Computer Architecture Review. Jo, Heeseung
|
|
|
- Audra Cain
- 6 years ago
- Views:
Transcription
1 Computer Architecture Review Jo, Heeseung
2 Computer Abstractions and Technology Jo, Heeseung


3 Below Your Program Application software Written in high-level language System software Compiler: translates HLL code to machine code Operating System: service code Hardware - Handling input/output - Managing memory and storage - Scheduling tasks & sharing resources Processor, memory, I/O controllers 3
 Encoded instructions and data")
4 Levels of Program Code High-level language Level of abstraction closer to problem domain Provides for productivity and portability Assembly language Textual representation of instructions Hardware representation Binary digits (bits) Encoded instructions and data 4

5 Components of a Computer Same components for all kinds of computer Desktop, server, embedded Input/output includes User-interface devices - Display, keyboard, mouse Storage devices - Hard disk, CD/DVD, flash Network adapters - For communicating with other computers 5
6 Arithmetic for Computers Jo, Heeseung

7 Integer Addition Example: Overflow if result out of range Adding +ve and -ve operands, no overflow Adding two +ve operands - Overflow if result sign is 1 Adding two -ve operands - Overflow if result sign is 0 7
8 Integer Subtraction Add negation of second operand Example: 7-6 = 7 + (-6) +7: : : Overflow if result out of range Subtracting two +ve or two -ve operands, no overflow Subtracting +ve from -ve operand - Overflow if result sign is 0 Subtracting -ve from +ve operand - Overflow if result sign is 1 8
9 Representation of Negative Numbers 9
10 Floating Point Representation for non-integral numbers Including very small and very large numbers Like scientific notation normalized not normalized In binary ±1.xxxxxxx 2 2 yyyy Types float and double in C 10
11 Floating Point Standard Defined by IEEE Std 754, 1985 Developed in response to divergence of representations Portability issues for scientific code Now almost universally adopted Two representations Single precision (32-bit) Double precision (64-bit) 11
12 IEEE Floating-Point Format single: 8 bits double: 11 bits single: 23 bits double: 52 bits S Exponent Fraction x ( 1) S (1 Fraction) 2 (Exponent Bias) S: sign bit (0 non-negative, 1 negative) Normalize significand: 1.0 significand < 2.0 Always has a leading pre-binary-point 1 bit, so no need to represent it explicitly (hidden bit) Significand is Fraction with the "1." restored Exponent: excess representation: actual exponent + Bias Ensures exponent is unsigned Single: Bias = 127; Double: Bias =
13 Floating-Point Example Represent = (-1) S = 1 Fraction = Exponent = -1 + Bias - Single: = 126 = Double: = 1022 = Single: Double:
14 Floating-Point Example What number is represented by the single-precision float S = 1 Fraction = Exponent = = 129 x = (-1) 1 ( ) 2 ( ) = (-1) =
15 Denormal Numbers Exponent = hidden bit is 0 x ( 1) S (0 Fraction) 2 Bias Smaller than normal numbers allow for gradual underflow, with diminishing precision Denormal with fraction = x ( 1) S (0 0) 2 Bias 0.0 Two representation s of 0.0! 15
16 Infinities and NaNs Exponent = , Fraction = ±Infinity Can be used in subsequent calculations, avoiding need for overflow check Exponent = , Fraction Not-a-Number (NaN) Indicates illegal or undefined result - e.g., 0.0 / 0.0 Can be used in subsequent calculations 16
17 The Processor Jo, Heeseung
18 Instruction Set The repertoire of instructions of a computer Different computers have different instruction sets But with many aspects in common Early computers had very simple instruction sets Simplified implementation Many modern computers also have simple instruction sets 18

19 Translation and Startup Many compilers produce object modules directly Static linking 19

20 CPU Overview 20

21 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup number of stages 21
22 Hazards Situations that prevent starting the next instruction in the next cycle Structure hazards A required resource is busy Data hazard Need to wait for previous instruction to complete its data read/write Control hazard Deciding on control action depends on previous instruction 22
23 Structure Hazards Conflict for use of a resource In MIPS pipeline with a single memory Load/store requires data access Instruction fetch would have to stall for that cycle - Would cause a pipeline "bubble" Hence, pipelined datapaths require separate instruction/data memories Or separate instruction/data caches 23
24 Data Hazards An instruction depends on completion of data access by a previous instruction add $s0, $t0, $t1 sub $t2, $s0, $t3 24
 Use result")


25 Forwarding (aka Bypassing) Use result when it is computed Don't wait for it to be stored in a register Requires extra connections in the datapath 25


26 Load-Use Data Hazard Can't always avoid stalls by forwarding If value not computed when needed Can't forward backward in time! 26
27 Code Scheduling to Avoid Stalls Reorder code to avoid use of load result in the next instruction C code for A = B + E; C = B + F; stall stall lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t2 sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 13 cycles lw $t1, 0($t0) lw $t2, 4($t0) lw $t4, 8($t0) add $t3, $t1, $t2 sw $t3, 12($t0) add $t5, $t1, $t4 sw $t5, 16($t0) 11 cycles 27
28 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can't always fetch correct instruction - Still working on ID stage of branch In MIPS pipeline Need to compare registers and compute target early in the pipeline Add hardware to do it in ID stage 28


29 Stall on Branch Wait until branch outcome determined before fetching next instruction 29
30 Branch Prediction Longer pipelines can't readily determine branch outcome early Stall penalty becomes unacceptable Predict outcome of branch Only stall if prediction is wrong In MIPS pipeline Can predict branches not taken Fetch instruction after branch, with no delay 30

31 MIPS with Predict Not Taken Predictio n correct Predictio n incorre ct 31
32 More-Realistic Branch Prediction Static branch prediction Based on typical branch behavior Example: loop and if-statement branches - Predict backward branches taken - Predict forward branches not taken Dynamic branch prediction Hardware measures actual branch behavior - e.g., record recent history of each branch Assume future behavior will continue the trend - When wrong, stall while re-fetching, and update history 32
33 Large and Fast: Exploiting Memory Hierarchy Jo, Heeseung
34 Memory Technology Static RAM (SRAM) 0.5ns - 2.5ns, $ $5000 per GB Dynamic RAM (DRAM) 50ns - 70ns, $20 - $75 per GB Magnetic disk 5ms - 20ms, $ $2 per GB Ideal memory Access time of SRAM Capacity and cost/gb of disk 34
35 Registers vs. Memory Qureshi (IBM Research) et al., Scalable High Performance Main Memory System Using Phase-Change Memory Technology, ISCA
36 Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to be accessed again soon e.g., instructions in a loop, induction variables Spatial locality Items near those accessed recently are likely to be accessed soon E.g., sequential instruction access, array data 36
37 Taking Advantage of Locality Memory hierarchy Store everything on disk Copy recently accessed (and nearby) items from disk to smaller DRAM memory Main memory Copy more recently accessed (and nearby) items from DRAM to smaller SRAM memory Cache memory attached to CPU 37

38 Memory Hierarchy Levels Block (aka line): unit of copying May be multiple words If accessed data is present in upper level Hit: access satisfied by upper level - Hit ratio: hits/accesses If accessed data is absent Miss: block copied from lower level - Time taken: miss penalty - Miss ratio: misses/accesses = 1 - hit ratio Then accessed data supplied from upper level 38
39 Virtual Memory Use main memory as a "cache" for secondary (disk) storage Managed jointly by CPU hardware and the operating system (OS) Programs share main memory Each gets a private virtual address space holding its frequently used code and data Protected from other programs CPU and OS translate virtual addresses to physical addresses VM "block" is called a page VM translation "miss" is called a page fault 39
 40")
40 Address Translation Fixed-size pages (e.g., 4K) 40
41 Page Fault Penalty On page fault, the page must be fetched from disk Takes millions of clock cycles Handled by OS code Try to minimize page fault rate Fully associative placement Smart replacement algorithms 41
42 Page Tables Stores placement information Array of page table entries, indexed by virtual page number Page table register in CPU points to page table in physical memory If page is present in memory PTE stores the physical page number Plus other status bits (referenced, dirty, ) If page is not present PTE can refer to location in swap space on disk 42

43 Translation Using a Page Table 43

44 Mapping Pages to Storage 44
45 Fast Translation Using a TLB Address translation would appear to require extra memory references One to access the PTE Then the actual memory access But access to page tables has good locality So use a fast cache of PTEs within the CPU Called a Translation Look-aside Buffer (TLB) Typical: PTEs, cycle for hit, cycles for miss, 0.01%-1% miss rate Misses could be handled by hardware or software 45
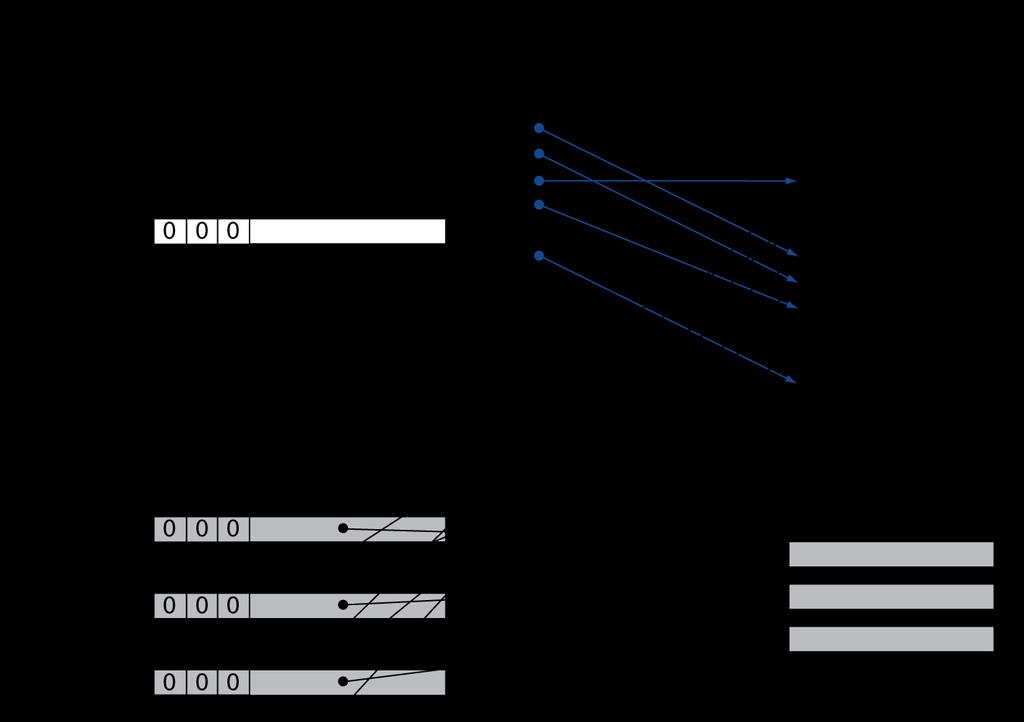
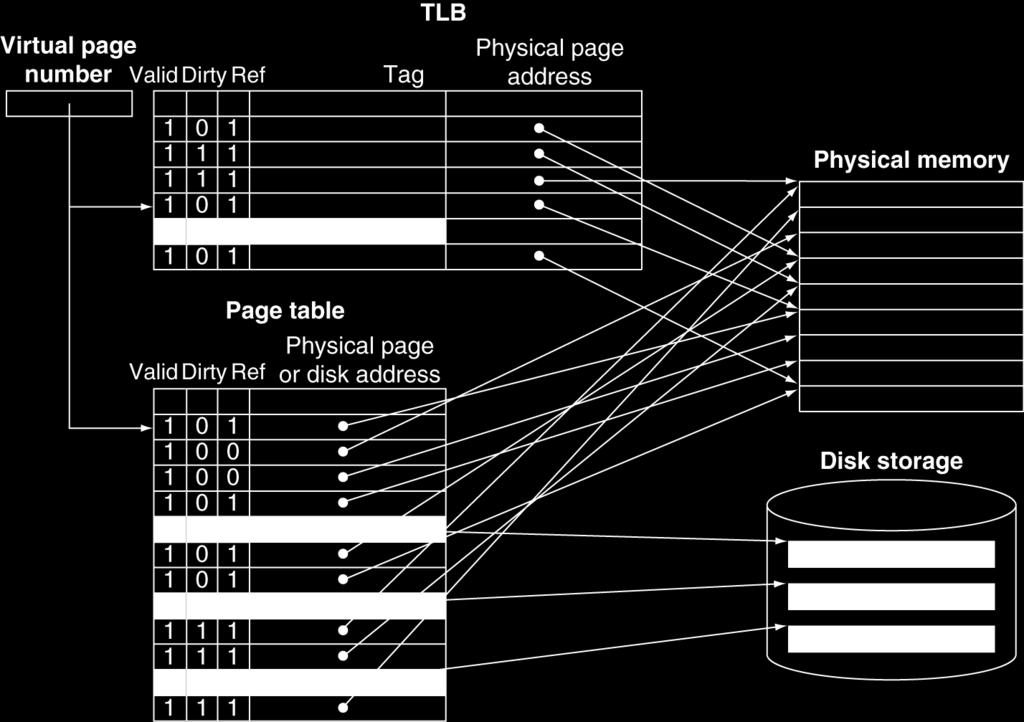
46 Fast Translation Using a TLB 46
Chapter 5. Memory Technology
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
V. Primary & Secondary Memory!
 V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-12a Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization Lecture-12a Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-12 Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
CSE 2021: Computer Organization Lecture-12 Caches-1 The basics of caches Shakil M. Khan Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY
 LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
Memory. Principle of Locality. It is impossible to have memory that is both. We create an illusion for the programmer. Employ memory hierarchy
 Datorarkitektur och operativsystem Lecture 7 Memory It is impossible to have memory that is both Unlimited (large in capacity) And fast 5.1 Intr roduction We create an illusion for the programmer Before
Datorarkitektur och operativsystem Lecture 7 Memory It is impossible to have memory that is both Unlimited (large in capacity) And fast 5.1 Intr roduction We create an illusion for the programmer Before
CSCI 402: Computer Architectures. Arithmetic for Computers (3) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Arithmetic for Computers (3) Fengguang Song Department of Computer & Information Science IUPUI 3.5 Today s Contents Floating point numbers: 2.5, 10.1, 100.2, etc.. How
CSCI 402: Computer Architectures Arithmetic for Computers (3) Fengguang Song Department of Computer & Information Science IUPUI 3.5 Today s Contents Floating point numbers: 2.5, 10.1, 100.2, etc.. How
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
5. Memory Hierarchy Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Movie Rental Store You have a huge warehouse with every movie ever made.
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Memory Technology. Chapter 5. Principle of Locality. Chapter 5 Large and Fast: Exploiting Memory Hierarchy 1
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
Computer Architecture Computer Science & Engineering. Chapter 5. Memory Hierachy BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Cycle Time for Non-pipelined & Pipelined processors
 Cycle Time for Non-pipelined & Pipelined processors Fetch Decode Execute Memory Writeback 250ps 350ps 150ps 300ps 200ps For a non-pipelined processor, the clock cycle is the sum of the latencies of all
Cycle Time for Non-pipelined & Pipelined processors Fetch Decode Execute Memory Writeback 250ps 350ps 150ps 300ps 200ps For a non-pipelined processor, the clock cycle is the sum of the latencies of all
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Memory Technology. Caches 1. Static RAM (SRAM) Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB
 Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB") Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
ECE260: Fundamentals of Computer Engineering
 Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Computer Systems Laboratory Sungkyunkwan University
 Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
The Memory Hierarchy Cache, Main Memory, and Virtual Memory
 The Memory Hierarchy Cache, Main Memory, and Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University The Simple View of Memory The simplest view
The Memory Hierarchy Cache, Main Memory, and Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University The Simple View of Memory The simplest view
Floating Point Arithmetic. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Floating Point Arithmetic Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Floating Point (1) Representation for non-integral numbers Including very
Floating Point Arithmetic Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Floating Point (1) Representation for non-integral numbers Including very
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Virtual Memory. Patterson & Hennessey Chapter 5 ELEC 5200/6200 1
 Virtual Memory Patterson & Hennessey Chapter 5 ELEC 5200/6200 1 Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system (OS) Programs
Virtual Memory Patterson & Hennessey Chapter 5 ELEC 5200/6200 1 Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system (OS) Programs
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 1. Computer Abstractions and Technology
 Chapter 1 Computer Abstractions and Technology The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications feasible Computers in automobiles Cell phones
Chapter 1 Computer Abstractions and Technology The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications feasible Computers in automobiles Cell phones
ECE 154A Introduction to. Fall 2012
 ECE 154A Introduction to Computer Architecture Fall 2012 Dmitri Strukov Lecture 10 Floating point review Pipelined design IEEE Floating Point Format single: 8 bits double: 11 bits single: 23 bits double:
ECE 154A Introduction to Computer Architecture Fall 2012 Dmitri Strukov Lecture 10 Floating point review Pipelined design IEEE Floating Point Format single: 8 bits double: 11 bits single: 23 bits double:
Memory Hierarchy Y. K. Malaiya
 Memory Hierarchy Y. K. Malaiya Acknowledgements Computer Architecture, Quantitative Approach - Hennessy, Patterson Vishwani D. Agrawal Review: Major Components of a Computer Processor Control Datapath
Memory Hierarchy Y. K. Malaiya Acknowledgements Computer Architecture, Quantitative Approach - Hennessy, Patterson Vishwani D. Agrawal Review: Major Components of a Computer Processor Control Datapath
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Floating Point Arithmetic
 Floating Point Arithmetic Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Floating Point Arithmetic Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
Computer Architecture and IC Design Lab. Chapter 3 Part 2 Arithmetic for Computers Floating Point
 Chapter 3 Part 2 Arithmetic for Computers Floating Point Floating Point Representation for non integral numbers Including very small and very large numbers 4,600,000,000 or 4.6 x 10 9 0.0000000000000000000000000166
Chapter 3 Part 2 Arithmetic for Computers Floating Point Floating Point Representation for non integral numbers Including very small and very large numbers 4,600,000,000 or 4.6 x 10 9 0.0000000000000000000000000166
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.
 Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Chapter 4: CPU 4.1 Introduction 4.3 Datapath 4.4 Control 4.5 Pipeline overview 4.6 Pipeline control * 4.7 Data hazard & forwarding * 4.8 Control hazard 4.14 Concluding Rem marks Hazards Situations that
Chapter 5. Large and Fast: Exploiting Memory Hierarchy. Part II Virtual Memory
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Part II Virtual Memory Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Part II Virtual Memory Virtual Memory Use main memory as a cache for secondary (disk) storage Managed jointly by CPU hardware and the operating system
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory
 1 COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 3 Review of Caches and Virtual Memory Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Chapter 5 B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 B Large and Fast: Exploiting Memory Hierarchy Dependability 5.5 Dependable Memory Hierarchy Chapter 6 Storage and Other I/O Topics 2 Dependability Service accomplishment Service delivered as
Chapter 5 B Large and Fast: Exploiting Memory Hierarchy Dependability 5.5 Dependable Memory Hierarchy Chapter 6 Storage and Other I/O Topics 2 Dependability Service accomplishment Service delivered as
CS/ECE 3330 Computer Architecture. Chapter 5 Memory
 CS/ECE 3330 Computer Architecture Chapter 5 Memory Last Chapter n Focused exclusively on processor itself n Made a lot of simplifying assumptions IF ID EX MEM WB n Reality: The Memory Wall 10 6 Relative
CS/ECE 3330 Computer Architecture Chapter 5 Memory Last Chapter n Focused exclusively on processor itself n Made a lot of simplifying assumptions IF ID EX MEM WB n Reality: The Memory Wall 10 6 Relative
EN2910A: Advanced Computer Architecture Topic 02: Review of classical concepts
 EN2910A: Advanced Computer Architecture Topic 02: Review of classical concepts Prof. Sherief Reda School of Engineering Brown University S. Reda EN2910A FALL'15 1 Classical concepts (prerequisite) 1. Instruction
EN2910A: Advanced Computer Architecture Topic 02: Review of classical concepts Prof. Sherief Reda School of Engineering Brown University S. Reda EN2910A FALL'15 1 Classical concepts (prerequisite) 1. Instruction
Signed Multiplication Multiply the positives Negate result if signs of operand are different
 Another Improvement Save on space: Put multiplier in product saves on speed: only single shift needed Figure: Improved hardware for multiplication Signed Multiplication Multiply the positives Negate result
Another Improvement Save on space: Put multiplier in product saves on speed: only single shift needed Figure: Improved hardware for multiplication Signed Multiplication Multiply the positives Negate result
Pipelined processors and Hazards
 Pipelined processors and Hazards Two options Processor HLL Compiler ALU LU Output Program Control unit 1. Either the control unit can be smart, i,e. it can delay instruction phases to avoid hazards. Processor
Pipelined processors and Hazards Two options Processor HLL Compiler ALU LU Output Program Control unit 1. Either the control unit can be smart, i,e. it can delay instruction phases to avoid hazards. Processor
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Recap from Last Time. CSE 2021: Computer Organization. It s All about Numbers! 5/12/2011. Text Pictures Video clips Audio
 CSE 2021: Computer Organization Recap from Last Time load from disk High-Level Program Lecture-2(a) Data Translation Binary patterns, signed and unsigned integers Today s topic Data Translation Code Translation
CSE 2021: Computer Organization Recap from Last Time load from disk High-Level Program Lecture-2(a) Data Translation Binary patterns, signed and unsigned integers Today s topic Data Translation Code Translation
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 29: an Introduction to Virtual Memory Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Virtual memory used to protect applications
ECE331: Hardware Organization and Design Lecture 29: an Introduction to Virtual Memory Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Virtual memory used to protect applications
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
CPU Pipelining Issues
 CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CPU Pipelining Issues What have you been beating your head against? This pipe stuff makes my head hurt! L17 Pipeline Issues & Memory 1 Pipelining Improve performance by increasing instruction throughput
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Modern Computer Architecture
 Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
Modern Computer Architecture Lecture3 Review of Memory Hierarchy Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Performance 1000 Recap: Who Cares About the Memory Hierarchy? Processor-DRAM Memory Gap
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
CS 61C: Great Ideas in Computer Architecture. Direct Mapped Caches
 CS 61C: Great Ideas in Computer Architecture Direct Mapped Caches Instructor: Justin Hsia 7/05/2012 Summer 2012 Lecture #11 1 Review of Last Lecture Floating point (single and double precision) approximates
CS 61C: Great Ideas in Computer Architecture Direct Mapped Caches Instructor: Justin Hsia 7/05/2012 Summer 2012 Lecture #11 1 Review of Last Lecture Floating point (single and double precision) approximates
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Different Storage Memories Chapter 5 Large and Fast: Exploiting Memory
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Different Storage Memories Chapter 5 Large and Fast: Exploiting Memory
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 5 (Part II) Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs
 Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs") Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Memory Hierarchy, Fully Associative Caches. Instructor: Nick Riasanovsky
 Memory Hierarchy, Fully Associative Caches Instructor: Nick Riasanovsky Review Hazards reduce effectiveness of pipelining Cause stalls/bubbles Structural Hazards Conflict in use of datapath component Data
Memory Hierarchy, Fully Associative Caches Instructor: Nick Riasanovsky Review Hazards reduce effectiveness of pipelining Cause stalls/bubbles Structural Hazards Conflict in use of datapath component Data
Memory Hierarchy. ENG3380 Computer Organization and Architecture Cache Memory Part II. Topics. References. Memory Hierarchy
 ENG338 Computer Organization and Architecture Part II Winter 217 S. Areibi School of Engineering University of Guelph Hierarchy Topics Hierarchy Locality Motivation Principles Elements of Design: Addresses
ENG338 Computer Organization and Architecture Part II Winter 217 S. Areibi School of Engineering University of Guelph Hierarchy Topics Hierarchy Locality Motivation Principles Elements of Design: Addresses
Lecture 29 Review" CPU time: the best metric" Be sure you understand CC, clock period" Common (and good) performance metrics"
 performance metrics") Be sure you understand CC, clock period Lecture 29 Review Suggested reading: Everything Q1: D[8] = D[8] + RF[1] + RF[4] I[15]: Add R2, R1, R4 RF[1] = 4 I[16]: MOV R3, 8 RF[4] = 5 I[17]: Add R2, R2, R3
Be sure you understand CC, clock period Lecture 29 Review Suggested reading: Everything Q1: D[8] = D[8] + RF[1] + RF[4] I[15]: Add R2, R1, R4 RF[1] = 4 I[16]: MOV R3, 8 RF[4] = 5 I[17]: Add R2, R2, R3
Chapter 5. Large and Fast: Exploiting Memory Hierarchy. Jiang Jiang
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 5 Large
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 5 Large
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
ECE468 Computer Organization and Architecture. Virtual Memory
 ECE468 Computer Organization and Architecture Virtual Memory ECE468 vm.1 Review: The Principle of Locality Probability of reference 0 Address Space 2 The Principle of Locality: Program access a relatively
ECE468 Computer Organization and Architecture Virtual Memory ECE468 vm.1 Review: The Principle of Locality Probability of reference 0 Address Space 2 The Principle of Locality: Program access a relatively
Virtual Memory. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Precise Definition of Virtual Memory Virtual memory is a mechanism for translating logical
Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Precise Definition of Virtual Memory Virtual memory is a mechanism for translating logical
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350):
:") The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
Do not start the test until instructed to do so!
 Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted one-page formula sheet and the MIPS reference card. No calculators
Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted one-page formula sheet and the MIPS reference card. No calculators
ECE4680 Computer Organization and Architecture. Virtual Memory
 ECE468 Computer Organization and Architecture Virtual Memory If I can see it and I can touch it, it s real. If I can t see it but I can touch it, it s invisible. If I can see it but I can t touch it, it
ECE468 Computer Organization and Architecture Virtual Memory If I can see it and I can touch it, it s real. If I can t see it but I can touch it, it s invisible. If I can see it but I can t touch it, it
Locality. Cache. Direct Mapped Cache. Direct Mapped Cache
 Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
Locality A principle that makes having a memory hierarchy a good idea If an item is referenced, temporal locality: it will tend to be referenced again soon spatial locality: nearby items will tend to be
Computer Architecture. Fall Dongkun Shin, SKKU
 Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
CS 61C: Great Ideas in Computer Architecture. The Memory Hierarchy, Fully Associative Caches
 CS 61C: Great Ideas in Computer Architecture The Memory Hierarchy, Fully Associative Caches Instructor: Alan Christopher 7/09/2014 Summer 2014 -- Lecture #10 1 Review of Last Lecture Floating point (single
CS 61C: Great Ideas in Computer Architecture The Memory Hierarchy, Fully Associative Caches Instructor: Alan Christopher 7/09/2014 Summer 2014 -- Lecture #10 1 Review of Last Lecture Floating point (single
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
EITF20: Computer Architecture Part 5.1.1: Virtual Memory
 EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
CMSC411 Fall 2013 Midterm 1
 CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
CMSC411 Fall 2013 Midterm 1 Name: Instructions You have 75 minutes to take this exam. There are 100 points in this exam, so spend about 45 seconds per point. You do not need to provide a number if you
Transistor: Digital Building Blocks
 Final Exam Review Transistor: Digital Building Blocks Logically, each transistor acts as a switch Combined to implement logic functions (gates) AND, OR, NOT Combined to build higher-level structures Multiplexer,
Final Exam Review Transistor: Digital Building Blocks Logically, each transistor acts as a switch Combined to implement logic functions (gates) AND, OR, NOT Combined to build higher-level structures Multiplexer,
Caches and Memory Hierarchy: Review. UCSB CS240A, Winter 2016
 Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
Caches and Memory Hierarchy: Review UCSB CS240A, Winter 2016 1 Motivation Most applications in a single processor runs at only 10-20% of the processor peak Most of the single processor performance loss
Caches and Memory Hierarchy: Review. UCSB CS240A, Fall 2017
 Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Caches and Memory Hierarchy: Review UCSB CS24A, Fall 27 Motivation Most applications in a single processor runs at only - 2% of the processor peak Most of the single processor performance loss is in the
Representing and Manipulating Floating Points. Jo, Heeseung
 Representing and Manipulating Floating Points Jo, Heeseung The Problem How to represent fractional values with finite number of bits? 0.1 0.612 3.14159265358979323846264338327950288... 2 Fractional Binary
Representing and Manipulating Floating Points Jo, Heeseung The Problem How to represent fractional values with finite number of bits? 0.1 0.612 3.14159265358979323846264338327950288... 2 Fractional Binary
Summary of Computer Architecture
 Summary of Computer Architecture Summary CHAP 1: INTRODUCTION Structure Top Level Peripherals Computer Central Processing Unit Main Memory Computer Systems Interconnection Communication lines Input Output
Summary of Computer Architecture Summary CHAP 1: INTRODUCTION Structure Top Level Peripherals Computer Central Processing Unit Main Memory Computer Systems Interconnection Communication lines Input Output
Caches. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Caches Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Memory Hierarchies. Instructor: Dmitri A. Gusev. Fall Lecture 10, October 8, CS 502: Computers and Communications Technology
 Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
ECE 15B Computer Organization Spring 2011
 ECE 15B Computer Organization Spring 2011 Dmitri Strukov Partially adapted from Computer Organization and Design, 4 th edition, Patterson and Hennessy, Agenda Instruction formats Addressing modes Advanced
ECE 15B Computer Organization Spring 2011 Dmitri Strukov Partially adapted from Computer Organization and Design, 4 th edition, Patterson and Hennessy, Agenda Instruction formats Addressing modes Advanced