Boost.Compute. A C++ library for GPU computing. Kyle Lutz
|
|
|
- Audrey Rose Randall
- 6 years ago
- Views:
Transcription
1 Boost.Compute A C++ library for GPU computing Kyle Lutz
2 GPUs (NVIDIA, AMD, Intel) Multi-core CPUs (Intel, AMD) STL for Parallel Devices Accelerators (Xeon Phi, Adapteva Epiphany) FPGAs (Altera, Xilinx)
3 accumulate() adjacent_difference() adjacent_find() all_of() any_of() binary_search() copy() copy_if() copy_n() count() count_if() equal() equal_range() exclusive_scan() fill() fill_n() find() find_end() find_if() find_if_not() for_each() gather() generate() generate_n() includes() inclusive_scan() inner_product() inplace_merge() iota() is_partitioned() is_permutation() is_sorted() lower_bound() lexicographical_compare() max_element() merge() min_element() minmax_element() mismatch() next_permutation() none_of() nth_element() partial_sum() partition() partition_copy() partition_point() prev_permutation() random_shuffle() reduce() remove() remove_if() replace() replace_copy() reverse() reverse_copy() rotate() rotate_copy() scatter() search() search_n() set_difference() set_intersection() set_symmetric_difference() set_union() sort() sort_by_key() stable_partition() stable_sort() swap_ranges() transform() transform_reduce() unique() unique_copy() upper_bound() Algorithms
4 Containers array<t, N> dynamic_bitset<t> flat_map<key, T> flat_set<t> stack<t> string valarray<t> vector<t> Iterators buffer_iterator<t> constant_buffer_iterator<t> constant_iterator<t> counting_iterator<t> discard_iterator function_input_iterator<function> permutation_iterator<elem, Index> transform_iterator<iter, Function> zip_iterator<itertuple> Random Number Generators bernoulli_distribution default_random_engine discrete_distribution linear_congruential_engine mersenne_twister_engine normal_distribution uniform_int_distribution uniform_real_distribution
5 Library Architecture Boost.Compute Interoperability STL-like API Lambda Expressions RNGs Core OpenCL GPU CPU FPGA
6 Why OpenCL? (or why not CUDA/Thrust/Bolt/SYCL/OpenACC/OpenMP/C++AMP?) Standard C++ (no special compiler or compiler extensions) Library-based solution (no special build-system integration) Vendor-neutral, open-standard
7 Low-level API
8 Low-level API Provides classes to wrap OpenCL objects such as buffer, context, program, and command_queue. Takes care of reference counting and error checking Also provides utility functions for handling error codes or setting up the default device
9 Low-level API #include <boost/compute/core.hpp> // lookup default compute device auto gpu = boost::compute::system::default_device(); // create opencl context for the device auto ctx = boost::compute::context(gpu); // create command queue for the device auto queue = boost::compute::command_queue(ctx, gpu); // print device name std::cout << device = << gpu.name() << std::endl;
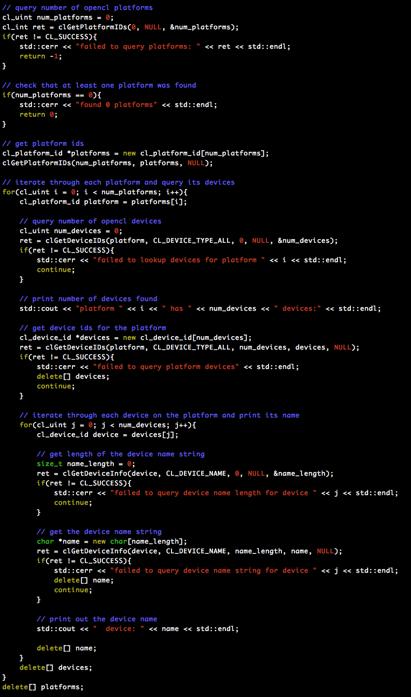
10
11 High-level API
12 Sort Host Data #include <vector> #include <algorithm> std::vector<int> vec = {... }; std::sort(vec.begin(), vec.end());
13 Sort Host Data #include <vector> #include <boost/compute/algorithm/sort.hpp> std::vector<int> vec = {... }; boost::compute::sort(vec.begin(), vec.end(), queue); STL Boost.Compute M 10M 100M
14 Parallel Reduction #include <boost/compute/algorithm/reduce.hpp> #include <boost/compute/container/vector.hpp> boost::compute::vector<int> data = {... }; int sum = 0; boost::compute::reduce( data.begin(), data.end(), &sum, queue ); std::cout << sum = << sum << std::endl;

15 Algorithm Internals Fundamentally, STL-like algorithms produce OpenCL kernel objects which are executed on a compute device. OpenCL C++
16 Custom Functions BOOST_COMPUTE_FUNCTION(int, plus_two, (int x), { return x + 2; }); boost::compute::transform( v.begin(), v.end(), v.begin(), plus_two, queue );
17 Lambda Expressions Offers a concise syntax for specifying custom operations Fully type-checked by the C++ compiler using boost::compute::lambda::_1; boost::compute::transform( v.begin(), v.end(), v.begin(), _1 + 2, queue );
18 Additional Features



19 OpenGL Interop OpenCL provides mechanisms for synchronizing with OpenGL to implement direct rendering on the GPU Boost.Compute provides easy to use functions for interacting with OpenGL in a portable manner. OpenCL OpenGL
20 Program Caching Helps mitigate run-time kernel compilation costs Frequently-used kernels are stored and retrieved from the global cache Offline cache reduces this to one compilation per system
21 Auto-tuning OpenCL supports a wide variety of hardware with diverse execution characteristics Algorithms support different execution parameters such as work-group size, amount of work to execute serially These parameters are tunable and their results are measurable Boost.Compute includes benchmarks and tuning utilities to find the optimal parameters for a given device
22 Auto-tuning
23 Recent News
24 Coming soon to Boost Went through Boost peer-review in December 2014 Accepted as an official Boost library in January 2015 Should be packaged in a Boost release this year (1.59)
25 Boost in GSoC Boost is an accepted organization for the Google Summer of Code 2015 Last year Boost.Compute mentored a student who implemented many new algorithms and features Open to mentoring another student this year See:
26 Thank You Source Documentation
Major Language Changes, pt. 1
 C++0x What is C++0x? Updated version of C++ language. Addresses unresolved problems in C++03. Almost completely backwards compatible. Greatly increases expressiveness (and complexity!) of language. Greatly
C++0x What is C++0x? Updated version of C++ language. Addresses unresolved problems in C++03. Almost completely backwards compatible. Greatly increases expressiveness (and complexity!) of language. Greatly
Parallelism and Concurrency in C++17 and C++20. Rainer Grimm Training, Coaching and, Technology Consulting
 Parallelism and Concurrency in C++17 and C++20 Rainer Grimm Training, Coaching and, Technology Consulting www.grimm-jaud.de Multithreading and Parallelism in C++ Multithreading in C++17 Parallel STL The
Parallelism and Concurrency in C++17 and C++20 Rainer Grimm Training, Coaching and, Technology Consulting www.grimm-jaud.de Multithreading and Parallelism in C++ Multithreading in C++17 Parallel STL The
Working Draft, Technical Specification for C++ Extensions for Parallelism, Revision 1
 Document Number: N3960 Date: 2014-02-28 Reply to: Jared Hoberock NVIDIA Corporation jhoberock@nvidia.com Working Draft, Technical Specification for C++ Extensions for Parallelism, Revision 1 Note: this
Document Number: N3960 Date: 2014-02-28 Reply to: Jared Hoberock NVIDIA Corporation jhoberock@nvidia.com Working Draft, Technical Specification for C++ Extensions for Parallelism, Revision 1 Note: this
To use various types of iterators with the STL algorithms ( ). To use Boolean functions to specify criteria for STL algorithms ( 23.8).
. To use Boolean functions to specify criteria for STL algorithms ( 23.8).") CHAPTER 23 STL Algorithms Objectives To use various types of iterators with the STL algorithms ( 23.1 23.20). To discover the four types of STL algorithms: nonmodifying algorithms, modifying algorithms,
CHAPTER 23 STL Algorithms Objectives To use various types of iterators with the STL algorithms ( 23.1 23.20). To discover the four types of STL algorithms: nonmodifying algorithms, modifying algorithms,
Concurrency and Parallelism with C++17 and C++20. Rainer Grimm Training, Coaching and, Technology Consulting
 Concurrency and Parallelism with C++17 and C++20 Rainer Grimm Training, Coaching and, Technology Consulting www.modernescpp.de Concurrency and Parallelism in C++ Concurrency and Parallelism in C++17 Parallel
Concurrency and Parallelism with C++17 and C++20 Rainer Grimm Training, Coaching and, Technology Consulting www.modernescpp.de Concurrency and Parallelism in C++ Concurrency and Parallelism in C++17 Parallel
Programming Languages Technical Specification for C++ Extensions for Parallelism
 ISO 05 All rights reserved ISO/IEC JTC SC WG N4409 Date: 05-04-0 ISO/IEC DTS 9570 ISO/IEC JTC SC Secretariat: ANSI Programming Languages Technical Specification for C++ Extensions for Parallelism Warning
ISO 05 All rights reserved ISO/IEC JTC SC WG N4409 Date: 05-04-0 ISO/IEC DTS 9570 ISO/IEC JTC SC Secretariat: ANSI Programming Languages Technical Specification for C++ Extensions for Parallelism Warning
Parallelism in C++ J. Daniel Garcia. Universidad Carlos III de Madrid. November 23, 2018
 J. Daniel Garcia Universidad Carlos III de Madrid November 23, 2018 cbea J. Daniel Garcia ARCOS@UC3M (josedaniel.garcia@uc3m.es) 1/58 Introduction to generic programming 1 Introduction to generic programming
J. Daniel Garcia Universidad Carlos III de Madrid November 23, 2018 cbea J. Daniel Garcia ARCOS@UC3M (josedaniel.garcia@uc3m.es) 1/58 Introduction to generic programming 1 Introduction to generic programming
Lecture 21 Standard Template Library. A simple, but very limited, view of STL is the generality that using template functions provides.
 Lecture 21 Standard Template Library STL: At a C++ standards meeting in 1994, the committee voted to adopt a proposal by Alex Stepanov of Hewlett-Packard Laboratories to include, as part of the standard
Lecture 21 Standard Template Library STL: At a C++ standards meeting in 1994, the committee voted to adopt a proposal by Alex Stepanov of Hewlett-Packard Laboratories to include, as part of the standard
C++ - parallelization and synchronization. Jakub Yaghob Martin Kruliš
 C++ - parallelization and synchronization Jakub Yaghob Martin Kruliš The problem Race conditions Separate threads with shared state Result of computation depends on OS scheduling Race conditions simple
C++ - parallelization and synchronization Jakub Yaghob Martin Kruliš The problem Race conditions Separate threads with shared state Result of computation depends on OS scheduling Race conditions simple
C++ - parallelization and synchronization. David Bednárek Jakub Yaghob Filip Zavoral
 C++ - parallelization and synchronization David Bednárek Jakub Yaghob Filip Zavoral The problem Race conditions Separate threads with shared state Result of computation depends on OS scheduling Race conditions
C++ - parallelization and synchronization David Bednárek Jakub Yaghob Filip Zavoral The problem Race conditions Separate threads with shared state Result of computation depends on OS scheduling Race conditions
C++ Standard Template Library
 C++ Standard Template Library CS 247: Software Engineering Principles Generic Algorithms A collection of useful, typesafe, generic (i.e., type-parameterized) containers that - know (almost) nothing about
C++ Standard Template Library CS 247: Software Engineering Principles Generic Algorithms A collection of useful, typesafe, generic (i.e., type-parameterized) containers that - know (almost) nothing about
New Iterator Concepts
 New Iterator Concepts Author: David Abrahams, Jeremy Siek, Thomas Witt Contact: dave@boost-consulting.com, jsiek@osl.iu.edu, witt@styleadvisor.com Organization: Boost Consulting, Indiana University Open
New Iterator Concepts Author: David Abrahams, Jeremy Siek, Thomas Witt Contact: dave@boost-consulting.com, jsiek@osl.iu.edu, witt@styleadvisor.com Organization: Boost Consulting, Indiana University Open
Data_Structures - Hackveda
 Data_Structures - Hackveda ( Talk to Live Mentor) Become a Data Structure and Algorithm Professional - (Beginner - Advanced) Skill level: Beginner - Advanced Training fee: INR 15999 only (Topics covered:
Data_Structures - Hackveda ( Talk to Live Mentor) Become a Data Structure and Algorithm Professional - (Beginner - Advanced) Skill level: Beginner - Advanced Training fee: INR 15999 only (Topics covered:
Parallel Programming with OpenMP and Modern C++ Alternatives
 Parallel Programming with OpenMP and Modern C++ Alternatives Michael F. Hava and Bernhard M. Gruber RISC Software GmbH Softwarepark 35, 4232 Hagenberg, Austria RISC Software GmbH Johannes Kepler University
Parallel Programming with OpenMP and Modern C++ Alternatives Michael F. Hava and Bernhard M. Gruber RISC Software GmbH Softwarepark 35, 4232 Hagenberg, Austria RISC Software GmbH Johannes Kepler University
Scientific programming (in C++)
") Scientific programming (in C++) F. Giacomini INFN-CNAF School on Open Science Cloud Perugia, June 2017 https://baltig.infn.it/giaco/201706_perugia_cpp What is C++ C++ is a programming language that is:
Scientific programming (in C++) F. Giacomini INFN-CNAF School on Open Science Cloud Perugia, June 2017 https://baltig.infn.it/giaco/201706_perugia_cpp What is C++ C++ is a programming language that is:
C and C++ Courses. C Language
 C Language The "C" Language is currently one of the most widely used programming languages. Designed as a tool for creating operating systems (with its help the first Unix systems were constructed) it
C Language The "C" Language is currently one of the most widely used programming languages. Designed as a tool for creating operating systems (with its help the first Unix systems were constructed) it
Generic Programming with JGL 4
 Generic Programming with JGL 4 By John Lammers Recursion Software, Inc. July 2004 TABLE OF CONTENTS Abstract...1 Introduction to Generic Programming...1 How does Java support generic programming?...2 The
Generic Programming with JGL 4 By John Lammers Recursion Software, Inc. July 2004 TABLE OF CONTENTS Abstract...1 Introduction to Generic Programming...1 How does Java support generic programming?...2 The
Distributed Real-Time Control Systems. Lecture 16 C++ Libraries Templates
 Distributed Real-Time Control Systems Lecture 16 C++ Libraries Templates 1 C++ Libraries One of the greatest advantages of C++ is to facilitate code reuse. If code is well organized and documented into
Distributed Real-Time Control Systems Lecture 16 C++ Libraries Templates 1 C++ Libraries One of the greatest advantages of C++ is to facilitate code reuse. If code is well organized and documented into
Foundations of Programming, Volume I, Linear structures
 Plan 1. Machine model. Objects. Values. Assignment, swap, move. 2. Introductory algorithms: advance, distance, find, copy. Iterators: operations, properties, classification. Ranges and their validity.
Plan 1. Machine model. Objects. Values. Assignment, swap, move. 2. Introductory algorithms: advance, distance, find, copy. Iterators: operations, properties, classification. Ranges and their validity.
Functors. Cristian Cibils
 Functors Cristian Cibils (ccibils@stanford.edu) Administrivia You should have Evil Hangman feedback on paperless. If it is there, you received credit Functors Let's say that we needed to find the number
Functors Cristian Cibils (ccibils@stanford.edu) Administrivia You should have Evil Hangman feedback on paperless. If it is there, you received credit Functors Let's say that we needed to find the number
More STL algorithms (revision 2)
") Doc No: N2666=08-0176 Reply to: Matt Austern Date: 2008-06-11 More STL algorithms (revision 2) This paper proposes a number of nonstandard STL-style algorithms for inclusion in the
Doc No: N2666=08-0176 Reply to: Matt Austern Date: 2008-06-11 More STL algorithms (revision 2) This paper proposes a number of nonstandard STL-style algorithms for inclusion in the
Efficient C++ Programming and Memory Management
 Efficient C++ Programming and Memory Management F. Giacomini INFN-CNAF ESC 17 Bertinoro, 22-28 October 2017 https://baltig.infn.it/giaco/cpp-memory-esc17 Outline Introduction Type deduction Function, function
Efficient C++ Programming and Memory Management F. Giacomini INFN-CNAF ESC 17 Bertinoro, 22-28 October 2017 https://baltig.infn.it/giaco/cpp-memory-esc17 Outline Introduction Type deduction Function, function
COPYRIGHTED MATERIAL. Index SYMBOLS. Index
 Index Index SYMBOLS &= (ampersand, equal) operator, 8 & (ampersand) operator, 8 \ (backslash) escape character, 4 ^= (caret, equal) operator, 9 ^ (caret) operator, 9 \r (carriage return) escape character,
Index Index SYMBOLS &= (ampersand, equal) operator, 8 & (ampersand) operator, 8 \ (backslash) escape character, 4 ^= (caret, equal) operator, 9 ^ (caret) operator, 9 \r (carriage return) escape character,
I. Introduction C++11 introduced a comprehensive mechanism to manage generation of random numbers in the <random> header file.
 Paper Number: P1068R0 Title: Vector API for random number generation Authors: Ilya Burylov Alexey Kukanov Ruslan Arutyunyan
Paper Number: P1068R0 Title: Vector API for random number generation Authors: Ilya Burylov Alexey Kukanov Ruslan Arutyunyan
High-Productivity CUDA Development with the Thrust Template Library. San Jose Convention Center September 23 rd 2010 Nathan Bell (NVIDIA Research)
") High-Productivity CUDA Development with the Thrust Template Library San Jose Convention Center September 23 rd 2010 Nathan Bell (NVIDIA Research) Diving In #include #include
High-Productivity CUDA Development with the Thrust Template Library San Jose Convention Center September 23 rd 2010 Nathan Bell (NVIDIA Research) Diving In #include #include
Michel Steuwer.
 Michel Steuwer http://homepages.inf.ed.ac.uk/msteuwer/ SKELCL: Algorithmic Skeletons for GPUs X i a i b i = reduce (+) 0 (zip ( ) A B) #include #include #include
Michel Steuwer http://homepages.inf.ed.ac.uk/msteuwer/ SKELCL: Algorithmic Skeletons for GPUs X i a i b i = reduce (+) 0 (zip ( ) A B) #include #include #include
GJL: The Generic Java Library
 GJL: The Generic Java Library An STL for Java Winter 1999 Semester Project Laboratoire des Méthodes de Programmation Ecole Polytechnique Fédérale de Lausanne Corine Hari February 2000 Table of Contents
GJL: The Generic Java Library An STL for Java Winter 1999 Semester Project Laboratoire des Méthodes de Programmation Ecole Polytechnique Fédérale de Lausanne Corine Hari February 2000 Table of Contents
Deitel Series Page How To Program Series
 Deitel Series Page How To Program Series Android How to Program C How to Program, 7/E C++ How to Program, 9/E C++ How to Program, Late Objects Version, 7/E Java How to Program, 9/E Java How to Program,
Deitel Series Page How To Program Series Android How to Program C How to Program, 7/E C++ How to Program, 9/E C++ How to Program, Late Objects Version, 7/E Java How to Program, 9/E Java How to Program,
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania
 OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
OpenCL: History & Future. November 20, 2017
 Mitglied der Helmholtz-Gemeinschaft OpenCL: History & Future November 20, 2017 OpenCL Portable Heterogeneous Computing 2 APIs and 2 kernel languages C Platform Layer API OpenCL C and C++ kernel language
Mitglied der Helmholtz-Gemeinschaft OpenCL: History & Future November 20, 2017 OpenCL Portable Heterogeneous Computing 2 APIs and 2 kernel languages C Platform Layer API OpenCL C and C++ kernel language
More STL algorithms. Design Decisions. Doc No: N2569= Reply to: Matt Austern Date:
 Doc No: N2569=08-0079 Reply to: Matt Austern Date: 2008-02-29 More STL algorithms This paper proposes a number of nonstandard STL-style algorithms for inclusion in the standard. Nothing
Doc No: N2569=08-0079 Reply to: Matt Austern Date: 2008-02-29 More STL algorithms This paper proposes a number of nonstandard STL-style algorithms for inclusion in the standard. Nothing
Single-source SYCL C++ on Xilinx FPGA. Xilinx Research Labs Khronos 2017/11/12 19
 Single-source SYCL C++ on Xilinx FPGA Xilinx Research Labs Khronos booth @SC17 2017/11/12 19 Khronos standards for heterogeneous systems 3D for the Web - Real-time apps and games in-browser - Efficiently
Single-source SYCL C++ on Xilinx FPGA Xilinx Research Labs Khronos booth @SC17 2017/11/12 19 Khronos standards for heterogeneous systems 3D for the Web - Real-time apps and games in-browser - Efficiently
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Contents. 2 Introduction to C++ Programming,
 cppfp2_toc.fm Page vii Thursday, February 14, 2013 9:33 AM Chapter 24 and Appendices F K are PDF documents posted online at www.informit.com/title/9780133439854 Preface xix 1 Introduction 1 1.1 Introduction
cppfp2_toc.fm Page vii Thursday, February 14, 2013 9:33 AM Chapter 24 and Appendices F K are PDF documents posted online at www.informit.com/title/9780133439854 Preface xix 1 Introduction 1 1.1 Introduction
Chapters and Appendices F J are PDF documents posted online at the book s Companion Website, which is accessible from.
 Contents Chapters 23 26 and Appendices F J are PDF documents posted online at the book s Companion Website, which is accessible from http://www.pearsonhighered.com/deitel See the inside front cover for
Contents Chapters 23 26 and Appendices F J are PDF documents posted online at the book s Companion Website, which is accessible from http://www.pearsonhighered.com/deitel See the inside front cover for
C++ How To Program 10 th Edition. Table of Contents
 C++ How To Program 10 th Edition Table of Contents Preface xxiii Before You Begin xxxix 1 Introduction to Computers and C++ 1 1.1 Introduction 1.2 Computers and the Internet in Industry and Research 1.3
C++ How To Program 10 th Edition Table of Contents Preface xxiii Before You Begin xxxix 1 Introduction to Computers and C++ 1 1.1 Introduction 1.2 Computers and the Internet in Industry and Research 1.3
Introduction to GIL, Boost and Generic Programming
 Introduction to GIL, Boost and Generic Programming Hailin Jin Advanced Technology Labs Adobe Systems Incorporated http://www.adobe.com/technology/people/sanjose/jin.html 1 Outline GIL Boost Generic programming
Introduction to GIL, Boost and Generic Programming Hailin Jin Advanced Technology Labs Adobe Systems Incorporated http://www.adobe.com/technology/people/sanjose/jin.html 1 Outline GIL Boost Generic programming
INTRODUCTION TO OPENCL TM A Beginner s Tutorial. Udeepta Bordoloi AMD
 INTRODUCTION TO OPENCL TM A Beginner s Tutorial Udeepta Bordoloi AMD IT S A HETEROGENEOUS WORLD Heterogeneous computing The new normal CPU Many CPU s 2, 4, 8, Very many GPU processing elements 100 s Different
INTRODUCTION TO OPENCL TM A Beginner s Tutorial Udeepta Bordoloi AMD IT S A HETEROGENEOUS WORLD Heterogeneous computing The new normal CPU Many CPU s 2, 4, 8, Very many GPU processing elements 100 s Different
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
CUDA Toolkit 4.2 Thrust Quick Start Guide. PG _v01 March 2012
 CUDA Toolkit 4.2 Thrust Quick Start Guide PG-05688-040_v01 March 2012 Document Change History Version Date Authors Description of Change 01 2011/1/13 NOJW Initial import from wiki. CUDA Toolkit 4.2 Thrust
CUDA Toolkit 4.2 Thrust Quick Start Guide PG-05688-040_v01 March 2012 Document Change History Version Date Authors Description of Change 01 2011/1/13 NOJW Initial import from wiki. CUDA Toolkit 4.2 Thrust
OpenCL Overview. Shanghai March Neil Trevett Vice President Mobile Content, NVIDIA President, The Khronos Group
 Copyright Khronos Group, 2012 - Page 1 OpenCL Overview Shanghai March 2012 Neil Trevett Vice President Mobile Content, NVIDIA President, The Khronos Group Copyright Khronos Group, 2012 - Page 2 Processor
Copyright Khronos Group, 2012 - Page 1 OpenCL Overview Shanghai March 2012 Neil Trevett Vice President Mobile Content, NVIDIA President, The Khronos Group Copyright Khronos Group, 2012 - Page 2 Processor
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
WRITING DATA PARALLEL ALGORITHMS ON GPUs
 WRITING DATA PARALLEL ALGORITHMS ON GPUs WITH C++ AMP Ade Miller Technical Director, CenturyLink Cloud. ABSTRACT TODAY MOST PCS, TABLETS AND PHONES SUPPORT MULTI-CORE PROCESSORS AND MOST PROGRAMMERS HAVE
WRITING DATA PARALLEL ALGORITHMS ON GPUs WITH C++ AMP Ade Miller Technical Director, CenturyLink Cloud. ABSTRACT TODAY MOST PCS, TABLETS AND PHONES SUPPORT MULTI-CORE PROCESSORS AND MOST PROGRAMMERS HAVE
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
I/O and STL Algorithms
 CS193D Handout 21 Winter 2005/2006 February 29, 2006 I/O and STL Algorithms See also: Chapter 14, Chapter 22 I/O and STL Algorithms CS193D, 2/29/06 1 Raw Input and Output ostream::put(char ch); ostream::write(const
CS193D Handout 21 Winter 2005/2006 February 29, 2006 I/O and STL Algorithms See also: Chapter 14, Chapter 22 I/O and STL Algorithms CS193D, 2/29/06 1 Raw Input and Output ostream::put(char ch); ostream::write(const
AN 831: Intel FPGA SDK for OpenCL
 AN 831: Intel FPGA SDK for OpenCL Host Pipelined Multithread Subscribe Send Feedback Latest document on the web: PDF HTML Contents Contents 1 Intel FPGA SDK for OpenCL Host Pipelined Multithread...3 1.1
AN 831: Intel FPGA SDK for OpenCL Host Pipelined Multithread Subscribe Send Feedback Latest document on the web: PDF HTML Contents Contents 1 Intel FPGA SDK for OpenCL Host Pipelined Multithread...3 1.1
Object-Oriented Programming for Scientific Computing
 Object-Oriented Programming for Scientific Computing STL Iterators and Algorithms Ole Klein Interdisciplinary Center for Scientific Computing Heidelberg University ole.klein@iwr.uni-heidelberg.de Summer
Object-Oriented Programming for Scientific Computing STL Iterators and Algorithms Ole Klein Interdisciplinary Center for Scientific Computing Heidelberg University ole.klein@iwr.uni-heidelberg.de Summer
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
AutoTVM & Device Fleet
 AutoTVM & Device Fleet ` Learning to Optimize Tensor Programs Frameworks High-level data flow graph and optimizations Hardware Learning to Optimize Tensor Programs Frameworks High-level data flow graph
AutoTVM & Device Fleet ` Learning to Optimize Tensor Programs Frameworks High-level data flow graph and optimizations Hardware Learning to Optimize Tensor Programs Frameworks High-level data flow graph
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
WP Tutorial. WP 0.6 for Oxygen Patrick Baudin, Loïc Correnson, Philippe Hermann. CEA LIST, Software Safety Laboratory
 WP Tutorial WP Tutorial WP 0.6 for Oxygen-20120901 Patrick Baudin, Loïc Correnson, Philippe Hermann CEA LIST, Software Safety Laboratory c 2010-2012 CEA LIST This work is based on the book ACSL by Example
WP Tutorial WP Tutorial WP 0.6 for Oxygen-20120901 Patrick Baudin, Loïc Correnson, Philippe Hermann CEA LIST, Software Safety Laboratory c 2010-2012 CEA LIST This work is based on the book ACSL by Example
Parallel STL in today s SYCL Ruymán Reyes
 Parallel STL in today s SYCL Ruymán Reyes ruyman@codeplay.com Codeplay Research 15 th November, 2016 Outline 1 Parallelism TS 2 The SYCL parallel STL 3 Heterogeneous Execution with Parallel STL 4 Conclusions
Parallel STL in today s SYCL Ruymán Reyes ruyman@codeplay.com Codeplay Research 15 th November, 2016 Outline 1 Parallelism TS 2 The SYCL parallel STL 3 Heterogeneous Execution with Parallel STL 4 Conclusions
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
MODULE 37 --THE STL-- ALGORITHM PART V
 MODULE 37 --THE STL-- ALGORITHM PART V My Training Period: hours Note: Compiled using Microsoft Visual C++.Net, win32 empty console mode application. g++ compilation example is given at the end of this
MODULE 37 --THE STL-- ALGORITHM PART V My Training Period: hours Note: Compiled using Microsoft Visual C++.Net, win32 empty console mode application. g++ compilation example is given at the end of this
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell 05/12/2015 IWOCL 2015 SYCL Tutorial Khronos OpenCL SYCL committee
 trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
Using SYCL as an Implementation Framework for HPX.Compute
 Using SYCL as an Implementation Framework for HPX.Compute Marcin Copik 1 Hartmut Kaiser 2 1 RWTH Aachen University mcopik@gmail.com 2 Louisiana State University Center for Computation and Technology The
Using SYCL as an Implementation Framework for HPX.Compute Marcin Copik 1 Hartmut Kaiser 2 1 RWTH Aachen University mcopik@gmail.com 2 Louisiana State University Center for Computation and Technology The
C++ for numerical computing - part 2
 C++ for numerical computing - part 2 Rupert Nash r.nash@epcc.ed.ac.uk 1 / 36 Recap 2 / 36 Iterators std::vector data = GetData(n); // C style iteration - fully explicit for (auto i=0; i!= n; ++i)
C++ for numerical computing - part 2 Rupert Nash r.nash@epcc.ed.ac.uk 1 / 36 Recap 2 / 36 Iterators std::vector data = GetData(n); // C style iteration - fully explicit for (auto i=0; i!= n; ++i)
Contest programming. Linear data structures. Maksym Planeta
 Contest programming Linear data structures Maksym Planeta 20.04.2018 1/2 Table of Contents Organisation Linear Data Structures Long arithmetic Practice 2/2 Update on organisation 11 weeks 9 exercises:
Contest programming Linear data structures Maksym Planeta 20.04.2018 1/2 Table of Contents Organisation Linear Data Structures Long arithmetic Practice 2/2 Update on organisation 11 weeks 9 exercises:
Copyright Khronos Group Page 1. Introduction to SYCL. SYCL Tutorial IWOCL
 Copyright Khronos Group 2015 - Page 1 Introduction to SYCL SYCL Tutorial IWOCL 2015-05-12 Copyright Khronos Group 2015 - Page 2 Introduction I am - Lee Howes - Senior staff engineer - GPU systems team
Copyright Khronos Group 2015 - Page 1 Introduction to SYCL SYCL Tutorial IWOCL 2015-05-12 Copyright Khronos Group 2015 - Page 2 Introduction I am - Lee Howes - Senior staff engineer - GPU systems team
Bigger Better More. The new C++ Standard Library. Thomas Witt April Copyright 2009 Thomas Witt
 Bigger Better More The new C++ Standard Library Thomas Witt April 24 2009 Landscape C99 (2003) Technical Report on C++ Library Extensions (TR1) Jan 2006 Committee Draft (CD) Oct 2008 C++ 0x TR2.NET, Java,
Bigger Better More The new C++ Standard Library Thomas Witt April 24 2009 Landscape C99 (2003) Technical Report on C++ Library Extensions (TR1) Jan 2006 Committee Draft (CD) Oct 2008 C++ 0x TR2.NET, Java,
Chris Sewell Li-Ta Lo James Ahrens Los Alamos National Laboratory
 Portability and Performance for Visualization and Analysis Operators Using the Data-Parallel PISTON Framework Chris Sewell Li-Ta Lo James Ahrens Los Alamos National Laboratory Outline! Motivation Portability
Portability and Performance for Visualization and Analysis Operators Using the Data-Parallel PISTON Framework Chris Sewell Li-Ta Lo James Ahrens Los Alamos National Laboratory Outline! Motivation Portability
Open Compute Stack (OpenCS) Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,
 Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,") Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
THRUST QUICK START GUIDE. DU _v8.0 September 2016
 THRUST QUICK START GUIDE DU-06716-001_v8.0 September 2016 TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. Installation and Versioning... 1 Chapter 2. Vectors... 2 2.1. Thrust Namespace... 4 2.2. Iterators
THRUST QUICK START GUIDE DU-06716-001_v8.0 September 2016 TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. Installation and Versioning... 1 Chapter 2. Vectors... 2 2.1. Thrust Namespace... 4 2.2. Iterators
BUILDING PARALLEL ALGORITHMS WITH BULK. Jared Hoberock Programming Systems and Applications NVIDIA Research github.
 BUILDING PARALLEL ALGORITHMS WITH BULK Jared Hoberock Programming Systems and Applications NVIDIA Research github.com/jaredhoberock B HELLO, BROTHER! #include #include struct hello
BUILDING PARALLEL ALGORITHMS WITH BULK Jared Hoberock Programming Systems and Applications NVIDIA Research github.com/jaredhoberock B HELLO, BROTHER! #include #include struct hello
Templates & the STL. CS 2308 :: Fall 2015 Molly O'Neil
 Templates & the STL CS 2308 :: Fall 2015 Molly O'Neil Function Templates Let's say we have a program that repeatedly needs to find the maximum value in an array In one place in our code, we need the max
Templates & the STL CS 2308 :: Fall 2015 Molly O'Neil Function Templates Let's say we have a program that repeatedly needs to find the maximum value in an array In one place in our code, we need the max
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening. Alberto Magni, Christophe Dubach, Michael O'Boyle
 A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Copyright Khronos Group, Page 1. OpenCL. GDC, March 2010
 Copyright Khronos Group, 2011 - Page 1 OpenCL GDC, March 2010 Authoring and accessibility Application Acceleration System Integration Copyright Khronos Group, 2011 - Page 2 Khronos Family of Standards
Copyright Khronos Group, 2011 - Page 1 OpenCL GDC, March 2010 Authoring and accessibility Application Acceleration System Integration Copyright Khronos Group, 2011 - Page 2 Khronos Family of Standards
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA
 EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
Getting Started with Intel SDK for OpenCL Applications
 Getting Started with Intel SDK for OpenCL Applications Webinar #1 in the Three-part OpenCL Webinar Series July 11, 2012 Register Now for All Webinars in the Series Welcome to Getting Started with Intel
Getting Started with Intel SDK for OpenCL Applications Webinar #1 in the Three-part OpenCL Webinar Series July 11, 2012 Register Now for All Webinars in the Series Welcome to Getting Started with Intel
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU
 Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
Copyright Khronos Group 2012 Page 1. OpenCL 1.2. August 2012
 Copyright Khronos Group 2012 Page 1 OpenCL 1.2 August 2012 Copyright Khronos Group 2012 Page 2 Khronos - Connecting Software to Silicon Khronos defines open, royalty-free standards to access graphics,
Copyright Khronos Group 2012 Page 1 OpenCL 1.2 August 2012 Copyright Khronos Group 2012 Page 2 Khronos - Connecting Software to Silicon Khronos defines open, royalty-free standards to access graphics,
MODULE 35 --THE STL-- ALGORITHM PART III
 MODULE 35 --THE STL-- ALGORITHM PART III My Training Period: hours Note: Compiled using Microsoft Visual C++.Net, win32 empty console mode application. g++ compilation example is given at the end of this
MODULE 35 --THE STL-- ALGORITHM PART III My Training Period: hours Note: Compiled using Microsoft Visual C++.Net, win32 empty console mode application. g++ compilation example is given at the end of this
GPU Programming. Rupesh Nasre.
 GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 CUDA Function Declarations device float DeviceFunc() global void KernelFunc() Executed on the: device device Callable
GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 CUDA Function Declarations device float DeviceFunc() global void KernelFunc() Executed on the: device device Callable
More performance options
 More performance options OpenCL, streaming media, and native coding options with INDE April 8, 2014 2014, Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, Intel Xeon, and Intel
More performance options OpenCL, streaming media, and native coding options with INDE April 8, 2014 2014, Intel Corporation. All rights reserved. Intel, the Intel logo, Intel Inside, Intel Xeon, and Intel
OpenCL Press Conference
 Copyright Khronos Group, 2011 - Page 1 OpenCL Press Conference Tokyo, November 2011 Neil Trevett Vice President Mobile Content, NVIDIA President, The Khronos Group Copyright Khronos Group, 2011 - Page
Copyright Khronos Group, 2011 - Page 1 OpenCL Press Conference Tokyo, November 2011 Neil Trevett Vice President Mobile Content, NVIDIA President, The Khronos Group Copyright Khronos Group, 2011 - Page
GpuWrapper: A Portable API for Heterogeneous Programming at CGG
 GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
The OpenVX Computer Vision and Neural Network Inference
 The OpenVX Computer and Neural Network Inference Standard for Portable, Efficient Code Radhakrishna Giduthuri Editor, OpenVX Khronos Group radha.giduthuri@amd.com @RadhaGiduthuri Copyright 2018 Khronos
The OpenVX Computer and Neural Network Inference Standard for Portable, Efficient Code Radhakrishna Giduthuri Editor, OpenVX Khronos Group radha.giduthuri@amd.com @RadhaGiduthuri Copyright 2018 Khronos
Fast BVH Construction on GPUs
 Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Exceptions, Templates, and the STL
 Exceptions, Templates, and the STL CSE100 Principles of Programming with C++, Fall 2018 (based off Chapter 16 slides by Pearson) Ryan Dougherty Arizona State University http://www.public.asu.edu/~redoughe/
Exceptions, Templates, and the STL CSE100 Principles of Programming with C++, Fall 2018 (based off Chapter 16 slides by Pearson) Ryan Dougherty Arizona State University http://www.public.asu.edu/~redoughe/
End to End Optimization Stack for Deep Learning
 End to End Optimization Stack for Deep Learning Presenter: Tianqi Chen Paul G. Allen School of Computer Science & Engineering University of Washington Collaborators University of Washington AWS AI Team
End to End Optimization Stack for Deep Learning Presenter: Tianqi Chen Paul G. Allen School of Computer Science & Engineering University of Washington Collaborators University of Washington AWS AI Team
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Automatic Pruning of Autotuning Parameter Space for OpenCL Applications
 Automatic Pruning of Autotuning Parameter Space for OpenCL Applications Ahmet Erdem, Gianluca Palermo 6, and Cristina Silvano 6 Department of Electronics, Information and Bioengineering Politecnico di
Automatic Pruning of Autotuning Parameter Space for OpenCL Applications Ahmet Erdem, Gianluca Palermo 6, and Cristina Silvano 6 Department of Electronics, Information and Bioengineering Politecnico di
Expose NVIDIA s performance counters to the userspace for NV50/Tesla
 Expose NVIDIA s performance counters to the userspace for NV50/Tesla Nouveau project Samuel Pitoiset Supervised by Martin Peres GSoC student 2013 & 2014 October 8, 2014 1 / 27 Summary 1 Introduction What
Expose NVIDIA s performance counters to the userspace for NV50/Tesla Nouveau project Samuel Pitoiset Supervised by Martin Peres GSoC student 2013 & 2014 October 8, 2014 1 / 27 Summary 1 Introduction What
Sequential Containers. Ali Malik
 Sequential Containers Ali Malik malikali@stanford.edu Game Plan Recap Stream wrapup Overview of STL Sequence Containers std::vector std::deque Container Adapters Announcements Recap stringstream Sometimes
Sequential Containers Ali Malik malikali@stanford.edu Game Plan Recap Stream wrapup Overview of STL Sequence Containers std::vector std::deque Container Adapters Announcements Recap stringstream Sometimes
HPC trends (Myths about) accelerator cards & more. June 24, Martin Schreiber,
 accelerator cards & more. June 24, Martin Schreiber,") HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
FPGA-based Supercomputing: New Opportunities and Challenges
 FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
SIGGRAPH Briefing August 2014
 Copyright Khronos Group 2014 - Page 1 SIGGRAPH Briefing August 2014 Neil Trevett VP Mobile Ecosystem, NVIDIA President, Khronos Copyright Khronos Group 2014 - Page 2 Significant Khronos API Ecosystem Advances
Copyright Khronos Group 2014 - Page 1 SIGGRAPH Briefing August 2014 Neil Trevett VP Mobile Ecosystem, NVIDIA President, Khronos Copyright Khronos Group 2014 - Page 2 Significant Khronos API Ecosystem Advances
Java SE 8 New Features
 Java SE 8 New Features Duration 2 Days What you will learn This Java SE 8 New Features training delves into the major changes and enhancements in Oracle Java SE 8. You'll focus on developing an understanding
Java SE 8 New Features Duration 2 Days What you will learn This Java SE 8 New Features training delves into the major changes and enhancements in Oracle Java SE 8. You'll focus on developing an understanding
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Lecture Topic: An Overview of OpenCL on Xeon Phi
 C-DAC Four Days Technology Workshop ON Hybrid Computing Coprocessors/Accelerators Power-Aware Computing Performance of Applications Kernels hypack-2013 (Mode-4 : GPUs) Lecture Topic: on Xeon Phi Venue
C-DAC Four Days Technology Workshop ON Hybrid Computing Coprocessors/Accelerators Power-Aware Computing Performance of Applications Kernels hypack-2013 (Mode-4 : GPUs) Lecture Topic: on Xeon Phi Venue
CS11 Introduction to C++ Spring Lecture 8
 CS11 Introduction to C++ Spring 2013-2014 Lecture 8 Local Variables string getusername() { string user; } cout user; return user;! What happens to user when function
CS11 Introduction to C++ Spring 2013-2014 Lecture 8 Local Variables string getusername() { string user; } cout user; return user;! What happens to user when function
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi
 Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Building Real-Time Professional Visualization Solutions on GPUs. Kristof Denolf Samuel Maroy Ronny Dewaele
 Building Real-Time Professional Visualization Solutions on GPUs Kristof Denolf Samuel Maroy Ronny Dewaele Page 2 Outline Barco s professional visualization solutions The need for performance portability
Building Real-Time Professional Visualization Solutions on GPUs Kristof Denolf Samuel Maroy Ronny Dewaele Page 2 Outline Barco s professional visualization solutions The need for performance portability
AMD CORPORATE TEMPLATE AMD Radeon Open Compute Platform Felix Kuehling
 AMD Radeon Open Compute Platform Felix Kuehling ROCM PLATFORM ON LINUX Compiler Front End AMDGPU Driver Enabled with ROCm GCN Assembly Device LLVM Compiler (GCN) LLVM Opt Passes GCN Target Host LLVM Compiler
AMD Radeon Open Compute Platform Felix Kuehling ROCM PLATFORM ON LINUX Compiler Front End AMDGPU Driver Enabled with ROCm GCN Assembly Device LLVM Compiler (GCN) LLVM Opt Passes GCN Target Host LLVM Compiler
2 Installation Installing SnuCL CPU Installing SnuCL Single Installing SnuCL Cluster... 7
 SnuCL User Manual Center for Manycore Programming Department of Computer Science and Engineering Seoul National University, Seoul 151-744, Korea http://aces.snu.ac.kr Release 1.3.2 December 2013 Contents
SnuCL User Manual Center for Manycore Programming Department of Computer Science and Engineering Seoul National University, Seoul 151-744, Korea http://aces.snu.ac.kr Release 1.3.2 December 2013 Contents
Chapter 16: Exceptions, Templates, and the Standard Template Library (STL)
") Chapter 16: Exceptions, Templates, and the Standard Template Library (STL) 6.1 Exceptions Exceptions Indicate that something unexpected has occurred or been detected Allow program to deal with the problem
Chapter 16: Exceptions, Templates, and the Standard Template Library (STL) 6.1 Exceptions Exceptions Indicate that something unexpected has occurred or been detected Allow program to deal with the problem