Spring Prof. Hyesoon Kim
|
|
|
- Tamsyn Hill
- 6 years ago
- Views:
Transcription


1 Spring 2011 Prof. Hyesoon Kim
2 2
3 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp Sources ready Sources ready T T T T T T T T One warp One warp Finite number of streaming processors SIMD Execution Unit 3
4 t0 t1 t2 tm SM 0 SM 1 t0 t1 t2 tm MT IU SP MT IU SP Blocks Blocks Shared Memory TF Shared Memory Texture L1 Memory L2 Threads are assigned to SMs in Block granularity Up to 8 Blocks to each SM as resource allows (# of blocks is dependent on the architecture) SM in G80 can take up to 768 threads Could be 256 (threads/block) * 3 blocks Or 128 (threads/block) * 6 blocks, etc. Threads run concurrently SM assigns/maintains thread id #s SM manages/schedules thread execution David Kirk/ NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, UIUC
5 PC PC PCPCPC PC PC Mux I-cache warp #id stall
6 TB1, W1 stall TB2, W1 stall TB3, W2 stall Fetch TB1 W1 TB2 W1 TB3 W1 TB = Thread Block, W = Warp One instruction for each warp (could be further optimizations) Round Robin, Greedy-fetch (switch when stall events such as branch, I-cache misses, buffer full) Thread scheduling polices Execute when all sources are ready TB3 W2 TB2 W1 Instruction: Time In-order execution within warps Scheduling polices: Greedy-execution, round-robin TB1 W1 TB1 W2 TB1 W Kirk & Hwu TB3 W2
7 Enough parallelism Switch to another thread Speculative execution is Branch predictor could be expensive Per thread predictor Branch elimination techniques Pipeline flush is too costly

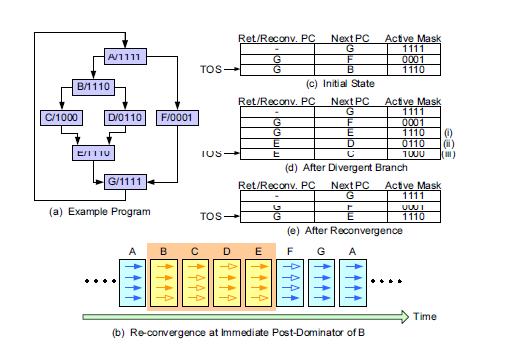
8 Basic Block Def: a sequence of consecutive operations in which flow of control enters at the beginning and leaves at the end without halt or possibility of branching except at the end Single entry, single exit Add r1, r2, r3 Br.cond target Mov r3, r4 Br jmp join Target add r1, r2, r3 Join mov r4 r5 A B C D B A D Control-flow graph C
9 Defn: Dominator Given a CFG, a node x dominates a node y, if every path from the Entry block to y contains x Given some BB, which blocks are guaranteed to have executed prior to executing the BB Defn: Post dominator: Given a CFG, a node x post dominates a node y, if every path from y to the Exit contains x Given some BB, which blocks are guaranteed to have executed after executing the BB reverse of dominator BB2 BB5 BB1 BB3 BB4 BB6 BB7
10 Defn: Immediate post dominator (ipdom) Each node n has a unique immediate post dominator m that is the first post dominator of n on any path from n to the Exit Closest node that post dominates First breadth-first successor that post dominates a node Immediate post dominator is the reconvergence point of divergent branch Entry BB1 BB2 BB3 BB4 BB5 BB6 BB7 Exit
11 Recap: 32 threads in a warm are executed in SIMD (share one instruction sequencer) Threads within a warp can be disabled (masked) For example, handling bank conflicts Threads contain arbitrary code including conditional branches How do we handle different conditions in different threads? No problem if the threads are in different warps Control divergence Predication
12 Predication Loop unrolling
13 if (cond) { b = 0; } else { b = 1; C (normal branch code) T C A D mov b, 1 jmp JOIN TARGET: mov b, 0 N B (predicated code) } A p1 = (cond) branch p1, TARGET A p1 = (cond) B B Convert control flow dependency to data dependency Pro: Eliminate hard-to-predict branches (in traditional architecture) Eliminate branch divergence (in CUDA) Cons: Extra instructions C A B C D (!p1) mov b, 1 (p1) mov b, 0
14 Comparison instructions set condition codes (CC) Instructions can be predicated to write results only when CC meets criterion (CC!= 0, CC >= 0, etc.) Compiler tries to predict if a branch condition is likely to produce many divergent warps If guaranteed not to diverge: only predicates if < 4 instructions If not guaranteed: only predicates if < 7 instructions May replace branches with instruction predication ALL predicated instructions take execution cycles Those with false conditions don t write their output Or invoke memory loads and stores Saves branch instructions, so can be cheaper than serializing divergent paths David Kirk/ NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, UIUC
15 Transforms an M-iteration loop into a loop with M/N iterations We say that the loop has been unrolled N times for(i=0;i<100;i+=4){ for(i=0;i<100;i++) a[i]*=2; } a[i]*=2; a[i+1]*=2; a[i+2]*=2; a[i+3]*=2;
16 Sum { 1-100}, How to calculate?
17 Reduction example If (threadid.x%==2) If (threadid.x%==4) If (threadid.x%==8) What about other threads? What about different paths? B A D C If (threadid.x>2) { do work B} else { do work C } Divergent branch! From Fung et al. MICRO 07
18 All branch conditions are serialized and will be executed Parallel code sequential code Divergence occurs within a warp granularity. It s a performance issue Degree of nested branches Depending on memory instructions, (cache hits or misses), divergent warps can occur Dynamic warp subdivision [Meng 10] Hardware solutions to reduce divergent branches Dynamic warp formation [Fung 07]
19
20 Register File (RF) 32 KB Provides 4 operands/clock TEX pipe can also read/write RF 2 SMs share 1 TEX Load/Store pipe can also read/write RF I$ L1 Multithreaded Instruction Buffer R F C$ L1 Operand Select Shared Mem MAD SFU David Kirk/ NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, UIUC
21 R1 R2 R1 R2 R3 Read write Read write R4 R3 R4 write Read write Read write1 Read4 Read3 Read2 Read1 Multiple read ports Banks
22 t0 t1 t2 tm SM 0 SM 1 t0 t1 t2 tm MT IU SP MT IU SP Blocks Blocks Shared Memory TF Courtesy: John Nicols, NVIDIA Shared Memory Texture L1 L2 Threads in a Block share data & results In Memory and Shared Memory Synchronize at barrier instruction Per-Block Shared Memory Allocation Keeps data close to processor Minimize trips to global Memory SM Shared Memory dynamically allocated to Blocks, one of the limiting resources Memory David Kirk/ NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, UIUC
23 Immediate address constants Indexed address constants Constants stored in DRAM, and cached on chip L1 per SM A constant value can be broadcast to all threads in a Warp Extremely efficient way of accessing a value that is common for all threads in a Block! Can reduce the number of registers. I$ L1 Multithreaded Instruction Buffer R F C$ L1 Operand Select MAD Shared Mem SFU David Kirk/ NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, UIUC
24 Textures are 1D,2D, 3D arrays of values stored in global DRAM Textures are cached in L1 and L2 Read-only access Caches are optimized for 2D access: Threads in a warp that follow 2D locality will achieve better memory performance Texels: elements of the arrays, texture elements
25 Designed to map textures onto 3D polygons Specialty hardware pipelines for: Fast data sampling from 1D, 2D, 3D arrays Swizzling of 2D, 3D data for optimal access Bilinear filtering in zero cycles Image compositing & blending operations Arrays indexed by u,v,w coordinates easy to program Extremely well suited for multigrid & finite difference methods
26 MSHR MSHR MSHR Many levels of queues Large size of queues High number of DRAM banks Sensitive to memory scheduling algorithms FRFCFS >> FCFS Interconnection network algorithm to get FRFCFS Effects Yan 09,
27 In-order execution but Warp cannot execute an instruction when sources are dependent on memory instructions, not when it generates memory requests High MLP Memory Request Memory Request Memory Request Memory Request W0 W1 C M C C M D Context Switch C M C C M D

28 High Merging Effects Inter-core merging Intra-core merging MSHR MSHR MSHR Techniques to take advantages of this SDMT Compiler optimization[yang 10]: increase memory reuse Cache coherence [Tarjan 10] Cache increase reuses
29 No Bank Conflicts Linear addressing stride == 1 No Bank Conflicts Random 1:1 Permutation Thread 0 Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Thread 6 Thread 7 Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 Thread 0 Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Thread 6 Thread 7 Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 Thread 15 Bank 15 Thread 15 Bank 15 David Kirk/ NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, UIUC
30 This has no conflicts if type of shared is 32-bits: foo = shared[baseindex + threadidx.x] But not if the data type is smaller 4-way bank conflicts: shared char shared[]; foo = shared[baseindex + threadidx.x]; Thread 0 Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Thread 6 Thread 7 Thread 15 Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 Bank 15 2-way bank conflicts: shared short shared[]; foo = shared[baseindex + threadidx.x]; Thread 0 Thread 1 Thread 2 Thread 3 Thread 4 Thread 5 Thread 6 Thread 7 Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 David Kirk/ NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, UIUC Thread 15 Bank 15
![Bulk-Synchronous Parallel (BSP) program (Valiant [90])](/docs-images/76/73510870/images/31-1.jpg "Synchronization within blocks using explicit Kernel1 Block barrier")

31 Bulk-Synchronous Parallel (BSP) program (Valiant [90]) Synchronization within blocks using explicit Kernel1 Block barrier Implicit barrier across kernels Kernel 1 Kernel 2 C.f.) Cuda 3.x Kernel2 Block Block barrier barrier Block Barrier Block barrier barrier barrier barrier
32 Use multiple kernels Write to same memory addresses Behavior is not guaranteed Data race Atomic operation No other threads can write to the same location Memory Write order is still arbitrary Keep being updated: atomic{add, Sub, Exch, Min, Max, Inc, Dec, CAS, And, Or, Xor} Performance degradation Fermi increases atomic performance by 5x to 20x (M. Shebanow)
33 White paper, NVIDIA s Next Generation, CUDA Compute Architecture Fermi White paper: World s Fastest GPU Delivering Great Gaming Performance with True Geometric Realism
34 SM 32 CUDA cores per SM (fully 32-lane) Dual Warp Scheduler and dispatches from two independent warps 64KB of RAM with a configurable partitioning of shared memory and L1 cache Programming support Unified Address Space with Full C++ Support Full 32-bit integer path with 64-bit extensions Memory access instructions to support transition to 64-bit addressing Memory system Data cache, ECC support, Atomic memory operations Concurrent kernel execution

35 Better integer support 4 SFU Dual warp scheduler More TLP 16 cores are executed together
36
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Branches are very frequent Approx. 20% of all instructions Can not wait until we know where it goes Long pipelines Branch outcome known after B cycles No scheduling past the
Spring 2009 Prof. Hyesoon Kim Branches are very frequent Approx. 20% of all instructions Can not wait until we know where it goes Long pipelines Branch outcome known after B cycles No scheduling past the
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Lecture 6. Programming with Message Passing Message Passing Interface (MPI)
") Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Active thread Idle thread
 Active thread Idle thread") Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CE 431 Parallel Computer Architecture Spring Graphics Processor Units (GPU) Architecture
 Architecture") CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
NVIDIA Fermi Architecture
 Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
L17: CUDA, cont. 11/3/10. Final Project Purpose: October 28, Next Wednesday, November 3. Example Projects
 L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
Lecture 9. Thread Divergence Scheduling Instruction Level Parallelism
 Lecture 9 Thread Divergence Scheduling Instruction Level Parallelism Announcements Tuesday s lecture on 2/11 will be moved to room 4140 from 6.30 PM to 7.50 PM Office hours cancelled on Thursday; make
Lecture 9 Thread Divergence Scheduling Instruction Level Parallelism Announcements Tuesday s lecture on 2/11 will be moved to room 4140 from 6.30 PM to 7.50 PM Office hours cancelled on Thursday; make
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Occupancy-based compilation
 Occupancy-based compilation Advanced Course on Compilers Spring 2015 (III-V): Lecture 10 Vesa Hirvisalo ESG/CSE/Aalto Today Threads and occupancy GPUs as the example SIMT execution warp (thread-group)
Occupancy-based compilation Advanced Course on Compilers Spring 2015 (III-V): Lecture 10 Vesa Hirvisalo ESG/CSE/Aalto Today Threads and occupancy GPUs as the example SIMT execution warp (thread-group)
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
L14: CUDA, cont. Execution Model and Memory Hierarchy"
 Programming Assignment 3, Due 11:59PM Nov. 7 L14: CUDA, cont. Execution Model and Hierarchy" October 27, 2011! Purpose: - Synthesize the concepts you have learned so far - Data parallelism, locality and
Programming Assignment 3, Due 11:59PM Nov. 7 L14: CUDA, cont. Execution Model and Hierarchy" October 27, 2011! Purpose: - Synthesize the concepts you have learned so far - Data parallelism, locality and
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
1/19/11. Administrative. L2: Hardware Execution Model and Overview. What is an Execution Model? Parallel programming model. Outline.
 L2: Hardware Execution Model and Overview January 19, 2011 Administrative First assignment out, due Friday at 5PM Use handin on CADE machines to submit handin cs6963 lab1 The file
L2: Hardware Execution Model and Overview January 19, 2011 Administrative First assignment out, due Friday at 5PM Use handin on CADE machines to submit handin cs6963 lab1 The file
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
CS 179: GPU Computing. Recitation 2: Synchronization, Shared memory, Matrix Transpose
 CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2)
") 1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
Administrative. L8: Writing Correct Programs, cont. and Control Flow. Questions/comments from previous lectures. Outline 2/10/11
 Administrative L8 Writing Correct Programs, cont. and Control Flow Next assignment available Goals of assignment simple memory hierarchy management block-thread decomposition tradeoff Due Thursday, Feb.
Administrative L8 Writing Correct Programs, cont. and Control Flow Next assignment available Goals of assignment simple memory hierarchy management block-thread decomposition tradeoff Due Thursday, Feb.
Register File Organization
 Register File Organization Sudhakar Yalamanchili unless otherwise noted (1) To understand the organization of large register files used in GPUs Objective Identify the performance bottlenecks and opportunities
Register File Organization Sudhakar Yalamanchili unless otherwise noted (1) To understand the organization of large register files used in GPUs Objective Identify the performance bottlenecks and opportunities
Spring 2010 Prof. Hyesoon Kim. Xbox 360 System Architecture, Anderews, Baker
 Spring 2010 Prof. Hyesoon Kim Xbox 360 System Architecture, Anderews, Baker 3 CPU cores 4-way SIMD vector units 8-way 1MB L2 cache (3.2 GHz) 2 way SMT 48 unified shaders 3D graphics units 512-Mbyte DRAM
Spring 2010 Prof. Hyesoon Kim Xbox 360 System Architecture, Anderews, Baker 3 CPU cores 4-way SIMD vector units 8-way 1MB L2 cache (3.2 GHz) 2 way SMT 48 unified shaders 3D graphics units 512-Mbyte DRAM
Portland State University ECE 588/688. Cray-1 and Cray T3E
 Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Analyzing CUDA Workloads Using a Detailed GPU Simulator
 CS 3580 - Advanced Topics in Parallel Computing Analyzing CUDA Workloads Using a Detailed GPU Simulator Mohammad Hasanzadeh Mofrad University of Pittsburgh November 14, 2017 1 Article information Title:
CS 3580 - Advanced Topics in Parallel Computing Analyzing CUDA Workloads Using a Detailed GPU Simulator Mohammad Hasanzadeh Mofrad University of Pittsburgh November 14, 2017 1 Article information Title:
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Arquitetura e Organização de Computadores 2
 Arquitetura e Organização de Computadores 2 Paralelismo em Nível de Dados Graphical Processing Units - GPUs Graphical Processing Units Given the hardware invested to do graphics well, how can be supplement
Arquitetura e Organização de Computadores 2 Paralelismo em Nível de Dados Graphical Processing Units - GPUs Graphical Processing Units Given the hardware invested to do graphics well, how can be supplement
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA
 Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
From Application to Technology OpenCL Application Processors Chung-Ho Chen
 From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
GPU ARCHITECTURE Chris Schultz, June 2017
 Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
Overview: Graphics Processing Units
 advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Advanced CUDA Programming. Dr. Timo Stich
 Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
The Graphics Pipeline: Evolution of the GPU!
 1 Today The Graphics Pipeline: Evolution of the GPU! Bigger picture: Parallel processor designs! Throughput-optimized (GPU-like)! Latency-optimized (Multicore CPU-like)! A look at NVIDIA s Fermi GPU architecture!
1 Today The Graphics Pipeline: Evolution of the GPU! Bigger picture: Parallel processor designs! Throughput-optimized (GPU-like)! Latency-optimized (Multicore CPU-like)! A look at NVIDIA s Fermi GPU architecture!
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS Spring 2012
 Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS Spring 2012") CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Agenda Instruction Optimizations Mixed Instruction Types Loop Unrolling
CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Agenda Instruction Optimizations Mixed Instruction Types Loop Unrolling
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
18-447: Computer Architecture Lecture 25: Main Memory. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013
 18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
18-447: Computer Architecture Lecture 25: Main Memory Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/3/2013 Reminder: Homework 5 (Today) Due April 3 (Wednesday!) Topics: Vector processing,
" # " $ % & ' ( ) * + $ " % '* + * ' "
 * + $ % '* + * '") ! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
Performance optimization with CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
CMU Introduction to Computer Architecture, Spring Midterm Exam 2. Date: Wed., 4/17. Legibility & Name (5 Points): Problem 1 (90 Points):
: Problem 1 (90 Points):") Name: CMU 18-447 Introduction to Computer Architecture, Spring 2013 Midterm Exam 2 Instructions: Date: Wed., 4/17 Legibility & Name (5 Points): Problem 1 (90 Points): Problem 2 (35 Points): Problem 3 (35
Name: CMU 18-447 Introduction to Computer Architecture, Spring 2013 Midterm Exam 2 Instructions: Date: Wed., 4/17 Legibility & Name (5 Points): Problem 1 (90 Points): Problem 2 (35 Points): Problem 3 (35
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION
 April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION. Julien Demouth, NVIDIA Cliff Woolley, NVIDIA
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Layout in CUDA Execution Scheduling in CUDA February 15, 2011 Dan Negrut, 2011 ME964 UW-Madison They have computers, and they may have
ME964 High Performance Computing for Engineering Applications Memory Layout in CUDA Execution Scheduling in CUDA February 15, 2011 Dan Negrut, 2011 ME964 UW-Madison They have computers, and they may have
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
LRU. Pseudo LRU A B C D E F G H A B C D E F G H H H C. Copyright 2012, Elsevier Inc. All rights reserved.
 LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME
 CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME 1 Last time... GPU Memory System Different kinds of memory pools, caches, etc Different optimization techniques 2 Warp Schedulers
CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME 1 Last time... GPU Memory System Different kinds of memory pools, caches, etc Different optimization techniques 2 Warp Schedulers
An Example of Physical Reality Behind CUDA. GeForce Speedup of Applications Why Massively Parallel Processor.
 Fall 007 Illinois ECE 498AL1 Programming Massively Parallel Processors Why Massively Parallel Processor A quiet revolution and potential build-up Calculation: 367 GFLOPS vs. 3 GFLOPS Bandwidth: 86.4 GB/s
Fall 007 Illinois ECE 498AL1 Programming Massively Parallel Processors Why Massively Parallel Processor A quiet revolution and potential build-up Calculation: 367 GFLOPS vs. 3 GFLOPS Bandwidth: 86.4 GB/s