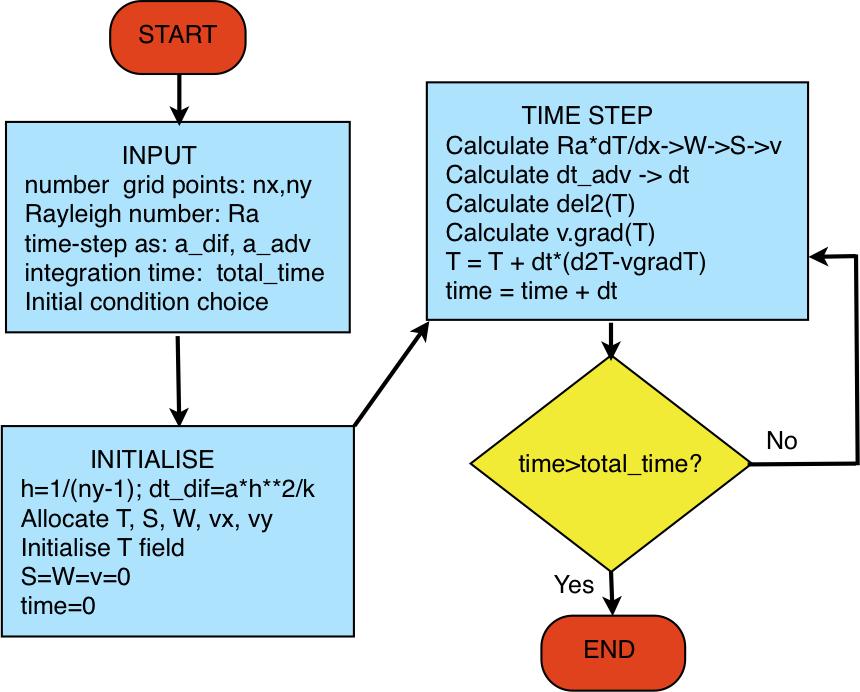
33
34 Program definition Input parameters: nx,ny : number of grid points (y=vertical, grid spacing is the same, i.e., dx=dy=h) Ra: Rayleigh number (typical range 1e3-1e7) total_time: large enough to reach stable state Boundary conditions T: as before, T=1 at bottom, 0 at top, dt/dx=0 at sides S and W: 0 at all boundaries Example structure Module with Poisson solver routines Module with 2_deriv, v_gradt, S_to_V routines main program Try to write frames at different times and make an animation!
35 Exercise Get everything together and run a test case with nx=257, ny=65 (i.e., aspect ratio 4) Ra=1e5 total_time=0.1 err=1.e-3 Random initial T field code, plots and parameter file for this case. Due next week:

36 Should look something like this Note: It won t look exactly the same, due to the random initial T field. You might get 2 or 4 cells instead of 3.
Numerical Modelling in Fortran: day 6. Paul Tackley, 2017
 Numerical Modelling in Fortran: day 6 Paul Tackley, 2017 Today s Goals 1. Learn about pointers, generic procedures and operators 2. Learn about iterative solvers for boundary value problems, including
Numerical Modelling in Fortran: day 6 Paul Tackley, 2017 Today s Goals 1. Learn about pointers, generic procedures and operators 2. Learn about iterative solvers for boundary value problems, including
Numerical Modelling in Fortran: day 3. Paul Tackley, 2017
 Numerical Modelling in Fortran: day 3 Paul Tackley, 2017 Today s Goals 1. Review subroutines/functions and finitedifference approximation from last week 2. Review points from reading homework Select case,
Numerical Modelling in Fortran: day 3 Paul Tackley, 2017 Today s Goals 1. Review subroutines/functions and finitedifference approximation from last week 2. Review points from reading homework Select case,
Shared Memory Programming With OpenMP Exercise Instructions
 Shared Memory Programming With OpenMP Exercise Instructions John Burkardt Interdisciplinary Center for Applied Mathematics & Information Technology Department Virginia Tech... Advanced Computational Science
Shared Memory Programming With OpenMP Exercise Instructions John Burkardt Interdisciplinary Center for Applied Mathematics & Information Technology Department Virginia Tech... Advanced Computational Science
CS 403: Lab 6: Profiling and Tuning
 CS 403: Lab 6: Profiling and Tuning Getting Started 1. Boot into Linux. 2. Get a copy of RAD1D from your CVS repository (cvs co RAD1D) or download a fresh copy of the tar file from the course website.
CS 403: Lab 6: Profiling and Tuning Getting Started 1. Boot into Linux. 2. Get a copy of RAD1D from your CVS repository (cvs co RAD1D) or download a fresh copy of the tar file from the course website.
Numerical Modelling in Fortran: day 4. Paul Tackley, 2017
 Numerical Modelling in Fortran: day 4 Paul Tackley, 2017 Today s Goals 1. Debugging; linux environments 2. Review key points from reading homework 3. Precision, logical and complex types 4. More input/output
Numerical Modelling in Fortran: day 4 Paul Tackley, 2017 Today s Goals 1. Debugging; linux environments 2. Review key points from reading homework 3. Precision, logical and complex types 4. More input/output
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Optimisation p.1/22. Optimisation
 Performance Tuning Optimisation p.1/22 Optimisation Optimisation p.2/22 Constant Elimination do i=1,n a(i) = 2*b*c(i) enddo What is wrong with this loop? Compilers can move simple instances of constant
Performance Tuning Optimisation p.1/22 Optimisation Optimisation p.2/22 Constant Elimination do i=1,n a(i) = 2*b*c(i) enddo What is wrong with this loop? Compilers can move simple instances of constant
Supercomputing in Plain English Part IV: Henry Neeman, Director
 Supercomputing in Plain English Part IV: Henry Neeman, Director OU Supercomputing Center for Education & Research University of Oklahoma Wednesday September 19 2007 Outline! Dependency Analysis! What is
Supercomputing in Plain English Part IV: Henry Neeman, Director OU Supercomputing Center for Education & Research University of Oklahoma Wednesday September 19 2007 Outline! Dependency Analysis! What is
CIS 403: Lab 6: Profiling and Tuning
 CIS 403: Lab 6: Profiling and Tuning Getting Started 1. Boot into Linux. 2. Get a copy of RAD1D from your CVS repository (cvs co RAD1D) or download a fresh copy of the tar file from the course website.
CIS 403: Lab 6: Profiling and Tuning Getting Started 1. Boot into Linux. 2. Get a copy of RAD1D from your CVS repository (cvs co RAD1D) or download a fresh copy of the tar file from the course website.
Shared Memory Programming With OpenMP Computer Lab Exercises
 Shared Memory Programming With OpenMP Computer Lab Exercises Advanced Computational Science II John Burkardt Department of Scientific Computing Florida State University http://people.sc.fsu.edu/ jburkardt/presentations/fsu
Shared Memory Programming With OpenMP Computer Lab Exercises Advanced Computational Science II John Burkardt Department of Scientific Computing Florida State University http://people.sc.fsu.edu/ jburkardt/presentations/fsu
Memory. From Chapter 3 of High Performance Computing. c R. Leduc
 Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
1 Stokes equations with FD on a staggered grid using the stream-function approach.
 Figure 1: Discretiation for the streamfunction approach. The boundary conditions are set through fictious boundary points. 1 Stokes equations with FD on a staggered grid using the stream-function approach.
Figure 1: Discretiation for the streamfunction approach. The boundary conditions are set through fictious boundary points. 1 Stokes equations with FD on a staggered grid using the stream-function approach.
Domain Decomposition: Computational Fluid Dynamics
 Domain Decomposition: Computational Fluid Dynamics December 0, 0 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Domain Decomposition: Computational Fluid Dynamics December 0, 0 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Advanced Computer Architecture Lab 3 Scalability of the Gauss-Seidel Algorithm
 Advanced Computer Architecture Lab 3 Scalability of the Gauss-Seidel Algorithm Andreas Sandberg 1 Introduction The purpose of this lab is to: apply what you have learned so
Advanced Computer Architecture Lab 3 Scalability of the Gauss-Seidel Algorithm Andreas Sandberg 1 Introduction The purpose of this lab is to: apply what you have learned so
15 Answers to Frequently-
 15 Answers to Frequently- Asked Questions In this chapter, we provide answers to some commonly asked questions about ARPS. Most of the questions are collected from the users. We will continue to collect
15 Answers to Frequently- Asked Questions In this chapter, we provide answers to some commonly asked questions about ARPS. Most of the questions are collected from the users. We will continue to collect
Bindel, Fall 2011 Applications of Parallel Computers (CS 5220) Tuning on a single core
 Tuning on a single core") Tuning on a single core 1 From models to practice In lecture 2, we discussed features such as instruction-level parallelism and cache hierarchies that we need to understand in order to have a reasonable
Tuning on a single core 1 From models to practice In lecture 2, we discussed features such as instruction-level parallelism and cache hierarchies that we need to understand in order to have a reasonable
Optimising for the p690 memory system
 Optimising for the p690 memory Introduction As with all performance optimisation it is important to understand what is limiting the performance of a code. The Power4 is a very powerful micro-processor
Optimising for the p690 memory Introduction As with all performance optimisation it is important to understand what is limiting the performance of a code. The Power4 is a very powerful micro-processor
2-D Wave Equation Suggested Project
 CSE 260 Introduction to Parallel Computation 2-D Wave Equation Suggested Project 10/9/01 Project Overview Goal: program a simple parallel application in a variety of styles. learn different parallel languages
CSE 260 Introduction to Parallel Computation 2-D Wave Equation Suggested Project 10/9/01 Project Overview Goal: program a simple parallel application in a variety of styles. learn different parallel languages
Domain Decomposition: Computational Fluid Dynamics
 Domain Decomposition: Computational Fluid Dynamics July 11, 2016 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Domain Decomposition: Computational Fluid Dynamics July 11, 2016 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Domain Decomposition: Computational Fluid Dynamics
 Domain Decomposition: Computational Fluid Dynamics May 24, 2015 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Domain Decomposition: Computational Fluid Dynamics May 24, 2015 1 Introduction and Aims This exercise takes an example from one of the most common applications of HPC resources: Fluid Dynamics. We will
Adarsh Krishnamurthy (cs184-bb) Bela Stepanova (cs184-bs)
 Bela Stepanova (cs184-bs)") OBJECTIVE FLUID SIMULATIONS Adarsh Krishnamurthy (cs184-bb) Bela Stepanova (cs184-bs) The basic objective of the project is the implementation of the paper Stable Fluids (Jos Stam, SIGGRAPH 99). The final
OBJECTIVE FLUID SIMULATIONS Adarsh Krishnamurthy (cs184-bb) Bela Stepanova (cs184-bs) The basic objective of the project is the implementation of the paper Stable Fluids (Jos Stam, SIGGRAPH 99). The final
Introduction. No Optimization. Basic Optimizations. Normal Optimizations. Advanced Optimizations. Inter-Procedural Optimizations
 Introduction Optimization options control compile time optimizations to generate an application with code that executes more quickly. Absoft Fortran 90/95 is an advanced optimizing compiler. Various optimizers
Introduction Optimization options control compile time optimizations to generate an application with code that executes more quickly. Absoft Fortran 90/95 is an advanced optimizing compiler. Various optimizers
DRAFT. ATMET Technical Note. Common Customizations for RAMS v6.0. Number 2. Prepared by: ATMET, LLC PO Box Boulder, Colorado
 DRAFT ATMET Technical Note Number 2 Common Customizations for RAMS v60 Prepared by: ATMET, LLC PO Box 19195 Boulder, Colorado 80308-2195 October 2006 Table of Contents 1 Adding Array Space to the Model
DRAFT ATMET Technical Note Number 2 Common Customizations for RAMS v60 Prepared by: ATMET, LLC PO Box 19195 Boulder, Colorado 80308-2195 October 2006 Table of Contents 1 Adding Array Space to the Model
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Stream Function-Vorticity CFD Solver MAE 6263
 Stream Function-Vorticity CFD Solver MAE 66 Charles O Neill April, 00 Abstract A finite difference CFD solver was developed for transient, two-dimensional Cartesian viscous flows. Flow parameters are solved
Stream Function-Vorticity CFD Solver MAE 66 Charles O Neill April, 00 Abstract A finite difference CFD solver was developed for transient, two-dimensional Cartesian viscous flows. Flow parameters are solved
Sami Ilvonen Pekka Manninen. Introduction to High-Performance Computing with Fortran. September 19 20, 2016 CSC IT Center for Science Ltd, Espoo
 Sami Ilvonen Pekka Manninen Introduction to High-Performance Computing with Fortran September 19 20, 2016 CSC IT Center for Science Ltd, Espoo All material (C) 2009-2016 by CSC IT Center for Science Ltd.
Sami Ilvonen Pekka Manninen Introduction to High-Performance Computing with Fortran September 19 20, 2016 CSC IT Center for Science Ltd, Espoo All material (C) 2009-2016 by CSC IT Center for Science Ltd.
CSU RAMS. Procedures for Common User Customizations of the Model. Updated by:
 CSU RAMS Procedures for Common User Customizations of the Model This document contains a list of instructions and examples of how to customize this model. This includes the addition of new scalar and scratch
CSU RAMS Procedures for Common User Customizations of the Model This document contains a list of instructions and examples of how to customize this model. This includes the addition of new scalar and scratch
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Let s look at each and begin with a view into the software
 Power Consumption Overview In this lesson we will Identify the different sources of power consumption in embedded systems. Look at ways to measure power consumption. Study several different methods for
Power Consumption Overview In this lesson we will Identify the different sources of power consumption in embedded systems. Look at ways to measure power consumption. Study several different methods for
The NEMO Ocean Modelling Code: A Case Study
 The NEMO Ocean Modelling Code: A Case Study CUG 24 th 27 th May 2010 Dr Fiona J. L. Reid Applications Consultant, EPCC f.reid@epcc.ed.ac.uk +44 (0)131 651 3394 Acknowledgements Cray Centre of Excellence
The NEMO Ocean Modelling Code: A Case Study CUG 24 th 27 th May 2010 Dr Fiona J. L. Reid Applications Consultant, EPCC f.reid@epcc.ed.ac.uk +44 (0)131 651 3394 Acknowledgements Cray Centre of Excellence
Parallel Code Optimisation
 April 8, 2008 Terms and terminology Identifying bottlenecks Optimising communications Optimising IO Optimising the core code Theoretical perfomance The theoretical floating point performance of a processor
April 8, 2008 Terms and terminology Identifying bottlenecks Optimising communications Optimising IO Optimising the core code Theoretical perfomance The theoretical floating point performance of a processor
Optimising with the IBM compilers
 Optimising with the IBM Overview Introduction Optimisation techniques compiler flags compiler hints code modifications Optimisation topics locals and globals conditionals data types CSE divides and square
Optimising with the IBM Overview Introduction Optimisation techniques compiler flags compiler hints code modifications Optimisation topics locals and globals conditionals data types CSE divides and square
Loop Transformations! Part II!
 Lecture 9! Loop Transformations! Part II! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Loop Unswitching Hoist invariant control-flow
Lecture 9! Loop Transformations! Part II! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Loop Unswitching Hoist invariant control-flow
HPC VT Machine-dependent Optimization
 HPC VT 2013 Machine-dependent Optimization Last time Choose good data structures Reduce number of operations Use cheap operations strength reduction Avoid too many small function calls inlining Use compiler
HPC VT 2013 Machine-dependent Optimization Last time Choose good data structures Reduce number of operations Use cheap operations strength reduction Avoid too many small function calls inlining Use compiler
An interesting related problem is Buffon s Needle which was first proposed in the mid-1700 s.
 Using Monte Carlo to Estimate π using Buffon s Needle Problem An interesting related problem is Buffon s Needle which was first proposed in the mid-1700 s. Here s the problem (in a simplified form). Suppose
Using Monte Carlo to Estimate π using Buffon s Needle Problem An interesting related problem is Buffon s Needle which was first proposed in the mid-1700 s. Here s the problem (in a simplified form). Suppose
Lecture 2: Introduction to OpenMP with application to a simple PDE solver
 Lecture 2: Introduction to OpenMP with application to a simple PDE solver Mike Giles Mathematical Institute Mike Giles Lecture 2: Introduction to OpenMP 1 / 24 Hardware and software Hardware: a processor
Lecture 2: Introduction to OpenMP with application to a simple PDE solver Mike Giles Mathematical Institute Mike Giles Lecture 2: Introduction to OpenMP 1 / 24 Hardware and software Hardware: a processor
Python Scripting for Computational Science
 Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures 43 Springer Table of Contents 1 Introduction... 1 1.1 Scripting versus Traditional Programming... 1 1.1.1
Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures 43 Springer Table of Contents 1 Introduction... 1 1.1 Scripting versus Traditional Programming... 1 1.1.1
Optimisation. CS7GV3 Real-time Rendering
 Optimisation CS7GV3 Real-time Rendering Introduction Talk about lower-level optimization Higher-level optimization is better algorithms Example: not using a spatial data structure vs. using one After that
Optimisation CS7GV3 Real-time Rendering Introduction Talk about lower-level optimization Higher-level optimization is better algorithms Example: not using a spatial data structure vs. using one After that
CUDA. Fluid simulation Lattice Boltzmann Models Cellular Automata
 CUDA Fluid simulation Lattice Boltzmann Models Cellular Automata Please excuse my layout of slides for the remaining part of the talk! Fluid Simulation Navier Stokes equations for incompressible fluids
CUDA Fluid simulation Lattice Boltzmann Models Cellular Automata Please excuse my layout of slides for the remaining part of the talk! Fluid Simulation Navier Stokes equations for incompressible fluids
Programming. Dr Ben Dudson University of York
 Programming Dr Ben Dudson University of York Outline Last lecture covered the basics of programming and IDL This lecture will cover More advanced IDL and plotting Fortran and C++ Programming techniques
Programming Dr Ben Dudson University of York Outline Last lecture covered the basics of programming and IDL This lecture will cover More advanced IDL and plotting Fortran and C++ Programming techniques
Autotuning. John Cavazos. University of Delaware UNIVERSITY OF DELAWARE COMPUTER & INFORMATION SCIENCES DEPARTMENT
 Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
Kampala August, Agner Fog
 Advanced microprocessor optimization Kampala August, 2007 Agner Fog www.agner.org Agenda Intel and AMD microprocessors Out Of Order execution Branch prediction Platform, 32 or 64 bits Choice of compiler
Advanced microprocessor optimization Kampala August, 2007 Agner Fog www.agner.org Agenda Intel and AMD microprocessors Out Of Order execution Branch prediction Platform, 32 or 64 bits Choice of compiler
Tiling: A Data Locality Optimizing Algorithm
 Tiling: A Data Locality Optimizing Algorithm Announcements Monday November 28th, Dr. Sanjay Rajopadhye is talking at BMAC Friday December 2nd, Dr. Sanjay Rajopadhye will be leading CS553 Last Monday Kelly
Tiling: A Data Locality Optimizing Algorithm Announcements Monday November 28th, Dr. Sanjay Rajopadhye is talking at BMAC Friday December 2nd, Dr. Sanjay Rajopadhye will be leading CS553 Last Monday Kelly
Amdahl s Law. AMath 483/583 Lecture 13 April 25, Amdahl s Law. Amdahl s Law. Today: Amdahl s law Speed up, strong and weak scaling OpenMP
 AMath 483/583 Lecture 13 April 25, 2011 Amdahl s Law Today: Amdahl s law Speed up, strong and weak scaling OpenMP Typically only part of a computation can be parallelized. Suppose 50% of the computation
AMath 483/583 Lecture 13 April 25, 2011 Amdahl s Law Today: Amdahl s law Speed up, strong and weak scaling OpenMP Typically only part of a computation can be parallelized. Suppose 50% of the computation
Lecture 16. Today: Start looking into memory hierarchy Cache$! Yay!
 Lecture 16 Today: Start looking into memory hierarchy Cache$! Yay! Note: There are no slides labeled Lecture 15. Nothing omitted, just that the numbering got out of sequence somewhere along the way. 1
Lecture 16 Today: Start looking into memory hierarchy Cache$! Yay! Note: There are no slides labeled Lecture 15. Nothing omitted, just that the numbering got out of sequence somewhere along the way. 1
Python Scripting for Computational Science
 Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures Sprin ger Table of Contents 1 Introduction 1 1.1 Scripting versus Traditional Programming 1 1.1.1 Why Scripting
Hans Petter Langtangen Python Scripting for Computational Science Third Edition With 62 Figures Sprin ger Table of Contents 1 Introduction 1 1.1 Scripting versus Traditional Programming 1 1.1.1 Why Scripting
Welcome to Part 3: Memory Systems and I/O
 Welcome to Part 3: Memory Systems and I/O We ve already seen how to make a fast processor. How can we supply the CPU with enough data to keep it busy? We will now focus on memory issues, which are frequently
Welcome to Part 3: Memory Systems and I/O We ve already seen how to make a fast processor. How can we supply the CPU with enough data to keep it busy? We will now focus on memory issues, which are frequently
Introduction. Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: We study the bandwidth problem
 Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
Why C? Because we can t in good conscience espouse Fortran.
 C Tutorial Why C? Because we can t in good conscience espouse Fortran. C Hello World Code: Output: C For Loop Code: Output: C Functions Code: Output: Unlike Fortran, there is no distinction in C between
C Tutorial Why C? Because we can t in good conscience espouse Fortran. C Hello World Code: Output: C For Loop Code: Output: C Functions Code: Output: Unlike Fortran, there is no distinction in C between
Control Structures. Code can be purely arithmetic assignments. At some point we will need some kind of control or decision making process to occur
 Control Structures Code can be purely arithmetic assignments At some point we will need some kind of control or decision making process to occur C uses the if keyword as part of it s control structure
Control Structures Code can be purely arithmetic assignments At some point we will need some kind of control or decision making process to occur C uses the if keyword as part of it s control structure
MAR 572 Geophysical Simulation
 MAR 572 Geophysical Simulation Wed/Fri 3:00-4:20 pm Endeavour 158 Prof. Marat Khairoutdinov Office hours: Endeavour 121; by email appt Email: marat.khairoutdinov@stonybrook.edu Class website: http://rossby.msrc.sunysb.edu/~marat/mar572.html
MAR 572 Geophysical Simulation Wed/Fri 3:00-4:20 pm Endeavour 158 Prof. Marat Khairoutdinov Office hours: Endeavour 121; by email appt Email: marat.khairoutdinov@stonybrook.edu Class website: http://rossby.msrc.sunysb.edu/~marat/mar572.html
ROB: head/tail. exercise: result of processing rest? 2. rename map (for next rename) log. phys. free list: X11, X3. PC log. reg prev.
 log. phys. free list: X11, X3. PC log. reg prev.") Exam Review 2 1 ROB: head/tail PC log. reg prev. phys. store? except? ready? A R3 X3 no none yes old tail B R1 X1 no none yes tail C R1 X6 no none yes D R4 X4 no none yes E --- --- yes none yes F --- ---
Exam Review 2 1 ROB: head/tail PC log. reg prev. phys. store? except? ready? A R3 X3 no none yes old tail B R1 X1 no none yes tail C R1 X6 no none yes D R4 X4 no none yes E --- --- yes none yes F --- ---
An Introduction to F2Py
 An Introduction to Jules Kouatchou, Hamid Oloso and Mike Rilee Jules.Kouatchou@nasa.gov, Amidu.O.Oloso@nasa.gov and Michael.Rilee@nasa.gov Goddard Space Flight Center Software System Support Office Code
An Introduction to Jules Kouatchou, Hamid Oloso and Mike Rilee Jules.Kouatchou@nasa.gov, Amidu.O.Oloso@nasa.gov and Michael.Rilee@nasa.gov Goddard Space Flight Center Software System Support Office Code
In examining performance Interested in several things Exact times if computable Bounded times if exact not computable Can be measured
 System Performance Analysis Introduction Performance Means many things to many people Important in any design Critical in real time systems 1 ns can mean the difference between system Doing job expected
System Performance Analysis Introduction Performance Means many things to many people Important in any design Critical in real time systems 1 ns can mean the difference between system Doing job expected
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Computer Organization & Assembly Language Programming
 Computer Organization & Assembly Language Programming CSE 2312-002 (Fall 2011) Lecture 5 Memory Junzhou Huang, Ph.D. Department of Computer Science and Engineering Fall 2011 CSE 2312 Computer Organization
Computer Organization & Assembly Language Programming CSE 2312-002 (Fall 2011) Lecture 5 Memory Junzhou Huang, Ph.D. Department of Computer Science and Engineering Fall 2011 CSE 2312 Computer Organization
Cache introduction. April 16, Howard Huang 1
 Cache introduction We ve already seen how to make a fast processor. How can we supply the CPU with enough data to keep it busy? The rest of CS232 focuses on memory and input/output issues, which are frequently
Cache introduction We ve already seen how to make a fast processor. How can we supply the CPU with enough data to keep it busy? The rest of CS232 focuses on memory and input/output issues, which are frequently
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
Threaded Programming. Lecture 9: Introduction to performance optimisation
 Threaded Programming Lecture 9: Introduction to performance optimisation Why? Large computer simulations are becoming common in many scientific disciplines. These often take a significant amount of time
Threaded Programming Lecture 9: Introduction to performance optimisation Why? Large computer simulations are becoming common in many scientific disciplines. These often take a significant amount of time
Numerical Modelling in Fortran: day 2. Paul Tackley, 2017
 Numerical Modelling in Fortran: day 2 Paul Tackley, 2017 Goals for today Review main points in online materials you read for homework http://www.cs.mtu.edu/%7eshene/courses/cs201/notes/intro.html More
Numerical Modelling in Fortran: day 2 Paul Tackley, 2017 Goals for today Review main points in online materials you read for homework http://www.cs.mtu.edu/%7eshene/courses/cs201/notes/intro.html More
Vectorization on KNL
 Vectorization on KNL Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2, with KNL, Jan. 23, 2017
Vectorization on KNL Steve Lantz Senior Research Associate Cornell University Center for Advanced Computing (CAC) steve.lantz@cornell.edu High Performance Computing on Stampede 2, with KNL, Jan. 23, 2017
Lab 9: FLUENT: Transient Natural Convection Between Concentric Cylinders
 Lab 9: FLUENT: Transient Natural Convection Between Concentric Cylinders Objective: The objective of this laboratory is to introduce how to use FLUENT to solve both transient and natural convection problems.
Lab 9: FLUENT: Transient Natural Convection Between Concentric Cylinders Objective: The objective of this laboratory is to introduce how to use FLUENT to solve both transient and natural convection problems.
Module 1: Introduction to Finite Difference Method and Fundamentals of CFD Lecture 13: The Lecture deals with:
 The Lecture deals with: Some more Suggestions for Improvement of Discretization Schemes Some Non-Trivial Problems with Discretized Equations file:///d /chitra/nptel_phase2/mechanical/cfd/lecture13/13_1.htm[6/20/2012
The Lecture deals with: Some more Suggestions for Improvement of Discretization Schemes Some Non-Trivial Problems with Discretized Equations file:///d /chitra/nptel_phase2/mechanical/cfd/lecture13/13_1.htm[6/20/2012
Supercomputing and Science An Introduction to High Performance Computing
 Supercomputing and Science An Introduction to High Performance Computing Part IV: Dependency Analysis and Stupid Compiler Tricks Henry Neeman, Director OU Supercomputing Center for Education & Research
Supercomputing and Science An Introduction to High Performance Computing Part IV: Dependency Analysis and Stupid Compiler Tricks Henry Neeman, Director OU Supercomputing Center for Education & Research
Algorithm Performance Factors. Memory Performance of Algorithms. Processor-Memory Performance Gap. Moore s Law. Program Model of Memory I
 Memory Performance of Algorithms CSE 32 Data Structures Lecture Algorithm Performance Factors Algorithm choices (asymptotic running time) O(n 2 ) or O(n log n) Data structure choices List or Arrays Language
Memory Performance of Algorithms CSE 32 Data Structures Lecture Algorithm Performance Factors Algorithm choices (asymptotic running time) O(n 2 ) or O(n log n) Data structure choices List or Arrays Language
MS6021 Scientific Computing. MatLab and Python for Mathematical Modelling. Aimed at the absolute beginner.
 MS6021 Scientific Computing MatLab and Python for Mathematical Modelling. Aimed at the absolute beginner. Natalia Kopteva Email: natalia.kopteva@ul.ie Web: http://www.staff.ul.ie/natalia/ Room: B2037 Office
MS6021 Scientific Computing MatLab and Python for Mathematical Modelling. Aimed at the absolute beginner. Natalia Kopteva Email: natalia.kopteva@ul.ie Web: http://www.staff.ul.ie/natalia/ Room: B2037 Office
PDF created with pdffactory Pro trial version How Computer Memory Works by Jeff Tyson. Introduction to How Computer Memory Works
 Main > Computer > Hardware How Computer Memory Works by Jeff Tyson Introduction to How Computer Memory Works When you think about it, it's amazing how many different types of electronic memory you encounter
Main > Computer > Hardware How Computer Memory Works by Jeff Tyson Introduction to How Computer Memory Works When you think about it, it's amazing how many different types of electronic memory you encounter
Compiling for Performance on hp OpenVMS I64. Doug Gordon Original Presentation by Bill Noyce European Technical Update Days, 2005
 Compiling for Performance on hp OpenVMS I64 Doug Gordon Original Presentation by Bill Noyce European Technical Update Days, 2005 Compilers discussed C, Fortran, [COBOL, Pascal, BASIC] Share GEM optimizer
Compiling for Performance on hp OpenVMS I64 Doug Gordon Original Presentation by Bill Noyce European Technical Update Days, 2005 Compilers discussed C, Fortran, [COBOL, Pascal, BASIC] Share GEM optimizer
EITF20: Computer Architecture Part 5.1.1: Virtual Memory
 EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
Figure 1 Common Sub Expression Optimization Example
 General Code Optimization Techniques Wesley Myers wesley.y.myers@gmail.com Introduction General Code Optimization Techniques Normally, programmers do not always think of hand optimizing code. Most programmers
General Code Optimization Techniques Wesley Myers wesley.y.myers@gmail.com Introduction General Code Optimization Techniques Normally, programmers do not always think of hand optimizing code. Most programmers
Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 HPC tools: an overview
 School of Physics, IPM February 16-21, 2008 HPC tools: an overview") Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 HPC tools: an overview Stefano Cozzini CNR/INFM Democritos and SISSA/eLab cozzini@democritos.it Agenda Tools for
Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 HPC tools: an overview Stefano Cozzini CNR/INFM Democritos and SISSA/eLab cozzini@democritos.it Agenda Tools for
Parallel Poisson Solver in Fortran
 Parallel Poisson Solver in Fortran Nilas Mandrup Hansen, Ask Hjorth Larsen January 19, 1 1 Introduction In this assignment the D Poisson problem (Eq.1) is to be solved in either C/C++ or FORTRAN, first
Parallel Poisson Solver in Fortran Nilas Mandrup Hansen, Ask Hjorth Larsen January 19, 1 1 Introduction In this assignment the D Poisson problem (Eq.1) is to be solved in either C/C++ or FORTRAN, first
Performance Engineering: Lab Session
 PDC Summer School 2018 Performance Engineering: Lab Session We are going to work with a sample toy application that solves the 2D heat equation (see the Appendix in this handout). You can download that
PDC Summer School 2018 Performance Engineering: Lab Session We are going to work with a sample toy application that solves the 2D heat equation (see the Appendix in this handout). You can download that
41st Cray User Group Conference Minneapolis, Minnesota
 41st Cray User Group Conference Minneapolis, Minnesota (MSP) Technical Lead, MSP Compiler The Copyright SGI Multi-Stream 1999, SGI Processor We know Multi-level parallelism experts for 25 years Multiple,
41st Cray User Group Conference Minneapolis, Minnesota (MSP) Technical Lead, MSP Compiler The Copyright SGI Multi-Stream 1999, SGI Processor We know Multi-level parallelism experts for 25 years Multiple,
Notes slides from before lecture. CSE 21, Winter 2017, Section A00. Lecture 3 Notes. Class URL:
 Notes slides from before lecture CSE 21, Winter 2017, Section A00 Lecture 3 Notes Class URL: http://vlsicad.ucsd.edu/courses/cse21-w17/ Notes slides from before lecture Notes January 18 (1) HW2 has been
Notes slides from before lecture CSE 21, Winter 2017, Section A00 Lecture 3 Notes Class URL: http://vlsicad.ucsd.edu/courses/cse21-w17/ Notes slides from before lecture Notes January 18 (1) HW2 has been
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
17/05/2018. Outline. Outline. Divide and Conquer. Control Abstraction for Divide &Conquer. Outline. Module 2: Divide and Conquer
 Module 2: Divide and Conquer Divide and Conquer Control Abstraction for Divide &Conquer 1 Recurrence equation for Divide and Conquer: If the size of problem p is n and the sizes of the k sub problems are
Module 2: Divide and Conquer Divide and Conquer Control Abstraction for Divide &Conquer 1 Recurrence equation for Divide and Conquer: If the size of problem p is n and the sizes of the k sub problems are
c Fluent Inc. May 16,
 Tutorial 1. Office Ventilation Introduction: This tutorial demonstrates how to model an office shared by two people working at computers, using Airpak. In this tutorial, you will learn how to: Open a new
Tutorial 1. Office Ventilation Introduction: This tutorial demonstrates how to model an office shared by two people working at computers, using Airpak. In this tutorial, you will learn how to: Open a new
Fluid Simulation. [Thürey 10] [Pfaff 10] [Chentanez 11]
![Fluid Simulation. [Thürey 10] [Pfaff 10] [Chentanez 11]](/thumbs/72/66717659.jpg "Fluid Simulation. [Thürey 10] [Pfaff 10] [Chentanez 11]") Fluid Simulation [Thürey 10] [Pfaff 10] [Chentanez 11] 1 Computational Fluid Dynamics 3 Graphics Why don t we just take existing models from CFD for Computer Graphics applications? 4 Graphics Why don t
Fluid Simulation [Thürey 10] [Pfaff 10] [Chentanez 11] 1 Computational Fluid Dynamics 3 Graphics Why don t we just take existing models from CFD for Computer Graphics applications? 4 Graphics Why don t
COMP Preliminaries Jan. 6, 2015
 Lecture 1 Computer graphics, broadly defined, is a set of methods for using computers to create and manipulate images. There are many applications of computer graphics including entertainment (games, cinema,
Lecture 1 Computer graphics, broadly defined, is a set of methods for using computers to create and manipulate images. There are many applications of computer graphics including entertainment (games, cinema,
Performance analysis basics
 Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
The parallelization of a block-tridiagonal matrix system for an electromagnetic wave simulation in TOKAMAK(TORIC) by MPI Fortran
 by MPI Fortran") The parallelization of a block-tridiagonal matrix system for an electromagnetic wave simulation in TOKAMAK(TORIC) by MPI Fortran Jungpyo Lee Graduate Student in a department
The parallelization of a block-tridiagonal matrix system for an electromagnetic wave simulation in TOKAMAK(TORIC) by MPI Fortran Jungpyo Lee Graduate Student in a department
Testing is a very big and important topic when it comes to software development. Testing has a number of aspects that need to be considered.
 Testing Testing is a very big and important topic when it comes to software development. Testing has a number of aspects that need to be considered. System stability is the system going to crash or not?
Testing Testing is a very big and important topic when it comes to software development. Testing has a number of aspects that need to be considered. System stability is the system going to crash or not?
Software Design Models, Tools & Processes. Lecture 6: Transition Phase Cecilia Mascolo
 Software Design Models, Tools & Processes Lecture 6: Transition Phase Cecilia Mascolo UML Component diagram Component documentation Your own classes should be documented the same way library classes are.
Software Design Models, Tools & Processes Lecture 6: Transition Phase Cecilia Mascolo UML Component diagram Component documentation Your own classes should be documented the same way library classes are.
2 TEST: A Tracer for Extracting Speculative Threads
 EE392C: Advanced Topics in Computer Architecture Lecture #11 Polymorphic Processors Stanford University Handout Date??? On-line Profiling Techniques Lecture #11: Tuesday, 6 May 2003 Lecturer: Shivnath
EE392C: Advanced Topics in Computer Architecture Lecture #11 Polymorphic Processors Stanford University Handout Date??? On-line Profiling Techniques Lecture #11: Tuesday, 6 May 2003 Lecturer: Shivnath
The NetBeans IDE is a big file --- a minimum of around 30 MB. After you have downloaded the file, simply execute the file to install the software.
 Introduction to Netbeans This document is a brief introduction to writing and compiling a program using the NetBeans Integrated Development Environment (IDE). An IDE is a program that automates and makes
Introduction to Netbeans This document is a brief introduction to writing and compiling a program using the NetBeans Integrated Development Environment (IDE). An IDE is a program that automates and makes
Manual and Compiler Optimizations
 Manual and Compiler Optimizations Shawn T. Brown, PhD. Director of Public Health Applications Pittsburgh Supercomputing Center, Carnegie Mellon University Introduction to Performance Optimization Real
Manual and Compiler Optimizations Shawn T. Brown, PhD. Director of Public Health Applications Pittsburgh Supercomputing Center, Carnegie Mellon University Introduction to Performance Optimization Real
Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
COMP4128 Programming Challenges
 COMP4128 Challenges School of Computer Science and Engineering UNSW Australia 2D Table of Contents 2 2D 1 2 3 4 5 6 2D 7 Divide 3 2D Wikipedia: an algorithm design paradigm based on multi-branched recursion
COMP4128 Challenges School of Computer Science and Engineering UNSW Australia 2D Table of Contents 2 2D 1 2 3 4 5 6 2D 7 Divide 3 2D Wikipedia: an algorithm design paradigm based on multi-branched recursion
AM119: Yet another OpenFoam tutorial
 AM119: Yet another OpenFoam tutorial Prof. Trask April 11, 2016 1 Todays project Today we re going to implement a projection method for the Navier-Stokes, learn how to build a mesh, and explore the difference
AM119: Yet another OpenFoam tutorial Prof. Trask April 11, 2016 1 Todays project Today we re going to implement a projection method for the Navier-Stokes, learn how to build a mesh, and explore the difference
Review of previous examinations TMA4280 Introduction to Supercomputing
 Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Computational modeling
 Computational modeling Lecture 3 : Random variables Theory: 1 Random variables Programming: 1 Implicit none statement 2 Modules 3 Outputs 4 Functions 5 Conditional statement Instructor : Cedric Weber Course
Computational modeling Lecture 3 : Random variables Theory: 1 Random variables Programming: 1 Implicit none statement 2 Modules 3 Outputs 4 Functions 5 Conditional statement Instructor : Cedric Weber Course
NIA CFD Seminar, October 4, 2011 Hyperbolic Seminar, NASA Langley, October 17, 2011
 NIA CFD Seminar, October 4, 2011 Hyperbolic Seminar, NASA Langley, October 17, 2011 First-Order Hyperbolic System Method If you have a CFD book for hyperbolic problems, you have a CFD book for all problems.
NIA CFD Seminar, October 4, 2011 Hyperbolic Seminar, NASA Langley, October 17, 2011 First-Order Hyperbolic System Method If you have a CFD book for hyperbolic problems, you have a CFD book for all problems.
ECE 5730 Memory Systems
 ECE 5730 Memory Systems Spring 2009 Off-line Cache Content Management Lecture 7: 1 Quiz 4 on Tuesday Announcements Only covers today s lecture No office hours today Lecture 7: 2 Where We re Headed Off-line
ECE 5730 Memory Systems Spring 2009 Off-line Cache Content Management Lecture 7: 1 Quiz 4 on Tuesday Announcements Only covers today s lecture No office hours today Lecture 7: 2 Where We re Headed Off-line
High-Performance Scientific Computing
 High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
LECTURE 0: Introduction and Background
 1 LECTURE 0: Introduction and Background September 10, 2012 1 Computational science The role of computational science has become increasingly significant during the last few decades. It has become the
1 LECTURE 0: Introduction and Background September 10, 2012 1 Computational science The role of computational science has become increasingly significant during the last few decades. It has become the
Where Does The Cpu Store The Address Of The
 Where Does The Cpu Store The Address Of The Next Instruction To Be Fetched The three most important buses are the address, the data, and the control buses. The CPU always knows where to find the next instruction
Where Does The Cpu Store The Address Of The Next Instruction To Be Fetched The three most important buses are the address, the data, and the control buses. The CPU always knows where to find the next instruction
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
Lecture 2: Single processor architecture and memory
 Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS.
 About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS. Phoenix FD core SIMULATION & RENDERING. SIMULATION CORE - GRID-BASED
About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS. Phoenix FD core SIMULATION & RENDERING. SIMULATION CORE - GRID-BASED