SPARK: A Parallelizing High-Level Synthesis Framework
|
|
|
- Reginald Welch
- 6 years ago
- Views:
Transcription
1 SPARK: A Parallelizing High-Level Synthesis Framework Sumit Gupta Rajesh Gupta, Nikil Dutt, Alex Nicolau Center for Embedded Computer Systems University of California, Irvine and San Diego Supported by Semiconductor Research Corporation & Intel Inc
2 System Level Synthesis System Level Model Task Analysis HW/SW Partitioning Hardware Behavioral Description High Level Synthesis ASIC I/O FPGA Memory Software Behavioral Description Software Compiler Processor Core 2
3 High Level Synthesis Transform behavioral descriptions to RTL/gate level x = a + b; c = a < b; if (c) then d = e f; else g = h + i; j = d x g; l = e + x; From C to CDFG to Architecture d = e - f x = a + b c = a < b T c j = d x g l = e + x If Node F g = h + i Control M e m o r y ALU Data path 3
4 High Level Synthesis Transform behavioral descriptions to RTL/gate level x = a + b; c = a < b; if (c) then d = e f; else g = h + i; j = d x g; l = e + x; From C to CDFG to Architecture T d = e - f x = a + b c = a < b c If Node F g = h + i Control M e m o r y Problem # 1 : Poor quality of HLS results beyond straight-line j = d x g behavioral descriptions Problem # 2 : Poor/No l = e + x controllability of the HLS results ALU Data path 4
5 Outline Motivation and Background Our Approach to Parallelizing High-Level Synthesis Code Transformations Techniques for PHLS Parallelizing Transformations Dynamic Transformations The PHLS Framework and Experimental Results Multimedia and Image Processing Applications Case Study: Intel Instruction Length Decoder Conclusions and Future Work 5
6 High-level Synthesis Well-researched area: from early 1980 s Renewed interest due to new system level design methodologies Large number of synthesis optimizations have been proposed Either operation level: : algebraic transformations on DSP codes or logic level: : Don t Care based control optimizations In contrast, compiler transformations operate at both operation level (fine-grain) and source level (coarse-grain) Parallelizing Compiler Transformations Different optimization objectives and cost models than HLS Our aim: : Develop Synthesis and Parallelizing Compiler Transformations that are useful for HLS Beyond scheduling results: in Circuit Area and Delay For large designs with complex control flow (nested conditionals/loops) 6
7 Our Approach: Parallelizing HLS (PHLS) C Input Original CDFG Scheduling & Binding Optimized CDFG VHDL Output Source-Level Compiler Transformations Scheduling Compiler & Dynamic Transformations Optimizing Compiler and Parallelizing Compiler transformations applied at Source-level (Pre-synthesis) and during Scheduling Source-level code refinement using Pre-synthesis transformations Code Restructuring by Speculative Code Motions Operation replication to improve concurrency Dynamic transformations: exploit new opportunities during scheduling 7
8 PHLS Transformations Organized into Four Groups 1. Pre-synthesis synthesis: : Loop-invariant code motions, Loop unrolling, CSE 2. Scheduling: : Speculative Code Motions, Multi- cycling, Operation Chaining, Loop Pipelining 3. Dynamic: : Transformations applied dynamically during scheduling: Dynamic CSE, Dynamic Copy Propagation, Dynamic Branch Balancing 4. Basic Compiler Transformations: : Copy Propagation, Dead Code Elimination 8
9 Speculative Code Motions Operation Movement to reduce impact of Programming Style on Quality of HLS Results Across Hierarchical Blocks + a If Node Speculation T F Reverse Speculation + b _ c Conditional Speculation Early Condition Execution Evaluates conditions As soon as possible 9
10 Dynamic Transformations Called dynamic since they are applied during scheduling (versus a pass before/after scheduling) Dynamic Branch Balancing Increase the scope of code motions Reduce impact of programming style on HLS results Dynamic CSE and Dynamic Copy Propagation Exploit the Operation movement and duplication due to speculative code motions Create new opportunities to apply these transformations Reduce the number of operations 10
11 Dynamic Branch Balancing If Node BB 1 + a + b _ c T F _ e BB 0 BB 3 BB 2 _ d BB 4 Original Design Resource Allocation If Node a BB 1 b _ c T F _ e Longest Path BB 0 BB 3 BB 2 _ d BB 4 Unbalanced Conditional Scheduled Design S0 S1 S2 S3 11
12 Insert New Scheduling Step in Shorter Branch If Node BB 1 + a + b _ c T F _ e Resource Allocation BB 0 BB 3 BB 2 _ d BB 4 If Node a BB 1 b _ c T F _ e BB 0 BB 3 BB 2 _ d BB 4 S0 S1 S2 S3 Original Design Scheduled Design 12
13 Insert New Scheduling Step in Shorter Branch If Node BB 1 + a + b _ c T F BB 0 BB 3 Original Design Resource Allocation BB 2 _ d If Node a BB 1 b _ c _ e T F BB 0 BB 3 BB 2 _ d _ e BB 4 Dynamic Branch _ Balancing BB 4 inserts new scheduling steps Enables Conditional e Speculation Leads to further code compaction Scheduled Design S0 S1 S2 S3 13
14 Dynamic CSE: : Going beyond Traditional CSE a = b + c; cd = b < c; if (cd) d = b + c; else e = g + h; If Node a = b + c BB 0 BB 1 T F d = a e = g + h BB 2 BB 3 BB 4 C Description a = b + c BB 0 After Traditional CSE If Node T BB 1 F d = b + c e = g + h BB 2 BB 3 BB 4 HTG Representation 14
15 Dynamic CSE: : Going beyond Traditional CSE a = b + c; cd = b < c; if (cd) d = b + c; else e = g + h; C Description a = b + c BB 0 We use notion of Dominance If Node d = b + c e = g + h BB 2 BB 3 BB 4 HTG Representation If Node Dominance of Basic Blocks T a = b + c BB 0 BB 1 F d = a e = g + h BB 2 BB 3 BB 4 After Traditional CSE Basic block BBi dominates BB 1BBj if all control paths from T F the initial basic block of the design graph leading to BBj goes through BBi We can eliminate an operation opj in BBj using common expression in opi if BBi dominates BBj 15
16 New Opportunities for Dynamic Dynamic CSE Scheduler decides to Speculate Due to Code Motions BB 1 BB 0 dcse = b + c BB 0 BB 1 a = b + c BB 2 BB 3 BB 4 BB 5 a = dcse BB 2 BB 3 BB 4 BB 5 d = b + c d = b + c BB 6 BB 7 BB 6 BB 7 BB 8 CSE not possible since BB2 does not dominate BB6 BB 8 CSE possible now since BB0 does not dominate BB6 16
17 New Opportunities for Dynamic Dynamic CSE Scheduler decides to Speculate Due to Code Motions BB 1 BB 0 dcse = b + c BB 0 BB 1 a = b + c BB 2 BB 3 BB 4 BB 5 a = dcse BB 2 BB 3 BB 4 BB 5 d = b + c d = dcse BB 6 BB 7 BB 6 BB 7 BB 8 BB 8 If If scheduler not possible moves since or or duplicates BB2 an an CSE operation possible op,, apply now CSE since on on remaining operations using op op CSE not possible does not dominate BB6 BB0 does not dominate BB6 17
18 Condition Speculation & Dynamic CSE BB 0 BB 0 BB 1 BB 2 BB Scheduler 3 decides to Conditionally BB Speculate 4 a' = b + c a' = b + c BB 1 BB 2 BB 3 BB 4 a = b + c BB 5 BB 6 BB 7 a = a' BB 5 BB 6 BB 7 d = b + c BB 8 d = b + c BB 8 18
19 Condition Speculation & Dynamic CSE BB 0 BB 0 BB 1 BB 2 BB Scheduler 3 decides to Conditionally BB Speculate 4 a' = b + c a' = b + c BB 1 BB 2 BB 3 BB 4 a = b + c BB 5 BB 6 BB 7 a = a' BB 5 BB 6 BB 7 d = b + c d = a' BB 8 BB 8 19
20 Condition Speculation & Dynamic CSE BB 0 BB 0 BB 1 BB 2 BB Scheduler 3 decides to Conditionally BB Speculate 4 a' = b + c a' = b + c BB 1 BB 2 BB 3 BB 4 Use the notion of dominance a = b + c by BB groups 5 of basic blocks BB 6 BB 7 All Control Paths leading up to BB8 come from either BB1 or d BB2: = b + c=> BB BB1 8 and d = a' BB 8 BB2 together dominate BB8 a = a' BB 5 BB 6 BB 7 20
21 Loop Node Loop Shifting: An Incremental Loop Pipelining Technique BB 0 Loop Node a + _ c BB 0 BB 1 BB 1 BB 2 a + b + _ c _ d Loop Shifting BB 2 b + a + _ d _ c BB 3 Loop Exit BB 3 Loop Exit BB 4 BB 4 21
22 Loop Node Loop Shifting: An Incremental Loop Pipelining Technique BB 0 Loop Node a + _ c BB 0 BB 1 BB 1 BB 2 a + b + _ c _ d Loop Shifting BB 2 b + a + _ c _ d BB 3 Loop Exit Compac -tion BB 3 Loop Exit BB 4 BB 4 22
23 SPARK High Level Synthesis Framework 23
24 SPARK Parallelizing HLS Framework C input and Synthesizable RTL VHDL output Tool-box of Transformations and Heuristics Each of these can be developed independently of the other Script based control over transformations & heuristics Hierarchical Intermediate Representation (HTGs( HTGs) Retains structural information about design (conditional blocks, loops) Enables efficient and structured application of transformations Complete HLS tool: Does Binding, Control Synthesis and Backend VHDL generation Interconnect Minimizing Resource Binding Enables Graphical Visualization of Design description and intermediate results 100,000+ lines of C++ code 24
25 Synthesizable C ANSI-C C front end from Edison Design Group (EDG) Features of C not supported for synthesis Pointers However, Arrays and passing by reference are supported Recursive Function Calls Gotos Features for which support has not been implemented Multi-dimensional arrays Structs Continue, Breaks Hardware component generated for each function A called function is instantiated as a hardware component in calling function 25
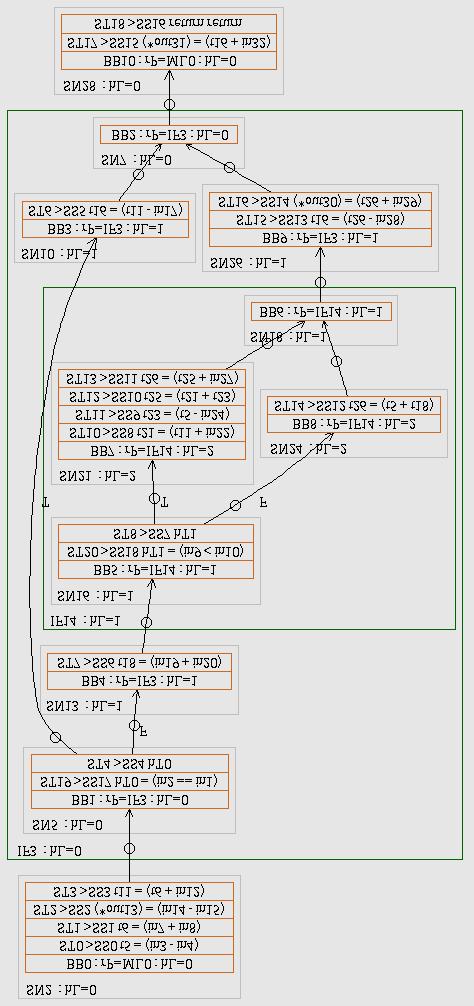
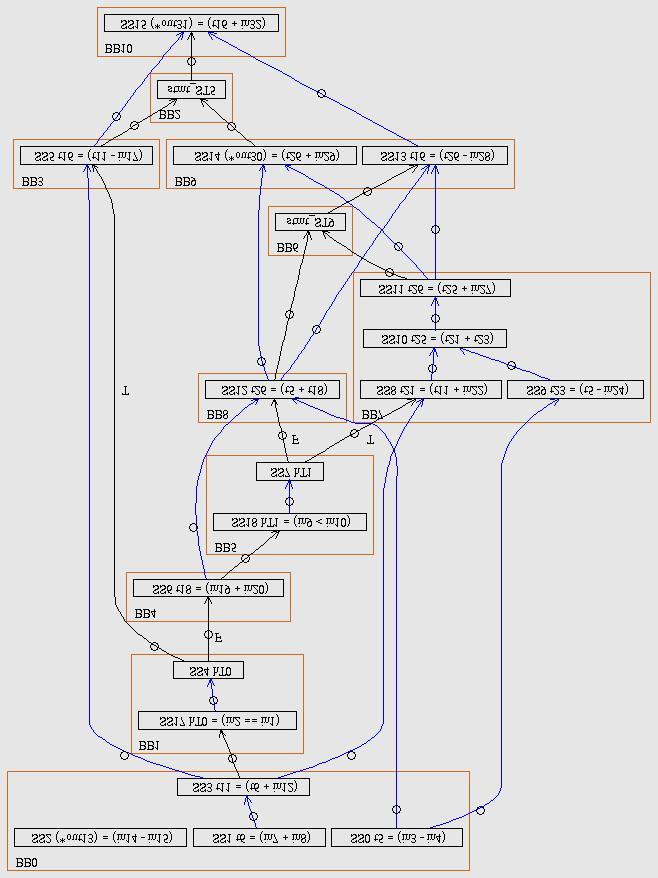
26 HTG Graph Visualization DFG 26
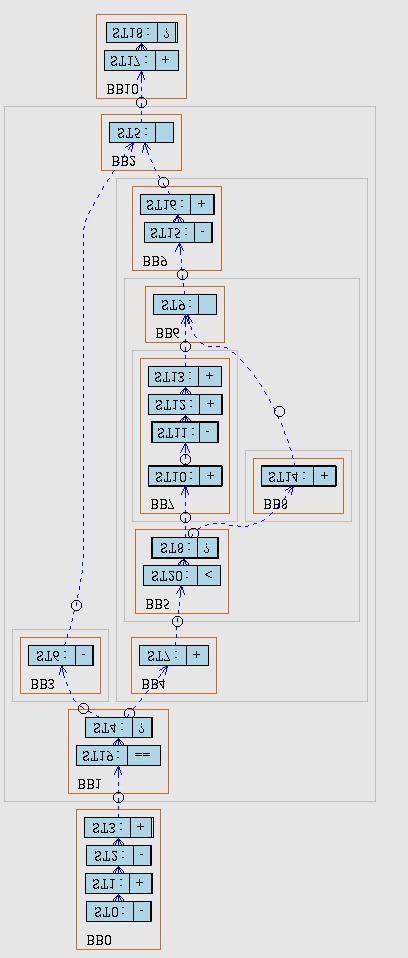
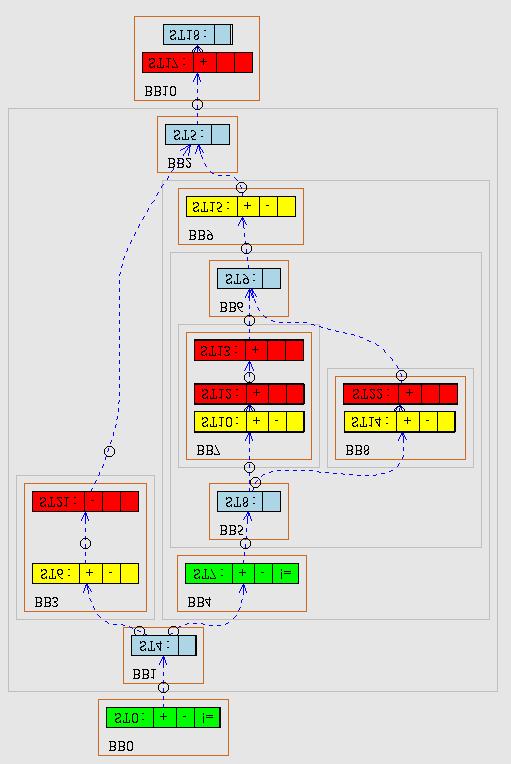
27 Resource Utilization Graph Scheduling 27

28 Example of Complex HTG Example of a real design: MPEG-1 1 pred2 function Just for demonstration; you are not expected to read the text Multiple nested loops and conditionals 28
29 Results presented here for Experiments Pre-synthesis transformations Speculative Code Motions Dynamic CSE We used SPARK to synthesize designs derived from several industrial designs MPEG-1, MPEG-2, GIMP Image Processing software Case Study of Intel Instruction Length Decoder Scheduling Results Number of States in FSM Cycles on Longest Path through Design VHDL: Logic Synthesis Critical Path Length (ns) Unit Area 29
30 Target Applications Design # of Ifs # of Loops # Non-Empty Basic Blocks # of Operations MPEG-1 pred MPEG-1 pred MPEG-2 dp_frame GIMP tiler
31 Scheduling & Logic Synthesis Results Longest Path(l cyc) MPEG-1 Pred1 Function Critical Path(c ns) 36% 42% Total Delay (c*l) 10% Unit Area Non-speculative CMs: Within BBs & Across Hier Blocks + Speculative Code Motions Longest Path(l cyc) MPEG-1 Pred2 Function Critical Path(c ns) + Pre-Synthesis Transforms + Dynamic CSE 39% 36% Total Delay (c*l) 8% Unit Area 31
32 Scheduling & Logic Synthesis Results Longest Path(l cyc) MPEG-1 Pred1 Function Critical Path(c ns) 36% 42% Total Delay (c*l) 10% Unit Area Non-speculative CMs: Within BBs & Across Hier Blocks + Speculative Code Motions Longest Path(l cyc) MPEG-1 Pred2 Function Critical Path(c ns) + Pre-Synthesis Transforms + Dynamic CSE 39% 36% Total Delay (c*l) Overall: % improvement in Delay Almost constant Area 8% Unit Area 32
33 1.2 Scheduling & Logic Synthesis Results MPEG-2 DpFrame Function 1.2 GIMP Tiler Function % % % 1% % 14% 0 Longest Path(l cyc) Critical Path(c ns) Total Delay (c*l) Unit Area Non-speculative CMs: Within BBs & Across Hier Blocks + Speculative Code Motions 0 Longest Path(l cyc) Critical Path(c ns) + Pre-Synthesis Transforms + Dynamic CSE Total Delay (c*l) Unit Area 33
34 1.2 Scheduling & Logic Synthesis Results MPEG-2 DpFrame Function 1.2 GIMP Tiler Function % % % 1% % 14% 0 Longest Path(l cyc) Critical Path(c ns) Total Delay (c*l) Unit Area Non-speculative CMs: Within BBs & Across Hier Blocks + Speculative Code Motions 0 Longest Path(l cyc) Critical Path(c ns) + Pre-Synthesis Transforms + Dynamic CSE Total Delay (c*l) Overall: % improvement in Delay Almost constant Area Unit Area 34
35 Case Study: Intel Instruction Length Decoder Stream of Instructions Instruction Buffer Instruction Length Decoder First Insn Second Insn Third Instruction 35
36 Example Design: ILD Block from Intel Case Study: A design derived from the Instruction Length Decoder of the Intel Pentium class of processors Decodes length of instructions streaming from memory Has to look at up to 4 bytes at a time Has to execute in one cycle and decode about 64 bytes of instructions Characteristics of Microprocessor functional blocks Low Latency: Single or Dual cycle implementation Consist of several small computations Intermix of control and data logic 36
37 Basic Instruction Length Decoder: Initial Description Length Contribution 1 Length Contribution 2 Length Contribution 3 Length Contribution = Total Length Of Instruction Byte 1 Byte 2 Byte 3 Byte 4 Need Byte 4? Need Byte 3? Need Byte 2? 37
38 Instruction Length Decoder: Decoding 2 nd Instruction Length Contribution 1 Length Contribution 2 Length Contribution 3 Length Contribution = Total Length Of Insn First Insn Byte 3 Byte 4 Byte 5 Byte 6 Need Byte 4? Need Byte 3? Need Byte 2? After decoding the length of an instruction Start looking from next byte Again examine up to 4 bytes to determine length of next instruction 38
39 Byte 1 Instruction Length Decoder: Parallelized Description Byte 2 Byte 3 Byte 4 Length Contribution 1 Length Contribution 2 Length Contribution 3 Length Contribution 4 Need Byte 4? Need Byte 3? = Total Length Of Instruction Speculatively calculate the length contribution of all 4 bytes at a time Determine actual total length of instruction based on this data Need Byte 2? 39
40 ILD: Extracting Further Parallelism Byte 1 Insn. Len Calc Byte 1 Byte 2 Byte 2 Insn. Len Calc Byte 3 Insn. Len Calc Byte 3 Byte 4 Byte 4 Insn. Len Calc Byte 5 Insn. Len Calc Byte 5 Speculatively calculate length of instructions assuming a new instruction starts at each byte Do this calculation for all bytes in parallel Traverse from 1 st byte to last Determine length of instructions starting from the 1 st till the last Discard unused calculations 40
41 Initial: Multi-Cycle Sequential Architecture Length Contribution 1 Length Contribution 2 Length Contribution 3 Length Contribution 4 Byte 1 Byte 2 Byte 3 Byte 4 Need Byte 4? Need Byte 3? Need Byte 2? 41
42 ILD Synthesis: Resulting Architecture Speculate Operations, Fully Unroll Loop, Eliminate Loop Index Variable 42
43 ILD Synthesis: Resulting Architecture Speculate Operations, Fully Unroll Loop, Eliminate Loop Index Variable Multi-cycle Sequential Architecture Single cycle Parallel Architecture Our toolbox approach enables us to develop a script to synthesize applications from different domains Final design looks close to the actual implementation done by Intel 43
44 Conclusions Parallelizing code transformations enable a new range of HLS transformations Provide the needed improvement in quality of HLS results Possible to be competitive against manually designed circuits. Can enable productivity improvements in microelectronic design Built a synthesis system with a range of code transformations Platform for applying Coarse and Fine-grain Optimizations Tool-box approach where transformations and heuristics can be developed Enables the designer to find the right synthesis script for different application domains Performance improvements of % across a number of designs We have shown its effectiveness on an Intel design 44
45 Advisors Acknowledgements Professors Rajesh Gupta, Nikil Dutt,, Alex Nicolau Contributors to SPARK framework Nick Savoiu, Mehrdad Reshadi, Sunwoo Kim Intel Strategic CAD Labs (SCL) Timothy Kam,, Mike Kishinevsky Supported by Semiconductor Research Corporation and Intel SCL 45
46 Thank You
SPARK : A High-Level Synthesis Framework For Applying Parallelizing Compiler Transformations
 SPARK : A High-Level Synthesis Framework For Applying Parallelizing Compiler Transformations Sumit Gupta Nikil Dutt Rajesh Gupta Alex Nicolau Center for Embedded Computer Systems University of California
SPARK : A High-Level Synthesis Framework For Applying Parallelizing Compiler Transformations Sumit Gupta Nikil Dutt Rajesh Gupta Alex Nicolau Center for Embedded Computer Systems University of California
Coordinated Transformations for High-Level Synthesis of High Performance Microprocessor Blocks
 Coordinated Transformations for High-Level Synthesis of High Performance Microprocessor Blocks Sumit Gupta Timothy Kam Michael Kishinevsky Shai Rotem Nick Savoiu Nikil Dutt Rajesh Gupta Alex Nicolau Center
Coordinated Transformations for High-Level Synthesis of High Performance Microprocessor Blocks Sumit Gupta Timothy Kam Michael Kishinevsky Shai Rotem Nick Savoiu Nikil Dutt Rajesh Gupta Alex Nicolau Center
Dynamic Common Sub-Expression Elimination during Scheduling in High-Level Synthesis
 Dynamic Common Sub-Expression Elimination during Scheduling in High-Level Synthesis Sumit Gupta Mehrdad Reshadi Nick Savoiu Nikil Dutt Rajesh Gupta Alex Nicolau Center for Embedded Computer Systems University
Dynamic Common Sub-Expression Elimination during Scheduling in High-Level Synthesis Sumit Gupta Mehrdad Reshadi Nick Savoiu Nikil Dutt Rajesh Gupta Alex Nicolau Center for Embedded Computer Systems University
Coordinated Parallelizing Compiler Optimizations and High-Level Synthesis
 Coordinated Parallelizing Compiler Optimizations and High-Level Synthesis SUMIT GUPTA Tallwood Venture Capital RAJESH KUMAR GUPTA University of California, San Deigo NIKIL D. DUTT University of California,
Coordinated Parallelizing Compiler Optimizations and High-Level Synthesis SUMIT GUPTA Tallwood Venture Capital RAJESH KUMAR GUPTA University of California, San Deigo NIKIL D. DUTT University of California,
User Manual for the SPARK Parallelizing High-Level Synthesis Framework Version 1.1
 User Manual for the SPARK Parallelizing High-Level Synthesis Framework Version 1.1 Sumit Gupta Center for Embedded Computer Systems University of California at San Diego and Irvine sumitg@cecs.uci.edu
User Manual for the SPARK Parallelizing High-Level Synthesis Framework Version 1.1 Sumit Gupta Center for Embedded Computer Systems University of California at San Diego and Irvine sumitg@cecs.uci.edu
Using Speculative Computation and Parallelizing techniques to improve Scheduling of Control based Designs
 Using Speculative Computation and Parallelizing techniques to improve Scheduling of Control based Designs Roberto Cordone Fabrizio Ferrandi, Gianluca Palermo, Marco D. Santambrogio, Donatella Sciuto Università
Using Speculative Computation and Parallelizing techniques to improve Scheduling of Control based Designs Roberto Cordone Fabrizio Ferrandi, Gianluca Palermo, Marco D. Santambrogio, Donatella Sciuto Università
Unit 2: High-Level Synthesis
 Course contents Unit 2: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 2 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Course contents Unit 2: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 2 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
VHDL for Synthesis. Course Description. Course Duration. Goals
 VHDL for Synthesis Course Description This course provides all necessary theoretical and practical know how to write an efficient synthesizable HDL code through VHDL standard language. The course goes
VHDL for Synthesis Course Description This course provides all necessary theoretical and practical know how to write an efficient synthesizable HDL code through VHDL standard language. The course goes
COE 561 Digital System Design & Synthesis Introduction
 1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
1 COE 561 Digital System Design & Synthesis Introduction Dr. Aiman H. El-Maleh Computer Engineering Department King Fahd University of Petroleum & Minerals Outline Course Topics Microelectronics Design
ICS 252 Introduction to Computer Design
 ICS 252 Introduction to Computer Design Lecture 3 Fall 2006 Eli Bozorgzadeh Computer Science Department-UCI System Model According to Abstraction level Architectural, logic and geometrical View Behavioral,
ICS 252 Introduction to Computer Design Lecture 3 Fall 2006 Eli Bozorgzadeh Computer Science Department-UCI System Model According to Abstraction level Architectural, logic and geometrical View Behavioral,
Verilog for High Performance
 Verilog for High Performance Course Description This course provides all necessary theoretical and practical know-how to write synthesizable HDL code through Verilog standard language. The course goes
Verilog for High Performance Course Description This course provides all necessary theoretical and practical know-how to write synthesizable HDL code through Verilog standard language. The course goes
High-Level Synthesis Creating Custom Circuits from High-Level Code
 High-Level Synthesis Creating Custom Circuits from High-Level Code Hao Zheng Comp Sci & Eng University of South Florida Exis%ng Design Flow Register-transfer (RT) synthesis - Specify RT structure (muxes,
High-Level Synthesis Creating Custom Circuits from High-Level Code Hao Zheng Comp Sci & Eng University of South Florida Exis%ng Design Flow Register-transfer (RT) synthesis - Specify RT structure (muxes,
HDL. Operations and dependencies. FSMs Logic functions HDL. Interconnected logic blocks HDL BEHAVIORAL VIEW LOGIC LEVEL ARCHITECTURAL LEVEL
 ARCHITECTURAL-LEVEL SYNTHESIS Motivation. Outline cgiovanni De Micheli Stanford University Compiling language models into abstract models. Behavioral-level optimization and program-level transformations.
ARCHITECTURAL-LEVEL SYNTHESIS Motivation. Outline cgiovanni De Micheli Stanford University Compiling language models into abstract models. Behavioral-level optimization and program-level transformations.
Architectural-Level Synthesis. Giovanni De Micheli Integrated Systems Centre EPF Lausanne
 Architectural-Level Synthesis Giovanni De Micheli Integrated Systems Centre EPF Lausanne This presentation can be used for non-commercial purposes as long as this note and the copyright footers are not
Architectural-Level Synthesis Giovanni De Micheli Integrated Systems Centre EPF Lausanne This presentation can be used for non-commercial purposes as long as this note and the copyright footers are not
High-Level Synthesis (HLS)
") Course contents Unit 11: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 11 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Course contents Unit 11: High-Level Synthesis Hardware modeling Data flow Scheduling/allocation/assignment Reading Chapter 11 Unit 11 1 High-Level Synthesis (HLS) Hardware-description language (HDL) synthesis
Hello I am Zheng, Hongbin today I will introduce our LLVM based HLS framework, which is built upon the Target Independent Code Generator.
 Hello I am Zheng, Hongbin today I will introduce our LLVM based HLS framework, which is built upon the Target Independent Code Generator. 1 In this talk I will first briefly introduce what HLS is, and
Hello I am Zheng, Hongbin today I will introduce our LLVM based HLS framework, which is built upon the Target Independent Code Generator. 1 In this talk I will first briefly introduce what HLS is, and
FPGA for Software Engineers
 FPGA for Software Engineers Course Description This course closes the gap between hardware and software engineers by providing the software engineer all the necessary FPGA concepts and terms. The course
FPGA for Software Engineers Course Description This course closes the gap between hardware and software engineers by providing the software engineer all the necessary FPGA concepts and terms. The course
NISC Application and Advantages
 NISC Application and Advantages Daniel D. Gajski Mehrdad Reshadi Center for Embedded Computer Systems University of California, Irvine Irvine, CA 92697-3425, USA {gajski, reshadi}@cecs.uci.edu CECS Technical
NISC Application and Advantages Daniel D. Gajski Mehrdad Reshadi Center for Embedded Computer Systems University of California, Irvine Irvine, CA 92697-3425, USA {gajski, reshadi}@cecs.uci.edu CECS Technical
Intermediate representation
 Intermediate representation Goals: encode knowledge about the program facilitate analysis facilitate retargeting facilitate optimization scanning parsing HIR semantic analysis HIR intermediate code gen.
Intermediate representation Goals: encode knowledge about the program facilitate analysis facilitate retargeting facilitate optimization scanning parsing HIR semantic analysis HIR intermediate code gen.
NEW FPGA DESIGN AND VERIFICATION TECHNIQUES MICHAL HUSEJKO IT-PES-ES
 NEW FPGA DESIGN AND VERIFICATION TECHNIQUES MICHAL HUSEJKO IT-PES-ES Design: Part 1 High Level Synthesis (Xilinx Vivado HLS) Part 2 SDSoC (Xilinx, HLS + ARM) Part 3 OpenCL (Altera OpenCL SDK) Verification:
NEW FPGA DESIGN AND VERIFICATION TECHNIQUES MICHAL HUSEJKO IT-PES-ES Design: Part 1 High Level Synthesis (Xilinx Vivado HLS) Part 2 SDSoC (Xilinx, HLS + ARM) Part 3 OpenCL (Altera OpenCL SDK) Verification:
Accelerating DSP Applications in Embedded Systems with a Coprocessor Data-Path
 Accelerating DSP Applications in Embedded Systems with a Coprocessor Data-Path Michalis D. Galanis, Gregory Dimitroulakos, and Costas E. Goutis VLSI Design Laboratory, Electrical and Computer Engineering
Accelerating DSP Applications in Embedded Systems with a Coprocessor Data-Path Michalis D. Galanis, Gregory Dimitroulakos, and Costas E. Goutis VLSI Design Laboratory, Electrical and Computer Engineering
High Level Synthesis
 High Level Synthesis Design Representation Intermediate representation essential for efficient processing. Input HDL behavioral descriptions translated into some canonical intermediate representation.
High Level Synthesis Design Representation Intermediate representation essential for efficient processing. Input HDL behavioral descriptions translated into some canonical intermediate representation.
SpecC Methodology for High-Level Modeling
 EDP 2002 9 th IEEE/DATC Electronic Design Processes Workshop SpecC Methodology for High-Level Modeling Rainer Dömer Daniel D. Gajski Andreas Gerstlauer Center for Embedded Computer Systems Universitiy
EDP 2002 9 th IEEE/DATC Electronic Design Processes Workshop SpecC Methodology for High-Level Modeling Rainer Dömer Daniel D. Gajski Andreas Gerstlauer Center for Embedded Computer Systems Universitiy
Compiler Design. Fall Control-Flow Analysis. Prof. Pedro C. Diniz
 Compiler Design Fall 2015 Control-Flow Analysis Sample Exercises and Solutions Prof. Pedro C. Diniz USC / Information Sciences Institute 4676 Admiralty Way, Suite 1001 Marina del Rey, California 90292
Compiler Design Fall 2015 Control-Flow Analysis Sample Exercises and Solutions Prof. Pedro C. Diniz USC / Information Sciences Institute 4676 Admiralty Way, Suite 1001 Marina del Rey, California 90292
Synthesizable FPGA Fabrics Targetable by the VTR CAD Tool
 Synthesizable FPGA Fabrics Targetable by the VTR CAD Tool Jin Hee Kim and Jason Anderson FPL 2015 London, UK September 3, 2015 2 Motivation for Synthesizable FPGA Trend towards ASIC design flow Design
Synthesizable FPGA Fabrics Targetable by the VTR CAD Tool Jin Hee Kim and Jason Anderson FPL 2015 London, UK September 3, 2015 2 Motivation for Synthesizable FPGA Trend towards ASIC design flow Design
Hardware Design Environments. Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University
 Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Co-synthesis and Accelerator based Embedded System Design
 Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
Co-synthesis and Accelerator based Embedded System Design COE838: Embedded Computer System http://www.ee.ryerson.ca/~courses/coe838/ Dr. Gul N. Khan http://www.ee.ryerson.ca/~gnkhan Electrical and Computer
Cadence SystemC Design and Verification. NMI FPGA Network Meeting Jan 21, 2015
 Cadence SystemC Design and Verification NMI FPGA Network Meeting Jan 21, 2015 The High Level Synthesis Opportunity Raising Abstraction Improves Design & Verification Optimizes Power, Area and Timing for
Cadence SystemC Design and Verification NMI FPGA Network Meeting Jan 21, 2015 The High Level Synthesis Opportunity Raising Abstraction Improves Design & Verification Optimizes Power, Area and Timing for
Tour of common optimizations
 Tour of common optimizations Simple example foo(z) { x := 3 + 6; y := x 5 return z * y } Simple example foo(z) { x := 3 + 6; y := x 5; return z * y } x:=9; Applying Constant Folding Simple example foo(z)
Tour of common optimizations Simple example foo(z) { x := 3 + 6; y := x 5 return z * y } Simple example foo(z) { x := 3 + 6; y := x 5; return z * y } x:=9; Applying Constant Folding Simple example foo(z)
FPGAs: Instant Access
 FPGAs: Instant Access Clive"Max"Maxfield AMSTERDAM BOSTON HEIDELBERG LONDON NEW YORK OXFORD PARIS SAN DIEGO SAN FRANCISCO SINGAPORE SYDNEY TOKYO % ELSEVIER Newnes is an imprint of Elsevier Newnes Contents
FPGAs: Instant Access Clive"Max"Maxfield AMSTERDAM BOSTON HEIDELBERG LONDON NEW YORK OXFORD PARIS SAN DIEGO SAN FRANCISCO SINGAPORE SYDNEY TOKYO % ELSEVIER Newnes is an imprint of Elsevier Newnes Contents
Two HDLs used today VHDL. Why VHDL? Introduction to Structured VLSI Design
 Two HDLs used today Introduction to Structured VLSI Design VHDL I VHDL and Verilog Syntax and ``appearance'' of the two languages are very different Capabilities and scopes are quite similar Both are industrial
Two HDLs used today Introduction to Structured VLSI Design VHDL I VHDL and Verilog Syntax and ``appearance'' of the two languages are very different Capabilities and scopes are quite similar Both are industrial
High-Level Synthesis
 High-Level Synthesis 1 High-Level Synthesis 1. Basic definition 2. A typical HLS process 3. Scheduling techniques 4. Allocation and binding techniques 5. Advanced issues High-Level Synthesis 2 Introduction
High-Level Synthesis 1 High-Level Synthesis 1. Basic definition 2. A typical HLS process 3. Scheduling techniques 4. Allocation and binding techniques 5. Advanced issues High-Level Synthesis 2 Introduction
VHDL Essentials Simulation & Synthesis
 VHDL Essentials Simulation & Synthesis Course Description This course provides all necessary theoretical and practical know-how to design programmable logic devices using VHDL standard language. The course
VHDL Essentials Simulation & Synthesis Course Description This course provides all necessary theoretical and practical know-how to design programmable logic devices using VHDL standard language. The course
Introduction to Electronic Design Automation. Model of Computation. Model of Computation. Model of Computation
 Introduction to Electronic Design Automation Model of Computation Jie-Hong Roland Jiang 江介宏 Department of Electrical Engineering National Taiwan University Spring 03 Model of Computation In system design,
Introduction to Electronic Design Automation Model of Computation Jie-Hong Roland Jiang 江介宏 Department of Electrical Engineering National Taiwan University Spring 03 Model of Computation In system design,
What Compilers Can and Cannot Do. Saman Amarasinghe Fall 2009
 What Compilers Can and Cannot Do Saman Amarasinghe Fall 009 Optimization Continuum Many examples across the compilation pipeline Static Dynamic Program Compiler Linker Loader Runtime System Optimization
What Compilers Can and Cannot Do Saman Amarasinghe Fall 009 Optimization Continuum Many examples across the compilation pipeline Static Dynamic Program Compiler Linker Loader Runtime System Optimization
A Process Model suitable for defining and programming MpSoCs
 A Process Model suitable for defining and programming MpSoCs MpSoC-Workshop at Rheinfels, 29-30.6.2010 F. Mayer-Lindenberg, TU Hamburg-Harburg 1. Motivation 2. The Process Model 3. Mapping to MpSoC 4.
A Process Model suitable for defining and programming MpSoCs MpSoC-Workshop at Rheinfels, 29-30.6.2010 F. Mayer-Lindenberg, TU Hamburg-Harburg 1. Motivation 2. The Process Model 3. Mapping to MpSoC 4.
VHDL. VHDL History. Why VHDL? Introduction to Structured VLSI Design. Very High Speed Integrated Circuit (VHSIC) Hardware Description Language
 Hardware Description Language") VHDL Introduction to Structured VLSI Design VHDL I Very High Speed Integrated Circuit (VHSIC) Hardware Description Language Joachim Rodrigues A Technology Independent, Standard Hardware description Language
VHDL Introduction to Structured VLSI Design VHDL I Very High Speed Integrated Circuit (VHSIC) Hardware Description Language Joachim Rodrigues A Technology Independent, Standard Hardware description Language
MARKET demands urge embedded systems to incorporate
 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 19, NO. 3, MARCH 2011 429 High Performance and Area Efficient Flexible DSP Datapath Synthesis Sotirios Xydis, Student Member, IEEE,
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 19, NO. 3, MARCH 2011 429 High Performance and Area Efficient Flexible DSP Datapath Synthesis Sotirios Xydis, Student Member, IEEE,
USC 227 Office hours: 3-4 Monday and Wednesday CS553 Lecture 1 Introduction 4
 CS553 Compiler Construction Instructor: URL: Michelle Strout mstrout@cs.colostate.edu USC 227 Office hours: 3-4 Monday and Wednesday http://www.cs.colostate.edu/~cs553 CS553 Lecture 1 Introduction 3 Plan
CS553 Compiler Construction Instructor: URL: Michelle Strout mstrout@cs.colostate.edu USC 227 Office hours: 3-4 Monday and Wednesday http://www.cs.colostate.edu/~cs553 CS553 Lecture 1 Introduction 3 Plan
ECE 486/586. Computer Architecture. Lecture # 7
 ECE 486/586 Computer Architecture Lecture # 7 Spring 2015 Portland State University Lecture Topics Instruction Set Principles Instruction Encoding Role of Compilers The MIPS Architecture Reference: Appendix
ECE 486/586 Computer Architecture Lecture # 7 Spring 2015 Portland State University Lecture Topics Instruction Set Principles Instruction Encoding Role of Compilers The MIPS Architecture Reference: Appendix
Automated modeling of custom processors for DCT algorithm
 Automated modeling of custom processors for DCT algorithm D. Ivošević and V. Sruk Faculty of Electrical Engineering and Computing / Department of Electronics, Microelectronics, Computer and Intelligent
Automated modeling of custom processors for DCT algorithm D. Ivošević and V. Sruk Faculty of Electrical Engineering and Computing / Department of Electronics, Microelectronics, Computer and Intelligent
Topic 14: Scheduling COS 320. Compiling Techniques. Princeton University Spring Lennart Beringer
 Topic 14: Scheduling COS 320 Compiling Techniques Princeton University Spring 2016 Lennart Beringer 1 The Back End Well, let s see Motivating example Starting point Motivating example Starting point Multiplication
Topic 14: Scheduling COS 320 Compiling Techniques Princeton University Spring 2016 Lennart Beringer 1 The Back End Well, let s see Motivating example Starting point Motivating example Starting point Multiplication
Performance Improvements of Microprocessor Platforms with a Coarse-Grained Reconfigurable Data-Path
 Performance Improvements of Microprocessor Platforms with a Coarse-Grained Reconfigurable Data-Path MICHALIS D. GALANIS 1, GREGORY DIMITROULAKOS 2, COSTAS E. GOUTIS 3 VLSI Design Laboratory, Electrical
Performance Improvements of Microprocessor Platforms with a Coarse-Grained Reconfigurable Data-Path MICHALIS D. GALANIS 1, GREGORY DIMITROULAKOS 2, COSTAS E. GOUTIS 3 VLSI Design Laboratory, Electrical
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Design Verification Lecture 01
 M. Hsiao 1 Design Verification Lecture 01 Course Title: Verification of Digital Systems Professor: Michael Hsiao (355 Durham) Prerequisites: Digital Logic Design, C/C++ Programming, Data Structures, Computer
M. Hsiao 1 Design Verification Lecture 01 Course Title: Verification of Digital Systems Professor: Michael Hsiao (355 Durham) Prerequisites: Digital Logic Design, C/C++ Programming, Data Structures, Computer
Worst Case Execution Time Analysis for Synthesized Hardware
 Worst Case Execution Time Analysis for Synthesized Hardware Jun-hee Yoo ihavnoid@poppy.snu.ac.kr Seoul National University, Seoul, Republic of Korea Xingguang Feng fengxg@poppy.snu.ac.kr Seoul National
Worst Case Execution Time Analysis for Synthesized Hardware Jun-hee Yoo ihavnoid@poppy.snu.ac.kr Seoul National University, Seoul, Republic of Korea Xingguang Feng fengxg@poppy.snu.ac.kr Seoul National
Previous Exam Questions System-on-a-Chip (SoC) Design
 Design") This image cannot currently be displayed. EE382V Problem: System Analysis (20 Points) This is a simple single microprocessor core platform with a video coprocessor, which is configured to process 32 bytes
This image cannot currently be displayed. EE382V Problem: System Analysis (20 Points) This is a simple single microprocessor core platform with a video coprocessor, which is configured to process 32 bytes
Interface Synthesis using Memory Mapping for an FPGA Platform. CECS Technical Report #03-20 June 2003
 Interface Synthesis using Memory Mapping for an FPGA Platform Manev Luthra Sumit Gupta Nikil Dutt Rajesh Gupta Alex Nicolau CECS Technical Report #03-20 June 2003 Center for Embedded Computer Systems School
Interface Synthesis using Memory Mapping for an FPGA Platform Manev Luthra Sumit Gupta Nikil Dutt Rajesh Gupta Alex Nicolau CECS Technical Report #03-20 June 2003 Center for Embedded Computer Systems School
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
HIGH-LEVEL SYNTHESIS
 HIGH-LEVEL SYNTHESIS Page 1 HIGH-LEVEL SYNTHESIS High-level synthesis: the automatic addition of structural information to a design described by an algorithm. BEHAVIORAL D. STRUCTURAL D. Systems Algorithms
HIGH-LEVEL SYNTHESIS Page 1 HIGH-LEVEL SYNTHESIS High-level synthesis: the automatic addition of structural information to a design described by an algorithm. BEHAVIORAL D. STRUCTURAL D. Systems Algorithms
INTERNATIONAL JOURNAL OF PROFESSIONAL ENGINEERING STUDIES Volume VII /Issue 2 / OCT 2016
 NEW VLSI ARCHITECTURE FOR EXPLOITING CARRY- SAVE ARITHMETIC USING VERILOG HDL B.Anusha 1 Ch.Ramesh 2 shivajeehul@gmail.com 1 chintala12271@rediffmail.com 2 1 PG Scholar, Dept of ECE, Ganapathy Engineering
NEW VLSI ARCHITECTURE FOR EXPLOITING CARRY- SAVE ARITHMETIC USING VERILOG HDL B.Anusha 1 Ch.Ramesh 2 shivajeehul@gmail.com 1 chintala12271@rediffmail.com 2 1 PG Scholar, Dept of ECE, Ganapathy Engineering
Lecture 20: High-level Synthesis (1)
") Lecture 20: High-level Synthesis (1) Slides courtesy of Deming Chen Some slides are from Prof. S. Levitan of U. of Pittsburgh Outline High-level synthesis introduction High-level synthesis operations Scheduling
Lecture 20: High-level Synthesis (1) Slides courtesy of Deming Chen Some slides are from Prof. S. Levitan of U. of Pittsburgh Outline High-level synthesis introduction High-level synthesis operations Scheduling
EEL 4783: HDL in Digital System Design
 EEL 4783: HDL in Digital System Design Lecture 4: HLS Intro* Prof. Mingjie Lin *Notes are drawn from the textbook and the George Constantinides notes 1 Course Material Sources 1) Low-Power High-Level Synthesis
EEL 4783: HDL in Digital System Design Lecture 4: HLS Intro* Prof. Mingjie Lin *Notes are drawn from the textbook and the George Constantinides notes 1 Course Material Sources 1) Low-Power High-Level Synthesis
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Reconfigurable Computing. Introduction
 Reconfigurable Computing Tony Givargis and Nikil Dutt Introduction! Reconfigurable computing, a new paradigm for system design Post fabrication software personalization for hardware computation Traditionally
Reconfigurable Computing Tony Givargis and Nikil Dutt Introduction! Reconfigurable computing, a new paradigm for system design Post fabrication software personalization for hardware computation Traditionally
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture
 Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture Ramadass Nagarajan Karthikeyan Sankaralingam Haiming Liu Changkyu Kim Jaehyuk Huh Doug Burger Stephen W. Keckler Charles R. Moore Computer
Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture Ramadass Nagarajan Karthikeyan Sankaralingam Haiming Liu Changkyu Kim Jaehyuk Huh Doug Burger Stephen W. Keckler Charles R. Moore Computer
System Level Design Flow
 System Level Design Flow What is needed and what is not Daniel D. Gajski Center for Embedded Computer Systems University of California, Irvine www.cecs.uci.edu/~gajski System Level Design Flow What is
System Level Design Flow What is needed and what is not Daniel D. Gajski Center for Embedded Computer Systems University of California, Irvine www.cecs.uci.edu/~gajski System Level Design Flow What is
Low energy and High-performance Embedded Systems Design and Reconfigurable Architectures
 Low energy and High-performance Embedded Systems Design and Reconfigurable Architectures Ass. Professor Dimitrios Soudris School of Electrical and Computer Eng., National Technical Univ. of Athens, Greece
Low energy and High-performance Embedded Systems Design and Reconfigurable Architectures Ass. Professor Dimitrios Soudris School of Electrical and Computer Eng., National Technical Univ. of Athens, Greece
Verilog Essentials Simulation & Synthesis
 Verilog Essentials Simulation & Synthesis Course Description This course provides all necessary theoretical and practical know-how to design programmable logic devices using Verilog standard language.
Verilog Essentials Simulation & Synthesis Course Description This course provides all necessary theoretical and practical know-how to design programmable logic devices using Verilog standard language.
xpilot: A Platform-Based Behavioral Synthesis System
 xpilot: A Platform-Based Behavioral Synthesis System Deming Chen, Jason Cong, Yiping Fan, Guoling Han, Wei Jiang, Zhiru Zhang University of California, Los Angeles Email: {demingc, cong, fanyp, leohgl,
xpilot: A Platform-Based Behavioral Synthesis System Deming Chen, Jason Cong, Yiping Fan, Guoling Han, Wei Jiang, Zhiru Zhang University of California, Los Angeles Email: {demingc, cong, fanyp, leohgl,
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Interface Synthesis using Memory Mapping for an FPGA Platform Λ
 Interface Synthesis using Memory Mapping for an FPGA Platform Λ Manev Luthra Sumit Gupta Nikil Dutt Rajesh Gupta Alex Nicolau Center for Embedded Computer Systems Dept. of Computer Science and Engineering
Interface Synthesis using Memory Mapping for an FPGA Platform Λ Manev Luthra Sumit Gupta Nikil Dutt Rajesh Gupta Alex Nicolau Center for Embedded Computer Systems Dept. of Computer Science and Engineering
SDSoC: Session 1
 SDSoC: Session 1 ADAM@ADIUVOENGINEERING.COM What is SDSoC SDSoC is a system optimising compiler which allows us to optimise Zynq PS / PL Zynq MPSoC PS / PL MicroBlaze What does this mean? Following the
SDSoC: Session 1 ADAM@ADIUVOENGINEERING.COM What is SDSoC SDSoC is a system optimising compiler which allows us to optimise Zynq PS / PL Zynq MPSoC PS / PL MicroBlaze What does this mean? Following the
Administration. Prerequisites. Meeting times. CS 380C: Advanced Topics in Compilers
 Administration CS 380C: Advanced Topics in Compilers Instructor: eshav Pingali Professor (CS, ICES) Office: POB 4.126A Email: pingali@cs.utexas.edu TA: TBD Graduate student (CS) Office: Email: Meeting
Administration CS 380C: Advanced Topics in Compilers Instructor: eshav Pingali Professor (CS, ICES) Office: POB 4.126A Email: pingali@cs.utexas.edu TA: TBD Graduate student (CS) Office: Email: Meeting
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
CSE 501: Compiler Construction. Course outline. Goals for language implementation. Why study compilers? Models of compilation
 CSE 501: Compiler Construction Course outline Main focus: program analysis and transformation how to represent programs? how to analyze programs? what to analyze? how to transform programs? what transformations
CSE 501: Compiler Construction Course outline Main focus: program analysis and transformation how to represent programs? how to analyze programs? what to analyze? how to transform programs? what transformations
CS377P Programming for Performance Single Thread Performance Out-of-order Superscalar Pipelines
 CS377P Programming for Performance Single Thread Performance Out-of-order Superscalar Pipelines Sreepathi Pai UTCS September 14, 2015 Outline 1 Introduction 2 Out-of-order Scheduling 3 The Intel Haswell
CS377P Programming for Performance Single Thread Performance Out-of-order Superscalar Pipelines Sreepathi Pai UTCS September 14, 2015 Outline 1 Introduction 2 Out-of-order Scheduling 3 The Intel Haswell
What Do Compilers Do? How Can the Compiler Improve Performance? What Do We Mean By Optimization?
 What Do Compilers Do? Lecture 1 Introduction I What would you get out of this course? II Structure of a Compiler III Optimization Example Reference: Muchnick 1.3-1.5 1. Translate one language into another
What Do Compilers Do? Lecture 1 Introduction I What would you get out of this course? II Structure of a Compiler III Optimization Example Reference: Muchnick 1.3-1.5 1. Translate one language into another
ECE1387 Exercise 3: Using the LegUp High-level Synthesis Framework
 ECE1387 Exercise 3: Using the LegUp High-level Synthesis Framework 1 Introduction and Motivation This lab will give you an overview of how to use the LegUp high-level synthesis framework. In LegUp, you
ECE1387 Exercise 3: Using the LegUp High-level Synthesis Framework 1 Introduction and Motivation This lab will give you an overview of how to use the LegUp high-level synthesis framework. In LegUp, you
COP5621 Exam 4 - Spring 2005
 COP5621 Exam 4 - Spring 2005 Name: (Please print) Put the answers on these sheets. Use additional sheets when necessary. Show how you derived your answer when applicable (this is required for full credit
COP5621 Exam 4 - Spring 2005 Name: (Please print) Put the answers on these sheets. Use additional sheets when necessary. Show how you derived your answer when applicable (this is required for full credit
Automatic Counterflow Pipeline Synthesis
 Automatic Counterflow Pipeline Synthesis Bruce R. Childers, Jack W. Davidson Computer Science Department University of Virginia Charlottesville, Virginia 22901 {brc2m, jwd}@cs.virginia.edu Abstract The
Automatic Counterflow Pipeline Synthesis Bruce R. Childers, Jack W. Davidson Computer Science Department University of Virginia Charlottesville, Virginia 22901 {brc2m, jwd}@cs.virginia.edu Abstract The
Controller FSM Design Issues : Correctness and Efficiency. Lecture Notes # 10. CAD Based Logic Design ECE 368
 ECE 368 CAD Based Logic Design Lecture Notes # 10 Controller FSM Design Issues : Correctness and Efficiency SHANTANU DUTT Department of Electrical & Computer Engineering University of Illinois, Chicago
ECE 368 CAD Based Logic Design Lecture Notes # 10 Controller FSM Design Issues : Correctness and Efficiency SHANTANU DUTT Department of Electrical & Computer Engineering University of Illinois, Chicago
MOJTABA MAHDAVI Mojtaba Mahdavi DSP Design Course, EIT Department, Lund University, Sweden
 High Level Synthesis with Catapult MOJTABA MAHDAVI 1 Outline High Level Synthesis HLS Design Flow in Catapult Data Types Project Creation Design Setup Data Flow Analysis Resource Allocation Scheduling
High Level Synthesis with Catapult MOJTABA MAHDAVI 1 Outline High Level Synthesis HLS Design Flow in Catapult Data Types Project Creation Design Setup Data Flow Analysis Resource Allocation Scheduling
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
NISC Technology Online Toolset
 NISC Technology Online Toolset Mehrdad Reshadi, Bita Gorjiara, Daniel Gajski Technical Report CECS-05-19 December 2005 Center for Embedded Computer Systems University of California Irvine Irvine, CA 92697-3425,
NISC Technology Online Toolset Mehrdad Reshadi, Bita Gorjiara, Daniel Gajski Technical Report CECS-05-19 December 2005 Center for Embedded Computer Systems University of California Irvine Irvine, CA 92697-3425,
Loop Optimizations. Outline. Loop Invariant Code Motion. Induction Variables. Loop Invariant Code Motion. Loop Invariant Code Motion
 Outline Loop Optimizations Induction Variables Recognition Induction Variables Combination of Analyses Copyright 2010, Pedro C Diniz, all rights reserved Students enrolled in the Compilers class at the
Outline Loop Optimizations Induction Variables Recognition Induction Variables Combination of Analyses Copyright 2010, Pedro C Diniz, all rights reserved Students enrolled in the Compilers class at the
April 9, 2000 DIS chapter 1
 April 9, 2000 DIS chapter 1 GEINTEGREERDE SYSTEMEN VOOR DIGITALE SIGNAALVERWERKING: ONTWERPCONCEPTEN EN ARCHITECTUURCOMPONENTEN INTEGRATED SYSTEMS FOR REAL- TIME DIGITAL SIGNAL PROCESSING: DESIGN CONCEPTS
April 9, 2000 DIS chapter 1 GEINTEGREERDE SYSTEMEN VOOR DIGITALE SIGNAALVERWERKING: ONTWERPCONCEPTEN EN ARCHITECTUURCOMPONENTEN INTEGRATED SYSTEMS FOR REAL- TIME DIGITAL SIGNAL PROCESSING: DESIGN CONCEPTS
A comparative evaluation of high-level hardware synthesis using Reed-Solomon decoder
 A comparative evaluation of high-level hardware synthesis using Reed-Solomon decoder The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters.
A comparative evaluation of high-level hardware synthesis using Reed-Solomon decoder The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters.
Lecture 7. Instruction Scheduling. I. Basic Block Scheduling II. Global Scheduling (for Non-Numeric Code)
") Lecture 7 Instruction Scheduling I. Basic Block Scheduling II. Global Scheduling (for Non-Numeric Code) Reading: Chapter 10.3 10.4 CS243: Instruction Scheduling 1 Scheduling Constraints Data dependences
Lecture 7 Instruction Scheduling I. Basic Block Scheduling II. Global Scheduling (for Non-Numeric Code) Reading: Chapter 10.3 10.4 CS243: Instruction Scheduling 1 Scheduling Constraints Data dependences
Control flow graphs and loop optimizations. Thursday, October 24, 13
 Control flow graphs and loop optimizations Agenda Building control flow graphs Low level loop optimizations Code motion Strength reduction Unrolling High level loop optimizations Loop fusion Loop interchange
Control flow graphs and loop optimizations Agenda Building control flow graphs Low level loop optimizations Code motion Strength reduction Unrolling High level loop optimizations Loop fusion Loop interchange
קורס VHDL for High Performance. VHDL
 קורס VHDL for High Performance תיאור הקורס קורסזהמספקאתכלהידע התיאורטיוהמעשילכתיבתקודHDL. VHDL לסינתזה בעזרת שפת הסטנדרט הקורסמעמיקמאודומלמדאת הדרךהיעילהלכתיבתקודVHDL בכדילקבלאתמימושתכןהלוגי המדויק. הקורסמשלב
קורס VHDL for High Performance תיאור הקורס קורסזהמספקאתכלהידע התיאורטיוהמעשילכתיבתקודHDL. VHDL לסינתזה בעזרת שפת הסטנדרט הקורסמעמיקמאודומלמדאת הדרךהיעילהלכתיבתקודVHDL בכדילקבלאתמימושתכןהלוגי המדויק. הקורסמשלב
8. Best Practices for Incremental Compilation Partitions and Floorplan Assignments
 8. Best Practices for Incremental Compilation Partitions and Floorplan Assignments QII51017-9.0.0 Introduction The Quartus II incremental compilation feature allows you to partition a design, compile partitions
8. Best Practices for Incremental Compilation Partitions and Floorplan Assignments QII51017-9.0.0 Introduction The Quartus II incremental compilation feature allows you to partition a design, compile partitions
An Algorithm for the Allocation of Functional Units from. Realistic RT Component Libraries. Department of Information and Computer Science
 An Algorithm for the Allocation of Functional Units from Realistic RT Component Libraries Roger Ang rang@ics.uci.edu Nikil Dutt dutt@ics.uci.edu Department of Information and Computer Science University
An Algorithm for the Allocation of Functional Units from Realistic RT Component Libraries Roger Ang rang@ics.uci.edu Nikil Dutt dutt@ics.uci.edu Department of Information and Computer Science University
A Partitioning Flow for Accelerating Applications in Processor-FPGA Systems
 A Partitioning Flow for Accelerating Applications in Processor-FPGA Systems MICHALIS D. GALANIS 1, GREGORY DIMITROULAKOS 2, COSTAS E. GOUTIS 3 VLSI Design Laboratory, Electrical & Computer Engineering
A Partitioning Flow for Accelerating Applications in Processor-FPGA Systems MICHALIS D. GALANIS 1, GREGORY DIMITROULAKOS 2, COSTAS E. GOUTIS 3 VLSI Design Laboratory, Electrical & Computer Engineering
High-Level Synthesis of Programmable Hardware Accelerators Considering Potential Varieties
 THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS TECHNICAL REPORT OF IEICE.,, (VDEC) 113 8656 7 3 1 CREST E-mail: hiroaki@cad.t.u-tokyo.ac.jp, fujita@ee.t.u-tokyo.ac.jp SoC Abstract
THE INSTITUTE OF ELECTRONICS, INFORMATION AND COMMUNICATION ENGINEERS TECHNICAL REPORT OF IEICE.,, (VDEC) 113 8656 7 3 1 CREST E-mail: hiroaki@cad.t.u-tokyo.ac.jp, fujita@ee.t.u-tokyo.ac.jp SoC Abstract
VHDL: RTL Synthesis Basics. 1 of 59
 VHDL: RTL Synthesis Basics 1 of 59 Goals To learn the basics of RTL synthesis. To be able to synthesize a digital system, given its VHDL model. To be able to relate VHDL code to its synthesized output.
VHDL: RTL Synthesis Basics 1 of 59 Goals To learn the basics of RTL synthesis. To be able to synthesize a digital system, given its VHDL model. To be able to relate VHDL code to its synthesized output.
SystemVerilog Essentials Simulation & Synthesis
 SystemVerilog Essentials Simulation & Synthesis Course Description This course provides all necessary theoretical and practical know-how to design programmable logic devices using SystemVerilog standard
SystemVerilog Essentials Simulation & Synthesis Course Description This course provides all necessary theoretical and practical know-how to design programmable logic devices using SystemVerilog standard
Multi-Level Computing Architectures (MLCA)
") Multi-Level Computing Architectures (MLCA) Faraydon Karim ST US-Fellow Emerging Architectures Advanced System Technology STMicroelectronics Outline MLCA What s the problem Traditional solutions: VLIW,
Multi-Level Computing Architectures (MLCA) Faraydon Karim ST US-Fellow Emerging Architectures Advanced System Technology STMicroelectronics Outline MLCA What s the problem Traditional solutions: VLIW,
HW/SW Co-design. Design of Embedded Systems Jaap Hofstede Version 3, September 1999
 HW/SW Co-design Design of Embedded Systems Jaap Hofstede Version 3, September 1999 Embedded system Embedded Systems is a computer system (combination of hardware and software) is part of a larger system
HW/SW Co-design Design of Embedded Systems Jaap Hofstede Version 3, September 1999 Embedded system Embedded Systems is a computer system (combination of hardware and software) is part of a larger system
SoC Design for the New Millennium Daniel D. Gajski
 SoC Design for the New Millennium Daniel D. Gajski Center for Embedded Computer Systems University of California, Irvine www.cecs.uci.edu/~gajski Outline System gap Design flow Model algebra System environment
SoC Design for the New Millennium Daniel D. Gajski Center for Embedded Computer Systems University of California, Irvine www.cecs.uci.edu/~gajski Outline System gap Design flow Model algebra System environment
CS Computer Architecture
 CS 35101 Computer Architecture Section 600 Dr. Angela Guercio Fall 2010 An Example Implementation In principle, we could describe the control store in binary, 36 bits per word. We will use a simple symbolic
CS 35101 Computer Architecture Section 600 Dr. Angela Guercio Fall 2010 An Example Implementation In principle, we could describe the control store in binary, 36 bits per word. We will use a simple symbolic
Pilot: A Platform-based HW/SW Synthesis System
 Pilot: A Platform-based HW/SW Synthesis System SOC Group, VLSI CAD Lab, UCLA Led by Jason Cong Zhong Chen, Yiping Fan, Xun Yang, Zhiru Zhang ICSOC Workshop, Beijing August 20, 2002 Outline Overview The
Pilot: A Platform-based HW/SW Synthesis System SOC Group, VLSI CAD Lab, UCLA Led by Jason Cong Zhong Chen, Yiping Fan, Xun Yang, Zhiru Zhang ICSOC Workshop, Beijing August 20, 2002 Outline Overview The
EE382V: System-on-a-Chip (SoC) Design
 Design") EE382V: System-on-a-Chip (SoC) Design Lecture 8 HW/SW Co-Design Sources: Prof. Margarida Jacome, UT Austin Andreas Gerstlauer Electrical and Computer Engineering University of Texas at Austin gerstl@ece.utexas.edu
EE382V: System-on-a-Chip (SoC) Design Lecture 8 HW/SW Co-Design Sources: Prof. Margarida Jacome, UT Austin Andreas Gerstlauer Electrical and Computer Engineering University of Texas at Austin gerstl@ece.utexas.edu
Advanced Instruction-Level Parallelism
 Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
The S6000 Family of Processors
 The S6000 Family of Processors Today s Design Challenges The advent of software configurable processors In recent years, the widespread adoption of digital technologies has revolutionized the way in which
The S6000 Family of Processors Today s Design Challenges The advent of software configurable processors In recent years, the widespread adoption of digital technologies has revolutionized the way in which
Synthesis at different abstraction levels
 Synthesis at different abstraction levels System Level Synthesis Clustering. Communication synthesis. High-Level Synthesis Resource or time constrained scheduling Resource allocation. Binding Register-Transfer
Synthesis at different abstraction levels System Level Synthesis Clustering. Communication synthesis. High-Level Synthesis Resource or time constrained scheduling Resource allocation. Binding Register-Transfer
Sequential Circuit Design: Principle
 Sequential Circuit Design: Principle Chapter 8 1 Outline 1. Overview on sequential circuits 2. Synchronous circuits 3. Danger of synthesizing asynchronous circuit 4. Inference of basic memory elements
Sequential Circuit Design: Principle Chapter 8 1 Outline 1. Overview on sequential circuits 2. Synchronous circuits 3. Danger of synthesizing asynchronous circuit 4. Inference of basic memory elements
System Level Design For Low Power. Yard. Doç. Dr. Berna Örs Yalçın
 System Level Design For Low Power Yard. Doç. Dr. Berna Örs Yalçın References System-Level Design Methodology, Daniel D. Gajski Hardware-software co-design of embedded systems : the POLIS approach / by
System Level Design For Low Power Yard. Doç. Dr. Berna Örs Yalçın References System-Level Design Methodology, Daniel D. Gajski Hardware-software co-design of embedded systems : the POLIS approach / by