Parallel Compu,ng with OpenACC
|
|
|
- Leslie Park
- 6 years ago
- Views:
Transcription
1 Parallel Compu,ng with OpenACC Wei Feinstein HPC User Services Parallel Programming Workshop 2017 Louisiana State University
2 AGENDA Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC Identify Available Parallelism Parallelize loops Optimize Data Locality Optimize loops Interoperability





3 Large Scale of applications Multi-Core CPU GPU Many-Core CPU (Intel Xeon Phi) Genomics Deep Learning Costal Storm Predic,on OpenMP OpenACC Phi Direc/ves High Level Programming (direcitve/pragma)
4 GPU Compu,ng History The first Graphics Processing Unit (GPU) was designed as graphics accelerators, supporting only specific fixed-function pipelines. Starting in the late 1990s, the hardware became increasingly programmable, NVIDIA's first GPU in The General Purpose GPU (GPGPU): its excellent floating point performance world's 1 st solution for general computing on GPUs. CUDA was designed and launched by NVIDIA CUDA (Compute Unified Device Architecture) is a parallel computing platform and programming model created by NVIDIA and implemented on the GPUs that they produce.


5 CPU GPU Latency Processor Throughput processor
6 Latency vs. Throughput Koenigsegg one 270 mph Baton Rouge to New Orleans in 0.29 hr (18 mins) Seats: 2 6th HPC Parallel Programming Workshop School bus 40 mph BR to NO in 2 hr Seats: 72 Parallel Compu,ng with OpenACC
 Throughput: 2/0.28 = 7.")

7 Latency vs. Throughput CPU Koenigsegg one latency: 0.28 hr (18 mins) Throughput: 2/0.28 = 7.14 people/hr 6th HPC Parallel Programming Workshop GPU School bus Latency: 2 hr Throughput: 72/2 = 36 people/hr Parallel Compu,ng with OpenACC
8 Comparison of Architectures CPU Optimized for low-latency access to cached data sets Control logic for out-oforder and speculative execution GPU Optimized for data-parallel, throughput computation Architecture tolerant of memory latency More transistors dedicated to computation Hide latency from other threads via fast context switching ALU Control ALU Cache DRAM DRAM ALU ALU




9 WHAT IS HETEROGENEOUS COMPUTING? Application Execution CPU High Serial Performance High Data Parallelism GPU +
10 3 Approaches to Heterogeneous Programming Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance Easy to use Portable code Most Performance Most Flexibility













11 Examples of GPU-accelerated Libraries NVIDIA cublas NVIDIA curand NVIDIA cusparse NVIDIA NPP Vector Signal Image Processing GPU Accelerated Linear Algebra Matrix Algebra on GPU and Multicore NVIDIA cufft Building-block ArrayFire Matrix Sparse Linear C++ STL Features IMSL Library Algorithms Computations for A Algebra for CUDA CUD


12 GPU Programming Languages Fortran OpenACC, CUDA Fortran C OpenACC, CUDA C C++ Thrust, CUDA C++ Python PyCUDA, Copperhead C# Numerical analytics GPU.NET MATLAB, Mathematica, LabVIEW
13 SAXPY void saxpy(int N, float a, float *x, float *y){ for (int i = 0; i < N; ++i) y[i] = a*x[i] + y[i]; x, y: vector with N elelments a: scalar
14 Saxpy_CPU void saxpy_cpu(int n, float a, float *x, float *y) { for (int i = 0; i < n; ++i) { y[i] = a * x[i] + y[i]; int main(int argc, char **argv){ long n= 1<<20; float *x = (float*)malloc(n * sizeof(float)); float *y = (float*)malloc(n * sizeof(float)); // Ini,alize vector x,y for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.0f; // Perform SAXPY saxpy_cpu(n, a, x, y);
![Saxpy_cuBLAS Saxpy_OpenACC extern void cublassaxpy(int,float,float*,int,float*,in t); int main(){ // Ini,alize vectors x, y for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.](/docs-images/78/78359627/images/15-1.jpg "0f; // Perform SAXPY #pragma acc host_data use_device(x,y) cublassaxpy(n, 2.")
15 Saxpy_cuBLAS Saxpy_OpenACC extern void cublassaxpy(int,float,float*,int,float*,in t); int main(){ // Ini,alize vectors x, y for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.0f; // Perform SAXPY #pragma acc host_data use_device(x,y) cublassaxpy(n, 2.0, x, 1, y, 1); void saxpy_acc(int n, float a, float *x, float *y) { #pragma acc parallel loop for (int i = 0; i < n; ++I { y[i] = a * x[i] + y[i]; int main(){ // Ini,alize vectors x, y for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.0f; // Perform SAXPY saxpy_acc(n, a, x, y); hip://docs.nvidia.com/cuda
16 Saxpy_CUDA // define CUDA kernel func,on global void saxpy_kernel( float a, float* x, float* y, int n ){ int i; i = blockidx.x*blockdim.x + threadidx.x; if( i <= n ) y[i] = a*x[i] + y[i]; Void main( float a, float* x, float* y, int n ){ float *xd, *yd; // manage device memory cudamalloc( (void**)&xd, n*sizeof(float) ); cudamalloc( (void**)&yd, n*sizeof(float) ); cudamemcpy( xd, x, n*sizeof(float), cudamemcpyhosttodevice ); cudamemcpy( yd, y, n*sizeof(float), cudamemcpyhosttodevice ); // calls the kernel func,on saxpy_kernel<<< (n+31)/32, 32 >>>( a, xd, yd, n ); cudamemcpy( x, xd, n*sizeof(float), cudamemcpydevicetohost ); // free device memory aner use cudafree( xd ); cudafree( yd );


17
18 3 Approaches to Heterogeneous Programming Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance Easy to use Portable code Most Performance Most Flexibility
19 AGENDA Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC Identify Available Parallelism Parallelize loops Optimize Data Locality Optimize loops Interoperability
20 What Are Compiler Directives? int main() { do_serial_stuff() #pragma acc parallel loop { for(int i=0; i < BIGN; i++) { compute intensive work do_more_serial_stuff(); ßInserts compiler hints to compute on GPU ßData and Execution returns to the CPU

21 What are OpenACC Direc,ves? CPU GPU Program myscience... serial code...!$acc kernels do k = 1,n1 do i = 1,n2... parallel enddo enddo!$acc end kernels End... Program myscience code... Designed for multicore CPUs & many core GPUs Portable compiler hints Compiler parallelizes code OpenACC Compiler Directives





22 OpenACC Execution Model Application Code $acc parallel z Rest of Sequential CPU Code GPU Compute-Intensive Functions Generate Parallel Code for GPU $acc end parallel CPU Rest of Sequential CPU Code 2 2
23 History of OpenACC OpenACC is a specification/standard for high-level, compiler directives to express parallelism on accelerators. Aims to be portable to a wide range of accelerators One specification for multiple vendors, multiple devices Original members: CAPS, Cray, NVIDIA and PGI First released 1.0 Nov was released Jue was released Oct
24 Why OPENACC? Simple: Directives are the easy path to accelerate applications compute intensive Open: OpenACC is an open GPU directives standard, making GPU programming straightforward and portable across parallel and multi-core processors Portable: GPU Directives represent parallelism at a high level, allowing portability to a wide range of architectures with the same code


25 Which Compilers Support OpenACC PGI compilers for C, C++ and Fortran Cray CCE compilers for Cray systems CAPS compilers NVIDIA OpenACC Standard
26 Using PGI compilers on Mike Login in to SuperMike: $ ssh usrid@mike.hpc.lsu.edu Get an interactive compute node: $ qsub -I -l nodes=1:ppn=16 l walltime=4:00:00 q shelob -A hpc_train_2017 Add the PGI compiler v15.10 $ soft add +portland $ pgcc V
27 Example: Jacobi Itera,on Iteratively EXAMPLE: converges to JACOBI correct value, ITERATION e.g., temprature, by computing new values at each point from the average of neighboring points. A k +1 (i, j) = A k (i 1, j) + A k (i + 1, j)+ A k (i, j 1)+ A k (i, j + 1) 4 A(i,j+1) A(i-1,j) A(i,j) A(i+1,j) A(i,j-1) Example: Solve Laplace equation in 2D: 2 f(x, y) = 0
28 JACOBI Iteration: C while ( error > tol && iter < iter_max ){ error = 0.0; for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[j][i] = 0.25 * ( A[j][i+1] + A[j] [i-1] + A[j-1][i] + A[j+1][i]); error = fmax( error, fabs(anew[j][i] A[j][i])); for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; iter++; // end while loop Iterate until converged Iterate across matrix elements Calculate new value from neighbors Compute max error for convergence Swap input/output arrays
29 AGENDA Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC Identify Available Parallelism Parallelize loops Optimize Data Locality Optimize loops Interoperability
30 Identify Available Parallelism Identify section of a code consuming the significant percentage of time (hot spots) Routines, loops Profilers: gpof (GNU) pgprof (PGI) Vampir NVIDIA visual profiler
31 Code Profiling (pgprof) Compile code with profiling info $ pgcc -Mprof=ccff laplace.c Generate pgprof.out $ pgcollect./a.out --> pgprof.out Visualize profile info $ pgprof exe./a.out

32
33 AGENDA Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC Identify Available Parallelism Parallelize loops Optimize Data Locality Optimize loops Interoperability
34 General Direc,ve Syntax and Scope C #pragma acc directive [clause [,] clause]...] { Often followed by a structured code block Fortran!$acc directive [clause [,] clause]...] Often paired with a matching end directive surrounding a structured code block!$acc end directive
35 Kernels Direc,ve The kernels construct expresses that a region may contain parallelism and the compiler determines what can safely be parallelized. #pragma acc kernels { for(int i=0; i<n; i++) { x[i] y[i] = 1.0; = 2.0; for(int i=0;i++{ i<n; { y[i] = a*x[i] +y[i]; kernel 1 kernel 2 The compiler identifies 2 parallel loops and generates 2 kernels. A kernel is a func,on executed on the GPU as an array of threads in parallel
36 Parallize with Kernels (C) while ( error > tol && iter < iter_max ) { error = 0.0; #pragma acc kernels { for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1] [i] + A[j+1][i]); error = fmax( error, fabs(anew[j][i] - A[j][i])); for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; iter++; Kernels end here Look for parallelism within this region. $pgcc acc fast ta=nvidia,time Minfo=all laplace_kernels1.c
37 Parallize with Kernels (Fortran) do while ( error.gt. tol.and. iter.lt. iter_max ) error=0.0!$acc kernels do j=1,m-2 do i=1,n-2 Look for parallelism within this region. Anew(i,j) = 0.25_fp_kind * ( A(i+1,j ) + A(i-1,j ) + & A(i,j-1) + A(i,j+1) ) error = max( error, abs(anew(i,j)-a(i,j)) ) end do end do do j=1,m-2 do i=1,n-2 A(i,j) = Anew(i,j) end do end do!$acc end kernels Kernels end here $pgfortran acc fast ta=nvidia,time Minfo=all laplace_kernels1.f90
38 How to compile with OpenACC Compile using PGI compiler $ pgcc acc fast ta=nvidia Minfo=accel laplace_kernels1.c $ pgf90 acc fast ta=nvidia Minfo=accel laplace_kernels1.f90
39 Compiler-Generated Info 47, Generating copyout(anew[1:4094][1:4094]) Generating copyin(a[:4096][:4096]) Generating copyout(a[1:4094][1:4094]) 48, Loop is parallelizable 49, Loop is parallelizable Accelerator kernel generated Generating Tesla code 48, #pragma acc loop gang /* blockidx.y */ 49, #pragma acc loop gang, vector(128) /* blockidx.x threadidx.x */ 52, Max reduction generated for error 56, Loop is parallelizable 57, Loop is parallelizable Accelerator kernel generated Generating Tesla code 56, #pragma acc loop gang /* blockidx.y */ 57, #pragma acc loop gang, vector(128) /* blockidx.x threadidx.x */
40 Check CPU & GPU U,liza,on Open a separate terminal $ ssh X mikexxx or shelobxxx $ top: CPU utilization $ nvidia-smi: GPU

41 Parallel Loop Directive parallel - Programmer identifies a block of code containing parallelism. Compiler generates a kernel. loop - Programmer identifies a loop that can be parallelized within the kernel. NOTE: parallel & loop are often placed together #pragma acc parallel loop for(int i=0; i<n; i++) { y[i] = a*x[i]+y[i]; { Parallel kernel Kernel: A function that runs in parallel on the GPU
42 Loop Clauses: Private & Reduc,on private A copy of the variable is made for each loop iteration. It is private by default reduction A private copy of the affected variable is generated for each loop iteration A reduction is then performed on the variables. Supports +, *, max, min, and various logical operations 2
43 Code using Parallel Loop Directive (C) while ( error > tol && iter < iter_max ) { error = 0.0; #pragma acc parallel loop reduction(max:err) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1] [i] + A[j+1][i]); error = fmax( error, fabs(anew[j][i] - A[j][i])); #pragma acc parallel loop for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; iter++; Parallelize loop on accelerator Parallelize loop on accelerator * A reduction means that all of the N*M values for err will be reduced to just one, the max.
44 Code using Parallel Loop Directive (Fortran) do while ( error.gt. tol.and. iter.lt. iter_max ) error=0.0!$acc parallel loop reduction(max:err) do j=1,m-2 do i=1,n-2 Anew(i,j) = 0.25 *( A(i+1,j)+A(i-1,j) + A(i,j-1) + A(i,j+1) ) error = max( error, abs(anew(i,j)-a(i,j)) ) end do end do!$acc end parallel!$acc parallel loop do j=1,m-2 do i=1,n-2 A(i,j) = Anew(i,j) end do end do!$acc end parallel Parallelize loop on accelerator Parallelize loop on accelerator * A reduction means that all of the N*M values for err will be reduced to just one, the max.
45 Kernels vs. Parallel Loops Kernels Compiler performs parallel analysis and parallelizes what it believes safe Can cover larger area of code with single directive Gives compiler additional leeway to optimize. Parallel Loop Requires analysis by programmer to ensure safe parallelism Will parallelize what a compiler may miss Straightforward path from OpenMP
46 OpenACC for Multicore CPUs Originally targeted to NVIDIA and AMD (GPUs) Latest PGI compiler (>=pgi15.10) generates parallel code on CPUs using OpenMP With the same set of OpenACC pragmas GPUs: -ta=nvidia CPUs: -ta=multicore using all the CPU cores Or export ACC_NUM_CORES = [ ] $ pgcc ta=multicore,time Minfo=all laplace_kernels2.c
47 OpenACC for Multicore CPUs 48, Loop is parallelizable Generating Multicore code 48, #pragma acc loop gang 49, Loop is parallelizable 56, Loop is parallelizable Generating Multicore code 56, #pragma acc loop gang 57, Loop is parallelizable Memory copy idiom, loop replaced by call to c_mcopy8
48 Performance Comparison Disappoin,ng performance using OpenACC with kernels/parallel loop
49 What Went Wrong? $ export PGI_ACC_TIME=1 $ pgcc ta=nvidia Minfo=accel laplace_parallel2.c o laplace_parallel2 $ pgcc ta=nvidia,time Minfo=accel laplace_parallel2.c o laplace_parallel2 $./laplace_parallel2
50 Data Movement main NVIDIA devicenum=0 time(us): 88,667,910 47: compute region reached 1000 times 47: data copyin transfers: 1000 device time(us): total=8,667 max=37 min=8 avg=8 47: kernel launched 1000 times grid: [4094] block: [128] device time(us): total=2,320,918 max=2,334 min=2,312 avg=2,320 elapsed time(us): total=2,362,785 max=2,471 min=2,353 avg=2,362 47: reduction kernel launched 1000 times grid: [1] block: [256] device time(us): total=14,001 max=15 min=14 avg=14 elapsed time(us): total=32,924 max=72 min=31 avg=32 47: data copyout transfers: 1000 device time(us): total=16,973 max=49 min=14 avg=16 47: data region reached 1000 times 47: data copyin transfers: 8000 device time(us): total=22,404,937 max=2,886 min=2,781 avg=2,800 56: compute region reached 1000 times 56: kernel launched 1000 times grid: [4094] block: [128] device time(us): total=1,802,925 max=1,822 min=1,783 avg=1,802 elapsed time(us): total=1,847,383 max=1,884 min=1,827 avg=1,847 56: data region reached 2000 times 56: data copyin transfers: 8000 device time(us): total=22,000,619 max=4,096 min=2,739 avg=2,750 56: data copyout transfers: 8000 device time(us): total=20,118,762 max=2,703 min=2,498 avg=2,514 63: data region reached 1000 times 63: data copyout transfers: 8000 device time(us): total=20,121,450 max=2,664 min=2,498 avg=2,515 Total,me: 88,667,910 Data transfer,me: 84,671,301 Compute,me: 3,996,609
51 Performance Profiling by NVVP from Nvidia soft add +cuda $ nvvp./laplace_parallel2

52
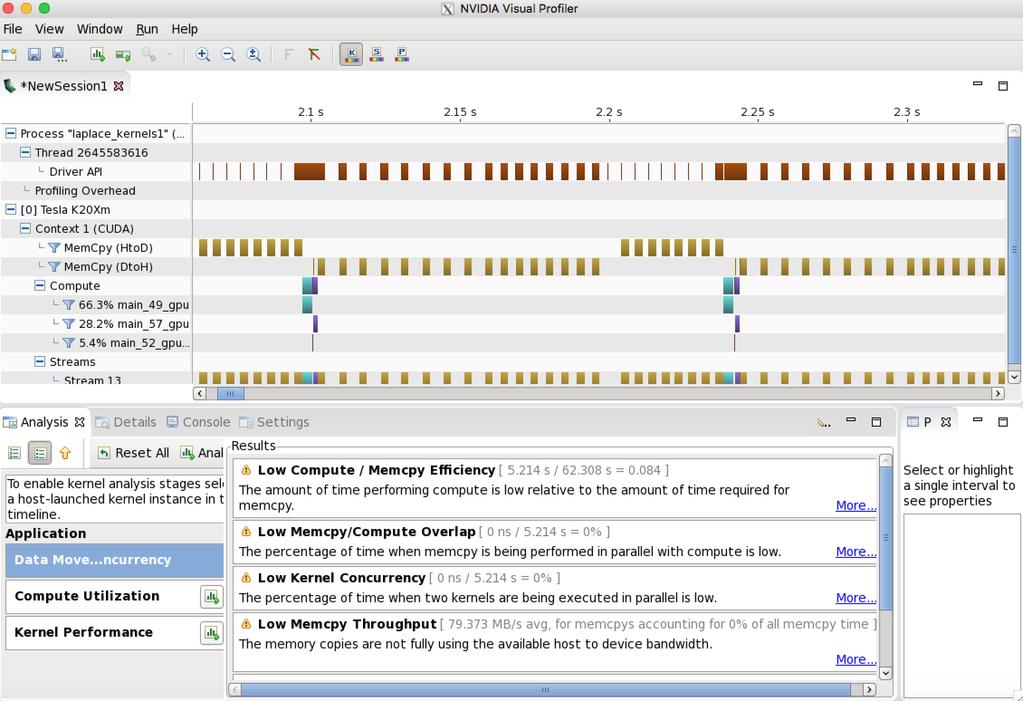
53
54 AGENDA Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC Identify Available Parallelism Parallelize loops Optimize Data Locality Optimize loops Interoperability
55 Data Flow Data Flow PCIe Bus 1. Copy input data from CPU memory to GPU memory 5 5
56 Data Flow PCIe Bus 1. Copy input data from CPU memory to GPU memory 2. Execute GPU Kernel 5 6


57 Data Flow PCIe Bus 1. Copy input data from CPU memory to GPU memory 2. Execute GPU Kernel 3. Copy results from GPU memory to CPU memory
58 OpenACC Memory Model Two separate memory spaces between host and accelerator Data transfer by DMA transfers Hidden from the programmer in OpenACC, so beware: Latency Bandwidth Limited device memory size
59 Code using Parallel Loop Pragam(C) while ( error > tol && iter < iter_max ) { error = 0.0; #pragma acc parallel loop reduction(max:err) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1] [i] + A[j+1][i]); error = fmax( error, fabs(anew[j][i] - A[j][i])); #pragma acc parallel loop for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; iter++; Parallelize loop on accelerator Parallelize loop on accelerator
60 How to Improve Data Movement Use data/array on GPU as long as possible Move data between CUP and GPU as less-frequently as possible Don t copy data back to CPU if not needed on CPU
61 Define Data Regions The data construct defines a region of code in which GPU arrays remain on the GPU and are shared among all kernels in that region. #pragma acc data { #pragma acc parallel loop... Data Region Arrays used within the data region will remain on the GPU until the end of the data region.
62 Data Clauses copy ( list ) copyin ( list ) copyout ( list ) create ( list ) present ( list ) Allocates memory on GPU and copies data from host to GPU when entering region and copies data to the host when exi,ng region. Allocates memory on GPU and copies data from host to GPU when entering region. Allocates memory on GPU and copies data to the host when exi,ng region. Allocates memory on GPU but does not copy. Data is already present on GPU from another containing data region. present_or_copy[in out], present_or_create, deviceptr. Will be made as default in the future
63 Array Shaping Compiler sometimes cannot determine size of arrays, specify explicitly using data clauses and array shape C/C++ #pragma acc data copyin(a[0:size]), copyout(b[s/4:3*s/4]) Fortran!$acc data copyin(a(1:end)), copyout(b(s/4:3*s/4)) Note: data clauses can be used on data, parallel, or kernels
64 Op,mizing Data Locality (C) #pragma acc data copy(a) create (Anew) while ( error > tol && iter < iter_max ) { error = 0.0; #pragma acc kernels { for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[j][i] = 0.25 * ( A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); error = fmax( error, fabs(anew[j][i] - A[j][i])); for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; iter++; Copy A to/from the accelerator only when needed. Create Anew as a device temporary.
65 Op,mizing Data Locality (Fortran)!$acc data copy(a) create(anew) do while ( error.gt. tol.and. iter.lt. iter_max ) error=0.0_fp_kind!$acc kernels do j=1,m-2 do i=1,n-2 Anew(i,j) = 0.25_fp_kind * ( A(i+1,j ) + A(i-1,j ) + & A(i,j-1) + A(i,j+1) ) error = max( error, abs(anew(i,j)-a(i,j)) ) end do end do do j=1,m-2 do i=1,n-2 A(i,j) = Anew(i,j) end do end do!$acc end kernels if(mod(iter,100).eq.0 ) write(*, (i5,f10.6) ), iter, error iter = iter + 1 end do!$acc end data
66 Performance main NVIDIA devicenum=0 time(us): 2,413,950 43: data region reached 1 time 43: data copyin transfers: 8 device time(us): total=22,409 max=2,812 min=2,794 avg=2,801 48: compute region reached 1000 times 48: data copyin transfers: 1000 device time(us): total=21,166 max=54 min=11 avg=21 48: kernel launched 1000 times grid: [4094] block: [128] device time(us): total=2,320,508 max=2,336 min=2,310 avg=2,320 elapsed time(us): total=2,365,313 max=2,396 min=2,355 avg=2,365 48: reduction kernel launched 1000 times grid: [1] block: [256] device time(us): total=14,000 max=14 min=14 avg=14 elapsed time(us): total=33,893 max=67 min=32 avg=33 48: data copyout transfers: 1000 device time(us): total=15,772 max=45 min=13 avg=15 68: data region reached 1 time 68: data copyout transfers: 9 device time(us): total=20,095 max=2,509 min=30 avg=2,232
67 Prior adding data construct main NVIDIA devicenum=0 time(us): 88,667,910a 47: compute region reached 1000 times 47: data copyin transfers: 1000 device time(us): total=8,667 max=37 min=8 avg=8 47: kernel launched 1000 times grid: [4094] block: [128] device time(us): total=2,320,918 max=2,334 min=2,312 avg=2,320 elapsed time(us): total=2,362,785 max=2,471 min=2,353 avg=2,362 47: reduction kernel launched 1000 times grid: [1] block: [256] device time(us): total=14,001 max=15 min=14 avg=14 elapsed time(us): total=32,924 max=72 min=31 avg=32 47: data copyout transfers: 1000 device time(us): total=16,973 max=49 min=14 avg=16 47: data region reached 1000 times 47: data copyin transfers: 8000 device time(us): total=22,404,937 max=2,886 min=2,781 avg=2,800 56: compute region reached 1000 times 56: kernel launched 1000 times grid: [4094] block: [128] device time(us): total=1,802,925 max=1,822 min=1,783 avg=1,802 elapsed time(us): total=1,847,383 max=1,884 min=1,827 avg=1,847 56: data region reached 2000 times 56: data copyin transfers: 8000 device time(us): total=22,000,619 max=4,096 min=2,739 avg=2,750 56: data copyout transfers: 8000 device time(us): total=20,118,762 max=2,703 min=2,498 avg=2,514 63: data region reached 1000 times 63: data copyout transfers: 8000 device time(us): total=20,121,450 max=2,664 min=2,498 avg=2,515

68
69 Performance
70 AGENDA Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC Identify Available Parallelism Parallelize loops Optimize Data Locality Optimize loops Interoperability
71 OpenACC: 3 Levels of Parallelism Vector Gang Vector Gang Workers Workers Vector threads work in lockstep (SIMD/SIMT parallelism) Workers compute a vector Gangs have 1 or more workers and share resources (such as cache, the streaming multiprocessor, etc.) Multiple gangs work independently of each other

; output[threadidx.")
72 CUDA Kernels: Parallel Threads A kernel is a func,on executed on the GPU as an array of threads in parallel All threads execute the same code, can take different paths float x = input[threadidx.x]; float y = func(x); output[threadidx.x] = y; Each thread has an ID Select input/output data Control decisions
73 CUDA Kernels: Subdivide into Blocks Threads are grouped into blocks
74 CUDA Kernels: Subdivide into Blocks Threads are grouped into blocks Blocks are grouped into a grid
75 CUDA Kernels: Subdivide into Blocks Threads are grouped into blocks Blocks are grouped into a grid A kernel is executed as a grid of blocks of threads
76 MAPPING OPENACC TO CUDA
77 OpenACC Execution Model on CUDA The OpenACC execu,on model has three levels: gang, worker, and vector For GPUs, the mapping is implementa,on dependent. Some possibili,es: gang==block, worker==warp, and vector==threads of a warp Depends on what the compiler thinks is the best mapping for a problem code portability is reduced
, num_workers(n), vector_length(n) #pragma acc kernels loop gang for (int i = 0; i < n; ++i) #pragma acc loop vector(128) for (int j = 0; j < n; ++j).")
78 Gang, Worker, Vector Clauses gang, worker, and vector can be added to a loop clause A parallel region can only specify one of each gang, worker, vector Control the size using the following clauses on the parallel region num_gangs(n), num_workers(n), vector_length(n) #pragma acc kernels loop gang for (int i = 0; i < n; ++i) #pragma acc loop vector(128) for (int j = 0; j < n; ++j)... #pragma acc parallel vector_length(128) #pragma acc loop gang for (int i = 0; i < n; ++i) #pragma acc loop vector for (int j = 0; j < n; ++j)...

...!$acc parallel!$acc loop collapse(2) do j=1,n-1 do i=1,n-1.")
79 Collapse Clause collapse(n): Transform the following n tightly nested loops into one, flattened loop. Useful when individual loops lack sufficient parallelism or more than 3 loops are nested (gang/worker/vector) #pragma acc parallel #pragma acc loop collapse(2) for(int i=0;i<n; i++) for(int j=0; j<n; j++)...!$acc parallel!$acc loop collapse(2) do j=1,n-1 do i=1,n-1... Loops must be tightly nested
80 The restrict keyword in C Ø Avoid pointer aliasing Applied to a pointer, e.g. float *restrict ptr; Meaning: for the lifetime of ptr, only it or a value directly derived from it (such as ptr + 1) will be used to access the object to which it points * In simple, the ptr will only point to the memory space of itself Ø OpenACC compilers often require restrict to determine independence. Otherwise the compiler can t parallelize loops that access ptr Note: if programmer violates the declaration, behavior is undefined. *
81 Rou,ne Construct Specifies that the compiler should generate a device copy of the function/subroutine and what type of parallelism the routine contains. Clauses: gang/worker/vector/seq (sequential) Specifies the level of parallelism contained in the routine.
82 #pragma acc routine vector void foo(float* v, int i, int n) { #pragma acc loop vector for ( int j=0; j<n; ++j) { v[i*n+j] = 1.0f/(i*j); #pragma acc parallel loop for ( int i=0; i<n; ++i) { foo(v,i); //call on the device Routine Construct
83 Update Construct Fortran #pragma acc update host/device [clause...] C!$acc update host/device [clause...] Used to update existing data after it has changed in its corresponding copy (e.g. update device copy after host copy changes) Move data from GPU to host, or host to GPU. Data movement can be conditional, and asynchronous.
84 Asynchronous Execution Ac,vated through async[(int)] clause on these direc,ves: parallel kernels update Without async: host waits for device to finish execution With async: host continues with code following directive Optional integer argument may be used to explicitly refer to region in a wait directive Two activities with same value are executed in the order the host process encounters them Two activities with different values may be executed in any order
85 Executable directive The wait Directive C: #pragma acc wait [(int)] Fortran:!$acc wait [(int)] Host thread waits for completion of asynchronous activities Optional argument: wait for asynchronous activity with argument in async clause
 wait(3) // kernel D D F E #pragma acc parallel loop async(5) \ wait(3) // kernel E #pragma acc wait(1) //kernel F on host 4 th HPC Parallel Programming")
86 #pragma acc parallel loop async(1) // kernel A #pragma acc parallel loop async(2) A B // kernel B #pragma acc wait(1,2) async(3) c #pragma acc parallel loop async(3) // wait(1,2) // or wait directive // kernel C #pragma acc parallel loop async(4) wait(3) // kernel D D F E #pragma acc parallel loop async(5) \ wait(3) // kernel E #pragma acc wait(1) //kernel F on host 4 th HPC Parallel Programming Workshop OpenACC Profiling & Tuning 86
87 AGENDA Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC Identify Available Parallelism Parallelize loops Optimize Data Locality Optimize loops Interoperability
88 3 Approaches to Heterogeneous Programming Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance Easy to use Portable code Most Performance Most Flexibility
89 Libraries: Easy, High-Quality Accelera,on Ease of use: Drop-in : Quality: Performance: Using libraries enables GPU acceleration without in-depth knowledge of GPU programming Many GPU-accelerated libraries follow standard APIs, thus enabling acceleration with minimal code changes Libraries offer high-quality implementations of functions encountered in a broad range of applications NVIDIA libraries are tuned by experts
90 host_data Construct C/C++ #pragma acc kernels host_data use_device(list) Fortran!$acc kernels host_data use_device(list) Make the address of device data available on host Specified variable addresses refer to device memory Variables must be present on device deviceptr data clause: inform compiler that the data already resides on the GPU
91 SAXPY void saxpy(int n, float a, float *x, float *restrict y) { for (int i = 0; i < n; ++i) y[i] = a*x[i] + y[i]; A func,on in the standard Basic Linear Algebra Subrou,nes (BLAS) library
92 cublassaxpy from cublas library void cublassaxpy( int n, const float *alpha, const float *x, int incx, float *y, int incy) A func,on in the standard Basic Linear Algebra Subrou,nes (BLAS) library, which is a GPU-accelerated library ready to be used on GPUs. cublas: GPU-accelerated drop-in library ready to be used on GPUs.
93 Saxpy_acc Saxpy_cuBLAS void saxpy_acc(int n, float a, float *x, float *y) { #pragma acc parallel loop for (int i = 0; i < n; ++i) { y[i] = a * x[i] + y[i]; a int main(){ // Ini,alize vectors x, y #pragma acc data create(x[0:n]) copyout(y[0:n]) #pragma acc parallel loop for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.0f; // Perform SAXPY saxpy_acc(n, a, x, y); extern void cublassaxpy(int,float,float*,int,float*,int); int main(){ // Ini,alize vectors x, y #pragma acc data create(x[0:n]) copyout(y[0:n]) #pragma acc parallel loop for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.0f; // Perform SAXPY #pragma acc host_data use_device(x,y) cublassaxpy(n, 2.0, x, 1, y, 1); hip://docs.nvidia.com/cuda
94 Saxpy_acc Saxpy_cuBLAS void saxpy_acc(int n, float a, float *x, float *y) { #pragma acc parallel loop for (int i = 0; i < n; ++i) { y[i] = a * x[i] + y[i]; a int main(){ // Ini,alize vectors x, y #pragma acc data create(x[0:n]) copyout(y[0:n]) #pragma acc parallel loop for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.0f; // Perform SAXPY saxpy_acc(n, a, x, y); extern void cublassaxpy(int,float,float*,int,float*,int); int main(){ // Ini,alize vectors x, y #pragma acc data create(x[0:n]) copyout(y[0:n]) #pragma acc parallel loop for (int i = 0; i < n; ++i) { x[i] = 1.0f; y[i] = 0.0f; // Perform SAXPY #pragma acc deviceptr (x,y) cublassaxpy(n, 2.0, x, 1, y, 1); hip://docs.nvidia.com/cuda
95 Code Profiling Optimize Loop Performance Parallelize Loops with OpenACC Optimize Data Locality
96 More Than One GPUs?
97 Internal control variables (ICVs): acc-device-type-var Controls which type of accelerator is used acc-device-num-var Controls which accelerator device is used Setting ICVs by API calls acc_set_device_type() acc_set_device_num() Querying of ICVs Device Management acc_get_device_type() acc_get_device_num()
98 OpenACC APIs acc_get_num_devices Returns the number of accelerator devices attached to host and the argument specifies type of devices to count C: int acc_get_num_devices(acc_device_t) Fortran: Integer function acc_get_num_devices(devicetype)
99 OpenACC APIs acc_set_device_num Sets ICV ACC_DEVICE_NUM Specifies which device of given type to use for next region Can not be called in a parallel, kernels or data region C: Void acc_set_device_num(int,acc_device_t) Fortran: Subroutine acc_set_device_num(devicenum,devicetype)
100 OpenACC APIs acc_get_device_num Return value of ICV ACC_DEVICE_NUM Return which device of given type to use for next region Can not be called in a parallel, kernels or data region C: Void acc_get_device_num(acc_device_t) Fortran: Subroutine acc_get_device_num(devicetype)
101 #pragma acc routine seq void saxpy(int n, float a, float *x, float *restrict y) { #pragma acc loop //kernels for (int i = 0; i < n; ++i) y[i] = a*x[i] + y[i]/2.3/1.2; int main(int argc, char **argv) { int n = 1<<40; float *x = (float*)malloc(n*sizeof(float)); float *y = (float*)malloc(n*sizeof(float)); for (int i = 0; i < n; ++i) { x[i] = 2.0f; y[i] = 1.0f; int gpu_ct=acc_get_num_devices(acc_device_nvidia); int tid=0; #pragma omp parallel private(tid) num_threads(gpu_ct) { int i=omp_get_thread_num(); acc_set_device_num(i,acc_device_nvidia); #pragma acc data copyin(n) copyin(x[0:n]) copyout(y[0:n]) { #pragma acc kernels for (int j=0; j<n*n; j++) { saxpy(n, 3.0f, x, y);
102 Direc,ve-based programming with mul,ple GPU cards openacc17]$ pgcc -acc -mp -fast saxpy_2gpu.c openacc17]$ nvidia-smi Mon May 29 02:20: NVIDIA-SMI Driver Version: GPU Name Persistence-M Bus-Id Disp.A Volatile Uncorr. ECC Fan Temp Perf Pwr:Usage/Cap Memory-Usage GPU-Util Compute M. ===============================+======================+====================== 0 Tesla K20Xm On 0000:20:00.0 Off 0 N/A 18C P0 62W / 235W 87MiB / 5759MiB 99% Default Tesla K20Xm On 0000:8B:00.0 Off 0 N/A 19C P0 63W / 235W 87MiB / 5759MiB 99% Default Processes: GPU Memory GPU PID Type Process name Usage ============================================================================= C./a.out 71MiB C./a.out 71MiB
103 Direc,ve-based programming on mul,-gpus OpenACC only supports one GPU Hybrid model: OpenACC + OpenMP to support mul,-gpu parallel programming Data management
104 Ge{ng Started for Labs Connect to mike cluster: ssh Login in to the interac,ve node qsub I A xxx l wall,me=2:00:00 l nodes=1:ppn=16 -q shelob Open another terminal ssh X shelobxxx /mikexxx
105 General Steps for Labs Code profiling to identify the target for parallelization pgprof: PGI visual profiler pgcc Minfo=ccff mycode.c o mycode pgcollect mycode pgprof exe mycode Add OpenACC pragmas/directives pgcc acc ta=nvidia,time Minfo=accel app.c o app pgf90 acc ta=nvidia,time Minfo=accel app.f90 o app
106 Exercise 1 1. For mm_acc_v0.c, speedup the matrix multiplication code segment using OpenACC directives/pragmas 2. For mm_acc_v1.c: Change A, B and C to dynamic arrays, i.e., the size of the matrix can be specified at runtime; Complete the function matmul_acc using the OpenACC directives; Compare performance with serial and OpenMP results
107 Exercise 2 Speedup the code segment using OpenACC directives/pragmas
An Introduc+on to OpenACC Part II
 An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
An Introduction to OpenACC - Part 1
 An Introduction to OpenACC - Part 1 Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 01-03, 2015 Outline of today
An Introduction to OpenACC - Part 1 Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 01-03, 2015 Outline of today
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC. Jeff Larkin, NVIDIA Developer Technologies
 INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC
 INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
Programming paradigms for GPU devices
 Programming paradigms for GPU devices OpenAcc Introduction Sergio Orlandini s.orlandini@cineca.it 1 OpenACC introduction express parallelism optimize data movements practical examples 2 3 Ways to Accelerate
Programming paradigms for GPU devices OpenAcc Introduction Sergio Orlandini s.orlandini@cineca.it 1 OpenACC introduction express parallelism optimize data movements practical examples 2 3 Ways to Accelerate
Introduction to Compiler Directives with OpenACC
 Introduction to Compiler Directives with OpenACC Agenda Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC - Identifying Available Parallelism
Introduction to Compiler Directives with OpenACC Agenda Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC - Identifying Available Parallelism
Introduction to OpenACC. Shaohao Chen Research Computing Services Information Services and Technology Boston University
 Introduction to OpenACC Shaohao Chen Research Computing Services Information Services and Technology Boston University Outline Introduction to GPU and OpenACC Basic syntax and the first OpenACC program:
Introduction to OpenACC Shaohao Chen Research Computing Services Information Services and Technology Boston University Outline Introduction to GPU and OpenACC Basic syntax and the first OpenACC program:
GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC. Authored by Mark Harris NVIDIA Corporation
 GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research
GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research
OpenACC Fundamentals. Steve Abbott November 13, 2016
 OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
OpenACC Fundamentals. Steve Abbott November 15, 2017
 OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
OpenACC Course Lecture 1: Introduction to OpenACC September 2015
 OpenACC Course Lecture 1: Introduction to OpenACC September 2015 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15:
OpenACC Course Lecture 1: Introduction to OpenACC September 2015 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15:
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
Introduction to OpenACC. Peng Wang HPC Developer Technology, NVIDIA
 Introduction to OpenACC Peng Wang HPC Developer Technology, NVIDIA penwang@nvidia.com Outline Introduction of directive-based parallel programming Basic parallel construct Data management Controlling parallelism
Introduction to OpenACC Peng Wang HPC Developer Technology, NVIDIA penwang@nvidia.com Outline Introduction of directive-based parallel programming Basic parallel construct Data management Controlling parallelism
GPU Computing with OpenACC Directives Presented by Bob Crovella. Authored by Mark Harris NVIDIA Corporation
 GPU Computing with OpenACC Directives Presented by Bob Crovella Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities
GPU Computing with OpenACC Directives Presented by Bob Crovella Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities
Introduction to GPU Computing. 周国峰 Wuhan University 2017/10/13
 Introduction to GPU Computing chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 GPU and Its Application 3 Ways to Develop Your GPU APP An Example to Show the Developments Add GPUs: Accelerate Science
Introduction to GPU Computing chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 GPU and Its Application 3 Ways to Develop Your GPU APP An Example to Show the Developments Add GPUs: Accelerate Science
GPU Computing with OpenACC Directives Dr. Timo Stich Developer Technology Group NVIDIA Corporation
 GPU Computing with OpenACC Directives Dr. Timo Stich Developer Technology Group NVIDIA Corporation WHAT IS GPU COMPUTING? Add GPUs: Accelerate Science Applications CPU GPU Small Changes, Big Speed-up Application
GPU Computing with OpenACC Directives Dr. Timo Stich Developer Technology Group NVIDIA Corporation WHAT IS GPU COMPUTING? Add GPUs: Accelerate Science Applications CPU GPU Small Changes, Big Speed-up Application
GPU Computing with OpenACC Directives
 GPU Computing with OpenACC Directives Alexey Romanenko Based on Jeff Larkin s PPTs 3 Ways to Accelerate Applications Applications Libraries OpenACC Directives Programming Languages Drop-in Acceleration
GPU Computing with OpenACC Directives Alexey Romanenko Based on Jeff Larkin s PPTs 3 Ways to Accelerate Applications Applications Libraries OpenACC Directives Programming Languages Drop-in Acceleration
ADVANCED ACCELERATED COMPUTING USING COMPILER DIRECTIVES. Jeff Larkin, NVIDIA
 ADVANCED ACCELERATED COMPUTING USING COMPILER DIRECTIVES Jeff Larkin, NVIDIA OUTLINE Compiler Directives Review Asynchronous Execution OpenACC Interoperability OpenACC `routine` Advanced Data Directives
ADVANCED ACCELERATED COMPUTING USING COMPILER DIRECTIVES Jeff Larkin, NVIDIA OUTLINE Compiler Directives Review Asynchronous Execution OpenACC Interoperability OpenACC `routine` Advanced Data Directives
Introduction to OpenACC
 Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org HPC Training Spring 2014 Louisiana State University Baton Rouge March 26, 2014 Introduction to OpenACC
Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org HPC Training Spring 2014 Louisiana State University Baton Rouge March 26, 2014 Introduction to OpenACC
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA
 OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Introduction to OpenACC Directives. Duncan Poole, NVIDIA
 Introduction to OpenACC Directives Duncan Poole, NVIDIA GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance
Introduction to OpenACC Directives Duncan Poole, NVIDIA GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance
INTRODUCTION TO OPENACC
 INTRODUCTION TO OPENACC Hossein Pourreza hossein.pourreza@umanitoba.ca March 31, 2016 Acknowledgement: Most of examples and pictures are from PSC (https://www.psc.edu/images/xsedetraining/openacc_may2015/
INTRODUCTION TO OPENACC Hossein Pourreza hossein.pourreza@umanitoba.ca March 31, 2016 Acknowledgement: Most of examples and pictures are from PSC (https://www.psc.edu/images/xsedetraining/openacc_may2015/
An Introduction to GPU Programming
 An Introduction to GPU Programming Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org Louisiana State University Baton Rouge October 22, 2014 GPU Computing History The first GPU (Graphics Processing
An Introduction to GPU Programming Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org Louisiana State University Baton Rouge October 22, 2014 GPU Computing History The first GPU (Graphics Processing
OpenACC Standard. Credits 19/07/ OpenACC, Directives for Accelerators, Nvidia Slideware
 OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015
 Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
OPENACC ONLINE COURSE 2018
 OPENACC ONLINE COURSE 2018 Week 1 Introduction to OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week 2 Data
OPENACC ONLINE COURSE 2018 Week 1 Introduction to OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week 2 Data
Introduction to OpenACC. 16 May 2013
 Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
Advanced OpenACC. Steve Abbott November 17, 2017
 Advanced OpenACC Steve Abbott , November 17, 2017 AGENDA Expressive Parallelism Pipelining Routines 2 The loop Directive The loop directive gives the compiler additional information
Advanced OpenACC Steve Abbott , November 17, 2017 AGENDA Expressive Parallelism Pipelining Routines 2 The loop Directive The loop directive gives the compiler additional information
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
Introduction to OpenACC
 Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 10-12, 2013 HPC@LSU
Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 10-12, 2013 HPC@LSU
Introduction to CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator
 Introduction to CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator What is CUDA? Programming language? Compiler? Classic car? Beer? Coffee? CUDA Parallel Computing Platform www.nvidia.com/getcuda Programming
Introduction to CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator What is CUDA? Programming language? Compiler? Classic car? Beer? Coffee? CUDA Parallel Computing Platform www.nvidia.com/getcuda Programming
Directive-based Programming for Highly-scalable Nodes
 Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
OpenACC introduction (part 2)
") OpenACC introduction (part 2) Aleksei Ivakhnenko APC Contents Understanding PGI compiler output Compiler flags and environment variables Compiler limitations in dependencies tracking Organizing data persistence
OpenACC introduction (part 2) Aleksei Ivakhnenko APC Contents Understanding PGI compiler output Compiler flags and environment variables Compiler limitations in dependencies tracking Organizing data persistence
ADVANCED OPENACC PROGRAMMING
 ADVANCED OPENACC PROGRAMMING DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES AGENDA Optimizing OpenACC Loops Routines Update Directive Asynchronous Programming Multi-GPU
ADVANCED OPENACC PROGRAMMING DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES AGENDA Optimizing OpenACC Loops Routines Update Directive Asynchronous Programming Multi-GPU
An Introduction to OpenACC. Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel
 An Introduction to OpenACC Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel Chapter 1 Introduction OpenACC is a software accelerator that uses the host and the device. It uses compiler
An Introduction to OpenACC Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel Chapter 1 Introduction OpenACC is a software accelerator that uses the host and the device. It uses compiler
OpenACC (Open Accelerators - Introduced in 2012)
") OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
Getting Started with Directive-based Acceleration: OpenACC
 Getting Started with Directive-based Acceleration: OpenACC Ahmad Lashgar Member of High-Performance Computing Research Laboratory, School of Computer Science Institute for Research in Fundamental Sciences
Getting Started with Directive-based Acceleration: OpenACC Ahmad Lashgar Member of High-Performance Computing Research Laboratory, School of Computer Science Institute for Research in Fundamental Sciences
Computing with OpenACC Directives. Francesco Salvadore SuperComputing Applications and Innovation Department
 Computing with OpenACC Directives Francesco Salvadore f.salvadore@cineca.it SuperComputing Applications and Innovation Department BASICS Common Accelerator Architecture Themes Separate device memory Many-cores
Computing with OpenACC Directives Francesco Salvadore f.salvadore@cineca.it SuperComputing Applications and Innovation Department BASICS Common Accelerator Architecture Themes Separate device memory Many-cores
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
An Introduction to OpenAcc
 An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
OPENACC ONLINE COURSE 2018
 OPENACC ONLINE COURSE 2018 Week 3 Loop Optimizations with OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week
OPENACC ONLINE COURSE 2018 Week 3 Loop Optimizations with OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
Introduction to OpenACC
 Introduction to OpenACC 2018 HPC Workshop: Parallel Programming Alexander B. Pacheco Research Computing July 17-18, 2018 CPU vs GPU CPU : consists of a few cores optimized for sequential serial processing
Introduction to OpenACC 2018 HPC Workshop: Parallel Programming Alexander B. Pacheco Research Computing July 17-18, 2018 CPU vs GPU CPU : consists of a few cores optimized for sequential serial processing
Accelerator programming with OpenACC
 ..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
..... Accelerator programming with OpenACC Colaboratorio Nacional de Computación Avanzada Jorge Castro jcastro@cenat.ac.cr 2018. Agenda 1 Introduction 2 OpenACC life cycle 3 Hands on session Profiling
INTRODUCTION TO OPENACC Lecture 3: Advanced, November 9, 2016
 INTRODUCTION TO OPENACC Lecture 3: Advanced, November 9, 2016 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Course Syllabus Oct 26: Analyzing and Parallelizing with OpenACC
INTRODUCTION TO OPENACC Lecture 3: Advanced, November 9, 2016 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Course Syllabus Oct 26: Analyzing and Parallelizing with OpenACC
MULTI GPU PROGRAMMING WITH MPI AND OPENACC JIRI KRAUS, NVIDIA
 MULTI GPU PROGRAMMING WITH MPI AND OPENACC JIRI KRAUS, NVIDIA MPI+OPENACC GDDR5 Memory System Memory GDDR5 Memory System Memory GDDR5 Memory System Memory GPU CPU GPU CPU GPU CPU PCI-e PCI-e PCI-e Network
MULTI GPU PROGRAMMING WITH MPI AND OPENACC JIRI KRAUS, NVIDIA MPI+OPENACC GDDR5 Memory System Memory GDDR5 Memory System Memory GDDR5 Memory System Memory GPU CPU GPU CPU GPU CPU PCI-e PCI-e PCI-e Network
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
GPU Programming Introduction
 GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
Blue Waters Programming Environment
 December 3, 2013 Blue Waters Programming Environment Blue Waters User Workshop December 3, 2013 Science and Engineering Applications Support Documentation on Portal 2 All of this information is Available
December 3, 2013 Blue Waters Programming Environment Blue Waters User Workshop December 3, 2013 Science and Engineering Applications Support Documentation on Portal 2 All of this information is Available
An OpenACC construct is an OpenACC directive and, if applicable, the immediately following statement, loop or structured block.
 API 2.6 R EF ER ENC E G U I D E The OpenACC API 2.6 The OpenACC Application Program Interface describes a collection of compiler directives to specify loops and regions of code in standard C, C++ and Fortran
API 2.6 R EF ER ENC E G U I D E The OpenACC API 2.6 The OpenACC Application Program Interface describes a collection of compiler directives to specify loops and regions of code in standard C, C++ and Fortran
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Introduction to OpenACC
 Introduction to OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 What is OpenACC? It is a directive based standard to allow developers to take advantage
Introduction to OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 What is OpenACC? It is a directive based standard to allow developers to take advantage
OpenACC and the Cray Compilation Environment James Beyer PhD
 OpenACC and the Cray Compilation Environment James Beyer PhD Agenda A brief introduction to OpenACC Cray Programming Environment (PE) Cray Compilation Environment, CCE An in depth look at CCE 8.2 and OpenACC
OpenACC and the Cray Compilation Environment James Beyer PhD Agenda A brief introduction to OpenACC Cray Programming Environment (PE) Cray Compilation Environment, CCE An in depth look at CCE 8.2 and OpenACC
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Programming techniques for heterogeneous architectures. Pietro Bonfa SuperComputing Applications and Innovation Department
 Programming techniques for heterogeneous architectures Pietro Bonfa p.bonfa@cineca.it SuperComputing Applications and Innovation Department Heterogeneous computing Gain performance or energy efficiency
Programming techniques for heterogeneous architectures Pietro Bonfa p.bonfa@cineca.it SuperComputing Applications and Innovation Department Heterogeneous computing Gain performance or energy efficiency
PGI Accelerator Programming Model for Fortran & C
 PGI Accelerator Programming Model for Fortran & C The Portland Group Published: v1.3 November 2010 Contents 1. Introduction... 5 1.1 Scope... 5 1.2 Glossary... 5 1.3 Execution Model... 7 1.4 Memory Model...
PGI Accelerator Programming Model for Fortran & C The Portland Group Published: v1.3 November 2010 Contents 1. Introduction... 5 1.1 Scope... 5 1.2 Glossary... 5 1.3 Execution Model... 7 1.4 Memory Model...
Optimizing OpenACC Codes. Peter Messmer, NVIDIA
 Optimizing OpenACC Codes Peter Messmer, NVIDIA Outline OpenACC in a nutshell Tune an example application Data motion optimization Asynchronous execution Loop scheduling optimizations Interface OpenACC
Optimizing OpenACC Codes Peter Messmer, NVIDIA Outline OpenACC in a nutshell Tune an example application Data motion optimization Asynchronous execution Loop scheduling optimizations Interface OpenACC
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2018 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Aside (P3 related): linear algebra Many scientific phenomena can be modeled as matrix operations Differential
CS 470 Spring 2018 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Aside (P3 related): linear algebra Many scientific phenomena can be modeled as matrix operations Differential
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to GPU Computing
 Introduction to GPU Computing Add GPUs: Accelerate Science Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois, Urbana Video Transcoding Elemental Tech
Introduction to GPU Computing Add GPUs: Accelerate Science Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois, Urbana Video Transcoding Elemental Tech
GPU Programming Paradigms
 GPU Programming with PGI CUDA Fortran and the PGI Accelerator Programming Model Boris Bierbaum, Sandra Wienke (26.3.2010) 1 GPUs@RZ Current: linuxc7: CentOS 5.3, Nvidia GeForce GT 220 hpc-denver: Windows
GPU Programming with PGI CUDA Fortran and the PGI Accelerator Programming Model Boris Bierbaum, Sandra Wienke (26.3.2010) 1 GPUs@RZ Current: linuxc7: CentOS 5.3, Nvidia GeForce GT 220 hpc-denver: Windows
The PGI Fortran and C99 OpenACC Compilers
 The PGI Fortran and C99 OpenACC Compilers Brent Leback, Michael Wolfe, and Douglas Miles The Portland Group (PGI) Portland, Oregon, U.S.A brent.leback@pgroup.com Abstract This paper provides an introduction
The PGI Fortran and C99 OpenACC Compilers Brent Leback, Michael Wolfe, and Douglas Miles The Portland Group (PGI) Portland, Oregon, U.S.A brent.leback@pgroup.com Abstract This paper provides an introduction
OpenACC Course. Lecture 4: Advanced OpenACC Techniques November 3, 2016
 OpenACC Course Lecture 4: Advanced OpenACC Techniques November 3, 2016 Lecture Objective: Demonstrate OpenACC pipelining, Interoperating with Libraries, and Use with MPI. 2 Advanced OpenACC Techniques:
OpenACC Course Lecture 4: Advanced OpenACC Techniques November 3, 2016 Lecture Objective: Demonstrate OpenACC pipelining, Interoperating with Libraries, and Use with MPI. 2 Advanced OpenACC Techniques:
OpenACC Course. Lecture 4: Advanced OpenACC Techniques November 12, 2015
 OpenACC Course Lecture 4: Advanced OpenACC Techniques November 12, 2015 Lecture Objective: Demonstrate OpenACC pipelining, Interoperating with Libraries, and Use with MPI. 2 Oct 1: Introduction to OpenACC
OpenACC Course Lecture 4: Advanced OpenACC Techniques November 12, 2015 Lecture Objective: Demonstrate OpenACC pipelining, Interoperating with Libraries, and Use with MPI. 2 Oct 1: Introduction to OpenACC
High-Productivity CUDA Programming. Cliff Woolley, Sr. Developer Technology Engineer, NVIDIA
 High-Productivity CUDA Programming Cliff Woolley, Sr. Developer Technology Engineer, NVIDIA HIGH-PRODUCTIVITY PROGRAMMING High-Productivity Programming What does this mean? What s the goal? Do Less Work
High-Productivity CUDA Programming Cliff Woolley, Sr. Developer Technology Engineer, NVIDIA HIGH-PRODUCTIVITY PROGRAMMING High-Productivity Programming What does this mean? What s the goal? Do Less Work
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2016
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator
 Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
GPU programming CUDA C. GPU programming,ii. COMP528 Multi-Core Programming. Different ways:
 COMP528 Multi-Core Programming GPU programming,ii www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Different ways: GPU programming
COMP528 Multi-Core Programming GPU programming,ii www.csc.liv.ac.uk/~alexei/comp528 Alexei Lisitsa Dept of computer science University of Liverpool a.lisitsa@.liverpool.ac.uk Different ways: GPU programming
PGI Fortran & C Accelerator Programming Model. The Portland Group
 PGI Fortran & C Accelerator Programming Model The Portland Group Published: v0.72 December 2008 Contents 1. Introduction...3 1.1 Scope...3 1.2 Glossary...3 1.3 Execution Model...4 1.4 Memory Model...5
PGI Fortran & C Accelerator Programming Model The Portland Group Published: v0.72 December 2008 Contents 1. Introduction...3 1.1 Scope...3 1.2 Glossary...3 1.3 Execution Model...4 1.4 Memory Model...5
PGPROF OpenACC Tutorial
 PGPROF OpenACC Tutorial Version 2017 PGI Compilers and Tools TABLE OF CONTENTS Chapter 1. Tutorial Setup...1 Chapter 2. Profiling the application... 2 Chapter 3. Adding OpenACC directives... 4 Chapter
PGPROF OpenACC Tutorial Version 2017 PGI Compilers and Tools TABLE OF CONTENTS Chapter 1. Tutorial Setup...1 Chapter 2. Profiling the application... 2 Chapter 3. Adding OpenACC directives... 4 Chapter
Approaches to GPU Computing. Libraries, OpenACC Directives, and Languages
 Approaches to GPU Computing Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois, Urbana
Approaches to GPU Computing Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois, Urbana
Parallelism III. MPI, Vectorization, OpenACC, OpenCL. John Cavazos,Tristan Vanderbruggen, and Will Killian
 Parallelism III MPI, Vectorization, OpenACC, OpenCL John Cavazos,Tristan Vanderbruggen, and Will Killian Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction MPI
Parallelism III MPI, Vectorization, OpenACC, OpenCL John Cavazos,Tristan Vanderbruggen, and Will Killian Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction MPI
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
PROFILER OPENACC TUTORIAL. Version 2018
 PROFILER OPENACC TUTORIAL Version 2018 TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. Tutorial Setup... 1 Profiling the application... 2 Adding OpenACC directives...4 Improving
PROFILER OPENACC TUTORIAL Version 2018 TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. Tutorial Setup... 1 Profiling the application... 2 Adding OpenACC directives...4 Improving
OpenACC 2.5 and Beyond. Michael Wolfe PGI compiler engineer
 OpenACC 2.5 and Beyond Michael Wolfe PGI compiler engineer michael.wolfe@pgroup.com OpenACC Timeline 2008 PGI Accelerator Model (targeting NVIDIA GPUs) 2011 OpenACC 1.0 (targeting NVIDIA GPUs, AMD GPUs)
OpenACC 2.5 and Beyond Michael Wolfe PGI compiler engineer michael.wolfe@pgroup.com OpenACC Timeline 2008 PGI Accelerator Model (targeting NVIDIA GPUs) 2011 OpenACC 1.0 (targeting NVIDIA GPUs, AMD GPUs)
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015
 Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
PGI Fortran & C Accelerator Compilers and Programming Model Technology Preview
 PGI Fortran & C Accelerator Compilers and Programming Model Technology Preview The Portland Group Published: v0.7 November 2008 Contents 1. Introduction... 1 1.1 Scope... 1 1.2 Glossary... 1 1.3 Execution
PGI Fortran & C Accelerator Compilers and Programming Model Technology Preview The Portland Group Published: v0.7 November 2008 Contents 1. Introduction... 1 1.1 Scope... 1 1.2 Glossary... 1 1.3 Execution
APPROACHES. TO GPU COMPUTING Libraries, OpenACC Directives, and Languages
 APPROACHES TO GPU COMPUTING Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Science Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois,
APPROACHES TO GPU COMPUTING Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Science Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois,
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2017
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
OpenACC Accelerator Directives. May 3, 2013
 OpenACC Accelerator Directives May 3, 2013 OpenACC is... An API Inspired by OpenMP Implemented by Cray, PGI, CAPS Includes functions to query device(s) Evolving Plan to integrate into OpenMP Support of
OpenACC Accelerator Directives May 3, 2013 OpenACC is... An API Inspired by OpenMP Implemented by Cray, PGI, CAPS Includes functions to query device(s) Evolving Plan to integrate into OpenMP Support of
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators
 Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2018
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
VSC Users Day 2018 Start to GPU Ehsan Moravveji
 Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPGPU Programming with OpenACC
 GPGPU Programming with OpenACC Sandra Wienke, M.Sc. wienke@itc.rwth-aachen.de IT Center, RWTH Aachen University PPCES, March 18th 2016 IT Center der RWTH Aachen University Agenda Introduction to GPGPUs
GPGPU Programming with OpenACC Sandra Wienke, M.Sc. wienke@itc.rwth-aachen.de IT Center, RWTH Aachen University PPCES, March 18th 2016 IT Center der RWTH Aachen University Agenda Introduction to GPGPUs
Using JURECA's GPU Nodes
 Mitglied der Helmholtz-Gemeinschaft Using JURECA's GPU Nodes Willi Homberg Supercomputing Centre Jülich (JSC) Introduction to the usage and programming of supercomputer resources in Jülich 23-24 May 2016
Mitglied der Helmholtz-Gemeinschaft Using JURECA's GPU Nodes Willi Homberg Supercomputing Centre Jülich (JSC) Introduction to the usage and programming of supercomputer resources in Jülich 23-24 May 2016
Advanced OpenMP Features
 Christian Terboven, Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group {terboven,schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Vectorization 2 Vectorization SIMD =
Christian Terboven, Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group {terboven,schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Vectorization 2 Vectorization SIMD =
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Using PGI compilers to solve initial value problems on GPU
 Using PGI compilers to solve initial value problems on GPU Ladislav Hanyk Charles University in Prague, Faculty of Mathematics and Physics Czech Republic Outline 1. NVIDIA GPUs and CUDA developer tools
Using PGI compilers to solve initial value problems on GPU Ladislav Hanyk Charles University in Prague, Faculty of Mathematics and Physics Czech Republic Outline 1. NVIDIA GPUs and CUDA developer tools
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team
 Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
arxiv: v1 [hep-lat] 12 Nov 2013
![arxiv: v1 [hep-lat] 12 Nov 2013](/thumbs/87/96002319.jpg "arxiv: v1 [hep-lat] 12 Nov 2013") Lattice Simulations using OpenACC compilers arxiv:13112719v1 [hep-lat] 12 Nov 2013 Indian Association for the Cultivation of Science, Kolkata E-mail: tppm@iacsresin OpenACC compilers allow one to use Graphics
Lattice Simulations using OpenACC compilers arxiv:13112719v1 [hep-lat] 12 Nov 2013 Indian Association for the Cultivation of Science, Kolkata E-mail: tppm@iacsresin OpenACC compilers allow one to use Graphics