How to Write Code that Will Survive the Many-Core Revolution
|
|
|
- Coral McCarthy
- 6 years ago
- Views:
Transcription
1 How to Write Code that Will Survive the Many-Core Revolution Write Once, Deploy Many(-Cores) Guillaume BARAT, EMEA Sales Manager





2 CAPS worldwide ecosystem Customers Business Partners Involved in many European Research projects OpenMP ARB Accelerator program subcommittee OpenStandard Initiative HMPP Competences Centers in Europe and Asia 2









")


3 Foreword How to write code that will survive the many-core revolution? is being setup as a collective initiative of HMPP Competence Centers o Gather competences from universities across the world (Asia, Europe, USA) and R&D projects: H4H, Autotune, TeraFlux o Visit for more information 3




4 Trend from Top500: Cores per Socket 500 Systems

5 Trend from Top500: Accelerators Systems Clearspeed CSX60022 ATI GPU IBM PowerXCell 8i NVIDIA 2070 NVIDIA 2050 NVIDIA
6 Study Results Many HPC codes aren t seeing a speed up with new hardware systems (due to many-core, lower bandwidth, lower memory/core, etc.) o Many applications will need a major redesign o Multi-core will cause many issues to hit-the-wall o So GPUs can offer a speed-up BUT o GPU still need to be more easy to program o Future portability is a key concern 6
7 SC11: Consensus about directives? OpenACC initiative (2011) o CAPS, Cray, NVIDIA, PGI o A first common syntax for accelerator regions o Visit for more information OpenHMPP initiative (2010) o Directive Open Standard for many-core programming o Complient with OpenACC syntax o Topics not covered by OpenACC: data-flow extension, tracing interface, auto-tuning APIs o Visit for more information 7







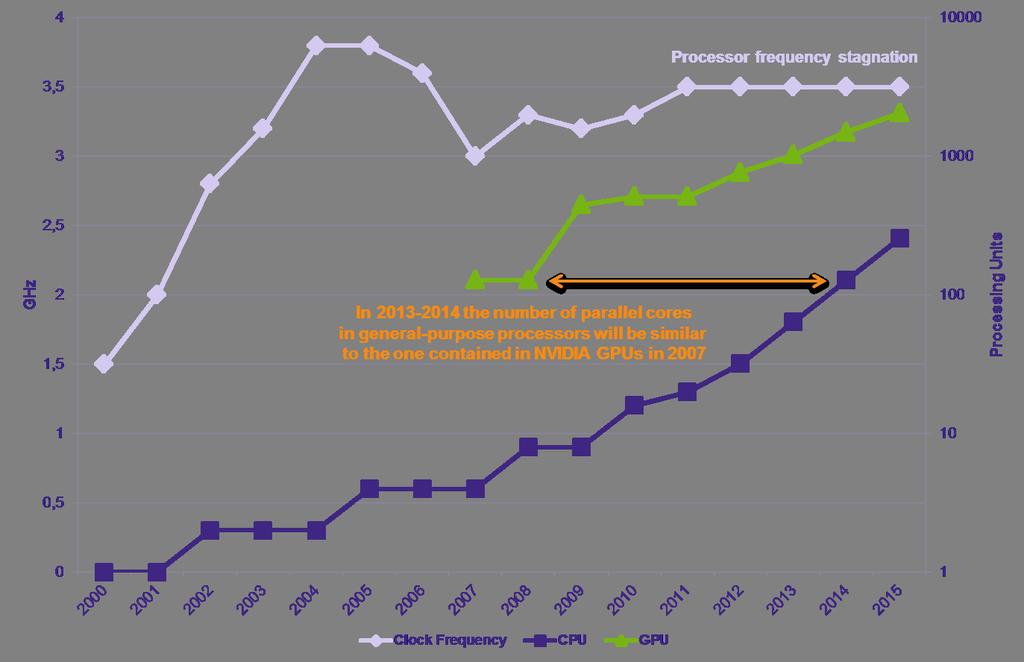
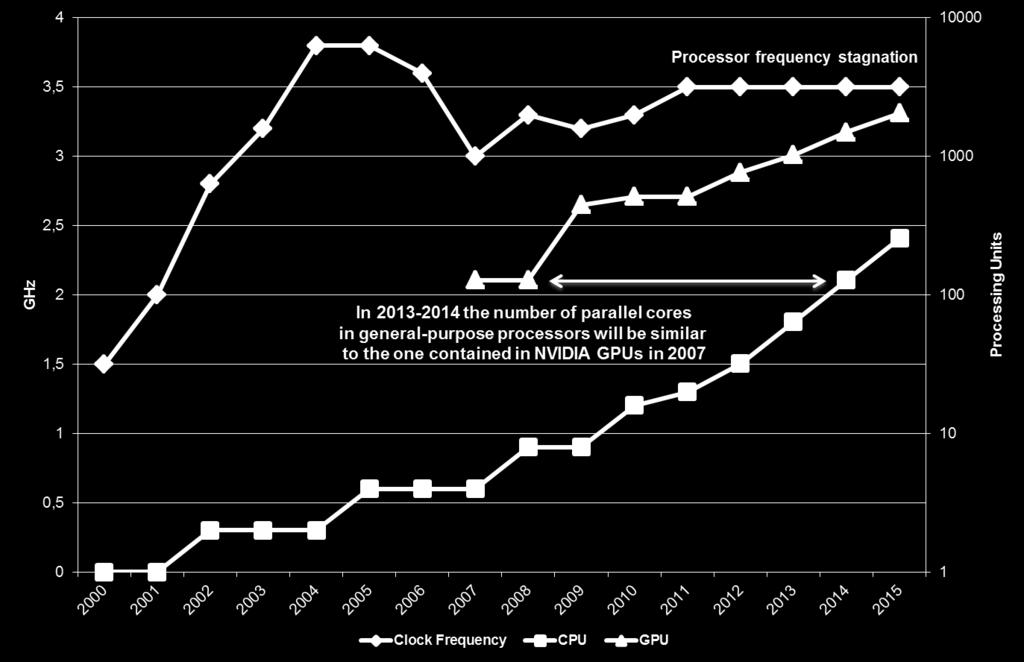


8 Where Are We Going? 8
")





9 What to Expect From the Architecture? Strong Non Uniform Memory Access (NUMA) effects o Not all memories may be coherent o Multiple address spaces Data transfer between CPU and GPUs, multiple address spaces Data/stream/vector parallelism to be exploited by GPUs E.g. CUDA / OpenCL Node is not an homogeneous piece of hardware Not only one device Balance between small and fat cores changes over Rme Many parallelism forms are needed to deal with Increasing number of processing units Some form of vector compurng (AVX or SSE instrucrons) 9
10 What to consider by writing your code Computing power comes from parallelism o Hardware (frequency increase) to software (parallel codes) shift o Driven by energy consumption Heterogeneity is the source of efficiency Few large fast OO cores combined with many smaller cores (e.g. APUs) Fast moving hardware targets environment o e.g. fast GPU improvements (RT and HW), new massively parallel CPU o Write codes that will last many architecture generations Keeping a unique version of the codes, preferably monolanguage, is a necessity o Reduce maintenance cost o Directive-based approaches suitable o Preserve code assets 10


11 Software Main Driving Forces ALF - Amdahl s Law is Forever o A high percentage of the execution time has to be parallel o Many algorithms/methods/techniques will have to be reviewed to scale Data locality is expected to be the main issue o Moving data will always suffer latency 11
12 One MPI Process per Core Approach Benefit o No need to change existing code Issues o Extra latency compared to shared memory use MPI implies some copying required by its semantics (even if efficient MPI implementations tend to reduce them) o Excessive memory utilization Partitioning for separate address spaces requires replication of parts of the data. When using domain decomposition, the sub-grid size may be so small that most points are replicated (i.e. ghost zone) Memory replication implies more stress on the memory bandwidth which finally produces a weak scaling o Cache trashing between MPI processes o Heterogeneity management How are MPI processes linked to accelerator resources? How to deal with different core speed? The balance may be hard to find between the optimal MPI process that makes good use of the CPU core and the use of the accelerators that may be more efficiently used with a different ratio 12
13 Thread Based Parallelism Approach Benefits o Some codes are already ported to OpenMP/threads APIs o Known APIs Issues o Data locality and affinity management Data locality and load balancing (main target of thread APIs) are in general two antagonistic objectives Usual thread APIs make it difficult / not direct to express data locality affinity o Reaching a tradeoff between vector parallelism (e.g. using the AVX instruction set), thread parallelism and MPI parallelism Vector parallelism is expected to impact more and more on the performance Current threads APIs have not been designed to simplify the implementation of such tradeoff o Threads granularity has to be tuned depending on core characteristics (e.g. SMT, heterogeneity) Thread code writing style does not make it easy to tune 13
14 An Approach for Portable Many-Core Codes 1 Try to expose node massive data parallelism in a target independent way 2 Do not hide parallelism by awkward coding 3 Keep code debug- able 4 Track performance issues 5 6 Exploit libraries When allowed, do not target 100% of possible performance, the last 20% are usually very intrusive in the code 14

, jam(2)! for( j = 0 ; j < p ; j++ ) {! for( i = 0 ; i < m ; i++ ) {! for (k =...) {...}! vout[j][i] = alpha *...;! }!")
15 1 - Express Parallelism, not Implementation Rely on code generation for implementation details o Usually not easy to go from a low level API to another low level one o Tuning has to be possible from the high level o But avoid relying on compiler advanced techniques for parallelism discovery, o You may have to change the algorithm! An example with HMPP #pragma hmppcg gridify(j,i)! #pragma hmppcg unroll(4), jam(2)! for( j = 0 ; j < p ; j++ ) {! for( i = 0 ; i < m ; i++ ) {! for (k =...) {...}! vout[j][i] = alpha *...;! }! }! 15
 o")

16 HMPP Hybrid Compiler Directive based approach for many-core Cuda & OpenCL devices and soon Intel MIC Features o With one source code, target multiple many-core architectures o Distribute computation over CPU & GPU cores (Multi-GPU) o High many-core performance with optimized data management o Libraries interoperability with user code o Protect your software investment by using an Open Standard Rapidly develop Many- core Accelerated applica4ons 16
17 Rich set of directives for performance Manycore programming directives in legacy code o Declare and generate GPU versions of computations (codelets) o Optimize data movement o Distribute computations over CPU cores & GPUs Tuning of GPU kernels o Advanced code optimizations o Control mapping of computations o Fully exploit GPU stream architecture

18 Performance does matter En average, HMPP reaches Cuda performance +/- 10% 2 x Intel(R) Xeon(R) 2.80GHz (8 cores) - MKL NVidia Tesla C2050, ECC acrvated HMPP, CUBLAS, MAGMA October

19 Guillaume Colin de Verdière, Onera XtremCFD Workshop, 7 th of October,
20 2 Do not hide parallelism Do not hide parallelism by awkward coding o Data structure aliasing, o Deep routine calling sequences o Separate concerns (functionality coding versus performance coding) Data parallelism when possible o Simple form of parallelism, easy to manage o Favor data locality o But sometimes too static Kernels level o Expose massive parallelism o Ensure that data affinity can be controlled o Make sure it is easy to tune the ratio vector / thread parallelism 20
21 Data Structure Management Data locality o Makes it easy to move from one address space to another one o Makes it easy to keep coherent Do not waste memory o Memory per core ratio not improving Choose simple data structures o Enable vector/simd computing o Use library friendly data structures o May come in multiple forms, e.g. sparse matrix representation For instance consider data collections to deal with multiple address spaces or multiple devices or parts of a device o Gives a level a adaptation for dealing with heterogeneity o Load distribution over the different devices is simple to express 21
 { #pragma hmpp <mgrp> f1 callsite myparallelfunc(d[k],n);")
22 HMPP 3.0 Map Operation on Data Collection #pragma hmpp <mgrp> parallel for(k=0;k<n;k++) { #pragma hmpp <mgrp> f1 callsite myparallelfunc(d[k],n); } CPU 0 CPU 1 GPU 0 GPU 1 GPU 2 Main memory Device memory Device memory Device memory d0 d1 d2 d3 d1 d2 d3 22
23 3 - Debugging Issues Avoid assuming you won t have to debug! Keep serial semantic o For instance, implies keeping serial libraries in the application code o Directives based programming makes this easy Ensure validation is possible even with rounding errors o Reductions, o Aggressive compiler optimizations Use defensive coding practices o Events logging, parameterize parallelism, add synchronization points, o Use debuggers (e.g. Allinea DDT) 23


24 Allinea DDT Debugging Tool for CPU/GPU Debug your kernels: o Debug CPU and GPU concurrently Examine thread data o Display variables Integrated with HMPP o Allows HMPP directives breakpoints o Step into HMPP codelets 24


25 4 - Performance Measurements Parallelism is about performance! Track Amdahl s Law Issues o Serial execution is a killer o Check scalability o Use performance tools Add performance measurement in the code o Detect bottleneck a.s.a.p. o Make it part of the validation process 25

26 HMPP Wizard Analyze the code to help migrate to many-core architectures within an incremental process Provide tuning advices o Check coalescing of memory accesses o Improve parallelism Make your Code Many- Core Friendly 26




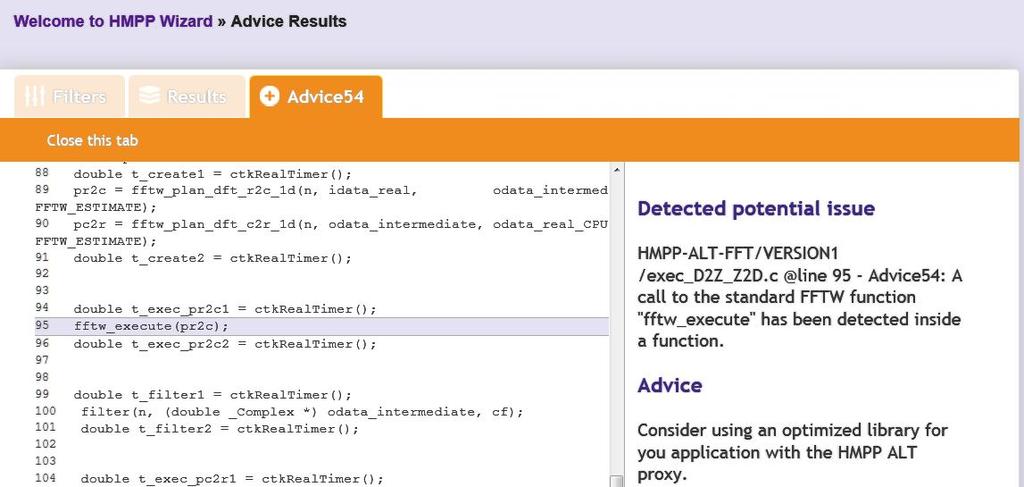
27 HMPP Wizard GPU library usage detection Access to MyDevDeck web online resources 27

28 HMPP Performance Analyzer Dynamic analyses Synthetize metrics based on GPU execution profile Tune your Codelet for Your Hardware 28
29 5 - Dealing with Libraries Library calls can usually only be partially replaced o No one to one mapping between libraries (e.g.blas, FFTW, CuFFT, CULA,LibJacket ) o No access to all code (i.e. avoid side effects) o Don t create dependencies on a specific target library as much as possible o Still want a unique source code Deal with multiple address spaces / multi-gpus o Data location may not be unique (copies) o Usual library calls assume shared memory o Library efficiency depends on updated data location (long term effect) Libraries can be written in many different languages o CUDA, OpenCL, HMPP, etc. There is not one binding choice depending on applications/users o Binding needs to adapt to uses depending on how it interacts with the remainder of the code o Choices depend on development methodology 29
! #pragma hmppalt!")
! NaRve GPU RunRme API!")
30 Library Interoperability in HMPP 3.0 C/CUDA/ call libroutine1 ( )! #pragma hmppalt! call libroutine2( )! call libroutine3( )! HMPP RunRme API proxy2 ( )! NaRve GPU RunRme API! GPU Lib gpulib( )!! CPU Lib cpulib1( )! cpulib3( )! 30
31 Conclusion Software has to expose massive parallelism o The key to success is the algorithm! o The implementation has just to keep parallelism flexible and easy to exploit Directive-based approaches are currently one of the most promising track o Preserve code assets o May separate parallelism exposure from the implementation (at node level) Remember that even if you are very careful in your choices you may have to rewrite parts of the code o Code architecture is the main asset here 31

32 Many-core programming Parallelization GPGPU NVIDIA Cuda OpenHMPP Directive-based programming Code Porting Methodology OpenACC Hybrid Many-core Programmin HPC community Petaflops Parallel computing HPC open standard Exaflops Open CL High Performance Computing Code speedup Multi-core programming Massively parallel HMPP Competence Center Hardware accelerators programming GPGPU DevDeck Parallel programming interface Global Solutions for Many-Core Programming
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO
 F. Bodin, CTO") How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
Code Migration Methodology for Heterogeneous Systems
 Code Migration Methodology for Heterogeneous Systems Directives based approach using HMPP - OpenAcc F. Bodin, CAPS CTO Introduction Many-core computing power comes from parallelism o Multiple forms of
Code Migration Methodology for Heterogeneous Systems Directives based approach using HMPP - OpenAcc F. Bodin, CAPS CTO Introduction Many-core computing power comes from parallelism o Multiple forms of
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise. June 2011
 MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
OpenACC Standard. Credits 19/07/ OpenACC, Directives for Accelerators, Nvidia Slideware
 OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
Incremental Migration of C and Fortran Applications to GPGPU using HMPP HPC Advisory Council China Conference 2010
 Innovative software for manycore paradigms Incremental Migration of C and Fortran Applications to GPGPU using HMPP HPC Advisory Council China Conference 2010 Introduction Many applications can benefit
Innovative software for manycore paradigms Incremental Migration of C and Fortran Applications to GPGPU using HMPP HPC Advisory Council China Conference 2010 Introduction Many applications can benefit
Heterogeneous Multicore Parallel Programming
 Innovative software for manycore paradigms Heterogeneous Multicore Parallel Programming S. Chauveau & L. Morin & F. Bodin Introduction Numerous legacy applications can benefit from GPU computing Many programming
Innovative software for manycore paradigms Heterogeneous Multicore Parallel Programming S. Chauveau & L. Morin & F. Bodin Introduction Numerous legacy applications can benefit from GPU computing Many programming
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
GPU Debugging Made Easy. David Lecomber CTO, Allinea Software
 GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Pragma-based GPU Programming and HMPP Workbench. Scott Grauer-Gray
 Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Parallel Hybrid Computing Stéphane Bihan, CAPS
 Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
A Uniform Programming Model for Petascale Computing
 A Uniform Programming Model for Petascale Computing Barbara Chapman University of Houston WPSE 2009, Tsukuba March 25, 2009 High Performance Computing and Tools Group http://www.cs.uh.edu/~hpctools Agenda
A Uniform Programming Model for Petascale Computing Barbara Chapman University of Houston WPSE 2009, Tsukuba March 25, 2009 High Performance Computing and Tools Group http://www.cs.uh.edu/~hpctools Agenda
Dealing with Heterogeneous Multicores
 Dealing with Heterogeneous Multicores François Bodin INRIA-UIUC, June 12 th, 2009 Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism
Dealing with Heterogeneous Multicores François Bodin INRIA-UIUC, June 12 th, 2009 Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives
 Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives José M. Andión, Manuel Arenaz, François Bodin, Gabriel Rodríguez and Juan Touriño 7th International Symposium on High-Level Parallel
Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives José M. Andión, Manuel Arenaz, François Bodin, Gabriel Rodríguez and Juan Touriño 7th International Symposium on High-Level Parallel
Tools and Methodology for Ensuring HPC Programs Correctness and Performance. Beau Paisley
 Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
designing a GPU Computing Solution
 designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ.
 An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
GpuWrapper: A Portable API for Heterogeneous Programming at CGG
 GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015
 Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
High performance Computing and O&G Challenges
 High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
CAPS Technology. ProHMPT, 2009 March12 th
 CAPS Technology ProHMPT, 2009 March12 th Overview of the Talk 1. HMPP in a nutshell Directives for Hardware Accelerators (HWA) 2. HMPP Code Generation Capabilities Efficient code generation for CUDA 3.
CAPS Technology ProHMPT, 2009 March12 th Overview of the Talk 1. HMPP in a nutshell Directives for Hardware Accelerators (HWA) 2. HMPP Code Generation Capabilities Efficient code generation for CUDA 3.
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Programming Heterogeneous Many-cores Using Directives
 Programming Heterogeneous Many-cores Using Directives HMPP - OpenAcc François Bodin, Florent Lebeau, CAPS entreprise Introduction Programming many-core systems faces the following dilemma o The constraint
Programming Heterogeneous Many-cores Using Directives HMPP - OpenAcc François Bodin, Florent Lebeau, CAPS entreprise Introduction Programming many-core systems faces the following dilemma o The constraint
Parallel Hybrid Computing F. Bodin, CAPS Entreprise
 Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
Hybrid programming with MPI and OpenMP On the way to exascale
 Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
ClearSpeed Visual Profiler
 ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP
 Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP Zhe Weng and Peter Strazdins*, Computer Systems Group, Research School of Computer Science, The Australian National University
Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP Zhe Weng and Peter Strazdins*, Computer Systems Group, Research School of Computer Science, The Australian National University
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Distributed Dense Linear Algebra on Heterogeneous Architectures. George Bosilca
 Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE
 HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
AutoTune Workshop. Michael Gerndt Technische Universität München
 AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
GPGPU. Alan Gray/James Perry EPCC The University of Edinburgh.
 GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Adrian Tate XK6 / openacc workshop Manno, Mar
 Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
FPGA-based Supercomputing: New Opportunities and Challenges
 FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster
 First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology
 Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
An Introduc+on to OpenACC Part II
 An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge
 Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Critically Missing Pieces on Accelerators: A Performance Tools Perspective
 Critically Missing Pieces on Accelerators: A Performance Tools Perspective, Karthik Murthy, Mike Fagan, and John Mellor-Crummey Rice University SC 2013 Denver, CO November 20, 2013 What Is Missing in GPUs?
Critically Missing Pieces on Accelerators: A Performance Tools Perspective, Karthik Murthy, Mike Fagan, and John Mellor-Crummey Rice University SC 2013 Denver, CO November 20, 2013 What Is Missing in GPUs?
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Towards a codelet-based runtime for exascale computing. Chris Lauderdale ET International, Inc.
 Towards a codelet-based runtime for exascale computing Chris Lauderdale ET International, Inc. What will be covered Slide 2 of 24 Problems & motivation Codelet runtime overview Codelets & complexes Dealing
Towards a codelet-based runtime for exascale computing Chris Lauderdale ET International, Inc. What will be covered Slide 2 of 24 Problems & motivation Codelet runtime overview Codelets & complexes Dealing
GPU GPU CPU. Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3
 /CPU,a),2,2 2,2 Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3 XMP XMP-dev CPU XMP-dev/StarPU XMP-dev XMP CPU StarPU CPU /CPU XMP-dev/StarPU N /CPU CPU. Graphics Processing Unit GP General-Purpose
/CPU,a),2,2 2,2 Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3 XMP XMP-dev CPU XMP-dev/StarPU XMP-dev XMP CPU StarPU CPU /CPU XMP-dev/StarPU N /CPU CPU. Graphics Processing Unit GP General-Purpose
ET International HPC Runtime Software. ET International Rishi Khan SC 11. Copyright 2011 ET International, Inc.
 HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
Arm crossplatform. VI-HPS platform October 16, Arm Limited
 Arm crossplatform tools VI-HPS platform October 16, 2018 An introduction to Arm Arm is the world's leading semiconductor intellectual property supplier We license to over 350 partners: present in 95% of
Arm crossplatform tools VI-HPS platform October 16, 2018 An introduction to Arm Arm is the world's leading semiconductor intellectual property supplier We license to over 350 partners: present in 95% of
From Physics Model to Results: An Optimizing Framework for Cross-Architecture Code Generation
 From Physics Model to Results: An Optimizing Framework for Cross-Architecture Code Generation Erik Schnetter, Perimeter Institute with M. Blazewicz, I. Hinder, D. Koppelman, S. Brandt, M. Ciznicki, M.
From Physics Model to Results: An Optimizing Framework for Cross-Architecture Code Generation Erik Schnetter, Perimeter Institute with M. Blazewicz, I. Hinder, D. Koppelman, S. Brandt, M. Ciznicki, M.
OpenMP 4.0. Mark Bull, EPCC
 OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic