Paul Burton April 2015 An Introduction to MPI Programming
|
|
|
- Kelly Blankenship
- 5 years ago
- Views:
Transcription
1 Paul Burton April 2015
2 Topics Introduction Initialising MPI & basic concepts Compiling and running a parallel program on the Cray Practical : Hello World MPI program Synchronisation Practical Data types and tags Basic sends and receives Practical Collective communications Reduction Operations MPI References
3 Introduction ( 1 of 4 ) Message Passing evolved in the late 1980 s Cray was dominate in supercomputing - with very expensive shared-memory vector processors Many companies tried new approaches to HPC Workstation and PC Technology was spreading rapidly The Attack of the Killer Micros Message Passing was a way to link them together - many different flavours PVM, PARMACS, CHIMP, OCCAM Cray recognised the need to change - switched to MPP using cheap DEC Alpha microprocessors (T3D/T3E) But application developers needed portable software
4 Introduction ( 2 of 4 ) Message Passing Interface (MPI) - The MPI Forum was a combination of end users and vendors (1992) - defined a standard set of library calls in Portable across different computer platforms - Fortran and C Interfaces Used by multiple tasks to send and receive data - Working together to solve a problem - Data is decomposed (split) into multiple parts - Each task handles a separate part on its own processor - Message passing to resolve data dependencies Works within a node and across Distributed Memory Nodes Can scale to thousands of processors - Subject to constraints of Amdahl s Law
5 Introduction ( 3 of 4 ) The MPI standard is large - Well over 100 routines in MPI version 1 - Result of trying to cater for many different flavours of message passing and a diverse range of computer architectures - And an additional 100+ in MPI version 2 (1997) Many sophisticated features - Designed for both homogenous and heterogeneous environments But most people only use a small subset - IFS was initially parallelised using Parmacs - This was replaced by about 10 MPI routines Hidden within MPL library
6 Introduction ( 4 of 4 ) This course will look at just a few basic routines - Fortran Interface Only - MPI version SPMD (Single Program Multiple Data) - As used at ECMWF in IFS A mass of useful material on the Web - Google is your friend!
7 SPMD The SPMD model is by far the most common - Single Program Multiple Data - One program executes multiple times simultaneously - The problem is divided across the multiple copies - Each work on a subset of the data MPMD - Multi Program Multiple Data - Different executable on different processors - Useful for coupled models for example - Part of the MPI 2 standard - Not currently used by IFS - Can be mimicked in SPMD mode Top level branch deciding which program (subroutine) this task will run
8 Some definitions Task - one running instance (copy) of a program - Equivalent to a UNIX process - Basic unit of an MPI parallel execution - May run on one processor Master Or across many if OpenMP is used as well Or many tasks on one processor (not a good idea!) - the master task is the first task in a parallel program : TaskID=0 Slave - all other tasks in a parallel program - Nothing intrinsically different between master/slave but the parallel program may treat them differently
9 The simplest MPI program... Lets start with hello world Introduces - 4 essential housekeeping routines - the use mpi statement - the concept of Communicators program hello implicit none print *,"Hello world" end
10 Hello World with MPI program hello implicit none use mpi integer:: ierror,ntasks,mytask call MPI_INIT(ierror) call MPI_COMM_SIZE(MPI_COMM_WORLD, ntasks, ierror) call MPI_COMM_RANK(MPI_COMM_WORLD, mytask, ierror) print *,"Hello world from task ",mytask," of ",ntasks call MPI_FINALIZE(ierror) end
11 use mpi : The MPI header file use mpi The MPI header file Always include in any routine calling an MPI function Contains declarations for constants used by MPI May contain interface blocks, so compiler will tell you if you make an obvious error in arguments to MPI library - This is not mandated by the standard so you shouldn t rely on it. You may want to test Cray s mpi to see if it does! In Fortran77 use include mpif.h instead
12 Hello World with MPI program hello implicit none use mpi integer:: ierror,ntasks,mytask call MPI_INIT(ierror) call MPI_COMM_SIZE(MPI_COMM_WORLD, ntasks, ierror) call MPI_COMM_RANK(MPI_COMM_WORLD, mytask, ierror) print *,"Hello world from task ",mytask," of ",ntasks call MPI_FINALIZE(ierror) end
13 MPI_INIT integer:: ierror call MPI_INIT(ierror) Initializes the MPI environment Expect a return code of zero for ierror - If an error occurs the MPI layer will normally abort the job - best practise would check for non zero codes - we will ignore for clarity but see later slides for MPI_ABORT On the Cray all tasks execute the code before MPI_INIT - this is an implementation dependent feature - try not to do anything that alters the state of the system before this, eg. I/O
14 Hello World with MPI program hello implicit none use mpi integer:: ierror,ntasks,mytask call MPI_INIT(ierror) call MPI_COMM_SIZE(MPI_COMM_WORLD, ntasks, ierror) call MPI_COMM_RANK(MPI_COMM_WORLD, mytask, ierror) print *,"Hello world from task ",mytask," of ",ntasks call MPI_FINALIZE(ierror) end
15 MPI_COMM_WORLD An MPI communicator Constant integer value from use mpi Communicators define sets or groups of tasks - dividing programs into subsets of tasks often not necessary - IFS also creates and uses some additional communicators useful when doing collective communications Useful if you want to dedicate a subset of tasks to a special job (eg. I/O server) - advanced topic MPI_COMM_WORLD means all tasks - many MPI programs only use MPI_COMM_WORLD - All our examples only use MPI_COMM_WORLD
16 Hello World with MPI program hello implicit none use mpi integer:: ierror,ntasks,mytask call MPI_INIT(ierror) call MPI_COMM_SIZE(MPI_COMM_WORLD, ntasks, ierror) call MPI_COMM_RANK(MPI_COMM_WORLD, mytask, ierror) print *,"Hello world from task ",mytask," of ",ntasks call MPI_FINALIZE(ierror) end
17 MPI_COMM_SIZE integer:: ierror,ntasks call MPI_COMM_SIZE(MPI_COMM_WORLD, ntasks, ierror) Returns the number of parallel tasks in the variable ntasks - the number of tasks is defined from the aprun command which starts the parallel executable Value can be used to help decompose the problem - in conjunction with Fortran allocatable/automatic arrays - avoid the need to recompile for different processor numbers
18 Hello World with MPI program hello implicit none use mpi integer:: ierror,ntasks,mytask call MPI_INIT(ierror) call MPI_COMM_SIZE(MPI_COMM_WORLD, ntasks, ierror) call MPI_COMM_RANK(MPI_COMM_WORLD, mytask, ierror) print *,"Hello world from task ",mytask," of ",ntasks call MPI_FINALIZE(ierror) end
19 MPI_COMM_RANK integer:: ierror, mytask call MPI_COMM_RANK(MPI_COMM_WORLD, mytask, ierror) Returns the rank of the task in mytask - In the range 0 to ntasks-1 Easy to make mistakes with this as Fortran arrays normally run 1:n - Used as a task identifier when sending/receiving messages
20 Hello World with MPI program hello implicit none use mpi integer:: ierror,ntasks,mytask call MPI_INIT(ierror) call MPI_COMM_SIZE(MPI_COMM_WORLD, ntasks, ierror) call MPI_COMM_RANK(MPI_COMM_WORLD, mytask, ierror) print *,"Hello world from task ",mytask," of ",ntasks call MPI_FINALIZE(ierror) end
21 MPI_FINALIZE integer:: ierror call MPI_FINALIZE(ierror) Tell the MPI layer that we have finished Any MPI call after this is an error - Like MPI_INIT, the MPI standard does not mandate what happens after an MPI_FINALIZE cannot guarantee that all tasks still execute after this point Does not stop the program at least one (probably all!) tasks will continue to run
22 MPI_ABORT integer:: ierror call MPI_ABORT(MPI_COMM_WORLD,ierror) Causes all tasks to abort Even if only one task makes call
23 PBSPro and MPI Many varied ways of defining your requirements For the exercises we ll keep it as simple as possible - Create an interactive shell in which you can run parallel jobs in up to one node (48 hyperthreaded CPUs) - You won t need to wait every time you run an executable! - Don t forget to log out when you re finished! - Not recommended for regular use! $ ssh cca # or ccb queue np one node $ qsub -q np -I -l EC_nodes=1 l EC_hyperthreads=2 interactive Use hyperthreading
24 Compiling an MPI Program Very easy using modules - Automatically adds all the flags/libraries required for MPI $ module load PrgEnv-cray # Use Cray compilers $ module load PrgEnv-intel # Use Intel compilers $ module load PrgEnv-gnu # Use Gnu compilers ---- or or $ ftn hello.f90 # produces a.out or and $ ftn -c hello.f90 # produces hello.o $ ftn hello.o -o hello.exe # produces hello.exe
25 Running an MPI Program aprun - Details and many options covered in other lectures - Here we will use a very simple form - Run from the MOM node, launches the parallel executable on the parallel (ESM) node(s) $ aprun n 4 <executable>
26 First Practical Copy all the practical exercises to your account on cca or ccb: - cd $HOME - mkdir mpi_course ; cd mpi_course - cp r ~trx/mpi.2015/*. Exercise1a - Run your own Hello World program with MPI See the README for details
27 MPI_BARRIER integer:: ierror call MPI_BARRIER(MPI_COMM_WORLD,ierror) Forces all tasks (in a communicator group) to synchronise - for timing points - to improve output of prints can be used to force ordering of events - to separate different communications phases A task waits in the barrier until all tasks reach it Then every task completes the call together Deadlock if one task does not reach the barrier - MPI_BARRIER will wait until the task reaches its cpu limit
28 MPI_BARRIER P0 P1 P2 P3
29 MPI_BARRIER P0 P1 P2 P3 P0 P1 P2 P3 IDRIS-CNRS
30 MPI_BARRIER P0 P1 P2 P3 P0 P1 P2 P3 P0 P1 P2 P3 IDRIS-CNRS
31 Second Practical Forcing the ordering of output Exercise 1b see the README file for more details
32 Basic Sends and Receives MPI_SEND - sends a message from one task to another MPI_RECV - receives a message from another task A message is just data with some form of identification - think of it as an some information and some headers To: Where the message should be sent to Subject: Some description of the contents (in MPI, a tag ) Body: The data itself (can be any size), various Fortran types You program the logic to send and receive messages - the sender and receiver are working together - every send must have a corresponding receive
33 MPI Datatypes MPI can send variables of any Fortran type - integer, real, real*8, logical,... - it needs to know the type There are predefined constants used to identify types - MPI_INTEGER, MPI_REAL, MPI_REAL8, MPI_LOGICAL... - Defined by use mpi Also user defined data types - MPI allows you create types created out of basic Fortran types (rather like a Fortran 90 structure) - Allows strided (non contiguous) data to be communicated - advanced topic
34 MPI Tags All messages are given an integer TAG value - standard says maximum value is at least (2^31) - CALL MPI_Comm_get_attr (MPI_COMM_WORLD,MPI_TAG_UB, maxtag, flag, error) This helps to identify a message (like an s subject ) Particularly useful when sending multiple messages You decide what tag values to use - Good ideas to use separate ranges of tags eg: 1000, 1001, in routine a 2000, 2001, in routine b
35 MPI_SEND FORTRAN_TYPE:: sbuf integer:: count, dest, tag, ierror call MPI_SEND( sbuf, count, MPI_TYPE, dest, tag, & MPI_COMM_WORLD, ierror) SBUF the array being sent input COUNT the number of elements to send input MPI_TYPE type of SBUF eg MPI_REAL input DEST the task id of the receiver input TAG the message identifier input
36 MPI_RECV FORTRAN_TYPE:: rbuf integer:: count, source, tag, status(mpi_status_size),ierror call MPI_RECV( rbuf, count, MPI_TYPE, source, tag, & MPI_COMM_WORLD, status, ierror) RBUF the array being received output COUNT the length of RBUF input MPI_TYPE type of RBUF eg MPI_REAL input SOURCE the task id of the sender input TAG the message identifier input STATUS information about the message output
37 More on MPI_RECV MPI_RECV will block (wait) until the message arrives - if message never sent then deadlock task will wait until it reaches cpu time limit, and then dies Order in which messages are received - For a given pair of processors using the same communicator, the MPI standard guarantees the messages will be received in the same order they were sent This means you need to be careful - If you are receiving multiple messages from the same task, you MUST do the MPI_RECVs in the same order as the MPI_SENDs - Otherwise the first MPI_RECV will wait forever, and eventually die - What happens if you don t know the ordering of the MPI_SENDs?
38 How to be less specific on MPI_RECV The source and tag can be more open - MPI_ANY_SOURCE means receive from any sender - MPI_ANY_TAG means receive any tag - Useful in more complex communication patterns - Used to receive messages in a more random order - helps smooth out load imbalance - May require over-allocation of receive buffer But how do we know what message we ve received? - status(mpi_source) will contain the actual sender - status(mpi_tag) will contain the actual tag 38
39 A simple example subroutine transfer(values,len,mytask) implicit none use mpi integer:: mytask,len,source,dest,tag,ierror,status(mpi_status_size) real:: values(len) tag = if(mytask.eq.0) then dest = 1 call MPI_SEND(values,len,MPI_REAL,dest,tag,MPI_COMM_WORLD,ierror) elseif(mytask.eq.1) then source = 0 call MPI_RECV(values,len,MPI_REAL,source,tag,MPI_COMM_WORLD,status,ierror) endif end
40 Third Practical Sending and receiving a message Exercise 1c see the README file for more details
41 Collective Communications (1) SEND/RECV is pairwise communication Often we want to do more complex communication patterns For example - Send the same message from one task to many other tasks - Receive messages from many tasks onto many other tasks We could write this with MPI_SEND & MPI_RECV - How? - Why not?
42 Collective Communications MPI contains Collective Communications routines - called by all tasks (in a comminicator group) together - replace multiple send/recv calls - easier to code and understand - can be more efficient - the MPI library may optimise the data transfers We will look at MPI_BCAST and MPI_GATHER Other routines will be summarised The diagrams are schematic - Help to conceptualise the data movement - The MPI library and machine hardware may actually be doing a more complex (and hopefully efficient!) communication pattern IFS uses a few collective routines, sometimes we hand code our own
43 MPI_BCAST FORTRAN_TYPE:: buff integer:: count, root, ierror call MPI_BCAST( buff,count,mpi_type,root,mpi_comm_world,ierror) ROOT task doing broadcast input BUFF array being broadcast input/output COUNT the number of elements input MPI_TYPE the kind of variable input The contents of buff are sent from task id root to all other tasks. Equivalent to putting MPI_SEND in a loop and matching MPI_RECVs
44 MPI_BCAST IDRIS-CNRS
45 MPI_BCAST IDRIS-CNRS
46 MPI_BCAST IDRIS-CNRS
47 MPI_BCAST IDRIS-CNRS
48 MPI_BCAST IDRIS-CNRS
49 MPI_GATHER FORTRAN_TYPE:: sbuff, rbuff integer:: count, root, ierror call MPI_GATHER( sbuff,scount,mpi_type, & rbuff,rcount,mpi_type,root,mpi_comm_world,ierror) ROOT task doing gather input SBUFF array being sent input RBUFF array being received output [S/R]COUNT number of items to/from input each task The contents of sbuff are sent from every task to task id root and received (concatenated in rank order) in array rbuff. Could also be done by putting MPI_RECV in a loop.

50 MPI_GATHER IDRIS-CNRS
51 MPI_GATHER IDRIS-CNRS
52 MPI_GATHER IDRIS-CNRS
53 MPI_GATHER IDRIS-CNRS
54 MPI_GATHER IDRIS-CNRS
55 Gather Routines MPI_ALLGATHER - gather arrays of equal length into one array on all tasks - Simpler and more efficient than doing MPI_GATHER followed by MPI_BCAST MPI_GATHERV - gather arrays of different lengths into one array on one task MPI_ALLGATHERV - gather arrays of different lengths into one array on all tasks Where do you think these may be useful?

56 MPI_ALLGATHER IDRIS-CNRS
57 MPI_ALLGATHER IDRIS-CNRS
58 MPI_ALLGATHER IDRIS-CNRS
59 MPI_ALLGATHER IDRIS-CNRS
60 MPI_ALLGATHER IDRIS-CNRS
61 Scatter Routines MPI_SCATTER - divide one array on one task equally amongst all tasks - each task receives the same amount of data MPI_SCATTERV - divide one array on one task unequally amongst all tasks - each task can receive a different amount of data Where do you think they might be useful?
62 MPI_SCATTER FORTRAN_TYPE:: sbuff, rbuff integer:: count, root, ierror call MPI_SCATTER( sbuff,scount,mpi_type, & rbuff,rcount,mpi_type,root,mpi_comm_world,ierror) ROOT task doing scatter input SBUFF array being sent input RBUFF array being received output [S/R]COUNT number of items to/from input each task The contents of sbuff on task id root are equally split and each task receives its part in array rbuff. Could also be done by putting MPI_SEND in a loop.
63 MPI_SCATTER IDRIS-CNRS
64 MPI_SCATTER IDRIS-CNRS
65 MPI_SCATTER IDRIS-CNRS
66 MPI_SCATTER IDRIS-CNRS
67 MPI_SCATTER IDRIS-CNRS
68 All to All Routines MPI_ALLTOALL - every task sends equal length parts of an array to all other tasks - every task receives equal parts from all other tasks - transpose of data over the tasks MPI_ALLTOALLV - as above but parts are different lengths
69 MPI_ALLTOALL FORTRAN_TYPE:: sbuff, rbuff integer:: count, root, ierror call MPI_SCATTER( sbuff,scount,mpi_type, & rbuff,rcount,mpi_type,mpi_comm_world,ierror) SBUFF array being sent input RBUFF array being received output [S/R]COUNT number of items to/from input each task The contents of sbuff on each task are equally split and each task receives an equal part into array rbuff. Could also be done by putting MPI_SEND/MPI_RECV in a loop.
70 MPI_ALLTOALL IDRIS-CNS
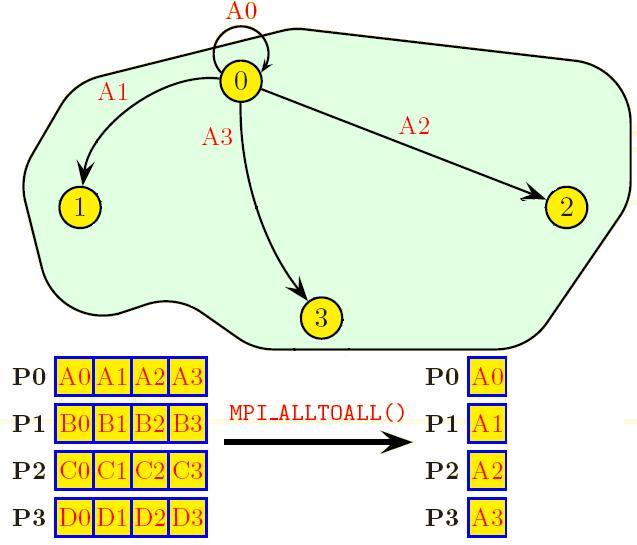
71 MPI_ALLTOALL IDRIS-CNRS
72 MPI_ALLTOALL IDRIS-CNRS
73 MPI_ALLTOALL IDRIS-CNRS
74 MPI_ALLTOALL IDRIS-CNRS
75 Reduction routines Perform both communications and simple math - Global sum, min, max,... Beware reproducibility - MPI makes no guarantee of reproducibility Eg. Summing an array of real numbers from each task May be summed in a different order each time - You may need to write your own order preserving summation if reproducibility is important to you. MPI_REDUCE - every task sends data and result is computed on the root task MPI_ALLREDUCE - every task sends, result is computed and broadcast back to all tasks. Equivalent to MPI_REDUCE followed by MPI_BCAST
76 MPI_REDUCE FORTRAN_TYPE:: sbuff, rbuff integer:: count, root, ierror call MPI_REDUCE( sbuff,rbuff,count,mpi_type,op_type, & root,mpi_comm_world,ierror) SBUFF array to be reduced input RBUFF result of reduction output COUNT number of items to be input reduced The contents of sbuff from all tasks are reduced according to OP_TYPE and the result is sent to RBUFF task root. OP_TYPE can be MPI_MAX, MPI_MIN, MPI_SUM, MPI_IPROD, MPI_IAND, MPI_BAND, MPI_IOR, MPI_BOR, MPI_LXOR, MPI_BXOR, MPI_MAXLOC, MPI_MINLOC

77 MPI_REDUCE IDRIS-CNRS

78 MPI_ALLREDUCE IDRIS-CNRS
79 MPI References Using MPI (2 nd edition) by William Gropp, Ewing Lusk and Anthony Skjellum; Copyright 1999 MIT; MIT Press ISBN The Message Passing Interface Standard on the web at
Cornell Theory Center. Discussion: MPI Collective Communication I. Table of Contents. 1. Introduction
 1 of 18 11/1/2006 3:59 PM Cornell Theory Center Discussion: MPI Collective Communication I This is the in-depth discussion layer of a two-part module. For an explanation of the layers and how to navigate
1 of 18 11/1/2006 3:59 PM Cornell Theory Center Discussion: MPI Collective Communication I This is the in-depth discussion layer of a two-part module. For an explanation of the layers and how to navigate
CSE. Parallel Algorithms on a cluster of PCs. Ian Bush. Daresbury Laboratory (With thanks to Lorna Smith and Mark Bull at EPCC)
") Parallel Algorithms on a cluster of PCs Ian Bush Daresbury Laboratory I.J.Bush@dl.ac.uk (With thanks to Lorna Smith and Mark Bull at EPCC) Overview This lecture will cover General Message passing concepts
Parallel Algorithms on a cluster of PCs Ian Bush Daresbury Laboratory I.J.Bush@dl.ac.uk (With thanks to Lorna Smith and Mark Bull at EPCC) Overview This lecture will cover General Message passing concepts
Programming with MPI Collectives
 Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing
 TMA4280 Introduction to Supercomputing") The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
Slides prepared by : Farzana Rahman 1
 Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
MPI MESSAGE PASSING INTERFACE
 MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
Recap of Parallelism & MPI
 Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
AMath 483/583 Lecture 21
 AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
CINES MPI. Johanne Charpentier & Gabriel Hautreux
 Training @ CINES MPI Johanne Charpentier & Gabriel Hautreux charpentier@cines.fr hautreux@cines.fr Clusters Architecture OpenMP MPI Hybrid MPI+OpenMP MPI Message Passing Interface 1. Introduction 2. MPI
Training @ CINES MPI Johanne Charpentier & Gabriel Hautreux charpentier@cines.fr hautreux@cines.fr Clusters Architecture OpenMP MPI Hybrid MPI+OpenMP MPI Message Passing Interface 1. Introduction 2. MPI
Practical Scientific Computing: Performanceoptimized
 Practical Scientific Computing: Performanceoptimized Programming Programming with MPI November 29, 2006 Dr. Ralf-Peter Mundani Department of Computer Science Chair V Technische Universität München, Germany
Practical Scientific Computing: Performanceoptimized Programming Programming with MPI November 29, 2006 Dr. Ralf-Peter Mundani Department of Computer Science Chair V Technische Universität München, Germany
Distributed Memory Parallel Programming
 COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
Outline. Communication modes MPI Message Passing Interface Standard
 MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
Introduction to the Message Passing Interface (MPI)
") Introduction to the Message Passing Interface (MPI) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction to the Message Passing Interface (MPI) Spring 2018
Introduction to the Message Passing Interface (MPI) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction to the Message Passing Interface (MPI) Spring 2018
IPM Workshop on High Performance Computing (HPC08) IPM School of Physics Workshop on High Perfomance Computing/HPC08
 IPM School of Physics Workshop on High Perfomance Computing/HPC08") IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
MPI: Message Passing Interface An Introduction. S. Lakshmivarahan School of Computer Science
 MPI: Message Passing Interface An Introduction S. Lakshmivarahan School of Computer Science MPI: A specification for message passing libraries designed to be a standard for distributed memory message passing,
MPI: Message Passing Interface An Introduction S. Lakshmivarahan School of Computer Science MPI: A specification for message passing libraries designed to be a standard for distributed memory message passing,
Week 3: MPI. Day 02 :: Message passing, point-to-point and collective communications
 Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
Elementary Parallel Programming with Examples. Reinhold Bader (LRZ) Georg Hager (RRZE)
 Georg Hager (RRZE)") Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs
: Parallelism on Multiple (Possibly Heterogeneous) CPUs") 1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) s http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) s http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
Outline. Communication modes MPI Message Passing Interface Standard. Khoa Coâng Ngheä Thoâng Tin Ñaïi Hoïc Baùch Khoa Tp.HCM
 THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
MA471. Lecture 5. Collective MPI Communication
 MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
L14 Supercomputing - Part 2
 Geophysical Computing L14-1 L14 Supercomputing - Part 2 1. MPI Code Structure Writing parallel code can be done in either C or Fortran. The Message Passing Interface (MPI) is just a set of subroutines
Geophysical Computing L14-1 L14 Supercomputing - Part 2 1. MPI Code Structure Writing parallel code can be done in either C or Fortran. The Message Passing Interface (MPI) is just a set of subroutines
The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs
: Parallelism on Multiple (Possibly Heterogeneous) CPUs") 1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
CS 6230: High-Performance Computing and Parallelization Introduction to MPI
 CS 6230: High-Performance Computing and Parallelization Introduction to MPI Dr. Mike Kirby School of Computing and Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT, USA
CS 6230: High-Performance Computing and Parallelization Introduction to MPI Dr. Mike Kirby School of Computing and Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT, USA
CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced
: Message-Passing Interface (MPI) advanced") 1 / 32 CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
1 / 32 CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
Part - II. Message Passing Interface. Dheeraj Bhardwaj
 Part - II Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110016 India http://www.cse.iitd.ac.in/~dheerajb 1 Outlines Basics of MPI How to compile and
Part - II Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110016 India http://www.cse.iitd.ac.in/~dheerajb 1 Outlines Basics of MPI How to compile and
Message passing. Week 3: MPI. Day 02 :: Message passing, point-to-point and collective communications. What is MPI?
 Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
CS 470 Spring Mike Lam, Professor. Distributed Programming & MPI
 CS 470 Spring 2018 Mike Lam, Professor Distributed Programming & MPI MPI paradigm Single program, multiple data (SPMD) One program, multiple processes (ranks) Processes communicate via messages An MPI
CS 470 Spring 2018 Mike Lam, Professor Distributed Programming & MPI MPI paradigm Single program, multiple data (SPMD) One program, multiple processes (ranks) Processes communicate via messages An MPI
CS 470 Spring Mike Lam, Professor. Distributed Programming & MPI
 CS 470 Spring 2017 Mike Lam, Professor Distributed Programming & MPI MPI paradigm Single program, multiple data (SPMD) One program, multiple processes (ranks) Processes communicate via messages An MPI
CS 470 Spring 2017 Mike Lam, Professor Distributed Programming & MPI MPI paradigm Single program, multiple data (SPMD) One program, multiple processes (ranks) Processes communicate via messages An MPI
Message-Passing and MPI Programming
 Message-Passing and MPI Programming 2.1 Transfer Procedures Datatypes and Collectives N.M. Maclaren Computing Service nmm1@cam.ac.uk ext. 34761 July 2010 These are the procedures that actually transfer
Message-Passing and MPI Programming 2.1 Transfer Procedures Datatypes and Collectives N.M. Maclaren Computing Service nmm1@cam.ac.uk ext. 34761 July 2010 These are the procedures that actually transfer
Chapter 3. Distributed Memory Programming with MPI
 An Introduction to Parallel Programming Peter Pacheco Chapter 3 Distributed Memory Programming with MPI 1 Roadmap n Writing your first MPI program. n Using the common MPI functions. n The Trapezoidal Rule
An Introduction to Parallel Programming Peter Pacheco Chapter 3 Distributed Memory Programming with MPI 1 Roadmap n Writing your first MPI program. n Using the common MPI functions. n The Trapezoidal Rule
Peter Pacheco. Chapter 3. Distributed Memory Programming with MPI. Copyright 2010, Elsevier Inc. All rights Reserved
 An Introduction to Parallel Programming Peter Pacheco Chapter 3 Distributed Memory Programming with MPI 1 Roadmap Writing your first MPI program. Using the common MPI functions. The Trapezoidal Rule in
An Introduction to Parallel Programming Peter Pacheco Chapter 3 Distributed Memory Programming with MPI 1 Roadmap Writing your first MPI program. Using the common MPI functions. The Trapezoidal Rule in
Distributed Memory Programming with MPI. Copyright 2010, Elsevier Inc. All rights Reserved
 An Introduction to Parallel Programming Peter Pacheco Chapter 3 Distributed Memory Programming with MPI 1 Roadmap Writing your first MPI program. Using the common MPI functions. The Trapezoidal Rule in
An Introduction to Parallel Programming Peter Pacheco Chapter 3 Distributed Memory Programming with MPI 1 Roadmap Writing your first MPI program. Using the common MPI functions. The Trapezoidal Rule in
Scalasca performance properties The metrics tour
 Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Experiencing Cluster Computing Message Passing Interface
 Experiencing Cluster Computing Message Passing Interface Class 6 Message Passing Paradigm The Underlying Principle A parallel program consists of p processes with different address spaces. Communication
Experiencing Cluster Computing Message Passing Interface Class 6 Message Passing Paradigm The Underlying Principle A parallel program consists of p processes with different address spaces. Communication
MPI: The Message-Passing Interface. Most of this discussion is from [1] and [2].
![MPI: The Message-Passing Interface. Most of this discussion is from [1] and [2].](/thumbs/73/69120417.jpg "MPI: The Message-Passing Interface. Most of this discussion is from [1] and [2].") MPI: The Message-Passing Interface Most of this discussion is from [1] and [2]. What Is MPI? The Message-Passing Interface (MPI) is a standard for expressing distributed parallelism via message passing.
MPI: The Message-Passing Interface Most of this discussion is from [1] and [2]. What Is MPI? The Message-Passing Interface (MPI) is a standard for expressing distributed parallelism via message passing.
CS4961 Parallel Programming. Lecture 18: Introduction to Message Passing 11/3/10. Final Project Purpose: Mary Hall November 2, 2010.
 Parallel Programming Lecture 18: Introduction to Message Passing Mary Hall November 2, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. -
Parallel Programming Lecture 18: Introduction to Message Passing Mary Hall November 2, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. -
AMath 483/583 Lecture 18 May 6, 2011
 AMath 483/583 Lecture 18 May 6, 2011 Today: MPI concepts Communicators, broadcast, reduce Next week: MPI send and receive Iterative methods Read: Class notes and references $CLASSHG/codes/mpi MPI Message
AMath 483/583 Lecture 18 May 6, 2011 Today: MPI concepts Communicators, broadcast, reduce Next week: MPI send and receive Iterative methods Read: Class notes and references $CLASSHG/codes/mpi MPI Message
Holland Computing Center Kickstart MPI Intro
 Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste
 Università di Trieste") Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Topics. Lecture 7. Review. Other MPI collective functions. Collective Communication (cont d) MPI Programming (III)
 MPI Programming (III)") Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
Introduction to MPI. May 20, Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign
 Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s
Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s
An Introduction to MPI
 An Introduction to MPI Parallel Programming with the Message Passing Interface William Gropp Ewing Lusk Argonne National Laboratory 1 Outline Background The message-passing model Origins of MPI and current
An Introduction to MPI Parallel Programming with the Message Passing Interface William Gropp Ewing Lusk Argonne National Laboratory 1 Outline Background The message-passing model Origins of MPI and current
Distributed Memory Programming with MPI
 Distributed Memory Programming with MPI Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Algoritmi Avanzati--modulo 2 2 Credits Peter Pacheco,
Distributed Memory Programming with MPI Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Algoritmi Avanzati--modulo 2 2 Credits Peter Pacheco,
A Message Passing Standard for MPP and Workstations
 A Message Passing Standard for MPP and Workstations Communications of the ACM, July 1996 J.J. Dongarra, S.W. Otto, M. Snir, and D.W. Walker Message Passing Interface (MPI) Message passing library Can be
A Message Passing Standard for MPP and Workstations Communications of the ACM, July 1996 J.J. Dongarra, S.W. Otto, M. Snir, and D.W. Walker Message Passing Interface (MPI) Message passing library Can be
Parallelization. Tianhe-1A, 2.45 Pentaflops/s, 224 Terabytes RAM. Nigel Mitchell
 Parallelization Tianhe-1A, 2.45 Pentaflops/s, 224 Terabytes RAM Nigel Mitchell Outline Pros and Cons of parallelization Shared memory vs. cluster computing MPI as a tool for sending and receiving messages
Parallelization Tianhe-1A, 2.45 Pentaflops/s, 224 Terabytes RAM Nigel Mitchell Outline Pros and Cons of parallelization Shared memory vs. cluster computing MPI as a tool for sending and receiving messages
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives n Understanding how MPI programs execute n Familiarity with fundamental MPI functions
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives n Understanding how MPI programs execute n Familiarity with fundamental MPI functions
Intermediate MPI. M. D. Jones, Ph.D. Center for Computational Research University at Buffalo State University of New York
 Intermediate MPI M. D. Jones, Ph.D. Center for Computational Research University at Buffalo State University of New York High Performance Computing I, 2008 M. D. Jones, Ph.D. (CCR/UB) Intermediate MPI
Intermediate MPI M. D. Jones, Ph.D. Center for Computational Research University at Buffalo State University of New York High Performance Computing I, 2008 M. D. Jones, Ph.D. (CCR/UB) Intermediate MPI
Practical Introduction to Message-Passing Interface (MPI)
") 1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
Parallel Computing Programming Distributed Memory Architectures
 Parallel Computing Programming Distributed Memory Architectures Dr. Gerhard Wellein,, Dr. Georg Hager Regionales Rechenzentrum Erlangen (RRZE) Vorlesung Parallelrechner Georg-Simon Simon-Ohm-Fachhochschule
Parallel Computing Programming Distributed Memory Architectures Dr. Gerhard Wellein,, Dr. Georg Hager Regionales Rechenzentrum Erlangen (RRZE) Vorlesung Parallelrechner Georg-Simon Simon-Ohm-Fachhochschule
Parallel Programming with MPI MARCH 14, 2018
 Parallel Programming with MPI SARDAR USMAN & EMAD ALAMOUDI SUPERVISOR: PROF. RASHID MEHMOOD RMEHMOOD@KAU.EDU.SA MARCH 14, 2018 Sources The presentation is compiled using following sources. http://mpi-forum.org/docs/
Parallel Programming with MPI SARDAR USMAN & EMAD ALAMOUDI SUPERVISOR: PROF. RASHID MEHMOOD RMEHMOOD@KAU.EDU.SA MARCH 14, 2018 Sources The presentation is compiled using following sources. http://mpi-forum.org/docs/
High Performance Computing
 High Performance Computing Course Notes 2009-2010 2010 Message Passing Programming II 1 Communications Point-to-point communications: involving exact two processes, one sender and one receiver For example,
High Performance Computing Course Notes 2009-2010 2010 Message Passing Programming II 1 Communications Point-to-point communications: involving exact two processes, one sender and one receiver For example,
Distributed Memory Programming with Message-Passing
 Distributed Memory Programming with Message-Passing Pacheco s book Chapter 3 T. Yang, CS240A Part of slides from the text book and B. Gropp Outline An overview of MPI programming Six MPI functions and
Distributed Memory Programming with Message-Passing Pacheco s book Chapter 3 T. Yang, CS240A Part of slides from the text book and B. Gropp Outline An overview of MPI programming Six MPI functions and
Lecture 4 Introduction to MPI
 CS075 1896 Lecture 4 Introduction to MPI Jeremy Wei Center for HPC, SJTU Mar 13th, 2017 1920 1987 2006 Recap of the last lecture (OpenMP) OpenMP is a standardized pragma-based intra-node parallel programming
CS075 1896 Lecture 4 Introduction to MPI Jeremy Wei Center for HPC, SJTU Mar 13th, 2017 1920 1987 2006 Recap of the last lecture (OpenMP) OpenMP is a standardized pragma-based intra-node parallel programming
MPI and comparison of models Lecture 23, cs262a. Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018
 MPI and comparison of models Lecture 23, cs262a Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018 MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers,
MPI and comparison of models Lecture 23, cs262a Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018 MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers,
東京大学情報基盤中心准教授片桐孝洋 Takahiro Katagiri, Associate Professor, Information Technology Center, The University of Tokyo
 Overview of MPI 東京大学情報基盤中心准教授片桐孝洋 Takahiro Katagiri, Associate Professor, Information Technology Center, The University of Tokyo 台大数学科学中心科学計算冬季学校 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction
Overview of MPI 東京大学情報基盤中心准教授片桐孝洋 Takahiro Katagiri, Associate Professor, Information Technology Center, The University of Tokyo 台大数学科学中心科学計算冬季学校 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction
Introduction to parallel computing concepts and technics
 Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
MPI. (message passing, MIMD)
") MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
MPI Message Passing Interface
 MPI Message Passing Interface Portable Parallel Programs Parallel Computing A problem is broken down into tasks, performed by separate workers or processes Processes interact by exchanging information
MPI Message Passing Interface Portable Parallel Programs Parallel Computing A problem is broken down into tasks, performed by separate workers or processes Processes interact by exchanging information
Collective Communications
 Collective Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Collective Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Message Passing Interface
 Message Passing Interface by Kuan Lu 03.07.2012 Scientific researcher at Georg-August-Universität Göttingen and Gesellschaft für wissenschaftliche Datenverarbeitung mbh Göttingen Am Faßberg, 37077 Göttingen,
Message Passing Interface by Kuan Lu 03.07.2012 Scientific researcher at Georg-August-Universität Göttingen and Gesellschaft für wissenschaftliche Datenverarbeitung mbh Göttingen Am Faßberg, 37077 Göttingen,
MPI Collective communication
 MPI Collective communication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) MPI Collective communication Spring 2018 1 / 43 Outline 1 MPI Collective communication
MPI Collective communication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) MPI Collective communication Spring 2018 1 / 43 Outline 1 MPI Collective communication
CSE 613: Parallel Programming. Lecture 21 ( The Message Passing Interface )
") CSE 613: Parallel Programming Lecture 21 ( The Message Passing Interface ) Jesmin Jahan Tithi Department of Computer Science SUNY Stony Brook Fall 2013 ( Slides from Rezaul A. Chowdhury ) Principles of
CSE 613: Parallel Programming Lecture 21 ( The Message Passing Interface ) Jesmin Jahan Tithi Department of Computer Science SUNY Stony Brook Fall 2013 ( Slides from Rezaul A. Chowdhury ) Principles of
Introduction to MPI. Ekpe Okorafor. School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014
 Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Introduction to MPI. SHARCNET MPI Lecture Series: Part I of II. Paul Preney, OCT, M.Sc., B.Ed., B.Sc.
 Introduction to MPI SHARCNET MPI Lecture Series: Part I of II Paul Preney, OCT, M.Sc., B.Ed., B.Sc. preney@sharcnet.ca School of Computer Science University of Windsor Windsor, Ontario, Canada Copyright
Introduction to MPI SHARCNET MPI Lecture Series: Part I of II Paul Preney, OCT, M.Sc., B.Ed., B.Sc. preney@sharcnet.ca School of Computer Science University of Windsor Windsor, Ontario, Canada Copyright
Parallel Computing and the MPI environment
 Parallel Computing and the MPI environment Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Parallel Computing and the MPI environment Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Chip Multiprocessors COMP Lecture 9 - OpenMP & MPI
 Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
Overview of MPI 國家理論中心數學組 高效能計算 短期課程. 名古屋大学情報基盤中心教授片桐孝洋 Takahiro Katagiri, Professor, Information Technology Center, Nagoya University
 Overview of MPI 名古屋大学情報基盤中心教授片桐孝洋 Takahiro Katagiri, Professor, Information Technology Center, Nagoya University 國家理論中心數學組 高效能計算 短期課程 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction Operations
Overview of MPI 名古屋大学情報基盤中心教授片桐孝洋 Takahiro Katagiri, Professor, Information Technology Center, Nagoya University 國家理論中心數學組 高效能計算 短期課程 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction Operations
Parallel Computing Programming Distributed Memory Architectures
 Parallel Computing Programming Distributed Memory Architectures Dr. Gerhard Wellein, Dr. Georg Hager Regionales Rechenzentrum Erlangen (RRZE) Blockkurs Parallelrechner Georg-Simon Simon-Ohm-Fachhochschule
Parallel Computing Programming Distributed Memory Architectures Dr. Gerhard Wellein, Dr. Georg Hager Regionales Rechenzentrum Erlangen (RRZE) Blockkurs Parallelrechner Georg-Simon Simon-Ohm-Fachhochschule
CS4961 Parallel Programming. Lecture 16: Introduction to Message Passing 11/3/11. Administrative. Mary Hall November 3, 2011.
 CS4961 Parallel Programming Lecture 16: Introduction to Message Passing Administrative Next programming assignment due on Monday, Nov. 7 at midnight Need to define teams and have initial conversation with
CS4961 Parallel Programming Lecture 16: Introduction to Message Passing Administrative Next programming assignment due on Monday, Nov. 7 at midnight Need to define teams and have initial conversation with
MPI MESSAGE PASSING INTERFACE
 MPI MESSAGE PASSING INTERFACE David COLIGNON, ULiège CÉCI - Consortium des Équipements de Calcul Intensif http://www.ceci-hpc.be Outline Introduction From serial source code to parallel execution MPI functions
MPI MESSAGE PASSING INTERFACE David COLIGNON, ULiège CÉCI - Consortium des Équipements de Calcul Intensif http://www.ceci-hpc.be Outline Introduction From serial source code to parallel execution MPI functions
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
Collective Communication: Gather. MPI - v Operations. Collective Communication: Gather. MPI_Gather. root WORKS A OK
 Collective Communication: Gather MPI - v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Collective Communication: Gather MPI - v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Message Passing Interface
 MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
An introduction to MPI
 An introduction to MPI C MPI is a Library for Message-Passing Not built in to compiler Function calls that can be made from any compiler, many languages Just link to it Wrappers: mpicc, mpif77 Fortran
An introduction to MPI C MPI is a Library for Message-Passing Not built in to compiler Function calls that can be made from any compiler, many languages Just link to it Wrappers: mpicc, mpif77 Fortran
MPI - v Operations. Collective Communication: Gather
 MPI - v Operations Based on notes by Dr. David Cronk Innovative Computing Lab University of Tennessee Cluster Computing 1 Collective Communication: Gather A Gather operation has data from all processes
MPI - v Operations Based on notes by Dr. David Cronk Innovative Computing Lab University of Tennessee Cluster Computing 1 Collective Communication: Gather A Gather operation has data from all processes
Basic MPI Communications. Basic MPI Communications (cont d)
") Basic MPI Communications MPI provides two non-blocking routines: MPI_Isend(buf,cnt,type,dst,tag,comm,reqHandle) buf: source of data to be sent cnt: number of data elements to be sent type: type of each
Basic MPI Communications MPI provides two non-blocking routines: MPI_Isend(buf,cnt,type,dst,tag,comm,reqHandle) buf: source of data to be sent cnt: number of data elements to be sent type: type of each
Message Passing with MPI
 Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Chapter 4. Message-passing Model
 Chapter 4 Message-Passing Programming Message-passing Model 2 1 Characteristics of Processes Number is specified at start-up time Remains constant throughout the execution of program All execute same program
Chapter 4 Message-Passing Programming Message-passing Model 2 1 Characteristics of Processes Number is specified at start-up time Remains constant throughout the execution of program All execute same program
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
Scientific Computing
 Lecture on Scientific Computing Dr. Kersten Schmidt Lecture 21 Technische Universität Berlin Institut für Mathematik Wintersemester 2014/2015 Syllabus Linear Regression, Fast Fourier transform Modelling
Lecture on Scientific Computing Dr. Kersten Schmidt Lecture 21 Technische Universität Berlin Institut für Mathematik Wintersemester 2014/2015 Syllabus Linear Regression, Fast Fourier transform Modelling
A Message Passing Standard for MPP and Workstations. Communications of the ACM, July 1996 J.J. Dongarra, S.W. Otto, M. Snir, and D.W.
 1 A Message Passing Standard for MPP and Workstations Communications of the ACM, July 1996 J.J. Dongarra, S.W. Otto, M. Snir, and D.W. Walker 2 Message Passing Interface (MPI) Message passing library Can
1 A Message Passing Standard for MPP and Workstations Communications of the ACM, July 1996 J.J. Dongarra, S.W. Otto, M. Snir, and D.W. Walker 2 Message Passing Interface (MPI) Message passing library Can
lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar cd mpibasic_lab/pi cd mpibasic_lab/decomp1d
 MPI Lab Getting Started Login to ranger.tacc.utexas.edu Untar the lab source code lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar Part 1: Getting Started with simple parallel coding hello mpi-world
MPI Lab Getting Started Login to ranger.tacc.utexas.edu Untar the lab source code lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar Part 1: Getting Started with simple parallel coding hello mpi-world
COMP 322: Fundamentals of Parallel Programming
 COMP 322: Fundamentals of Parallel Programming https://wiki.rice.edu/confluence/display/parprog/comp322 Lecture 37: Introduction to MPI (contd) Vivek Sarkar Department of Computer Science Rice University
COMP 322: Fundamentals of Parallel Programming https://wiki.rice.edu/confluence/display/parprog/comp322 Lecture 37: Introduction to MPI (contd) Vivek Sarkar Department of Computer Science Rice University
Review of MPI Part 2
 Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
Distributed Memory Machines and Programming. Lecture 7
 Distributed Memory Machines and Programming Lecture 7 James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16 Slides from Kathy Yelick CS267 Lecture 7 1 Outline Distributed Memory Architectures Properties
Distributed Memory Machines and Programming Lecture 7 James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16 Slides from Kathy Yelick CS267 Lecture 7 1 Outline Distributed Memory Architectures Properties
Parallel Programming with MPI: Day 1
 Parallel Programming with MPI: Day 1 Science & Technology Support High Performance Computing Ohio Supercomputer Center 1224 Kinnear Road Columbus, OH 43212-1163 1 Table of Contents Brief History of MPI
Parallel Programming with MPI: Day 1 Science & Technology Support High Performance Computing Ohio Supercomputer Center 1224 Kinnear Road Columbus, OH 43212-1163 1 Table of Contents Brief History of MPI
High Performance Computing Course Notes Message Passing Programming I
 High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming I Message Passing Programming Message Passing is the most widely used parallel programming model Message passing works
High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming I Message Passing Programming Message Passing is the most widely used parallel programming model Message passing works
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives Understanding how MPI programs execute Familiarity with fundamental MPI functions
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives Understanding how MPI programs execute Familiarity with fundamental MPI functions
Számítogépes modellezés labor (MSc)
") Számítogépes modellezés labor (MSc) Running Simulations on Supercomputers Gábor Rácz Physics of Complex Systems Department Eötvös Loránd University, Budapest September 19, 2018, Budapest, Hungary Outline
Számítogépes modellezés labor (MSc) Running Simulations on Supercomputers Gábor Rácz Physics of Complex Systems Department Eötvös Loránd University, Budapest September 19, 2018, Budapest, Hungary Outline
Parallel Programming Using MPI
 Parallel Programming Using MPI Gregory G. Howes Department of Physics and Astronomy University of Iowa Iowa High Performance Computing Summer School University of Iowa Iowa City, Iowa 6-8 June 2012 Thank
Parallel Programming Using MPI Gregory G. Howes Department of Physics and Astronomy University of Iowa Iowa High Performance Computing Summer School University of Iowa Iowa City, Iowa 6-8 June 2012 Thank
MPI Tutorial. Shao-Ching Huang. IDRE High Performance Computing Workshop
 MPI Tutorial Shao-Ching Huang IDRE High Performance Computing Workshop 2013-02-13 Distributed Memory Each CPU has its own (local) memory This needs to be fast for parallel scalability (e.g. Infiniband,
MPI Tutorial Shao-Ching Huang IDRE High Performance Computing Workshop 2013-02-13 Distributed Memory Each CPU has its own (local) memory This needs to be fast for parallel scalability (e.g. Infiniband,
Message Passing Interface
 Message Passing Interface DPHPC15 TA: Salvatore Di Girolamo DSM (Distributed Shared Memory) Message Passing MPI (Message Passing Interface) A message passing specification implemented
Message Passing Interface DPHPC15 TA: Salvatore Di Girolamo DSM (Distributed Shared Memory) Message Passing MPI (Message Passing Interface) A message passing specification implemented
MPI 5. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 5 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 5 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
The Message Passing Model
 Introduction to MPI The Message Passing Model Applications that do not share a global address space need a Message Passing Framework. An application passes messages among processes in order to perform
Introduction to MPI The Message Passing Model Applications that do not share a global address space need a Message Passing Framework. An application passes messages among processes in order to perform
Scalasca performance properties The metrics tour
 Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
PyConZA High Performance Computing with Python. Kevin Colville Python on large clusters with MPI
 PyConZA 2012 High Performance Computing with Python Kevin Colville Python on large clusters with MPI Andy Rabagliati Python to read and store data on CHPC Petabyte data store www.chpc.ac.za High Performance
PyConZA 2012 High Performance Computing with Python Kevin Colville Python on large clusters with MPI Andy Rabagliati Python to read and store data on CHPC Petabyte data store www.chpc.ac.za High Performance
Collective Communication: Gatherv. MPI v Operations. root
 Collective Communication: Gather MPI v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Collective Communication: Gather MPI v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
MPI Program Structure
 MPI Program Structure Handles MPI communicator MPI_COMM_WORLD Header files MPI function format Initializing MPI Communicator size Process rank Exiting MPI 1 Handles MPI controls its own internal data structures
MPI Program Structure Handles MPI communicator MPI_COMM_WORLD Header files MPI function format Initializing MPI Communicator size Process rank Exiting MPI 1 Handles MPI controls its own internal data structures
Tutorial 2: MPI. CS486 - Principles of Distributed Computing Papageorgiou Spyros
 Tutorial 2: MPI CS486 - Principles of Distributed Computing Papageorgiou Spyros What is MPI? An Interface Specification MPI = Message Passing Interface Provides a standard -> various implementations Offers
Tutorial 2: MPI CS486 - Principles of Distributed Computing Papageorgiou Spyros What is MPI? An Interface Specification MPI = Message Passing Interface Provides a standard -> various implementations Offers
1 Overview. KH Computational Physics QMC. Parallel programming.
 Parallel programming 1 Overview Most widely accepted technique for parallel programming is so called: M P I = Message Passing Interface. This is not a package or program, but rather a standardized collection
Parallel programming 1 Overview Most widely accepted technique for parallel programming is so called: M P I = Message Passing Interface. This is not a package or program, but rather a standardized collection