Our new HPC-Cluster An overview
|
|
|
- Egbert Horton
- 6 years ago
- Views:
Transcription
1 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg,
2 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
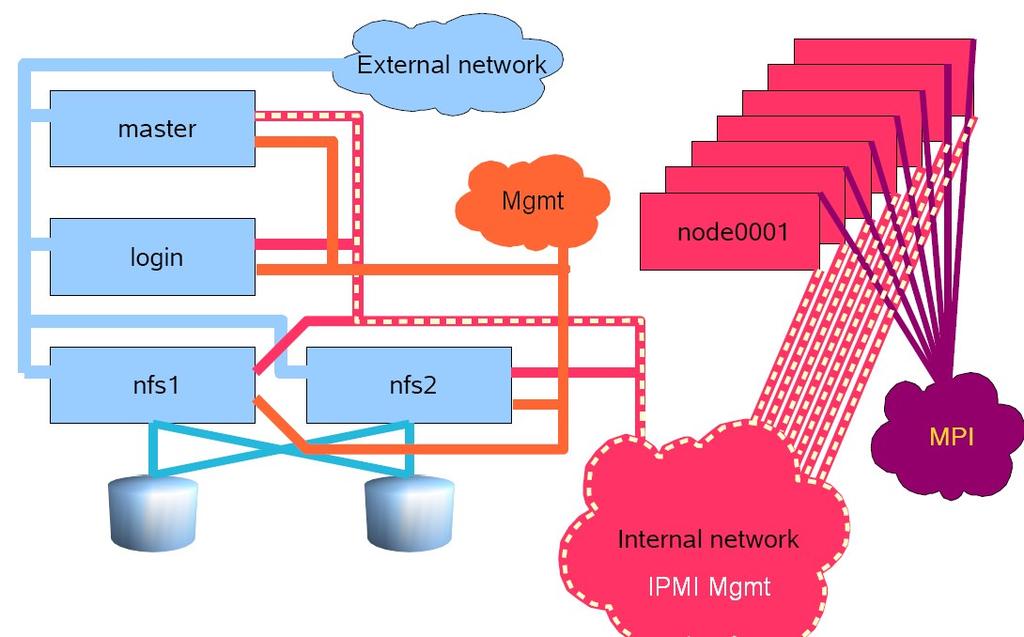
3 Layout
4 Hardware overview Compute Nodes: 187 per node: 2 Quad-Core AMD Opteron 2345 (Barcelona) 2.2GHz most nodes have 16GB + some with 32GB 250GB local disc space Communication: 176 nodes with Infiniband, others with GE Storage: 2 fileservers (NFS) in fail-over mode, 64TB storage capacity Performance(Infiniband nodes only): 12.3 TFlops peak, 8.95 TFlops with LIN- PACK
5 Storage Current partitioning of storage: /home 1 TB quota (2GB, 10k files), incr. backup /data 8 TB no quota, no backup, long term storage /scratch1 8 TB no quota, no backup, short term storage /scratch2 8 TB no quota, no backup, short term storage + special project partitions (10 TB) + another 29 TB in reserve long term = some months 1 year short term = 1 run 1 week In addition, ordinary Linux-HOME is a available on login node in /lhome/dau12345
6 Software Compilers: Intel Compiler v10.0 and v11.0 GNU Compiler v4.1.2 GNU Compiler v4.3.3 (soon) MPI implementations: Intel MPI OpenMPI MVAPICH2 Parastation Math. libraries: Math Kernel Library (MKL) atlas GNU Scientific Library (GSL) PETSc
7 Getting an account First, fill out the form which you can find on the page of the Rechenzentrum. Required information are: Titel of project Description of the project Memory requirements and storage requirements (long and short term) Average runtime of jobs Maximum number of cores used simultaneously Job types: parallel and/or serial Programming languages: Fortran, C, C++, Java Compiler: GNU, Intel Libraries: MKL, atlas, blas PETSc After submitting, printing, signing and returning it to the Rechenzentrum, you get an account. Login: > ssh
8 Modules The compilers and MPI-libraries are packed in different modules. module avail module load impi-gcc module list module unload impi-gcc Available modules: lists all available modules loads a module (here, impi-gcc) lists loaded modules unloads the module impi-gcc impi-gcc mvapich2-gcc openmpi-gcc parastation-gcc impi-intel mvapich2-intel openmpi-intel parastation-intel intel-10.0-icc intel-10.0-ifort intel-11.0
9 Math. libraries Math Kernel Library (MKL): To set the environment variables: source /opt/intel/mkl/ /tools/environment/mklvarsem64t.sh Then add the following libraries for linking. For GNU compiler: -lmkl gf lp64 -lmkl gnu thread -lmkl core -lpthread -lm For Intel compiler: -lmkl intel lp64 -lmkl sequential -lmkl core -lpthread ATLAS: The ATLAS library is located in: /opt/lapack/atlas-3.8.2/lib
10 Queueing system Torque queueing system with Maui scheduler in Fair-Share mode List of queues: common Max. # of nodes = 32 Max. walltime = 48h Max. # number of jobs per user = 10 running + 50 in queue common32 (for 32GB nodes) Max. # of nodes = 16 Max. walltime = 48h Max. # number of jobs per user = 10 in total serial parallel special project queues
11 Submit jobs Interactive jobs: athene1> qsub -I -l nodes=4:ppn=8 -l walltime=12:00:00 -l mem=12gb node001> mpiexec -n 32./my mpi job node001> exit Batch jobs: qsub jobscript qstat [[-f] job id] [-u username] qdel [job id] qalter...[-l resource list]... job id more info in the man pages
12 Queueing system Example script: #!/bin/bash #PBS -o myjob.out #PBS -j oe #PBS -S /bin/bash #PBS -l nodes=4:ppn=8 #PBS -l walltime=12:00:00 #PBS -l mem=12gb cd ${PBS O WORKDIR} mpiexec -n 32./my mpi job specify file for stdout join stdout and stderr specify shell specify # of nodes and processors specify runtime specify required memory change to submit directory

13 pbstop Place a file.pbstoprc in your home directory containing: host=athene2 columns=8 maxnodegrid=8 show cpu=0,1,2,3,4,5,6,7
14 MPI - Message Passing Interface Characteristics: Standardized distributed memory parallelism with message passing Process-based Each process has its own set of local variables Data is copied between local memories with messages that are sent and received via explicit calls to MPI routines (MPI Init, MPI Send, MPI Recv, MPI Gather, MPI Scatter, MPI Reduce,..., MPI Finalize) Detailed information for all routines together with small example programs can be found in the MPI Standard (Online on or in physics library 84/ST 230 M583)
15 MPI - Pros and Cons Pros: Runs on both shared and distributed memory architectures Portable. Exists on almost all systems Very flexible. Thus can be used to a wide range of problems Very scalable programs (depending on the algorithm) Explicit parallelism better performance Communication and computation can in principle overlap Cons: Requires more programming changes to go from serial to parallel version Can be hard to debug Complicates profiling and optimization Performance is limited by the communication between the processes
16 Hello World - MPI hello world mpi.c: #include <stdio.h> #include <stdlib.h> #include <mpi.h> int main (int argc, char **argv) { int rank, size; MPI Init (&argc, &argv); /* starts MPI */ MPI Comm rank (MPI COMM WORLD, &rank); /* get current process id */ MPI Comm size (MPI COMM WORLD, &size); /* get number of processes */ printf ( "Hello world from process %d of %d\n.", rank, size); MPI Finalize (); return EXIT SUCCESS } Compiling and running the code: > mpicc hello world mpi.c > mpiexec -n 2./a.out Hello world from process 0 of 2. Hello world from process 1 of 2.
17 OpenMP Characteristics: Standardized shared memory parallelism Thread-based Each thread sees same global memory and a set of local variables Mainly loop-parallelism via OpenMP-directives (e.g., OMP PARALLEL DO) Compiler translates OpenMP directives into thread-handling (Intel: -openmp, GNU: -fopenmp) The latest official OpenMP specifications can be found on Also contains a number of examples.
18 OpenMP - Pros and Cons Pros: Easier to program and to debug than MPI Directives can be added incrementally gradual parallelization Can still run the program as a serial code Serial code doesn t have to be changed significantly Code easier to understand easier to maintain Becomes more and more important (Many-Core processors) Implicit messaging Cons: Can only be run on shared memory architectures Requires compiler that supports OpenMP Mostly used for loop parallelization Overhead is an issue if loop is too small Threads are executed in a nondeterministic order Explicit synchronization is required
19 Hello world - OpenMP hello world openmp.c: #include <omp.h> #include <stdio.h> int main (int argc, char *argv[]) { int th id, nthreads; #pragma omp parallel private(th id) /* start a threaded block, each thread gets its own th id*/ { th id = omp get thread num(); /* get thread number */ printf("hello World from thread %d\n.", th id); #pragma omp barrier /* wait until all threads finished printing */ if ( th id == 0 ) { /* only thread 0 */ nthreads = omp get num threads(); /* get number of threads */ printf("there are %d threads\n.",nthreads); /* and print it */ } } return 0; } Compiling and running the code: > icc -openmp hello world openmp.c >./a.out Hello World from thread 1. Hello World from thread 0. There are 2 threads.
20 Hybrid MPI + OpenMP Why hybrid: Most modern HPC systems are clusters of SMP nodes. Elegant in concept and architecture: Using MPI on node interconnect and OpenMP within each SMP node. Good usage of shared memory system resources (memory, latency, bandwidth). Avoids the extra communication overhead with MPI within node. OpenMP allows increased and/or dynamic load balancing. Reduction of replicated data on MPI level (Volume/node > Volume/core) Significantly reduces the number of MPI processes OpenMP threading makes each process faster, even when code is already Amdahl-limited
Practical Introduction to Message-Passing Interface (MPI)
") 1 Outline of the workshop 2 Practical Introduction to Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your
1 Outline of the workshop 2 Practical Introduction to Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your
Cluster Clonetroop: HowTo 2014
 2014/02/25 16:53 1/13 Cluster Clonetroop: HowTo 2014 Cluster Clonetroop: HowTo 2014 This section contains information about how to access, compile and execute jobs on Clonetroop, Laboratori de Càlcul Numeric's
2014/02/25 16:53 1/13 Cluster Clonetroop: HowTo 2014 Cluster Clonetroop: HowTo 2014 This section contains information about how to access, compile and execute jobs on Clonetroop, Laboratori de Càlcul Numeric's
Computing with the Moore Cluster
 Computing with the Moore Cluster Edward Walter An overview of data management and job processing in the Moore compute cluster. Overview Getting access to the cluster Data management Submitting jobs (MPI
Computing with the Moore Cluster Edward Walter An overview of data management and job processing in the Moore compute cluster. Overview Getting access to the cluster Data management Submitting jobs (MPI
Tech Computer Center Documentation
 Tech Computer Center Documentation Release 0 TCC Doc February 17, 2014 Contents 1 TCC s User Documentation 1 1.1 TCC SGI Altix ICE Cluster User s Guide................................ 1 i ii CHAPTER 1
Tech Computer Center Documentation Release 0 TCC Doc February 17, 2014 Contents 1 TCC s User Documentation 1 1.1 TCC SGI Altix ICE Cluster User s Guide................................ 1 i ii CHAPTER 1
Advanced Message-Passing Interface (MPI)
") Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Effective Use of CCV Resources
 Effective Use of CCV Resources Mark Howison User Services & Support This talk... Assumes you have some familiarity with a Unix shell Provides examples and best practices for typical usage of CCV systems
Effective Use of CCV Resources Mark Howison User Services & Support This talk... Assumes you have some familiarity with a Unix shell Provides examples and best practices for typical usage of CCV systems
Lecture 4: OpenMP Open Multi-Processing
 CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
Getting started with the CEES Grid
 Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
Parallel Computing: Overview
 Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
Introduction to PICO Parallel & Production Enviroment
 Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
OBTAINING AN ACCOUNT:
 HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
ACEnet for CS6702 Ross Dickson, Computational Research Consultant 29 Sep 2009
 ACEnet for CS6702 Ross Dickson, Computational Research Consultant 29 Sep 2009 What is ACEnet? Shared resource......for research computing... physics, chemistry, oceanography, biology, math, engineering,
ACEnet for CS6702 Ross Dickson, Computational Research Consultant 29 Sep 2009 What is ACEnet? Shared resource......for research computing... physics, chemistry, oceanography, biology, math, engineering,
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Alessandro Grottesi a.grottesi@cineca.it SuperComputing Applications and
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
Introduction to GALILEO
 November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
November 27, 2016 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it SuperComputing Applications and Innovation Department
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
OpenMPand the PGAS Model. CMSC714 Sept 15, 2015 Guest Lecturer: Ray Chen
 OpenMPand the PGAS Model CMSC714 Sept 15, 2015 Guest Lecturer: Ray Chen LastTime: Message Passing Natural model for distributed-memory systems Remote ( far ) memory must be retrieved before use Programmer
OpenMPand the PGAS Model CMSC714 Sept 15, 2015 Guest Lecturer: Ray Chen LastTime: Message Passing Natural model for distributed-memory systems Remote ( far ) memory must be retrieved before use Programmer
How to run applications on Aziz supercomputer. Mohammad Rafi System Administrator Fujitsu Technology Solutions
 How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
How to run applications on Aziz supercomputer Mohammad Rafi System Administrator Fujitsu Technology Solutions Agenda Overview Compute Nodes Storage Infrastructure Servers Cluster Stack Environment Modules
Hybrid MPI/OpenMP parallelization. Recall: MPI uses processes for parallelism. Each process has its own, separate address space.
 Hybrid MPI/OpenMP parallelization Recall: MPI uses processes for parallelism. Each process has its own, separate address space. Thread parallelism (such as OpenMP or Pthreads) can provide additional parallelism
Hybrid MPI/OpenMP parallelization Recall: MPI uses processes for parallelism. Each process has its own, separate address space. Thread parallelism (such as OpenMP or Pthreads) can provide additional parallelism
Genius Quick Start Guide
 Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
Genius Quick Start Guide Overview of the system Genius consists of a total of 116 nodes with 2 Skylake Xeon Gold 6140 processors. Each with 18 cores, at least 192GB of memory and 800 GB of local SSD disk.
Simple examples how to run MPI program via PBS on Taurus HPC
 Simple examples how to run MPI program via PBS on Taurus HPC MPI setup There's a number of MPI implementations install on the cluster. You can list them all issuing the following command: module avail/load/list/unload
Simple examples how to run MPI program via PBS on Taurus HPC MPI setup There's a number of MPI implementations install on the cluster. You can list them all issuing the following command: module avail/load/list/unload
Practical Introduction to
 1 2 Outline of the workshop Practical Introduction to What is ScaleMP? When do we need it? How do we run codes on the ScaleMP node on the ScaleMP Guillimin cluster? How to run programs efficiently on ScaleMP?
1 2 Outline of the workshop Practical Introduction to What is ScaleMP? When do we need it? How do we run codes on the ScaleMP node on the ScaleMP Guillimin cluster? How to run programs efficiently on ScaleMP?
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Practical Introduction to Message-Passing Interface (MPI)
") 1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
JURECA Tuning for the platform
 JURECA Tuning for the platform Usage of ParaStation MPI 2017-11-23 Outline ParaStation MPI Compiling your program Running your program Tuning parameters Resources 2 ParaStation MPI Based on MPICH (3.2)
JURECA Tuning for the platform Usage of ParaStation MPI 2017-11-23 Outline ParaStation MPI Compiling your program Running your program Tuning parameters Resources 2 ParaStation MPI Based on MPICH (3.2)
Shared Memory programming paradigm: openmp
 IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
Introduction to HPC2N
 Introduction to HPC2N Birgitte Brydsø HPC2N, Umeå University 4 May 2017 1 / 24 Overview Kebnekaise and Abisko Using our systems The File System The Module System Overview Compiler Tool Chains Examples
Introduction to HPC2N Birgitte Brydsø HPC2N, Umeå University 4 May 2017 1 / 24 Overview Kebnekaise and Abisko Using our systems The File System The Module System Overview Compiler Tool Chains Examples
Scientific Programming in C XIV. Parallel programming
 Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
User Guide of High Performance Computing Cluster in School of Physics
 User Guide of High Performance Computing Cluster in School of Physics Prepared by Sue Yang (xue.yang@sydney.edu.au) This document aims at helping users to quickly log into the cluster, set up the software
User Guide of High Performance Computing Cluster in School of Physics Prepared by Sue Yang (xue.yang@sydney.edu.au) This document aims at helping users to quickly log into the cluster, set up the software
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Parallele Numerik. Blatt 1
 Universität Konstanz FB Mathematik & Statistik Prof. Dr. M. Junk Dr. Z. Yang Ausgabe: 02. Mai; SS08 Parallele Numerik Blatt 1 As a first step, we consider two basic problems. Hints for the realization
Universität Konstanz FB Mathematik & Statistik Prof. Dr. M. Junk Dr. Z. Yang Ausgabe: 02. Mai; SS08 Parallele Numerik Blatt 1 As a first step, we consider two basic problems. Hints for the realization
Introduction to the SHARCNET Environment May-25 Pre-(summer)school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology
school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology") Introduction to the SHARCNET Environment 2010-May-25 Pre-(summer)school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology available hardware and software resources our web portal
Introduction to the SHARCNET Environment 2010-May-25 Pre-(summer)school webinar Speaker: Alex Razoumov University of Ontario Institute of Technology available hardware and software resources our web portal
Lab: Scientific Computing Tsunami-Simulation
 Lab: Scientific Computing Tsunami-Simulation Session 4: Optimization and OMP Sebastian Rettenberger, Michael Bader 23.11.15 Session 4: Optimization and OMP, 23.11.15 1 Department of Informatics V Linux-Cluster
Lab: Scientific Computing Tsunami-Simulation Session 4: Optimization and OMP Sebastian Rettenberger, Michael Bader 23.11.15 Session 4: Optimization and OMP, 23.11.15 1 Department of Informatics V Linux-Cluster
30 Nov Dec Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy
 Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Introduction to HPC2N
 Introduction to HPC2N Birgitte Brydsø, Jerry Eriksson, and Pedro Ojeda-May HPC2N, Umeå University 12 September 2017 1 / 38 Overview Kebnekaise and Abisko Using our systems The File System The Module System
Introduction to HPC2N Birgitte Brydsø, Jerry Eriksson, and Pedro Ojeda-May HPC2N, Umeå University 12 September 2017 1 / 38 Overview Kebnekaise and Abisko Using our systems The File System The Module System
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Lecture 14: Mixed MPI-OpenMP programming. Lecture 14: Mixed MPI-OpenMP programming p. 1
 Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
INTRODUCTION TO OPENMP
 INTRODUCTION TO OPENMP Hossein Pourreza hossein.pourreza@umanitoba.ca February 25, 2016 Acknowledgement: Examples used in this presentation are courtesy of SciNet. What is High Performance Computing (HPC)
INTRODUCTION TO OPENMP Hossein Pourreza hossein.pourreza@umanitoba.ca February 25, 2016 Acknowledgement: Examples used in this presentation are courtesy of SciNet. What is High Performance Computing (HPC)
Hybrid MPI and OpenMP Parallel Programming
 Hybrid MPI and OpenMP Parallel Programming Jemmy Hu SHARCNET HPTC Consultant July 8, 2015 Objectives difference between message passing and shared memory models (MPI, OpenMP) why or why not hybrid? a common
Hybrid MPI and OpenMP Parallel Programming Jemmy Hu SHARCNET HPTC Consultant July 8, 2015 Objectives difference between message passing and shared memory models (MPI, OpenMP) why or why not hybrid? a common
MPI introduction - exercises -
 MPI introduction - exercises - Paolo Ramieri, Maurizio Cremonesi May 2016 Startup notes Access the server and go on scratch partition: ssh a08tra49@login.galileo.cineca.it cd $CINECA_SCRATCH Create a job
MPI introduction - exercises - Paolo Ramieri, Maurizio Cremonesi May 2016 Startup notes Access the server and go on scratch partition: ssh a08tra49@login.galileo.cineca.it cd $CINECA_SCRATCH Create a job
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing
 Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Introduction to CINECA HPC Environment
 Introduction to CINECA HPC Environment 23nd Summer School on Parallel Computing 19-30 May 2014 m.cestari@cineca.it, i.baccarelli@cineca.it Goals You will learn: The basic overview of CINECA HPC systems
Introduction to CINECA HPC Environment 23nd Summer School on Parallel Computing 19-30 May 2014 m.cestari@cineca.it, i.baccarelli@cineca.it Goals You will learn: The basic overview of CINECA HPC systems
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Compilation and Parallel Start
 Compiling MPI Programs Programming with MPI Compiling and running MPI programs Type to enter text Jan Thorbecke Delft University of Technology 2 Challenge the future Compiling and Starting MPI Jobs Compiling:
Compiling MPI Programs Programming with MPI Compiling and running MPI programs Type to enter text Jan Thorbecke Delft University of Technology 2 Challenge the future Compiling and Starting MPI Jobs Compiling:
ISTeC Cray High Performance Computing System User s Guide Version 5.0 Updated 05/22/15
 ISTeC Cray High Performance Computing System User s Guide Version 5.0 Updated 05/22/15 Contents Purpose and Audience for this Document... 3 System Architecture... 3 Website... 5 Accounts... 5 Access...
ISTeC Cray High Performance Computing System User s Guide Version 5.0 Updated 05/22/15 Contents Purpose and Audience for this Document... 3 System Architecture... 3 Website... 5 Accounts... 5 Access...
Tutorial: parallel coding MPI
 Tutorial: parallel coding MPI Pascal Viot September 12, 2018 Pascal Viot Tutorial: parallel coding MPI September 12, 2018 1 / 24 Generalities The individual power of a processor is still growing, but at
Tutorial: parallel coding MPI Pascal Viot September 12, 2018 Pascal Viot Tutorial: parallel coding MPI September 12, 2018 1 / 24 Generalities The individual power of a processor is still growing, but at
Introduction to High Performance Computing (HPC) Resources at GACRC
 Resources at GACRC") Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu 1 Outline GACRC? High Performance
Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu 1 Outline GACRC? High Performance
COMP4510 Introduction to Parallel Computation. Shared Memory and OpenMP. Outline (cont d) Shared Memory and OpenMP
 Shared Memory and OpenMP") COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
Supercomputing environment TMA4280 Introduction to Supercomputing
 Supercomputing environment TMA4280 Introduction to Supercomputing NTNU, IMF February 21. 2018 1 Supercomputing environment Supercomputers use UNIX-type operating systems. Predominantly Linux. Using a shell
Supercomputing environment TMA4280 Introduction to Supercomputing NTNU, IMF February 21. 2018 1 Supercomputing environment Supercomputers use UNIX-type operating systems. Predominantly Linux. Using a shell
Working on the NewRiver Cluster
 Working on the NewRiver Cluster CMDA3634: Computer Science Foundations for Computational Modeling and Data Analytics 22 February 2018 NewRiver is a computing cluster provided by Virginia Tech s Advanced
Working on the NewRiver Cluster CMDA3634: Computer Science Foundations for Computational Modeling and Data Analytics 22 February 2018 NewRiver is a computing cluster provided by Virginia Tech s Advanced
Introduction to HPC Using the New Cluster at GACRC
 Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Compiling applications for the Cray XC
 Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
The cluster system. Introduction 22th February Jan Saalbach Scientific Computing Group
 The cluster system Introduction 22th February 2018 Jan Saalbach Scientific Computing Group cluster-help@luis.uni-hannover.de Contents 1 General information about the compute cluster 2 Available computing
The cluster system Introduction 22th February 2018 Jan Saalbach Scientific Computing Group cluster-help@luis.uni-hannover.de Contents 1 General information about the compute cluster 2 Available computing
Knights Landing production environment on MARCONI
 Knights Landing production environment on MARCONI Alessandro Marani - a.marani@cineca.it March 20th, 2017 Agenda In this presentation, we will discuss - How we interact with KNL environment on MARCONI
Knights Landing production environment on MARCONI Alessandro Marani - a.marani@cineca.it March 20th, 2017 Agenda In this presentation, we will discuss - How we interact with KNL environment on MARCONI
Working with Shell Scripting. Daniel Balagué
 Working with Shell Scripting Daniel Balagué Editing Text Files We offer many text editors in the HPC cluster. Command-Line Interface (CLI) editors: vi / vim nano (very intuitive and easy to use if you
Working with Shell Scripting Daniel Balagué Editing Text Files We offer many text editors in the HPC cluster. Command-Line Interface (CLI) editors: vi / vim nano (very intuitive and easy to use if you
Running applications on the Cray XC30
 Running applications on the Cray XC30 Running on compute nodes By default, users do not access compute nodes directly. Instead they launch jobs on compute nodes using one of three available modes: 1. Extreme
Running applications on the Cray XC30 Running on compute nodes By default, users do not access compute nodes directly. Instead they launch jobs on compute nodes using one of three available modes: 1. Extreme
MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization
 SCV Staff Boston University Scientific Computing and Visualization") MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization 2 Glenn Bresnahan Director, SCV MGHPCC Buy-in Program Kadin Tseng HPC Programmer/Consultant
MIGRATING TO THE SHARED COMPUTING CLUSTER (SCC) SCV Staff Boston University Scientific Computing and Visualization 2 Glenn Bresnahan Director, SCV MGHPCC Buy-in Program Kadin Tseng HPC Programmer/Consultant
Using the MaRC2 HPC Cluster
 Using the MaRC2 HPC Cluster Manuel Haim, 06/2013 Using MaRC2??? 2 Using MaRC2 Overview Get access rights and permissions Starting a terminal session (Linux, Windows, Mac) Intro to the BASH Shell (and available
Using the MaRC2 HPC Cluster Manuel Haim, 06/2013 Using MaRC2??? 2 Using MaRC2 Overview Get access rights and permissions Starting a terminal session (Linux, Windows, Mac) Intro to the BASH Shell (and available
XSEDE New User Tutorial
 April 2, 2014 XSEDE New User Tutorial Jay Alameda National Center for Supercomputing Applications XSEDE Training Survey Make sure you sign the sign in sheet! At the end of the module, I will ask you to
April 2, 2014 XSEDE New User Tutorial Jay Alameda National Center for Supercomputing Applications XSEDE Training Survey Make sure you sign the sign in sheet! At the end of the module, I will ask you to
Distributed Memory Programming With MPI Computer Lab Exercises
 Distributed Memory Programming With MPI Computer Lab Exercises Advanced Computational Science II John Burkardt Department of Scientific Computing Florida State University http://people.sc.fsu.edu/ jburkardt/classes/acs2
Distributed Memory Programming With MPI Computer Lab Exercises Advanced Computational Science II John Burkardt Department of Scientific Computing Florida State University http://people.sc.fsu.edu/ jburkardt/classes/acs2
Introduction to HPC Numerical libraries on FERMI and PLX
 Introduction to HPC Numerical libraries on FERMI and PLX HPC Numerical Libraries 11-12-13 March 2013 a.marani@cineca.it WELCOME!! The goal of this course is to show you how to get advantage of some of
Introduction to HPC Numerical libraries on FERMI and PLX HPC Numerical Libraries 11-12-13 March 2013 a.marani@cineca.it WELCOME!! The goal of this course is to show you how to get advantage of some of
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016
 1/18/2016") Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
A Brief Introduction to The Center for Advanced Computing
 A Brief Introduction to The Center for Advanced Computing May 1, 2006 Hardware 324 Opteron nodes, over 700 cores 105 Athlon nodes, 210 cores 64 Apple nodes, 128 cores Gigabit networking, Myrinet networking,
A Brief Introduction to The Center for Advanced Computing May 1, 2006 Hardware 324 Opteron nodes, over 700 cores 105 Athlon nodes, 210 cores 64 Apple nodes, 128 cores Gigabit networking, Myrinet networking,
UAntwerpen, 24 June 2016
 Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
Cerebro Quick Start Guide
 Cerebro Quick Start Guide Overview of the system Cerebro consists of a total of 64 Ivy Bridge processors E5-4650 v2 with 10 cores each, 14 TB of memory and 24 TB of local disk. Table 1 shows the hardware
Cerebro Quick Start Guide Overview of the system Cerebro consists of a total of 64 Ivy Bridge processors E5-4650 v2 with 10 cores each, 14 TB of memory and 24 TB of local disk. Table 1 shows the hardware
The RWTH Compute Cluster Environment
 The RWTH Compute Cluster Environment Tim Cramer 29.07.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) The RWTH Compute Cluster (1/2) The Cluster provides ~300 TFlop/s No. 32 in TOP500
The RWTH Compute Cluster Environment Tim Cramer 29.07.2013 Source: D. Both, Bull GmbH Rechen- und Kommunikationszentrum (RZ) The RWTH Compute Cluster (1/2) The Cluster provides ~300 TFlop/s No. 32 in TOP500
MPI 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Windows-HPC Environment at RWTH Aachen University
 Windows-HPC Environment at RWTH Aachen University Christian Terboven, Samuel Sarholz {terboven, sarholz}@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University PPCES 2009 March
Windows-HPC Environment at RWTH Aachen University Christian Terboven, Samuel Sarholz {terboven, sarholz}@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University PPCES 2009 March
Using Sapelo2 Cluster at the GACRC
 Using Sapelo2 Cluster at the GACRC New User Training Workshop Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Sapelo2 Cluster Diagram
Using Sapelo2 Cluster at the GACRC New User Training Workshop Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Sapelo2 Cluster Diagram
Practical Introduction to
 Outline of the workshop Practical Introduction to Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your serial code What is OpenMP? Why do
Outline of the workshop Practical Introduction to Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your serial code What is OpenMP? Why do
OpenMP Programming. Aiichiro Nakano
 OpenMP Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
OpenMP Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
ECE 574 Cluster Computing Lecture 10
 ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
EE/CSCI 451 Introduction to Parallel and Distributed Computation. Discussion #4 2/3/2017 University of Southern California
 EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
Hybrid Programming with MPI and OpenMP. B. Estrade
 Hybrid Programming with MPI and OpenMP B. Estrade Objectives understand the difference between message passing and shared memory models; learn of basic models for utilizing both message
Hybrid Programming with MPI and OpenMP B. Estrade Objectives understand the difference between message passing and shared memory models; learn of basic models for utilizing both message
Batch Systems. Running calculations on HPC resources
 Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
High Performance Computing (HPC) Using zcluster at GACRC
 Using zcluster at GACRC") High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?
High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?
Shifter on Blue Waters
 Shifter on Blue Waters Why Containers? Your Computer Another Computer (Supercomputer) Application Application software libraries System libraries software libraries System libraries Why Containers? Your
Shifter on Blue Waters Why Containers? Your Computer Another Computer (Supercomputer) Application Application software libraries System libraries software libraries System libraries Why Containers? Your
Introduction to Parallel Programming. Martin Čuma Center for High Performance Computing University of Utah
 Introduction to Parallel Programming Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Types of parallel computers. Parallel programming options. How to
Introduction to Parallel Programming Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Types of parallel computers. Parallel programming options. How to
Tutorial: Compiling, Makefile, Parallel jobs
 Tutorial: Compiling, Makefile, Parallel jobs Hartmut Häfner Steinbuch Centre for Computing (SCC) Funding: www.bwhpc-c5.de Outline Compiler + Numerical Libraries commands Linking Makefile Intro, Syntax
Tutorial: Compiling, Makefile, Parallel jobs Hartmut Häfner Steinbuch Centre for Computing (SCC) Funding: www.bwhpc-c5.de Outline Compiler + Numerical Libraries commands Linking Makefile Intro, Syntax
CS420: Operating Systems
 Threads James Moscola Department of Physical Sciences York College of Pennsylvania Based on Operating System Concepts, 9th Edition by Silberschatz, Galvin, Gagne Threads A thread is a basic unit of processing
Threads James Moscola Department of Physical Sciences York College of Pennsylvania Based on Operating System Concepts, 9th Edition by Silberschatz, Galvin, Gagne Threads A thread is a basic unit of processing
ITCS 4/5145 Parallel Computing Test 1 5:00 pm - 6:15 pm, Wednesday February 17, 2016 Solutions Name:...
 ITCS 4/5145 Parallel Computing Test 1 5:00 pm - 6:15 pm, Wednesday February 17, 016 Solutions Name:... Answer questions in space provided below questions. Use additional paper if necessary but make sure
ITCS 4/5145 Parallel Computing Test 1 5:00 pm - 6:15 pm, Wednesday February 17, 016 Solutions Name:... Answer questions in space provided below questions. Use additional paper if necessary but make sure
Introduction to OpenMP. Lecture 2: OpenMP fundamentals
 Introduction to OpenMP Lecture 2: OpenMP fundamentals Overview 2 Basic Concepts in OpenMP History of OpenMP Compiling and running OpenMP programs What is OpenMP? 3 OpenMP is an API designed for programming
Introduction to OpenMP Lecture 2: OpenMP fundamentals Overview 2 Basic Concepts in OpenMP History of OpenMP Compiling and running OpenMP programs What is OpenMP? 3 OpenMP is an API designed for programming
Answers to Federal Reserve Questions. Training for University of Richmond
 Answers to Federal Reserve Questions Training for University of Richmond 2 Agenda Cluster Overview Software Modules PBS/Torque Ganglia ACT Utils 3 Cluster overview Systems switch ipmi switch 1x head node
Answers to Federal Reserve Questions Training for University of Richmond 2 Agenda Cluster Overview Software Modules PBS/Torque Ganglia ACT Utils 3 Cluster overview Systems switch ipmi switch 1x head node
Introduction to High Performance Computing (HPC) Resources at GACRC
 Resources at GACRC") Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007
 HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
Open Multi-Processing: Basic Course
 HPC2N, UmeåUniversity, 901 87, Sweden. May 26, 2015 Table of contents Overview of Paralellism 1 Overview of Paralellism Parallelism Importance Partitioning Data Distributed Memory Working on Abisko 2 Pragmas/Sentinels
HPC2N, UmeåUniversity, 901 87, Sweden. May 26, 2015 Table of contents Overview of Paralellism 1 Overview of Paralellism Parallelism Importance Partitioning Data Distributed Memory Working on Abisko 2 Pragmas/Sentinels
To connect to the cluster, simply use a SSH or SFTP client to connect to:
 RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
Introduction to Cheyenne. 12 January, 2017 Consulting Services Group Brian Vanderwende
 Introduction to Cheyenne 12 January, 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical specs of the Cheyenne supercomputer and expanded GLADE file systems The Cheyenne computing
Introduction to Cheyenne 12 January, 2017 Consulting Services Group Brian Vanderwende Topics we will cover Technical specs of the Cheyenne supercomputer and expanded GLADE file systems The Cheyenne computing
Introduction to Parallel Programming (Session 2: MPI + Matlab/Octave/R)
") Introduction to Parallel Programming (Session 2: MPI + Matlab/Octave/R) Xingfu Wu Department of Computer Science & Engineering Texas A&M University IAMCS, Feb 24, 2012 Survey n Who is mainly programming
Introduction to Parallel Programming (Session 2: MPI + Matlab/Octave/R) Xingfu Wu Department of Computer Science & Engineering Texas A&M University IAMCS, Feb 24, 2012 Survey n Who is mainly programming
NBIC TechTrack PBS Tutorial. by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen
 NBIC TechTrack PBS Tutorial by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen 1 NBIC PBS Tutorial This part is an introduction to clusters and the PBS
NBIC TechTrack PBS Tutorial by Marcel Kempenaar, NBIC Bioinformatics Research Support group, University Medical Center Groningen 1 NBIC PBS Tutorial This part is an introduction to clusters and the PBS
Introduction to Parallel Programming with MPI
 Introduction to Parallel Programming with MPI PICASso Tutorial October 25-26, 2006 Stéphane Ethier (ethier@pppl.gov) Computational Plasma Physics Group Princeton Plasma Physics Lab Why Parallel Computing?
Introduction to Parallel Programming with MPI PICASso Tutorial October 25-26, 2006 Stéphane Ethier (ethier@pppl.gov) Computational Plasma Physics Group Princeton Plasma Physics Lab Why Parallel Computing?
Wednesday, August 10, 11. The Texas Advanced Computing Center Michael B. Gonzales, Ph.D. Program Director, Computational Biology
 The Texas Advanced Computing Center Michael B. Gonzales, Ph.D. Program Director, Computational Biology Computational Biology @ TACC Goal: Establish TACC as a leading center for ENABLING computational biology
The Texas Advanced Computing Center Michael B. Gonzales, Ph.D. Program Director, Computational Biology Computational Biology @ TACC Goal: Establish TACC as a leading center for ENABLING computational biology
Department of Informatics V. Tsunami-Lab. Session 4: Optimization and OMP Michael Bader, Alex Breuer. Alex Breuer
 Tsunami-Lab Session 4: Optimization and OMP Michael Bader, MAC-Cluster: Overview Intel Sandy Bridge (snb) AMD Bulldozer (bdz) Product Name (base frequency) Xeon E5-2670 (2.6 GHz) AMD Opteron 6274 (2.2
Tsunami-Lab Session 4: Optimization and OMP Michael Bader, MAC-Cluster: Overview Intel Sandy Bridge (snb) AMD Bulldozer (bdz) Product Name (base frequency) Xeon E5-2670 (2.6 GHz) AMD Opteron 6274 (2.2
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Hybrid Model Parallel Programs
 Hybrid Model Parallel Programs Charlie Peck Intermediate Parallel Programming and Cluster Computing Workshop University of Oklahoma/OSCER, August, 2010 1 Well, How Did We Get Here? Almost all of the clusters
Hybrid Model Parallel Programs Charlie Peck Intermediate Parallel Programming and Cluster Computing Workshop University of Oklahoma/OSCER, August, 2010 1 Well, How Did We Get Here? Almost all of the clusters