Introduction to CELL B.E. and GPU Programming. Agenda
|
|
|
- Alan Gallagher
- 6 years ago
- Views:
Transcription
1 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources Sources: IBM Cell Programming Workshop, 03/02/2008, GaTech UIUC course Programming Massively Parallel Processors, Fall 2007 CUDA Programming Guide, Version 2, 06/2008, NVIDIA Corp. 1
2 Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources GPU / CPU Performance GT200 = Telsa T10P ~1000 GFLOPS Cell B.E. 200Gflops 8 SPEs 3.0G Xeon Quad Core ~80 GFLOPS June 2008 Single Precision Floating-Point Operations per Second for the CPU and GPU* *Source: NVIDIA 2




3 Successful Projects Source: Major Limiters to Processor Performance ILP Wall Diminishing returns from deeper pipeline Wall DRAM latency vs. processor cores frequency Power Wall Limits in CMOS technology System power density P P P P TDP 80~150W TDP 160 W The amount of transistors doing direct computation is shrinking relative to the total number of transistors. 3



4 * Chip level multi-processors Vector Units/SIMD Rethink memory organization *Jack Dongarra, An Overview of High Performance Computing and Challenges for the Future, SIAM Annual Meeting, San Diego, CA, July 7, Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources 4




5 Cell B.E. Highlights (3.2GHz) Cell B.E. Products 5


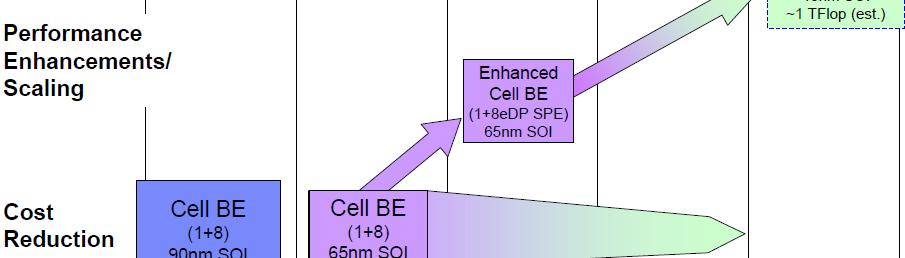
6 Roadrunner Cell B.E. Architecture Roadmap 6




7 Cell B.E. Block Diagram SPU Core: Registers & Logic Channel Unit: Message passing interface for I/O Local Store: 256KB of SRAM private to the SPU Core DMA Unit: Transfers data between Local Store and Main PPE and SPE Architectural Difference 7


8 Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources Cell Software Environment 8


 handles SPE process")

9 Cell/BE Basic Programming Concepts The PPE is just a PowerPC running Linux. No special programming techniques or compilers are needed. The PPE manages SPE processes as POSIX pthreads*. IBM-provided library (libspe2) handles SPE process management within the threads. Compiler tools embed SPE executables into PPE executables: one file provides instructions for all execution units. Control & Data Flow of PPE & SPE 9
10 PPE Programming Environment PPE runs PowerPC applications and operating system PPE handles thread allocation and resource management among SPEs PPE s Linux kernel controls the SPUs execution of programs Schedule SPE execution independent from regular Linux threads Responsible for runtime loading, passing parameters to SPE programs, notification of SPE events and errors, and debugger support PPE s Linux kernel manages virtual memory, including mapping each SPE s local store (LS) and problem state (PS) into the effectiveaddress space The kernel also controls virtual-memory mapping of MFC resources, as well as MFC segment-fault and page-fault handling Large pages (16-MB pages, using the hugetlbfs Linux extension) are supported Compiler tools embed SPE executables into PPE executables SPE Programming Environment Each SPE has a SIMD instruction set, 128 vector registers and two in-order execution units, and no operating system Data must be moved between main memory and the 256 KB of SPE local store with explicit DMA commands Standard compilers are provided GNU and XL compilers, C, C++ and Fortran Will compile scalar code into the SIMD-only SPE instruction set Language extensions provide SIMD types and instructions. SDK provides math and programming libraries as well as documentation The programmer must handle A set of processors with varied strengths and unequal access to data and communication Data layout and SIMD instructions to exploit SIMD utilization Local store management (data locality and overlapping communication and computational) 10
11 PPE C/C++ Language Extensions (Intrinsics) C-language extensions: vector data types and vector commands (Intrinsics) Intrinsics - inline assembly-language g instructions Vector data types 128-bit vector types Sixteen 8-bit values, signed or unsigned Eight 16-bit values, signed or unsigned Four 32-bit values, signed or unsigned Four single-precision IEEE-754 floating-point values Example: vector signed int: 128-bit operand containing four 32-bit signed ints Vector intrinsics Specific Intrinsics Intrinsics that have a one-to-one mapping with a single assembly-language instruction Generic Intrinsics Intrinsics that map to one or more assembly-language instructions as a function of the type of input parameters Predicates Intrinsics Intrinsics that compare values and return an integer that may be used directly as a value or as a condition for branching SPE C/C++ Language Extensions (Intrinsics) Vector Data Types Three classes of intrinsics Specific Intrinsics - one-to-one mapping with a single assemblylanguage instruction prefixed by the string, si_ e.g., si_to_char // Cast byte element 3 of qword to char Generic Intrinsics and Built-Ins - map to one or more assemblylanguage instructions as a function of the type of input parameters prefixed by the string, spu_ e.g., d = spu_add(a, b) // Vector add Composite Intrinsics - constructed from a sequence of specific or generic intrinsics prefixed by the string, spu_ e.g., spu_mfcdma32(ls, ea, size, tagid, cmd) //Initiate DMA to or from 32- bit effective address 11
12 Hello World SPE code Compiled to hello_spu.o Hello World PPE: Single 12
 are provided for sending messages from the SPE to the PPE")
13 Hello World PPE: Multi- PPE SPE Communication PPE communicates with SPEs through MMIO registers supported by the MFC of each SPE Three primary communication mechanisms between the PPE and SPEs Mailboxes Queues for exchanging 32-bit messages Two mailboxes (the SPU Write Outbound Mailbox and the SPU Write Outbound Interrupt Mailbox) are provided for sending messages from the SPE to the PPE One mailbox (the SPU Read Inbound Mailbox) is provided for sending messages to the SPE Signal notification registers Each SPE has two 32-bit signal-notification registers, each has a corresponding memory-mapped mapped I/O (MMIO) register into which the signal-notificationnotification data is written by the sending processor Signal-notification channels, or signals, are inbound (to an SPE) registers They can be used by other SPEs, the PPE, or other devices to send information, such as a buffer-completion synchronization flag, to an SPE DMAs To transfer data between main storage and the LS 13


14 Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources NVIDIA s Tesla T10P T10P chip 240 cores; 1.3~1.5 GHz Tpeak, 1 Tflop/s, 32bit, single precision Tpeak, 100 Gflop/s, 64bit, double precision IEEE 754r capabilities C1060 Card - PCIe 16x 1 T10P; 1.33 Ghz 4GB DRAM ~160W Tpeak ~936 Gflop S 1060 Computing Server 4 T10P devices ~700W 14


15 CPU vs. GPU: Models CPU One linear memory spaces Cached GPU Several memory spaces R/W capabilities Cached/non-cached Main cache register CPU Traditional C programs on CPU CUDA programs on GPU Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources 15
16 CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that: Is a coprocessor to the CPU or host Has its own DRAM (device memory) Runs many threads in parallel Data-parallel portions of an application are executed on the device as kernels which run in parallel on many threads Differences between GPU and CPU threads GPU threads are extremely lightweight Very little creation overhead GPU needs 1000s of threads for full efficiency Multi-core CPU needs only a few GPU Programming Model w/ CUDA Compute device CUDA kernels A grid of thread blocks CUDA kernel Source: NDVIA 16
17 Block and IDs s and blocks have IDs So each thread can decide Device what data to work on Block ID: 1D or 2D ID: 1D, 2D, or 3D Simplifies memory addressing when processing multidimensional data Image processing Solving PDEs on volumes (0, 0) (0, 1) Block (1, 1) (1, 0) (1, 1) Grid 1 Block (0, 0) Block (0, 1) (2, 0) (2, 1) Block (1, 0) Block (1, 1) (3, 0) (3, 1) (4, 0) (4, 1) Block (2, 0) Block (2, 1) (0, 2) (1, 2) (2, 2) (3, 2) (4, 2) Source: NDVIA CUDA Device Space Overview Each thread can: R/W per-thread registers R/W per-thread local memory R/W per-block shared memory R/W per-grid global memory Read only per-grid constant memory Read only per-grid texture memory The host can R/W global, constant, and texture memories Host (Device) Grid Block (0, 0) Block (1, 0) Registers Shared (0, 0) Registers (1, 0) Registers Shared (0, 0) Registers (1, 0) Local Local Local Local Global Constant Texture 17
18 Global, Constant, and Texture Memories (Long Latency Accesses) Global memory Main means of communicating R/W Data between host and device Contents visible to all threads Texture and Constant Memories Constants initialized by host Contents visible to all threads Host (Device) Grid Block (0, 0) Block (1, 0) Registers Local Shared Registers (0, 0) (1, 0) Global Constant Texture Local Registers Local Shared Registers (0, 0) (1, 0) Local Source: NDVIA Access Times Register dedicated HW - single cycle Shared dedicated HW - single cycle Local DRAM, no cache - *slow* Global DRAM, no cache - *slow* Constant DRAM, cached, 1 10s 100s of cycles, depending on cache locality Texture DRAM, cached, 1 10s 100s 10s 100s of cycles, depending on cache locality Instruction (invisible) DRAM, cached 18
19 CUDA Device Allocation cudamalloc() Allocates object in the device Global l Requires two parameters Address of a pointer to the allocated object Size of of allocated object cudafree() Frees object from device Global Pointer to freed object Host (Device) Grid Block (0, 0) Block (1, 0) Local Memor y Shared Register s (0, 0) Global Constant Texture Register s (1, 0) Local Memor y Local Memor y Shared Register s (0, 0) Register s (1, 0) Local Memor y CUDA Host-Device Data Transfer cudamemcpy( ) memory data transfer Requires four parameters Pointer to source Pointer to destination Number of bytes copied Type of transfer Host to Host Host to Device Device to Host Device to Device cudamemcpyasync( ) Host (Device) Grid Block (0, 0) Block (1, 0) Local Memor y Shared Register s (0, 0) Global Constant Texture Register s (1, 0) Local Memor y Local Memor y Shared Register s (0, 0) Register s (1, 0) Local Memor y 19
20 CUDA Function Declarations Executed on the: Only callable from the: device float DeviceFunc() device device global void KernelFunc() device host host float HostFunc() host host global defines a kernel function Must return void device and host can be used together CUDA Function Declarations (cont.) device functions cannot have their address taken For functions executed on the device: No recursion No static variable declarations inside the function No variable number of arguments 20
21 Language Extensions: Variable Type Qualifiers Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block device int GlobalVar; global grid application device constant int ConstantVar; constant grid application device is optional when used with local, shared, or constant Automatic variables without any qualifier reside in a register Except arrays that reside in local memory Calling a Kernel Function Creation A kernel function must be called with an execution configuration: global void KernelFunc(...); dim3 DimGrid(100, 50); // 5000 thread blocks dim3 DimBlock(4, 8, 8); // 256 threads per block size_t SharedMemBytes = 64; // 64 bytes of shared memory KernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...); Any call to a kernel function is asynchronous,explicit synch needed for blocking 21

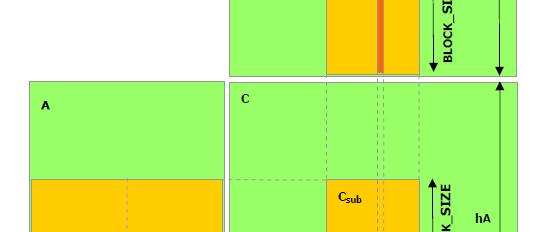
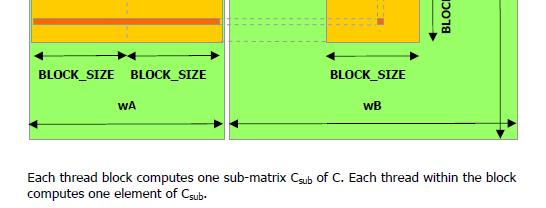
22 Dense Matrix Multiplication Dense Matrix Multiplication - Host Side 22





23 Dense Matrix Multiplication - Device Side Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources 23
24 Cell B.E. vs. Tesla T10P GPU Architecture Cell B.E. Tesla T10P Cores Heterogeneous 8 SPE/ 1 PPE (dual hreads). 3.2GHz. AltVec ISA Peak SP SPEs: 25.6x8=200 GFLOPS PPE: 25.6 GFLOPS PEAK DP SPEs: 14 GFLOPS, 102 GFLOPS (PowerXCell 8i) PPE: 6.4 GFLOPS* Uniform simple Processors; co-processor to CPU (30 Multiprocessors, 8 cores / MP, total 240 cores/threads), NVIDIA private ISA Peak SP 1T GFLOPS* Peak DP 125 GFLOPS* LS (256KB/spe), main memory (no direct Device, Shared (16Kb/MP) access for SPU) Bandwidth 128bits, 25GB/s to main memory. 512bits, 102GB/s to DRAM; PCIe 16x to CPU side (4GB/s one-way, 8GB/s bi-direction) Inter-core communication Programming Very fast, 204.8GB/s on EIB. mailbox, signal, DMA C/C++ Extensions, support Fortran, Stacks on SPE; full debug support 2-level SIMD; has to manually SIMD ize code SPE code length limitation. Library FFT, BLAS, High level Acceleration Lib, FFT, BLAS Local barrier, Shard memory, or return to CPU for global sync. DMA to CPU memory C/C++ Extensions, no-stacks on GPU Cores; limited debug support 1-level SIMD, scalar unit exposed to programmer directly. Kernel code length limitation Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU Architecture Overview CUDA Programming Model A Comparison: CELL B.E. vs. GPU Resources 24



25 Cell Resources GPU Resources NVIDIA CUDA Center UIUC Course: Programming Massively Parallel Processors GP-GPU resources Books: GPU-GEMS 2/3 25
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
 with Nvidia CUDA. Libby Shoop") General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CIS 665: GPU Programming. Lecture 2: The CUDA Programming Model
 CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
CIS 665: GPU Programming Lecture 2: The CUDA Programming Model 1 Slides References Nvidia (Kitchen) David Kirk + Wen-Mei Hwu (UIUC) Gary Katz and Joe Kider 2 3D 3D API: API: OpenGL OpenGL or or Direct3D
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Intro to GPU s for Parallel Computing
 Intro to GPU s for Parallel Computing Goals for Rest of Course Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability across future
Intro to GPU s for Parallel Computing Goals for Rest of Course Learn how to program massively parallel processors and achieve high performance functionality and maintainability scalability across future
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Cell Programming Tips & Techniques
 Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Sony/Toshiba/IBM (STI) CELL Processor. Scientific Computing for Engineers: Spring 2008
 CELL Processor. Scientific Computing for Engineers: Spring 2008") Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
Cell Processor and Playstation 3
 Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Core/Many-Core Architectures and Programming. Prof. Huiyang Zhou
 ST: CDA 6938 Multi-Core/Many Core/Many-Core Architectures and Programming http://csl.cs.ucf.edu/courses/cda6938/ Prof. Huiyang Zhou School of Electrical Engineering and Computer Science University of Central
ST: CDA 6938 Multi-Core/Many Core/Many-Core Architectures and Programming http://csl.cs.ucf.edu/courses/cda6938/ Prof. Huiyang Zhou School of Electrical Engineering and Computer Science University of Central
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
1/25/12. Administrative
 Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
High Performance Computing
 GPGPU A Current Trend in High Performance Computing Chokchai Box Leangsuksun, PhD SWEPCO Endowed Professor*, Computer Science Director, High Performance Computing Initiative Louisiana Tech University box@latech.edu
GPGPU A Current Trend in High Performance Computing Chokchai Box Leangsuksun, PhD SWEPCO Endowed Professor*, Computer Science Director, High Performance Computing Initiative Louisiana Tech University box@latech.edu
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014
 GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014 Solutions to Parallel Processing Message Passing (distributed) MPI (library) Threads (shared memory) pthreads (library) OpenMP (compiler)
GPU Computation CSCI 4239/5239 Advanced Computer Graphics Spring 2014 Solutions to Parallel Processing Message Passing (distributed) MPI (library) Threads (shared memory) pthreads (library) OpenMP (compiler)
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Using The CUDA Programming Model
 Using The CUDA Programming Model Leveraging GPUs for Application Acceleration Dan Ernst, Brandon Holt University of Wisconsin Eau Claire 1 What is (Historical) GPGPU? General Purpose computation using
Using The CUDA Programming Model Leveraging GPUs for Application Acceleration Dan Ernst, Brandon Holt University of Wisconsin Eau Claire 1 What is (Historical) GPGPU? General Purpose computation using
Parallel Systems Course: Chapter IV. GPU Programming. Jan Lemeire Dept. ETRO November 6th 2008
 Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
GPU Computing with CUDA. Part 2: CUDA Introduction
 GPU Computing with CUDA Part 2: CUDA Introduction Dortmund, June 4, 2009 SFB 708, AK "Modellierung und Simulation" Dominik Göddeke Angewandte Mathematik und Numerik TU Dortmund dominik.goeddeke@math.tu-dortmund.de
GPU Computing with CUDA Part 2: CUDA Introduction Dortmund, June 4, 2009 SFB 708, AK "Modellierung und Simulation" Dominik Göddeke Angewandte Mathematik und Numerik TU Dortmund dominik.goeddeke@math.tu-dortmund.de
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Cell SDK and Best Practices
 Cell SDK and Best Practices Stefan Lutz Florian Braune Hardware-Software-Co-Design Universität Erlangen-Nürnberg siflbrau@mb.stud.uni-erlangen.de Stefan.b.lutz@mb.stud.uni-erlangen.de 1 Overview - Introduction
Cell SDK and Best Practices Stefan Lutz Florian Braune Hardware-Software-Co-Design Universität Erlangen-Nürnberg siflbrau@mb.stud.uni-erlangen.de Stefan.b.lutz@mb.stud.uni-erlangen.de 1 Overview - Introduction
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
COMP 635: Seminar on Heterogeneous Processors. Lecture 7: ClearSpeed CSX600 Processor.
 COMP 635: Seminar on Heterogeneous Processors Lecture 7: ClearSpeed CSX600 Processor www.cs.rice.edu/~vsarkar/comp635 Vivek Sarkar Department of Computer Science Rice University vsarkar@rice.edu October
COMP 635: Seminar on Heterogeneous Processors Lecture 7: ClearSpeed CSX600 Processor www.cs.rice.edu/~vsarkar/comp635 Vivek Sarkar Department of Computer Science Rice University vsarkar@rice.edu October
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
GPU Memory Memory issue for CUDA programming
 Memory issue for CUDA programming Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block device int GlobalVar; global
Memory issue for CUDA programming Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block device int GlobalVar; global
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Amir Khorsandi Spring 2012
 Introduction to Amir Khorsandi Spring 2012 History Motivation Architecture Software Environment Power of Parallel lprocessing Conclusion 5/7/2012 9:48 PM ٢ out of 37 5/7/2012 9:48 PM ٣ out of 37 IBM, SCEI/Sony,
Introduction to Amir Khorsandi Spring 2012 History Motivation Architecture Software Environment Power of Parallel lprocessing Conclusion 5/7/2012 9:48 PM ٢ out of 37 5/7/2012 9:48 PM ٣ out of 37 IBM, SCEI/Sony,
GPU Memory. GPU Memory. Memory issue for CUDA programming. Copyright 2013 Yong Cao, Referencing UIUC ECE498AL Course Notes
 Memory issue for CUDA programming CUDA Variable Type Qualifiers Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block
Memory issue for CUDA programming CUDA Variable Type Qualifiers Variable declaration Memory Scope Lifetime device local int LocalVar; local thread thread device shared int SharedVar; shared block block
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
Software Development Kit for Multicore Acceleration Version 3.0
 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
Programming for Performance on the Cell BE processor & Experiences at SSSU. Sri Sathya Sai University
 Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total