General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
|
|
|
- Godwin Austin
- 6 years ago
- Views:
Transcription
1 General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3
2 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates critical path of application Data parallel algorithms leverage GPU attributes Large data arrays, streaming throughput Fine-grain SIMD parallelism sometimes also referred to as SIMT, emphasizing the threads Low-latency floating point (FP) computation 4
 physics, image processing Physical modeling, computational")
3 What is (Historical) GPGPU? Applications see GPGPU.org, GPU Gems Game effects (FX) physics, image processing Physical modeling, computational engineering, matrix algebra, convolution, correlation, sorting 5

4 CUDA Compute Unified Device Architecture General purpose programming model User kicks off batches of threads on the GPU GPU = dedicated super-threaded, massively data parallel co-processor Targeted software stack Compute oriented drivers, language, and tools Driver for loading computation programs into GPU Standalone Driver - Optimized for computation Interface designed for compute graphics-free API Data sharing with OpenGL buffer objects Guaranteed maximum download & readback speeds Explicit GPU memory management 7





5 Parallel Computing on a GPU: First Generation 8-series GPUs deliver 25 to 200+ GFLOPS on compiled parallel C applications Available in laptops, desktops, and clusters GPU parallelism is doubling every year Programming model scales transparently Programmable in C with CUDA tools Multithreaded SPMD model uses application data parallelism and thread parallelism GeForce 8800 Tesla D870 Tesla S870 9



6 New server: wulver 2 GPU Cards:!! GTX 770! Kepler Architecture! Compute capability 3.0!!!! GTX 970! Maxwell Architecture! Compute capability 5.2! 10



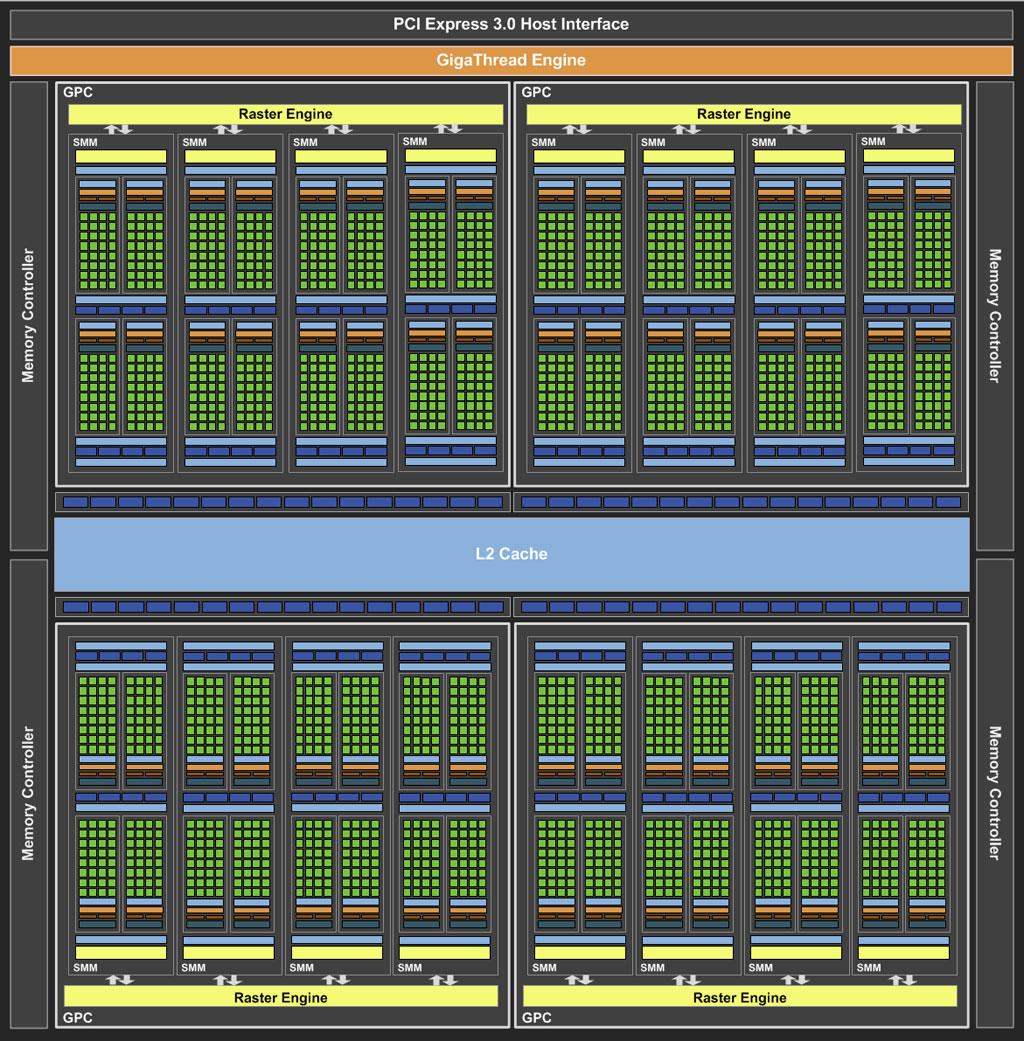
7 GTX 770 Kepler 11


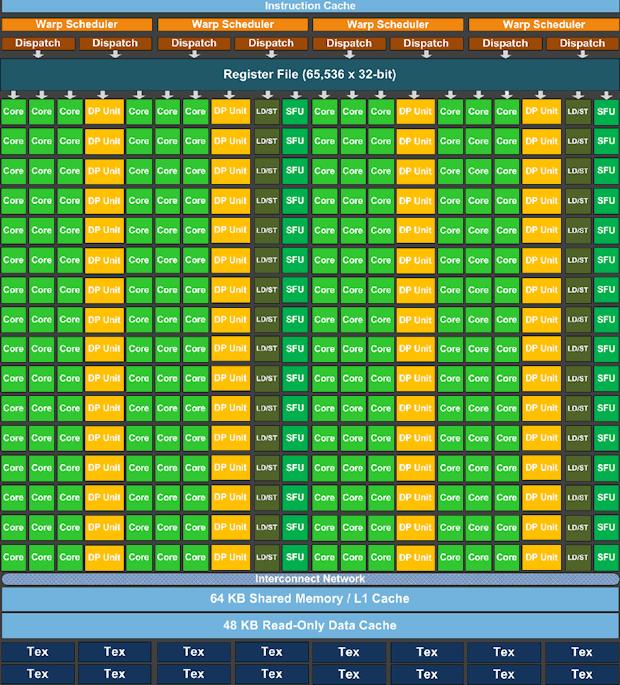
8 GPU architecture evolution: Maxwell 12

9 Architecture: TK1 Keppler 192 cores!! On 1 SMX:! streaming! Multiprocessor! 13
10 CUDA Devices and Threads A compute device Is a coprocessor to the CPU or host ( memory Has its own DRAM (device Runs many threads in parallel Is typically a GPU but can also be another type of parallel processing device Data-parallel portions of an application are expressed as device kernels which run on many threads Differences between GPU and CPU threads GPU threads are extremely lightweight Very little creation overhead GPU needs 1000s of threads for full efficiency Multi-core CPU needs only a few 14
11 CUDA C Integrated host+device app C program Serial or modestly parallel parts in host C code Highly parallel parts in device SPMD kernel C code ( host ) Serial Code ( device ) Parallel Kernel KernelA<<< nblk, ntid >>>(args);... ( host ) Serial Code ( device ) Parallel Kernel KernelB<<< nblk, ntid >>>(args);... 16
12 Extended C Type Qualifiers global, device, shared, local, constant Keywords threadidx, blockidx Intrinsics syncthreads Runtime API Memory, symbol, execution management Function launch device float filter[n]; global void convolve (float *image) { } shared float region[m];... region[threadidx] = image[i]; syncthreads()... image[j] = result; // Allocate GPU memory void *myimage = cudamalloc(bytes) // 100 blocks, 10 threads per block convolve<<<100, 10>>> (myimage); 19
13 nvcc compiler Special compiler that creates device code and host code /usr/local/cuda/bin/nvcc threadid.cu -o threadid -arch=sm_20 The arch will allow you to create code for each type of compute level See the nvidia developer documentation 20
14 Arrays of Parallel Threads A CUDA kernel is executed by an array of threads ( SPMD ) All threads run the same code Each thread has an ID that it uses to compute memory addresses and make control decisions threadid float x = input[threadid]; float y = func(x); output[threadid] = y; 22
15 Thread Blocks: Scalable Cooperation Divide monolithic thread array into multiple blocks Threads within a block cooperate via shared memory, atomic operations and barrier synchronization Threads in different blocks cannot cooperate threadid Thread Block 0 Thread Block 1 Thread Block N float x = input[threadid]; float y = func(x); output[threadid] = y; float x = input[threadid]; float y = func(x); output[threadid] = y; float x = input[threadid]; float y = func(x); output[threadid] = y; 23
16 CUDA API Highlights: Easy and Lightweight The API is an extension to the ANSI C programming language Low learning curve The hardware is designed to enable lightweight runtime and driver High performance 24
17 Block IDs and Thread IDs original architectures Each thread uses IDs to decide what data to work on Block ID: 1D or 2D Thread ID: 1D, 2D, or 3D Simplifies memory addressing when processing multidimensional data Image processing Solving PDEs on volumes Host Kernel 1 Kernel 2 Device Grid 1 Grid 2 Block (0, 0) Block (0, 1) Block (1, 0) Block (1, 1) Block (1, 1) (0,0,1) (1,0,1) (2,0,1) (3,0,1) Thread (0,0,0) Thread (1,0,0) Thread (2,0,0) Thread (3,0,0) Thread (0,1,0) Thread (1,1,0) Thread (2,1,0) Thread (3,1,0) Courtesy: NDVIA 25
18 Assigning grids, blocks of threads Obtaining a thread s ID depends on layout chosen The complicated aspect of CUDA programming Host Device Kernel 1 Grid 1 Block (0, 0) Block (0, 1) Block (1, 0) Block (1, 1) Grid 2 Kernel 2 Block (1, 1) (0,0,1) (1,0,1) (2,0,1) (3,0,1) Thread (0,0,0) Thread (1,0,0) Thread (2,0,0) Thread (3,0,0) Thread (0,1,0) Thread (1,1,0) Thread (2,1,0) Thread (3,1,0) Courtesy: NDVIA 26
19 CUDA Memory Model Overview Global memory Main means of communicating R/W Data between host and device Grid ( 0 (0, Block ( 0 (1, Block Contents visible to all threads Long latency access Shared Memory Registers Registers Shared Memory Registers Registers We will focus on global memory for now Host ( 0 (1, Thread ( 0 (0, Thread Global Memory ( 0 (1, Thread ( 0 (0, Thread 27

20 CUDA Device Memory Allocation cudamalloc() Allocates object in the device Global Memory Requires two parameters Address of a pointer to the allocated object Size of of allocated object cudafree() Frees object from device Global Memory Pointer to freed object Host Grid ( 0 (0, Block Registers Global Memory Shared Memory ( 0 (0, Thread Registers ( 0 (1, Thread ( 0 (1, Block Shared Memory Registers Registers ( 0 (1, Thread ( 0 (0, Thread 28
21 (. cont ) CUDA Device Memory Allocation Code example: Allocate a 64 * 64 single precision float array Attach the allocated storage to Md d is often used to indicate a device data structure TILE_WIDTH = 64; Float* Md int size = TILE_WIDTH * TILE_WIDTH * sizeof(float); cudamalloc((void**)&md, size); cudafree(md); 29
22 CUDA Host-Device Data Transfer cudamemcpy() memory data transfer Grid Requires four parameters Pointer to destination Pointer to source Number of bytes copied ( 0 (0, Block Registers Shared Memory Registers ( 0 (1, Block Shared Memory Registers Registers Type of transfer Host to Host ( 0 (1, Thread ( 0 (0, Thread ( 0 (1, Thread ( 0 (0, Thread Host to Device Device to Host Host Global Memory Device to Device Asynchronous transfer 30
23 CUDA Host-Device Data Transfer (cont.) Code example: Transfer a 64 * 64 single precision float array M is in host memory and Md is in device memory cudamemcpyhosttodevice and cudamemcpydevicetohost are symbolic constants cudamemcpy(md, M, size, cudamemcpyhosttodevice); cudamemcpy(m, Md, size, cudamemcpydevicetohost); 31
24 CUDA Keywords 32
25 CUDA Function Declarations () DeviceFunc device float () KernelFunc global void Executed on the: device device Only callable from the: device host host float () HostFunc host host global defines a kernel function Must return void device and host can be used together 33
26 Calling a Kernel Function Thread Creation A kernel function must be called with an execution configuration: global void KernelFunc(...); dim3 DimGrid(100, 50); // 5000 thread blocks dim3 DimBlock(4, 8, 8); // 256 threads per block size_t SharedMemBytes = 64; // 64 bytes of shared memory KernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...); Any call to a kernel function is asynchronous from CUDA 1.0 on, explicit synch needed for blocking 35
27 Grids, Blocks, and Threads Separate presentation 36
28 A Simple Running Example Matrix Multiplication A simple matrix multiplication example that illustrates the basic features of memory and thread management in CUDA programs Leave shared memory usage until later Local, register usage Thread ID usage Memory data transfer API between host and device Assume square matrix for simplicity 37
29 Programming Model: Square Matrix Multiplication Example P = M * N of size WIDTH x WIDTH Without tiling: One thread calculates one element of P M and N are loaded WIDTH times from global memory N M P WIDTH WIDTH WIDTH WIDTH 38
30 Memory Layout of a Matrix in C M 0,0! M 0,1! M 0,2! M 0,3! M 1,0! M 1,1! M 1,2! M 1,3! M 2,0! M 2,1! M 2,2! M 2,3! M 3,0! M 3,1! M 3,2! M 3,3! M! M 0,0! M 0,1! M 0,2! M 0,3! M 1,1! M 1,0! M 1,2! M 1,3! M 2,0! M 2,1! M 2,2! M 2,3! M 3,0! M 3,1! M 3,2! M 3,3! 39
31 Step 1: Matrix Multiplication A Simple Host Version in C // Matrix multiplication on the (CPU) host in double N precision! ( Width void MatrixMulOnHost(float* M, float* N, float* P, int { ( i ++ for (int i = 0; i < Width; j! for (int j = 0; j < Width; ++j) { double sum = 0; for (int k = 0; k < Width; ++k) { double a = M[i * width + k]; } } M double b = N[k * width + j]; sum += a * b; } P[i * Width + j] = sum; k! i! P k! WIDTH WIDTH WIDTH WIDTH 40
32 Step 2: Input Matrix Data Transfer ( Code (Host-side ( Width void MatrixMulOnDevice(float* M, float* N, float* P, int { int size = Width * Width * sizeof(float); float* Md, Nd, Pd;! 1. // Allocate and Load M, N to device memory cudamalloc(&md, size); cudamemcpy(md, M, size, cudamemcpyhosttodevice); cudamalloc(&nd, size); cudamemcpy(nd, N, size, cudamemcpyhosttodevice); // Allocate P on the device cudamalloc(&pd, size); 41
33 Step 3: Output Matrix Data Transfer ( Code (Host-side 2. // Kernel invocation code to be shown later!!! 3. // Read P from the device! cudamemcpy(p, Pd, size, cudamemcpydevicetohost);!! // Free device matrices! cudafree(md); cudafree(nd); cudafree (Pd);! }! 42
34 Step 4: Kernel Function // Matrix multiplication kernel per thread code ( Width global void MatrixMulKernel(float* Md, float* Nd, float* Pd, int { // Pvalue is used to store the element of the matrix // that is computed by the thread float Pvalue = 0; 43
35 (. cont ) Step 4: Kernel Function { ( k ++ for (int k = 0; k < Width; float Melement = Md[threadIdx.y*Width+k]; float Nelement = Nd[k*Width+threadIdx.x]; Pvalue += Melement * Nelement; } Nd tx! k! WIDTH } Pd[threadIdx.y*Width+threadIdx.x] = Pvalue; Md Pd ty! ty! k! tx! WIDTH WIDTH WIDTH 44
36 Step 5: Kernel Invocation (Host-side Code) // Setup the execution configuration dim3 dimgrid(1, 1); dim3 dimblock(width, Width); // Launch the device computation threads! MatrixMulKernel<<<dimGrid, dimblock>>>(md, Nd, Pd, Width); 45
37 Only One Thread Block Used One Block of threads compute matrix Pd Each thread computes one element of Pd Each thread Loads a row of matrix Md Loads a column of matrix Nd Perform one multiply and addition for each pair of Md and Nd elements Compute to off-chip memory access ratio close to 1:1 (not very ( high Size of matrix limited by the number of threads allowed in a thread block Grid 1 Block WIDTH Thread )2, 2 ( Md Nd Pd
38 Step 7: Handling Arbitrary Sized Square Matrices Have each 2D thread block to compute a (TILE_WIDTH) 2 sub-matrix (tile) of the result matrix Each has (TILE_WIDTH) 2 threads Nd WIDTH Generate a 2D Grid of (WIDTH/ TILE_WIDTH) 2 blocks Md You still need to put a loop around the kernel call for cases where WIDTH/ TILE_WIDTH is greater than max grid size (64K)!! Pd bx! by! TILE_WIDTH! ty! tx! WIDTH WIDTH WIDTH 47
39 Some Useful Information on Tools 48
40 Compiling a CUDA Program Virtual Physical C/C++ CUDA Application NVCC PTX Code PTX to Target Compiler float4 me = gx[gtid]; me.x += me.y * me.z; CPU Code Parallel Thread ( PTX ) execution Virtual Machine and ISA Programming model Execution resources and state ld.global.v4.f32 {$f1,$f3,$f5,$f7}, [$r9+0]; mad.f32 $f1, $f5, $f3, $f1; G80 GPU Target code 49
41 Compilation Any source file containing CUDA language extensions must be compiled with NVCC NVCC is a compiler driver Works by invoking all the necessary tools and compilers like cudacc, g++, cl,... NVCC outputs: ( Code C code (host CPU PTX Must then be compiled with the rest of the application using another tool Object code directly Or, PTX source, interpreted at runtime 50
42 Linking Any executable with CUDA code requires two dynamic libraries: ( cudart ) The CUDA runtime library ( cuda ) The CUDA core library 51
43 Debugging Using the Device Emulation Mode An executable compiled in device emulation mode (nvcc -deviceemu) runs completely on the host using the CUDA runtime No need of any device and CUDA driver Each device thread is emulated with a host thread Running in device emulation mode, one can: (. etc Use host native debug support (breakpoints, inspection, Access any device-specific data from host code and vice-versa Call any host function from device code (e.g. printf) and viceversa Detect deadlock situations caused by improper usage of syncthreads 52
44 Device Emulation Mode Pitfalls Emulated device threads execute sequentially, so simultaneous accesses of the same memory location by multiple threads could produce different results. Dereferencing device pointers on the host or host pointers on the device can produce correct results in device emulation mode, but will generate an error in device execution mode 53
45 Floating Point Results of floating-point computations will slightly differ because of: Different compiler outputs, instruction sets Use of extended precision for intermediate results There are various options to force strict single precision on the host 54
CIS 665: GPU Programming. Lecture 2: The CUDA Programming Model
 CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
GPGPU. Lecture 2: CUDA
 GPGPU Lecture 2: CUDA GPU is fast Previous GPGPU Constraints Dealing with graphics API Working with the corner cases of the graphics API Addressing modes Limited texture size/dimension Shader capabilities
GPGPU Lecture 2: CUDA GPU is fast Previous GPGPU Constraints Dealing with graphics API Working with the corner cases of the graphics API Addressing modes Limited texture size/dimension Shader capabilities
GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014
 GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014 Solutions to Parallel Processing Message Passing (distributed) MPI (library) Threads (shared memory) pthreads (library) OpenMP (compiler)
GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014 Solutions to Parallel Processing Message Passing (distributed) MPI (library) Threads (shared memory) pthreads (library) OpenMP (compiler)
Lecture 1: Introduction
 ECE 498AL Applied Parallel Programming Lecture 1: Introduction 1 Course Goals Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability
ECE 498AL Applied Parallel Programming Lecture 1: Introduction 1 Course Goals Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Computation to Core Mapping Lessons learned from a simple application
 Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
Using The CUDA Programming Model
 Using The CUDA Programming Model Leveraging GPUs for Application Acceleration Dan Ernst, Brandon Holt University of Wisconsin Eau Claire 1 What is (Historical) GPGPU? General Purpose computation using
Using The CUDA Programming Model Leveraging GPUs for Application Acceleration Dan Ernst, Brandon Holt University of Wisconsin Eau Claire 1 What is (Historical) GPGPU? General Purpose computation using
Lessons learned from a simple application
 Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Intro to GPU s for Parallel Computing
 Intro to GPU s for Parallel Computing Goals for Rest of Course Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability across future
Intro to GPU s for Parallel Computing Goals for Rest of Course Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability across future
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
CS 677: Parallel Programming for Many-core Processors Lecture 1
 1 CS 677: Parallel Programming for Many-core Processors Lecture 1 Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Objectives Learn how to program
1 CS 677: Parallel Programming for Many-core Processors Lecture 1 Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Objectives Learn how to program
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CSE 591: GPU Programming. Programmer Interface. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Many-core Processors Lecture 1. Instructor: Philippos Mordohai Webpage:
 1 CS 677: Parallel Programming for Many-core Processors Lecture 1 Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Objectives Learn how to program
1 CS 677: Parallel Programming for Many-core Processors Lecture 1 Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Objectives Learn how to program
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
GPU Architecture and Programming. Ozcan Ozturk Bilkent University Ankara, Turkey
 GPU Architecture and Programming Ozcan Ozturk Ankara, Turkey 1 Overview Massively Parallel Processing CPU/GPU Architecture CUDA Programming OpenCL Programming Other Accelerators 2 Overview Massively Parallel
GPU Architecture and Programming Ozcan Ozturk Ankara, Turkey 1 Overview Massively Parallel Processing CPU/GPU Architecture CUDA Programming OpenCL Programming Other Accelerators 2 Overview Massively Parallel
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Core/Many-Core Architectures and Programming. Prof. Huiyang Zhou
 ST: CDA 6938 Multi-Core/Many Core/Many-Core Architectures and Programming http://csl.cs.ucf.edu/courses/cda6938/ Prof. Huiyang Zhou School of Electrical Engineering and Computer Science University of Central
ST: CDA 6938 Multi-Core/Many Core/Many-Core Architectures and Programming http://csl.cs.ucf.edu/courses/cda6938/ Prof. Huiyang Zhou School of Electrical Engineering and Computer Science University of Central
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture 22
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture 22
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
CPUs+GPUs. PCIe: 1GB/s per lane x16 => 16GB/s full duplex. DMI2 20 Gb/s 40x PCIe C L1 L2. 40x PCIe. 2 QPI links 2x 19.2GB/s Full Duplex.
 GPU AND MANYCORE CPUs+GPUs PCH: PCI, SCSI/ SATA, USB, Audio, etc. DMI2 20 Gb/s 40x PCIe C L1 L2 C L1 L2 C L1 L2 C L1 L2 Memory 1A 2A Banks 3A C L1 L2 C L1 L2 L3 Memory Controller 1B 2B 3B x16 1C 2C 3C
GPU AND MANYCORE CPUs+GPUs PCH: PCI, SCSI/ SATA, USB, Audio, etc. DMI2 20 Gb/s 40x PCIe C L1 L2 C L1 L2 C L1 L2 C L1 L2 Memory 1A 2A Banks 3A C L1 L2 C L1 L2 L3 Memory Controller 1B 2B 3B x16 1C 2C 3C
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Nvidia G80 Architecture and CUDA Programming
 Nvidia G80 Architecture and CUDA Programming School of Electrical Engineering and Computer Science CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that:
Nvidia G80 Architecture and CUDA Programming School of Electrical Engineering and Computer Science CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that:
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
High Performance Computing
 GPGPU A Current Trend in High Performance Computing Chokchai Box Leangsuksun, PhD SWEPCO Endowed Professor*, Computer Science Director, High Performance Computing Initiative Louisiana Tech University box@latech.edu
GPGPU A Current Trend in High Performance Computing Chokchai Box Leangsuksun, PhD SWEPCO Endowed Professor*, Computer Science Director, High Performance Computing Initiative Louisiana Tech University box@latech.edu
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
Introduction to GPU (Graphics Processing Unit) Architecture & Programming
 Architecture & Programming") Introduction to GU (Graphics rocessing Unit) Architecture & rogramming C240A. 2017 T. Yang ome of slides are from M. Hall of Utah C6235 Overview Hardware architecture rogramming model Example Historical
Introduction to GU (Graphics rocessing Unit) Architecture & rogramming C240A. 2017 T. Yang ome of slides are from M. Hall of Utah C6235 Overview Hardware architecture rogramming model Example Historical
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Application Acceleration Using the Massive Parallel Processing Power of GPUs
 Application Acceleration Using the Massive Parallel Processing Power of GPUs Shady S. Khalifa Sh.khalfia@fci-cu.edu.eg Faculty of Computers and Information Cairo Agenda Introduction to GPGPU (General Purpose
Application Acceleration Using the Massive Parallel Processing Power of GPUs Shady S. Khalifa Sh.khalfia@fci-cu.edu.eg Faculty of Computers and Information Cairo Agenda Introduction to GPGPU (General Purpose
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
ECE/CS 757: Advanced Computer Architecture II GPGPUs
 ECE/CS 757: Advanced Computer Architecture II GPGPUs Instructor:Mikko H Lipasti Spring 2015 University of Wisconsin-Madison Lecture notes based on slides created by John Shen, Mark Hill, David Wood, Guri
ECE/CS 757: Advanced Computer Architecture II GPGPUs Instructor:Mikko H Lipasti Spring 2015 University of Wisconsin-Madison Lecture notes based on slides created by John Shen, Mark Hill, David Wood, Guri
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
An Example of Physical Reality Behind CUDA. GeForce Speedup of Applications Why Massively Parallel Processor.
 Fall 007 Illinois ECE 498AL1 Programming Massively Parallel Processors Why Massively Parallel Processor A quiet revolution and potential build-up Calculation: 367 GFLOPS vs. 3 GFLOPS Bandwidth: 86.4 GB/s
Fall 007 Illinois ECE 498AL1 Programming Massively Parallel Processors Why Massively Parallel Processor A quiet revolution and potential build-up Calculation: 367 GFLOPS vs. 3 GFLOPS Bandwidth: 86.4 GB/s
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Massively Parallel Computing with CUDA. Carlos Alberto Martínez Angeles Cinvestav-IPN
 Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
CS : Many-core Computing with CUDA
 CS4402-9535: Many-core Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 (Moreno Maza) CS4402-9535: Many-core Computing with CUDA UWO-CS4402-CS9535
CS4402-9535: Many-core Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 (Moreno Maza) CS4402-9535: Many-core Computing with CUDA UWO-CS4402-CS9535
CUDA Parallel Programming Model Michael Garland
 CUDA Parallel Programming Model Michael Garland NVIDIA Research Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of a parallel
CUDA Parallel Programming Model Michael Garland NVIDIA Research Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of a parallel
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Introduction to CUDA (2 of 2)
") Announcements Introduction to CUDA (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Open pull request for Project 0 Project 1 released. Due Sunday 09/30 Not due Tuesday, 09/25 Code
Announcements Introduction to CUDA (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Open pull request for Project 0 Project 1 released. Due Sunday 09/30 Not due Tuesday, 09/25 Code
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
CUDA Parallel Programming Model. Scalable Parallel Programming with CUDA
 CUDA Parallel Programming Model Scalable Parallel Programming with CUDA Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of
CUDA Parallel Programming Model Scalable Parallel Programming with CUDA Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
COMP 322: Fundamentals of Parallel Programming
 COMP 322: Fundamentals of Parallel Programming Lecture 38: General-Purpose GPU (GPGPU) Computing Guest Lecturer: Max Grossman Instructors: Vivek Sarkar, Mack Joyner Department of Computer Science, Rice
COMP 322: Fundamentals of Parallel Programming Lecture 38: General-Purpose GPU (GPGPU) Computing Guest Lecturer: Max Grossman Instructors: Vivek Sarkar, Mack Joyner Department of Computer Science, Rice
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Overview: Graphics Processing Units
 advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Building CUDA apps under Visual Studio Accessing Newton CUDA Programming Model CUDA API February 03, 2011 Dan Negrut, 2011 ME964 UW-Madison
ME964 High Performance Computing for Engineering Applications Building CUDA apps under Visual Studio Accessing Newton CUDA Programming Model CUDA API February 03, 2011 Dan Negrut, 2011 ME964 UW-Madison
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
Blockseminar: Verteiltes Rechnen und Parallelprogrammierung. Tim Conrad
 Blockseminar: Verteiltes Rechnen und Parallelprogrammierung Tim Conrad GPU Computer: CHINA.imp.fu-berlin.de Today Introduction to GPGPUs Hands on to get you started Assignment 3 Projects Traditional Computing
Blockseminar: Verteiltes Rechnen und Parallelprogrammierung Tim Conrad GPU Computer: CHINA.imp.fu-berlin.de Today Introduction to GPGPUs Hands on to get you started Assignment 3 Projects Traditional Computing
CS/EE 217 GPU Architecture and Parallel Programming. Lecture 22: Introduction to OpenCL
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 22: Introduction to OpenCL Objective To Understand the OpenCL programming model basic concepts and data types OpenCL application programming
CS/EE 217 GPU Architecture and Parallel Programming Lecture 22: Introduction to OpenCL Objective To Understand the OpenCL programming model basic concepts and data types OpenCL application programming
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
L18: Introduction to CUDA
 L18: Introduction to CUDA November 5, 2009 Administrative Homework assignment 3 will be posted today (after class) Due, Thursday, November 5 before class - Use the handin program on the CADE machines -
L18: Introduction to CUDA November 5, 2009 Administrative Homework assignment 3 will be posted today (after class) Due, Thursday, November 5 before class - Use the handin program on the CADE machines -
1/25/12. Administrative
 Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Data parallel computing
 Data parallel computing CHAPTER 2 David Luebke CHAPTER OUTLINE 2.1 Data Parallelism...20 2.2 CUDA C Program Structure...22 2.3 A Vector Addition Kernel...25 2.4 Device Global Memory and Data Transfer...27
Data parallel computing CHAPTER 2 David Luebke CHAPTER OUTLINE 2.1 Data Parallelism...20 2.2 CUDA C Program Structure...22 2.3 A Vector Addition Kernel...25 2.4 Device Global Memory and Data Transfer...27
Module 3: CUDA Execution Model -I. Objective
 ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
CSE 591: GPU Programming. Memories. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
GPU. Ben de Waal Summer 2008
 GPU Ben de Waal Summer 2008 Agenda Quick Roadmap A few observations And a few positions 2 GPUs are Great at Graphics Crysis 2006 Crytek / Electronic Arts Hellgate: London 2005-2006 Flagship 3 Studios,
GPU Ben de Waal Summer 2008 Agenda Quick Roadmap A few observations And a few positions 2 GPUs are Great at Graphics Crysis 2006 Crytek / Electronic Arts Hellgate: London 2005-2006 Flagship 3 Studios,