Lecture 5. Other Adder Issues
|
|
|
- Clement Freeman
- 6 years ago
- Views:
Transcription
1 Lecture 5 Other Adder Issues Mark Horowitz Computer Systems Laboratory Stanford University horowitz@stanford.edu Copyright 24 by Mark Horowitz with information from Brucek Khailany 1 Overview Reading There are many papers on fast adder design. I have collected a few of them and have posted a web page that lists them under reading You should read the Adder paper posted by Sam Naffziger. It should explain how to build Ling adder (useful for homework) Introduction: In the previous lecture we talked about different ways to organized adders, and showed a couple different ways to think about tree adders. This lecture will look at the Ling reformulation of the adder equations, and then look at some other issue that the designers of modern adders need to consider. If we have time, we will talk about the construction of floating point adder units. Much of this material first appeared in a lecture from Brucek Khailany 2
2 Review: Basic Tree Adder Architecture Convert input operands into propagate and generate P i = a i +b i G i = a i *b i Carry calculation Use P s & G s to compute carry to every bit (c i ) Either build a combining tree for each bit Or Fan-out results from tree(s) to each output Remember that C i+1 = G i: + P i: Cin Some times people try to combine Cin with the LSB of PG tree to remove the need for this gate (Make G = G +P Cin) Compute final sum Si = ai bi ci 3 Ling Adder Ling adders is just a way to reformulate the Pg Gg equations The normal equation are: G4 = G 3 + P 3 (G 2 + P 2 (G 1 + P 1 G )) P4 = P P 1 P 2 P 3 The equation for G4 requires a 4 stack since it is really G4 = G 3 + P 3 G 2 + P 3 P 2 G 1 + P 3 P 2 P 1 G Stacks are bad, so it is always nice to reduce them Notice if P = A+B, then if G is true P is also true, so G4 = P 3 G 3 + P 3 G 2 + P 3 P 2 G 1 + P 3 P 2 P 1 G G4 = P 3 (G 3 + G 2 + P 2 G 1 + P 2 P 1 G ) Define H4 = (G 3 + G 2 + P 2 G 1 + P 2 P 1 G ) H4 is easier to compute than G Can compute H4 directly from inputs w/o first computing P,G 4
3 Ling Adders cont d But now the problem is how to use H? Ultimately need G Want it to work in any tree type structure Each group does not need P MSB But the next more significant group need it to use H Define pseudo P called I to replace Pg I4 = P -1 P P 1 P 2 I4 1 = P 3 P 4 P 5 P 6 Then the combining formula looks just like it did before! H8 = H4 1 + I4 1 H4 I H 1 5 Who Cares? Normally this type of optimization would not matter much Trick only works with P,G, and not Pg Gg Gg does not imply that Pg is true H does not imply I either This means you get savings only at the first level of tree But adders are carefully optimized, and every bit helps Ultimately need to add the missing P back to generate Carry Put Cin into Ii in the open slot for P -1 When you generate C from H, I Cin i+1 = P i (H i: + I i: ), which is not much slower than normal Carry In carry select adders, P i can be added to the local chains 6
4 Ling vs. CLA Energy [pj] R2 Ling R2 CLA R4 Ling R4 CLA Delay [FO4] R. Zlatanovici, ESSCIRC 3 From Bora Nikolic 7 Review: Carry-Select Adders The Carry must fan-out to drive the width of the select group This fanout must be accounted for A.B[15:8] A.B[7:] Sum 1 SUM[7:] SUM[15:8] 8

5 Simple Linear Carry-Select Adders Now ripple the carry through the select blocks Critical path is linear with the number of blocks This could be a mux, but since carryout is monotonic on Cin you can simplify the mux 9 Select Trees: What To Do When C in is Late For the upper ½ of an adder, Cin 32 is usually late If the use the architecture on the previous page, you then need to ripple the carry through 4 selects Would be better to compute how Sum i depends on Cin 32 while we are computing Cin 32 Assume you have 8 bit groups the algorithm is Compute Sum1 (assume Cin to group is 1) and Sum Use Cout of previous group to create new Sum1* and Sum* Sum* =(Cout 56? Sum : Sum ) Sum1* =(Cout1 56? Sum : Sum ) The result is Sum1* is the correct sum if carryout 47 is 1 Sum* is the correct sum if carryout 47 is Effectively in one gate you have doubled the group size 1
6 Select Trees Generally need to use them in fast adders Otherwise can t generate the conditional sums fast enough But they are usually used only once In radix 4 systems to move 4 bit groups to depend on C16 In binary tree systems to make final group size around 8 But sometimes people go overboard In the Alpha adder, C32 was slow enough Rippled through 3 of these stages! These were differential pass transistors stages But still 11 Alpha Adder 12
.")

7 72-bit Pentium II Adder 72-bit adder (Jason Stinson).35u process Domino Kogge-Stone CLA+sumselect Combines terms in both domino and CMOS stages bit Pentium II Adder 14


8 72-bit Pentium II Adder bit Pentium II Adder 16


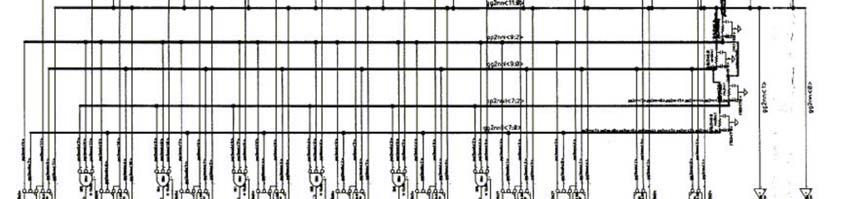

9 72-bit Pentium II Adder bit Pentium II Adder 18
10 72-bit Pentium II Adder 19 A Real-World Adder Design Example Part of Imagine A high-performance media processor designed at Stanford 32-bit segmented integer adder Two-level tree to compute global carries Uses carry-select to compute final sums from global carries Static CMOS logic Also pass gate logic Design constraints Area Design complexity (modularity) Speed 2
11 Adder Architecture A[31] B[31] A[24] B[24] A[23] B[23] A[16] B[16] A[15] B[15] A[8] B[8] A[7] B[7] A[] B[] PGK's: PGK's: PGK's: PGK's: Group PGK Group PGK Group PGK Group PGK COUT Global Carry Chain CIN PGK's[31:24] PGK's[23:16] PGK's[15:8] PGK's[7:] Conditional Sum 1 Conditional Sum 1 Conditional Sum 1 Sum CIN SUM[31:24] SUM[23:16] SUM[15:8] SUM[7:] 21 This Adder Is A Trade-off It is balancing design/logic complexity and speed It uses large groups which will ultimately limit performance It does use some tree structures It does not ripple carries But the group generation is a little slow Also uses large block sizes (8 bits) Does not move the carry select input to lower significance Need to worry about how outputs in block are generated 22
12 Segmented Adder: Details PGK s: Convert input operands into Propagate (P), Generate (G), Kill(K) Group PGK s: Determine P,G,K for groups of 8 bits Global carry chain: Compute cin[8], cin[16], cin[24], cout(cin[32]) from group PGK s and cin Conditional sums: Compute 8-bit sum for cin= and 8-bit sum for cin=1 as soon as PGK s are known Final Mux: Use cin s from global carry chain to select conditional sums 23 PGK Logic Pre-computation necessary to do fast carry computation P = a b A P B G = ab K = ~(a+b) A B G_b A B K Size gates to fan-out to four carry chains Note: To do A-B, use ~B here 24
13 Compute Group PGK s: Use Manchester Carry Chains Usually dynamic, but still works with static logic Group PGK s: GP = P[7].P[6].P[5].P[4].P[3].P[2].P[1].P[] GG = G[7] + G[6].P[7] + G[5].P[6].P[7]+ GK = ~(GG+GP) Use Carry chains Example for GG (group generate): P[] G_b[] P[1] G_b[1] P[2] G_b[2] P[3] G_b[3] P[] G_b[4] P[5] G_b[5] P[6] G_b[6] P[7] G_b[7] GG K[] K[1] K[2] K[3] K[4] K[5] K[6] K[7] 25 Carry Chain Sizing Minimize size of transistors not on critical path Taper sizes along carry chain Reduces diffusion capacitance What does tapering decrease? It increases the LE of the critical input Why is the ratio of the first inverter funny 26
14 Static Carry Chains Sizing is to reduce the parasitic delay This delay dominates in large fanin structures, since it grows proportional to n 2 Using geometric sizing (reducing each transistor along the chain by α) makes the parasitic delay linear But still does not make them fast Even though this chain is static logic Drive the carry chain both up (K) and down (G) Output is degraded, since it uses nmos only pass devices Using CMOS transmission gates is usually slower because of the added parasitic capacitors 27 Global Carry Chain Must fan out GCIN[3:1] to 8 muxes Added load capacitance slows down the chain GG_b[] GG_b[1] GG_b[2] GG_b[3] GP[] GP[1] GP[2] GP[3] CIN COUT GK[] GK[1] GK[2] GK[3] GCIN[1] GCIN[2] GCIN[3] 28
15 Conditional Sums Use same carry chain Do two of these (one for cin=, one for cin=1): P[] G_b[] P[1] G_b[1] P[2] G_b[2] P[3] G_b[3] P[] G_b[4] P[5] G_b[5] P[6] G_b[6] P[7] G_b[7] CIN K[] K[1] K[2] K[3] K[4] K[5] K[6] K[7] P[] P[1] P[2] P[3] P[4] P[5] P[6] P[7] SUM[] SUM[1] SUM[2] SUM[3] SUM[4] SUM[5] SUM[6] SUM[7] Mux SUM[7:] and SUM1[7:] with output of global carry chain 29 Arithmetic Operations For Media Processing Used in Media processing DSP s, multimedia extensions to instruction set architectures (MMX, VIS) Consider three variations of conventional arithmetic: Segmented Arithmetic Break carry chain Arithmetic operations similar to add/subtract Example: 4 parallel 8-bit unsigned absolute differences Saturation Don t wraparound on overflow 3
16 Segmented add operation Support 32-bit, dual half-word, or quad byte ops Example: 4 parallel byte additions Treat each byte as a separate 2 s complement number Don t propagate the carries across byte boundaries F F F F + F E Modification For Segmentation PGK's: Only modify carry propagation in global carry chain A[31] B[31] A[24] B[24] PGK's: A[23] B[23] A[16] B[16] PGK's: A[15] B[15] A[8] B[8] PGK's: A[7] B[7] A[] B[] Group PGK Group PGK Group PGK Group PGK COUT Global Carry Chain CIN PGK's[31:24] PGK's[23:16] PGK's[15:8] PGK's[7:] Conditional Sum 1 Conditional Sum 1 Conditional Sum 1 Sum CIN SUM[31:24] SUM[23:16] SUM[15:8] SUM[7:] 32
17 Global Carry w/ Segment Support This method adds mux to critical path GG_b[2] We can improve on this Possible to move off critical path By moving to start of adder CIN GP[2] GK[2] GG_b[] GG_b[1] GG_b[2] GP[] GP[1] GP[2] CIN If the op type is known early GK[] For cells at start of segment Change P, G definition Change Cin to local carry chains GK[1] GK[2] CIN CIN GCIN[3] GCIN[2] CIN GCIN[1] 33 Absolute Difference Example: 4 parallel byte absolute differences Important in MPEG encoding algorithm Algorithm: Take two unsigned 8-bit numbers (between and 255) Compute a-b Result is unsigned (between and 255) 34
18 Absolute Difference How do we compute a-b? We need to compute a-b and b-a and take the positive one Remember that in 2 s complement, -x = ~x + 1 The carry-select adder will compute a+~b+1 and a+~b a+~b+1 = a-b a+~b = a -b-1 Note that ~(b - a) + 1 = a - b so ~(b - a) = a - b - 1 or b -a = ~(a -b-1) So, to compute a-b, just choose between SUM1 or ~SUM depending on the sign bit 35 Sum of Absolute Differences PGK's: A[31] B[31] Must do conditional sum for lower 8 bits Must further modify global carry chain to look at sign bits If positive, choose SUM1; If negative, choose ~SUM A[24] B[24] PGK's: A[23] B[23] A[16] B[16] PGK's: A[15] B[15] A[8] B[8] PGK's: A[7] B[7] A[] B[] Group PGK Group PGK Group PGK Group PGK COUT Global Carry Chain CIN PGK's[31:24] PGK's[23:16] PGK's[15:8] PGK's[7:] Conditional Sum 1 Conditional Sum 1 Conditional Sum 1 Conditional Sum 1 36 SUM[31:24] SUM[23:16] SUM[15:8] SUM[7:]
19 Saturation Often in media and signal processors, saturating arithmetic is supported: Don t wraparound on overflow Result should be largest (or smallest) value possible Examples: 32-bit saturating integer add: IADDS32(x7FFFFFFF,X1)=x7FFFFFFF 8-bit saturating unsigned subtract: USUBS8(x2FE2FE,x3FE1FF)=x1 37 Hardware Support For Saturation Overflow detection Example: signed addition Can look at sign bits of inputs and outputs Or can compute using ovf = cinmsb coutmsb Overflow propagation Similar to segmented, global carry chain, except for overflows Output muxing Need a many-to-one mux for each byte to choose between: xff,x,x7f,x8 and the unsaturated value Methods for speeding up saturation Could probably do carry-select saturation detection 38
 Standard cell implementation ~23.")

20 Simulated Performance Two implementations: Custom circuits (using circuits from these slides) 15.1 FO4 delays through integer adder 9.3 FO4 delays through overflow detection and saturation ~3λ x 5λ for adder only (excluding ovf det and saturation) Standard cell implementation ~23.5 FO4 delays through integer adder ~1 FO4 delays through overflow detection and saturation ~8λ x 8λ for adder only (excluding ovf det and saturation) Significant room for speed improvement through any of the following techniques: Domino circuits Faster carry-chain structures e.g. carry-select on upper half of carry chains within each group pgk 39 Adder layout 323 µm 5 µm PGK s GROUP PGK LOCAL CARRY CHAINS SUM SUM SUM SUM SUM SUM SUM SUM -.25 µm process 4
21 Adder Results From Previous Years 8 bit Manchester carry chains are slow, no matter how you size them. If you are going to use 8 bit groups, you probably need look-ahead in that group Using dynamic gates is much faster than static gates but Need to worry a lot more about clock skew and noise margin issues. You also need to think about power It is possible to move segment overhead off the critical path Saturation is a pain since you need to know overflow condition before you can select the correct sum But you can calculate overflow early if you spend hardware 41 Floating-Point Number Representation IEEE Format Single-Precision Floating-Point numbers: Contain Sign bit, exponent, and mantissa Number represents (-1)S*(1.mantissa)*(2)Exp-127 Numbers are in sign magnitude form S Exp Mantissa
22 Floating-Point Addition A Basic Algorithm: Compare exponents of A & B Perform alignment shift: Whichever has smaller exponent, shift its mantissa right by exp(a)-exp(b) Add unshifted mantissa with shifted mantissa Round result Perform normalize shift: Shift output of add so that leading 1 lands in the right place, then adjust exponent of result >> + >> B 43 Alignment Shifter Use difference in exponents as shift amount Simplest shifter is 5 stages of 2:1 muxes Control wires for each stage come directly from exp diff: 44
23 Shifter Design Can improve on this: Stage 1: 4:1 mux; shift by, 8, 16, or 24 Stage 2: 6:1 mux; shift by, 1, 2, 3, 4, 5, or 6 Must do pre-computation on shift amount to convert to 1-hot mux selects, but need buffer chain for fan-out anyway Tradeoffs between number of stages and logical effort of each stage are possible But shifters are not fast Especially if the shift amount is not know in advance For floating point shift amount depends on the operands 45 Aside: What About Segmented Shifts? Example: support 32-bit arithmetic shifts or 16-bit arithmetic shifts Arithmetic shifts mean sign extend msb on right shifts Increases the number of mux inputs and/or stages of the shifter (at least for bits near the msb): Stage 1: 5:1 mux: 32-bit shift by, 8, 16, 24 or 16-bit shift by 8 Stage 2: 7:1 mux 32-bit shift by, 2, 4, 6 or 16-bit shift by 2, 4, 6 Stage 3: 3:1 mux 32-bit shift by, 1 or 16-bit shift by 1 46
24 Fast Floating Point Trick In general floating point requires two variable length shifts To normalize the inputs mantissa s to equal significance To renormalize the output, so mantissa s MSB is 1 The critical observation is that no operation requires two both If the numbers are the same significance Don t need a normalization shift greater than 1 bit But you can get large cancellation, and need renormalization If the numbers are difference significance Need to normalize them But they can t cancel, max renormalization is a shift of +/- 1 But don t use this trick if throughput more important than latency 47 Floating Point Rounding In integer world, there is a right answer You have all the bits to start with Overflow is an error With floating point numbers, there is not one right answer You loose bits all the time Example is when you right shift for normalization Need to decide what answer to give IEEE standard gives many options Most common is rounded Rounding seems easy, but it is quite complex Don t know the significance of result until you have it But you want to add the ½ for rounding during the add See Appendix A of Hennessy & Patterson for details 48
25 Normalize Shifter Shift mantissa so that leading one lands in the right place Adjust exponent if necessary If the input operands have very different exponents, the leading one will be in one of two places If the input operands have the same exponents or exponents that only differ by 1, the leading one could be anywhere e.g = Floating-Point Adder Summary Basic operation: Shift, Add, Shift Carry-select adder important for rounding compute two correctly rounded adds in parallel choose the correct one based on overflow detection Can reuse same hardware for floating-point, integer, and segmented arithmetic operations Built 4-cycle pipelined floating-point adder runs at 3 FO4 delays per cycle in standard cell implementation (5 FO4 from clocking overhead) ~1,λ x 33λ 5
Binary Arithmetic. Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T.
 Binary Arithmetic Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. MIT 6.004 Fall 2018 Reminder: Encoding Positive Integers Bit i in a binary representation (in right-to-left order)
Binary Arithmetic Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. MIT 6.004 Fall 2018 Reminder: Encoding Positive Integers Bit i in a binary representation (in right-to-left order)
Computer Architecture Set Four. Arithmetic
 Computer Architecture Set Four Arithmetic Arithmetic Where we ve been: Performance (seconds, cycles, instructions) Abstractions: Instruction Set Architecture Assembly Language and Machine Language What
Computer Architecture Set Four Arithmetic Arithmetic Where we ve been: Performance (seconds, cycles, instructions) Abstractions: Instruction Set Architecture Assembly Language and Machine Language What
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 3. Arithmetic for Computers Implementation
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 3 Arithmetic for Computers Implementation Today Review representations (252/352 recap) Floating point Addition: Ripple
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 3 Arithmetic for Computers Implementation Today Review representations (252/352 recap) Floating point Addition: Ripple
CAD4 The ALU Fall 2009 Assignment. Description
 CAD4 The ALU Fall 2009 Assignment To design a 16-bit ALU which will be used in the datapath of the microprocessor. This ALU must support two s complement arithmetic and the instructions in the baseline
CAD4 The ALU Fall 2009 Assignment To design a 16-bit ALU which will be used in the datapath of the microprocessor. This ALU must support two s complement arithmetic and the instructions in the baseline
MOS High Performance Arithmetic
 MOS High Performance Arithmetic Mark Horowitz Stanford University horowitz@ee.stanford.edu Arithmetic Is Important Then Now (TegraK1) 2 What Is Hard? 9999999 + 1 3 Proof: 1 st Gen 2 nd Gen 4 And Getting
MOS High Performance Arithmetic Mark Horowitz Stanford University horowitz@ee.stanford.edu Arithmetic Is Important Then Now (TegraK1) 2 What Is Hard? 9999999 + 1 3 Proof: 1 st Gen 2 nd Gen 4 And Getting
Number Systems and Computer Arithmetic
 Number Systems and Computer Arithmetic Counting to four billion two fingers at a time What do all those bits mean now? bits (011011011100010...01) instruction R-format I-format... integer data number text
Number Systems and Computer Arithmetic Counting to four billion two fingers at a time What do all those bits mean now? bits (011011011100010...01) instruction R-format I-format... integer data number text
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Arithmetic Unit 10122011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Fixed Point Arithmetic Addition/Subtraction
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Arithmetic Unit 10122011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Recap Fixed Point Arithmetic Addition/Subtraction
Chapter 3 Arithmetic for Computers
 Chapter 3 Arithmetic for Computers 1 Arithmetic Where we've been: Abstractions: Instruction Set Architecture Assembly Language and Machine Language What's up ahead: Implementing the Architecture operation
Chapter 3 Arithmetic for Computers 1 Arithmetic Where we've been: Abstractions: Instruction Set Architecture Assembly Language and Machine Language What's up ahead: Implementing the Architecture operation
Chapter 3: part 3 Binary Subtraction
 Chapter 3: part 3 Binary Subtraction Iterative combinational circuits Binary adders Half and full adders Ripple carry and carry lookahead adders Binary subtraction Binary adder-subtractors Signed binary
Chapter 3: part 3 Binary Subtraction Iterative combinational circuits Binary adders Half and full adders Ripple carry and carry lookahead adders Binary subtraction Binary adder-subtractors Signed binary
Microcomputers. Outline. Number Systems and Digital Logic Review
 Microcomputers Number Systems and Digital Logic Review Lecture 1-1 Outline Number systems and formats Common number systems Base Conversion Integer representation Signed integer representation Binary coded
Microcomputers Number Systems and Digital Logic Review Lecture 1-1 Outline Number systems and formats Common number systems Base Conversion Integer representation Signed integer representation Binary coded
M.J. Flynn 1. Lecture 6 EE 486. Bit logic. Ripple adders. Add algorithms. Addition. EE 486 lecture 6: Integer Addition
 EE 486 lecture 6: Integer Addition M. J. Flynn Computer Architecture & Arithmetic Group 1 Stanford University Computer Architecture & Arithmetic Group 2 Stanford University Addition The add function is
EE 486 lecture 6: Integer Addition M. J. Flynn Computer Architecture & Arithmetic Group 1 Stanford University Computer Architecture & Arithmetic Group 2 Stanford University Addition The add function is
Jan Rabaey Homework # 7 Solutions EECS141
 UNIVERSITY OF CALIFORNIA College of Engineering Department of Electrical Engineering and Computer Sciences Last modified on March 30, 2004 by Gang Zhou (zgang@eecs.berkeley.edu) Jan Rabaey Homework # 7
UNIVERSITY OF CALIFORNIA College of Engineering Department of Electrical Engineering and Computer Sciences Last modified on March 30, 2004 by Gang Zhou (zgang@eecs.berkeley.edu) Jan Rabaey Homework # 7
Learning Outcomes. Spiral 2 2. Digital System Design DATAPATH COMPONENTS
 2-2. 2-2.2 Learning Outcomes piral 2 2 Arithmetic Components and Their Efficient Implementations I know how to combine overflow and subtraction results to determine comparison results of both signed and
2-2. 2-2.2 Learning Outcomes piral 2 2 Arithmetic Components and Their Efficient Implementations I know how to combine overflow and subtraction results to determine comparison results of both signed and
6.004 Computation Structures Spring 2009
 MIT OpenCourseWare http://ocw.mit.edu 6.004 Computation Structures Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. M A S S A C H U S E T T
MIT OpenCourseWare http://ocw.mit.edu 6.004 Computation Structures Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. M A S S A C H U S E T T
Lecture 7: Instruction Set Architectures - IV
 Lecture 7: Instruction Set Architectures - IV Last Time Register organization Memory issues (endian-ness, alignment, etc.) Today Exceptions General principles of ISA design Role of compiler Computer arithmetic
Lecture 7: Instruction Set Architectures - IV Last Time Register organization Memory issues (endian-ness, alignment, etc.) Today Exceptions General principles of ISA design Role of compiler Computer arithmetic
Lecture Topics. Announcements. Today: Integer Arithmetic (P&H ) Next: continued. Consulting hours. Introduction to Sim. Milestone #1 (due 1/26)
 Next: continued. Consulting hours. Introduction to Sim. Milestone #1 (due 1/26)") Lecture Topics Today: Integer Arithmetic (P&H 3.1-3.4) Next: continued 1 Announcements Consulting hours Introduction to Sim Milestone #1 (due 1/26) 2 1 Overview: Integer Operations Internal representation
Lecture Topics Today: Integer Arithmetic (P&H 3.1-3.4) Next: continued 1 Announcements Consulting hours Introduction to Sim Milestone #1 (due 1/26) 2 1 Overview: Integer Operations Internal representation
Part I: Translating & Starting a Program: Compiler, Linker, Assembler, Loader. Lecture 4
 Part I: a Program: Compiler, Linker, Assembler, Loader Lecture 4 Program Translation Hierarchy C program Com piler Assem bly language program Assem bler Object: Machine language module Object: Library
Part I: a Program: Compiler, Linker, Assembler, Loader Lecture 4 Program Translation Hierarchy C program Com piler Assem bly language program Assem bler Object: Machine language module Object: Library
CS101 Lecture 04: Binary Arithmetic
 CS101 Lecture 04: Binary Arithmetic Binary Number Addition Two s complement encoding Briefly: real number representation Aaron Stevens (azs@bu.edu) 25 January 2013 What You ll Learn Today Counting in binary
CS101 Lecture 04: Binary Arithmetic Binary Number Addition Two s complement encoding Briefly: real number representation Aaron Stevens (azs@bu.edu) 25 January 2013 What You ll Learn Today Counting in binary
Basic Arithmetic (adding and subtracting)
") Basic Arithmetic (adding and subtracting) Digital logic to show add/subtract Boolean algebra abstraction of physical, analog circuit behavior 1 0 CPU components ALU logic circuits logic gates transistors
Basic Arithmetic (adding and subtracting) Digital logic to show add/subtract Boolean algebra abstraction of physical, analog circuit behavior 1 0 CPU components ALU logic circuits logic gates transistors
Partitioned Branch Condition Resolution Logic
 1 Synopsys Inc. Synopsys Module Compiler Group 700 Middlefield Road, Mountain View CA 94043-4033 (650) 584-5689 (650) 584-1227 FAX aamirf@synopsys.com http://aamir.homepage.com Partitioned Branch Condition
1 Synopsys Inc. Synopsys Module Compiler Group 700 Middlefield Road, Mountain View CA 94043-4033 (650) 584-5689 (650) 584-1227 FAX aamirf@synopsys.com http://aamir.homepage.com Partitioned Branch Condition
At the ith stage: Input: ci is the carry-in Output: si is the sum ci+1 carry-out to (i+1)st state
st state") Chapter 4 xi yi Carry in ci Sum s i Carry out c i+ At the ith stage: Input: ci is the carry-in Output: si is the sum ci+ carry-out to (i+)st state si = xi yi ci + xi yi ci + xi yi ci + xi yi ci = x i yi
Chapter 4 xi yi Carry in ci Sum s i Carry out c i+ At the ith stage: Input: ci is the carry-in Output: si is the sum ci+ carry-out to (i+)st state si = xi yi ci + xi yi ci + xi yi ci + xi yi ci = x i yi
Fundamentals of Computer Systems
 Fundamentals of Computer Systems Combinational Logic Martha. Kim Columbia University Spring 6 / Combinational Circuits Combinational circuits are stateless. Their output is a function only of the current
Fundamentals of Computer Systems Combinational Logic Martha. Kim Columbia University Spring 6 / Combinational Circuits Combinational circuits are stateless. Their output is a function only of the current
POWER PERFORMANCE OPTIMIZATION METHODS FOR DIGITAL CIRCUITS
 POWER PERFORMANCE OPTIMIZATION METHODS FOR DIGITAL CIRCUITS Radu Zlatanovici zradu@eecs.berkeley.edu http://www.eecs.berkeley.edu/~zradu Department of Electrical Engineering and Computer Sciences University
POWER PERFORMANCE OPTIMIZATION METHODS FOR DIGITAL CIRCUITS Radu Zlatanovici zradu@eecs.berkeley.edu http://www.eecs.berkeley.edu/~zradu Department of Electrical Engineering and Computer Sciences University
MULTIPLE OPERAND ADDITION. Multioperand Addition
 MULTIPLE OPERAND ADDITION Chapter 3 Multioperand Addition Add up a bunch of numbers Used in several algorithms Multiplication, recurrences, transforms, and filters Signed (two s comp) and unsigned Don
MULTIPLE OPERAND ADDITION Chapter 3 Multioperand Addition Add up a bunch of numbers Used in several algorithms Multiplication, recurrences, transforms, and filters Signed (two s comp) and unsigned Don
CPE 335 Computer Organization. MIPS Arithmetic Part I. Content from Chapter 3 and Appendix B
 CPE 335 Computer Organization MIPS Arithmetic Part I Content from Chapter 3 and Appendix B Dr. Iyad Jafar Adatped from Dr. Gheith Abandah Slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html
CPE 335 Computer Organization MIPS Arithmetic Part I Content from Chapter 3 and Appendix B Dr. Iyad Jafar Adatped from Dr. Gheith Abandah Slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html
Overview. EECS Components and Design Techniques for Digital Systems. Lec 16 Arithmetic II (Multiplication) Computer Number Systems.
 Computer Number Systems.") Overview EE 15 - omponents and Design Techniques for Digital ystems Lec 16 Arithmetic II (Multiplication) Review of Addition Overflow Multiplication Further adder optimizations for multiplication LA in
Overview EE 15 - omponents and Design Techniques for Digital ystems Lec 16 Arithmetic II (Multiplication) Review of Addition Overflow Multiplication Further adder optimizations for multiplication LA in
ECE468 Computer Organization & Architecture. The Design Process & ALU Design
 ECE6 Computer Organization & Architecture The Design Process & Design The Design Process "To Design Is To Represent" Design activity yields description/representation of an object -- Traditional craftsman
ECE6 Computer Organization & Architecture The Design Process & Design The Design Process "To Design Is To Represent" Design activity yields description/representation of an object -- Traditional craftsman
Learning Outcomes. Spiral 2-2. Digital System Design DATAPATH COMPONENTS
 2-2. 2-2.2 Learning Outcomes piral 2-2 Arithmetic Components and Their Efficient Implementations I understand the control inputs to counters I can design logic to control the inputs of counters to create
2-2. 2-2.2 Learning Outcomes piral 2-2 Arithmetic Components and Their Efficient Implementations I understand the control inputs to counters I can design logic to control the inputs of counters to create
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 15: Midterm 1 Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Basics Midterm to cover Book Sections (inclusive) 1.1 1.5
ECE331: Hardware Organization and Design Lecture 15: Midterm 1 Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Basics Midterm to cover Book Sections (inclusive) 1.1 1.5
10.1. Unit 10. Signed Representation Systems Binary Arithmetic
 0. Unit 0 Signed Representation Systems Binary Arithmetic 0.2 BINARY REPRESENTATION SYSTEMS REVIEW 0.3 Interpreting Binary Strings Given a string of s and 0 s, you need to know the representation system
0. Unit 0 Signed Representation Systems Binary Arithmetic 0.2 BINARY REPRESENTATION SYSTEMS REVIEW 0.3 Interpreting Binary Strings Given a string of s and 0 s, you need to know the representation system
Learning Outcomes. Spiral 2 2. Digital System Design DATAPATH COMPONENTS
 2-2. 2-2.2 Learning Outcomes piral 2 2 Arithmetic Components and Their Efficient Implementations I know how to combine overflow and subtraction results to determine comparison results of both signed and
2-2. 2-2.2 Learning Outcomes piral 2 2 Arithmetic Components and Their Efficient Implementations I know how to combine overflow and subtraction results to determine comparison results of both signed and
Arithmetic Logic Unit. Digital Computer Design
 Arithmetic Logic Unit Digital Computer Design Arithmetic Circuits Arithmetic circuits are the central building blocks of computers. Computers and digital logic perform many arithmetic functions: addition,
Arithmetic Logic Unit Digital Computer Design Arithmetic Circuits Arithmetic circuits are the central building blocks of computers. Computers and digital logic perform many arithmetic functions: addition,
CS Computer Architecture. 1. Explain Carry Look Ahead adders in detail
 1. Explain Carry Look Ahead adders in detail A carry-look ahead adder (CLA) is a type of adder used in digital logic. A carry-look ahead adder improves speed by reducing the amount of time required to
1. Explain Carry Look Ahead adders in detail A carry-look ahead adder (CLA) is a type of adder used in digital logic. A carry-look ahead adder improves speed by reducing the amount of time required to
Floating Point Arithmetic
 Floating Point Arithmetic Clark N. Taylor Department of Electrical and Computer Engineering Brigham Young University clark.taylor@byu.edu 1 Introduction Numerical operations are something at which digital
Floating Point Arithmetic Clark N. Taylor Department of Electrical and Computer Engineering Brigham Young University clark.taylor@byu.edu 1 Introduction Numerical operations are something at which digital
Inf2C - Computer Systems Lecture 2 Data Representation
 Inf2C - Computer Systems Lecture 2 Data Representation Boris Grot School of Informatics University of Edinburgh Last lecture Moore s law Types of computer systems Computer components Computer system stack
Inf2C - Computer Systems Lecture 2 Data Representation Boris Grot School of Informatics University of Edinburgh Last lecture Moore s law Types of computer systems Computer components Computer system stack
Outline. EEL-4713 Computer Architecture Multipliers and shifters. Deriving requirements of ALU. MIPS arithmetic instructions
 Outline EEL-4713 Computer Architecture Multipliers and shifters Multiplication and shift registers Chapter 3, section 3.4 Next lecture Division, floating-point 3.5 3.6 EEL-4713 Ann Gordon-Ross.1 EEL-4713
Outline EEL-4713 Computer Architecture Multipliers and shifters Multiplication and shift registers Chapter 3, section 3.4 Next lecture Division, floating-point 3.5 3.6 EEL-4713 Ann Gordon-Ross.1 EEL-4713
VTU NOTES QUESTION PAPERS NEWS RESULTS FORUMS Arithmetic (a) The four possible cases Carry (b) Truth table x y
 The four possible cases Carry (b) Truth table x y") Arithmetic A basic operation in all digital computers is the addition and subtraction of two numbers They are implemented, along with the basic logic functions such as AND,OR, NOT,EX- OR in the ALU subsystem
Arithmetic A basic operation in all digital computers is the addition and subtraction of two numbers They are implemented, along with the basic logic functions such as AND,OR, NOT,EX- OR in the ALU subsystem
Slide Set 5. for ENCM 369 Winter 2014 Lecture Section 01. Steve Norman, PhD, PEng
 Slide Set 5 for ENCM 369 Winter 2014 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2014 ENCM 369 W14 Section
Slide Set 5 for ENCM 369 Winter 2014 Lecture Section 01 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary Winter Term, 2014 ENCM 369 W14 Section
 CS6303 COMPUTER ARCHITECTURE LESSION NOTES UNIT II ARITHMETIC OPERATIONS ALU In computing an arithmetic logic unit (ALU) is a digital circuit that performs arithmetic and logical operations. The ALU is
CS6303 COMPUTER ARCHITECTURE LESSION NOTES UNIT II ARITHMETIC OPERATIONS ALU In computing an arithmetic logic unit (ALU) is a digital circuit that performs arithmetic and logical operations. The ALU is
Topic Notes: Bits and Bytes and Numbers
 Computer Science 220 Assembly Language & Comp Architecture Siena College Fall 2010 Topic Notes: Bits and Bytes and Numbers Binary Basics At least some of this will be review, but we will go over it for
Computer Science 220 Assembly Language & Comp Architecture Siena College Fall 2010 Topic Notes: Bits and Bytes and Numbers Binary Basics At least some of this will be review, but we will go over it for
Principles of Computer Architecture. Chapter 3: Arithmetic
 3-1 Chapter 3 - Arithmetic Principles of Computer Architecture Miles Murdocca and Vincent Heuring Chapter 3: Arithmetic 3-2 Chapter 3 - Arithmetic 3.1 Overview Chapter Contents 3.2 Fixed Point Addition
3-1 Chapter 3 - Arithmetic Principles of Computer Architecture Miles Murdocca and Vincent Heuring Chapter 3: Arithmetic 3-2 Chapter 3 - Arithmetic 3.1 Overview Chapter Contents 3.2 Fixed Point Addition
Chapter 5. Digital Design and Computer Architecture, 2 nd Edition. David Money Harris and Sarah L. Harris. Chapter 5 <1>
 Chapter 5 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 5 Chapter 5 :: Topics Introduction Arithmetic Circuits umber Systems Sequential Building
Chapter 5 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 5 Chapter 5 :: Topics Introduction Arithmetic Circuits umber Systems Sequential Building
MIPS Integer ALU Requirements
 MIPS Integer ALU Requirements Add, AddU, Sub, SubU, AddI, AddIU: 2 s complement adder/sub with overflow detection. And, Or, Andi, Ori, Xor, Xori, Nor: Logical AND, logical OR, XOR, nor. SLTI, SLTIU (set
MIPS Integer ALU Requirements Add, AddU, Sub, SubU, AddI, AddIU: 2 s complement adder/sub with overflow detection. And, Or, Andi, Ori, Xor, Xori, Nor: Logical AND, logical OR, XOR, nor. SLTI, SLTIU (set
Arithmetic Circuits. Nurul Hazlina Adder 2. Multiplier 3. Arithmetic Logic Unit (ALU) 4. HDL for Arithmetic Circuit
 4. HDL for Arithmetic Circuit") Nurul Hazlina 1 1. Adder 2. Multiplier 3. Arithmetic Logic Unit (ALU) 4. HDL for Arithmetic Circuit Nurul Hazlina 2 Introduction 1. Digital circuits are frequently used for arithmetic operations 2. Fundamental
Nurul Hazlina 1 1. Adder 2. Multiplier 3. Arithmetic Logic Unit (ALU) 4. HDL for Arithmetic Circuit Nurul Hazlina 2 Introduction 1. Digital circuits are frequently used for arithmetic operations 2. Fundamental
Chapter 3 Arithmetic for Computers. ELEC 5200/ From P-H slides
 Chapter 3 Arithmetic for Computers 1 Arithmetic for Computers Operations on integers Addition and subtraction Multiplication and division Dealing with overflow Floating-point real numbers Representation
Chapter 3 Arithmetic for Computers 1 Arithmetic for Computers Operations on integers Addition and subtraction Multiplication and division Dealing with overflow Floating-point real numbers Representation
Computer Architecture and Organization
 3-1 Chapter 3 - Arithmetic Computer Architecture and Organization Miles Murdocca and Vincent Heuring Chapter 3 Arithmetic 3-2 Chapter 3 - Arithmetic Chapter Contents 3.1 Fixed Point Addition and Subtraction
3-1 Chapter 3 - Arithmetic Computer Architecture and Organization Miles Murdocca and Vincent Heuring Chapter 3 Arithmetic 3-2 Chapter 3 - Arithmetic Chapter Contents 3.1 Fixed Point Addition and Subtraction
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 11: Floating Point & Floating Point Addition Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Last time: Single Precision Format
ECE232: Hardware Organization and Design Lecture 11: Floating Point & Floating Point Addition Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Last time: Single Precision Format
DIGITAL TECHNICS. Dr. Bálint Pődör. Óbuda University, Microelectronics and Technology Institute
 DIGITAL TECHNIC Dr. Bálint Pődör Óbuda University, Microelectronics and Technology Institute 4. LECTURE: COMBINATIONAL LOGIC DEIGN: ARITHMETIC (THROUGH EXAMPLE) 2nd (Autumn) term 28/29 COMBINATIONAL LOGIC
DIGITAL TECHNIC Dr. Bálint Pődör Óbuda University, Microelectronics and Technology Institute 4. LECTURE: COMBINATIONAL LOGIC DEIGN: ARITHMETIC (THROUGH EXAMPLE) 2nd (Autumn) term 28/29 COMBINATIONAL LOGIC
Data Representation Type of Data Representation Integers Bits Unsigned 2 s Comp Excess 7 Excess 8
 Data Representation At its most basic level, all digital information must reduce to 0s and 1s, which can be discussed as binary, octal, or hex data. There s no practical limit on how it can be interpreted
Data Representation At its most basic level, all digital information must reduce to 0s and 1s, which can be discussed as binary, octal, or hex data. There s no practical limit on how it can be interpreted
Two-Level CLA for 4-bit Adder. Two-Level CLA for 4-bit Adder. Two-Level CLA for 16-bit Adder. A Closer Look at CLA Delay
 Two-Level CLA for 4-bit Adder Individual carry equations C 1 = g 0 +p 0, C 2 = g 1 +p 1 C 1,C 3 = g 2 +p 2 C 2, = g 3 +p 3 C 3 Fully expanded (infinite hardware) CLA equations C 1 = g 0 +p 0 C 2 = g 1
Two-Level CLA for 4-bit Adder Individual carry equations C 1 = g 0 +p 0, C 2 = g 1 +p 1 C 1,C 3 = g 2 +p 2 C 2, = g 3 +p 3 C 3 Fully expanded (infinite hardware) CLA equations C 1 = g 0 +p 0 C 2 = g 1
CHAPTER 1 Numerical Representation
 CHAPTER 1 Numerical Representation To process a signal digitally, it must be represented in a digital format. This point may seem obvious, but it turns out that there are a number of different ways to
CHAPTER 1 Numerical Representation To process a signal digitally, it must be represented in a digital format. This point may seem obvious, but it turns out that there are a number of different ways to
Lecture 3: Basic Adders and Counters
 Lecture 3: Basic Adders and Counters ECE 645 Computer Arithmetic /5/8 ECE 645 Computer Arithmetic Lecture Roadmap Revisiting Addition and Overflow Rounding Techniques Basic Adders and Counters Required
Lecture 3: Basic Adders and Counters ECE 645 Computer Arithmetic /5/8 ECE 645 Computer Arithmetic Lecture Roadmap Revisiting Addition and Overflow Rounding Techniques Basic Adders and Counters Required
ECE 341. Lecture # 6
 ECE 34 Lecture # 6 Instructor: Zeshan Chishti zeshan@pdx.edu October 5, 24 Portland State University Lecture Topics Design of Fast Adders Carry Looakahead Adders (CLA) Blocked Carry-Lookahead Adders Multiplication
ECE 34 Lecture # 6 Instructor: Zeshan Chishti zeshan@pdx.edu October 5, 24 Portland State University Lecture Topics Design of Fast Adders Carry Looakahead Adders (CLA) Blocked Carry-Lookahead Adders Multiplication
Kinds Of Data CHAPTER 3 DATA REPRESENTATION. Numbers Are Different! Positional Number Systems. Text. Numbers. Other
 Kinds Of Data CHAPTER 3 DATA REPRESENTATION Numbers Integers Unsigned Signed Reals Fixed-Point Floating-Point Binary-Coded Decimal Text ASCII Characters Strings Other Graphics Images Video Audio Numbers
Kinds Of Data CHAPTER 3 DATA REPRESENTATION Numbers Integers Unsigned Signed Reals Fixed-Point Floating-Point Binary-Coded Decimal Text ASCII Characters Strings Other Graphics Images Video Audio Numbers
AN IMPROVED FUSED FLOATING-POINT THREE-TERM ADDER. Mohyiddin K, Nithin Jose, Mitha Raj, Muhamed Jasim TK, Bijith PS, Mohamed Waseem P
 AN IMPROVED FUSED FLOATING-POINT THREE-TERM ADDER Mohyiddin K, Nithin Jose, Mitha Raj, Muhamed Jasim TK, Bijith PS, Mohamed Waseem P ABSTRACT A fused floating-point three term adder performs two additions
AN IMPROVED FUSED FLOATING-POINT THREE-TERM ADDER Mohyiddin K, Nithin Jose, Mitha Raj, Muhamed Jasim TK, Bijith PS, Mohamed Waseem P ABSTRACT A fused floating-point three term adder performs two additions
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 9: Binary Addition & Multiplication Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Pop Quiz! Using 4 bits signed integer notation:
ECE331: Hardware Organization and Design Lecture 9: Binary Addition & Multiplication Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Pop Quiz! Using 4 bits signed integer notation:
EE878 Special Topics in VLSI. Computer Arithmetic for Digital Signal Processing
 EE878 Special Topics in VLSI Computer Arithmetic for Digital Signal Processing Part 6b High-Speed Multiplication - II Spring 2017 Koren Part.6b.1 Accumulating the Partial Products After generating partial
EE878 Special Topics in VLSI Computer Arithmetic for Digital Signal Processing Part 6b High-Speed Multiplication - II Spring 2017 Koren Part.6b.1 Accumulating the Partial Products After generating partial
Chapter 6 ARITHMETIC FOR DIGITAL SYSTEMS
 Chapter 6 ARITHMETIC FOR DIGITAL SYSTEMS Introduction Notation Systems Principle of Generation and Propagation The bit Full Adder Enhancement Techniques for Adders Multioperand Adders Multiplication Addition
Chapter 6 ARITHMETIC FOR DIGITAL SYSTEMS Introduction Notation Systems Principle of Generation and Propagation The bit Full Adder Enhancement Techniques for Adders Multioperand Adders Multiplication Addition
E40M. Binary Numbers, Codes. M. Horowitz, J. Plummer, R. Howe 1
 E40M Binary Numbers, Codes M. Horowitz, J. Plummer, R. Howe 1 Reading Chapter 5 in the reader A&L 5.6 M. Horowitz, J. Plummer, R. Howe 2 Useless Box Lab Project #2 Adding a computer to the Useless Box
E40M Binary Numbers, Codes M. Horowitz, J. Plummer, R. Howe 1 Reading Chapter 5 in the reader A&L 5.6 M. Horowitz, J. Plummer, R. Howe 2 Useless Box Lab Project #2 Adding a computer to the Useless Box
Introduction to Field Programmable Gate Arrays
 Introduction to Field Programmable Gate Arrays Lecture 2/3 CERN Accelerator School on Digital Signal Processing Sigtuna, Sweden, 31 May 9 June 2007 Javier Serrano, CERN AB-CO-HT Outline Digital Signal
Introduction to Field Programmable Gate Arrays Lecture 2/3 CERN Accelerator School on Digital Signal Processing Sigtuna, Sweden, 31 May 9 June 2007 Javier Serrano, CERN AB-CO-HT Outline Digital Signal
CS 101: Computer Programming and Utilization
 CS 101: Computer Programming and Utilization Jul-Nov 2017 Umesh Bellur (cs101@cse.iitb.ac.in) Lecture 3: Number Representa.ons Representing Numbers Digital Circuits can store and manipulate 0 s and 1 s.
CS 101: Computer Programming and Utilization Jul-Nov 2017 Umesh Bellur (cs101@cse.iitb.ac.in) Lecture 3: Number Representa.ons Representing Numbers Digital Circuits can store and manipulate 0 s and 1 s.
ECE 2020B Fundamentals of Digital Design Spring problems, 6 pages Exam Two Solutions 26 February 2014
 Problem 1 (4 parts, 21 points) Encoders and Pass Gates Part A (8 points) Suppose the circuit below has the following input priority: I 1 > I 3 > I 0 > I 2. Complete the truth table by filling in the input
Problem 1 (4 parts, 21 points) Encoders and Pass Gates Part A (8 points) Suppose the circuit below has the following input priority: I 1 > I 3 > I 0 > I 2. Complete the truth table by filling in the input
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Digital Computer Arithmetic ECE 666
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Digital Computer Arithmetic ECE 666 Part 6b High-Speed Multiplication - II Israel Koren ECE666/Koren Part.6b.1 Accumulating the Partial
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Digital Computer Arithmetic ECE 666 Part 6b High-Speed Multiplication - II Israel Koren ECE666/Koren Part.6b.1 Accumulating the Partial
ECE 550D Fundamentals of Computer Systems and Engineering. Fall 2017
 ECE 550D Fundamentals of Computer Systems and Engineering Fall 2017 Combinational Logic Prof. John Board Duke University Slides are derived from work by Profs. Tyler Bletsch and Andrew Hilton (Duke) Last
ECE 550D Fundamentals of Computer Systems and Engineering Fall 2017 Combinational Logic Prof. John Board Duke University Slides are derived from work by Profs. Tyler Bletsch and Andrew Hilton (Duke) Last
CO212 Lecture 10: Arithmetic & Logical Unit
 CO212 Lecture 10: Arithmetic & Logical Unit Shobhanjana Kalita, Dept. of CSE, Tezpur University Slides courtesy: Computer Architecture and Organization, 9 th Ed, W. Stallings Integer Representation For
CO212 Lecture 10: Arithmetic & Logical Unit Shobhanjana Kalita, Dept. of CSE, Tezpur University Slides courtesy: Computer Architecture and Organization, 9 th Ed, W. Stallings Integer Representation For
Design and Analysis of Kogge-Stone and Han-Carlson Adders in 130nm CMOS Technology
 Design and Analysis of Kogge-Stone and Han-Carlson Adders in 130nm CMOS Technology Senthil Ganesh R & R. Kalaimathi 1 Assistant Professor, Electronics and Communication Engineering, Info Institute of Engineering,
Design and Analysis of Kogge-Stone and Han-Carlson Adders in 130nm CMOS Technology Senthil Ganesh R & R. Kalaimathi 1 Assistant Professor, Electronics and Communication Engineering, Info Institute of Engineering,
CHAPTER 5: Representing Numerical Data
 CHAPTER 5: Representing Numerical Data The Architecture of Computer Hardware and Systems Software & Networking: An Information Technology Approach 4th Edition, Irv Englander John Wiley and Sons 2010 PowerPoint
CHAPTER 5: Representing Numerical Data The Architecture of Computer Hardware and Systems Software & Networking: An Information Technology Approach 4th Edition, Irv Englander John Wiley and Sons 2010 PowerPoint
Chapter Three. Arithmetic
 Chapter Three 1 Arithmetic Where we've been: Performance (seconds, cycles, instructions) Abstractions: Instruction Set Architecture Assembly Language and Machine Language What's up ahead: Implementing
Chapter Three 1 Arithmetic Where we've been: Performance (seconds, cycles, instructions) Abstractions: Instruction Set Architecture Assembly Language and Machine Language What's up ahead: Implementing
Module 2: Computer Arithmetic
 Module 2: Computer Arithmetic 1 B O O K : C O M P U T E R O R G A N I Z A T I O N A N D D E S I G N, 3 E D, D A V I D L. P A T T E R S O N A N D J O H N L. H A N N E S S Y, M O R G A N K A U F M A N N
Module 2: Computer Arithmetic 1 B O O K : C O M P U T E R O R G A N I Z A T I O N A N D D E S I G N, 3 E D, D A V I D L. P A T T E R S O N A N D J O H N L. H A N N E S S Y, M O R G A N K A U F M A N N
By, Ajinkya Karande Adarsh Yoga
 By, Ajinkya Karande Adarsh Yoga Introduction Early computer designers believed saving computer time and memory were more important than programmer time. Bug in the divide algorithm used in Intel chips.
By, Ajinkya Karande Adarsh Yoga Introduction Early computer designers believed saving computer time and memory were more important than programmer time. Bug in the divide algorithm used in Intel chips.
Tailoring the 32-Bit ALU to MIPS
 Tailoring the 32-Bit ALU to MIPS MIPS ALU extensions Overflow detection: Carry into MSB XOR Carry out of MSB Branch instructions Shift instructions Slt instruction Immediate instructions ALU performance
Tailoring the 32-Bit ALU to MIPS MIPS ALU extensions Overflow detection: Carry into MSB XOR Carry out of MSB Branch instructions Shift instructions Slt instruction Immediate instructions ALU performance
Arithmetic Processing
 CS/EE 5830/6830 VLSI ARCHITECTURE Chapter 1 Basic Number Representations and Arithmetic Algorithms Arithmetic Processing AP = (operands, operation, results, conditions, singularities) Operands are: Set
CS/EE 5830/6830 VLSI ARCHITECTURE Chapter 1 Basic Number Representations and Arithmetic Algorithms Arithmetic Processing AP = (operands, operation, results, conditions, singularities) Operands are: Set
PESIT Bangalore South Campus
 INTERNAL ASSESSMENT TEST III Date : 21/11/2017 Max Marks : 40 Subject & Code : Computer Organization (15CS34) Semester : III (A & B) Name of the faculty: Mrs. Sharmila Banu Time : 11.30 am 1.00 pm Answer
INTERNAL ASSESSMENT TEST III Date : 21/11/2017 Max Marks : 40 Subject & Code : Computer Organization (15CS34) Semester : III (A & B) Name of the faculty: Mrs. Sharmila Banu Time : 11.30 am 1.00 pm Answer
CHW 261: Logic Design
 CHW 261: Logic Design Instructors: Prof. Hala Zayed Dr. Ahmed Shalaby http://www.bu.edu.eg/staff/halazayed14 http://bu.edu.eg/staff/ahmedshalaby14# Slide 1 Slide 2 Slide 3 Digital Fundamentals CHAPTER
CHW 261: Logic Design Instructors: Prof. Hala Zayed Dr. Ahmed Shalaby http://www.bu.edu.eg/staff/halazayed14 http://bu.edu.eg/staff/ahmedshalaby14# Slide 1 Slide 2 Slide 3 Digital Fundamentals CHAPTER
THE DESIGN OF AN IC HALF PRECISION FLOATING POINT ARITHMETIC LOGIC UNIT
 Clemson University TigerPrints All Theses Theses 12-2009 THE DESIGN OF AN IC HALF PRECISION FLOATING POINT ARITHMETIC LOGIC UNIT Balaji Kannan Clemson University, balaji.n.kannan@gmail.com Follow this
Clemson University TigerPrints All Theses Theses 12-2009 THE DESIGN OF AN IC HALF PRECISION FLOATING POINT ARITHMETIC LOGIC UNIT Balaji Kannan Clemson University, balaji.n.kannan@gmail.com Follow this
Floating Point. CSE 351 Autumn Instructor: Justin Hsia
 Floating Point CSE 351 Autumn 2017 Instructor: Justin Hsia Teaching Assistants: Lucas Wotton Michael Zhang Parker DeWilde Ryan Wong Sam Gehman Sam Wolfson Savanna Yee Vinny Palaniappan http://xkcd.com/571/
Floating Point CSE 351 Autumn 2017 Instructor: Justin Hsia Teaching Assistants: Lucas Wotton Michael Zhang Parker DeWilde Ryan Wong Sam Gehman Sam Wolfson Savanna Yee Vinny Palaniappan http://xkcd.com/571/
SIDDHARTH INSTITUTE OF ENGINEERING AND TECHNOLOGY :: PUTTUR (AUTONOMOUS) Siddharth Nagar, Narayanavanam Road QUESTION BANK UNIT I
 Siddharth Nagar, Narayanavanam Road QUESTION BANK UNIT I") SIDDHARTH INSTITUTE OF ENGINEERING AND TECHNOLOGY :: PUTTUR (AUTONOMOUS) Siddharth Nagar, Narayanavanam Road 517583 QUESTION BANK Subject with Code : DICD (16EC5703) Year & Sem: I-M.Tech & I-Sem Course
SIDDHARTH INSTITUTE OF ENGINEERING AND TECHNOLOGY :: PUTTUR (AUTONOMOUS) Siddharth Nagar, Narayanavanam Road 517583 QUESTION BANK Subject with Code : DICD (16EC5703) Year & Sem: I-M.Tech & I-Sem Course
COMPUTER ARCHITECTURE AND ORGANIZATION Register Transfer and Micro-operations 1. Introduction A digital system is an interconnection of digital
 Register Transfer and Micro-operations 1. Introduction A digital system is an interconnection of digital hardware modules that accomplish a specific information-processing task. Digital systems vary in
Register Transfer and Micro-operations 1. Introduction A digital system is an interconnection of digital hardware modules that accomplish a specific information-processing task. Digital systems vary in
MACHINE LEVEL REPRESENTATION OF DATA
 MACHINE LEVEL REPRESENTATION OF DATA CHAPTER 2 1 Objectives Understand how integers and fractional numbers are represented in binary Explore the relationship between decimal number system and number systems
MACHINE LEVEL REPRESENTATION OF DATA CHAPTER 2 1 Objectives Understand how integers and fractional numbers are represented in binary Explore the relationship between decimal number system and number systems
Topic Notes: Bits and Bytes and Numbers
 Computer Science 220 Assembly Language & Comp Architecture Siena College Fall 2011 Topic Notes: Bits and Bytes and Numbers Binary Basics At least some of this will be review for most of you, but we start
Computer Science 220 Assembly Language & Comp Architecture Siena College Fall 2011 Topic Notes: Bits and Bytes and Numbers Binary Basics At least some of this will be review for most of you, but we start
COMPUTER ORGANIZATION AND ARCHITECTURE
 COMPUTER ORGANIZATION AND ARCHITECTURE For COMPUTER SCIENCE COMPUTER ORGANIZATION. SYLLABUS AND ARCHITECTURE Machine instructions and addressing modes, ALU and data-path, CPU control design, Memory interface,
COMPUTER ORGANIZATION AND ARCHITECTURE For COMPUTER SCIENCE COMPUTER ORGANIZATION. SYLLABUS AND ARCHITECTURE Machine instructions and addressing modes, ALU and data-path, CPU control design, Memory interface,
Numeric Encodings Prof. James L. Frankel Harvard University
 Numeric Encodings Prof. James L. Frankel Harvard University Version of 10:19 PM 12-Sep-2017 Copyright 2017, 2016 James L. Frankel. All rights reserved. Representation of Positive & Negative Integral and
Numeric Encodings Prof. James L. Frankel Harvard University Version of 10:19 PM 12-Sep-2017 Copyright 2017, 2016 James L. Frankel. All rights reserved. Representation of Positive & Negative Integral and
The ALU consists of combinational logic. Processes all data in the CPU. ALL von Neuman machines have an ALU loop.
 CS 320 Ch 10 Computer Arithmetic The ALU consists of combinational logic. Processes all data in the CPU. ALL von Neuman machines have an ALU loop. Signed integers are typically represented in sign-magnitude
CS 320 Ch 10 Computer Arithmetic The ALU consists of combinational logic. Processes all data in the CPU. ALL von Neuman machines have an ALU loop. Signed integers are typically represented in sign-magnitude
Digital Logic & Computer Design CS Professor Dan Moldovan Spring 2010
 Digital Logic & Computer Design CS 434 Professor Dan Moldovan Spring 2 Copyright 27 Elsevier 5- Chapter 5 :: Digital Building Blocks Digital Design and Computer Architecture David Money Harris and Sarah
Digital Logic & Computer Design CS 434 Professor Dan Moldovan Spring 2 Copyright 27 Elsevier 5- Chapter 5 :: Digital Building Blocks Digital Design and Computer Architecture David Money Harris and Sarah
Decimal & Binary Representation Systems. Decimal & Binary Representation Systems
 Decimal & Binary Representation Systems Decimal & binary are positional representation systems each position has a value: d*base i for example: 321 10 = 3*10 2 + 2*10 1 + 1*10 0 for example: 101000001
Decimal & Binary Representation Systems Decimal & binary are positional representation systems each position has a value: d*base i for example: 321 10 = 3*10 2 + 2*10 1 + 1*10 0 for example: 101000001
Floating Point. CSE 351 Autumn Instructor: Justin Hsia
 Floating Point CSE 351 Autumn 2017 Instructor: Justin Hsia Teaching Assistants: Lucas Wotton Michael Zhang Parker DeWilde Ryan Wong Sam Gehman Sam Wolfson Savanna Yee Vinny Palaniappan Administrivia Lab
Floating Point CSE 351 Autumn 2017 Instructor: Justin Hsia Teaching Assistants: Lucas Wotton Michael Zhang Parker DeWilde Ryan Wong Sam Gehman Sam Wolfson Savanna Yee Vinny Palaniappan Administrivia Lab
Operations On Data CHAPTER 4. (Solutions to Odd-Numbered Problems) Review Questions
 Review Questions") CHAPTER 4 Operations On Data (Solutions to Odd-Numbered Problems) Review Questions 1. Arithmetic operations interpret bit patterns as numbers. Logical operations interpret each bit as a logical values
CHAPTER 4 Operations On Data (Solutions to Odd-Numbered Problems) Review Questions 1. Arithmetic operations interpret bit patterns as numbers. Logical operations interpret each bit as a logical values
Computer Science 324 Computer Architecture Mount Holyoke College Fall Topic Notes: Bits and Bytes and Numbers
 Computer Science 324 Computer Architecture Mount Holyoke College Fall 2007 Topic Notes: Bits and Bytes and Numbers Number Systems Much of this is review, given the 221 prerequisite Question: how high can
Computer Science 324 Computer Architecture Mount Holyoke College Fall 2007 Topic Notes: Bits and Bytes and Numbers Number Systems Much of this is review, given the 221 prerequisite Question: how high can
CPE 323 REVIEW DATA TYPES AND NUMBER REPRESENTATIONS IN MODERN COMPUTERS
 CPE 323 REVIEW DATA TYPES AND NUMBER REPRESENTATIONS IN MODERN COMPUTERS Aleksandar Milenković The LaCASA Laboratory, ECE Department, The University of Alabama in Huntsville Email: milenka@uah.edu Web:
CPE 323 REVIEW DATA TYPES AND NUMBER REPRESENTATIONS IN MODERN COMPUTERS Aleksandar Milenković The LaCASA Laboratory, ECE Department, The University of Alabama in Huntsville Email: milenka@uah.edu Web:
*Instruction Matters: Purdue Academic Course Transformation. Introduction to Digital System Design. Module 4 Arithmetic and Computer Logic Circuits
 Purdue IM:PACT* Fall 2018 Edition *Instruction Matters: Purdue Academic Course Transformation Introduction to Digital System Design Module 4 Arithmetic and Computer Logic Circuits Glossary of Common Terms
Purdue IM:PACT* Fall 2018 Edition *Instruction Matters: Purdue Academic Course Transformation Introduction to Digital System Design Module 4 Arithmetic and Computer Logic Circuits Glossary of Common Terms
CPE 323 REVIEW DATA TYPES AND NUMBER REPRESENTATIONS IN MODERN COMPUTERS
 CPE 323 REVIEW DATA TYPES AND NUMBER REPRESENTATIONS IN MODERN COMPUTERS Aleksandar Milenković The LaCASA Laboratory, ECE Department, The University of Alabama in Huntsville Email: milenka@uah.edu Web:
CPE 323 REVIEW DATA TYPES AND NUMBER REPRESENTATIONS IN MODERN COMPUTERS Aleksandar Milenković The LaCASA Laboratory, ECE Department, The University of Alabama in Huntsville Email: milenka@uah.edu Web:
Fundamentals of Computer Systems
 Fundamentals of Computer Systems Combinational Logic Stephen. Edwards Columbia University Summer 7 Combinational Circuits Combinational circuits are stateless. Their output is a function only of the current
Fundamentals of Computer Systems Combinational Logic Stephen. Edwards Columbia University Summer 7 Combinational Circuits Combinational circuits are stateless. Their output is a function only of the current
COSC 243. Data Representation 3. Lecture 3 - Data Representation 3 1. COSC 243 (Computer Architecture)
") COSC 243 Data Representation 3 Lecture 3 - Data Representation 3 1 Data Representation Test Material Lectures 1, 2, and 3 Tutorials 1b, 2a, and 2b During Tutorial a Next Week 12 th and 13 th March If you
COSC 243 Data Representation 3 Lecture 3 - Data Representation 3 1 Data Representation Test Material Lectures 1, 2, and 3 Tutorials 1b, 2a, and 2b During Tutorial a Next Week 12 th and 13 th March If you
Digital Circuit Design and Language. Datapath Design. Chang, Ik Joon Kyunghee University
 Digital Circuit Design and Language Datapath Design Chang, Ik Joon Kyunghee University Typical Synchronous Design + Control Section : Finite State Machine + Data Section: Adder, Multiplier, Shift Register
Digital Circuit Design and Language Datapath Design Chang, Ik Joon Kyunghee University Typical Synchronous Design + Control Section : Finite State Machine + Data Section: Adder, Multiplier, Shift Register
EE878 Special Topics in VLSI. Computer Arithmetic for Digital Signal Processing
 EE878 Special Topics in VLSI Computer Arithmetic for Digital Signal Processing Part 6c High-Speed Multiplication - III Spring 2017 Koren Part.6c.1 Array Multipliers The two basic operations - generation
EE878 Special Topics in VLSI Computer Arithmetic for Digital Signal Processing Part 6c High-Speed Multiplication - III Spring 2017 Koren Part.6c.1 Array Multipliers The two basic operations - generation
Signed integers: 2 s complement. Adder: a circuit that does addition. Sign extension 42 = = Arithmetic Circuits & Multipliers
 Signed integers: 2 s complement N bits -2 N- 2 N-2 2 3 2 2 2 2 Arithmetic Circuits & Multipliers Addition, subtraction Performance issues -- ripple carry -- carry bypass -- carry skip -- carry lookahead
Signed integers: 2 s complement N bits -2 N- 2 N-2 2 3 2 2 2 2 Arithmetic Circuits & Multipliers Addition, subtraction Performance issues -- ripple carry -- carry bypass -- carry skip -- carry lookahead
Floating Point. CSE 351 Autumn Instructor: Justin Hsia
 Floating Point CSE 351 Autumn 2016 Instructor: Justin Hsia Teaching Assistants: Chris Ma Hunter Zahn John Kaltenbach Kevin Bi Sachin Mehta Suraj Bhat Thomas Neuman Waylon Huang Xi Liu Yufang Sun http://xkcd.com/899/
Floating Point CSE 351 Autumn 2016 Instructor: Justin Hsia Teaching Assistants: Chris Ma Hunter Zahn John Kaltenbach Kevin Bi Sachin Mehta Suraj Bhat Thomas Neuman Waylon Huang Xi Liu Yufang Sun http://xkcd.com/899/
CS/COE 0447 Example Problems for Exam 2 Spring 2011
 CS/COE 0447 Example Problems for Exam 2 Spring 2011 1) Show the steps to multiply the 4-bit numbers 3 and 5 with the fast shift-add multipler. Use the table below. List the multiplicand (M) and product
CS/COE 0447 Example Problems for Exam 2 Spring 2011 1) Show the steps to multiply the 4-bit numbers 3 and 5 with the fast shift-add multipler. Use the table below. List the multiplicand (M) and product
EECS150 - Digital Design Lecture 13 - Combinational Logic & Arithmetic Circuits Part 3
 EECS15 - Digital Design Lecture 13 - Combinational Logic & Arithmetic Circuits Part 3 October 8, 22 John Wawrzynek Fall 22 EECS15 - Lec13-cla3 Page 1 Multiplication a 3 a 2 a 1 a Multiplicand b 3 b 2 b
EECS15 - Digital Design Lecture 13 - Combinational Logic & Arithmetic Circuits Part 3 October 8, 22 John Wawrzynek Fall 22 EECS15 - Lec13-cla3 Page 1 Multiplication a 3 a 2 a 1 a Multiplicand b 3 b 2 b
EC2303-COMPUTER ARCHITECTURE AND ORGANIZATION
 EC2303-COMPUTER ARCHITECTURE AND ORGANIZATION QUESTION BANK UNIT-II 1. What are the disadvantages in using a ripple carry adder? (NOV/DEC 2006) The main disadvantage using ripple carry adder is time delay.
EC2303-COMPUTER ARCHITECTURE AND ORGANIZATION QUESTION BANK UNIT-II 1. What are the disadvantages in using a ripple carry adder? (NOV/DEC 2006) The main disadvantage using ripple carry adder is time delay.