ABSTRACT I. INTRODUCTION. 905 P a g e
|
|
|
- Antonia Gordon
- 6 years ago
- Views:
Transcription
1 Design and Implements of Booth and Robertson s multipliers algorithm on FPGA Dr. Ravi Shankar Mishra Prof. Puran Gour Braj Bihari Soni Head of the Department Assistant professor M.Tech. scholar NRI IIST, BHOPAL NRI IIST, BHOPAL NRI IIST, BHOPAL ABSTRACT The Arithmetic and logical unit play an important role in digital systems. Particular, Multiplication is especially relevant instead of other arithmetic operators, such as division or exponentiation, which one is also utilized by multiplier as building blocks. Multipliers are key components of many high performance systems such as FIR filters, microprocessors, digital signal processors, etc. A system s performance is generally determined by the performance of the multiplier because the multiplier is generally the slowest element in the system. For faster computation, this paper compared Robertson s and Booth s algorithm in which quick and accurate performance of multiplier operation has been done. These algorithms provides high performance than other multiplication algorithms. For achieving these task, Xilinx ISE 8.1i software has been used and implemented on FPGA xc3s400pq Keywords: Booth, FPGA, VHDL, Robertson s, Multiplication, Xilinx ISE 8.1i I. INTRODUCTION Digital arithmetic operations are very important in the design of digital processors and applicationspecific systems. Arithmetic circuits form an important class of circuits in digital systems. With the remarkable progress in the very large scale integration (VLSI) circuit technology, many complex circuits, unthinkable yesterday have become easily realizable today.algorithms that seemed impossible to implement now, have attractive implementation possibilities for the future. This means that not only the conventional computer arithmetic methods, but also the unconventional ones are worth investigation in new designs. Multiplication is especially relevant since other arithmetic operators, such as division or exponentiation, which they usually utilize multipliers as building blocks [3]. Hardware implementation of arithmetic operations has been oriented typically to use VLSI circuits. Among the arithmetic operations, the multiplication is widely used in applications such as graphics and scientific computation. Therefore, different kind of schemes has been developed. There are several algorithms for the computation of multiplication. Conventional algorithms include: 1) Booth s algorithm. 2) Robertson s algorithm. 1). BOOTH'S ALGORITHM Requires that we can do an addition or a subtraction each iteration (not always an addition). When doing multiplication, strings of 0s in the multiplier require only shifting (no addition). When doing multiplication, strings of 1s in the multiplier require an operation only at each end. We need to add or subtract only at positions in the multiplier where there is a transition from a 0 to a 1, or from a 1 to a 0.[12] 905 P a g e
2 10 subtract multiplicand from left half of product and shifting 11 no arithmetic operation only shifting So, here we are using arithmetic right shift (ASR).[14] 2).ROBERTSON'S ALGORITHM Fig1-Flowchart of booth algorithm By above flow chart description we have, b=multiplier, a=multiplicand, m= Product. First we will need twice as many bits in our product as we have in our original two operands. The leftmost bit of our operands (both multiplier and multiplicand) is a sign bit, and cannot be used as part of the value. Then Decide which operand will be the multiplier and which will be the multiplicand. If any operand and both is negative it is represent in two's complement. Begin with a product that consists of the multiplier with an additional X leading zero bits. And check the LSB and the previous LSB of product to determine the arithmetic action. If it is the FIRST pass, use 0 as the previous LSB. Possible arithmetic actions: 00 no arithmetic operation only shifting 01 add multiplicand to left half of product and shifting Fig2-Flowchart of Robertson s algorithm Consider the case that we want to multiply two 8 bit numbers X = x0x1:::x3 and Y = y0y1:::y3. Depending on the sign of the two operands X and Y, there are 4 cases to be considered: X0 = y0 = 0, that is, both X and Y are positive. Hence, multiplication of these numbers is similar to the multiplication of unsigned numbers. In other words, the product P is computed in a series of add-and-shift steps of the form P i P i + X i * Y P i+1 P i * 2-1 Note that all partial products are nonnegative. Hence, leading 0s are introduced during 906 P a g e

3 right shift of the partial product. x0 = 1; y0 = 0, that is, X is negative and Y is positive. In this case, the partial product is always positive (till the sign bit x0 is used). In the final step, a subtraction is performed. That is, x0 = 0; y0 = 1, that is, X is positive and Y is negative. In this case, the partial product is positive and hence leading 0s are shifted into the partial product until the rest 1 in X is encountered. Multiplication of Y by this 1, and addition to the result causes the partial product to be negative, from which point on leading 1s are shifted in (rather than 0s). x0 = 1; y0 = 1, that is, both X and Y are negative. Once again, leading 1s are shifted into the partial product whenever the partial product is negative. Also, since X is negative, the correction step (subtraction as the last step) is also performed. Recall the difference in the correction steps between multiplication of two integers and two fractions. In the case of two integers, the correction step involves subtraction and shift right. Whereas, in the case of fractions, the correction step involves subtraction and setting.[5] Fig.3: synthesis report of 4 4 -bit Booth multiplier III.RESULT AND DISCUSSION The design of fixed point 4 4 -bit booth multipliers, 4 4 -bit Robertson s multipliers has been done using VHDL and implemented in a Xilinx Spartan-3AN (Selected Device : 3s400pq208-5) FPGA using the Xilinx ISE 8.1i design tool. Figs. 3,4,5,6 illustrate the synthesis report and RTL View (Top Module) and Internal RTL View and Simulation result of 4 4 -bit Booth multipliers.figs. 7,8,9,10 illustrate the synthesis report and RTL View (Top Module) and Internal RTL View and Simulation result of 4 4 -bit Robertson s multipliers. Table 1 summarizes the FPGA device resources utilization for 4 4 Booth and 4 4Robertson s multiplier for Spartan-3AN (Selected Device : 3s400pq208-5). Fig.4: RTL View of 4 4 -bit Booth multiplier (Top Module) 907 P a g e


 Fig 6: Simulation of")

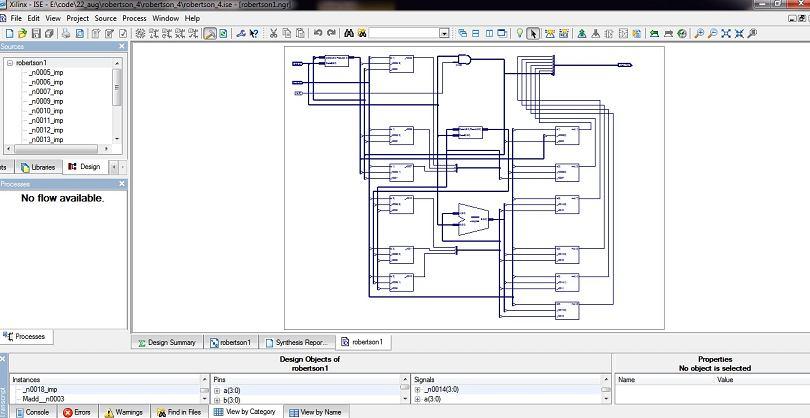
4 Fig.7: synthesis report of 4 4 -bit Robertson s multiplier Fig 5: Internal RTL View of 4 4 -bit Booth multiplier Fig.8: RTL View of 4 4 -bit Robertson s multiplier (Top Module) Fig 6: Simulation of 4 4 -bit Booth multiplier Fig.9: Internal RTL View of 4 4 -bit Robertson s multiplier 908 P a g e
![[1] Muhammad H. Rais and Mohamed H.](/docs-images/75/72253408/images/5-0.jpg "Al Mijalli, FPGA Based Fixed Width 4 4, 6 6, 8 8 and 12 12-Bit Multipliers using Spartan-3AN, IJCSNS International Journal of Computer Science and Network Security, VOL.11 No.2, February 2011 [2] T.J. Todman, G.")
5 [1] Muhammad H. Rais and Mohamed H. Al Mijalli, FPGA Based Fixed Width 4 4, 6 6, 8 8 and Bit Multipliers using Spartan-3AN, IJCSNS International Journal of Computer Science and Network Security, VOL.11 No.2, February 2011 [2] T.J. Todman, G.A. Constantinides, S.J.E. Wilton, O. Mencer, W. Luk and P.Y.K. Cheung, Reconfigurable computing: architectures and design methods, in IEE Proc. of the Computer and Digital Techniques, 2005, Vol. 152, No. 2, pp Fig.10: Simulation of 4 4 -bit Robertson s multiplier IV. DEVICE UTILIZATION Table 1:FPGA resource utilization for Booth and Robertson s multiplier for Spartan-3AN (Selected Device : 3s400pq208-5) Bit Wid th Multipli ers algorith m Numb er of Slices Numb er of 4 input LUTs Numb er of bonde d IOBs Dele y 4 4 Booth s ns 4 4 Robertso n s ns V. CONCLUSION We have presented the FPGA implementation for fixed point 4 4 Booth multiplier algorithm, 4 4 Robertson s multiplier algorithm. So, after comparison of booth algorithm and Robertson s algorithm results concluded that, Robertson s algorithm used less hardware but booth algorithm take less delay time. We have used a FPGA Spartan XC3S400pq208-5 for physical implementation and for synthesis and simulation process we have used the computation packet ISE 8.1i provided by Xilinx. References [3] M.A.G. Martinez, R.P. Gomez, G.M. Luna and F.R. Henrique, FPGA Implementation of an Efficient Multiplier over Finite Fields GF(2m) Proceedings of International Conf. On Reconfigurable Computing and FPGAs, [4] C. Maxfield, The Design Warrior s Guide to FPGAs: Devices, Tools and flows. Newnes Publishers, MA, [5 ] John Wiley & Sons Arithmetic and Logic in Computer Systems A JOHN WILEY & SONS, INC., PUBLICATION. [6] E.III. Walters, M.G. Arnold, and M.J. Schulte, Using truncated multipliers in DCT and IDCT hardware accelerators, in Proc. of the XIII SPIE Advanced Signal Processing Algorithms, Architectures, and Implementations, 2003, pp [ 7] J.H.Kim, J.S.Lee and J.D.Cho A Low Power Booth Multiplier Based on Operand Swapping in Instruction Level Journal of the Korean Physical Society, Vol. 33, No., January 1998, pp. S258_S261. [8] Stuart F. Oberman, and Michael J. Flynn, Division Algorithms and Implementations IEEE Transactions on Computers, vol. 46, no. 8, August 1997 [9] L. Song, K.K. Parhi, Efficient Finite Field Serial/Parallel Multiplication, Proc. of International Conf. On Application Specific Systems, Architectures and Processors, pp , Chicago,USA, [10] Rajendra Katti A Modified Booth Algorithm for High Radix Fixed-point Multiplication IEEE 909 P a g e
6 Trans. VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL 2. NO 1. Dec. l994. [11] P. E. Madrid, B. Millar, and E. E. Swartzlander, Modified Booth algorithm for high radix fixed-point multiplication, IEEE Trans. VLSI Syst., vol. 1, no. 2, pp , June 1993 [12] J. J. F. Cavanagh, Digital Computer Arithmetic, New York: McGraw Hill, [13] Douglas L. Perry, VHDL programming by Example. [online] [web] &printsec=frontcover&dq=vhdl 910 P a g e
VLSI IMPLEMENTATION OF PIPELINED QUADRATIC FUNCTION
 VLSI IMPLEMENTATION OF PIPELINED QUADRATIC FUNCTION A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIRMENTS FOR THE DEGREE OF Master of Technology In VLSI Design and Embedded Systems By NARESH KUMAR
VLSI IMPLEMENTATION OF PIPELINED QUADRATIC FUNCTION A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIRMENTS FOR THE DEGREE OF Master of Technology In VLSI Design and Embedded Systems By NARESH KUMAR
Pipelined Quadratic Equation based Novel Multiplication Method for Cryptographic Applications
 , Vol 7(4S), 34 39, April 204 ISSN (Print): 0974-6846 ISSN (Online) : 0974-5645 Pipelined Quadratic Equation based Novel Multiplication Method for Cryptographic Applications B. Vignesh *, K. P. Sridhar
, Vol 7(4S), 34 39, April 204 ISSN (Print): 0974-6846 ISSN (Online) : 0974-5645 Pipelined Quadratic Equation based Novel Multiplication Method for Cryptographic Applications B. Vignesh *, K. P. Sridhar
International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
 An Efficient Implementation of Double Precision Floating Point Multiplier Using Booth Algorithm Pallavi Ramteke 1, Dr. N. N. Mhala 2, Prof. P. R. Lakhe M.Tech [IV Sem], Dept. of Comm. Engg., S.D.C.E, [Selukate],
An Efficient Implementation of Double Precision Floating Point Multiplier Using Booth Algorithm Pallavi Ramteke 1, Dr. N. N. Mhala 2, Prof. P. R. Lakhe M.Tech [IV Sem], Dept. of Comm. Engg., S.D.C.E, [Selukate],
Implementation of IEEE754 Floating Point Multiplier
 Implementation of IEEE754 Floating Point Multiplier A Kumutha 1 Shobha. P 2 1 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67. 2 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67.
Implementation of IEEE754 Floating Point Multiplier A Kumutha 1 Shobha. P 2 1 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67. 2 MVJ College of Engineering, Near ITPB, Channasandra, Bangalore-67.
High speed Integrated Circuit Hardware Description Language), RTL (Register transfer level). Abstract:
, RTL (Register transfer level). Abstract:") based implementation of 8-bit ALU of a RISC processor using Booth algorithm written in VHDL language Paresh Kumar Pasayat, Manoranjan Pradhan, Bhupesh Kumar Pasayat Abstract: This paper explains the design
based implementation of 8-bit ALU of a RISC processor using Booth algorithm written in VHDL language Paresh Kumar Pasayat, Manoranjan Pradhan, Bhupesh Kumar Pasayat Abstract: This paper explains the design
DESIGN AND IMPLEMENTATION OF VLSI SYSTOLIC ARRAY MULTIPLIER FOR DSP APPLICATIONS
 International Journal of Computing Academic Research (IJCAR) ISSN 2305-9184 Volume 2, Number 4 (August 2013), pp. 140-146 MEACSE Publications http://www.meacse.org/ijcar DESIGN AND IMPLEMENTATION OF VLSI
International Journal of Computing Academic Research (IJCAR) ISSN 2305-9184 Volume 2, Number 4 (August 2013), pp. 140-146 MEACSE Publications http://www.meacse.org/ijcar DESIGN AND IMPLEMENTATION OF VLSI
OPTIMIZATION OF AREA COMPLEXITY AND DELAY USING PRE-ENCODED NR4SD MULTIPLIER.
 OPTIMIZATION OF AREA COMPLEXITY AND DELAY USING PRE-ENCODED NR4SD MULTIPLIER. A.Anusha 1 R.Basavaraju 2 anusha201093@gmail.com 1 basava430@gmail.com 2 1 PG Scholar, VLSI, Bharath Institute of Engineering
OPTIMIZATION OF AREA COMPLEXITY AND DELAY USING PRE-ENCODED NR4SD MULTIPLIER. A.Anusha 1 R.Basavaraju 2 anusha201093@gmail.com 1 basava430@gmail.com 2 1 PG Scholar, VLSI, Bharath Institute of Engineering
High Speed Special Function Unit for Graphics Processing Unit
 High Speed Special Function Unit for Graphics Processing Unit Abd-Elrahman G. Qoutb 1, Abdullah M. El-Gunidy 1, Mohammed F. Tolba 1, and Magdy A. El-Moursy 2 1 Electrical Engineering Department, Fayoum
High Speed Special Function Unit for Graphics Processing Unit Abd-Elrahman G. Qoutb 1, Abdullah M. El-Gunidy 1, Mohammed F. Tolba 1, and Magdy A. El-Moursy 2 1 Electrical Engineering Department, Fayoum
An Optimized Montgomery Modular Multiplication Algorithm for Cryptography
 118 IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.1, January 2013 An Optimized Montgomery Modular Multiplication Algorithm for Cryptography G.Narmadha 1 Asst.Prof /ECE,
118 IJCSNS International Journal of Computer Science and Network Security, VOL.13 No.1, January 2013 An Optimized Montgomery Modular Multiplication Algorithm for Cryptography G.Narmadha 1 Asst.Prof /ECE,
ISSN Vol.02, Issue.11, December-2014, Pages:
 ISSN 2322-0929 Vol.02, Issue.11, December-2014, Pages:1208-1212 www.ijvdcs.org Implementation of Area Optimized Floating Point Unit using Verilog G.RAJA SEKHAR 1, M.SRIHARI 2 1 PG Scholar, Dept of ECE,
ISSN 2322-0929 Vol.02, Issue.11, December-2014, Pages:1208-1212 www.ijvdcs.org Implementation of Area Optimized Floating Point Unit using Verilog G.RAJA SEKHAR 1, M.SRIHARI 2 1 PG Scholar, Dept of ECE,
VLSI Design Of a Novel Pre Encoding Multiplier Using DADDA Multiplier. Guntur(Dt),Pin:522017
,Pin:522017") VLSI Design Of a Novel Pre Encoding Multiplier Using DADDA Multiplier 1 Katakam Hemalatha,(M.Tech),Email Id: hema.spark2011@gmail.com 2 Kundurthi Ravi Kumar, M.Tech,Email Id: kundurthi.ravikumar@gmail.com
VLSI Design Of a Novel Pre Encoding Multiplier Using DADDA Multiplier 1 Katakam Hemalatha,(M.Tech),Email Id: hema.spark2011@gmail.com 2 Kundurthi Ravi Kumar, M.Tech,Email Id: kundurthi.ravikumar@gmail.com
FPGA IMPLEMENTATION OF FLOATING POINT ADDER AND MULTIPLIER UNDER ROUND TO NEAREST
 FPGA IMPLEMENTATION OF FLOATING POINT ADDER AND MULTIPLIER UNDER ROUND TO NEAREST SAKTHIVEL Assistant Professor, Department of ECE, Coimbatore Institute of Engineering and Technology Abstract- FPGA is
FPGA IMPLEMENTATION OF FLOATING POINT ADDER AND MULTIPLIER UNDER ROUND TO NEAREST SAKTHIVEL Assistant Professor, Department of ECE, Coimbatore Institute of Engineering and Technology Abstract- FPGA is
Fused Floating Point Arithmetic Unit for Radix 2 FFT Implementation
 IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 6, Issue 2, Ver. I (Mar. -Apr. 2016), PP 58-65 e-issn: 2319 4200, p-issn No. : 2319 4197 www.iosrjournals.org Fused Floating Point Arithmetic
IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 6, Issue 2, Ver. I (Mar. -Apr. 2016), PP 58-65 e-issn: 2319 4200, p-issn No. : 2319 4197 www.iosrjournals.org Fused Floating Point Arithmetic
Design of Delay Efficient Distributed Arithmetic Based Split Radix FFT
 Design of Delay Efficient Arithmetic Based Split Radix FFT Nisha Laguri #1, K. Anusudha *2 #1 M.Tech Student, Electronics, Department of Electronics Engineering, Pondicherry University, Puducherry, India
Design of Delay Efficient Arithmetic Based Split Radix FFT Nisha Laguri #1, K. Anusudha *2 #1 M.Tech Student, Electronics, Department of Electronics Engineering, Pondicherry University, Puducherry, India
Design and Implementation of VLSI 8 Bit Systolic Array Multiplier
 Design and Implementation of VLSI 8 Bit Systolic Array Multiplier Khumanthem Devjit Singh, K. Jyothi MTech student (VLSI & ES), GIET, Rajahmundry, AP, India Associate Professor, Dept. of ECE, GIET, Rajahmundry,
Design and Implementation of VLSI 8 Bit Systolic Array Multiplier Khumanthem Devjit Singh, K. Jyothi MTech student (VLSI & ES), GIET, Rajahmundry, AP, India Associate Professor, Dept. of ECE, GIET, Rajahmundry,
Design of Double Precision Floating Point Multiplier Using Vedic Multiplication
 Design of Double Precision Floating Point Multiplier Using Vedic Multiplication 1 D.Heena Tabassum, 2 K.Sreenivas Rao 1, 2 Electronics and Communication Engineering, 1, 2 Annamacharya institute of technology
Design of Double Precision Floating Point Multiplier Using Vedic Multiplication 1 D.Heena Tabassum, 2 K.Sreenivas Rao 1, 2 Electronics and Communication Engineering, 1, 2 Annamacharya institute of technology
Designing an Improved 64 Bit Arithmetic and Logical Unit for Digital Signaling Processing Purposes
 Available Online at- http://isroj.net/index.php/issue/current-issue ISROJ Index Copernicus Value for 2015: 49.25 Volume 02 Issue 01, 2017 e-issn- 2455 8818 Designing an Improved 64 Bit Arithmetic and Logical
Available Online at- http://isroj.net/index.php/issue/current-issue ISROJ Index Copernicus Value for 2015: 49.25 Volume 02 Issue 01, 2017 e-issn- 2455 8818 Designing an Improved 64 Bit Arithmetic and Logical
Implementation of Double Precision Floating Point Multiplier in VHDL
 ISSN (O): 2349-7084 International Journal of Computer Engineering In Research Trends Available online at: www.ijcert.org Implementation of Double Precision Floating Point Multiplier in VHDL 1 SUNKARA YAMUNA
ISSN (O): 2349-7084 International Journal of Computer Engineering In Research Trends Available online at: www.ijcert.org Implementation of Double Precision Floating Point Multiplier in VHDL 1 SUNKARA YAMUNA
DESIGN OF LOGARITHM BASED FLOATING POINT MULTIPLICATION AND DIVISION ON FPGA
 DESIGN OF LOGARITHM BASED FLOATING POINT MULTIPLICATION AND DIVISION ON FPGA N. Ramya Rani 1 V. Subbiah 2 and L. Sivakumar 1 1 Department of Electronics & Communication Engineering, Sri Krishna College
DESIGN OF LOGARITHM BASED FLOATING POINT MULTIPLICATION AND DIVISION ON FPGA N. Ramya Rani 1 V. Subbiah 2 and L. Sivakumar 1 1 Department of Electronics & Communication Engineering, Sri Krishna College
An Efficient Design of Sum-Modified Booth Recoder for Fused Add-Multiply Operator
 An Efficient Design of Sum-Modified Booth Recoder for Fused Add-Multiply Operator M.Chitra Evangelin Christina Associate Professor Department of Electronics and Communication Engineering Francis Xavier
An Efficient Design of Sum-Modified Booth Recoder for Fused Add-Multiply Operator M.Chitra Evangelin Christina Associate Professor Department of Electronics and Communication Engineering Francis Xavier
HIGH PERFORMANCE QUATERNARY ARITHMETIC LOGIC UNIT ON PROGRAMMABLE LOGIC DEVICE
 International Journal of Advances in Applied Science and Engineering (IJAEAS) ISSN (P): 2348-1811; ISSN (E): 2348-182X Vol. 2, Issue 1, Feb 2015, 01-07 IIST HIGH PERFORMANCE QUATERNARY ARITHMETIC LOGIC
International Journal of Advances in Applied Science and Engineering (IJAEAS) ISSN (P): 2348-1811; ISSN (E): 2348-182X Vol. 2, Issue 1, Feb 2015, 01-07 IIST HIGH PERFORMANCE QUATERNARY ARITHMETIC LOGIC
A Review on Optimizing Efficiency of Fixed Point Multiplication using Modified Booth s Algorithm
 A Review on Optimizing Efficiency of Fixed Point Multiplication using Modified Booth s Algorithm Mahendra R. Bhongade, Manas M. Ramteke, Vijay G. Roy Author Details Mahendra R. Bhongade, Department of
A Review on Optimizing Efficiency of Fixed Point Multiplication using Modified Booth s Algorithm Mahendra R. Bhongade, Manas M. Ramteke, Vijay G. Roy Author Details Mahendra R. Bhongade, Department of
Prachi Sharma 1, Rama Laxmi 2, Arun Kumar Mishra 3 1 Student, 2,3 Assistant Professor, EC Department, Bhabha College of Engineering
 A Review: Design of 16 bit Arithmetic and Logical unit using Vivado 14.7 and Implementation on Basys 3 FPGA Board Prachi Sharma 1, Rama Laxmi 2, Arun Kumar Mishra 3 1 Student, 2,3 Assistant Professor,
A Review: Design of 16 bit Arithmetic and Logical unit using Vivado 14.7 and Implementation on Basys 3 FPGA Board Prachi Sharma 1, Rama Laxmi 2, Arun Kumar Mishra 3 1 Student, 2,3 Assistant Professor,
A Novel Efficient VLSI Architecture for IEEE 754 Floating point multiplier using Modified CSA
 RESEARCH ARTICLE OPEN ACCESS A Novel Efficient VLSI Architecture for IEEE 754 Floating point multiplier using Nishi Pandey, Virendra Singh Sagar Institute of Research & Technology Bhopal Abstract Due to
RESEARCH ARTICLE OPEN ACCESS A Novel Efficient VLSI Architecture for IEEE 754 Floating point multiplier using Nishi Pandey, Virendra Singh Sagar Institute of Research & Technology Bhopal Abstract Due to
VHDL implementation of 32-bit floating point unit (FPU)
") VHDL implementation of 32-bit floating point unit (FPU) Nikhil Arora Govindam Sharma Sachin Kumar M.Tech student M.Tech student M.Tech student YMCA, Faridabad YMCA, Faridabad YMCA, Faridabad Abstract The
VHDL implementation of 32-bit floating point unit (FPU) Nikhil Arora Govindam Sharma Sachin Kumar M.Tech student M.Tech student M.Tech student YMCA, Faridabad YMCA, Faridabad YMCA, Faridabad Abstract The
Power Optimized Programmable Truncated Multiplier and Accumulator Using Reversible Adder
 Power Optimized Programmable Truncated Multiplier and Accumulator Using Reversible Adder Syeda Mohtashima Siddiqui M.Tech (VLSI & Embedded Systems) Department of ECE G Pulla Reddy Engineering College (Autonomous)
Power Optimized Programmable Truncated Multiplier and Accumulator Using Reversible Adder Syeda Mohtashima Siddiqui M.Tech (VLSI & Embedded Systems) Department of ECE G Pulla Reddy Engineering College (Autonomous)
VHDL IMPLEMENTATION OF FLOATING POINT MULTIPLIER USING VEDIC MATHEMATICS
 VHDL IMPLEMENTATION OF FLOATING POINT MULTIPLIER USING VEDIC MATHEMATICS I.V.VAIBHAV 1, K.V.SAICHARAN 1, B.SRAVANTHI 1, D.SRINIVASULU 2 1 Students of Department of ECE,SACET, Chirala, AP, India 2 Associate
VHDL IMPLEMENTATION OF FLOATING POINT MULTIPLIER USING VEDIC MATHEMATICS I.V.VAIBHAV 1, K.V.SAICHARAN 1, B.SRAVANTHI 1, D.SRINIVASULU 2 1 Students of Department of ECE,SACET, Chirala, AP, India 2 Associate
Carry-Free Radix-2 Subtractive Division Algorithm and Implementation of the Divider
 Tamkang Journal of Science and Engineering, Vol. 3, No., pp. 29-255 (2000) 29 Carry-Free Radix-2 Subtractive Division Algorithm and Implementation of the Divider Jen-Shiun Chiang, Hung-Da Chung and Min-Show
Tamkang Journal of Science and Engineering, Vol. 3, No., pp. 29-255 (2000) 29 Carry-Free Radix-2 Subtractive Division Algorithm and Implementation of the Divider Jen-Shiun Chiang, Hung-Da Chung and Min-Show
Pipelined High Speed Double Precision Floating Point Multiplier Using Dadda Algorithm Based on FPGA
 RESEARCH ARTICLE OPEN ACCESS Pipelined High Speed Double Precision Floating Point Multiplier Using Dadda Algorithm Based on FPGA J.Rupesh Kumar, G.Ram Mohan, Sudershanraju.Ch M. Tech Scholar, Dept. of
RESEARCH ARTICLE OPEN ACCESS Pipelined High Speed Double Precision Floating Point Multiplier Using Dadda Algorithm Based on FPGA J.Rupesh Kumar, G.Ram Mohan, Sudershanraju.Ch M. Tech Scholar, Dept. of
FPGA Based Design and Simulation of 32- Point FFT Through Radix-2 DIT Algorith
 FPGA Based Design and Simulation of 32- Point FFT Through Radix-2 DIT Algorith Sudhanshu Mohan Khare M.Tech (perusing), Dept. of ECE Laxmi Naraian College of Technology, Bhopal, India M. Zahid Alam Associate
FPGA Based Design and Simulation of 32- Point FFT Through Radix-2 DIT Algorith Sudhanshu Mohan Khare M.Tech (perusing), Dept. of ECE Laxmi Naraian College of Technology, Bhopal, India M. Zahid Alam Associate
OPTIMIZING THE POWER USING FUSED ADD MULTIPLIER
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 11, November 2014,
IMPLEMENTATION OF AN ADAPTIVE FIR FILTER USING HIGH SPEED DISTRIBUTED ARITHMETIC
 IMPLEMENTATION OF AN ADAPTIVE FIR FILTER USING HIGH SPEED DISTRIBUTED ARITHMETIC Thangamonikha.A 1, Dr.V.R.Balaji 2 1 PG Scholar, Department OF ECE, 2 Assitant Professor, Department of ECE 1, 2 Sri Krishna
IMPLEMENTATION OF AN ADAPTIVE FIR FILTER USING HIGH SPEED DISTRIBUTED ARITHMETIC Thangamonikha.A 1, Dr.V.R.Balaji 2 1 PG Scholar, Department OF ECE, 2 Assitant Professor, Department of ECE 1, 2 Sri Krishna
University, Patiala, Punjab, India 1 2
 1102 Design and Implementation of Efficient Adder based Floating Point Multiplier LOKESH BHARDWAJ 1, SAKSHI BAJAJ 2 1 Student, M.tech, VLSI, 2 Assistant Professor,Electronics and Communication Engineering
1102 Design and Implementation of Efficient Adder based Floating Point Multiplier LOKESH BHARDWAJ 1, SAKSHI BAJAJ 2 1 Student, M.tech, VLSI, 2 Assistant Professor,Electronics and Communication Engineering
Optimized Modified Booth Recorder for Efficient Design of the Operator
 Optimized Modified Booth Recorder for Efficient Design of the Operator 1 DEEPTHI MALLELA, M.TECH.,VLSI 2 VEERABABU A, ASSISTANT PROFESSOR,DEPT.OF ECE 3 SRINIVASULU K,HOD,DEPT. OF ECE 1,2,3 NARASIMHA REDDY
Optimized Modified Booth Recorder for Efficient Design of the Operator 1 DEEPTHI MALLELA, M.TECH.,VLSI 2 VEERABABU A, ASSISTANT PROFESSOR,DEPT.OF ECE 3 SRINIVASULU K,HOD,DEPT. OF ECE 1,2,3 NARASIMHA REDDY
Simulation Results Analysis Of Basic And Modified RBSD Adder Circuits 1 Sobina Gujral, 2 Robina Gujral Bagga
 Simulation Results Analysis Of Basic And Modified RBSD Adder Circuits 1 Sobina Gujral, 2 Robina Gujral Bagga 1 Assistant Professor Department of Electronics and Communication, Chandigarh University, India
Simulation Results Analysis Of Basic And Modified RBSD Adder Circuits 1 Sobina Gujral, 2 Robina Gujral Bagga 1 Assistant Professor Department of Electronics and Communication, Chandigarh University, India
Implementation and Comparative Analysis between Devices for Double Precision Interval Arithmetic Radix 4 Wallace tree Multiplication
 Implementation and Comparative Analysis between Devices for Double Precision Interval Arithmetic Radix 4 Wallace tree Multiplication Krutika Ranjankumar Bhagwat #1, Dr. Tejas V. Shah * 2, Prof. Deepali
Implementation and Comparative Analysis between Devices for Double Precision Interval Arithmetic Radix 4 Wallace tree Multiplication Krutika Ranjankumar Bhagwat #1, Dr. Tejas V. Shah * 2, Prof. Deepali
Area-Time Efficient Square Architecture
 AMSE JOURNALS 2015-Series: Advances D; Vol. 20; N 1; pp 21-34 Submitted March 2015; Revised Sept. 21, 2015; Accepted Oct. 15, 2015 Area-Time Efficient Square Architecture *Ranjan Kumar Barik, **Manoranjan
AMSE JOURNALS 2015-Series: Advances D; Vol. 20; N 1; pp 21-34 Submitted March 2015; Revised Sept. 21, 2015; Accepted Oct. 15, 2015 Area-Time Efficient Square Architecture *Ranjan Kumar Barik, **Manoranjan
A Modified Radix2, Radix4 Algorithms and Modified Adder for Parallel Multiplication
 International Journal of Emerging Engineering Research and Technology Volume 3, Issue 8, August 2015, PP 90-95 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) A Modified Radix2, Radix4 Algorithms and
International Journal of Emerging Engineering Research and Technology Volume 3, Issue 8, August 2015, PP 90-95 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) A Modified Radix2, Radix4 Algorithms and
A Novel Architecture of Parallel Multiplier Using Modified Booth s Recoding Unit and Adder for Signed and Unsigned Numbers
 International Journal of Research Studies in Science, Engineering and Technology Volume 2, Issue 8, August 2015, PP 55-61 ISSN 2349-4751 (Print) & ISSN 2349-476X (Online) A Novel Architecture of Parallel
International Journal of Research Studies in Science, Engineering and Technology Volume 2, Issue 8, August 2015, PP 55-61 ISSN 2349-4751 (Print) & ISSN 2349-476X (Online) A Novel Architecture of Parallel
Design and Implementation of Signed, Rounded and Truncated Multipliers using Modified Booth Algorithm for Dsp Systems.
 Design and Implementation of Signed, Rounded and Truncated Multipliers using Modified Booth Algorithm for Dsp Systems. K. Ram Prakash 1, A.V.Sanju 2 1 Professor, 2 PG scholar, Department of Electronics
Design and Implementation of Signed, Rounded and Truncated Multipliers using Modified Booth Algorithm for Dsp Systems. K. Ram Prakash 1, A.V.Sanju 2 1 Professor, 2 PG scholar, Department of Electronics
International Journal of Research in Computer and Communication Technology, Vol 4, Issue 11, November- 2015
 Design of Dadda Algorithm based Floating Point Multiplier A. Bhanu Swetha. PG.Scholar: M.Tech(VLSISD), Department of ECE, BVCITS, Batlapalem. E.mail:swetha.appari@gmail.com V.Ramoji, Asst.Professor, Department
Design of Dadda Algorithm based Floating Point Multiplier A. Bhanu Swetha. PG.Scholar: M.Tech(VLSISD), Department of ECE, BVCITS, Batlapalem. E.mail:swetha.appari@gmail.com V.Ramoji, Asst.Professor, Department
Comparison of Adders for optimized Exponent Addition circuit in IEEE754 Floating point multiplier using VHDL
 International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 11, Issue 07 (July 2015), PP.60-65 Comparison of Adders for optimized Exponent Addition
International Journal of Engineering Research and Development e-issn: 2278-067X, p-issn: 2278-800X, www.ijerd.com Volume 11, Issue 07 (July 2015), PP.60-65 Comparison of Adders for optimized Exponent Addition
Chapter 3: Arithmetic for Computers
 Chapter 3: Arithmetic for Computers Objectives Signed and Unsigned Numbers Addition and Subtraction Multiplication and Division Floating Point Computer Architecture CS 35101-002 2 The Binary Numbering
Chapter 3: Arithmetic for Computers Objectives Signed and Unsigned Numbers Addition and Subtraction Multiplication and Division Floating Point Computer Architecture CS 35101-002 2 The Binary Numbering
High Performance and Area Efficient DSP Architecture using Dadda Multiplier
 2017 IJSRST Volume 3 Issue 6 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Science and Technology High Performance and Area Efficient DSP Architecture using Dadda Multiplier V.Kiran Kumar
2017 IJSRST Volume 3 Issue 6 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Science and Technology High Performance and Area Efficient DSP Architecture using Dadda Multiplier V.Kiran Kumar
Comparison of pipelined IEEE-754 standard floating point multiplier with unpipelined multiplier
 Journal of Scientific & Industrial Research Vol. 65, November 2006, pp. 900-904 Comparison of pipelined IEEE-754 standard floating point multiplier with unpipelined multiplier Kavita Khare 1, *, R P Singh
Journal of Scientific & Industrial Research Vol. 65, November 2006, pp. 900-904 Comparison of pipelined IEEE-754 standard floating point multiplier with unpipelined multiplier Kavita Khare 1, *, R P Singh
Sum to Modified Booth Recoding Techniques For Efficient Design of the Fused Add-Multiply Operator
 Sum to Modified Booth Recoding Techniques For Efficient Design of the Fused Add-Multiply Operator D.S. Vanaja 1, S. Sandeep 2 1 M. Tech scholar in VLSI System Design, Department of ECE, Sri VenkatesaPerumal
Sum to Modified Booth Recoding Techniques For Efficient Design of the Fused Add-Multiply Operator D.S. Vanaja 1, S. Sandeep 2 1 M. Tech scholar in VLSI System Design, Department of ECE, Sri VenkatesaPerumal
A Simple Method to Improve the throughput of A Multiplier
 International Journal of Electronics and Communication Engineering. ISSN 0974-2166 Volume 6, Number 1 (2013), pp. 9-16 International Research Publication House http://www.irphouse.com A Simple Method to
International Journal of Electronics and Communication Engineering. ISSN 0974-2166 Volume 6, Number 1 (2013), pp. 9-16 International Research Publication House http://www.irphouse.com A Simple Method to
Run-Time Reconfigurable multi-precision floating point multiplier design based on pipelining technique using Karatsuba-Urdhva algorithms
 Run-Time Reconfigurable multi-precision floating point multiplier design based on pipelining technique using Karatsuba-Urdhva algorithms 1 Shruthi K.H., 2 Rekha M.G. 1M.Tech, VLSI design and embedded system,
Run-Time Reconfigurable multi-precision floating point multiplier design based on pipelining technique using Karatsuba-Urdhva algorithms 1 Shruthi K.H., 2 Rekha M.G. 1M.Tech, VLSI design and embedded system,
Simulation & Synthesis of FPGA Based & Resource Efficient Matrix Coprocessor Architecture
 Simulation & Synthesis of FPGA Based & Resource Efficient Matrix Coprocessor Architecture Jai Prakash Mishra 1, Mukesh Maheshwari 2 1 M.Tech Scholar, Electronics & Communication Engineering, JNU Jaipur,
Simulation & Synthesis of FPGA Based & Resource Efficient Matrix Coprocessor Architecture Jai Prakash Mishra 1, Mukesh Maheshwari 2 1 M.Tech Scholar, Electronics & Communication Engineering, JNU Jaipur,
International Journal of Engineering and Techniques - Volume 4 Issue 2, April-2018
 RESEARCH ARTICLE DESIGN AND ANALYSIS OF RADIX-16 BOOTH PARTIAL PRODUCT GENERATOR FOR 64-BIT BINARY MULTIPLIERS K.Deepthi 1, Dr.T.Lalith Kumar 2 OPEN ACCESS 1 PG Scholar,Dept. Of ECE,Annamacharya Institute
RESEARCH ARTICLE DESIGN AND ANALYSIS OF RADIX-16 BOOTH PARTIAL PRODUCT GENERATOR FOR 64-BIT BINARY MULTIPLIERS K.Deepthi 1, Dr.T.Lalith Kumar 2 OPEN ACCESS 1 PG Scholar,Dept. Of ECE,Annamacharya Institute
DESIGN AND IMPLEMENTATION BY USING BIT LEVEL TRANSFORMATION OF ADDER TREES FOR MCMS USING VERILOG
 DESIGN AND IMPLEMENTATION BY USING BIT LEVEL TRANSFORMATION OF ADDER TREES FOR MCMS USING VERILOG 1 S. M. Kiranbabu, PG Scholar in VLSI Design, 2 K. Manjunath, Asst. Professor, ECE Department, 1 babu.ece09@gmail.com,
DESIGN AND IMPLEMENTATION BY USING BIT LEVEL TRANSFORMATION OF ADDER TREES FOR MCMS USING VERILOG 1 S. M. Kiranbabu, PG Scholar in VLSI Design, 2 K. Manjunath, Asst. Professor, ECE Department, 1 babu.ece09@gmail.com,
Design of a Multiplier Architecture Based on LUT and VHBCSE Algorithm For FIR Filter
 African Journal of Basic & Applied Sciences 9 (1): 53-58, 2017 ISSN 2079-2034 IDOSI Publications, 2017 DOI: 10.5829/idosi.ajbas.2017.53.58 Design of a Multiplier Architecture Based on LUT and VHBCSE Algorithm
African Journal of Basic & Applied Sciences 9 (1): 53-58, 2017 ISSN 2079-2034 IDOSI Publications, 2017 DOI: 10.5829/idosi.ajbas.2017.53.58 Design of a Multiplier Architecture Based on LUT and VHBCSE Algorithm
An FPGA Based Floating Point Arithmetic Unit Using Verilog
 An FPGA Based Floating Point Arithmetic Unit Using Verilog T. Ramesh 1 G. Koteshwar Rao 2 1PG Scholar, Vaagdevi College of Engineering, Telangana. 2Assistant Professor, Vaagdevi College of Engineering,
An FPGA Based Floating Point Arithmetic Unit Using Verilog T. Ramesh 1 G. Koteshwar Rao 2 1PG Scholar, Vaagdevi College of Engineering, Telangana. 2Assistant Professor, Vaagdevi College of Engineering,
HIGH SPEED SINGLE PRECISION FLOATING POINT UNIT IMPLEMENTATION USING VERILOG
 HIGH SPEED SINGLE PRECISION FLOATING POINT UNIT IMPLEMENTATION USING VERILOG 1 C.RAMI REDDY, 2 O.HOMA KESAV, 3 A.MAHESWARA REDDY 1 PG Scholar, Dept of ECE, AITS, Kadapa, AP-INDIA. 2 Asst Prof, Dept of
HIGH SPEED SINGLE PRECISION FLOATING POINT UNIT IMPLEMENTATION USING VERILOG 1 C.RAMI REDDY, 2 O.HOMA KESAV, 3 A.MAHESWARA REDDY 1 PG Scholar, Dept of ECE, AITS, Kadapa, AP-INDIA. 2 Asst Prof, Dept of
An FPGA based Implementation of Floating-point Multiplier
 An FPGA based Implementation of Floating-point Multiplier L. Rajesh, Prashant.V. Joshi and Dr.S.S. Manvi Abstract In this paper we describe the parameterization, implementation and evaluation of floating-point
An FPGA based Implementation of Floating-point Multiplier L. Rajesh, Prashant.V. Joshi and Dr.S.S. Manvi Abstract In this paper we describe the parameterization, implementation and evaluation of floating-point
High Speed Radix 8 CORDIC Processor
 High Speed Radix 8 CORDIC Processor Smt. J.M.Rudagi 1, Dr. Smt. S.S ubbaraman 2 1 Associate Professor, K.L.E CET, Chikodi, karnataka, India. 2 Professor, W C E Sangli, Maharashtra. 1 js_itti@yahoo.co.in
High Speed Radix 8 CORDIC Processor Smt. J.M.Rudagi 1, Dr. Smt. S.S ubbaraman 2 1 Associate Professor, K.L.E CET, Chikodi, karnataka, India. 2 Professor, W C E Sangli, Maharashtra. 1 js_itti@yahoo.co.in
Evaluation of High Speed Hardware Multipliers - Fixed Point and Floating point
 International Journal of Electrical and Computer Engineering (IJECE) Vol. 3, No. 6, December 2013, pp. 805~814 ISSN: 2088-8708 805 Evaluation of High Speed Hardware Multipliers - Fixed Point and Floating
International Journal of Electrical and Computer Engineering (IJECE) Vol. 3, No. 6, December 2013, pp. 805~814 ISSN: 2088-8708 805 Evaluation of High Speed Hardware Multipliers - Fixed Point and Floating
I. Introduction. India; 2 Assistant Professor, Department of Electronics & Communication Engineering, SRIT, Jabalpur (M.P.
 A Decimal / Binary Multi-operand Adder using a Fast Binary to Decimal Converter-A Review Ruchi Bhatt, Divyanshu Rao, Ravi Mohan 1 M. Tech Scholar, Department of Electronics & Communication Engineering,
A Decimal / Binary Multi-operand Adder using a Fast Binary to Decimal Converter-A Review Ruchi Bhatt, Divyanshu Rao, Ravi Mohan 1 M. Tech Scholar, Department of Electronics & Communication Engineering,
Two High Performance Adaptive Filter Implementation Schemes Using Distributed Arithmetic
 Two High Performance Adaptive Filter Implementation Schemes Using istributed Arithmetic Rui Guo and Linda S. ebrunner Abstract istributed arithmetic (A) is performed to design bit-level architectures for
Two High Performance Adaptive Filter Implementation Schemes Using istributed Arithmetic Rui Guo and Linda S. ebrunner Abstract istributed arithmetic (A) is performed to design bit-level architectures for
REALIZATION OF MULTIPLE- OPERAND ADDER-SUBTRACTOR BASED ON VEDIC MATHEMATICS
 REALIZATION OF MULTIPLE- OPERAND ADDER-SUBTRACTOR BASED ON VEDIC MATHEMATICS NEETA PANDEY 1, RAJESHWARI PANDEY 2, SAMIKSHA AGARWAL 3, PRINCE KUMAR 4 Department of Electronics and Communication Engineering
REALIZATION OF MULTIPLE- OPERAND ADDER-SUBTRACTOR BASED ON VEDIC MATHEMATICS NEETA PANDEY 1, RAJESHWARI PANDEY 2, SAMIKSHA AGARWAL 3, PRINCE KUMAR 4 Department of Electronics and Communication Engineering
Optimized Design and Implementation of a 16-bit Iterative Logarithmic Multiplier
 Optimized Design and Implementation a 16-bit Iterative Logarithmic Multiplier Laxmi Kosta 1, Jaspreet Hora 2, Rupa Tomaskar 3 1 Lecturer, Department Electronic & Telecommunication Engineering, RGCER, Nagpur,India,
Optimized Design and Implementation a 16-bit Iterative Logarithmic Multiplier Laxmi Kosta 1, Jaspreet Hora 2, Rupa Tomaskar 3 1 Lecturer, Department Electronic & Telecommunication Engineering, RGCER, Nagpur,India,
August Issue Page 96 of 107 ISSN
 Design of High Performance AMBA AHB Reconfigurable Arbiter on system- on- chip Vimlesh Sahu 1 Dr. Ravi Shankar Mishra 2 Puran Gour 3 M.Tech NIIST BHOPAL HOD (EC) NIIST BHOPAL ASST.Prof.NIIST Bhopal vimlesh_sahu@yahoo.com
Design of High Performance AMBA AHB Reconfigurable Arbiter on system- on- chip Vimlesh Sahu 1 Dr. Ravi Shankar Mishra 2 Puran Gour 3 M.Tech NIIST BHOPAL HOD (EC) NIIST BHOPAL ASST.Prof.NIIST Bhopal vimlesh_sahu@yahoo.com
An Efficient Design of Vedic Multiplier using New Encoding Scheme
 An Efficient Design of Vedic Multiplier using New Encoding Scheme Jai Skand Tripathi P.G Student, United College of Engineering & Research, India Priya Keerti Tripathi P.G Student, Jaypee University of
An Efficient Design of Vedic Multiplier using New Encoding Scheme Jai Skand Tripathi P.G Student, United College of Engineering & Research, India Priya Keerti Tripathi P.G Student, Jaypee University of
Implementation of Low Power High Speed 32 bit ALU using FPGA
 Implementation of Low Power High Speed 32 bit ALU using FPGA J.P. Verma Assistant Professor (Department of Electronics & Communication Engineering) Maaz Arif; Brij Bhushan Choudhary& Nitish Kumar Electronics
Implementation of Low Power High Speed 32 bit ALU using FPGA J.P. Verma Assistant Professor (Department of Electronics & Communication Engineering) Maaz Arif; Brij Bhushan Choudhary& Nitish Kumar Electronics
Bit-Level Optimization of Adder-Trees for Multiple Constant Multiplications for Efficient FIR Filter Implementation
 Bit-Level Optimization of Adder-Trees for Multiple Constant Multiplications for Efficient FIR Filter Implementation 1 S. SRUTHI, M.Tech, Vlsi System Design, 2 G. DEVENDAR M.Tech, Asst.Professor, ECE Department,
Bit-Level Optimization of Adder-Trees for Multiple Constant Multiplications for Efficient FIR Filter Implementation 1 S. SRUTHI, M.Tech, Vlsi System Design, 2 G. DEVENDAR M.Tech, Asst.Professor, ECE Department,
32-bit Signed and Unsigned Advanced Modified Booth Multiplication using Radix-4 Encoding Algorithm
 2016 IJSRSET Volume 2 Issue 3 Print ISSN : 2395-1990 Online ISSN : 2394-4099 Themed Section: Engineering and Technology 32-bit Signed and Unsigned Advanced Modified Booth Multiplication using Radix-4 Encoding
2016 IJSRSET Volume 2 Issue 3 Print ISSN : 2395-1990 Online ISSN : 2394-4099 Themed Section: Engineering and Technology 32-bit Signed and Unsigned Advanced Modified Booth Multiplication using Radix-4 Encoding
A Review of Various Adders for Fast ALU
 58 JEST-M, Vol 3, Issue 2, July-214 A Review of Various Adders for Fast ALU 1Assistnat Profrssor Department of Electronics and Communication, Chandigarh University 2Assistnat Profrssor Department of Electronics
58 JEST-M, Vol 3, Issue 2, July-214 A Review of Various Adders for Fast ALU 1Assistnat Profrssor Department of Electronics and Communication, Chandigarh University 2Assistnat Profrssor Department of Electronics
High Throughput Radix-D Multiplication Using BCD
 High Throughput Radix-D Multiplication Using BCD Y.Raj Kumar PG Scholar, VLSI&ES, Dept of ECE, Vidya Bharathi Institute of Technology, Janagaon, Warangal, Telangana. Dharavath Jagan, M.Tech Associate Professor,
High Throughput Radix-D Multiplication Using BCD Y.Raj Kumar PG Scholar, VLSI&ES, Dept of ECE, Vidya Bharathi Institute of Technology, Janagaon, Warangal, Telangana. Dharavath Jagan, M.Tech Associate Professor,
A Ripple Carry Adder based Low Power Architecture of LMS Adaptive Filter
 A Ripple Carry Adder based Low Power Architecture of LMS Adaptive Filter A.S. Sneka Priyaa PG Scholar Government College of Technology Coimbatore ABSTRACT The Least Mean Square Adaptive Filter is frequently
A Ripple Carry Adder based Low Power Architecture of LMS Adaptive Filter A.S. Sneka Priyaa PG Scholar Government College of Technology Coimbatore ABSTRACT The Least Mean Square Adaptive Filter is frequently
Analysis of Different Multiplication Algorithms & FPGA Implementation
 IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 4, Issue 2, Ver. I (Mar-Apr. 2014), PP 29-35 e-issn: 2319 4200, p-issn No. : 2319 4197 Analysis of Different Multiplication Algorithms & FPGA
IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 4, Issue 2, Ver. I (Mar-Apr. 2014), PP 29-35 e-issn: 2319 4200, p-issn No. : 2319 4197 Analysis of Different Multiplication Algorithms & FPGA
Efficient Radix-10 Multiplication Using BCD Codes
 Efficient Radix-10 Multiplication Using BCD Codes P.Ranjith Kumar Reddy M.Tech VLSI, Department of ECE, CMR Institute of Technology. P.Navitha Assistant Professor, Department of ECE, CMR Institute of Technology.
Efficient Radix-10 Multiplication Using BCD Codes P.Ranjith Kumar Reddy M.Tech VLSI, Department of ECE, CMR Institute of Technology. P.Navitha Assistant Professor, Department of ECE, CMR Institute of Technology.
International Journal of Advanced Research in Computer Science and Software Engineering
 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Configuring Floating Point Multiplier on Spartan 2E Hardware
ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Configuring Floating Point Multiplier on Spartan 2E Hardware
AN EFFICIENT FLOATING-POINT MULTIPLIER DESIGN USING COMBINED BOOTH AND DADDA ALGORITHMS
 AN EFFICIENT FLOATING-POINT MULTIPLIER DESIGN USING COMBINED BOOTH AND DADDA ALGORITHMS 1 DHANABAL R, BHARATHI V, 3 NAAMATHEERTHAM R SAMHITHA, 4 PAVITHRA S, 5 PRATHIBA S, 6 JISHIA EUGINE 1 Asst Prof. (Senior
AN EFFICIENT FLOATING-POINT MULTIPLIER DESIGN USING COMBINED BOOTH AND DADDA ALGORITHMS 1 DHANABAL R, BHARATHI V, 3 NAAMATHEERTHAM R SAMHITHA, 4 PAVITHRA S, 5 PRATHIBA S, 6 JISHIA EUGINE 1 Asst Prof. (Senior
DESIGN OF QUATERNARY ADDER FOR HIGH SPEED APPLICATIONS
 DESIGN OF QUATERNARY ADDER FOR HIGH SPEED APPLICATIONS Ms. Priti S. Kapse 1, Dr. S. L. Haridas 2 1 Student, M. Tech. Department of Electronics, VLSI, GHRACET, Nagpur, (India) 2 H.O.D. of Electronics and
DESIGN OF QUATERNARY ADDER FOR HIGH SPEED APPLICATIONS Ms. Priti S. Kapse 1, Dr. S. L. Haridas 2 1 Student, M. Tech. Department of Electronics, VLSI, GHRACET, Nagpur, (India) 2 H.O.D. of Electronics and
Australian Journal of Basic and Applied Sciences
 ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com High Speed And Area Efficient Multiplier 1 P.S.Tulasiram, 2 D. Vaithiyanathan and 3 Dr. R. Seshasayanan
ISSN:1991-8178 Australian Journal of Basic and Applied Sciences Journal home page: www.ajbasweb.com High Speed And Area Efficient Multiplier 1 P.S.Tulasiram, 2 D. Vaithiyanathan and 3 Dr. R. Seshasayanan
Chapter 5 : Computer Arithmetic
 Chapter 5 Computer Arithmetic Integer Representation: (Fixedpoint representation): An eight bit word can be represented the numbers from zero to 255 including = 1 = 1 11111111 = 255 In general if an nbit
Chapter 5 Computer Arithmetic Integer Representation: (Fixedpoint representation): An eight bit word can be represented the numbers from zero to 255 including = 1 = 1 11111111 = 255 In general if an nbit
Improved Design of High Performance Radix-10 Multiplication Using BCD Codes
 International OPEN ACCESS Journal ISSN: 2249-6645 Of Modern Engineering Research (IJMER) Improved Design of High Performance Radix-10 Multiplication Using BCD Codes 1 A. Anusha, 2 C.Ashok Kumar 1 M.Tech
International OPEN ACCESS Journal ISSN: 2249-6645 Of Modern Engineering Research (IJMER) Improved Design of High Performance Radix-10 Multiplication Using BCD Codes 1 A. Anusha, 2 C.Ashok Kumar 1 M.Tech
FPGA Implementation of Single Precision Floating Point Multiplier Using High Speed Compressors
 2018 IJSRST Volume 4 Issue 2 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Science and Technology FPGA Implementation of Single Precision Floating Point Multiplier Using High Speed Compressors
2018 IJSRST Volume 4 Issue 2 Print ISSN: 2395-6011 Online ISSN: 2395-602X Themed Section: Science and Technology FPGA Implementation of Single Precision Floating Point Multiplier Using High Speed Compressors
Implementation of Efficient Modified Booth Recoder for Fused Sum-Product Operator
 Implementation of Efficient Modified Booth Recoder for Fused Sum-Product Operator A.Sindhu 1, K.PriyaMeenakshi 2 PG Student [VLSI], Dept. of ECE, Muthayammal Engineering College, Rasipuram, Tamil Nadu,
Implementation of Efficient Modified Booth Recoder for Fused Sum-Product Operator A.Sindhu 1, K.PriyaMeenakshi 2 PG Student [VLSI], Dept. of ECE, Muthayammal Engineering College, Rasipuram, Tamil Nadu,
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK DESIGN OF QUATERNARY ADDER FOR HIGH SPEED APPLICATIONS MS. PRITI S. KAPSE 1, DR.
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK DESIGN OF QUATERNARY ADDER FOR HIGH SPEED APPLICATIONS MS. PRITI S. KAPSE 1, DR.
Power and Area Efficient Implementation for Parallel FIR Filters Using FFAs and DA
 Power and Area Efficient Implementation for Parallel FIR Filters Using FFAs and DA Krishnapriya P.N 1, Arathy Iyer 2 M.Tech Student [VLSI & Embedded Systems], Sree Narayana Gurukulam College of Engineering,
Power and Area Efficient Implementation for Parallel FIR Filters Using FFAs and DA Krishnapriya P.N 1, Arathy Iyer 2 M.Tech Student [VLSI & Embedded Systems], Sree Narayana Gurukulam College of Engineering,
IEEE-754 compliant Algorithms for Fast Multiplication of Double Precision Floating Point Numbers
 International Journal of Research in Computer Science ISSN 2249-8257 Volume 1 Issue 1 (2011) pp. 1-7 White Globe Publications www.ijorcs.org IEEE-754 compliant Algorithms for Fast Multiplication of Double
International Journal of Research in Computer Science ISSN 2249-8257 Volume 1 Issue 1 (2011) pp. 1-7 White Globe Publications www.ijorcs.org IEEE-754 compliant Algorithms for Fast Multiplication of Double
An FPGA Implementation of 8-bit RISC Microcontroller
 An FPGA Implementation of 8-bit RISC Microcontroller Krishna Kumar mishra 1, Vaibhav Purwar 2, Pankaj Singh 3 1 M.Tech scholar, Department of Electronic and Communication Engineering Kanpur Institute of
An FPGA Implementation of 8-bit RISC Microcontroller Krishna Kumar mishra 1, Vaibhav Purwar 2, Pankaj Singh 3 1 M.Tech scholar, Department of Electronic and Communication Engineering Kanpur Institute of
Implementation of Double Precision Floating Point Multiplier on FPGA
 Implementation of Double Precision Floating Point Multiplier on FPGA A.Keerthi 1, K.V.Koteswararao 2 PG Student [VLSI], Dept. of ECE, Sree Vidyanikethan Engineering College, Tirupati, India 1 Assistant
Implementation of Double Precision Floating Point Multiplier on FPGA A.Keerthi 1, K.V.Koteswararao 2 PG Student [VLSI], Dept. of ECE, Sree Vidyanikethan Engineering College, Tirupati, India 1 Assistant
FPGA based Simulation of Clock Gated ALU Architecture with Multiplexed Logic Enable for Low Power Applications
 IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 04, 2015 ISSN (online): 2321-0613 FPGA based Simulation of Clock Gated ALU Architecture with Multiplexed Logic Enable for
IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 04, 2015 ISSN (online): 2321-0613 FPGA based Simulation of Clock Gated ALU Architecture with Multiplexed Logic Enable for
Implementation and Analysis of Modified Double Precision Interval Arithmetic Array Multiplication
 Implementation and Analysis of Modified Double Precision Interval Arithmetic Array Multiplication Krutika Ranjan Kumar Bhagwat #1, Prof. Tejas V. Shah *2, Prof. Deepali H. Shah #3 #* Instrumentation &
Implementation and Analysis of Modified Double Precision Interval Arithmetic Array Multiplication Krutika Ranjan Kumar Bhagwat #1, Prof. Tejas V. Shah *2, Prof. Deepali H. Shah #3 #* Instrumentation &
THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE
 THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE Design and Implementation of Optimized Floating Point Matrix Multiplier Based on FPGA Maruti L. Doddamani IV Semester, M.Tech (Digital Electronics), Department
THE INTERNATIONAL JOURNAL OF SCIENCE & TECHNOLEDGE Design and Implementation of Optimized Floating Point Matrix Multiplier Based on FPGA Maruti L. Doddamani IV Semester, M.Tech (Digital Electronics), Department
Performance Analysis of 64-Bit Carry Look Ahead Adder
 Journal From the SelectedWorks of Journal November, 2014 Performance Analysis of 64-Bit Carry Look Ahead Adder Daljit Kaur Ana Monga This work is licensed under a Creative Commons CC_BY-NC International
Journal From the SelectedWorks of Journal November, 2014 Performance Analysis of 64-Bit Carry Look Ahead Adder Daljit Kaur Ana Monga This work is licensed under a Creative Commons CC_BY-NC International
32 bit Arithmetic Logical Unit (ALU) using VHDL
 using VHDL") 32 bit Arithmetic Logical Unit (ALU) using VHDL 1, Richa Singh Rathore 2 1 M. Tech Scholar, Department of ECE, Jayoti Vidyapeeth Women s University, Rajasthan, INDIA, dishamalik26@gmail.com 2 M. Tech Scholar,
32 bit Arithmetic Logical Unit (ALU) using VHDL 1, Richa Singh Rathore 2 1 M. Tech Scholar, Department of ECE, Jayoti Vidyapeeth Women s University, Rajasthan, INDIA, dishamalik26@gmail.com 2 M. Tech Scholar,
Design and Implementation of IEEE-754 Decimal Floating Point Adder, Subtractor and Multiplier
 International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 8958, Volume-4 Issue 1, October 2014 Design and Implementation of IEEE-754 Decimal Floating Point Adder, Subtractor and Multiplier
International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 8958, Volume-4 Issue 1, October 2014 Design and Implementation of IEEE-754 Decimal Floating Point Adder, Subtractor and Multiplier
ARCHITECTURAL DESIGN OF 8 BIT FLOATING POINT MULTIPLICATION UNIT
 ARCHITECTURAL DESIGN OF 8 BIT FLOATING POINT MULTIPLICATION UNIT Usha S. 1 and Vijaya Kumar V. 2 1 VLSI Design, Sathyabama University, Chennai, India 2 Department of Electronics and Communication Engineering,
ARCHITECTURAL DESIGN OF 8 BIT FLOATING POINT MULTIPLICATION UNIT Usha S. 1 and Vijaya Kumar V. 2 1 VLSI Design, Sathyabama University, Chennai, India 2 Department of Electronics and Communication Engineering,
Parallelized Radix-4 Scalable Montgomery Multipliers
 Parallelized Radix-4 Scalable Montgomery Multipliers Nathaniel Pinckney and David Money Harris 1 1 Harvey Mudd College, 301 Platt. Blvd., Claremont, CA, USA e-mail: npinckney@hmc.edu ABSTRACT This paper
Parallelized Radix-4 Scalable Montgomery Multipliers Nathaniel Pinckney and David Money Harris 1 1 Harvey Mudd College, 301 Platt. Blvd., Claremont, CA, USA e-mail: npinckney@hmc.edu ABSTRACT This paper
Computations Of Elementary Functions Based On Table Lookup And Interpolation
 RESEARCH ARTICLE OPEN ACCESS Computations Of Elementary Functions Based On Table Lookup And Interpolation Syed Aliasgar 1, Dr.V.Thrimurthulu 2, G Dillirani 3 1 Assistant Professor, Dept.of ECE, CREC, Tirupathi,
RESEARCH ARTICLE OPEN ACCESS Computations Of Elementary Functions Based On Table Lookup And Interpolation Syed Aliasgar 1, Dr.V.Thrimurthulu 2, G Dillirani 3 1 Assistant Professor, Dept.of ECE, CREC, Tirupathi,
An Efficient Fused Add Multiplier With MWT Multiplier And Spanning Tree Adder
 An Efficient Fused Add Multiplier With MWT Multiplier And Spanning Tree Adder 1.M.Megha,M.Tech (VLSI&ES),2. Nataraj, M.Tech (VLSI&ES), Assistant Professor, 1,2. ECE Department,ST.MARY S College of Engineering
An Efficient Fused Add Multiplier With MWT Multiplier And Spanning Tree Adder 1.M.Megha,M.Tech (VLSI&ES),2. Nataraj, M.Tech (VLSI&ES), Assistant Professor, 1,2. ECE Department,ST.MARY S College of Engineering
An Efficient Flexible Architecture for Error Tolerant Applications
 An Efficient Flexible Architecture for Error Tolerant Applications Sheema Mol K.N 1, Rahul M Nair 2 M.Tech Student (VLSI DESIGN), Department of Electronics and Communication Engineering, Nehru College
An Efficient Flexible Architecture for Error Tolerant Applications Sheema Mol K.N 1, Rahul M Nair 2 M.Tech Student (VLSI DESIGN), Department of Electronics and Communication Engineering, Nehru College
Implementation of 64-Bit Pipelined Floating Point ALU Using Verilog
 International Journal of Computer System (ISSN: 2394-1065), Volume 02 Issue 04, April, 2015 Available at http://www.ijcsonline.com/ Implementation of 64-Bit Pipelined Floating Point ALU Using Verilog Megha
International Journal of Computer System (ISSN: 2394-1065), Volume 02 Issue 04, April, 2015 Available at http://www.ijcsonline.com/ Implementation of 64-Bit Pipelined Floating Point ALU Using Verilog Megha
A Decimal Floating Point Arithmetic Unit for Embedded System Applications using VLSI Techniques
 A Decimal Floating Point Arithmetic Unit for Embedded System Applications using VLSI Techniques Rajeshwari Mathapati #1, Shrikant. K.Shirakol *2 # Dept of E&CE, S.D.M. College of Engg. and Tech., Dharwad,
A Decimal Floating Point Arithmetic Unit for Embedded System Applications using VLSI Techniques Rajeshwari Mathapati #1, Shrikant. K.Shirakol *2 # Dept of E&CE, S.D.M. College of Engg. and Tech., Dharwad,
Batchu Jeevanarani and Thota Sreenivas Department of ECE, Sri Vasavi Engg College, Tadepalligudem, West Godavari (DT), Andhra Pradesh, India
, Andhra Pradesh, India") Memory-Based Realization of FIR Digital Filter by Look-Up- Table Optimization Batchu Jeevanarani and Thota Sreenivas Department of ECE, Sri Vasavi Engg College, Tadepalligudem, West Godavari (DT), Andhra
Memory-Based Realization of FIR Digital Filter by Look-Up- Table Optimization Batchu Jeevanarani and Thota Sreenivas Department of ECE, Sri Vasavi Engg College, Tadepalligudem, West Godavari (DT), Andhra
Efficient Design of Radix Booth Multiplier
 Efficient Design of Radix Booth Multiplier 1Head and Associate professor E&TC Department, Pravara Rural Engineering College Loni 2ME E&TC Engg, Pravara Rural Engineering College Loni --------------------------------------------------------------------------***----------------------------------------------------------------------------
Efficient Design of Radix Booth Multiplier 1Head and Associate professor E&TC Department, Pravara Rural Engineering College Loni 2ME E&TC Engg, Pravara Rural Engineering College Loni --------------------------------------------------------------------------***----------------------------------------------------------------------------
FPGA Implementation of a High Speed Multiplier Employing Carry Lookahead Adders in Reduction Phase
 FPGA Implementation of a High Speed Multiplier Employing Carry Lookahead Adders in Reduction Phase Abhay Sharma M.Tech Student Department of ECE MNNIT Allahabad, India ABSTRACT Tree Multipliers are frequently
FPGA Implementation of a High Speed Multiplier Employing Carry Lookahead Adders in Reduction Phase Abhay Sharma M.Tech Student Department of ECE MNNIT Allahabad, India ABSTRACT Tree Multipliers are frequently