PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
|
|
|
- Tobias Little
- 6 years ago
- Views:
Transcription

1 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015
2 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability for a single code to run well anywhere. 2
3 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability for a single code to run well anywhere. Many programming models provide functional portability, but can we provide performance portability too? 3








4 OPENACC Directives for Portable Parallelism OPEN SINGLE SOURCE main() { <serial code> #pragma acc kernels { <parallel code> } } PORTABLE HIGH PERFORMANCE 4
5 [The] focus on mythical Performance Portability misses the point. The issue is maintainability. Enabling Application Portability across HPC Platforms: An Application Perspective, OpenMPCon
6 Having a common code base using a portable programming environment even if you must fill the code with ifdefs or have architecture specific versions of key kernels is the only way to support maintainability. Enabling Application Portability across HPC Platforms: An Application Perspective, OpenMPCon
7 MAINTAINABLE CODE Portable parallelism is easier to maintain. #if defined(cpu) #pragma omp parallel for simd #elif defined(mic) #pragma omp target teams distribute \ parallel for simd #elif defined(omp_gpu) #pragma omp target teams distribute \ parallel for schedule(static,1) #elif defined(something_else) #pragma omp target... #endif for(int i = 0; i < N; i++) #pragma acc parallel loop for(int i = 0; i < N; i++) 7
8 Performance portability enables maintainable code. 8
9 But is performance portability a myth? 9
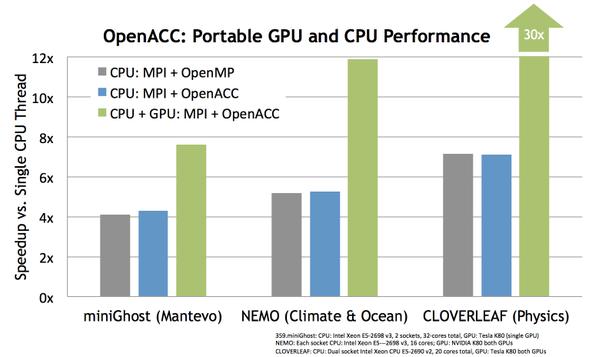
10 Speedup vs single CPU Core OPENACC DELIVERS PERFORMANCE PORTABILITY CPU: MPI + OpenMP * minighost (Mantevo) NEMO (Climate & Ocean) CLOVERLEAF (Physics) PGI Compiler minighost: CPU: Intel Xeon E v3, 2 sockets, 32-cores total, GPU: Tesla K80 (single GPU) NEMO: Each socket CPU: Intel Xeon E v3, 16 cores; GPU: NVIDIA K80 both GPUs CLOVERLEAF: CPU: Dual socket Intel Xeon CPU E v2, 20 cores total, GPU: Tesla K80 both GPUs * NEMO run used 10all-MPI
11 Speedup vs single CPU Core OPENACC DELIVERS PERFORMANCE PORTABILITY CPU: MPI + OpenMP * CPU: MPI + OpenACC minighost (Mantevo) NEMO (Climate & Ocean) CLOVERLEAF (Physics) PGI Compiler minighost: CPU: Intel Xeon E v3, 2 sockets, 32-cores total, GPU: Tesla K80 (single GPU) NEMO: Each socket CPU: Intel Xeon E v3, 16 cores; GPU: NVIDIA K80 both GPUs CLOVERLEAF: CPU: Dual socket Intel Xeon CPU E v2, 20 cores total, GPU: Tesla K80 both GPUs * NEMO run used 11all-MPI
12 Speedup vs single CPU Core OPENACC DELIVERS PERFORMANCE PORTABILITY 30X CPU: MPI + OpenMP * CPU: MPI + OpenACC CPU + GPU: MPI + OpenACC minighost (Mantevo) NEMO (Climate & Ocean) CLOVERLEAF (Physics) PGI Compiler minighost: CPU: Intel Xeon E v3, 2 sockets, 32-cores total, GPU: Tesla K80 (single GPU) NEMO: Each socket CPU: Intel Xeon E v3, 16 cores; GPU: NVIDIA K80 both GPUs CLOVERLEAF: CPU: Dual socket Intel Xeon CPU E v2, 20 cores total, GPU: Tesla K80 both GPUs * NEMO run used 12all-MPI
13 WHY OPENACC? The right programming model for performance portability. DESCRIPTIVE Directives inform and enable the compiler to effectively parallelize on any architecture. INCREMENTAL Programmer can tune the code when needed without ifdefs or loss of portability. MODERN Removes scalability blockers by design to support modern processors. MATURE Multiple mature implementations on multiple platforms. 13
14 OpenACC is enabling Scientific discoveries 14
 Module Benchmarked on Titan Supercomputer (AMD CPU vs Tesla K20X) 11.")

15 Speedup vs CPU LS-DALTON Large-scale application for calculating highaccuracy molecular energies Lines of Code Modified Minimal Effort # of Weeks Required # of Codes to Maintain <100 Lines 1 Week 1 Source Big Performance LS-DALTON CCSD(T) Module Benchmarked on Titan Supercomputer (AMD CPU vs Tesla K20X) 11.7x OpenACC makes GPU computing approachable for domain scientists. Initial OpenACC implementation required only minor effort, and more importantly, no modifications of our existing CPU implementation. 7.9x 8.9x Janus Juul Eriksen, PhD Fellow qleap Center for Theoretical Chemistry, Aarhus University ALANINE-1 13 ATOMS ALANINE-2 23 ATOMS ALANINE-3 33 ATOMS 15


16 NUMECA OpenACC Accelerates Commercial CFD Application OpenACC enabled us to target routines for GPU acceleration without rewriting code, allowing us to maintain portability on a code that is 20-year old. CHALLENGE Accelerate 20 year old highly optimized code on GPUs SOLUTION Accelerated computationally intensive routines with OpenACC RESULTS Achieved 10x or higher speed-ups on key routines Full app speedup of up to 2x on the Oak Ridge Titan supercomputer Total time spent on optimizing various routines with OpenACC was just five person-months David Gutzwiller, Head of HPC NUMECA International 16


17 MRI RECONSTRUCTION OpenACC Accelerates Advanced MRI Reconstruction Model CHALLENGE Produce detailed and accurate brain images by applying computationally intensive algorithms to MRI data Within short reconstruction time for diagnostic use SOLUTION Accelerated MRI reconstruction application with OpenACC using NVIDIA GPUs Now that we ve seen how easy it is to program the GPU using OpenACC and the PGI compiler, we re looking forward to translating more of our projects RESULTS Reduced reconstruction time for a single high-resolution MRI scan from 40 days to a couple of hours Scaled on Blue Waters at NCSA to reconstruct 3000 images in under 24 hours Brad Sutton, Associate Professor of Bioengineering and Technical Director of the Biomedical Imaging Center University of Illinois at Urbana-Champaign 17
* NVIDIA K40 (OpenACC) LHS RHS Linear Solver Ghost cell packing CHALLENGE Accelerate a complex memory bounded implicit CFD solver on GPU SOLUTION Accelerated")

18 Speedup Vs Single CPU Core INCOMP3D 3D incompressible Navier-Stokes fully implicit CFD solver SD7003 URANS Test Run Xeon E5645 (MPI)* NVIDIA K40 (OpenACC) LHS RHS Linear Solver Ghost cell packing CHALLENGE Accelerate a complex memory bounded implicit CFD solver on GPU SOLUTION Accelerated mathematical formulations one loop at a time with OpenACC RESULTS Achieved average speedups of 3X on Tesla GPU over parallel MPI implementation on x86 multicore processor Structured approach to parallelism provided by OpenACC allowed better algorithm design without worrying about GPU internals OpenACC is a highly effective tool for programming fully implicit CFD solvers on GPU to achieve 3X speedup Lixiang Luo, Researcher Aerospace Engineering Computational Fluid Dynamics Laboratory North Carolina State University (NCSU) * CPU Speedup on 6 cores of Xeon E5645, with 18 additional cores performance reduces due to partitioning and MPI overheads
19 Can a single programming model provide both functional and performance portability? 19
20 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability for a single code to run well anywhere. Many programming models provide functional portability, but OpenACC can provide performance portability too! 20

21
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
OpenACC Course Lecture 1: Introduction to OpenACC September 2015
 OpenACC Course Lecture 1: Introduction to OpenACC September 2015 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15:
OpenACC Course Lecture 1: Introduction to OpenACC September 2015 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15:
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015
 HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
Directive-based Programming for Highly-scalable Nodes
 Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
GTC 2017 S7672. OpenACC Best Practices: Accelerating the C++ NUMECA FINE/Open CFD Solver
 David Gutzwiller, NUMECA USA (david.gutzwiller@numeca.com) Dr. Ravi Srinivasan, Dresser-Rand Alain Demeulenaere, NUMECA USA 5/9/2017 GTC 2017 S7672 OpenACC Best Practices: Accelerating the C++ NUMECA FINE/Open
David Gutzwiller, NUMECA USA (david.gutzwiller@numeca.com) Dr. Ravi Srinivasan, Dresser-Rand Alain Demeulenaere, NUMECA USA 5/9/2017 GTC 2017 S7672 OpenACC Best Practices: Accelerating the C++ NUMECA FINE/Open
Programming NVIDIA GPUs with OpenACC Directives
 Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe michael.wolfe@pgroup.com http://www.pgroup.com/accelerate Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe mwolfe@nvidia.com http://www.pgroup.com/accelerate
Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe michael.wolfe@pgroup.com http://www.pgroup.com/accelerate Programming NVIDIA GPUs with OpenACC Directives Michael Wolfe mwolfe@nvidia.com http://www.pgroup.com/accelerate
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
SENSEI / SENSEI-Lite / SENEI-LDC Updates
 SENSEI / SENSEI-Lite / SENEI-LDC Updates Chris Roy and Brent Pickering Aerospace and Ocean Engineering Dept. Virginia Tech July 23, 2014 Collaborations with Math Collaboration on the implicit SENSEI-LDC
SENSEI / SENSEI-Lite / SENEI-LDC Updates Chris Roy and Brent Pickering Aerospace and Ocean Engineering Dept. Virginia Tech July 23, 2014 Collaborations with Math Collaboration on the implicit SENSEI-LDC
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
OpenACC Fundamentals. Steve Abbott November 13, 2016
 OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi
 Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Scientific Programming in C XIV. Parallel programming
 Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
ENABLING NEW SCIENCE GPU SOLUTIONS
 ENABLING NEW SCIENCE TESLA BIO Workbench The NVIDIA Tesla Bio Workbench enables biophysicists and computational chemists to push the boundaries of life sciences research. It turns a standard PC into a
ENABLING NEW SCIENCE TESLA BIO Workbench The NVIDIA Tesla Bio Workbench enables biophysicists and computational chemists to push the boundaries of life sciences research. It turns a standard PC into a
A Simple Guideline for Code Optimizations on Modern Architectures with OpenACC and CUDA
 A Simple Guideline for Code Optimizations on Modern Architectures with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle, J. Ryan Acks.: CEA/DIFF, IDRIS, GENCI, NVIDIA, Région
A Simple Guideline for Code Optimizations on Modern Architectures with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle, J. Ryan Acks.: CEA/DIFF, IDRIS, GENCI, NVIDIA, Région
Evaluating OpenMP s Effectiveness in the Many-Core Era
 Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
John Levesque Nov 16, 2001
 1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA
 Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle,
Towards an Efficient CPU-GPU Code Hybridization: a Simple Guideline for Code Optimizations on Modern Architecture with OpenACC and CUDA L. Oteski, G. Colin de Verdière, S. Contassot-Vivier, S. Vialle,
Porting Scalable Parallel CFD Application HiFUN on NVIDIA GPU
 Porting Scalable Parallel CFD Application NVIDIA D. V., N. Munikrishna, Nikhil Vijay Shende 1 N. Balakrishnan 2 Thejaswi Rao 3 1. S & I Engineering Solutions Pvt. Ltd., Bangalore, India 2. Aerospace Engineering,
Porting Scalable Parallel CFD Application NVIDIA D. V., N. Munikrishna, Nikhil Vijay Shende 1 N. Balakrishnan 2 Thejaswi Rao 3 1. S & I Engineering Solutions Pvt. Ltd., Bangalore, India 2. Aerospace Engineering,
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory
 Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
ACCELERATION OF A COMPUTATIONAL FLUID DYNAMICS CODE WITH GPU USING OPENACC
 Nonlinear Computational Aeroelasticity Lab ACCELERATION OF A COMPUTATIONAL FLUID DYNAMICS CODE WITH GPU USING OPENACC N I C H O L S O N K. KO U K PA I Z A N P H D. C A N D I D AT E GPU Technology Conference
Nonlinear Computational Aeroelasticity Lab ACCELERATION OF A COMPUTATIONAL FLUID DYNAMICS CODE WITH GPU USING OPENACC N I C H O L S O N K. KO U K PA I Z A N P H D. C A N D I D AT E GPU Technology Conference
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
Stan Posey, NVIDIA, Santa Clara, CA, USA
 Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
Understanding Dynamic Parallelism
 Understanding Dynamic Parallelism Know your code and know yourself Presenter: Mark O Connor, VP Product Management Agenda Introduction and Background Fixing a Dynamic Parallelism Bug Understanding Dynamic
Understanding Dynamic Parallelism Know your code and know yourself Presenter: Mark O Connor, VP Product Management Agenda Introduction and Background Fixing a Dynamic Parallelism Bug Understanding Dynamic
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
The Design and Implementation of OpenMP 4.5 and OpenACC Backends for the RAJA C++ Performance Portability Layer
 The Design and Implementation of OpenMP 4.5 and OpenACC Backends for the RAJA C++ Performance Portability Layer William Killian Tom Scogland, Adam Kunen John Cavazos Millersville University of Pennsylvania
The Design and Implementation of OpenMP 4.5 and OpenACC Backends for the RAJA C++ Performance Portability Layer William Killian Tom Scogland, Adam Kunen John Cavazos Millersville University of Pennsylvania
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy.! Thomas C.
 The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
OPENACC ONLINE COURSE 2018
 OPENACC ONLINE COURSE 2018 Week 3 Loop Optimizations with OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week
OPENACC ONLINE COURSE 2018 Week 3 Loop Optimizations with OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
Achieving Portable Performance for GTC-P with OpenACC on GPU, multi-core CPU, and Sunway Many-core Processor
 Achieving Portable Performance for GTC-P with OpenACC on GPU, multi-core CPU, and Sunway Many-core Processor Stephen Wang 1, James Lin 1,4, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See 1,3
Achieving Portable Performance for GTC-P with OpenACC on GPU, multi-core CPU, and Sunway Many-core Processor Stephen Wang 1, James Lin 1,4, William Tang 2, Stephane Ethier 2, Bei Wang 2, Simon See 1,3
Accelerator programming with OpenACC
 ..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster
 First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems
 Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems Junjie Li (lijunj@iu.edu) Shijie Sheng (shengs@iu.edu) Raymond Sheppard (rsheppar@iu.edu) Pervasive Technology
Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems Junjie Li (lijunj@iu.edu) Shijie Sheng (shengs@iu.edu) Raymond Sheppard (rsheppar@iu.edu) Pervasive Technology
Porting MILC to GPU: Lessons learned
 Porting MILC to GPU: Lessons learned Dylan Roeh Jonathan Troup Guochun Shi Volodymyr Kindratenko Innovative Systems Laboratory National Center for Supercomputing Applications University of Illinois at
Porting MILC to GPU: Lessons learned Dylan Roeh Jonathan Troup Guochun Shi Volodymyr Kindratenko Innovative Systems Laboratory National Center for Supercomputing Applications University of Illinois at
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Performance Analysis of the PSyKAl Approach for a NEMO-based Benchmark
 Performance Analysis of the PSyKAl Approach for a NEMO-based Benchmark Mike Ashworth, Rupert Ford and Andrew Porter Scientific Computing Department and STFC Hartree Centre STFC Daresbury Laboratory United
Performance Analysis of the PSyKAl Approach for a NEMO-based Benchmark Mike Ashworth, Rupert Ford and Andrew Porter Scientific Computing Department and STFC Hartree Centre STFC Daresbury Laboratory United
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels
 National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5. Alistair Hart (Cray UK Ltd.)
") Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5 Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking statements that are based on
Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5 Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking statements that are based on
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Interactive Supercomputing for State-of-the-art Biomolecular Simulation
 Interactive Supercomputing for State-of-the-art Biomolecular Simulation John E. Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Interactive Supercomputing for State-of-the-art Biomolecular Simulation John E. Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
OpenStaPLE, an OpenACC Lattice QCD Application
 OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
How GPUs can find your next hit: Accelerating virtual screening with OpenCL. Simon Krige
 How GPUs can find your next hit: Accelerating virtual screening with OpenCL Simon Krige ACS 2013 Agenda > Background > About blazev10 > What is a GPU? > Heterogeneous computing > OpenCL: a framework for
How GPUs can find your next hit: Accelerating virtual screening with OpenCL Simon Krige ACS 2013 Agenda > Background > About blazev10 > What is a GPU? > Heterogeneous computing > OpenCL: a framework for
A General Discussion on! Parallelism!
 Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
A case study of performance portability with OpenMP 4.5
 A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
A case study of performance portability with OpenMP 4.5 Rahul Gayatri, Charlene Yang, Thorsten Kurth, Jack Deslippe NERSC pre-print copy 1 Outline General Plasmon Pole (GPP) application from BerkeleyGW
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
Experiences with CUDA & OpenACC from porting ACME to GPUs
 Experiences with CUDA & OpenACC from porting ACME to GPUs Matthew Norman Irina Demeshko Jeffrey Larkin Aaron Vose Mark Taylor ORNL is managed by UT-Battelle for the US Department of Energy ORNL Sandia
Experiences with CUDA & OpenACC from porting ACME to GPUs Matthew Norman Irina Demeshko Jeffrey Larkin Aaron Vose Mark Taylor ORNL is managed by UT-Battelle for the US Department of Energy ORNL Sandia
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
Lecture 1. Introduction Course Overview
 Lecture 1 Introduction Course Overview Welcome to CSE 260! Your instructor is Scott Baden baden@ucsd.edu Office: room 3244 in EBU3B Office hours Week 1: Today (after class), Tuesday (after class) Remainder
Lecture 1 Introduction Course Overview Welcome to CSE 260! Your instructor is Scott Baden baden@ucsd.edu Office: room 3244 in EBU3B Office hours Week 1: Today (after class), Tuesday (after class) Remainder
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC. Jeff Larkin, NVIDIA Developer Technologies
 INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels
 National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS
 CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS Roberto Gomperts (NVIDIA, Corp.) Michael Frisch (Gaussian, Inc.) Giovanni Scalmani (Gaussian, Inc.) Brent Leback (PGI) TOPICS Gaussian Design
CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS Roberto Gomperts (NVIDIA, Corp.) Michael Frisch (Gaussian, Inc.) Giovanni Scalmani (Gaussian, Inc.) Brent Leback (PGI) TOPICS Gaussian Design
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
OpenACC Pipelining Jeff Larkin November 18, 2016
 OpenACC Pipelining Jeff Larkin , November 18, 2016 Asynchronous Programming Programming multiple operations without immediate synchronization Real World Examples: Cooking a Meal: Boiling
OpenACC Pipelining Jeff Larkin , November 18, 2016 Asynchronous Programming Programming multiple operations without immediate synchronization Real World Examples: Cooking a Meal: Boiling
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015
 Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
AMBER 11 Performance Benchmark and Profiling. July 2011
 AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
Industrial achievements on Blue Waters using CPUs and GPUs
 Industrial achievements on Blue Waters using CPUs and GPUs HPC User Forum, September 17, 2014 Seattle Seid Korić PhD Technical Program Manager Associate Adjunct Professor koric@illinois.edu Think Big!
Industrial achievements on Blue Waters using CPUs and GPUs HPC User Forum, September 17, 2014 Seattle Seid Korić PhD Technical Program Manager Associate Adjunct Professor koric@illinois.edu Think Big!
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
AFOSR BRI: Codifying and Applying a Methodology for Manual Co-Design and Developing an Accelerated CFD Library
 AFOSR BRI: Codifying and Applying a Methodology for Manual Co-Design and Developing an Accelerated CFD Library Synergy@VT Collaborators: Paul Sathre, Sriram Chivukula, Kaixi Hou, Tom Scogland, Harold Trease,
AFOSR BRI: Codifying and Applying a Methodology for Manual Co-Design and Developing an Accelerated CFD Library Synergy@VT Collaborators: Paul Sathre, Sriram Chivukula, Kaixi Hou, Tom Scogland, Harold Trease,
STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC. Stefan Maintz, Dr. Markus Wetzstein
 STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC Stefan Maintz, Dr. Markus Wetzstein smaintz@nvidia.com; mwetzstein@nvidia.com Companies Academia VASP USERS AND USAGE 12-25% of CPU cycles @ supercomputing
STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC Stefan Maintz, Dr. Markus Wetzstein smaintz@nvidia.com; mwetzstein@nvidia.com Companies Academia VASP USERS AND USAGE 12-25% of CPU cycles @ supercomputing