第三章 Instruction-Level Parallelism and Its Dynamic Exploitation. 陈文智 浙江大学计算机学院 2014 年 10 月
|
|
|
- Zoe Sharp
- 6 years ago
- Views:
Transcription
1 第三章 Instruction-Level Parallelism and Its Dynamic Exploitation 陈文智 浙江大学计算机学院 2014 年 10 月 1
2 3.3 The Major Hurdle of Pipelining Pipeline Hazards 本科回顾 Appendix A Taxonomy of hazard Performance of pipeline with Hazard Structural hazard Data Hazards Control Hazards 2
3 3.3.1 Taxonomy of hazard A hazard is a condition that prevents an instruction in the pipe from executing its next scheduled pipe stage Structural hazards These are conflicts over hardware resources. Data hazards Instruction depends on result of prior computation which is not ready (computed or stored) yet Control hazards branch condition and the branch PC are not available in time to fetch an instruction on the next clock 3
4 Hazards can always be resolved by Stall The simplest way to "fix" hazards is to stall the pipeline. Stall means suspending the pipeline for some instructions by one or more clock cycles. The stall delays all instructions issued after the instruction that was stalled, while other instructions in the pipeline go on proceeding. A pipeline stall is also called a pipeline bubble or simply bubble. No new instructions are fetched during a stall. 4

5 3.3.2 Performance of pipeline with stalls Recall the speedup formula: 5
6 Assumptions for calculation The ideal CPI on a pipelined processor is almost always 1. So Ignore the overhead of pipelining clock cycle. Pipe stages are ideal balanced. 6
7 Clock cycle unpipelined = Clock cycle pipelining CPl unpipelined = pipeline depth 7
8 3.3.3 Structural hazard Structural hazards Occurs when two or more instructions want to use the same hardware resource in the same cycle Causes bubble (stall) in pipelined machines Overcome by replicating hardware resources Multiple accesses to the register file Multiple accesses to memory some functional unit is not pipelined. Not fully pipelined functional units 8
9 一 Multi access to the register file Simply insert a stall, speedup will be decreased. We have resolved it with double bump 9

10 Double Bump Works! 10
11 二 Multi access to Single Memory Time (clock cycles) I n s t r. Ld/St Instr 1 Mem Reg Mem Reg Mem Reg Mem Reg O r d e r Instr 2 Instr 3 Insert stall Mem Reg Mem Reg Mem provide another memory port split instruction memory and data memory use instruction buffer Reg Mem Reg 11
12 Insert Stall Time (clock cycles) I n s t r. O r d e r Ld/St Instr 1 Instr 2 Stall Instr 3 Mem Reg Mem Reg Mem Reg Mem Reg Mem Reg Mem Reg Bubble Bubble Bubble Bubble Bubble Mem Reg Mem Reg 12
13 Split instruction and data memory Time (clock cycles) I n s t r. Ld/St Instr 1 IM Reg DM Reg IM Reg DM Reg O r d e r Instr 2 Instr 3 IM Reg DM Reg IM Reg DM Reg Split instruction and data memory / multiple memory port / instruction buffer means: fetch the instruction and data inference using different hardware resources. 13
14 三 Not fully pipelined function unit Unpipelined Float Adder ADDD IF ID ADDD WB ADDD IF ID stall stall stall stall stall ADDD Not fully pipelined Adder ADDD IF ID A1 A2 A3 WB ADDD IF ID stall A1 A2 A3 Fully pipelined Adder ADDD IF ID A1 A2 A3 A4 A5 A6 WB ADDD IF ID A1 A2 A3 A4 A5 A6 WB Or multiple unpipelined Float Adder ADDD IF ID ADDD1 WB ADDD IF ID ADDD2 WB 14
15 四 Why allow machine with structural hazard? To reduce cost. i.e. adding split caches, requires twice the memory bandwidth. also fully pipelined floating point units costs lots of gates. It is not worth the cost if the hazard does not occur very often. To reduce latency of the unit. Making functional units pipelined adds delay (pipeline overhead -> registers.) An unpipelined version may require fewer clocks per operation. Reducing latency has other performance benefits, as we will see. 15
16 Example: impact of structural hazard to performance Example Many machines have unpipelined float-point multiplier. The function unit time of FP multiplier is 6 clock cycles FP multiply has a frequency of 14% in a SPECfp benchmark Will the structural hzard have a large performance impact on the SPECfp benchmark? 16
17 Answer to the example In the best case: FP multiplies are distributed uniformly. There is one multiply in every 7 clock. 1/(14%) Then there will be no structural hazard,then there is no performance penalty at all. In the worst case: the multiplies are all clustered with no intervening instructions. Then every multiply instruction have to stall 5 clock cycles to wait for the multiplier be released. The CPI will increase 70% to 1.7, if the ideal CPI is 1. Experiment result: This structural hazard increase execution time by less than 3%. 17
18 3.3.4 Pipelining Data Hazards Taxonomy of Hazards Structural hazards These are conflicts over hardware resources. Data hazards Instruction depends on result of prior computation which is not ready (computed or stored) yet Control hazards branch condition and the branch PC are not available in time to fetch an instruction on the next clock 18
19 一 Data hazard Data hazards occur when the pipeline changes the order of read/write accesses to operands comparing with that in sequential executing. Let s see an Example DADD R1, R1, R3 DSUB R4, R1, R5 AND R6, R1, R7 OR XOR R8, R1, R9 R10, R1, R11 19
20 Data hazard Basic structure An instruction in flight wants to use a data value that s not done yet Done means it s been computed and it s located where I would normally expect to go look in the pipe hardware to find it Basic cause You are used to assuming a purely sequential model of instruction execution Instruction N finishes before instruction N+k, for k >= 1 There are dependencies now between nearby instructions ( near in sequential order of fetch from memory) Consequence Data hazards -- instructions want data values that are not done yet, or in the right place yet 20
21 Coping with data hazards:example Time ( clock cycle) I n s t r. ADD R1,R2,R3 SUB R4, R1, R5 IM Reg IM R1, read DM R1 w DM Reg. O r d e r AND R6,R1,R7 OR R8,R1,R9 XOR R10,R1,R11 No Hazrd IM R1, read IM R1, read DM IM R1, read 21
22 二 Somecases Double Bump can do! Time ( clock cycle) I n s t r. ADD R1,R2,R3 SUB R4, R1, R5 IM Reg IM R1, read DM R1 w DM Reg. O r d e r AND R6,R1,R7 OR R8,R1,R9 double bump can do! XOR R10,R1,R11 No Hazard IM R1, read IM R1, read DM IM R1, read 22
23 三 Proposed solution STALL Proposed solution Don t let them overlap like this? Mechanics Don t let the instruction flow through the pipe In particular, don t let it WRITE any bits anywhere in the pipe hardware that represents REAL CPU state (e.g., register file, memory) Let the instruction wait until the hazard resolved. Name for this operation: PIPELINE STALL 23
24 How do we stall? Insert nop by compiler Time ( clock cycle) I n s t r. ADD R1,R2,R3 NOP IM Reg DM R1 w Bubble Bubble Bubble Bubble Bubble. O r d e r NOP (ADD R0, R0, R0) SUB R4,R1,R5 double bump can do! AND R6, R1,R7 No Hazard Bubble Bubble Bubble Bubble IM R1, read IM R1, read 24
25 How do we stall? Add hardware Interlock! Add extra hardware to detect stall situations Watches the instruction field bits Looks for read versus write conflicts in particular pipe stages Basically, a bunch of careful case logic Add extra hardware to push bubbles thru pipe Actually, relatively easy Can just let the instruction you want to stall GO FORWARD through the pipe but, TURN OFF the bits that allow any results to get written into the machine state So, the instruction executes (it does the work), but doesn t save 25
26 Interlock: insert stalls Time ( clock cycle) I n s t r.. O r d e r ADD R1,R2,R3 DSUB, R4, R1,R5 AND R6,R1,R7 IM Reg IM No Hazard Bubble DM Bubble Empty slots in the pipe called bubbles; means no real instruction work getting saved here R1 w R1, read IM R1, read 26
27 Detect: Data Hazard Logic Rs =? Rd Rt =? Rd between IF/ID and ID/EX, EX/MEM Stages Rs Rt Rd Rd Rd 27
28 四 Forwarding If the result you need does not exist AT ALL yet, you are out of luck, sorry. But, what if the result exists, but is not stored back yet? Instead of stalling until the result is stored back in its natural home grab the result on the fly from inside the pipe, and send it to the other instruction (another pipe stage) that wants to use it 28
29 Forwarding Generic name: forwarding ( bypass, shortcircuiting) Instead of waiting to store the result, we forward it immediately (more or less) to the instruction that wants it Mechanically, we add buses to the datapath to move these values around, and these buses always point backwards in the datapath, from later stages to earlier stages 29
30 Forwarding: reduce data hazard stalls Data may be already computed - just not in the Register File Time ( clock cycle) I n s t r.. O r d e r ADD R1,R2,R3 SUB R4, R1, R5 AND R6,R1,R7 IM Reg IM R1, read IM R1 DM R1, read R1 R1 w DM Reg DM EX/MEM.output input port MEM/WB.output input port 30
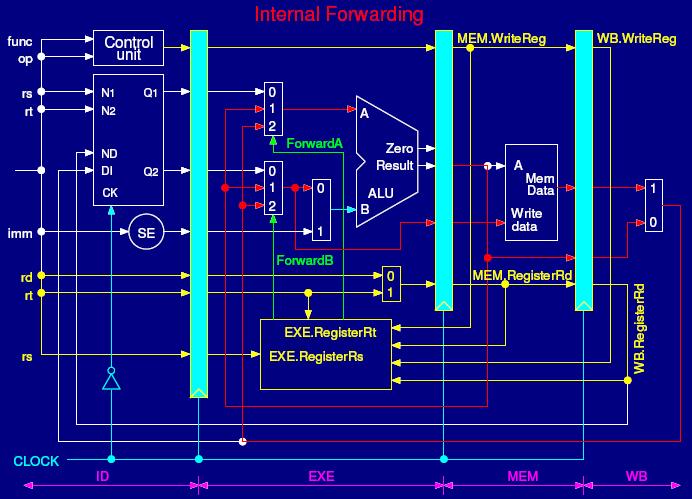
31 Hardware Change for Forwarding NextPC Registers Immediate ID/EX mux mux EX/MEM Data Memory MEM/WR mux EX/Mem.output input MEM/WB.output input MEM/WB.LMD input 31
32 Forwarding path to other input entry store MEM/WB.LMD DM input load 32
33 33

34 34
35 Forwarding isn t Always availability 35
36 So we have to insert stall: Load stall Time (clock cycles) I n s t r. O r d e r lw r1, 0(r2) sub r4,r1,r6 and r6,r1,r7 or r8,r1,r9 Ifetch Reg Ifetch Reg Ifetch DMem Bubble Bubble Bubble Reg Reg Ifetch DMem Reg Reg DMem Reg DMem 36
37 Solution (without forwarding) 37
38 Solution (with forwarding) 38
39 The performance influence of load stall Example Assume 30% of the instructions are loads. Half the time, instruction following a load instruction depends on the result of the load. If hazard causes a single cycle delay, how much faster is the ideal pipeline? Answer CPI = 1+30% 50% 1=1.15 The performance decrease about 15% due to load stall. 39

40 Fraction of loads that cause a stall Fraction of load that cause a stall 45% 40% 41% 35% 30% 25% 24% 23% 24% 20% 20% 20% 15% 10% 5% 12% 10% 10% 4% 0% 40
41 五 Instruction reordering by compiler to avoid load stall Try producing fast code for a = b + c; d = e f; assuming a, b, c, d,e, and f in memory. Slow code: LW LW ADD SW LW LW SUB SW Rb,b Rc,c Ra,Rb,Rc a,ra Re,e Rf,f Rd,Re,Rf d,rd Fast code: LW LW LW ADD LW SW SUB SW Rb,b Rc,c Re,e Ra,Rb,Rc Rf,f a,ra Rd,Re,Rf d,rd 41
42 3.3.5 Pipelining Control Hazards Taxonomy of Hazards Structural hazards These are conflicts over hardware resources. Data hazards Instruction depends on result of prior computation which is not ready (computed or stored) yet OK, we did these, Double Bump, Forwarding path, software scheduling, otherwise have to stall Control hazards branch condition and the branch PC are not available in time to fetch an instruction on the next clock 42
Pipeline Review. Review
 Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipelining: Hazards Ver. Jan 14, 2014
 POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
COSC4201 Pipelining. Prof. Mokhtar Aboelaze York University
 COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
What is Pipelining? Time per instruction on unpipelined machine Number of pipe stages
 What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
What is Pipelining? RISC remainder (our assumptions)
") What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
Lecture 3. Pipelining. Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1
 Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Modern Computer Architecture
 Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Overview. Appendix A. Pipelining: Its Natural! Sequential Laundry 6 PM Midnight. Pipelined Laundry: Start work ASAP
 Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Appendix A. Overview
 Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation
 Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
Advanced Computer Architecture Pipelining
 Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
DLX Unpipelined Implementation
 LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
Pipelining. Maurizio Palesi
 * Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
* Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
CPE Computer Architecture. Appendix A: Pipelining: Basic and Intermediate Concepts
 CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. Complications With Long Instructions
 CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Appendix C. Abdullah Muzahid CS 5513
 Appendix C Abdullah Muzahid CS 5513 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero) Single address mode for load/store: base + displacement no indirection
Appendix C Abdullah Muzahid CS 5513 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero) Single address mode for load/store: base + displacement no indirection
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Pipelining: Basic and Intermediate Concepts
 Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of fpipelining i Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 Unpipelined
Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of fpipelining i Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 Unpipelined
Pipelining. Each step does a small fraction of the job All steps ideally operate concurrently
 Pipelining Computational assembly line Each step does a small fraction of the job All steps ideally operate concurrently A form of vertical concurrency Stage/segment - responsible for 1 step 1 machine
Pipelining Computational assembly line Each step does a small fraction of the job All steps ideally operate concurrently A form of vertical concurrency Stage/segment - responsible for 1 step 1 machine
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Appendix C: Pipelining: Basic and Intermediate Concepts
 Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
The Processor Pipeline. Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes.
 The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
mywbut.com Pipelining
 Pipelining 1 What Is Pipelining? Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. Today, pipelining is the key implementation technique used to make
Pipelining 1 What Is Pipelining? Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. Today, pipelining is the key implementation technique used to make
Lecture 9. Pipeline Hazards. Christos Kozyrakis Stanford University
 Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
ECEC 355: Pipelining
 ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
Outline. Pipelining basics The Basic Pipeline for DLX & MIPS Pipeline hazards. Handling exceptions Multi-cycle operations
 Pipelining 1 Outline Pipelining basics The Basic Pipeline for DLX & MIPS Pipeline hazards Structural Hazards Data Hazards Control Hazards Handling exceptions Multi-cycle operations 2 Pipelining basics
Pipelining 1 Outline Pipelining basics The Basic Pipeline for DLX & MIPS Pipeline hazards Structural Hazards Data Hazards Control Hazards Handling exceptions Multi-cycle operations 2 Pipelining basics
C.1 Introduction. What Is Pipelining? C-2 Appendix C Pipelining: Basic and Intermediate Concepts
 C-2 Appendix C Pipelining: Basic and Intermediate Concepts C.1 Introduction Many readers of this text will have covered the basics of pipelining in another text (such as our more basic text Computer Organization
C-2 Appendix C Pipelining: Basic and Intermediate Concepts C.1 Introduction Many readers of this text will have covered the basics of pipelining in another text (such as our more basic text Computer Organization
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
HY425 Lecture 05: Branch Prediction
 HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Advanced Computer Architecture
 ECE 563 Advanced Computer Architecture Fall 2010 Lecture 2: Review of Metrics and Pipelining 563 L02.1 Fall 2010 Review from Last Time Computer Architecture >> instruction sets Computer Architecture skill
ECE 563 Advanced Computer Architecture Fall 2010 Lecture 2: Review of Metrics and Pipelining 563 L02.1 Fall 2010 Review from Last Time Computer Architecture >> instruction sets Computer Architecture skill
Pipelining! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar DEIB! 30 November, 2017!
 Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Advanced Topics on Heterogeneous System Architectures Pipelining! Politecnico di Milano! Seminar Room @ DEIB! 30 November, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Outline!
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Appendix C. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Appendix C Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure C.2 The pipeline can be thought of as a series of data paths shifted in time. This shows
Appendix C Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure C.2 The pipeline can be thought of as a series of data paths shifted in time. This shows
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
Lecture 5: Pipelining Basics
 Lecture 5: Pipelining Basics Biggest contributors to performance: clock speed, parallelism Today: basic pipelining implementation (Sections A.1-A.3) 1 The Assembly Line Unpipelined Start and finish a job
Lecture 5: Pipelining Basics Biggest contributors to performance: clock speed, parallelism Today: basic pipelining implementation (Sections A.1-A.3) 1 The Assembly Line Unpipelined Start and finish a job
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
ECE473 Computer Architecture and Organization. Pipeline: Control Hazard
 Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
CSE 502 Graduate Computer Architecture. Lec 3-5 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
EE557--FALL 1999 MAKE-UP MIDTERM 1. Closed books, closed notes
 NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
NAME: STUDENT NUMBER: EE557--FALL 1999 MAKE-UP MIDTERM 1 Closed books, closed notes Q1: /1 Q2: /1 Q3: /1 Q4: /1 Q5: /15 Q6: /1 TOTAL: /65 Grade: /25 1 QUESTION 1(Performance evaluation) 1 points We are
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSE 502 Graduate Computer Architecture. Lec 3-5 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Moore s Law Gordon Moore @ Intel (1965) 2 Computer Architecture Trends (1)
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Chapter 4 (Part II) Sequential Laundry
 Sequential Laundry") Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
Chapter 4 (Part II) The Processor Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Sequential Laundry 6 P 7 8 9 10 11 12 1 2 A T a s k O r d e r A B C D 30 30 30 30 30 30 30 30 30 30
ECE 154A Introduction to. Fall 2012
 ECE 154A Introduction to Computer Architecture Fall 2012 Dmitri Strukov Lecture 10 Floating point review Pipelined design IEEE Floating Point Format single: 8 bits double: 11 bits single: 23 bits double:
ECE 154A Introduction to Computer Architecture Fall 2012 Dmitri Strukov Lecture 10 Floating point review Pipelined design IEEE Floating Point Format single: 8 bits double: 11 bits single: 23 bits double:
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
ECE331: Hardware Organization and Design Lecture 27: Midterm2 review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Midterm 2 Review Midterm will cover Section 1.6: Processor
Overview of Pipelining
 EEC 58 Compter Architectre Pipelining Department of Electrical Engineering and Compter Science Cleveland State University Fndamental Principles Overview of Pipelining Pipelined Design otivation: Increase
EEC 58 Compter Architectre Pipelining Department of Electrical Engineering and Compter Science Cleveland State University Fndamental Principles Overview of Pipelining Pipelined Design otivation: Increase
Processor Architecture
 Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong (jinkyu@skku.edu)
Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong (jinkyu@skku.edu)
CSE 502 Graduate Computer Architecture. Lec 4-6 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 4-6 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 4-6 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
CS 61C: Great Ideas in Computer Architecture. Lecture 13: Pipelining. Krste Asanović & Randy Katz
 CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http://inst.eecs.berkeley.edu/~cs61c/fa17 RISC-V Pipeline Pipeline Control Hazards Structural Data R-type
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
ECS 154B Computer Architecture II Spring 2009
 ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
Lecture 2: Pipelining Basics. Today: chapter 1 wrap-up, basic pipelining implementation (Sections A.1 - A.4)
") Lecture 2: Pipelining Basics Today: chapter 1 wrap-up, basic pipelining implementation (Sections A.1 - A.4) 1 Defining Fault, Error, and Failure A fault produces a latent error; it becomes effective when
Lecture 2: Pipelining Basics Today: chapter 1 wrap-up, basic pipelining implementation (Sections A.1 - A.4) 1 Defining Fault, Error, and Failure A fault produces a latent error; it becomes effective when