Accelerating image registration on GPUs
|
|
|
- Jeffry Marshall
- 6 years ago
- Views:
Transcription
1 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10)
2 Contents Motivation: Image registration with FAIR GPU Programming Combining Matlab and CUDA Future Work 2
3 Image registration in FAIR MOTIVATION 3

4 Image Registration in FAIR 4
5 Variational model for image registration Find mapping or deformation field u : R d d a R, d { 2,3} such that the energy functional E( u) = D[ J,u] + α S[ u] with data term D and regularizer S is minimized. 5
 numerical optimization techniques Constrained image registration FAIR, J.")
6 FAIR: Flexible Algorithms for Image Registration Framework for image registration in Matlab Different transformations, data terms, regularizers Different (multi-level) numerical optimization techniques Constrained image registration FAIR, J. Modersitzki, SIAM,

7 Image Registration cycle 7


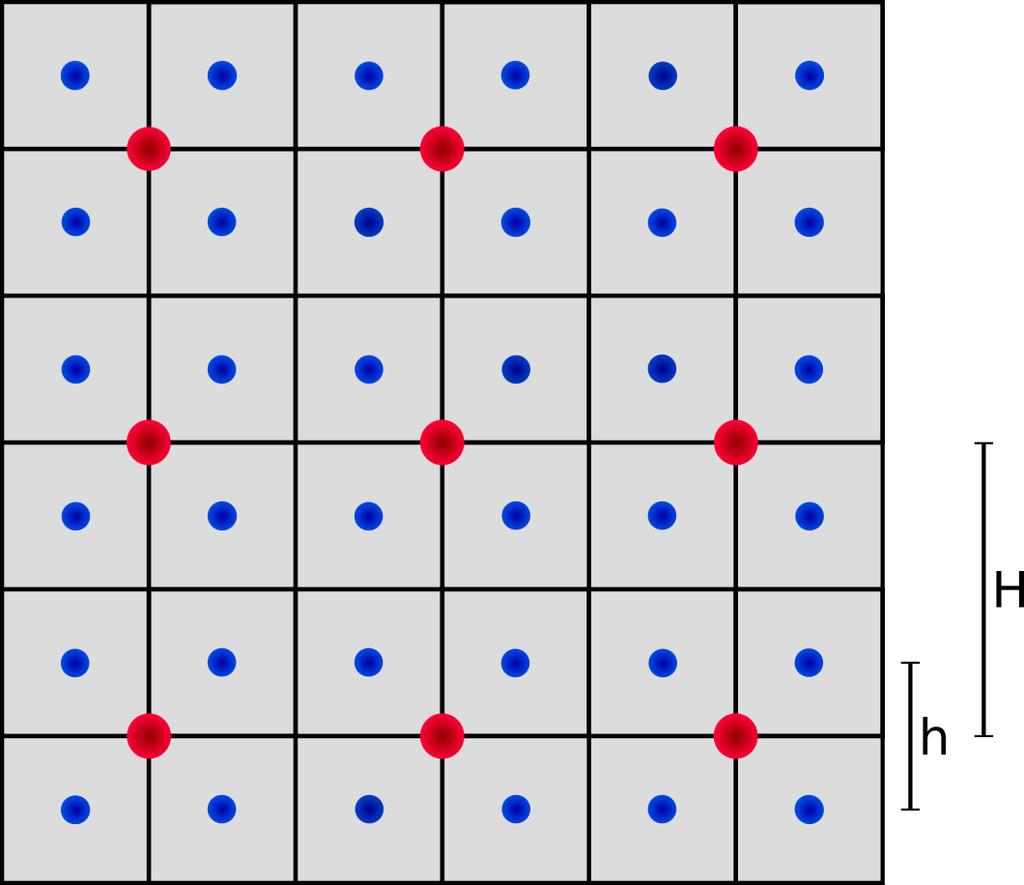
8 Runtime distribution for rigid registration cycle 4% 22% 15% Functional Optimization 59% Interpolation Matlab plots 8
9 GPUs COMPUTER ARCHITECTURE 9
10 Nvidia GeForce GTX 295 Costs: 450 Interface: PCI-E 2.0 x16 Shader Clock: 1242 MHz Memory Clock: 999 MHz Memory Bandwidth: 2x112 GB/s FLOPS: 2x894 GFLOPS Max Power Draw: 289 W Framebuffer: 2x896 MB Memory Bus: 2x448 bit Shader Processors: 2x240 10
11 Why GPUs? Graphics Processing Units (GPUs) are a massively parallel computer architecture GPUs offer high computational performance at low costs GPGPU General-Purpose computing on a GPU Using graphic hardware for non-graphic computations Programming Tools: CUDA or OpenCL Without explicitly parallel algorithms, the performance potential of current hardware architectures cannot be used any more 11
12 CPU vs. GPU CPUs are great for task parallelism Fast caches Branching adaptability GPUs are great for data parallelism Multiple ALUs Fast onboard memory High throughput on parallel tasks Executes program on each fragment Think of the GPU (device) as a massively-threaded coprocessor 12


13 Memory Architecture Constant Memory Shared Memory Texture Memory Device Memory 13
14 Data-parallel Programming What is CUDA? Compute Unified Device Architecture Software architecture for managing data-parallel programming Write kernels (functions) that execute on the device and process multiple data elements in parallel Massive threading Local memory 14
15 Paradigm of the CUDA toolkit I Thread 0 Thread 1 Thread 2 OpenMP Divide domain into huge chunks Equally distribute to threads Parallelize outer most loop to minimize overhead 15
16 Paradigm of the CUDA toolkit II CUDA Divide domain into small pieces But! Data Mapping is different to enblock distribution of OpenMP Alignment constraints must be met No cache and cache lines need to be considered Block 1 Block 2 Thread 0 Thread 1 Thread 2 Thread 0 Thread Thread

17 Grid Size and Block Size Grid size: The size and shape of the data that the program will be working on Block size: The block size indicates the sub-area of the original grid that will be assigned to a multiprocessor 17
18 CUDA Example GPU: global void sum(float* a, float* b, float* c) { int idx = blockidx.x*blockdim.x + threadidx.x; // computes array index for current thread c[idx] = a[idx] + b[idx]; // adds array entry (global memory) } CPU: void vector_add(float *in_a, float *in_b, float *out, unsigned int length){ float* a, *b, *c; Declare data cudamalloc((void**)&a_gpu, sizeof(float)*length); cudamalloc((void**)&b_gpu, sizeof(float)*length); cudamalloc((void**)&out_gpu, sizeof(float)*length); cudamemcpy ( a_gpu,in_a, sizeof ( float ) *length, cudamemcpyhosttodevice ); cudamemcpy ( b_gpu,in_a, sizeof ( float ) *length, cudamemcpyhosttodevice ); dim3 dimblock(256,1); dim3 dimgrid(length/dimblock.x,1); sum<<<dimgrid,dimblock>>>(a,b,c); Allocate data on GPU Copy data to GPU Define block/grid sizes Kernel execution cudamemcpy ( out_gpu,out, sizeof ( float ) *length, cudamemcpydevicetohost );} Write back data to CPU 18
19 OpenCL OpenCL (Open Computing Language) is an open standard for heterogeneous parallel computing Managed by non-profit technology consortium Khronos group Analogous to the open industry standards OpenGL for 3D graphics OpenCL exploits task-based and data-based parallelism Similar to CUDA, OpenCL includes a language (based on C99) for writing kernels executing on devices like GPU, cell, or multicore processors Performance of high level heterogeneous tools? 19
20 nvmex COMBINING MATLAB AND CUDA 20
21 MATLAB MEX interface 21
22 CUDA MEX environment MATLAB script nvmex.m compiles CUDA code to create MATLAB function files 1. Allocate memory on the GPU 2. Transfer the data from the host to the GPU 3. Perform computation on GPU (library, custom code) 4. Transfer results from the GPU to the host 22
23 Basic interpolation schemes: Host side 23
24 Basic interpolation schemes: GPU kernel 24
25 B-Spline Interpolation [Sigg, C. and Hadwiger, M.] Combine 2 linear interpolations to obtain B-spline interpolation 25
26 Runtime Results Interpolation I 26
27 Runtime Results Interpolation II 1 0,1 time (ms) 0,01 0,001 SplineInter2D (bilinear texture) Theoretical Best Case runtime Theoretical worst Case runtime 0,
28 Discretization Error Accuracy f+hf -f(h) f-f(h) h 28
29 Persistent Memory and Hybrid Memory Goal: avoid allocation and deallocation of memory for each call to a GPU kernel through Matlab Static variables routine to clear CUDA MEX persistent variable Saves up to 17% runtime for bigger images (2048x1024) 29
30 CUDA MEX Registration cycle 30
31 Runtime summary for rigid registration Time includes data transfers and Matlab visualization (plots about 20 %) GPU pays off for large images (speedup factor about 2x, pure GPU kernels about 20x) A lot more potential to move more parts to GPU xsize ysize Matlab Matlab+GPU s 14 s s 33 s s 92 s 31
32 A Multigrid Solver for Diffusion-based PDEs MULTIGRID ON GPU 32
33 What is Multigrid? May consume a lot of time during optimization step to find an updated transformation A very fast and efficient iterative solver for huge sparse, linear (and nonlinear) systems A u = f Geometric multigrid on structured grids is well suited for GPU implementation because of regular data access patterns Multigrid exhibits a convergence rate that is independent of the number of unknowns N, i.e. a multigrid solver has complexity O(N) 33


34 Multigrid Idea Multigrid methods are based on two principles: 1. Smoothing property Smooth error on fine grid 34
35 Multigrid Idea Multigrid methods are based on two principles: 1. Smoothing property 2. Coarse grid principle Approximate smooth error on coarser grids 35


36 Complex Diffusion on Nvidia GeForce GTX runtime V(2,2) in ms x x x x x4096 Image size Runtime on 2 x C2 Penryn (8 2.8 GHz, 8 x 22,4 GFLOPs is 1100 ms for 4096 x 4096 Speedup factor 14 36
37 Summary and Future Work When to use GPGPU Suitable algorithms? Get the promised performance? Get it at low effort and cost? Future Work Multi-GPU OpenCL Adapt GPU multigrid to image registration 37
38 Questions?
39 Acknowledgements Nvidia Corporation developer.nvidia.com/cuda Technical Brief Architecture Overview CUDA Programming Guide Supercomputing 2008 Education Program: CUDA Introduction, Christian Trefftz / Greg Wolffe (Grand Valley State University) AMD/ATI pdf ATI Stream SDK User Guide 39
40 Possible Improvements 40
41 Runtime Results Interpolation II 41
42 Full Multigrid Cycle Smoothing V-cycle Interpolation of solution u Exact solution Restriction of residual r = f - Au Interpolation of error and correction of solution u 42

43 Multigrid on GTX 295 with red-black splitting Runtime V(2,2) in ms x x x x x4096 Image size 43

 streaming bandwidth (100 GB /")
44 Memory Bandwidth 100% Percent of memory bandwidth 90% 80% 70% 60% 50% 40% 30% 20% 10% 0% 1024x x x x x4096 Image size In percent from maximum measured (rounded) streaming bandwidth (100 GB / s) 44
45 Frames per second for Image Stitching fps (stitching GTX 295) fps (solver GTX 295) fps (CPU) x x x x x4096 CPU: Intel Core2 Quad Q9550@2.83GHz with OpenMP (4 cores) 45
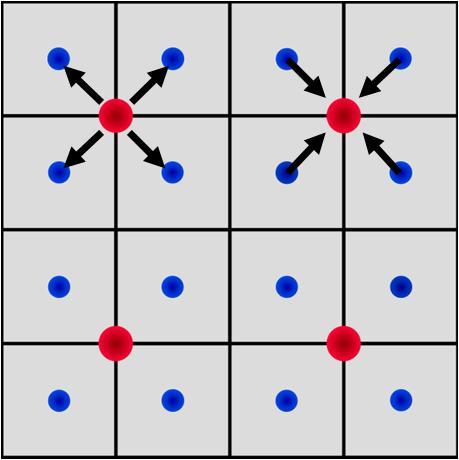
46 Interpolation and Restriction 46
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Multigrid algorithms on multi-gpu architectures
 Multigrid algorithms on multi-gpu architectures H. Köstler European Multi-Grid Conference EMG 2010 Isola d Ischia, Italy 20.9.2010 2 Contents Work @ LSS GPU Architectures and Programming Paradigms Applications
Multigrid algorithms on multi-gpu architectures H. Köstler European Multi-Grid Conference EMG 2010 Isola d Ischia, Italy 20.9.2010 2 Contents Work @ LSS GPU Architectures and Programming Paradigms Applications
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Master Thesis Accelerating Image Registration on GPUs
 Master Thesis Accelerating Image Registration on GPUs A proof of concept migration of FAIR to CUDA Sunil Ramgopal Tatavarty Prof. Dr. Ulrich Rüde Dr.-Ing.Harald Köstler Lehrstuhl für Systemsimulation Universität
Master Thesis Accelerating Image Registration on GPUs A proof of concept migration of FAIR to CUDA Sunil Ramgopal Tatavarty Prof. Dr. Ulrich Rüde Dr.-Ing.Harald Köstler Lehrstuhl für Systemsimulation Universität
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
How to Optimize Geometric Multigrid Methods on GPUs
 How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
Real-time Graphics 9. GPGPU
 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Technical Application Field. Scientific Computing. Applied Numerics
 EVIP Technical Application Field Scientific Computing Applied Numerics Variational Modeling EVIP Parallel Processing Rank efficient operators Elasticity modeled Image Registration Motivation Given a reference
EVIP Technical Application Field Scientific Computing Applied Numerics Variational Modeling EVIP Parallel Processing Rank efficient operators Elasticity modeled Image Registration Motivation Given a reference
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
PhD Student. Associate Professor, Co-Director, Center for Computational Earth and Environmental Science. Abdulrahman Manea.
 Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Comparison of High-Speed Ray Casting on GPU
 Comparison of High-Speed Ray Casting on GPU using CUDA and OpenGL November 8, 2008 NVIDIA 1,2, Andreas Weinlich 1, Holger Scherl 2, Markus Kowarschik 2 and Joachim Hornegger 1 1 Chair of Pattern Recognition
Comparison of High-Speed Ray Casting on GPU using CUDA and OpenGL November 8, 2008 NVIDIA 1,2, Andreas Weinlich 1, Holger Scherl 2, Markus Kowarschik 2 and Joachim Hornegger 1 1 Chair of Pattern Recognition
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU Programming for Mathematical and Scientific Computing
 GPU Programming for Mathematical and Scientific Computing Ethan Kerzner and Timothy Urness Department of Mathematics and Computer Science Drake University Des Moines, IA 50311 ethan.kerzner@gmail.com timothy.urness@drake.edu
GPU Programming for Mathematical and Scientific Computing Ethan Kerzner and Timothy Urness Department of Mathematics and Computer Science Drake University Des Moines, IA 50311 ethan.kerzner@gmail.com timothy.urness@drake.edu
GPGPU. Alan Gray/James Perry EPCC The University of Edinburgh.
 GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Using a GPU in InSAR processing to improve performance
 Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
GPU 101. Mike Bailey. Oregon State University. Oregon State University. Computer Graphics gpu101.pptx. mjb April 23, 2017
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
GPU 101. Mike Bailey. Oregon State University
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
"On the Capability and Achievable Performance of FPGAs for HPC Applications"
 "On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
"On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
GPU Programming Using NVIDIA CUDA
 GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
GPU Programming Using NVIDIA CUDA Siddhante Nangla 1, Professor Chetna Achar 2 1, 2 MET s Institute of Computer Science, Bandra Mumbai University Abstract: GPGPU or General-Purpose Computing on Graphics
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
Geometric Multigrid on Multicore Architectures: Performance-Optimized Complex Diffusion
 Geometric Multigrid on Multicore Architectures: Performance-Optimized Complex Diffusion M. Stürmer, H. Köstler, and U. Rüde Lehrstuhl für Systemsimulation Friedrich-Alexander-Universität Erlangen-Nürnberg
Geometric Multigrid on Multicore Architectures: Performance-Optimized Complex Diffusion M. Stürmer, H. Köstler, and U. Rüde Lehrstuhl für Systemsimulation Friedrich-Alexander-Universität Erlangen-Nürnberg
Introduction to CUDA
 Introduction to CUDA Oliver Meister November 7 th 2012 Tutorial Parallel Programming and High Performance Computing, November 7 th 2012 1 References D. Kirk, W. Hwu: Programming Massively Parallel Processors,
Introduction to CUDA Oliver Meister November 7 th 2012 Tutorial Parallel Programming and High Performance Computing, November 7 th 2012 1 References D. Kirk, W. Hwu: Programming Massively Parallel Processors,
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
GRAPHICS HARDWARE. Niels Joubert, 4th August 2010, CS147
 GRAPHICS HARDWARE Niels Joubert, 4th August 2010, CS147 Rendering Latest GPGPU Today Enabling Real Time Graphics Pipeline History Architecture Programming RENDERING PIPELINE Real-Time Graphics Vertices
GRAPHICS HARDWARE Niels Joubert, 4th August 2010, CS147 Rendering Latest GPGPU Today Enabling Real Time Graphics Pipeline History Architecture Programming RENDERING PIPELINE Real-Time Graphics Vertices
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
OpenMP and GPU Programming
 OpenMP and GPU Programming GPU Intro Emanuele Ruffaldi https://github.com/eruffaldi/course_openmpgpu PERCeptual RObotics Laboratory, TeCIP Scuola Superiore Sant Anna Pisa,Italy e.ruffaldi@sssup.it April
OpenMP and GPU Programming GPU Intro Emanuele Ruffaldi https://github.com/eruffaldi/course_openmpgpu PERCeptual RObotics Laboratory, TeCIP Scuola Superiore Sant Anna Pisa,Italy e.ruffaldi@sssup.it April
GPGPU, 4th Meeting Mordechai Butrashvily, CEO GASS Company for Advanced Supercomputing Solutions
 GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Accelerating CFD with Graphics Hardware
 Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Duksu Kim. Professional Experience Senior researcher, KISTI High performance visualization
 Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
General-purpose computing on graphics processing units (GPGPU)
") General-purpose computing on graphics processing units (GPGPU) Thomas Ægidiussen Jensen Henrik Anker Rasmussen François Rosé November 1, 2010 Table of Contents Introduction CUDA CUDA Programming Kernels
General-purpose computing on graphics processing units (GPGPU) Thomas Ægidiussen Jensen Henrik Anker Rasmussen François Rosé November 1, 2010 Table of Contents Introduction CUDA CUDA Programming Kernels
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid. Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014
 Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
GPGPU introduction and network applications. PacketShaders, SSLShader
 GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge