CS377P Programming for Performance GPU Programming - I
|
|
|
- Kory Knight
- 6 years ago
- Views:
Transcription
1 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015
2 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance
3 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance
4 Background Discrete GPUs CUDA
5 Basics CUDA is a C++ dialect extra keywords extra semantics CUDA code consists of: device code (executes on the GPU) host code (executes on the CPU) execution always starts on the CPU CUDA compiler is nvcc
6 First CUDA program: Vector addition void vector_add(int *a, int *b, int *c, int N) { for(int i = 0; i < N; i++) { c[i] = a[i] + b[i]; } } int main(void) {... vector_add(a, b, c, N); }
7 Kernels: global keyword global void vector_add(int *a, int *b, int *c, int N) {... } int main(void) {... vector_add<<<...>>>(a, b, c, N); } The global keyword indicates a GPU kernel GPU kernels must be called with a configuration
8 Kernels: Configuration GPU kernels are SPMD kernels All threads execute the same code Number of threads to execute is specified at launch time As a grid of B thread blocks of T threads each Total threads: B T Reason: Only threads within the same thread block can communicate with each other (cheaply) Other reasons too, but this is the only algorithm-specific reason
9 Determining the Configuration: Work Size Determine a thread block size: say, 256 threads Divide work by thread block size Round up N/256 Configuration can be changed every call int threads = 256; int Nup = (N + threads - 1) / threads; int blocks = Nup / threads; vector_add<<<blocks, threads>>>(...)
10 Distributing work in the kernel global vector_add(int *a, int *b, int *c, int N) { int tid = threadidx.x + blockidx.x * blockdim.x; } if(tid < N) { c[tid] = a[tid] + b[tid]; } Maximum 2 32 threads supported griddim, blockdim, blockidx and threadidx are CUDA-provided variables
11 CUDA vector add so far global vector_add(int *a, int *b, int *c, int N) { int tid = threadidx.x + blockidx.x * blockdim.x; } if(tid < N) { c[tid] = a[tid] + b[tid]; } int main(void) { int threads = 256; int Nup = (N + threads - 1) / threads; int blocks = Nup / threads;... } vector_add<<<blocks, threads>>>(a, b, c, N);
12 CUDA vector add: GPU memory GPU can t read CPU memory directly by default Arrays a, b need to be copied to GPU memory The result c needs to be copied back to CPU memory Two CUDA functions: cudamalloc allocates GPU memory cudamemcpy copies memory between CPU and GPU
13 CUDA vector add with GPU memory int *g_a, *g_b, *g_c; cudamalloc(&g_a, sizeof(a[0]) * N); cudamalloc(&g_b, sizeof(b[0]) * N); cudamalloc(&g_c, sizeof(c[0]) * N); cudamemcpy(g_a, a, sizeof(a[0]) * N, cudamemcpyhosttodevice); cudamemcpy(g_b, b, sizeof(b[0]) * N, cudamemcpyhosttodevice); vector_add<<<...>>>(g_a, g_b, g_c, N); cudamemcpy(c, g_c, sizeof(c[0]) * N, cudamemcpydevicetohost);
14 CUDA vector add: complete? global vector_add(int *a, int *b, int *c, int N) { int tid = threadidx.x + blockidx.x * blockdim.x; } if(tid < N) { c[tid] = a[tid] + b[tid]; } int main(void) { int threads = 256; int Nup = (N + threads - 1) / threads; int blocks = Nup / threads; cudamalloc(&g_a, sizeof(a[0]) * N); cudamalloc(&g_b, sizeof(b[0]) * N); cudamalloc(&g_c, sizeof(c[0]) * N); cudamemcpy(g_a, a, sizeof(a[0]) * N, cudamemcpyhosttodevice); cudamemcpy(g_b, b, sizeof(b[0]) * N, cudamemcpyhosttodevice); vector_add<<<blocks, threads>>>(g_a, g_b, g_c, N); } cudamemcpy(c, g_c, sizeof(c[0]) * N, cudamemcpydevicetohost);
15 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance
16 Heterogeneous Systems GPU + CPU form a heterogeneous system A system with non-trivial choices of where to perform a computation Parallel execution is possible CPU and GPU can work independently in parallel In fact, GPU allows data transfers in parallel to GPU execution Consider distributing work so that all execution units (CPU and GPU) are fully utilized Not easy to do manually, but no automatic solution widely accepted yet
17 Measurement Pitfalls Keep in mind: A GPU program is a parallel CPU program i.e. GPU code sometimes runs on a separate thread A CPU + GPU system is a distributed system i.e. clocks are unsynchronized especially across GPU cores Use timelines not intervals to reason about performance timelines capture overlap timelines illustrate critical path NVIDIA Profiler provides timelines
18 How NOT to time a GPU kernel struct stopwatch va; clock_start (&va ) ; vector_add_1 <<<14*8, 384>>>(ga, gb, gc, N) ; clock_stop (&va) ; printf (TIMEFMT "s \n", va.elapsed.tv_sec, va.elapsed.tv_nsec ) ; Output is approx. 40µs on my machine NVIDIA Compute Profiler: gputime=[ ] (µs)

19 Vector Addition Performance

20 Vector Addition Performance
21 How many threads: GPU Occupancy CPU threads share resources by time multiplexing One thread owns all CPU resources (registers, etc.) for its time slice Context-switches are performed by OS GPU threads do not share resources Own fixed partition of resources for entire lifetime of thread Context-switches are performed by hardware every few cycles Changing number of threads changes utilization of resources
22 GPU Resources per SM (NVIDIA Kepler) Resource Available Maximum Threads /block Shared Memory 48K (max) 48K/block Registers /thread Thread Blocks 16 16/SM Every block consumes: T threads T R registers where R is registers per thread 1 block SM shared memory per block (optional) The resource that gets exhausted first determines occupancy and residency Occupancy: number of hardware threads utilized Residency: number of hardware blocks utilized
23 GPU Occupancy: Example 1 kernel<<<2048, 32>>>() T = 32 thread limit 2048/32 = 64 thread blocks R = 100 ( = 3200 per thread block) register limit 65536/3200 = 20 thread blocks SM = 1K SM limit 48K/1K = 48 thread blocks Limiting resource: thread blocks (16) Residency: 16 Occupancy: (16 32)/2048 = 25%
24 GPU Occupancy: Example 2 kernel<<<2048, 64>>>() T = 64 thread limit 2048/64 = 32 thread blocks R = 100 ( = 6400 per thread block) register limit 65536/6400 =? thread blocks SM = 1K SM limit 48K/1K = 48 thread blocks Limiting resource:? Residency:? Occupancy: (? 64)/2048 =?%
25 How many threads? Try to maximize utilization (NVIDIA Manual) Next class: Better strategy
26 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance
27 Data Layout for GPU programs (AoS) struct pt { int x; int y; }; global void aos_kernel(int n_pts, struct pt *p) { int tid = blockidx.x * blockdim.x + threadidx.x; int nthreads = blockdim.x * griddim.x; } for(int i = tid; i < n_pts; i += nthreads) { p[i].x = i; p[i].y = i * 10; } In main(): struct pt *p; cudamalloc(&p,...)
28 Data Layout for GPU programs (SoA) struct pt { int *x; int *y; }; global void soa_kernel(int n_pts, struct pt p) { int tid = blockidx.x * blockdim.x + threadidx.x; int nthreads = blockdim.x * griddim.x; } for(int i = tid; i < n_pts; i += nthreads) { p.x[i] = i; p.y[i] = i * 10; } In main(): struct pt p; cudamalloc(&p.x,...) cudamalloc(&p.y,...)
29 AoS vs SoA for GPU programs Array of Structures Structure of Arrays Which is better for CPU? Which is better for GPU?
30 AoS memory layout transaction boundary transaction boundary p[0].x p[0].y p[1].x p[1].y p[2].x p[2].y p[3].x p[3].y p[4].x p[4].y p[i].x memory bandwidth utilization?
31 SoA memory layout transaction boundary transaction boundary p.x[0] p.x[1] p.x[2] p.x[3] p.x[4] p.x[5] p.x[6] p.x[7] p.x[8] p.x[9] p.y[0] p.y[1] p.y[2] p.y[3] p.y[4] p.y[5] p.y[6] p.y[7] p.y[8] p.x[9] p.x[i] memory bandwidth utilization?
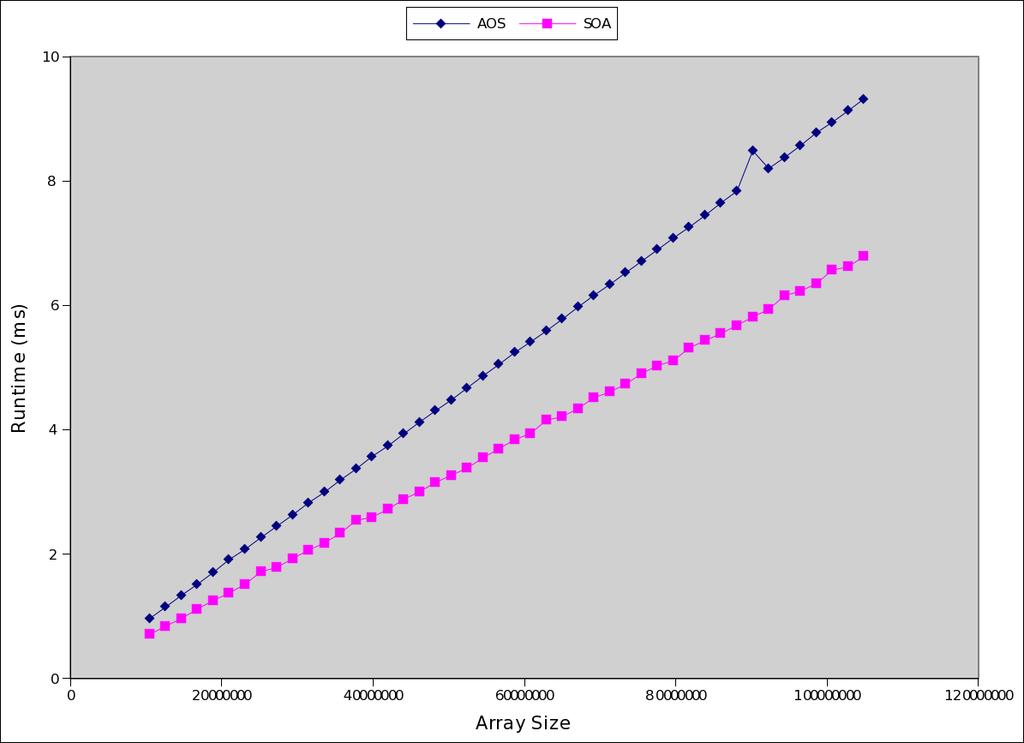
32 AoS vs SoA Performance

33 AoS vs SoA: Number of Memory Transactions
34 Assigning Work to Threads Blocked: start = tid * blksize; end = start + blksize; for(i = start; i < N && i < end; i++) a[i] = b[i] + c[i] Interleaved: start = tid; for(i = start; i < N; i+=nthreads) a[i] = b[i] + c[i] Which, if any, is faster?

35 Blocking vs Interleaved
36 Exploiting Spatial Locality: Texture Caches Textures are 2-D images that are wrapped around 3-D models Exhibit 2-D locality, so textures have a separate cache GPU contains a texture fetch unit that non-graphics programs can also use Step 1: map arrays to textures Step 2: replace array reads by tex1dfetch(), tex2dfetch() Catch: Only read-only data can be cached you can write to the array, but it may not become visible through the texture in the same kernel call i.e. texture caches are not coherent with GPU memory Easiest way to use textures: const restrict * Compiler will automatically use texture cache for marked arrays
37 Exploiting Locality: Shared Memory Shared Memory is on-chip software-managed cache, also known as a scratchpad 48K maximum size Partitioned among thread blocks shared qualifier places variables in shared memory Can be used for communicating between threads of the same thread block shared int x; if(threadidx.x == 0) x = 1; syncthreads(); //required! printf("%d\n", x);
;")
38 Shared Memory (SGEMM) shared float c_sub[blocksize][blocksize]; // calculate c_sub syncthreads(); // write out c_sub to memory
39 Constant Data Cache 64KB of constant data not written by kernel Suitable for read-only, broadcast data All threads in a warp read the same constant data item at the same time what type of locality is this? Uses: Filter coefficients 2dconv: convolution matrix entries
40 Summary of Memory Performance Layout data structures in memory to maximize bandwidth utilization Assign work to threads to maximize bandwidth utilization Rethink caching strategies identify readonly data identify blocks that you can load into shared memory identify tables of constants
41 To be continued...
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA
 CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
CUDA. More on threads, shared memory, synchronization. cuprintf
 CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
Automatic translation from CUDA to C++ Luca Atzori, Vincenzo Innocente, Felice Pantaleo, Danilo Piparo
 Automatic translation from CUDA to C++ Luca Atzori, Vincenzo Innocente, Felice Pantaleo, Danilo Piparo 31 August, 2015 Goals Running CUDA code on CPUs. Why? Performance portability! A major challenge faced
Automatic translation from CUDA to C++ Luca Atzori, Vincenzo Innocente, Felice Pantaleo, Danilo Piparo 31 August, 2015 Goals Running CUDA code on CPUs. Why? Performance portability! A major challenge faced
CUDA Programming. Aiichiro Nakano
 CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
GPU programming: CUDA. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA Kenjiro Taura 1 / 36
 CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
Speed Up Your Codes Using GPU
 Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
MIC-GPU: High-Performance Computing for Medical Imaging on Programmable Graphics Hardware (GPUs)
") MIC-GPU: High-Performance Computing for Medical Imaging on Programmable Graphics Hardware (GPUs) CUDA API Klaus Mueller, Ziyi Zheng, Eric Papenhausen Stony Brook University Function Qualifiers Device Global,
MIC-GPU: High-Performance Computing for Medical Imaging on Programmable Graphics Hardware (GPUs) CUDA API Klaus Mueller, Ziyi Zheng, Eric Papenhausen Stony Brook University Function Qualifiers Device Global,
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES. Stephen Jones, GTC 2017
 CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Massively Parallel Algorithms
 Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
COSC 462 Parallel Programming
 November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
CUDA Parallel Programming Model Michael Garland
 CUDA Parallel Programming Model Michael Garland NVIDIA Research Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of a parallel
CUDA Parallel Programming Model Michael Garland NVIDIA Research Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of a parallel
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
Programming with CUDA, WS09
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
An Introduction to GPU Computing and CUDA Architecture
 An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Real-time Graphics 9. GPGPU
 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
CUDA Parallel Programming Model. Scalable Parallel Programming with CUDA
 CUDA Parallel Programming Model Scalable Parallel Programming with CUDA Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of
CUDA Parallel Programming Model Scalable Parallel Programming with CUDA Some Design Goals Scale to 100s of cores, 1000s of parallel threads Let programmers focus on parallel algorithms not mechanics of
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
CUDA Basics. July 6, 2016
 Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
CUDA. Sathish Vadhiyar High Performance Computing
 CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Zero-copy. Table of Contents. Multi-GPU Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Zero-copy. Multigpu.
 Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
Basic CUDA workshop. Outlines. Setting Up Your Machine Architecture Getting Started Programming CUDA. Fine-Tuning. Penporn Koanantakool
 Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
GPU programming CUDA C. GPU programming,ii. COMP528 Multi-Core Programming. Different ways:
 COMP528 Multi-Core Programming GPU programming,ii www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Different ways: GPU programming
COMP528 Multi-Core Programming GPU programming,ii www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Different ways: GPU programming
simcuda: A C++ based CUDA Simulation Framework
 Technical Report simcuda: A C++ based CUDA Simulation Framework Abhishek Das and Andreas Gerstlauer UT-CERC-16-01 May 20, 2016 Computer Engineering Research Center Department of Electrical & Computer Engineering
Technical Report simcuda: A C++ based CUDA Simulation Framework Abhishek Das and Andreas Gerstlauer UT-CERC-16-01 May 20, 2016 Computer Engineering Research Center Department of Electrical & Computer Engineering
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
GPU COMPUTING. Ana Lucia Varbanescu (UvA)
") GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
Introduction to CUDA C
 Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race