CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
|
|
|
- Hillary French
- 6 years ago
- Views:
Transcription
1 CUDA Workshop High Performance GPU computing EXEBIT Karthikeyan

2 CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration
3 Compute Unified Device Architecture CUDA Exposes GPU computing for general purpose Flexible and scalable architecture Based on industry-standard C/C++ Small set of extensions to enable heterogeneous programming Straightforward APIs to manage devices, memory etc. For NVIDIA GPUs only
4 Concepts to be covered Heterogeneous computing Blocks, Threads Indexing Shared memory syncthreads() Warps, Divergence Asynchronous operation Handling errors Managing devices

5 Heterogeneous Computing CPU Host, CPU RAM Host Memory GPU Device, GPU RAM Device Memory
6 Hello World! GPU code kernel global indicates it runs on device Triple angle brackets mark a call from host code to device code kernel launch Returns void global void mykernel(void) { cuprintf( Hello World!\n ); } int main(void) { mykernel<<<1,1>>>(); printf( CPU Hello World!\n"); return 0; }

7 Hello World! nvcc helloworld.cu./a.out
8 Working with codes Open Terminal ssh X user#@ (user 1-25) ssh X guest@ (user 26-50) ssh X guest@ (user 26-50) cd codes/helloworld/ make./helloworld gedit &
9 Hello World! Parallel Change to mykernel<<<n,1>>>(); Launches N blocks CPU calls kernel & continues its work Compile: $ cd helloworld_blocks $ make $./helloworld_blocks global void mykernel(void) { cuprintf( Hello World!\n ); } int main(void) { int N=100; mykernel<<<n,1>>>(); printf( CPU Hello World!\n"); return 0; }
10 Processing Flow PCI Bus Copy from Host Memory (CPU) to Device Memory (GPU)
11 Processing Flow CPU launches Kernel PCI Bus Kernel accesses memory at much faster rate Utilizes on-chip cache memory

 to Host Memory")
12 Processing Flow PCI Bus Copy results back from Device Memory (GPU) to Host Memory (CPU)
13 Device Memory Management cudaerror_t cudamalloc( void ** devptr, size_t size_bytes) cudaerror_t cudamemcpy ( void* dst, void* src, size_t count, enum cudamemcpykind kind) cudamemcpyhosttohost Host -> Host cudamemcpyhosttodevice Host -> Device cudamemcpydevicetohost Device -> Host cudamemcpydevicetodevice Device -> Device Example: int a[100], *dev_a; cudamalloc (&dev_a, sizeof(int)*100); cudamemcpy( dev_a, a, sizeof(int)*100, cudamemcpyhosttodevice);
14 Vector Addition How to identify which block it is? Each block takes care of one element blockidx.x You can have 3 dimensional blocks blockidx.x, blockidx.y, blockidx.z griddim.x dim3(65535,65535,1024) void vectoradd(int *a, int *b, int *c) { for( int i=0; i<100; i++) c[i] = a[i] + b[i]; } global void vectoradd(int *a, int *b, int *c) { int i = blockidx.x; c[i] = a[i] + b[i]; }
15 Vector Addition global void vectoradd(int *a,int *b, int *c) { int i= blockidx.x; c[i] = a[i] + b[i]; } int main(void) { int host_a[100], host_b[100],host_c[100]; int *dev_a, *dev_b, *dev_c; cudamalloc( &dev_a, sizeof(int)*100); cudamalloc( &dev_b, sizeof(int)*100); cudamalloc( &dev_c, sizeof(int)*100); } Memory Allocation Compile: $ cd vectoradd/ $ make $./vectoradd Memory Copy cudamemcpy(dev_a, host_a, sizeof(int)*100, cudamemcpyhosttodevice); cudamemcpy(dev_b, host_b, sizeof(int)*100, cudamemcpyhosttodevice); vectoradd<<<n,1>>>(dev_a,dev_b,dev_c); cudamemcpy(host_c, dev_c, sizeof(int)*100, cudamemcpydevicetohost); return 0;
16 Threads A block can have many threads. For vector addition, the kernel launch would be vectoradd<<<1,n>>>(da,db,dc); Maximum thread Dimension (3-dimensional) (1024,1024,64) threadidx.x blockdim.x global void vectoradd(int *a, int *b, int *c) { int i=threadidx.x; c[i]=a[i]+b[i]; } Compile: $ cd vectoradd_threads/ $ make $./vectoradd_threads

17 Threads 3D mesh inside 3D mesh Why threads? Communicate Synchronize Blocks can t
18 Built-in Variables threadidx.x, threadidx.y, threadidx.z blockidx.x, blockidx.y, blockidx.z blockdim.x, y, z (1024,1024,64) Number of threads per block. griddim.x, y, z (65535, 65535, 1024) - Number of blocks in a kernel call (called as Grid of blocks)
19 Index Calculation Using blocks and threads simultaneously. i=threadidx.x + blockdim.x*blockidx.x; threadidx.x threadidx.x threadidx.x threadidx.x blockidx.x=0 blockidx.x=1 blockidx.x=2 blockidx.x=3 blockdim.x=8 (no of threads in a block) griddim.x=4 (no of blocks in that kernel launch) add<<<n/threads_per_block, THREADS_PER_BLOCK>>>(
20 Boundary Conditions Usually blockdim.x is in multiples of 32 Always put boundary conditions on data size global void vectoradd(int *a, int *b, int *c, int N) { int i = threadidx + blockdim.x * blockidx.x; if(i<n) c[i]=a[i]+b[i]; } Compile: $ cd vectoradd_full/ $ make $./vectoradd_full
21 For Very Large N Very large N (N>10 6 ) global void vectoradd(int *a, int *b, int *c, long N) { long i = threadidx + blockdim.x * blockidx.x; for(; i<n; i+= griddim.x * blockdim.x) c[i]=a[i]+b[i]; } Compile: $ cd vectoradd_large/ $ make $./vectoradd_large

22 Block Scheduling Streaming Multiprocessors are executing units - SM Different GPUs have different no of SMs. There is communication among threads. No communication among blocks. No specific order in block scheduling.
23 Block Scheduling All threads in a block execute in a single SM No guarantee in order of execution Hardware schedules based on available SMs 3 SMs available BLOCK 1 BLOCK 2 BLOCK 3 BLOCK 4
24 Block Scheduling All threads in a block execute in a single SM No guarantee in order of execution Hardware schedules based on available SMs 3 SMs available BLOCK 1 BLOCK 2 BLOCK 3 BLOCK 4
25 Block Scheduling All threads in a block execute in a single SM No guarantee in order of execution Hardware schedules based on available SMs 3 SMs available BLOCK 1 BLOCK 2 BLOCK 4
26 Block Scheduling All threads in a block execute in a single SM No guarantee in order of execution Hardware schedules based on available SMs 3 SMs available BLOCK 1 BLOCK 2 BLOCK 4
27 1-D Stencil Compute a(i)+a(i+1)+a(i+2) global void stencil(int *a, int *b) { int i=threadidx.x; b[i]=a[i]+a[i+1]+a[i+2]; } Compile: $ cd 1dstencil/ $ make $./1dstencil threadidx.x=0 threadidx.x=1
28 Global Memory Till now we have been using global memory for our computations. Very slow to access Allocated using cudamalloc(..)
29 1-D Stencil Revisited Compute a(i)+a(i+1)+a(i+2) global void stencil(int *a, int *b) { int i=threadidx.x; b[i]=a[i]+a[i+1]+a[i+2]; } Data could be shared among threads threadidx.x=0 threadidx.x=1 3 global read + 1 global write per thread
30 Shared Memory Memory shared among threads inside a block. Cannot be accessed from another block Declared inside kernel code shared int a[100]; On-chip, very fast
31 1-D Stencil Shared Copy to shared memory global void stencil(int *a, int *b) { int i = threadidx.x; shared sa[100]; sa[i] = a[i]; b[i] = sa[i]+sa[i+1]+sa[i+2]; } Compile: $ cd 1dstencil_shared $ make $./1dstencil_shared Write the result to global memory Shared memory is visible a block only. Cannot be accessed by other blocks, CPU
32 Access Times Registers (1-2 cycles) Shared memory (10 cycles) Global memory (100s of cycles) Local memory (100s of cycles)
33 Run time Comparison 3 global read + 1 global write per thread 3* =400 cycles 1 global read + 3 shared read + 1 global write per thread 1*100+3*10+1*100= 230 cycles Use nvprof./file_name to see the runtime of programs
 memory Accessible by all threads and host (CPU) Data lifetime= Entire program from allocation to de-allocation Host (CPU) memory Not directly")
34 Memory Hierarchy Registers Per thread on chip Data lifetime = thread lifetime Local memory Per thread off-chip memory (DRAM) Data lifetime = thread lifetime Shared memory Per thread block : on-chip memory Data lifetime = block lifetime Global (device) memory Accessible by all threads and host (CPU) Data lifetime= Entire program from allocation to de-allocation Host (CPU) memory Not directly accessible by CUDA threads
35 syncthreads() Synchronizes all threads within a block Waits till all the threads execute till syncthreads(); Used to prevent RAW, WAR, WAW hazards RAW Read After Write WAR Write After Read WAW Write After Write Synchronize to commit all the memory writes, reads and computation. syncthreads();
36 Reduction Addition of N numbers Other operations +,*, AND, OR, XOR, maximum, minimum etc. void reduce(int *a, int *result) { *result=0; for( int i=0; i<100; i++) result=result+a[i]; } Serial How to parallelize?
37 Reduction Addition of N numbers Other operations +,*, AND, OR, XOR, maximum, minimum etc. void reduce(int *a, int *result) { *result=0; for( int i=0; i<100; i++) result=result+a[i]; } Serial How to parallelize? Using associative property! a+b+c+d = (a+b)+ (c+d)
38 Reduction N numbers log 2 (N) steps to compute Share result of 1 st step to other threads in 2 nd step threadidx.x Some algorithms are not straight forward to implement in parallel.
39 Reduction kernel Read to Shared memory Operate & write to shared memory Write to global memory global void reduce(int *a, int *result) { int i= threadidx.x; shared s_a[n]; s_a[i]=a[i]; syncthreads( ); for( int stride=1; stride < N; stride*=2){ if(i%stride==0) s_a[2*i]=s_a[2*i] + s_a[2*i+stride]; syncthreads( ); } *result=s_a[0]; } Compile: $ cd reduction/ $ make $./reduction
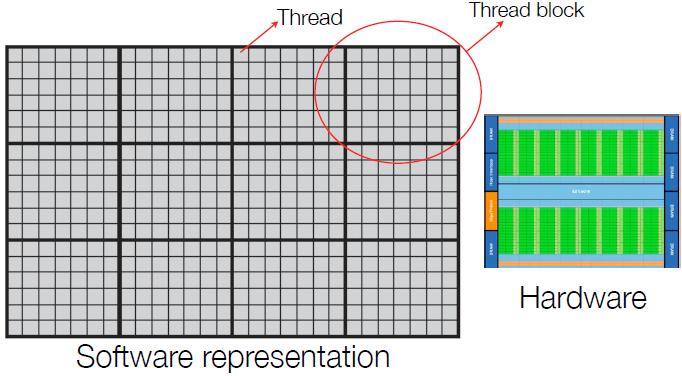
40 CUDA programming model

41 CUDA programming model Blocks mapped to SM
42 Warps Inside SM, threads are split into group of 32 threads called warps. All threads in single warp execute in parallel. If executing warp needs waiting or barrier, it is put into hold and another warp is dispatched for execution. This is taken care by warp scheduler All threads in a warp execute SAME instruction.

43 Warp No guarantee on order of warps dispatched. GPU architectures Tesla,Fermi, Kepler Warp size = 32 Fermi 2 warp schedulers 2 instruction units
44 Divergence Alternative threads in a warp execute different each warp takes 2 time step Warp 1 if ( threadidx.x%2==0) a[ threadidx.x ] +=1 else a[ threadidx.x ] +=2 } if else
45 Divergence All threads in a warp executes same instruction each warp takes 1 time step if ( threadidx.x<32) a[ threadidx.x ] +=1 else a[ threadidx.x ] +=2 } Warp 1 (if) Warp 2 (else)
46 Reduction revisited Divergence at all strides Each thread in a warp execute different instructions Solution: Modify condition for( int stride=1; stride < N; stride*=2){ if( i % stride==0) sa[2*i] = sa[2*i] + sa[2*i+stride]; syncthreads( ); } *result=sa[0]; }
47 Reduction (No Divergence) Add elements stride away No Divergence for stride>=32 for( int stride=blockdim.x; stride >0; stride/=2) if( i < stride) sa[i]=sa[i] + sa[i+stride]; syncthreads( ); *result=sa[0]; } Compile: $ cd reduction_nodiv/ $ make $./reduction_nodiv
48 Resource allocation Split your program to small kernels. Why? Each SM has limited registers, shared memory. The amount depends on compute capability of GPU 1.0, 1.1, 1.2, 1.3, 2.x, 3.0, 3.5, 5.0 Fermi, Tesla, Kepler Global memory is large (>512MB) nvcc Xptxas=-v filename.cu
49 Resource limits Number of thread blocks per SM is limited by Registers Shared memory usage No. of blocks per SM Number of threads Limits X 3.X 5.0 Registers/SM 16K 32K 64K 64K Shared Memory/SM 16KB 48KB 48KB 64KB Blocks/SM Threads/SM Occupancy
50 Asynchronous Kernel launches are Asynchronous cudamemcpy, cudamalloc Synchronous cudamemcpyasync() - Asynchronous, does not block the CPU cudadevicesynchronize() - Blocks the CPU until all preceding CUDA calls have completed Asynchronous calls can utilize CPU also while GPU is busy.
51 Handling Errors All CUDA API calls return an error code (cudaerror_t) Error in the API call itself Error in an earlier asynchronous operation (e.g. kernel) Get the error code for the last error: cudaerror_t cudagetlasterror(void) Get a string to describe the error: char *cudageterrorstring(cudaerror_t) printf("%s\n", cudageterrorstring(cudagetlasterror()));
52 Device Management Application can query and select GPUs cudagetdevicecount(int *count) cudasetdevice(int device) cudagetdevice(int *device) cudagetdeviceproperties(cudadeviceprop *prop, int device) Multiple host threads can share a device A single host thread can manage multiple devices cudasetdevice(i) to select current device cudamemcpy( ) for peer-to-peer copies
53 Summary Write and launch CUDA C/C++ kernels global, <<<>>>, blockidx, threadidx, blockdim Manage GPU memory cudamalloc(), cudamemcpy(), cudafree() Manage communication and synchronization shared, syncthreads() cudamemcpy() vs cudamemcpyasync(), cudadevicesynchronize() Resource limits Registers, Shared memory, blocks/sm, threads/sm
54 Advanced concepts(not covered) Memory Coalescing Constant memory Streams Atomics Shared memory conflicts Texture memory
55 Tools nvcc NVIDIA compiler nvprof - command line profiler nvvp Visual profiler cuda-memcheck Memory bugs Nsight Visual Studio, Eclipse Allinea DDT
56 Libraries CUBLAS CUDA accelerated Basic Linear Algebra CUFFT Fast Fourier Transform (1D, 2D, 3D) Thrust C++ template library (similar to C++ STL) CULA Dense, Sparse Linear Algebra OpenCV Computer Vision, Image processing AccelerEyes ArrayFire MATLAB, LabVIEW, Mathematica, Python ABACUS, AMBER, ANSYS, GROMACS, LAAMPS, NAMD,
57 Online Resources Coursera - Heterogeneous computing Udacity - CS344 Intro To Parallel Programming GPU computing Webinars CUDA Documentation Books CUDA by Example Programming Massively Parallel Processors: A Hands-on Approach GPU GEMS
58 Questions?
GPU Programming Introduction
 GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
An Introduction to GPU Computing and CUDA Architecture
 An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
HPCSE II. GPU programming and CUDA
 HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation
 CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation What is CUDA? CUDA Platform Expose GPU computing for general purpose Retain performance CUDA C/C++ Based on industry-standard C/C++ Small
CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation What is CUDA? CUDA Platform Expose GPU computing for general purpose Retain performance CUDA C/C++ Based on industry-standard C/C++ Small
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Lecture 6b Introduction of CUDA programming
 CS075 1896 1920 1987 2006 Lecture 6b Introduction of CUDA programming 0 1 0, What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on
CS075 1896 1920 1987 2006 Lecture 6b Introduction of CUDA programming 0 1 0, What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on
CUDA Exercises. CUDA Programming Model Lukas Cavigelli ETZ E 9 / ETZ D Integrated Systems Laboratory
 CUDA Exercises CUDA Programming Model 05.05.2015 Lukas Cavigelli ETZ E 9 / ETZ D 61.1 Integrated Systems Laboratory Exercises 1. Enumerate GPUs 2. Hello World CUDA kernel 3. Vectors Addition Threads and
CUDA Exercises CUDA Programming Model 05.05.2015 Lukas Cavigelli ETZ E 9 / ETZ D 61.1 Integrated Systems Laboratory Exercises 1. Enumerate GPUs 2. Hello World CUDA kernel 3. Vectors Addition Threads and
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Introduction to CUDA C
 NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Introduction to CUDA C
 Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
CS 179: GPU Computing. Lecture 2: The Basics
 CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team
 Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CS377P Programming for Performance GPU Programming - I
 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
GPU COMPUTING. Ana Lucia Varbanescu (UvA)
") GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
Speed Up Your Codes Using GPU
 Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
Speed Up Your Codes Using GPU Wu Di and Yeo Khoon Seng (Department of Mechanical Engineering) The use of Graphics Processing Units (GPU) for rendering is well known, but their power for general parallel
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to CUDA CIRC Summer School 2014
 Introduction to CUDA CIRC Summer School 2014 Baowei Liu Center of Integrated Research Computing University of Rochester October 20, 2014 Introduction Overview What will you learn on this class? Start from
Introduction to CUDA CIRC Summer School 2014 Baowei Liu Center of Integrated Research Computing University of Rochester October 20, 2014 Introduction Overview What will you learn on this class? Start from
Massively Parallel Algorithms
 Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
CUDA. More on threads, shared memory, synchronization. cuprintf
 CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU Architecture and Programming. Andrei Doncescu inspired by NVIDIA
 GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
04. CUDA Data Transfer
 04. CUDA Data Transfer Fall Semester, 2015 COMP427 Parallel Programming School of Computer Sci. and Eng. Kyungpook National University 2013-5 N Baek 1 CUDA Compute Unified Device Architecture General purpose
04. CUDA Data Transfer Fall Semester, 2015 COMP427 Parallel Programming School of Computer Sci. and Eng. Kyungpook National University 2013-5 N Baek 1 CUDA Compute Unified Device Architecture General purpose
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
COSC 462 Parallel Programming
 November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
Advanced Topics: Streams, Multi-GPU, Tools, Libraries, etc.
 CSC 391/691: GPU Programming Fall 2011 Advanced Topics: Streams, Multi-GPU, Tools, Libraries, etc. Copyright 2011 Samuel S. Cho Streams Until now, we have largely focused on massively data-parallel execution
CSC 391/691: GPU Programming Fall 2011 Advanced Topics: Streams, Multi-GPU, Tools, Libraries, etc. Copyright 2011 Samuel S. Cho Streams Until now, we have largely focused on massively data-parallel execution
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator
 Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Introduction to CUDA Programming (Compute Unified Device Architecture) Jongsoo Kim Korea Astronomy and Space Science 2018 Workshop
 Jongsoo Kim Korea Astronomy and Space Science 2018 Workshop") Introduction to CUDA Programming (Compute Unified Device Architecture) Jongsoo Kim Korea Astronomy and Space Science Institute @COMAC 2018 Workshop www.top500.org Summit #1, Linpack: 122.3 Pflos/s 4356
Introduction to CUDA Programming (Compute Unified Device Architecture) Jongsoo Kim Korea Astronomy and Space Science Institute @COMAC 2018 Workshop www.top500.org Summit #1, Linpack: 122.3 Pflos/s 4356
Programming with CUDA, WS09
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
CUDA Basics. July 6, 2016
 Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
GPU Computing Workshop CSU Getting Started. Garland Durham Quantos Analytics
 1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
CSE 599 I Accelerated Computing Programming GPUS. Intro to CUDA C
 CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
Massively Parallel Computing with CUDA. Carlos Alberto Martínez Angeles Cinvestav-IPN
 Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Massively Parallel Computing with CUDA Carlos Alberto Martínez Angeles Cinvestav-IPN What is a GPU? A graphics processing unit (GPU) The term GPU was popularized by Nvidia in 1999 marketed the GeForce
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA
 CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
CSC266 Introduction to Parallel Computing using GPUs Introduction to CUDA Sreepathi Pai October 18, 2017 URCS Outline Background Memory Code Execution Model Outline Background Memory Code Execution Model
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
HIGH-PERFORMANCE COMPUTING WITH CUDA AND TESLA GPUS
 HIGH-PERFORMANCE COMPUTING WITH CUDA AND TESLA GPUS Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or
HIGH-PERFORMANCE COMPUTING WITH CUDA AND TESLA GPUS Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or
COSC 462. CUDA Basics: Blocks, Grids, and Threads. Piotr Luszczek. November 1, /10
 COSC 462 CUDA Basics: Blocks, Grids, and Threads Piotr Luszczek November 1, 2017 1/10 Minimal CUDA Code Example global void sum(double x, double y, double *z) { *z = x + y; } int main(void) { double *device_z,
COSC 462 CUDA Basics: Blocks, Grids, and Threads Piotr Luszczek November 1, 2017 1/10 Minimal CUDA Code Example global void sum(double x, double y, double *z) { *z = x + y; } int main(void) { double *device_z,
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
INTRODUCTION TO GPU COMPUTING IN AALTO. Topi Siro
 INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 12.6.2013 OUTLINE PART I Introduction to GPUs Basics of CUDA PART II Maximizing performance Coalesced memory access Optimizing memory transfers Occupancy
INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 12.6.2013 OUTLINE PART I Introduction to GPUs Basics of CUDA PART II Maximizing performance Coalesced memory access Optimizing memory transfers Occupancy
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
INTRODUCTION TO GPU COMPUTING IN AALTO. Topi Siro
 INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 11.6.2014 PART I Introduction to GPUs Basics of CUDA (and OpenACC) Running GPU jobs on Triton Hands-on 1 PART II Optimizing CUDA codes Libraries Hands-on
INTRODUCTION TO GPU COMPUTING IN AALTO Topi Siro 11.6.2014 PART I Introduction to GPUs Basics of CUDA (and OpenACC) Running GPU jobs on Triton Hands-on 1 PART II Optimizing CUDA codes Libraries Hands-on
Basic CUDA workshop. Outlines. Setting Up Your Machine Architecture Getting Started Programming CUDA. Fine-Tuning. Penporn Koanantakool
 Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine