A superscalar machine is one in which multiple instruction streams allow completion of more than one instruction per cycle.
|
|
|
- Reynold McLaughlin
- 6 years ago
- Views:
Transcription
1 CS 320 Ch. 16 SuperScalar Machines A superscalar machine is one in which multiple instruction streams allow completion of more than one instruction per cycle. A superpipelined machine is one in which a single pipeline is double clocked so that two instructions are executed per clock cycle. Instruction level parallelism is a measure of the degree to which multiple instructions can be executed in parallel. Superscalar machines can execute instructions out of order. Either the compiler or the CPU hardware recognizes instruction sequences, determines dependencies, and allows rearrangement of instructions. The author lists five limitations to instruction level parallelism. True data dependency (RAW) procedural dependency resource conflicts output dependency (WAW) antidependency (WAR) Here is an example of a true data dependency. add r1, r2 mov r3, r1 ;can't do this until after the add In the pipeline for a true data dependency a NOP is added to allow one instruction to complete. A procedural dependency is one in which the instruction following a branch forms a procedural dependency. Without executing the branch you don't know what instruction to execute next. instruction level parallelism vs machine level parallelism Instruction level parallelism exists when instructions have no dependencies and thus can be executed in parallel. Machine level parallelism is the ability of a machine to exploit instruction level parallelism. Instructions come out of memory in proper order. The processor can then reorder these instructions and issue them to the pipeline in a different order to achieve some parallelism and efficiency. This process is called the instruction issue policy. There are three instruction issue policies in use. In-order issue with in-order completion in-order issue with out-of-order completion out-of-order issue with out-of-order completion.

2 The following figure illustrates issue policy. A) In-order issue with in-order completion B) in-order issue with out-of-order completion C) out-of-order issue with out-of-order completion. I1 requires 2 cycles to execute I3 and I4 conflict for the same functional unit I5 depends on the value produced by I4 I5 and I6 conflict for a functional unit. The register window that sits between the decode and the execute unit is a buffer that hold decoded instructions that are ready for execution. this buffer is significant because it is the thing that allows look ahead to determine what instructions can be done in parallel and in what order.
3 The following code is an example of an output dependency (WAW) I1: R3 R3 op 5 I2: R4 R3 + 1 I3: R3 R5 + 1 I4: R7 R3 op R4 I2 cannot execute before I1 since it needs the result in R3. This is a data dependency. I4 cannot execute before I3 for similar reasons. But I1 and I3 have an output dependency. If I3 executes before I1 then the wrong value will be loaded into R3. This is an output dependency. The following code illustrates an antidependency. (WAR) I1: R3 R3 op R5 I2: R4 R3 + 1 I3: R3 R5 + 1 I4: R7 R3 op R4 I3 cannot complete before I2 since I2 uses the old value of R3 and not the value created by I3. This is like a data dependency only reversed in time. Register renaming: To avoid antidependencies and output dependencies, a register may be allocated in two forms: one form has its old value and one form gets the new value. This allows the old value to be used while the new value is calculated and changed. This renaming is done in hardware. The author cites simulation studies that indicate that without register renaming, the gains from added functional units are not significant. ********************************************* PENTIUM The Pentium 4 architecture is said to be a CISC shell around a RISC core. The Inherited CISC instruction set is converted to microoperations that are more RISC like. These are fed into a superscalar pipeline.
 The diagram shows three caches. L2 cache holds data an instructions. The trace cache is the instruction L1 cache.")
4 The figure below shows the Pentium 4 block diagram. Answer the questions below related to this diagram. A) The P4 is said to have an in-order front end. Instructions are fetched from memory in static order. B) The diagram shows three caches. L2 cache holds data an instructions. The trace cache is the instruction L1 cache. The L1 D cache is the L1 data cache. C) The P4 instructions are of variable length (inherited all the way back to the 8080). The trace cache gets 64 bytes at a time from the L2 cache. The fetch/decode unit scans the bytes and finds instruction boundaries. Each instruction is broken up into from one to four micro-ops each of which is 118-bits long. These RISC like instructions are then used in the instruction pipeline. D) The 118 bit micro-ops are needed to accommodate the CISC instructions on the P4. E) The micro-ops go into the L1 instruction cache (trace cache) after being generated. F) The branch history is done at the trace cache and the branch target buffer logic (BTB). There are 4 bits for branch history since the pipe is 20 stages long, accurate branch prediction is essential. If an instruction has no history then static branch prediction is used. G) For static branch prediction there are three rules for prediction conditional branches with no history: 1) If not IP relative predict taken if the branch is a return, otherwise not taken. 2) If IP relative backward predict taken. 3) If IP relative forward predict not taken. H) The micro-ops are executed out-of-order. The order depends on dependencies. I) Some instructions may require the execution of hundreds of microinstructions. For instructions which require more than four microops, the microop is sent to a microprogram ROM which in turn, generates hundreds of microinstructions if necessary.
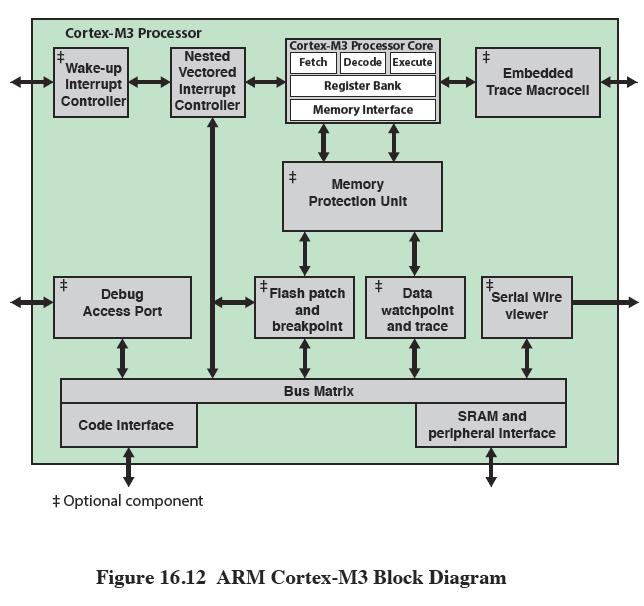
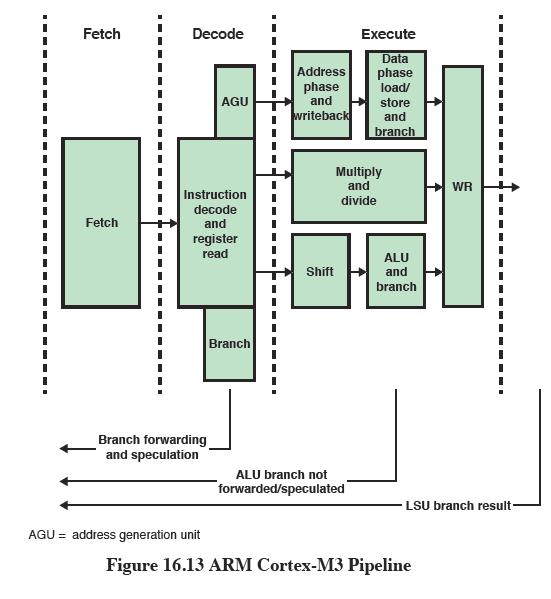
5 J) The P4 does register renaming. It remaps 16 architectural registers into a set of 128 physical registers. It thereby removes antidependencies and output dependencies. K) Note that register renaming does not eliminate data dependencies. This is not possible. L) If a branch prediction is wrong micro-ops are flushed from the pipe and a correction is made to the branch predictor logic. M) It is critical that the P4 pipeline do a good job of branch prediction because the pipe is so long that it is expensive to flush. ARM Cortex A3 The figure below is an architectural diagram of the ARM Cortex M3 processor. In the center of the diagram is a Memory Protection Unit. This unit restricts access of data within a process so that two processes don't interfere with one another. This is used in multiprocess applications. This processor has a pipeline. Fetch, Decode, Execute There is also a Wake-up interrupt controller which allows processor to go to sleep in a very low-power mode and wake up in response to an external stimulus. This processor uses the Thumb-2 instruction set. This has mostly 16-bit Thumb1 instructions but has a few (5) 32-bit instructions. In the instruction decode stage of the pipeline the hardware decodes the instruction, generates addresses for the load/store unit, and does a branch based on offset or link register. The link register is a one level stack that is built into the registers. This processor does not do branch prediction. This is too complicated for a microcontroller. To deal with branches the processor uses Branch Forwarding and Branch Speculation. In Branch forwarding some branches are pushed ahead by one cycle in the pipeline to speed things up. In Branch speculation conditional branches the branch target is fetched speculatively before it is known that the branch will be taken.
6
7
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 14 Instruction Level Parallelism and Superscalar Processors
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 14 Instruction Level Parallelism and Superscalar Processors What is Superscalar? Common instructions (arithmetic, load/store,
William Stallings Computer Organization and Architecture 8 th Edition Chapter 14 Instruction Level Parallelism and Superscalar Processors What is Superscalar? Common instructions (arithmetic, load/store,
Superscalar Processors
 Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
TECH. CH14 Instruction Level Parallelism and Superscalar Processors. What is Superscalar? Why Superscalar? General Superscalar Organization
 CH14 Instruction Level Parallelism and Superscalar Processors Decode and issue more and one instruction at a time Executing more than one instruction at a time More than one Execution Unit What is Superscalar?
CH14 Instruction Level Parallelism and Superscalar Processors Decode and issue more and one instruction at a time Executing more than one instruction at a time More than one Execution Unit What is Superscalar?
What is Superscalar? CSCI 4717 Computer Architecture. Why the drive toward Superscalar? What is Superscalar? (continued) In class exercise
 In class exercise") CSCI 4717/5717 Computer Architecture Topic: Instruction Level Parallelism Reading: Stallings, Chapter 14 What is Superscalar? A machine designed to improve the performance of the execution of scalar instructions.
CSCI 4717/5717 Computer Architecture Topic: Instruction Level Parallelism Reading: Stallings, Chapter 14 What is Superscalar? A machine designed to improve the performance of the execution of scalar instructions.
Architectures & instruction sets R_B_T_C_. von Neumann architecture. Computer architecture taxonomy. Assembly language.
 Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Organisasi Sistem Komputer
 LOGO Organisasi Sistem Komputer OSK 11 Superscalar Pendidikan Teknik Elektronika FT UNY What is Superscalar? Common instructions (arithmetic, load/store, conditional branch) can be initiated and executed
LOGO Organisasi Sistem Komputer OSK 11 Superscalar Pendidikan Teknik Elektronika FT UNY What is Superscalar? Common instructions (arithmetic, load/store, conditional branch) can be initiated and executed
Superscalar Machines. Characteristics of superscalar processors
 Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Superscalar Processing (5) Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?
 Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?") Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14
 Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Superscalar Processors
 Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Computer Systems Architecture I. CSE 560M Lecture 10 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
ASSEMBLY LANGUAGE MACHINE ORGANIZATION
 ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
Lecture 9: Superscalar processing
 Lecture 9 Superscalar processors Superscalar- processing Stallings: Ch 14 Instruction dependences Register renaming Pentium / PowerPC Goal Concurrent execution of scalar instructions Several independent
Lecture 9 Superscalar processors Superscalar- processing Stallings: Ch 14 Instruction dependences Register renaming Pentium / PowerPC Goal Concurrent execution of scalar instructions Several independent
Superscalar Processors Ch 13. Superscalar Processing (5) Computer Organization II 10/10/2001. New dependency for superscalar case? (8) Name dependency
 Computer Organization II 10/10/2001. New dependency for superscalar case? (8) Name dependency") Superscalar Processors Ch 13 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction 1 New dependency for superscalar case? (8) Name dependency (nimiriippuvuus) two use the same
Superscalar Processors Ch 13 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction 1 New dependency for superscalar case? (8) Name dependency (nimiriippuvuus) two use the same
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
RISC & Superscalar. COMP 212 Computer Organization & Architecture. COMP 212 Fall Lecture 12. Instruction Pipeline no hazard.
 COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU
 1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
Chapter 13 Reduced Instruction Set Computers
 Chapter 13 Reduced Instruction Set Computers Contents Instruction execution characteristics Use of a large register file Compiler-based register optimization Reduced instruction set architecture RISC pipelining
Chapter 13 Reduced Instruction Set Computers Contents Instruction execution characteristics Use of a large register file Compiler-based register optimization Reduced instruction set architecture RISC pipelining
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Branch Prediction & Speculative Execution. Branch Penalties in Modern Pipelines
 6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
Dynamic Scheduling. CSE471 Susan Eggers 1
 Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
Processing Unit CS206T
 Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Chapter 5. Introduction ARM Cortex series
 Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
Chapter 5 Introduction ARM Cortex series 5.1 ARM Cortex series variants 5.2 ARM Cortex A series 5.3 ARM Cortex R series 5.4 ARM Cortex M series 5.5 Comparison of Cortex M series with 8/16 bit MCUs 51 5.1
In embedded systems there is a trade off between performance and power consumption. Using ILP saves power and leads to DECREASING clock frequency.
 Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Tutorial 4 KE What are the differences among sequential access, direct access, and random access?
 Tutorial 4 KE40703 1. What are the differences among sequential access, direct access, and random access? Sequential access: Memory is organized into units of data, called records. Access must be made
Tutorial 4 KE40703 1. What are the differences among sequential access, direct access, and random access? Sequential access: Memory is organized into units of data, called records. Access must be made
Ti Parallel Computing PIPELINING. Michał Roziecki, Tomáš Cipr
 Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
CS 152 Computer Architecture and Engineering. Lecture 12 - Advanced Out-of-Order Superscalars
 CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
Hyperthreading Technology
 Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Basic Computer Architecture
 Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Pipelining, Branch Prediction, Trends
 Pipelining, Branch Prediction, Trends 10.1-10.4 Topics 10.1 Quantitative Analyses of Program Execution 10.2 From CISC to RISC 10.3 Pipelining the Datapath Branch Prediction, Delay Slots 10.4 Overlapping
Pipelining, Branch Prediction, Trends 10.1-10.4 Topics 10.1 Quantitative Analyses of Program Execution 10.2 From CISC to RISC 10.3 Pipelining the Datapath Branch Prediction, Delay Slots 10.4 Overlapping
Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
") Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Pipeline issues. Pipeline hazard: RaW. Pipeline hazard: RaW. Calcolatori Elettronici e Sistemi Operativi. Hazards. Data hazard.
 Calcolatori Elettronici e Sistemi Operativi Pipeline issues Hazards Pipeline issues Data hazard Control hazard Structural hazard Pipeline hazard: RaW Pipeline hazard: RaW 5 6 7 8 9 5 6 7 8 9 : add R,R,R
Calcolatori Elettronici e Sistemi Operativi Pipeline issues Hazards Pipeline issues Data hazard Control hazard Structural hazard Pipeline hazard: RaW Pipeline hazard: RaW 5 6 7 8 9 5 6 7 8 9 : add R,R,R
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5
 EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Chapter 4. MARIE: An Introduction to a Simple Computer 4.8 MARIE 4.8 MARIE A Discussion on Decoding
 4.8 MARIE This is the MARIE architecture shown graphically. Chapter 4 MARIE: An Introduction to a Simple Computer 2 4.8 MARIE MARIE s Full Instruction Set A computer s control unit keeps things synchronized,
4.8 MARIE This is the MARIE architecture shown graphically. Chapter 4 MARIE: An Introduction to a Simple Computer 2 4.8 MARIE MARIE s Full Instruction Set A computer s control unit keeps things synchronized,
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS Computer Architecture
 CS 35101 Computer Architecture Section 600 Dr. Angela Guercio Fall 2010 An Example Implementation In principle, we could describe the control store in binary, 36 bits per word. We will use a simple symbolic
CS 35101 Computer Architecture Section 600 Dr. Angela Guercio Fall 2010 An Example Implementation In principle, we could describe the control store in binary, 36 bits per word. We will use a simple symbolic
Portland State University ECE 587/687. Memory Ordering
 Portland State University ECE 587/687 Memory Ordering Copyright by Alaa Alameldeen, Zeshan Chishti and Haitham Akkary 2018 Handling Memory Operations Review pipeline for out of order, superscalar processors
Portland State University ECE 587/687 Memory Ordering Copyright by Alaa Alameldeen, Zeshan Chishti and Haitham Akkary 2018 Handling Memory Operations Review pipeline for out of order, superscalar processors
omputer Design Concept adao Nakamura
 omputer Design Concept adao Nakamura akamura@archi.is.tohoku.ac.jp akamura@umunhum.stanford.edu 1 1 Pascal s Calculator Leibniz s Calculator Babbage s Calculator Von Neumann Computer Flynn s Classification
omputer Design Concept adao Nakamura akamura@archi.is.tohoku.ac.jp akamura@umunhum.stanford.edu 1 1 Pascal s Calculator Leibniz s Calculator Babbage s Calculator Von Neumann Computer Flynn s Classification
The Microarchitecture Level
 The Microarchitecture Level Chapter 4 The Data Path (1) The data path of the example microarchitecture used in this chapter. The Data Path (2) Useful combinations of ALU signals and the function performed.
The Microarchitecture Level Chapter 4 The Data Path (1) The data path of the example microarchitecture used in this chapter. The Data Path (2) Useful combinations of ALU signals and the function performed.
Hardware Speculation Support
 Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
Hardware Speculation Support Conditional instructions Most common form is conditional move BNEZ R1, L ;if MOV R2, R3 ;then CMOVZ R2,R3, R1 L: ;else Other variants conditional loads and stores nullification
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
SYLLABUS. osmania university CHAPTER - 1 : REGISTER TRANSFER LANGUAGE AND MICRO OPERATION CHAPTER - 2 : BASIC COMPUTER
 Contents i SYLLABUS osmania university UNIT - I CHAPTER - 1 : REGISTER TRANSFER LANGUAGE AND MICRO OPERATION Difference between Computer Organization and Architecture, RTL Notation, Common Bus System using
Contents i SYLLABUS osmania university UNIT - I CHAPTER - 1 : REGISTER TRANSFER LANGUAGE AND MICRO OPERATION Difference between Computer Organization and Architecture, RTL Notation, Common Bus System using
Control Hazards. Branch Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Lecture 5: Instruction Pipelining. Pipeline hazards. Sequential execution of an N-stage task: N Task 2
 Lecture 5: Instruction Pipelining Basic concepts Pipeline hazards Branch handling and prediction Zebo Peng, IDA, LiTH Sequential execution of an N-stage task: 3 N Task 3 N Task Production time: N time
Lecture 5: Instruction Pipelining Basic concepts Pipeline hazards Branch handling and prediction Zebo Peng, IDA, LiTH Sequential execution of an N-stage task: 3 N Task 3 N Task Production time: N time
COSC 243. Computer Architecture 2. Lecture 12 Computer Architecture 2. COSC 243 (Computer Architecture)
") COSC 243 1 Overview This Lecture Architectural topics CISC RISC Multi-core processors Source: Chapter 15,16 and 17(10 th edition) 2 Moore s Law Gordon E. Moore Co-founder of Intel April 1965 The complexity
COSC 243 1 Overview This Lecture Architectural topics CISC RISC Multi-core processors Source: Chapter 15,16 and 17(10 th edition) 2 Moore s Law Gordon E. Moore Co-founder of Intel April 1965 The complexity
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Portland State University ECE 587/687. The Microarchitecture of Superscalar Processors
 Portland State University ECE 587/687 The Microarchitecture of Superscalar Processors Copyright by Alaa Alameldeen and Haitham Akkary 2011 Program Representation An application is written as a program,
Portland State University ECE 587/687 The Microarchitecture of Superscalar Processors Copyright by Alaa Alameldeen and Haitham Akkary 2011 Program Representation An application is written as a program,
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Communications and Computer Engineering II: Lecturer : Tsuyoshi Isshiki
 Communications and Computer Engineering II: Microprocessor 2: Processor Micro-Architecture Lecturer : Tsuyoshi Isshiki Dept. Communications and Computer Engineering, Tokyo Institute of Technology isshiki@ict.e.titech.ac.jp
Communications and Computer Engineering II: Microprocessor 2: Processor Micro-Architecture Lecturer : Tsuyoshi Isshiki Dept. Communications and Computer Engineering, Tokyo Institute of Technology isshiki@ict.e.titech.ac.jp
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Alexandria University
 Alexandria University Faculty of Engineering Computer and Communications Department CC322: CC423: Advanced Computer Architecture Sheet 3: Instruction- Level Parallelism and Its Exploitation 1. What would
Alexandria University Faculty of Engineering Computer and Communications Department CC322: CC423: Advanced Computer Architecture Sheet 3: Instruction- Level Parallelism and Its Exploitation 1. What would
Static & Dynamic Instruction Scheduling
 CS3014: Concurrent Systems Static & Dynamic Instruction Scheduling Slides originally developed by Drew Hilton, Amir Roth, Milo Martin and Joe Devietti at University of Pennsylvania 1 Instruction Scheduling
CS3014: Concurrent Systems Static & Dynamic Instruction Scheduling Slides originally developed by Drew Hilton, Amir Roth, Milo Martin and Joe Devietti at University of Pennsylvania 1 Instruction Scheduling
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
UNIT- 5. Chapter 12 Processor Structure and Function
 UNIT- 5 Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data Write data CPU With Systems Bus CPU Internal Structure Registers
UNIT- 5 Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data Write data CPU With Systems Bus CPU Internal Structure Registers
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Advanced Computer Architecture
 Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
CMSC411 Fall 2013 Midterm 2 Solutions
 CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
Like scalar processor Processes individual data items Item may be single integer or floating point number. - 1 of 15 - Superscalar Architectures
 Superscalar Architectures Have looked at examined basic architecture concepts Starting with simple machines Introduced concepts underlying RISC machines From characteristics of RISC instructions Found
Superscalar Architectures Have looked at examined basic architecture concepts Starting with simple machines Introduced concepts underlying RISC machines From characteristics of RISC instructions Found
Modern Processors. RISC Architectures
 Modern Processors RISC Architectures Figures used from: Manolis Katevenis, RISC Architectures, Ch. 20 in Zomaya, A.Y.H. (ed), Parallel and Distributed Computing Handbook, McGraw-Hill, 1996 RISC Characteristics
Modern Processors RISC Architectures Figures used from: Manolis Katevenis, RISC Architectures, Ch. 20 in Zomaya, A.Y.H. (ed), Parallel and Distributed Computing Handbook, McGraw-Hill, 1996 RISC Characteristics
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Chapter 3 & Appendix C Part B: ILP and Its Exploitation
 CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 12 Processor Structure and Function
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data
William Stallings Computer Organization and Architecture 8 th Edition Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Architectural Performance. Superscalar Processing. 740 October 31, i486 Pipeline. Pipeline Stage Details. Page 1
 Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
SRAMs to Memory. Memory Hierarchy. Locality. Low Power VLSI System Design Lecture 10: Low Power Memory Design
 SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Micro-programmed Control Ch 17
 Micro-programmed Control Ch 17 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics Course Summary 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to
Micro-programmed Control Ch 17 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics Course Summary 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to
Lecture1: introduction. Outline: History overview Central processing unite Register set Special purpose address registers Datapath Control unit
 Lecture1: introduction Outline: History overview Central processing unite Register set Special purpose address registers Datapath Control unit 1 1. History overview Computer systems have conventionally
Lecture1: introduction Outline: History overview Central processing unite Register set Special purpose address registers Datapath Control unit 1 1. History overview Computer systems have conventionally
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
Intel released new technology call P6P
 P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
Reduced Instruction Set Computer
 Reduced Instruction Set Computer RISC - Reduced Instruction Set Computer By reducing the number of instructions that a processor supports and thereby reducing the complexity of the chip, it is possible
Reduced Instruction Set Computer RISC - Reduced Instruction Set Computer By reducing the number of instructions that a processor supports and thereby reducing the complexity of the chip, it is possible
Chapter 06: Instruction Pipelining and Parallel Processing
 Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Computer Systems Architecture
 Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
 1 cycle per instruction I
1 cycle per instruction I Micro-programmed Control Ch 15
 Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to modify Lots of
Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to modify Lots of
Hardwired Control (4) Micro-programmed Control Ch 17. Micro-programmed Control (3) Machine Instructions vs. Micro-instructions
 Micro-programmed Control Ch 17. Micro-programmed Control (3) Machine Instructions vs. Micro-instructions") Micro-programmed Control Ch 17 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics Course Summary Hardwired Control (4) Complex Fast Difficult to design Difficult to modify
Micro-programmed Control Ch 17 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics Course Summary Hardwired Control (4) Complex Fast Difficult to design Difficult to modify
CS311 Lecture: Pipelining, Superscalar, and VLIW Architectures revised 10/18/07
 CS311 Lecture: Pipelining, Superscalar, and VLIW Architectures revised 10/18/07 Objectives ---------- 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as
CS311 Lecture: Pipelining, Superscalar, and VLIW Architectures revised 10/18/07 Objectives ---------- 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread