Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
|
|
|
- Leslie Chambers
- 6 years ago
- Views:
Transcription


1 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620


2 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved concurrently Each part is broken down to a series of instructions Instructions from each part execute simultaneously on different processors An overall control/coordination mechanism is employed
3 Overview: What is Parallel Computing The computational problem should be able to Be broken apart into discrete pieces of work that can be solved simultaneously Execute multiple program instructions at any moment in time Be solved in less time with multiple compute resources than with a single compute resource The compute resources might be A single computer with multiple processors An arbitrary number of computers connected by a network A combination of both A special computational component inside a single computer, separate from the main processors (GPU)
4 Measuring of speed FLOPS floating-point operations per second MFLOPS GFLOPS TFLOPS PFLOPS
5 The Demand for Computation Speed Suppose whole global atmosphere divided into cells of size 1 mile 1 mile 1 mile to a height of 10 miles (10 cells high) about cells. Suppose you want to predict the global weather for a week If each calculation requires 200 floating point operations (low estimate, can be as high as 4000), floating point operations necessary in one time step.
6 The Demand for Computation Speed To forecast one scenario of the weather for one week using 1-minute intervals, we need 60 (min/hr) * 24 (hr/day) * 7 (day) = 10,080 (~ 10 time steps) The week-long forecast would require operations Modern weather prediction use multi-model ensemble forecasting, which calculate numerous different scenarios with different probabilities and provide an estimated forecast
7 The Demand for Computation Speed Maximum number of floating point operations per clock tick for x86_64 CPU architecture is 4 A single-core CPU with 2.5Ghz clock speed will have: Single core simulation: !"#
8 The Demand for Computation Speed To do this within five minutes: $ 3.4 PS4: theoretical peak performance of 1.84 (TFLOPS) using 8 cores

9 Who is using parallel computing?
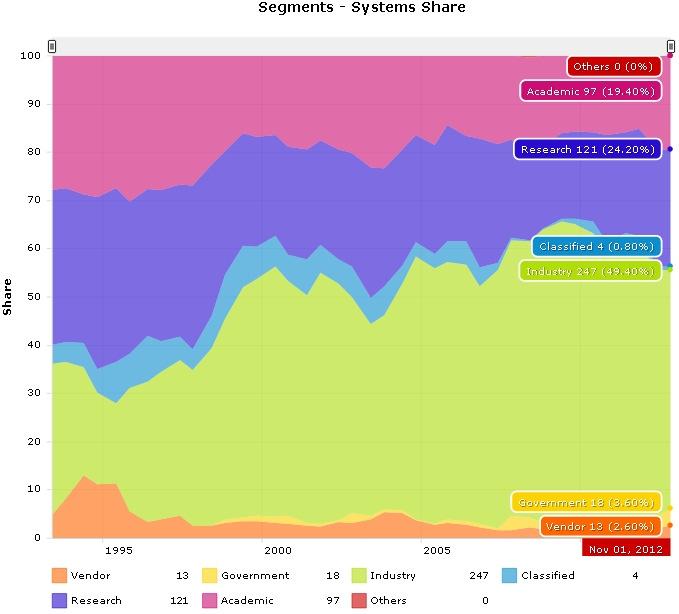
10
11 Parallel Speedup Speedup factor: with p is the number of processors: %"& '%&" (! %"& ")" (! * + Ideally: + * * * Super-linear speed up: / &")!% (1) Poor sequential reference implementation (2) Memory caching (3) I/O Blocking
12 Parallel Efficiency Efficiency 7 * + 100% Limiting factors: (1) non-parallelizable code (2) repetition (3) communication overhead
13 Amdahl s Law Theoretical max: Let f be the fraction of the program that is notparallelizable. Assuming no communication overhead, the parallel simulation time is: + * N 1O * Replacing this result in the speedup equation: * * N 1O * N1O O1 N1 This is known as Amdahl s Law
14 Types of Parallel Computers Flynn s Taxonomy Single Instruction, Single Data Stream SIMD Single Instruction, Multiple Data Streams SIMD Multiple Instructions, Single Data Stream MISD Multiple Instruction, Multiple Data Streams MIMD

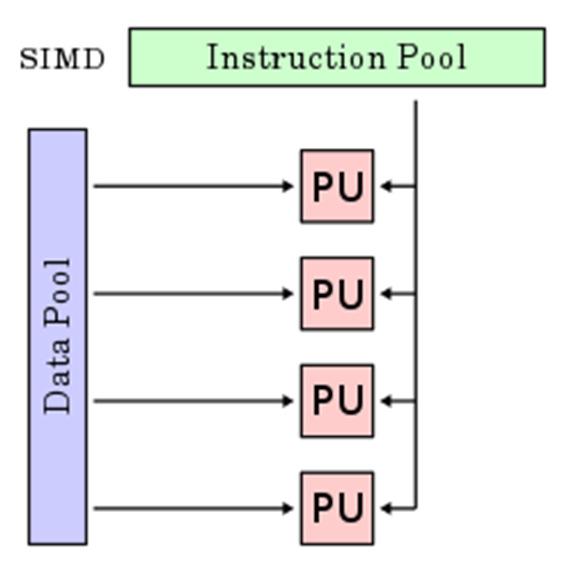
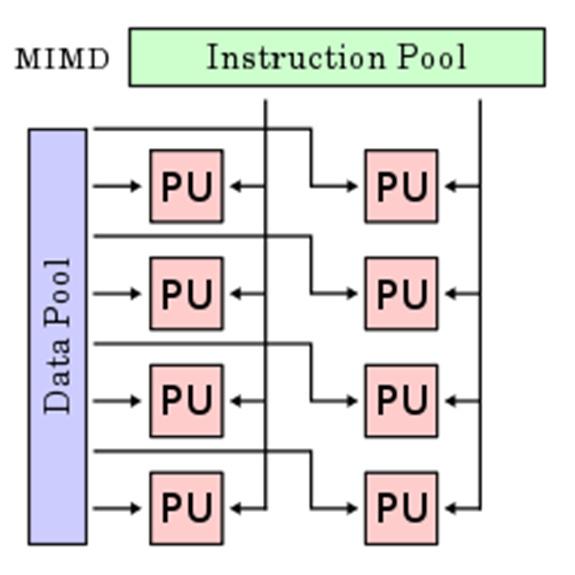
15 Types of Parallel Computers
16 Types of Parallel Computers Streaming SIMD extensions for x86 architecture Shared Memory Distributed Shared Memory Heterogeneous Computing Accelerators Message Passing

17 Streaming SIMD Intel s SSE AMD s 3DNow
 OpenMP: Compiler extensions handle parallelization through in-code markers (3) Vendor libraries (e.g. Intel math kernel libraries)")
18 Shared Memory One processor, multiple threads All threads have read/write access to the same memory Programming models: (1) Threads (pthread) programmer manages all parallelism (2) OpenMP: Compiler extensions handle parallelization through in-code markers (3) Vendor libraries (e.g. Intel math kernel libraries)
19 Heterogeneous Computing (Accelerators) Cell (PS3 processor) Developed for PS3 Used in the world s first supercomputer to reach 1PFLOPS Difficult to program FPGA (field programmable gate array) Dynamically reconfigurable circuit board Expensive, difficult to program Power efficient, low heat
20 Heterogeneous Computing (Accelerators) GPU (Graphic Processing Units) Processor unit on graphic cards designed to support graphic rendering (numerical manipulation) Significant advantage for certain classes of scientific problem Programming Models: CUDA Library developed by NVIDIA for their GPUs OpenACC Standard devides by NVIDIA, Cray, and Portal Compiler (PGI). Similar to OpenMP in the usage of in-code marker to specify portions to be accelerated OpenAMP Extensions to Visual C++ (Microsoft) to direct computation to GPU OpenCL Set of standards by the group behind OpenGL
 MapReduce programming mode")
21 Message Passing Processes handle their own memory, data is passed between processes via messages. Scales well Commodity parts Expandable Heterogenous Programming Models: MPI: standardized message passing library MPI + OpenMP (hybrid model) MapReduce programming mode Specialized languages (not gaining traction in scientific computing community)
22 Benchmarking LINPACK (Linear Algebra Package) Dense Matrix Solver HPCC High-Performance Computing Challenge HPL (LINPACK to solve linear system of equation) DGEMM (Double Precision General Matric Multiply) STREAM (Memory bandwidth) PTRANS (Parallel Matrix Transpose to measure processors communication) RandomAccess (Random memory updates) FFT (double precision complex discrete fourier transform) Communication bandwidth and latency
23 Benchmarking SHOC Scalable Heterogeneous Computing Benchmark non-traditional systems (GPUs) TestDFSIO Benchmark I/O performance of MapReduce/HDFS
24 Ranking TOP500 Rank the supercomputers based on their LINPACK score GREEN500 Rank the supercomputers with emphasis on energy usage (LINPACK score / power consumption) GRAPH500 Benchmark for data-intensive computing
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
A General Discussion on! Parallelism!
 Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
BİL 542 Parallel Computing
 BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Parallel computer architecture classification
 Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 1. Copyright 2012, Elsevier Inc. All rights reserved. Computer Technology
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
EECS4201 Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Computing on GPUs. Prof. Dr. Uli Göhner. DYNAmore GmbH. Stuttgart, Germany
 Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Parallel Programming Programowanie równoległe
 Parallel Programming Programowanie równoległe Lecture 1: Introduction. Basic notions of parallel processing Paweł Rzążewski Grading laboratories (4 tasks, each for 3-4 weeks) total 50 points, final test
Parallel Programming Programowanie równoległe Lecture 1: Introduction. Basic notions of parallel processing Paweł Rzążewski Grading laboratories (4 tasks, each for 3-4 weeks) total 50 points, final test
Thinking Outside of the Tera-Scale Box. Piotr Luszczek
 Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Introduction to Parallel Programming and Computing for Computational Sciences. By Justin McKennon
 Introduction to Parallel Programming and Computing for Computational Sciences By Justin McKennon History of Serialized Computing Until recently, software and programs have been explicitly designed to run
Introduction to Parallel Programming and Computing for Computational Sciences By Justin McKennon History of Serialized Computing Until recently, software and programs have been explicitly designed to run
Overview of High Performance Computing
 Overview of High Performance Computing Timothy H. Kaiser, PH.D. tkaiser@mines.edu http://inside.mines.edu/~tkaiser/csci580fall13/ 1 Near Term Overview HPC computing in a nutshell? Basic MPI - run an example
Overview of High Performance Computing Timothy H. Kaiser, PH.D. tkaiser@mines.edu http://inside.mines.edu/~tkaiser/csci580fall13/ 1 Near Term Overview HPC computing in a nutshell? Basic MPI - run an example
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
BlueGene/L (No. 4 in the Latest Top500 List)
") BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
BlueGene/L (No. 4 in the Latest Top500 List) first supercomputer in the Blue Gene project architecture. Individual PowerPC 440 processors at 700Mhz Two processors reside in a single chip. Two chips reside
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
CSC2/458 Parallel and Distributed Systems Machines and Models
 CSC2/458 Parallel and Distributed Systems Machines and Models Sreepathi Pai January 23, 2018 URCS Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics Outline Recap Scalability Taxonomy
CSC2/458 Parallel and Distributed Systems Machines and Models Sreepathi Pai January 23, 2018 URCS Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics Outline Recap Scalability Taxonomy
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Review of previous examinations TMA4280 Introduction to Supercomputing
 Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
An Introduction to Parallel Programming
 Dipartimento di Informatica e Sistemistica University of Pavia Processor Architectures, Fall 2011 Denition Motivation Taxonomy What is parallel programming? Parallel computing is the simultaneous use of
Dipartimento di Informatica e Sistemistica University of Pavia Processor Architectures, Fall 2011 Denition Motivation Taxonomy What is parallel programming? Parallel computing is the simultaneous use of
Introduction to Parallel Programming
 Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Parallel Numerics, WT 2013/ Introduction
 Parallel Numerics, WT 2013/2014 1 Introduction page 1 of 122 Scope Revise standard numerical methods considering parallel computations! Required knowledge Numerics Parallel Programming Graphs Literature
Parallel Numerics, WT 2013/2014 1 Introduction page 1 of 122 Scope Revise standard numerical methods considering parallel computations! Required knowledge Numerics Parallel Programming Graphs Literature
Advanced Scientific Computing
 Advanced Scientific Computing Fall 2010 H. Zhang CS595 Overview, Page 1 Topics Fundamentals: Parallel computers (application oriented view) Parallel and distributed numerical computation MPI: message-passing
Advanced Scientific Computing Fall 2010 H. Zhang CS595 Overview, Page 1 Topics Fundamentals: Parallel computers (application oriented view) Parallel and distributed numerical computation MPI: message-passing
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Measuring Performance. Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks
 Measuring Performance Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks Why Measure Performance? Performance tells you how you are doing and whether things can be improved appreciably When
Measuring Performance Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks Why Measure Performance? Performance tells you how you are doing and whether things can be improved appreciably When
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Course web site: teaching/courses/car. Piazza discussion forum:
 Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
CSL 860: Modern Parallel
 CSL 860: Modern Parallel Computation Course Information www.cse.iitd.ac.in/~subodh/courses/csl860 Grading: Quizes25 Lab Exercise 17 + 8 Project35 (25% design, 25% presentations, 50% Demo) Final Exam 25
CSL 860: Modern Parallel Computation Course Information www.cse.iitd.ac.in/~subodh/courses/csl860 Grading: Quizes25 Lab Exercise 17 + 8 Project35 (25% design, 25% presentations, 50% Demo) Final Exam 25
A General Discussion on! Parallelism!
 Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware!! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy
Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware!! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing. Introduction to Parallel Computing
 High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
Test on Wednesday! Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs)
") Test on Wednesday! 50 minutes Closed notes, closed computer, closed everything Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs) Study notes and readings posted on course
Test on Wednesday! 50 minutes Closed notes, closed computer, closed everything Material covered since Monday, Feb 8 (no Linux, Git, C, MD, or compiling programs) Study notes and readings posted on course
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Duksu Kim. Professional Experience Senior researcher, KISTI High performance visualization
 Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Parallel and High Performance Computing CSE 745
 Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Top500 Supercomputer list
 Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Top500 Supercomputer list Tends to represent parallel computers, so distributed systems such as SETI@Home are neglected. Does not consider storage or I/O issues Both custom designed machines and commodity
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
Computer Comparisons Using HPCC. Nathan Wichmann Benchmark Engineer
 Computer Comparisons Using HPCC Nathan Wichmann Benchmark Engineer Outline Comparisons using HPCC HPCC test used Methods used to compare machines using HPCC Normalize scores Weighted averages Comparing
Computer Comparisons Using HPCC Nathan Wichmann Benchmark Engineer Outline Comparisons using HPCC HPCC test used Methods used to compare machines using HPCC Normalize scores Weighted averages Comparing
High Performance Computing Systems
 High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
High Performance Computing Systems Shared Memory Doug Shook Shared Memory Bottlenecks Trips to memory Cache coherence 2 Why Multicore? Shared memory systems used to be purely the domain of HPC... What
HPCC Results. Nathan Wichmann Benchmark Engineer
 HPCC Results Nathan Wichmann Benchmark Engineer Outline What is HPCC? Results Comparing current machines Conclusions May 04 2 HPCChallenge Project Goals To examine the performance of HPC architectures
HPCC Results Nathan Wichmann Benchmark Engineer Outline What is HPCC? Results Comparing current machines Conclusions May 04 2 HPCChallenge Project Goals To examine the performance of HPC architectures
Unit 9 : Fundamentals of Parallel Processing
 Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Why Multiprocessors?
 Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Lecture 1: Gentle Introduction to GPUs
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 1: Gentle Introduction to GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Who Am I? Mohamed
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Benchmark Results. 2006/10/03
 Benchmark Results cychou@nchc.org.tw 2006/10/03 Outline Motivation HPC Challenge Benchmark Suite Software Installation guide Fine Tune Results Analysis Summary 2 Motivation Evaluate, Compare, Characterize
Benchmark Results cychou@nchc.org.tw 2006/10/03 Outline Motivation HPC Challenge Benchmark Suite Software Installation guide Fine Tune Results Analysis Summary 2 Motivation Evaluate, Compare, Characterize
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Parallel computing and GPU introduction
 國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
LACORE: A RISC-V BASED LINEAR ALGEBRA ACCELERATOR FOR SOC DESIGNS
 1 LACORE: A RISC-V BASED LINEAR ALGEBRA ACCELERATOR FOR SOC DESIGNS Samuel Steffl and Sherief Reda Brown University, Department of Computer Engineering Partially funded by NSF grant 1438958 Published as
1 LACORE: A RISC-V BASED LINEAR ALGEBRA ACCELERATOR FOR SOC DESIGNS Samuel Steffl and Sherief Reda Brown University, Department of Computer Engineering Partially funded by NSF grant 1438958 Published as
3/24/2014 BIT 325 PARALLEL PROCESSING ASSESSMENT. Lecture Notes:
 BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow.
 Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Performance of computer systems
 Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
PIPELINE AND VECTOR PROCESSING
 PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
PIPELINE AND VECTOR PROCESSING PIPELINING: Pipelining is a technique of decomposing a sequential process into sub operations, with each sub process being executed in a special dedicated segment that operates
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Commodity Cluster Computing
 Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
Introduction. CSCI 4850/5850 High-Performance Computing Spring 2018
 Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
CS650 Computer Architecture. Lecture 10 Introduction to Multiprocessors and PC Clustering
 CS650 Computer Architecture Lecture 10 Introduction to Multiprocessors and PC Clustering Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 10: Intro to Multiprocessors/Clustering
CS650 Computer Architecture Lecture 10 Introduction to Multiprocessors and PC Clustering Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 10: Intro to Multiprocessors/Clustering
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs