Lecture 33: More on MPI I/O. William Gropp
|
|
|
- Elijah Fox
- 6 years ago
- Views:
Transcription
1 Lecture 33: More on MPI I/O William Gropp
2 Today s Topics High level parallel I/O libraries Options for efficient I/O Example of I/O for a distributed array Understanding why collective I/O offers better performance Optimizing parallel I/O performance 2
3 Portable File Formats Ad-hoc file formats Difficult to collaborate Cannot leverage post-processing tools MPI provides external32 data encoding No one uses this High level I/O libraries netcdf and HDF5 Better solutions than external32 Define a container for data - Describes contents - May be queried (self-describing) Standard format for metadata about the file Wide range of post-processing tools available 3 3
4 Higher Level I/O Libraries Scientific applications work with structured data and desire more selfdescribing file formats netcdf and HDF5 are two popular higher level I/O libraries Abstract away details of file layout Provide standard, portable file formats Include metadata describing contents For parallel machines, these should be built on top of MPI-IO HDF5 has an MPI-IO option 4 4


5 netcdf Data Model netcdf provides a means for storing multiple, multi-dimensional arrays in a single file, along with information about the arrays 5
6 Parallel netcdf (PnetCDF) (Serial) netcdf API for accessing multidimensional data sets Portable file format Popular in both fusion and climate communities Parallel netcdf Very similar API to netcdf Tuned for better performance in today s computing environments Retains the file format so netcdf and PnetCDF applications can share files PnetCDF builds on top of any Cluster PnetCDF ROMIO PVFS2 IBM BG PnetCDF IBM MPI GPFS MPI-IO implementation 6 6
7 I/O in netcdf and PnetCDF (Serial) netcdf Parallel read All processes read the file independently No possibility of collective optimizations Sequential write PnetCDF Parallel writes are carried out by shipping data to a single process Just like our stdout checkpoint code Parallel read/write to shared netcdf file Built on top of MPI-IO which utilizes optimal I/O facilities of the parallel file system and MPI-IO implementation Allows for MPI-IO hints and datatypes for further optimization P0 P1 P2 P3 netcdf Parallel File System P0 P1 P2 P3 Parallel netcdf Parallel File System 7
8 Optimizations Given complete access information, an implementation can perform optimizations such as: Data Sieving: Read large chunks and extract what is really needed Collective I/O: Merge requests of different processes into larger requests Improved prefetching and caching 8 8
9 Bandwidth Results 3D distributed array access written as levels 0, 2, 3 Five different machines (dated but still relevant) NCSA Teragrid IA-64 cluster with GPFS and MPICH2 ASC Purple at LLNL with GPFS and IBM s MPI Jazz cluster at Argonne with PVFS and MPICH2 Cray XT3 at ORNL with Lustre and Cray s MPI SDSC Datastar with GPFS and IBM s MPI Since these are all different machines with different amounts of I/O hardware, we compare the performance of the different levels of access on a particular machine, not across machines 9 9


10 Distributed Array Access Read Write Array size: 512 x 512 x 512 Note log scaling! Thanks to Weikuan Yu, Wei-keng Liao, Bill Loewe, and Anthony Chan for these results. 10
11 Detailed Example: Distributed Array Access Global array size: m x n Array is distributed on a 2D grid of processes: nproc(1) x nproc(2) Coordinates of a process in the grid: icoord(1), icoord(2) (0-based indices) Local array stored in file in a layout corresponding to global array in columnmajor (Fortran) order Two cases local array is stored contiguously in memory local array has ghost area around it in memory 11
12 n P0 icoord = (0,0) P1 icoord = (0,1) P2 icoord = (0,2) m P3 icoord = (1,0) P4 P5 icoord = (1,1) icoord = (1,2) nproc(1) = 2, nproc(2) = 3 12
13 CASE I: LOCAL ARRAY CONTIGUOUS IN MEMORY iarray_of_sizes(1) = m iarray_of_sizes(2) = n iarray_of_subsizes(1) = m/nproc(1) iarray_of_subsizes(2) = n/nproc(2) iarray_of_starts(1) = icoord(1) * iarray_of_subsizes(1) iarray_of_starts(2) = icoord(2) * iarray_of_subsizes(2) ndims = 2 zerooffset = 0! 0-based, even in Fortran! 0-based, even in Fortran call MPI_TYPE_CREATE_SUBARRAY(ndims, iarray_of_sizes, iarray_of_subsizes, iarray_of_starts, MPI_ORDER_FORTRAN, MPI_REAL, ifiletype, ierr) call MPI_TYPE_COMMIT(ifiletype, ierr) call MPI_FILE_OPEN(MPI_COMM_WORLD, /home/me/test, MPI_MODE_CREATE + MPI_MODE_RDWR, MPI_INFO_NULL, ifh, ierr) call MPI_FILE_SET_VIEW(ifh, zerooffset, MPI_REAL, ifiletype, native, MPI_INFO_NULL, ierr) ilocal_size = iarray_of_subsizes(1) * iarray_of_subsizes(2) call MPI_FILE_WRITE_ALL(ifh, local_array, ilocal_size, MPI_REAL, istatus, ierr) call MPI_FILE_CLOSE(ifh, ierr) 13
14 CASE II: LOCAL ARRAY HAS GHOST AREA OF SIZE 2 ON EACH SIDE Local array Ghost area! Create derived datatype describing layout of local array in memory iarray_of_sizes(1) = m/nproc(1) + 4 iarray_of_sizes(2) = n/nproc(2) + 4 iarray_of_subsizes(1) = m/nproc(1) iarray_of_subsizes(2) = n/nproc(2) iarray_of_starts(1) = 2 iarray_of_starts(2) = 2 ndims = 2! 0-based, even in Fortran! 0-based, even in Fortran call MPI_TYPE_CREATE_SUBARRAY(ndims, iarray_of_sizes, iarray_of_subsizes, iarray_of_starts, MPI_ORDER_FORTRAN, MPI_REAL, imemtype, ierr) call MPI_TYPE_COMMIT(imemtype, ierr) Continued... 14
15 CASE II continued! Create derived datatype to describe layout of local array in the file iarray_of_sizes(1) = m iarray_of_sizes(2) = n iarray_of_subsizes(1) = m/nproc(1) iarray_of_subsizes(2) = n/nproc(2) iarray_of_starts(1) = icoord(1) * iarray_of_subsizes(1) iarray_of_starts(2) = icoord(2) * iarray_of_subsizes(2) ndims = 2 zerooffset = 0! 0-based, even in Fortran! 0-based, even in Fortran call MPI_TYPE_CREATE_SUBARRAY(ndims, iarray_of_sizes, iarray_of_subsizes, iarray_of_starts, MPI_ORDER_FORTRAN, MPI_REAL, ifiletype, ierr) call MPI_TYPE_COMMIT(ifiletype, ierr)! Open the file, set the view, and write call MPI_FILE_OPEN(MPI_COMM_WORLD, /home/thakur/test, MPI_MODE_CREATE + MPI_MODE_RDWR, MPI_INFO_NULL, ifh, ierr) call MPI_FILE_SET_VIEW(ifh, zerooffset, MPI_REAL, ifiletype, native, MPI_INFO_NULL, ierr) call MPI_FILE_WRITE_ALL(ifh, local_array, 1, imemtype, istatus, ierr) call MPI_FILE_CLOSE(ifh, ierr) 15
16 Comments On MPI I/O Understand why collective I/O is better, and how it enables efficient implementation of I/O More on tuning MPI IO performance Common errors in using MPI IO 16
17 Collective I/O The next slide shows the trace for the collective I/O case Note that the entire program runs for a little more than 1 sec Each process does its entire I/O with a single write or read operation Data is exchanged with other processes so that everyone gets what they need Very efficient! 17


18 Collective I/O 18 18
19 Data Sieving The next slide shows the trace for the data sieving case Note that the program runs for about 5 sec now Since the default data sieving buffer size happens to be large enough, each process can read with a single read operation, although more data is read than actually needed (because of holes) Since PVFS doesn t support file locking, data sieving cannot be used for writes, resulting in many small writes (1K per process) 19

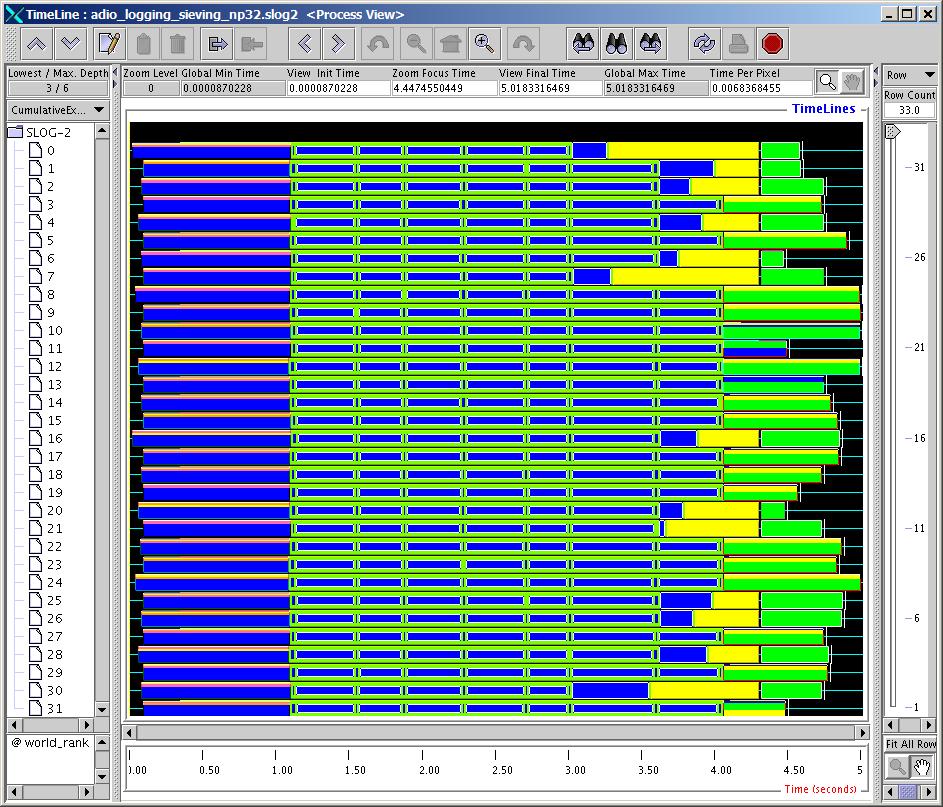
20 Data Sieving 20 20
21 Posix I/O The next slide shows the trace for Posix I/O Lots of small reads and writes (1K each per process) The reads take much longer than the writes in this case because of a TCPincast problem happening in the switch Total program takes about 80 sec Very inefficient! 21

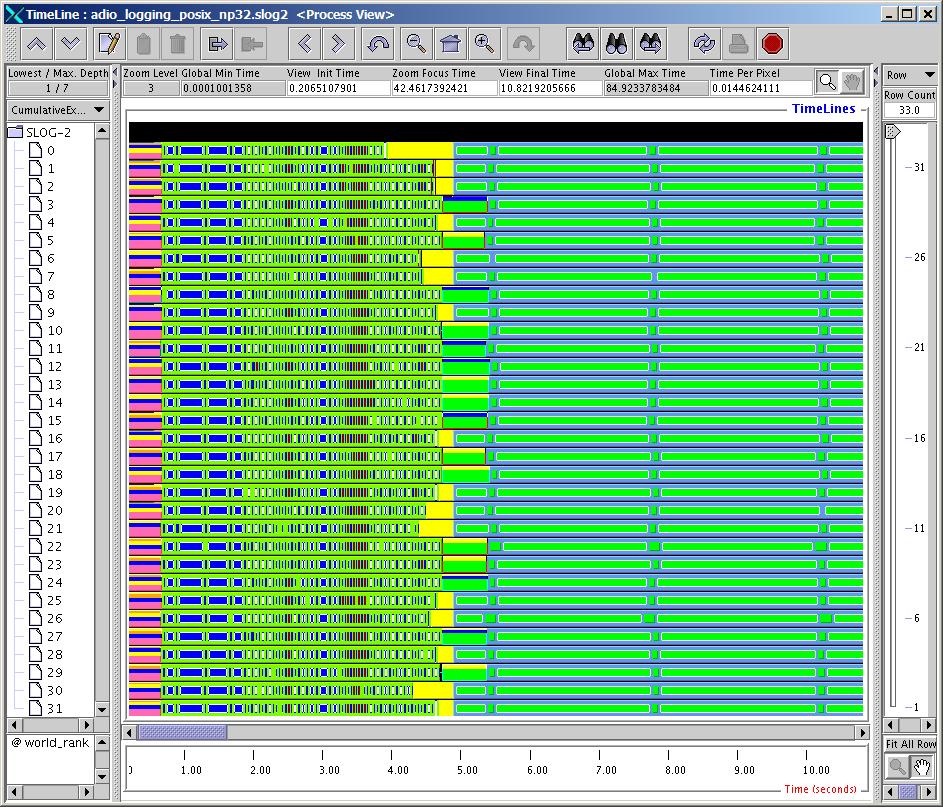
22 Posix I/O 22 22
23 Passing Hints MPI defines MPI_Info Provides an extensible list of key=value pairs Used to package variable, optional types of arguments that may not be standard Used in IO, Dynamic, and RMA, as well as with communicators 23
24 Passing Hints to MPI-IO MPI_Info info; MPI_Info_create(&info); /* no. of I/O devices to be used for file striping */ MPI_Info_set(info, "striping_factor", "4"); /* the striping unit in bytes */ MPI_Info_set(info, "striping_unit", "65536"); MPI_File_open(MPI_COMM_WORLD, "/pfs/datafile", MPI_MODE_CREATE MPI_MODE_RDWR, info, &fh); MPI_Info_free(&info); 24
25 Passing Hints to MPI-IO (Fortran) integer info call MPI_Info_create(info, ierr)! no. of I/O devices to be used for file striping call MPI_Info_set(info, "striping_factor", "4, ierr )! the striping unit in bytes call MPI_Info_set(info, "striping_unit", "65536, ierr ) call MPI_File_open(MPI_COMM_WORLD, "/pfs/datafile", & MPI_MODE_CREATE + MPI_MODE_RDWR, info, & fh, ierr ) call MPI_Info_free( info, ierr ) 25 25
26 Examples of Hints (used in ROMIO) striping_unit striping_factor cb_buffer_size cb_nodes ind_rd_buffer_size ind_wr_buffer_size start_iodevice pfs_svr_buf direct_read direct_write MPI predefined hints New Algorithm Parameters Platform-specific hints 26 26
27 Common MPI I/O Hints Controlling parallel file system striping_factor - size of strips on I/O servers striping_unit - number of I/O servers to stripe across start_iodevice - which I/O server to start with Controlling aggregation cb_config_list - list of aggregators cb_nodes - number of aggregators (upper bound) Tuning ROMIO (most common MPI-IO implementation) optimizations romio_cb_read, romio_cb_write - aggregation on/off romio_ds_read, romio_ds_write - data sieving on/off 27 27

28 Aggregation Example Cluster of SMPs One SMP box has fast connection to disks Data is aggregated to processes on single box Processes on that box perform I/O on behalf of the others 28 28
29 Ensuring Parallel I/O is Parallel On Blue Waters, by default, files are not striped That is, there is no parallelism in distributing the file across multiple disks You can set the striping factor on a directory; inherited by all files created in that directory lfs setstripe -c 4 <directory-name> You can set the striping factor on a file when it is created with MPI_File_open, using the hints, e.g., set MPI_Info_set(info, striping_factor, 4 ); MPI_Info_set(info, cb_nodes, 4 ); 29
30 Finding Hints on Blue Waters Setting the environment variable MPICH_MPIIO_HINTS_DISPLAY=1 causes the program to print out the available I/O hints and their values. 30
31 Example of Hints Display PE 0: MPICH/MPIIO environment settings: PE 0: MPICH_MPIIO_HINTS_DISPLAY = 1 PE 0: MPICH_MPIIO_HINTS = NULL PE 0: MPICH_MPIIO_ABORT_ON_RW_ERROR = disable PE 0: MPICH_MPIIO_CB_ALIGN = 2 PE 0: MPIIO hints for ioperf.out.tfargq: cb_buffer_size = romio_cb_read = automatic romio_cb_write = automatic cb_nodes = 1 cb_align = 2 romio_no_indep_rw = false romio_cb_pfr = disable romio_cb_fr_types = aar romio_cb_fr_alignment = 1 romio_cb_ds_threshold = 0 romio_cb_alltoall = automatic ind_rd_buffer_size = ind_wr_buffer_size = romio_ds_read = disable romio_ds_write = disable striping_factor = 1 striping_unit = romio_lustre_start_iodevice = 0 direct_io = false aggregator_placement_stride = -1 abort_on_rw_error = disable cb_config_list = *:* 31
32 Summary of I/O Tuning MPI I/O has many features that can help users achieve high performance The most important of these features are the ability to specify noncontiguous accesses, the collective I/O functions, and the ability to pass hints to the implementation Users must use the above features! In particular, when accesses are noncontiguous, users must create derived datatypes, define file views, and use the collective I/O functions 32 32
33 Common Errors in Using MPI-IO Not defining file offsets as MPI_Offset in C and integer (kind=mpi_offset_kind) in Fortran (or perhaps integer*8 in Fortran 77) In Fortran, passing the offset or displacement directly as a constant (e.g., 0) in the absence of function prototypes (F90 mpi module) Using darray datatype for a block distribution other than the one defined in darray (e.g., floor division) filetype defined using offsets that are not monotonically nondecreasing, e.g., 0, 3, 8, 4, 6. (can occur in irregular applications) 33 33
Parallel I/O and MPI-IO contd. Rajeev Thakur
 Parallel I/O and MPI-IO contd. Rajeev Thakur Outline Accessing noncontiguous data with MPI-IO Special features in MPI-IO for accessing subarrays and distributed arrays I/O performance tuning 2 Accessing
Parallel I/O and MPI-IO contd. Rajeev Thakur Outline Accessing noncontiguous data with MPI-IO Special features in MPI-IO for accessing subarrays and distributed arrays I/O performance tuning 2 Accessing
Parallel I/O. Steve Lantz Senior Research Associate Cornell CAC. Workshop: Data Analysis on Ranger, January 19, 2012
 Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Data Analysis on Ranger, January 19, 2012 Based on materials developed by Bill Barth at TACC 1. Lustre 2 Lustre Components All Ranger
Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Data Analysis on Ranger, January 19, 2012 Based on materials developed by Bill Barth at TACC 1. Lustre 2 Lustre Components All Ranger
Parallel I/O. Steve Lantz Senior Research Associate Cornell CAC. Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012
 Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012 Based on materials developed by Bill Barth at TACC Introduction: The Parallel
Parallel I/O Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar, May 16, 2012 Based on materials developed by Bill Barth at TACC Introduction: The Parallel
Best Practice Guide - Parallel I/O
 Sandra Mendez, LRZ, Germany Sebastian Lührs, FZJ, Germany Dominic Sloan-Murphy (Editor), EPCC, United Kingdom Andrew Turner (Editor), EPCC, United Kingdom Volker Weinberg (Editor), LRZ, Germany Version
Sandra Mendez, LRZ, Germany Sebastian Lührs, FZJ, Germany Dominic Sloan-Murphy (Editor), EPCC, United Kingdom Andrew Turner (Editor), EPCC, United Kingdom Volker Weinberg (Editor), LRZ, Germany Version
Introduction to Parallel I/O
 Introduction to Parallel I/O Bilel Hadri bhadri@utk.edu NICS Scientific Computing Group OLCF/NICS Fall Training October 19 th, 2011 Outline Introduction to I/O Path from Application to File System Common
Introduction to Parallel I/O Bilel Hadri bhadri@utk.edu NICS Scientific Computing Group OLCF/NICS Fall Training October 19 th, 2011 Outline Introduction to I/O Path from Application to File System Common
MPI-IO Performance Optimization IOR Benchmark on IBM ESS GL4 Systems
 MPI-IO Performance Optimization IOR Benchmark on IBM ESS GL4 Systems Xinghong He HPC Application Support IBM Systems WW Client Centers May 24 2016 Agenda System configurations Storage system, compute cluster
MPI-IO Performance Optimization IOR Benchmark on IBM ESS GL4 Systems Xinghong He HPC Application Support IBM Systems WW Client Centers May 24 2016 Agenda System configurations Storage system, compute cluster
Parallel I/O Techniques and Performance Optimization
 Parallel I/O Techniques and Performance Optimization Lonnie Crosby lcrosby1@utk.edu NICS Scientific Computing Group NICS/RDAV Spring Training 2012 March 22, 2012 2 Outline Introduction to I/O Path from
Parallel I/O Techniques and Performance Optimization Lonnie Crosby lcrosby1@utk.edu NICS Scientific Computing Group NICS/RDAV Spring Training 2012 March 22, 2012 2 Outline Introduction to I/O Path from
Parallel I/O: Not Your Job. Rob Latham and Rob Ross Mathematics and Computer Science Division Argonne National Laboratory {robl,
 Parallel I/O: Not Your Job Rob Latham and Rob Ross Mathematics and Computer Science Division Argonne National Laboratory {robl, rross}@mcs.anl.gov Computational Science! Use of computer simulation as a
Parallel I/O: Not Your Job Rob Latham and Rob Ross Mathematics and Computer Science Division Argonne National Laboratory {robl, rross}@mcs.anl.gov Computational Science! Use of computer simulation as a
Parallel I/O for High Performance and Scalability. It's Not Your Job (...it's mine)
") Parallel I/O for High Performance and Scalability or It's Not Your Job (...it's mine) Rob Latham Mathematics and Computer Science Division Argonne National Laboratory robl@mcs.anl.gov Computational Science
Parallel I/O for High Performance and Scalability or It's Not Your Job (...it's mine) Rob Latham Mathematics and Computer Science Division Argonne National Laboratory robl@mcs.anl.gov Computational Science
Optimizing I/O on the Cray XE/XC
 Optimizing I/O on the Cray XE/XC Agenda Scaling I/O Parallel Filesystems and Lustre I/O patterns Optimising I/O Scaling I/O We tend to talk a lot about scaling application computation Nodes, network, software
Optimizing I/O on the Cray XE/XC Agenda Scaling I/O Parallel Filesystems and Lustre I/O patterns Optimising I/O Scaling I/O We tend to talk a lot about scaling application computation Nodes, network, software
Parallel NetCDF. Rob Latham Mathematics and Computer Science Division Argonne National Laboratory
 Parallel NetCDF Rob Latham Mathematics and Computer Science Division Argonne National Laboratory robl@mcs.anl.gov I/O for Computational Science Application Application Parallel File System I/O Hardware
Parallel NetCDF Rob Latham Mathematics and Computer Science Division Argonne National Laboratory robl@mcs.anl.gov I/O for Computational Science Application Application Parallel File System I/O Hardware
Scalable I/O. Ed Karrels,
 Scalable I/O Ed Karrels, edk@illinois.edu I/O performance overview Main factors in performance Know your I/O Striping Data layout Collective I/O 2 of 32 I/O performance Length of each basic operation High
Scalable I/O Ed Karrels, edk@illinois.edu I/O performance overview Main factors in performance Know your I/O Striping Data layout Collective I/O 2 of 32 I/O performance Length of each basic operation High
Application I/O on Blue Waters. Rob Sisneros Kalyana Chadalavada
 Application I/O on Blue Waters Rob Sisneros Kalyana Chadalavada I/O For Science! HDF5 I/O Library PnetCDF Adios IOBUF Scien'st Applica'on I/O Middleware U'li'es Parallel File System Darshan Blue Waters
Application I/O on Blue Waters Rob Sisneros Kalyana Chadalavada I/O For Science! HDF5 I/O Library PnetCDF Adios IOBUF Scien'st Applica'on I/O Middleware U'li'es Parallel File System Darshan Blue Waters
Analyzing the High Performance Parallel I/O on LRZ HPC systems. Sandra Méndez. HPC Group, LRZ. June 23, 2016
 Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Parallel I/O on Theta with Best Practices
 Parallel I/O on Theta with Best Practices Paul Coffman pcoffman@anl.gov Francois Tessier, Preeti Malakar, George Brown ALCF 1 Parallel IO Performance on Theta dependent on optimal Lustre File System utilization
Parallel I/O on Theta with Best Practices Paul Coffman pcoffman@anl.gov Francois Tessier, Preeti Malakar, George Brown ALCF 1 Parallel IO Performance on Theta dependent on optimal Lustre File System utilization
Introdução ao MPI-IO. Escola Regional de Alto Desempenho 2018 Porto Alegre RS. Jean Luca Bez 1 Francieli Z. Boito 2 Philippe O. A.
 Introdução ao MPI-IO Escola Regional de Alto Desempenho 2018 Porto Alegre RS Jean Luca Bez 1 Francieli Z. Boito 2 Philippe O. A. Navaux 1 1 GPPD - INF - Universidade Federal do Rio Grande do Sul 2 INRIA
Introdução ao MPI-IO Escola Regional de Alto Desempenho 2018 Porto Alegre RS Jean Luca Bez 1 Francieli Z. Boito 2 Philippe O. A. Navaux 1 1 GPPD - INF - Universidade Federal do Rio Grande do Sul 2 INRIA
Programming with MPI: Advanced Topics
 Programming with MPI: Advanced Topics Steve Lantz Senior Research Associate Cornell CAC Workshop: Introduction to Parallel Computing on Ranger, May 19, 2010 Based on materials developed by by Bill Barth
Programming with MPI: Advanced Topics Steve Lantz Senior Research Associate Cornell CAC Workshop: Introduction to Parallel Computing on Ranger, May 19, 2010 Based on materials developed by by Bill Barth
High-Performance Techniques for Parallel I/O
 1 High-Performance Techniques for Parallel I/O Avery Ching Northwestern University Kenin Coloma Northwestern University Jianwei Li Northwestern University Alok Choudhary Northwestern University Wei-keng
1 High-Performance Techniques for Parallel I/O Avery Ching Northwestern University Kenin Coloma Northwestern University Jianwei Li Northwestern University Alok Choudhary Northwestern University Wei-keng
PERFORMANCE OF PARALLEL IO ON LUSTRE AND GPFS
 PERFORMANCE OF PARALLEL IO ON LUSTRE AND GPFS David Henty and Adrian Jackson (EPCC, The University of Edinburgh) Charles Moulinec and Vendel Szeremi (STFC, Daresbury Laboratory Outline Parallel IO problem
PERFORMANCE OF PARALLEL IO ON LUSTRE AND GPFS David Henty and Adrian Jackson (EPCC, The University of Edinburgh) Charles Moulinec and Vendel Szeremi (STFC, Daresbury Laboratory Outline Parallel IO problem
Overview of High Performance Input/Output on LRZ HPC systems. Christoph Biardzki Richard Patra Reinhold Bader
 Overview of High Performance Input/Output on LRZ HPC systems Christoph Biardzki Richard Patra Reinhold Bader Agenda Choosing the right file system Storage subsystems at LRZ Introduction to parallel file
Overview of High Performance Input/Output on LRZ HPC systems Christoph Biardzki Richard Patra Reinhold Bader Agenda Choosing the right file system Storage subsystems at LRZ Introduction to parallel file
High Performance Computing
 High Performance Computing ADVANCED SCIENTIFIC COMPUTING Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich
High Performance Computing ADVANCED SCIENTIFIC COMPUTING Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich
Introduction to I/O at CHPC
 CENTER FOR HIGH PERFORMANCE COMPUTING Introduction to I/O at CHPC Martin Čuma, m.cumautah.edu Center for High Performance Computing Fall 2015 Outline Types of storage available at CHPC Types of file I/O
CENTER FOR HIGH PERFORMANCE COMPUTING Introduction to I/O at CHPC Martin Čuma, m.cumautah.edu Center for High Performance Computing Fall 2015 Outline Types of storage available at CHPC Types of file I/O
Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen
 Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen May 5, 2008 Cray Inc. Proprietary Slide 1 Goals of the Presentation Provide users an overview of the
Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen May 5, 2008 Cray Inc. Proprietary Slide 1 Goals of the Presentation Provide users an overview of the
HDF5 I/O Performance. HDF and HDF-EOS Workshop VI December 5, 2002
 HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
Mark Pagel
 Mark Pagel pags@cray.com New features in XT MPT 3.1 and MPT 3.2 Features as a result of scaling to 150K MPI ranks MPI-IO Improvements(MPT 3.1 and MPT 3.2) SMP aware collective improvements(mpt 3.2) Misc
Mark Pagel pags@cray.com New features in XT MPT 3.1 and MPT 3.2 Features as a result of scaling to 150K MPI ranks MPI-IO Improvements(MPT 3.1 and MPT 3.2) SMP aware collective improvements(mpt 3.2) Misc
Chapter 11. Parallel I/O. Rajeev Thakur and William Gropp
 Chapter 11 Parallel I/O Rajeev Thakur and William Gropp Many parallel applications need to access large amounts of data. In such applications, the I/O performance can play a significant role in the overall
Chapter 11 Parallel I/O Rajeev Thakur and William Gropp Many parallel applications need to access large amounts of data. In such applications, the I/O performance can play a significant role in the overall
CHALLENGES FOR PARALLEL I/O IN GRID COMPUTING
 CHALLENGES FOR PARALLEL I/O IN GRID COMPUTING AVERY CHING 1, KENIN COLOMA 2, AND ALOK CHOUDHARY 3 1 Northwestern University, aching@ece.northwestern.edu, 2 Northwestern University, kcoloma@ece.northwestern.edu,
CHALLENGES FOR PARALLEL I/O IN GRID COMPUTING AVERY CHING 1, KENIN COLOMA 2, AND ALOK CHOUDHARY 3 1 Northwestern University, aching@ece.northwestern.edu, 2 Northwestern University, kcoloma@ece.northwestern.edu,
MPI-IO. Warwick RSE. Chris Brady Heather Ratcliffe. The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann.
 MPI-IO Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE Getting data in and out The purpose of MPI-IO is to get data
MPI-IO Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE Getting data in and out The purpose of MPI-IO is to get data
Parallel I/O Libraries and Techniques
 Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Guidelines for Efficient Parallel I/O on the Cray XT3/XT4
 Guidelines for Efficient Parallel I/O on the Cray XT3/XT4 Jeff Larkin, Cray Inc. and Mark Fahey, Oak Ridge National Laboratory ABSTRACT: This paper will present an overview of I/O methods on Cray XT3/XT4
Guidelines for Efficient Parallel I/O on the Cray XT3/XT4 Jeff Larkin, Cray Inc. and Mark Fahey, Oak Ridge National Laboratory ABSTRACT: This paper will present an overview of I/O methods on Cray XT3/XT4
Introduction to High Performance Parallel I/O
 Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Parallel IO Benchmarking
 Parallel IO Benchmarking Jia-Ying Wu August 17, 2016 MSc in High Performance Computing with Data Science The University of Edinburgh Year of Presentation: 2016 Abstract The project is aimed to investigate
Parallel IO Benchmarking Jia-Ying Wu August 17, 2016 MSc in High Performance Computing with Data Science The University of Edinburgh Year of Presentation: 2016 Abstract The project is aimed to investigate
I/O in scientific applications
 COSC 4397 Parallel I/O (II) Access patterns Spring 2010 I/O in scientific applications Different classes of I/O operations Required I/O: reading input data and writing final results Checkpointing: data
COSC 4397 Parallel I/O (II) Access patterns Spring 2010 I/O in scientific applications Different classes of I/O operations Required I/O: reading input data and writing final results Checkpointing: data
Lustre Parallel Filesystem Best Practices
 Lustre Parallel Filesystem Best Practices George Markomanolis Computational Scientist KAUST Supercomputing Laboratory georgios.markomanolis@kaust.edu.sa 7 November 2017 Outline Introduction to Parallel
Lustre Parallel Filesystem Best Practices George Markomanolis Computational Scientist KAUST Supercomputing Laboratory georgios.markomanolis@kaust.edu.sa 7 November 2017 Outline Introduction to Parallel
What is a file system
 COSC 6397 Big Data Analytics Distributed File Systems Edgar Gabriel Spring 2017 What is a file system A clearly defined method that the OS uses to store, catalog and retrieve files Manage the bits that
COSC 6397 Big Data Analytics Distributed File Systems Edgar Gabriel Spring 2017 What is a file system A clearly defined method that the OS uses to store, catalog and retrieve files Manage the bits that
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
A Parallel API for Creating and Reading NetCDF Files
 A Parallel API for Creating and Reading NetCDF Files January 4, 2015 Abstract Scientists recognize the importance of portable and efficient mechanisms for storing datasets created and used by their applications.
A Parallel API for Creating and Reading NetCDF Files January 4, 2015 Abstract Scientists recognize the importance of portable and efficient mechanisms for storing datasets created and used by their applications.
Reducing I/O variability using dynamic I/O path characterization in petascale storage systems
 J Supercomput (2017) 73:2069 2097 DOI 10.1007/s11227-016-1904-7 Reducing I/O variability using dynamic I/O path characterization in petascale storage systems Seung Woo Son 1 Saba Sehrish 2 Wei-keng Liao
J Supercomput (2017) 73:2069 2097 DOI 10.1007/s11227-016-1904-7 Reducing I/O variability using dynamic I/O path characterization in petascale storage systems Seung Woo Son 1 Saba Sehrish 2 Wei-keng Liao
Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications
 Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen, Cray Inc. ABSTRACT: The Cray XT implementation of MPI provides configurable runtime environment variables
Managing Cray XT MPI Runtime Environment Variables to Optimize and Scale Applications Geir Johansen, Cray Inc. ABSTRACT: The Cray XT implementation of MPI provides configurable runtime environment variables
Improving MPI Independent Write Performance Using A Two-Stage Write-Behind Buffering Method
 Improving MPI Independent Write Performance Using A Two-Stage Write-Behind Buffering Method Wei-keng Liao 1, Avery Ching 1, Kenin Coloma 1, Alok Choudhary 1, and Mahmut Kandemir 2 1 Northwestern University
Improving MPI Independent Write Performance Using A Two-Stage Write-Behind Buffering Method Wei-keng Liao 1, Avery Ching 1, Kenin Coloma 1, Alok Choudhary 1, and Mahmut Kandemir 2 1 Northwestern University
An Evolutionary Path to Object Storage Access
 An Evolutionary Path to Object Storage Access David Goodell +, Seong Jo (Shawn) Kim*, Robert Latham +, Mahmut Kandemir*, and Robert Ross + *Pennsylvania State University + Argonne National Laboratory Outline
An Evolutionary Path to Object Storage Access David Goodell +, Seong Jo (Shawn) Kim*, Robert Latham +, Mahmut Kandemir*, and Robert Ross + *Pennsylvania State University + Argonne National Laboratory Outline
Parallel I/O from a User s Perspective
 Parallel I/O from a User s Perspective HPC Advisory Council Stanford University, Dec. 6, 2011 Katie Antypas Group Leader, NERSC User Services NERSC is DOE in HPC Production Computing Facility NERSC computing
Parallel I/O from a User s Perspective HPC Advisory Council Stanford University, Dec. 6, 2011 Katie Antypas Group Leader, NERSC User Services NERSC is DOE in HPC Production Computing Facility NERSC computing
Improving Collective I/O Performance by Pipelining Request Aggregation and File Access
 Improving Collective I/O Performance by Pipelining Request Aggregation and File Access Saba Sehrish ssehrish@eecs.northwestern.edu Alok Choudhary choudhar@eecs.northwestern.edu Seung Woo Son sson@eecs.northwestern.edu
Improving Collective I/O Performance by Pipelining Request Aggregation and File Access Saba Sehrish ssehrish@eecs.northwestern.edu Alok Choudhary choudhar@eecs.northwestern.edu Seung Woo Son sson@eecs.northwestern.edu
Parallel I/O Performance Study and Optimizations with HDF5, A Scientific Data Package
 Parallel I/O Performance Study and Optimizations with HDF5, A Scientific Data Package MuQun Yang, Christian Chilan, Albert Cheng, Quincey Koziol, Mike Folk, Leon Arber The HDF Group Champaign, IL 61820
Parallel I/O Performance Study and Optimizations with HDF5, A Scientific Data Package MuQun Yang, Christian Chilan, Albert Cheng, Quincey Koziol, Mike Folk, Leon Arber The HDF Group Champaign, IL 61820
MPI Parallel I/O. Chieh-Sen (Jason) Huang. Department of Applied Mathematics. National Sun Yat-sen University
 Huang. Department of Applied Mathematics. National Sun Yat-sen University") MPI Parallel I/O Chieh-Sen (Jason) Huang Department of Applied Mathematics National Sun Yat-sen University Materials are taken from the book, Using MPI-2: Advanced Features of the Message-Passing Interface
MPI Parallel I/O Chieh-Sen (Jason) Huang Department of Applied Mathematics National Sun Yat-sen University Materials are taken from the book, Using MPI-2: Advanced Features of the Message-Passing Interface
Advanced MPI. William Gropp* Rusty Lusk Rob Ross Rajeev Thakur *University of Illinois. Argonne NaAonal Laboratory
 Advanced MPI William Gropp* Rusty Lusk Rob Ross Rajeev Thakur *University of Illinois Argonne NaAonal Laboratory Table of Contents IntroducAon 4 Mesh Algorithms and Game of Life 8 Parallel I/O and Life
Advanced MPI William Gropp* Rusty Lusk Rob Ross Rajeev Thakur *University of Illinois Argonne NaAonal Laboratory Table of Contents IntroducAon 4 Mesh Algorithms and Game of Life 8 Parallel I/O and Life
What NetCDF users should know about HDF5?
 What NetCDF users should know about HDF5? Elena Pourmal The HDF Group July 20, 2007 7/23/07 1 Outline The HDF Group and HDF software HDF5 Data Model Using HDF5 tools to work with NetCDF-4 programs files
What NetCDF users should know about HDF5? Elena Pourmal The HDF Group July 20, 2007 7/23/07 1 Outline The HDF Group and HDF software HDF5 Data Model Using HDF5 tools to work with NetCDF-4 programs files
How To write(101)data on a large system like a Cray XT called HECToR
data on a large system like a Cray XT called HECToR") How To write(101)data on a large system like a Cray XT called HECToR Martyn Foster mfoster@cray.com Topics Why does this matter? IO architecture on the Cray XT Hardware Architecture Language layers OS
How To write(101)data on a large system like a Cray XT called HECToR Martyn Foster mfoster@cray.com Topics Why does this matter? IO architecture on the Cray XT Hardware Architecture Language layers OS
Evaluating Algorithms for Shared File Pointer Operations in MPI I/O
 Evaluating Algorithms for Shared File Pointer Operations in MPI I/O Ketan Kulkarni and Edgar Gabriel Parallel Software Technologies Laboratory, Department of Computer Science, University of Houston {knkulkarni,gabriel}@cs.uh.edu
Evaluating Algorithms for Shared File Pointer Operations in MPI I/O Ketan Kulkarni and Edgar Gabriel Parallel Software Technologies Laboratory, Department of Computer Science, University of Houston {knkulkarni,gabriel}@cs.uh.edu
Enabling Active Storage on Parallel I/O Software Stacks. Seung Woo Son Mathematics and Computer Science Division
 Enabling Active Storage on Parallel I/O Software Stacks Seung Woo Son sson@mcs.anl.gov Mathematics and Computer Science Division MSST 2010, Incline Village, NV May 7, 2010 Performing analysis on large
Enabling Active Storage on Parallel I/O Software Stacks Seung Woo Son sson@mcs.anl.gov Mathematics and Computer Science Division MSST 2010, Incline Village, NV May 7, 2010 Performing analysis on large
COSC 6374 Parallel Computation. Parallel I/O (I) I/O basics. Concept of a clusters
 I/O basics. Concept of a clusters") COSC 6374 Parallel I/O (I) I/O basics Fall 2010 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network card 1 Network card
COSC 6374 Parallel I/O (I) I/O basics Fall 2010 Concept of a clusters Processor 1 local disks Compute node message passing network administrative network Memory Processor 2 Network card 1 Network card
Evaluating I/O Characteristics and Methods for Storing Structured Scientific Data
 Evaluating I/O Characteristics and Methods for Storing Structured Scientific Data Avery Ching 1, Alok Choudhary 1, Wei-keng Liao 1,LeeWard, and Neil Pundit 1 Northwestern University Sandia National Laboratories
Evaluating I/O Characteristics and Methods for Storing Structured Scientific Data Avery Ching 1, Alok Choudhary 1, Wei-keng Liao 1,LeeWard, and Neil Pundit 1 Northwestern University Sandia National Laboratories
PARALLEL I/O FOR SHARED MEMORY APPLICATIONS USING OPENMP
 PARALLEL I/O FOR SHARED MEMORY APPLICATIONS USING OPENMP A Dissertation Presented to the Faculty of the Department of Computer Science University of Houston In Partial Fulfillment of the Requirements for
PARALLEL I/O FOR SHARED MEMORY APPLICATIONS USING OPENMP A Dissertation Presented to the Faculty of the Department of Computer Science University of Houston In Partial Fulfillment of the Requirements for
Many parallel applications need to access large amounts of data. In such. possible to achieve good I/O performance in parallel applications by using a
 Chapter 13 Parallel I/O Rajeev Thakur & William Gropp Many parallel applications need to access large amounts of data. In such applications, the I/O performance can play a signicant role in the overall
Chapter 13 Parallel I/O Rajeev Thakur & William Gropp Many parallel applications need to access large amounts of data. In such applications, the I/O performance can play a signicant role in the overall
Parallel I/O with MPI TMA4280 Introduction to Supercomputing
 Parallel I/O with MPI TMA4280 Introduction to Supercomputing NTNU, IMF March 27. 2017 1 Limits of data processing Development of computational resource allow running more complex simulations. Volume of
Parallel I/O with MPI TMA4280 Introduction to Supercomputing NTNU, IMF March 27. 2017 1 Limits of data processing Development of computational resource allow running more complex simulations. Volume of
Data Management of Scientific Datasets on High Performance Interactive Clusters
 Data Management of Scientific Datasets on High Performance Interactive Clusters Faisal Ghias Mir Master of Science Thesis Stockholm, Sweden February 2006 Abstract The data analysis on scientific datasets
Data Management of Scientific Datasets on High Performance Interactive Clusters Faisal Ghias Mir Master of Science Thesis Stockholm, Sweden February 2006 Abstract The data analysis on scientific datasets
HPC Input/Output. I/O and Darshan. Cristian Simarro User Support Section
 HPC Input/Output I/O and Darshan Cristian Simarro Cristian.Simarro@ecmwf.int User Support Section Index Lustre summary HPC I/O Different I/O methods Darshan Introduction Goals Considerations How to use
HPC Input/Output I/O and Darshan Cristian Simarro Cristian.Simarro@ecmwf.int User Support Section Index Lustre summary HPC I/O Different I/O methods Darshan Introduction Goals Considerations How to use
Exploiting Lustre File Joining for Effective Collective IO
 Exploiting Lustre File Joining for Effective Collective IO Weikuan Yu, Jeffrey Vetter Oak Ridge National Laboratory Computer Science & Mathematics Oak Ridge, TN, USA 37831 {wyu,vetter}@ornl.gov R. Shane
Exploiting Lustre File Joining for Effective Collective IO Weikuan Yu, Jeffrey Vetter Oak Ridge National Laboratory Computer Science & Mathematics Oak Ridge, TN, USA 37831 {wyu,vetter}@ornl.gov R. Shane
A Comparative Experimental Study of Parallel File Systems for Large-Scale Data Processing
 A Comparative Experimental Study of Parallel File Systems for Large-Scale Data Processing Z. Sebepou, K. Magoutis, M. Marazakis, A. Bilas Institute of Computer Science (ICS) Foundation for Research and
A Comparative Experimental Study of Parallel File Systems for Large-Scale Data Processing Z. Sebepou, K. Magoutis, M. Marazakis, A. Bilas Institute of Computer Science (ICS) Foundation for Research and
Parallel I/O on JUQUEEN
 Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
MPI, Part 3. Scientific Computing Course, Part 3
 MPI, Part 3 Scientific Computing Course, Part 3 Non-blocking communications Diffusion: Had to Global Domain wait for communications to compute Could not compute end points without guardcell data All work
MPI, Part 3 Scientific Computing Course, Part 3 Non-blocking communications Diffusion: Had to Global Domain wait for communications to compute Could not compute end points without guardcell data All work
Parallel I/O and Portable Data Formats PnetCDF and NetCDF 4
 Parallel I/O and Portable Data Formats PnetDF and NetDF 4 Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing entre Forschungszentrum Jülich GmbH Jülich, March 13 th, 2017 Outline Introduction
Parallel I/O and Portable Data Formats PnetDF and NetDF 4 Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing entre Forschungszentrum Jülich GmbH Jülich, March 13 th, 2017 Outline Introduction
Lustre Lockahead: Early Experience and Performance using Optimized Locking. Michael Moore
 Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
Lustre Lockahead: Early Experience and Performance using Optimized Locking Michael Moore Agenda Purpose Investigate performance of a new Lustre and MPI-IO feature called Lustre Lockahead (LLA) Discuss
Noncontiguous I/O Accesses Through MPI-IO
 Noncontiguous I/O Accesses Through MPI-IO Avery Ching Alok Choudhary Kenin Coloma Wei-keng Liao Center for Parallel and Distributed Computing Northwestern University Evanston, IL 60208 aching, choudhar,
Noncontiguous I/O Accesses Through MPI-IO Avery Ching Alok Choudhary Kenin Coloma Wei-keng Liao Center for Parallel and Distributed Computing Northwestern University Evanston, IL 60208 aching, choudhar,
Data Sieving and Collective I/O in ROMIO
 Appeared in Proc. of the 7th Symposium on the Frontiers of Massively Parallel Computation, February 1999, pp. 182 189. c 1999 IEEE. Data Sieving and Collective I/O in ROMIO Rajeev Thakur William Gropp
Appeared in Proc. of the 7th Symposium on the Frontiers of Massively Parallel Computation, February 1999, pp. 182 189. c 1999 IEEE. Data Sieving and Collective I/O in ROMIO Rajeev Thakur William Gropp
Parallel I/O with MPI
 Parallel I/O with MPI March 15 2017 Benedikt Steinbusch Jülich Supercomputing Centre Parallel I/O with MPI Part I: Introduction March 15 2017 Benedikt Steinbusch Features of MPI I/O Standardized I/O API
Parallel I/O with MPI March 15 2017 Benedikt Steinbusch Jülich Supercomputing Centre Parallel I/O with MPI Part I: Introduction March 15 2017 Benedikt Steinbusch Features of MPI I/O Standardized I/O API
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
I/O Analysis and Optimization for an AMR Cosmology Application
 I/O Analysis and Optimization for an AMR Cosmology Application Jianwei Li Wei-keng Liao Alok Choudhary Valerie Taylor ECE Department, Northwestern University {jianwei, wkliao, choudhar, taylor}@ece.northwestern.edu
I/O Analysis and Optimization for an AMR Cosmology Application Jianwei Li Wei-keng Liao Alok Choudhary Valerie Taylor ECE Department, Northwestern University {jianwei, wkliao, choudhar, taylor}@ece.northwestern.edu
Using MPI File Caching to Improve Parallel Write Performance for Large-Scale Scientific Applications
 Using MPI File Caching to Improve Parallel Write Performance for Large-Scale Scientific Applications Wei-keng Liao, Avery Ching, Kenin Coloma, Arifa Nisar, and Alok Choudhary Electrical Engineering and
Using MPI File Caching to Improve Parallel Write Performance for Large-Scale Scientific Applications Wei-keng Liao, Avery Ching, Kenin Coloma, Arifa Nisar, and Alok Choudhary Electrical Engineering and
Adaptable IO System (ADIOS)
") Adaptable IO System (ADIOS) http://www.cc.gatech.edu/~lofstead/adios Cray User Group 2008 May 8, 2008 Chen Jin, Scott Klasky, Stephen Hodson, James B. White III, Weikuan Yu (Oak Ridge National Laboratory)
Adaptable IO System (ADIOS) http://www.cc.gatech.edu/~lofstead/adios Cray User Group 2008 May 8, 2008 Chen Jin, Scott Klasky, Stephen Hodson, James B. White III, Weikuan Yu (Oak Ridge National Laboratory)
Advanced Parallel Programming
 Advanced Parallel Programming Derived Datatypes Dr Daniel Holmes Applications Consultant dholmes@epcc.ed.ac.uk Overview Lecture will cover derived datatypes memory layouts vector datatypes floating vs
Advanced Parallel Programming Derived Datatypes Dr Daniel Holmes Applications Consultant dholmes@epcc.ed.ac.uk Overview Lecture will cover derived datatypes memory layouts vector datatypes floating vs
Advanced Parallel Programming
 Advanced Parallel Programming Derived Datatypes Dr David Henty HPC Training and Support Manager d.henty@epcc.ed.ac.uk +44 131 650 5960 16/01/2014 MPI-IO 2: Derived Datatypes 2 Overview Lecture will cover
Advanced Parallel Programming Derived Datatypes Dr David Henty HPC Training and Support Manager d.henty@epcc.ed.ac.uk +44 131 650 5960 16/01/2014 MPI-IO 2: Derived Datatypes 2 Overview Lecture will cover
Introduction to I/O at CHPC
 CENTER FOR HIGH PERFORMANCE COMPUTING Introduction to I/O at CHPC Martin Čuma, m.cuma@utah.edu Center for High Performance Computing Fall 2018 Outline Types of storage available at CHPC Types of file I/O
CENTER FOR HIGH PERFORMANCE COMPUTING Introduction to I/O at CHPC Martin Čuma, m.cuma@utah.edu Center for High Performance Computing Fall 2018 Outline Types of storage available at CHPC Types of file I/O
Evaluating Structured I/O Methods for Parallel File Systems
 INTERNATIONAL JOURNAL OF HIGH PERFORMANCE COMPUTING AND NETWORKING 1 Evaluating Structured I/O Methods for Parallel File Systems Avery Ching, Alok Choudhary, Wei-keng Liao, Robert Ross, William Gropp Abstract
INTERNATIONAL JOURNAL OF HIGH PERFORMANCE COMPUTING AND NETWORKING 1 Evaluating Structured I/O Methods for Parallel File Systems Avery Ching, Alok Choudhary, Wei-keng Liao, Robert Ross, William Gropp Abstract
Welcome! Virtual tutorial starts at 15:00 BST
 Welcome! Virtual tutorial starts at 15:00 BST Parallel IO and the ARCHER Filesystem ARCHER Virtual Tutorial, Wed 8 th Oct 2014 David Henty Reusing this material This work is licensed
Welcome! Virtual tutorial starts at 15:00 BST Parallel IO and the ARCHER Filesystem ARCHER Virtual Tutorial, Wed 8 th Oct 2014 David Henty Reusing this material This work is licensed
Feasibility Study of Effective Remote I/O Using a Parallel NetCDF Interface in a Long-Latency Network
 Feasibility Study of Effective Remote I/O Using a Parallel NetCDF Interface in a Long-Latency Network Yuichi Tsujita Abstract NetCDF provides portable and selfdescribing I/O data format for array-oriented
Feasibility Study of Effective Remote I/O Using a Parallel NetCDF Interface in a Long-Latency Network Yuichi Tsujita Abstract NetCDF provides portable and selfdescribing I/O data format for array-oriented
Pattern-Aware File Reorganization in MPI-IO
 Pattern-Aware File Reorganization in MPI-IO Jun He, Huaiming Song, Xian-He Sun, Yanlong Yin Computer Science Department Illinois Institute of Technology Chicago, Illinois 60616 {jhe24, huaiming.song, sun,
Pattern-Aware File Reorganization in MPI-IO Jun He, Huaiming Song, Xian-He Sun, Yanlong Yin Computer Science Department Illinois Institute of Technology Chicago, Illinois 60616 {jhe24, huaiming.song, sun,
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Hybrid Programming with OpenMP and MPI. Karl W. Schulz. Texas Advanced Computing Center The University of Texas at Austin
 Hybrid Programming with OpenMP and MPI Karl W. Schulz Texas Advanced Computing Center The University of Texas at Austin UT/Portugal Summer Institute Training Coimbra, Portugal July 17, 2008 Hybrid Outline
Hybrid Programming with OpenMP and MPI Karl W. Schulz Texas Advanced Computing Center The University of Texas at Austin UT/Portugal Summer Institute Training Coimbra, Portugal July 17, 2008 Hybrid Outline
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files
 System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
Meta-data Management System for High-Performance Large-Scale Scientific Data Access
 Meta-data Management System for High-Performance Large-Scale Scientific Data Access Wei-keng Liao, Xaiohui Shen, and Alok Choudhary Department of Electrical and Computer Engineering Northwestern University
Meta-data Management System for High-Performance Large-Scale Scientific Data Access Wei-keng Liao, Xaiohui Shen, and Alok Choudhary Department of Electrical and Computer Engineering Northwestern University
pnfs, POSIX, and MPI-IO: A Tale of Three Semantics
 Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
High Performance File I/O for The Blue Gene/L Supercomputer
 High Performance File I/O for The Blue Gene/L Supercomputer H. Yu, R. K. Sahoo, C. Howson, G. Almási, J. G. Castaños, M. Gupta IBM T. J. Watson Research Ctr, Yorktown Hts, NY {yuh,rsahoo,chowson,gheorghe,castanos,mgupta}@us.ibm.com
High Performance File I/O for The Blue Gene/L Supercomputer H. Yu, R. K. Sahoo, C. Howson, G. Almási, J. G. Castaños, M. Gupta IBM T. J. Watson Research Ctr, Yorktown Hts, NY {yuh,rsahoo,chowson,gheorghe,castanos,mgupta}@us.ibm.com
A High Performance Implementation of MPI-IO for a Lustre File System Environment
 A High Performance Implementation of MPI-IO for a Lustre File System Environment Phillip M. Dickens and Jeremy Logan Department of Computer Science, University of Maine Orono, Maine, USA dickens@umcs.maine.edu
A High Performance Implementation of MPI-IO for a Lustre File System Environment Phillip M. Dickens and Jeremy Logan Department of Computer Science, University of Maine Orono, Maine, USA dickens@umcs.maine.edu
libhio: Optimizing IO on Cray XC Systems With DataWarp
 libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
Scalable and Modular Parallel I/ O for Open MPI
 Scalable and Modular Parallel I/ O for Open MPI Parallel Software Technologies Laboratory Department of Computer Science, University of Houston gabriel@cs.uh.edu Outline Motivation MPI I/O: basic concepts
Scalable and Modular Parallel I/ O for Open MPI Parallel Software Technologies Laboratory Department of Computer Science, University of Houston gabriel@cs.uh.edu Outline Motivation MPI I/O: basic concepts
Do You Know What Your I/O Is Doing? (and how to fix it?) William Gropp
 William Gropp") Do You Know What Your I/O Is Doing? (and how to fix it?) William Gropp www.cs.illinois.edu/~wgropp Messages Current I/O performance is often appallingly poor Even relative to what current systems can achieve
Do You Know What Your I/O Is Doing? (and how to fix it?) William Gropp www.cs.illinois.edu/~wgropp Messages Current I/O performance is often appallingly poor Even relative to what current systems can achieve
Crossing the Chasm: Sneaking a parallel file system into Hadoop
 Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
Crossing the Chasm: Sneaking a parallel file system into Hadoop Wittawat Tantisiriroj Swapnil Patil, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University In this work Compare and contrast large
COSC 6374 Parallel Computation. Scientific Data Libraries. Edgar Gabriel Fall Motivation
 COSC 6374 Parallel Computation Scientific Data Libraries Edgar Gabriel Fall 2013 Motivation MPI I/O is good It knows about data types (=> data conversion) It can optimize various access patterns in applications
COSC 6374 Parallel Computation Scientific Data Libraries Edgar Gabriel Fall 2013 Motivation MPI I/O is good It knows about data types (=> data conversion) It can optimize various access patterns in applications
ECSS Project: Prof. Bodony: CFD, Aeroacoustics
 ECSS Project: Prof. Bodony: CFD, Aeroacoustics Robert McLay The Texas Advanced Computing Center June 19, 2012 ECSS Project: Bodony Aeroacoustics Program Program s name is RocfloCM It is mixture of Fortran
ECSS Project: Prof. Bodony: CFD, Aeroacoustics Robert McLay The Texas Advanced Computing Center June 19, 2012 ECSS Project: Bodony Aeroacoustics Program Program s name is RocfloCM It is mixture of Fortran
Parallel storage. Toni Cortes Team leader. EXPERTISE training school
 Parallel storage Toni Cortes Team leader Jan 11 th, 2018 EXPERTISE training school Agenda Introduction Parallel file systems Object stores Back to interfaces dataclay: next generation object store Agenda
Parallel storage Toni Cortes Team leader Jan 11 th, 2018 EXPERTISE training school Agenda Introduction Parallel file systems Object stores Back to interfaces dataclay: next generation object store Agenda
Taming Parallel I/O Complexity with Auto-Tuning
 Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Taming Parallel I/O Complexity with Auto-Tuning Babak Behzad 1, Huong Vu Thanh Luu 1, Joseph Huchette 2, Surendra Byna 3, Prabhat 3, Ruth Aydt 4, Quincey Koziol 4, Marc Snir 1,5 1 University of Illinois
Parallel I/O and Portable Data Formats
 Parallel I/O and Portable Data Formats Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Reykjavík, August 25 th, 2017 Overview I/O can be the main bottleneck
Parallel I/O and Portable Data Formats Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Reykjavík, August 25 th, 2017 Overview I/O can be the main bottleneck
Improving I/O Performance in POP (Parallel Ocean Program)
") Improving I/O Performance in POP (Parallel Ocean Program) Wang Di 2 Galen M. Shipman 1 Sarp Oral 1 Shane Canon 1 1 National Center for Computational Sciences, Oak Ridge National Laboratory Oak Ridge, TN
Improving I/O Performance in POP (Parallel Ocean Program) Wang Di 2 Galen M. Shipman 1 Sarp Oral 1 Shane Canon 1 1 National Center for Computational Sciences, Oak Ridge National Laboratory Oak Ridge, TN
MPICH on Clusters: Future Directions
 MPICH on Clusters: Future Directions Rajeev Thakur Mathematics and Computer Science Division Argonne National Laboratory thakur@mcs.anl.gov http://www.mcs.anl.gov/~thakur Introduction Linux clusters are
MPICH on Clusters: Future Directions Rajeev Thakur Mathematics and Computer Science Division Argonne National Laboratory thakur@mcs.anl.gov http://www.mcs.anl.gov/~thakur Introduction Linux clusters are
MPI-2 Overview. Rolf Rabenseifner University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS)
") MPI-2 Overview rabenseifner@hlrs.de University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Acknowledgements Parts of this course is based on MPI-2 tutorial on the
MPI-2 Overview rabenseifner@hlrs.de University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 Acknowledgements Parts of this course is based on MPI-2 tutorial on the
Challenges in HPC I/O
 Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
Implementing Byte-Range Locks Using MPI One-Sided Communication
 Implementing Byte-Range Locks Using MPI One-Sided Communication Rajeev Thakur, Robert Ross, and Robert Latham Mathematics and Computer Science Division Argonne National Laboratory Argonne, IL 60439, USA
Implementing Byte-Range Locks Using MPI One-Sided Communication Rajeev Thakur, Robert Ross, and Robert Latham Mathematics and Computer Science Division Argonne National Laboratory Argonne, IL 60439, USA
A First Implementation of Parallel IO in Chapel for Block Data Distribution 1
 A First Implementation of Parallel IO in Chapel for Block Data Distribution 1 Rafael LARROSA a, Rafael ASENJO a Angeles NAVARRO a and Bradford L. CHAMBERLAIN b a Dept. of Compt. Architect. Univ. of Malaga,
A First Implementation of Parallel IO in Chapel for Block Data Distribution 1 Rafael LARROSA a, Rafael ASENJO a Angeles NAVARRO a and Bradford L. CHAMBERLAIN b a Dept. of Compt. Architect. Univ. of Malaga,