Scientific discovery, analysis and prediction made possible through high performance computing.
|
|
|
- Dana Baldwin
- 6 years ago
- Views:
Transcription




1 Scientific discovery, analysis and prediction made possible through high performance computing.

2 An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013

3 Introduction
4 Contents What is GPU computing? Brief History of GPGPU Introduction to CUDA CUDA API Basics Advanced CUDA Concepts
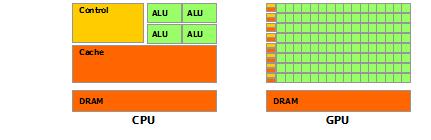
5 What is GPU computing? GPU computing is the use of the GPU together with the CPU to accelerate general purpose applications GPGPU (General Purpose Computing on GPUs) Offload the most computationally intense work to the GPU As a tag-team, the CPU and GPU work well together CPU: Optimized for serial processes SISD (MIMD) GPU: Optimized for parallel processes SIMD
6 Why GPU computing? CPU vs GPU
7 AMD Opteron 2435 Specs (CPU) 6 processor cores 12 virtual cores (hyperthreading) 904 million transistors ~100 GFLOPs 768 KB L1 Cache 3 MB L2 Cache 6 MB L3 Cache
8 Nvidia Tesla x2090 Specs 512 CUDA cores 3 billion transistors (GPU) 1.33 TFLOPs (SP floating point) 665 GFLOPs (DP floating point) 6 GB on-board memory 177 GB/s memory bandwidth
9
10
11
12 Brief History of GPGPU On October 11 th, 1999, Nvidia creates the first ever GPU Offloaded the task of transformation & lighting In the early 2000 s, many started to notice the power of the GPU Researchers started writing code in OpenGL and Cg Limited accessibility to general programmers and industry Seeing a need, Nvidia made their GPUs fully programmable Offered the CUDA parallel programming model Works in a variety of languages, most notably C, C++ and Fortran
13 Introduction to CUDA Compute Unified Device Architecture (CUDA) With CUDA, an Nvidia GPU can be used for general purpose processing Only Nvidia GPUs are able to be used with CUDA Different versions of CUDA result in different API calls being available CUDA will work on all Nvidia GPUs from the G8x series onwards Nvidia Tesla GPUs available on ARSC s supercomputer Fish compute nodes CUDA works on all major operating systems Microsoft Windows, Mac OSX, and many variants of Linux
14 Introduction to CUDA (cont.) To run CUDA at home, you can visit: Download the CUDA release for your operating system Follow the instructions in the provided Getting Started guide Once you have installed the CUDA toolkit, you will have all of the necessary tools to compile and run CUDA on your system An important tool is nvcc which does the work of compiling your CUDA source code into a binary CUDA source code is normally contained in a file with the suffix.cu
15 CUDA API Basics In the following section, I will be going through some of the basic API calls available in CUDA For those familiar with C/C++, these will seem fairly natural to the language With a few caveats, such as << >> Each new API call will give information about the API call and a small piece of example code to show how it could be used. DISCLAIMER: While there are Fortran examples online for use with CUDA, I have neither tested nor tried any. All of the following works with C.
16 cudamalloc Similar to the malloc command for allocation of memory on a server Allocates a chunk of memory in the GPU s available memory Can use a pointer to indicate the start of available memory float * or void* Called with two arguments: A reference to a memory location (i.e. &var1) Size of memory to allocate to the memory location Made easier with a function called sizeof()
17 cudamalloc const int N = 20;! size_t size = 30 * sizeof(float);! float* d_a, d_b;! void* d_c;!! cudamalloc(&d_a, (10 * sizeof(float)));! cudamalloc(&d_b, (N * sizeof(float)));! cudamalloc(&d_c, size);!
18 cudafree cudafree releases the memory that has been allocated on the device Identical to free() for C/C++ malloc() cudafree and cudamalloc behave differently depending on where they were executed cudafree run on the device cannot free device memory that was allocated by the host cudamalloc run on the device will only be able to allocate space up to the cudalimitmallocheapsize Called with a single argument: Pointer to memory location on device
19 cudafree float* d_a;! cudamalloc(&d_a, 30 * sizeof(float));!...! cudafree(d_a);!
20 cudamemcpy This function copies data between the host system and the GPU device It is required that the memory copy has a pre-allocated amount of space available for the data to be copied The function is used for copying data to and from the device and also to copy on the device cudamemcpyhosttodevice cudamemcpydevicetohost cudamemcpydevicetodevice Called with 4 arguments: A pointer to the memory that is being copied to A pointer to the memory that is being copied from The size of the data being transferred from the second arg. to the first arg. The direction to copy the data (host to device, device to host)
21 cudamemcpy cudamemcpy(d_a, h_a, 30 * sizeof(float), cudamemcpyhosttodevice);!...! cudamemcpy(h_a, d_a, 30 * sizeof(float), cudamemcpydevicetohost);!! const int N = 50;! size_t size = N * sizeof(float);! cudamemcpy(d_b, h_b, size, cudamemcpyhosttodevice);!...! cudamemcpy(h_b, d_b, size, cudamemcpydevicetohost);!
22 Example Code What does this code do? What would you expect the result to be from this running on the GPU?



23 Kernels When I think of kernels, I think of two things
24 CUDA Kernels A kernel is a function callable from the host system to the CUDA-enabled device for being run on many threads in parallel This allows for work to be performed on data that has been loaded onto the memory of the GPU CUDA expands the C language with a set of its own directives for controlling the flow of execution Kernels are defined using one of three prefixes: host : Runs only on the host, can only be executed from the host device : Runs only on the device, can only be executed from device global : Runs only on the device, can only be executed from the host A limitation of CUDA kernels is that they can not be recursive (i.e. call themselves) and cannot have a variable number of arguments
25 CUDA Kernel Examples device void increment_values(...) {... }!! global float gpu_main(...) {... }!! host int main(...) {... }!
26 CUDA Kernel Examples host void incrementonhost(float *host_a, int N)! {! }! for (int i = 0; i < N; i++) {! }! host_a[i] = host_a[i] + 1.f;! global void incrementondevice(float *device_a, int N)! {! }! int idx = blockidx.x * blockdim.x + threadidx.x;! if (idx < N) {! }! device_a[idx] = device_a[idx] + 1.f;!
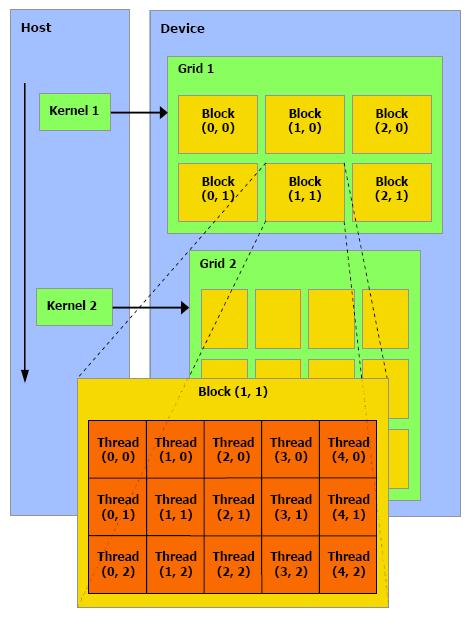
27 CUDA Thread Indexing You may have noticed the undefined syntax in previous example i.e. threadidx.x, blockdim.x, blockidx.x CUDA has these built-in variables for the blocks of threads that are run against a kernel Rather than performing a loop, we use the parallel nature of the threads to perform the same work For a better understanding of this concept, take a look at the picture in the following slide
28
29 CUDA Thread Indexing The first thing to understand is that for every kernel, a grid is created when executing that kernel A grid is a 2-D array of blocks A block is a 3-D array of threads All of the threads within a block are able to communicate and synchronize Threads within a block share memory A thread is a single instance of a parallel process To gain the true power of the GPU, hundreds of threads must be executing in parallel Due to hardware restrictions, the most threads possible per block is 512
30 CUDA Thread Indexing Every CUDA thread has its own unique ID This can be determined in a straightforward way using its blockdim, blockidx & threadidx variables For a 1D block: int idx = blockidx.x * blockdim.x + threadidx.x;! For a 2D block: int idx = blockidx.x * blockdim.x * blockdim.y + threadidx.y * blockdim.x + threadidx.x;! For a 3D block: int idx = blockidx.x * blockdim.x * blockdim.y * blockdim.z + threadidx.z * blockdim.x * blockdim.y + threadidx.y * blockdim.x + threadidx.x;!
31 CUDA Thread Indexing Modeling the block after the problem can result in easier thread indexing For example, a matrix can be indexed like this: int idx = blockidx.x * blockdim.x + threadidx.x;! int idy = blockidx.y * blockdim.y + threadidx.y;! These built-in variables can be used in a variety of ways to index your data The data is accessible by all threads The programmer decides how best to access and manipulate the data
32 CUDA Dim3 Variables Another CUDA addition to the C language is the dim3 type for a variable dim3 provides a way of defining dimensions that a grid of blocks or a block of threads can have These provide the ability for unsigned integers to be used as the limits to these dimensions As their name implies, they are capable of being 3-D definitions to match with thread structure within a block dim3 variables are defined using parentheses to indicate the dimensions dim3 <varname>(<dim1>,<dim2>,<dim3>);
33 CUDA Dim3 Example int M = 4;! int N = 8;! dim3 blocks_per_grid(m,m);! dim3 threads_per_block(n,n);!
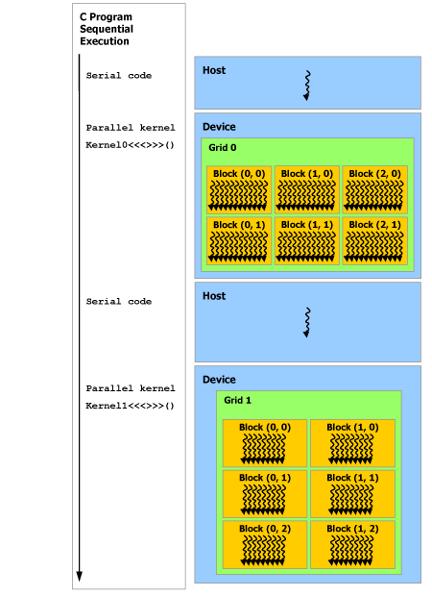
34 Running a CUDA Kernel To run a CUDA kernel, an extension to the C language has been added function_name<<<dimgrid, dimblock>>>(args);! CUDA kernels run asynchronously You can continue running sequential code on the CPU while the parallel work is being done on the GPU Calls to the function cudamemcpy() block the execution of the next lines of code All threads running on the GPU are synchronized before they are returned by cudamemcpy
35
36 Example Code What does this code do? What would you expect the result to be from this running on the GPU?
37 The More You Know Now you know everything you need to make a working CUDA program Know enough to be dangerous Basics are easy just like in every parallel programming extension Doing things right takes practice May not be obvious changes, requires optimization Understanding when a code should be written for the GPU Lots of data to compute over Using the same commands regardless of input Limited branching (or branching in an expected way)
38 CUDA Warps A warp may sound like something out of Star Trek A weaving term used to describe threads arranged lengthwise on a loom and crossed by the woof In CUDA, the hardware is designed to execute in groups of 32 threads This is known as a warp The smallest amount of threads that can be executed Naturally, 32 threads of parallel work on data is hardly working the GPU to its fullest The GPU takes the input of blocks and breaks them down into warps to be executed on the GPU Can be run on old, new, or future Nvidia GPUs due to the abstraction in code for the SMs Conditional branching done based on warps can be much more efficient Conditionals can have a profound effect on the runtime of kernels
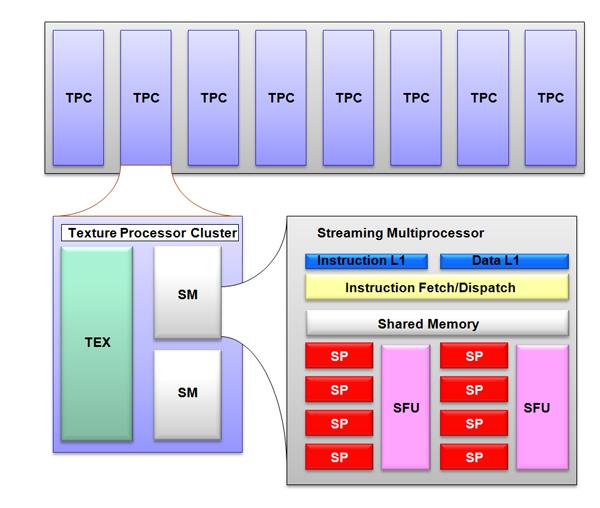
39 Nvidia GPU Architecture
40 CUDA Memory Threads within the same block CAN communicate with each other during execution This is due to a shared 16 KB memory block inside a streaming multiprocessor Threads outside of the same block must write back their results before they are accessible by other blocks Makes memory management more complicated All of the threads in a block are guaranteed to run on the same SM Uses the same shared memory block Similar to cache in CPUs, this shared memory block is much faster than reading from the GPU memory Very nearly as fast as reading / writing to a GPU register
41 CUDA Limitations An SM has 8,192 registers shared amongst all threads All blocks using that SM are limited by this value Choice of SM is done by the hardware, not by the programmer The number of active blocks on an SM can not exceed 8 The number of active warps on an SM can not exceed 24 Meaning only 768 threads per SM maximum 12,288 threads can be executing on all SMs at a time Optimizing a CUDA program Finding a balance between number of blocks and their size A block of 512 threads would be very inefficient since only one block could be running on an SM ( = 256 threads idle) Nvidia recommends running between 128 and 256 threads per block
42 CUDA Shared Memory The shared memory available to all threads in a block is managed by the programmer The CUDA software does not make use of this memory unless requested Efficient use of the shared memory in blocks contributes to faster execution of code Reads / writes to global device memory can be times slower than shared memory accesses Takes 4 clock cycles to read from shared memory Takes 400 clock cycles to read from global memory! Registers >(=) Shared > Global
43 CUDA Shared Memory For a kernel to use shared memory, it must first declare an amount of shared memory to allocate A third optional argument to the CUDA kernel execution function_name<<<numblocks, numdims, sharedmemsize>>>(args) To use the shared memory, it is easiest to let the memory be dynamically allocated extern shared float* shared_data; This will allocate the full size of the shared memory to this variable To have more than one array of data allocated in shared memory extern shared float* shared; float* a = &shared[0]; float* b = &shared[count_a];
44 CUDA Shared Memory Example global void testfunc(int count_a) {! extern shared float* shared;! }!! float* a = &shared[0];! float* b = &shared[count_a];!...! int problemsize = 256 * 2048;! int numthreadsperblock = 256;! int numblocks = problemsize / numthreadsperblock;! int sharedmemsize = numthreadsperblock * sizeof(float);! int count_a = 64;! testfunc<<<numblocks,numthreadsperblock,sharedmemsize>>>(count_a);!!
45 Synchronize Threads Before attempting to write out data to global memory, you must synchronize the threads You run the risk of trying to pull from memory for data that has not been written yet Race conditions syncthreads(); This is run from inside a kernel to block until all threads in a block reach this point For blocking until all of the threads in a grid have finished cudathreadsynchronize(); This must be run from the host
46 Example Code What does this code do? What would you expect the result to be from this running on the GPU?
47 CUDA Errors Detecting and handling errors is essential to creating robust and usable software No one wants to use code that fails with no way to determine why CUDA provides error codes specific to particular problems encountered These error codes can be converted into a string of characters to be displayed CUDA error codes have their own type: cudaerror_t char* cudageterrorstring(cudaerror_t code); Provides a human-readable description of the error code A convenient command to get the most recent CUDA error cudagetlasterror(); Useful if done after a blocking call since it will get the latest error at the end of a kernel execution for example
48 CUDA Error Example void checkcudaerror(const char *msg) {! cudaerror_t err = cudagetlasterror();! }! if ( cudasuccess!= err)! {! }! fprintf(stderr, CUDA Error: %s: %s.\n, msg,! cudageterrorstring(err));! exit(exit_failure);!
49 Example Code What does this code do? What would you expect the result to be from this running on the GPU?
50 Conclusion CUDA is only one example of how to write code for the GPU OpenCL, Microsoft s DirectCompute, and C++ AMP CUDA attempts to make programming for the GPU easy by providing a familiar code structure Easier than passing textures in OpenGL Further work is being done to make running code on the GPU truly easy OpenACC directives or compilation by LLVM Give GPU programming a try and have fun!
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Basics of CADA Programming - CUDA 4.0 and newer
 Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
HPCSE II. GPU programming and CUDA
 HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
GPU Architecture and Programming. Andrei Doncescu inspired by NVIDIA
 GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Real-time Graphics 9. GPGPU
 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
CS 179: GPU Computing. Lecture 2: The Basics
 CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Programming with CUDA, WS09
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
CUDA programming interface - CUDA C
 CUDA programming interface - CUDA C Presentation CUDA functions Device settings Memory (de)allocation within the device global memory data transfers between host memory and device global memory Data partitioning
CUDA programming interface - CUDA C Presentation CUDA functions Device settings Memory (de)allocation within the device global memory data transfers between host memory and device global memory Data partitioning
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
Massively Parallel Computing with CUDA. Carlos Alberto Martínez Angeles Cinvestav-IPN
 Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team
 Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
CUDA Basics. July 6, 2016
 Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Massively Parallel Algorithms
 Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Basic CUDA workshop. Outlines. Setting Up Your Machine Architecture Getting Started Programming CUDA. Fine-Tuning. Penporn Koanantakool
 Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Review. Lecture 10. Today s Outline. Review. 03b.cu. 03?.cu CUDA (II) Matrix addition CUDA-C API
 Matrix addition CUDA-C API") Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
GPU Programming. Rupesh Nasre.
 GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 Hello World. #include int main() { printf("hello World.\n"); return 0; Compile: nvcc hello.cu Run: a.out GPU
GPU Programming Rupesh Nasre. http://www.cse.iitm.ac.in/~rupesh IIT Madras July 2017 Hello World. #include int main() { printf("hello World.\n"); return 0; Compile: nvcc hello.cu Run: a.out GPU
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA
 CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
INTRODUCTION TO GPU COMPUTING IN AALTO. Topi Siro
 INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 12.6.2013 OUTLINE PART I Introduction to GPUs Basics of CUDA PART II Maximizing performance Coalesced memory access Optimizing memory transfers Occupancy
INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 12.6.2013 OUTLINE PART I Introduction to GPUs Basics of CUDA PART II Maximizing performance Coalesced memory access Optimizing memory transfers Occupancy
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Data parallel computing
 Data parallel computing CHAPTER 2 David Luebke CHAPTER OUTLINE 2.1 Data Parallelism...20 2.2 CUDA C Program Structure...22 2.3 A Vector Addition Kernel...25 2.4 Device Global Memory and Data Transfer...27
Data parallel computing CHAPTER 2 David Luebke CHAPTER OUTLINE 2.1 Data Parallelism...20 2.2 CUDA C Program Structure...22 2.3 A Vector Addition Kernel...25 2.4 Device Global Memory and Data Transfer...27
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example