Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed
|
|
|
- Abel Brooks
- 5 years ago
- Views:
Transcription






1 Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed Marco Aldinucci Computer Science Dept. - University of Torino - Italy Marco Danelutto, Massimiliano Meneghin, Massimo Torquti Computer Science Dept. - University of Pisa - Italy Peter Kilpatrick Computer Science Dept. - Queen s University Belfast - U.K. ParCo Sep. 1st - Lyon - France
2 Outline Motivation Commodity architecture evolution Efficiency for fine-grained computation POSIX thread evaluation FastFlow Architecture Implementation Experimental results Micro-benchmarks Real-world App: the Smith-Waterman sequence alignment application Conclusion, future works, and surprise dessert (before lunch) 2
3 [< 2004] Shared Font-Side Bus (Centralized Snooping)
4 [< 2004] Shared Font-Side Bus (Centralized Snooping)
5 [2005] Dual Independent Buses (Centralized Snooping)
6 [2005] Dual Independent Buses (Centralized Snooping)
![[2007] Dedicated High-Speed](/docs-images/81/82795304/images/7-1.jpg "Interconnects (Centralized")
7 [2007] Dedicated High-Speed Interconnects (Centralized Snooping)
8 [2007] Dedicated High-Speed Interconnects (Centralized Snooping)
9 [2009] QuickPath (MESI-F Directory Coherence)
10 [2009] QuickPath (MESI-F Directory Coherence)
11 This and next generation SCM Exploit cache coherence and it is likely to happens also in the next future Memory fences are expensive Increasing core count will make it worse Atomic operations does not solve the problem (still fences) Fine-grained parallelism is off-limits I/O bound problems, High-throughput, Streaming, Irregular DP problems Automatic and assisted parallelization
12 Micro-benchmarks: farm of tasks Used to implement: parameter sweeping, master-worker, etc. void Emitter () { for ( i =0; i <streamlen;++i){ task = create_task (); queue=select_worker_queue(); queue >PUSH(task); } } void Worker() { while (!end_of_stream){ myqueue >POP(&task); do_work(task) ; } } int main () { spawn_thread( Emitter ) ; for ( i =0; i <nworkers;++i){ spawn_thread(worker); } wait_end () ; } E W 1 W 2 W n C
13 Using POSIX lock/unlock queues W 1 E W 2 C Ideal 50 μs 5 μs 0.5 μs 8 W n 6 Speedup Number of Cores
14 Using POSIX lock/unlock queues W 1 E W 2 C Ideal 50 μs 5 μs 0.5 μs 8 W n 6 Speedup Number of Cores
15 Using CompareAndSwap queues W 1 E W 2 C Ideal 50 μs 5 μs 0.5 μs 8 W n 6 Speedup Number of Cores
16 Using CompareAndSwap queues W 1 E W 2 C Ideal 50 μs 5 μs 0.5 μs 8 W n 6 Speedup Number of Cores
17 Evaluation Poor performance for fine-grained computations Memory fences seriously affect the performance
18 What about avoiding fences in SCM? Highly-level semantics matters! DP paradigms entail data bidirectional data exchange among cores Cache reconciliation can be made faster but not avoided Task Parallel, Streaming, Systolic usually result in a one-way data flow Is cache coherency really strictly needed? Well described by a data flowing graphs (streaming networks)
19 Streaming Networks A Streaming Network can be easily build POSIX (or other) threads Asynchronous channels But exploiting a global address space Threads can still share the memory using locks SPMC MPMC Asynchronous channels Thread lifecycle control + FIFO Queue Queue: Single Producer Single Consumer (SPSC), Single Producer Multiple Consumer (SPMC), Multiple Producer Single Consumer (MPSC), Multiple Producer Multiple Consumer (MPMC) Lifecycle: ready - active waiting (yield + over-provisioning) MCSP SPSC
20 Queues: state of the art MPMC Dozen of lock-free (and wait-free) proposal The quality is usually measured with number of atomic operations (CAS) SPSC CAS 1 lock-free, fence-free J. Giacomoni, T. Moseley, and M. Vachharajani. Fastforward for efficient pipeline parallelism: a cache-optimized concurrent lock-free queue. PPoPP ACM. Supports Total Store Order OOO architectures (e.g. Intel Core) Active waiting. Use OS as less as possible. Native SPMC and MPSC see MPMC
21 SPMC and MCSP via SPSC + control SPMC(x) fence-free queue wit x consumers One SPSC input queue and x SPSC output queues One flow of control (thread) dispatch items from input to outputs E MPSC(y) fence-free queue with y producers One SPSC output queue and y SPSC input queues One flow of control (thread) gather items from inputs to output C x and y can be dynamically changed MPMC = MCSP + SPMC Just juxtapose the two parametric networks
22 FastFlow: A step forward Implements lock-free SPSC, SPMC, MPSC, MPMC queues Exploiting streaming networks Features can be composed as parametric streaming networks (graphs) E.g. an optimized memory allocator can be added by fusing the allocator graphs with the application graphs Not described here Features are represented as skeletons, actually which compilation target are streaming networks C++ STL-like implementation Can be used as a low-level library Can be used to generatively compile skeletons into streaming networks Blazing fast on fine-grained computations
23 Very fine grain (0.5 μs) W 1 E W 2 C Ideal POSIX lock CAS FastFlow 8 W n 6 Speedup Number of Cores
24 Very fine grain (0.5 μs) W 1 E W 2 C Ideal POSIX lock CAS FastFlow 8 W n 6 Speedup Number of Cores
25 Fine grain (5 μs) W 1 E W 2 C Ideal POSIX lock CAS FastFlow 8 W n 6 Speedup Number of Cores
26 Fine grain (5 μs) W 1 E W 2 C Ideal POSIX lock CAS FastFlow 8 W n 6 Speedup Number of Cores
27 Medium grain (50 μs) W 1 E W 2 C Ideal POSIX lock CAS FastFlow 8 W n 6 Speedup Number of Cores

28 Medium grain (50 μs) W 1 E W 2 C Ideal POSIX lock CAS FastFlow 8 W n 6 Speedup Number of Cores
29 Biosequence alignment Smith-Waterman algorithm Local alignment Time and space demanding O(mn), often replaced by approximated BLAST Dynamic programming Real-world application It has been accelerated by using FPGA, GCPU (CUDA), SSE2/x86, IBM Cell Best software implementation SWPS3: evolution of Farrar s implementation SSE2 + POSIX IPC
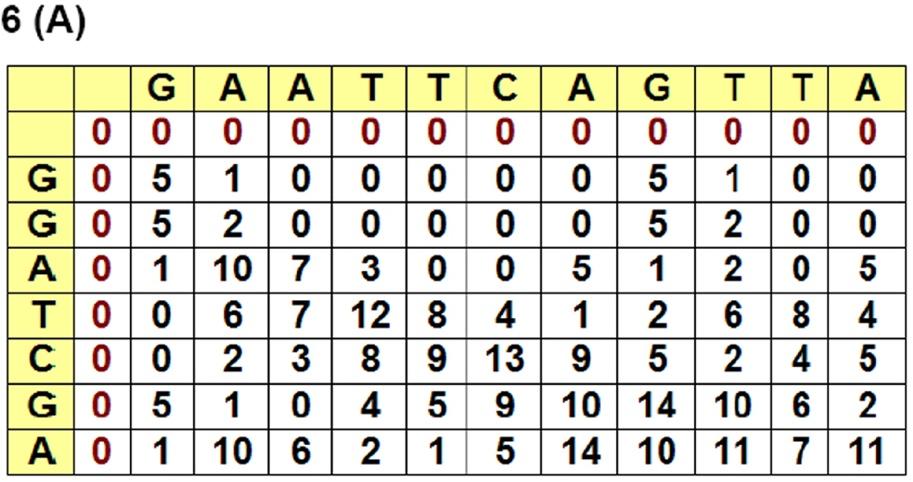
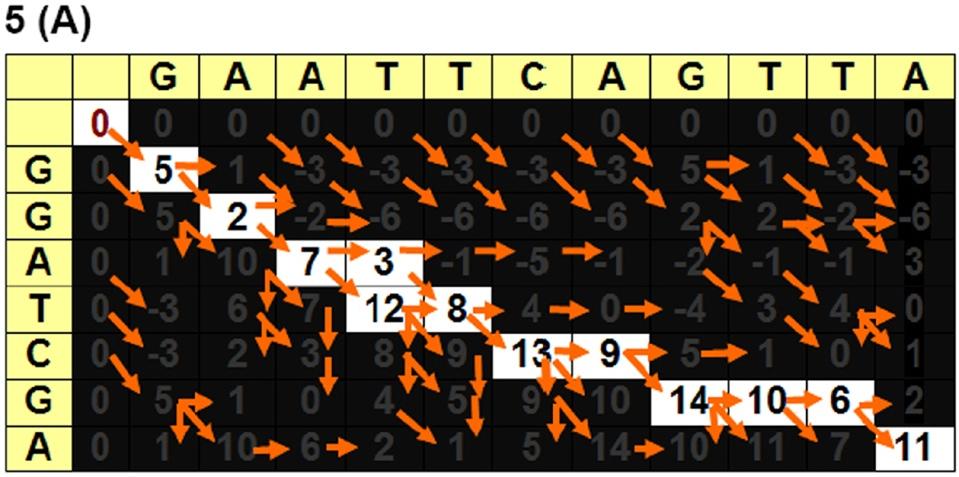

30 Smith-Waterman algorithm Local alignment - dynamic programming - O(nm)
31 Substitution Matrix: describes the rate at which one character in a sequence changes to other character states over time Gap Penalty: describes the costs of gaps, possibly as function of gap length Experiment parameters Affine Gap Penalty: 10-2k, 5-2k,... Substitution Matrix: BLOSUM50

32 Biosequence testbed Each query sequence (protein) is aligned against the whole Threads or Processes or... SW 1 protein DB SW 2 E.g. Compare unknown sequence against a DB of known sequences Query Sequences SW n Results SWPS3 implementation exploits POSIX processes and pipes Faster than POSIX threads + locks UniProtKB Swiss-Prot sequences amino-acids Shared memory (read-only)
33 Smith Waterman (10-2k gap penalty) 40 SWPS3 FastFlow GCPUS (the higher the better) Query sequence lenght
34 Smith Waterman (5-2k gap penalty) 20 SWPS3 FastFlow GCPUS (the higher the better) Query sequence lenght
35 Conclusions FastFlow support efficiently streaming applications on commodity SCM (e.g. Intel core architecture) More efficiently than POSIX threads (standard or CAS lock) Smith Waterman algorithm with FastFlow Obtained from SWPS3 by syntactically substituting read and write on POSIX pipes with fastflow push and FastFlow pop an push In turn, POSIX pipes are faster than POSIX threads + locks in this case Scores twice the speed of best known parallel implementation (SWPS3) on the same hardware (Intel 2 x Quad-core 2.5 GHz)
36 Future Work FastFlow Is open source (STL-like C++ library will be released soon) [ ] Contact me if you interested Include a specialized (very fast) parallel memory allocator [ ] Can be used to automatically parallelize a wide class of problems [ ] Since it efficiently supports fine grain computations Can be used as compilation target for skeletons [ ] Support parametric parallelism schemas and support compositionality (can be formalized as graph rewriting) Can be extended for CC-NUMA architectures [ ] Can be used to extend Intel TBB and OpenMP [ ] Increasing the performances of those tools
 FastFlow is also faster than Open")
37 GCUPS P14942 P05013 P01111 P02232 P27895 P03435 P25705 P10635 P01008 P07327 P k gap penalty Query sequence length (protein length) P19096 P04775 P07756 FastFlow OpenMP Cilk TBB SWPS3 Q9UKN1 P20930 P0C6B8 P28167 Q8WXI7 Query sequence (protein) FastFlow is also faster than Open MP, Intel TBB and Cilk (at least for streaming on Intel 2 x quad-core)
38


39 THANK YOU! QUESTIONS?... and one question for you Are those chips really build for parallel computing?
Efficient Smith-Waterman on multi-core with FastFlow
 BioBITs Euromicro PDP 2010 - Pisa Italy - 17th Feb 2010 Efficient Smith-Waterman on multi-core with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino - Italy Massimo Torquati Computer
BioBITs Euromicro PDP 2010 - Pisa Italy - 17th Feb 2010 Efficient Smith-Waterman on multi-core with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino - Italy Massimo Torquati Computer
An efficient Unbounded Lock-Free Queue for Multi-Core Systems
 An efficient Unbounded Lock-Free Queue for Multi-Core Systems Authors: Marco Aldinucci 1, Marco Danelutto 2, Peter Kilpatrick 3, Massimiliano Meneghin 4 and Massimo Torquati 2 1 Computer Science Dept.
An efficient Unbounded Lock-Free Queue for Multi-Core Systems Authors: Marco Aldinucci 1, Marco Danelutto 2, Peter Kilpatrick 3, Massimiliano Meneghin 4 and Massimo Torquati 2 1 Computer Science Dept.
Accelerating code on multi-cores with FastFlow
 EuroPar 2011 Bordeaux - France 1st Sept 2001 Accelerating code on multi-cores with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino (Turin) - Italy Massimo Torquati and Marco Danelutto
EuroPar 2011 Bordeaux - France 1st Sept 2001 Accelerating code on multi-cores with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino (Turin) - Italy Massimo Torquati and Marco Danelutto
High-level parallel programming: (few) ideas for challenges in formal methods
 ideas for challenges in formal methods") COST Action IC701 Limerick - Republic of Ireland 21st June 2011 High-level parallel programming: (few) ideas for challenges in formal methods Marco Aldinucci Computer Science Dept. - University of Torino
COST Action IC701 Limerick - Republic of Ireland 21st June 2011 High-level parallel programming: (few) ideas for challenges in formal methods Marco Aldinucci Computer Science Dept. - University of Torino
Accelerating sequential programs using FastFlow and self-offloading
 Università di Pisa Dipartimento di Informatica Technical Report: TR-10-03 Accelerating sequential programs using FastFlow and self-offloading Marco Aldinucci Marco Danelutto Peter Kilpatrick Massimiliano
Università di Pisa Dipartimento di Informatica Technical Report: TR-10-03 Accelerating sequential programs using FastFlow and self-offloading Marco Aldinucci Marco Danelutto Peter Kilpatrick Massimiliano
Parallel Programming using FastFlow
 Parallel Programming using FastFlow Massimo Torquati Computer Science Department, University of Pisa - Italy Karlsruhe, September 2nd, 2014 Outline Structured Parallel Programming
Parallel Programming using FastFlow Massimo Torquati Computer Science Department, University of Pisa - Italy Karlsruhe, September 2nd, 2014 Outline Structured Parallel Programming
FastFlow: high-level programming patterns with non-blocking lock-free run-time support
 UPMARC Workshop on Task-Based Parallel Programming Uppsala 2012 September 28, 2012 Uppsala, Sweden FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci
UPMARC Workshop on Task-Based Parallel Programming Uppsala 2012 September 28, 2012 Uppsala, Sweden FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci
Introduction to FastFlow programming
 Introduction to FastFlow programming SPM lecture, November 2016 Massimo Torquati Computer Science Department, University of Pisa - Italy Objectives Have a good idea of the FastFlow
Introduction to FastFlow programming SPM lecture, November 2016 Massimo Torquati Computer Science Department, University of Pisa - Italy Objectives Have a good idea of the FastFlow
FastFlow: targeting distributed systems
 FastFlow: targeting distributed systems Massimo Torquati ParaPhrase project meeting, Pisa Italy 11 th July, 2012 torquati@di.unipi.it Talk outline FastFlow basic concepts two-tier parallel model From single
FastFlow: targeting distributed systems Massimo Torquati ParaPhrase project meeting, Pisa Italy 11 th July, 2012 torquati@di.unipi.it Talk outline FastFlow basic concepts two-tier parallel model From single
An Efficient Synchronisation Mechanism for Multi-Core Systems
 An Efficient Synchronisation Mechanism for Multi-Core Systems Marco Aldinucci 1, Marco Danelutto 2, Peter Kilpatrick 3, Massimiliano Meneghin 4, and Massimo Torquati 2 1 Computer Science Department, University
An Efficient Synchronisation Mechanism for Multi-Core Systems Marco Aldinucci 1, Marco Danelutto 2, Peter Kilpatrick 3, Massimiliano Meneghin 4, and Massimo Torquati 2 1 Computer Science Department, University
Marco Danelutto. October 2010, Amsterdam. Dept. of Computer Science, University of Pisa, Italy. Skeletons from grids to multicores. M.
 Marco Danelutto Dept. of Computer Science, University of Pisa, Italy October 2010, Amsterdam Contents 1 2 3 4 Structured parallel programming Structured parallel programming Algorithmic Cole 1988 common,
Marco Danelutto Dept. of Computer Science, University of Pisa, Italy October 2010, Amsterdam Contents 1 2 3 4 Structured parallel programming Structured parallel programming Algorithmic Cole 1988 common,
P1261R0: Supporting Pipelines in C++
 P1261R0: Supporting Pipelines in C++ Date: 2018-10-08 Project: Audience Authors: ISO JTC1/SC22/WG21: Programming Language C++ SG14, SG1 Michael Wong (Codeplay), Daniel Garcia (UC3M), Ronan Keryell (Xilinx)
P1261R0: Supporting Pipelines in C++ Date: 2018-10-08 Project: Audience Authors: ISO JTC1/SC22/WG21: Programming Language C++ SG14, SG1 Michael Wong (Codeplay), Daniel Garcia (UC3M), Ronan Keryell (Xilinx)
Marco Danelutto. May 2011, Pisa
 Marco Danelutto Dept. of Computer Science, University of Pisa, Italy May 2011, Pisa Contents 1 2 3 4 5 6 7 Parallel computing The problem Solve a problem using n w processing resources Obtaining a (close
Marco Danelutto Dept. of Computer Science, University of Pisa, Italy May 2011, Pisa Contents 1 2 3 4 5 6 7 Parallel computing The problem Solve a problem using n w processing resources Obtaining a (close
Marco Aldinucci Salvatore Ruggieri, Massimo Torquati
 Marco Aldinucci aldinuc@di.unito.it Computer Science Department University of Torino Italy Salvatore Ruggieri, Massimo Torquati ruggieri@di.unipi.it torquati@di.unipi.it Computer Science Department University
Marco Aldinucci aldinuc@di.unito.it Computer Science Department University of Torino Italy Salvatore Ruggieri, Massimo Torquati ruggieri@di.unipi.it torquati@di.unipi.it Computer Science Department University
FastFlow: targeting distributed systems Massimo Torquati
 FastFlow: targeting distributed systems Massimo Torquati May 17 th, 2012 torquati@di.unipi.it http://www.di.unipi.it/~torquati FastFlow node FastFlow's implementation is based on the concept of node (ff_node
FastFlow: targeting distributed systems Massimo Torquati May 17 th, 2012 torquati@di.unipi.it http://www.di.unipi.it/~torquati FastFlow node FastFlow's implementation is based on the concept of node (ff_node
Structured approaches for multi/many core targeting
 Structured approaches for multi/many core targeting Marco Danelutto M. Torquati, M. Aldinucci, M. Meneghin, P. Kilpatrick, D. Buono, S. Lametti Dept. Computer Science, Univ. of Pisa CoreGRID Programming
Structured approaches for multi/many core targeting Marco Danelutto M. Torquati, M. Aldinucci, M. Meneghin, P. Kilpatrick, D. Buono, S. Lametti Dept. Computer Science, Univ. of Pisa CoreGRID Programming
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Introduction to FastFlow programming
 Introduction to FastFlow programming Hands-on session Massimo Torquati Computer Science Department, University of Pisa - Italy Outline The FastFlow tutorial FastFlow basic concepts
Introduction to FastFlow programming Hands-on session Massimo Torquati Computer Science Department, University of Pisa - Italy Outline The FastFlow tutorial FastFlow basic concepts
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Intel Thread Building Blocks, Part IV
 Intel Thread Building Blocks, Part IV SPD course 2017-18 Massimo Coppola 13/04/2018 1 Mutexes TBB Classes to build mutex lock objects The lock object will Lock the associated data object (the mutex) for
Intel Thread Building Blocks, Part IV SPD course 2017-18 Massimo Coppola 13/04/2018 1 Mutexes TBB Classes to build mutex lock objects The lock object will Lock the associated data object (the mutex) for
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Fast Sequence Alignment Method Using CUDA-enabled GPU
 Fast Sequence Alignment Method Using CUDA-enabled GPU Yeim-Kuan Chang Department of Computer Science and Information Engineering National Cheng Kung University Tainan, Taiwan ykchang@mail.ncku.edu.tw De-Yu
Fast Sequence Alignment Method Using CUDA-enabled GPU Yeim-Kuan Chang Department of Computer Science and Information Engineering National Cheng Kung University Tainan, Taiwan ykchang@mail.ncku.edu.tw De-Yu
Master Program (Laurea Magistrale) in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.
 in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.") Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Questions answered in this lecture: CS 537 Lecture 19 Threads and Cooperation. What s in a process? Organizing a Process
 Questions answered in this lecture: CS 537 Lecture 19 Threads and Cooperation Why are threads useful? How does one use POSIX pthreads? Michael Swift 1 2 What s in a process? Organizing a Process A process
Questions answered in this lecture: CS 537 Lecture 19 Threads and Cooperation Why are threads useful? How does one use POSIX pthreads? Michael Swift 1 2 What s in a process? Organizing a Process A process
THE Smith-Waterman (SW) algorithm [1] is a wellknown
![THE Smith-Waterman (SW) algorithm [1] is a wellknown](/thumbs/95/125558830.jpg "THE Smith-Waterman (SW) algorithm [1] is a wellknown") Design and Implementation of the Smith-Waterman Algorithm on the CUDA-Compatible GPU Yuma Munekawa, Fumihiko Ino, Member, IEEE, and Kenichi Hagihara Abstract This paper describes a design and implementation
Design and Implementation of the Smith-Waterman Algorithm on the CUDA-Compatible GPU Yuma Munekawa, Fumihiko Ino, Member, IEEE, and Kenichi Hagihara Abstract This paper describes a design and implementation
FastFlow: high-level programming patterns with non-blocking lock-free run-time support
 International Summer School in Parallel Patterns!! June 10, 2014! Dublin, Ireland FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci! Parallel programming
International Summer School in Parallel Patterns!! June 10, 2014! Dublin, Ireland FastFlow: high-level programming patterns with non-blocking lock-free run-time support Marco Aldinucci! Parallel programming
Marwan Burelle. Parallel and Concurrent Programming
 marwan.burelle@lse.epita.fr http://wiki-prog.infoprepa.epita.fr Outline 1 2 3 OpenMP Tell Me More (Go, OpenCL,... ) Overview 1 Sharing Data First, always try to apply the following mantra: Don t share
marwan.burelle@lse.epita.fr http://wiki-prog.infoprepa.epita.fr Outline 1 2 3 OpenMP Tell Me More (Go, OpenCL,... ) Overview 1 Sharing Data First, always try to apply the following mantra: Don t share
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ.
 An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
Single-Producer/ Single-Consumer Queues on Shared Cache Multi-Core Systems
 Università di Pisa Dipartimento di Informatica Technical Report: TR-1-2 Single-Producer/ Single-Consumer Queues on Shared Cache Multi-Core Systems Massimo Torquati Computer Science Department University
Università di Pisa Dipartimento di Informatica Technical Report: TR-1-2 Single-Producer/ Single-Consumer Queues on Shared Cache Multi-Core Systems Massimo Torquati Computer Science Department University
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
High Performance Technique for Database Applications Using a Hybrid GPU/CPU Platform
 High Performance Technique for Database Applications Using a Hybrid GPU/CPU Platform M. Affan Zidan, Talal Bonny, and Khaled N. Salama Electrical Engineering Program King Abdullah University of Science
High Performance Technique for Database Applications Using a Hybrid GPU/CPU Platform M. Affan Zidan, Talal Bonny, and Khaled N. Salama Electrical Engineering Program King Abdullah University of Science
Distributed File Systems Issues. NFS (Network File System) AFS: Namespace. The Andrew File System (AFS) Operating Systems 11/19/2012 CSC 256/456 1
 AFS: Namespace. The Andrew File System (AFS) Operating Systems 11/19/2012 CSC 256/456 1") Distributed File Systems Issues NFS (Network File System) Naming and transparency (location transparency versus location independence) Host:local-name Attach remote directories (mount) Single global name
Distributed File Systems Issues NFS (Network File System) Naming and transparency (location transparency versus location independence) Host:local-name Attach remote directories (mount) Single global name
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
An Architectural Framework for Accelerating Dynamic Parallel Algorithms on Reconfigurable Hardware
 An Architectural Framework for Accelerating Dynamic Parallel Algorithms on Reconfigurable Hardware Tao Chen, Shreesha Srinath Christopher Batten, G. Edward Suh Computer Systems Laboratory School of Electrical
An Architectural Framework for Accelerating Dynamic Parallel Algorithms on Reconfigurable Hardware Tao Chen, Shreesha Srinath Christopher Batten, G. Edward Suh Computer Systems Laboratory School of Electrical
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Parallel Processing for Scanning Genomic Data-Bases
 1 Parallel Processing for Scanning Genomic Data-Bases D. Lavenier and J.-L. Pacherie a {lavenier,pacherie}@irisa.fr a IRISA, Campus de Beaulieu, 35042 Rennes cedex, France The scan of a genomic data-base
1 Parallel Processing for Scanning Genomic Data-Bases D. Lavenier and J.-L. Pacherie a {lavenier,pacherie}@irisa.fr a IRISA, Campus de Beaulieu, 35042 Rennes cedex, France The scan of a genomic data-base
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Intel Thread Building Blocks
 Intel Thread Building Blocks SPD course 2017-18 Massimo Coppola 23/03/2018 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
Intel Thread Building Blocks SPD course 2017-18 Massimo Coppola 23/03/2018 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
AAlign: A SIMD Framework for Pairwise Sequence Alignment on x86-based Multi- and Many-core Processors
 AAlign: A SIMD Framework for Pairwise Sequence Alignment on x86-based Multi- and Many-core Processors Kaixi Hou, Hao Wang, Wu-chun Feng {kaixihou,hwang121,wfeng}@vt.edu Pairwise Sequence Alignment Algorithms
AAlign: A SIMD Framework for Pairwise Sequence Alignment on x86-based Multi- and Many-core Processors Kaixi Hou, Hao Wang, Wu-chun Feng {kaixihou,hwang121,wfeng}@vt.edu Pairwise Sequence Alignment Algorithms
Biology 644: Bioinformatics
 Find the best alignment between 2 sequences with lengths n and m, respectively Best alignment is very dependent upon the substitution matrix and gap penalties The Global Alignment Problem tries to find
Find the best alignment between 2 sequences with lengths n and m, respectively Best alignment is very dependent upon the substitution matrix and gap penalties The Global Alignment Problem tries to find
Hyper-Threading Performance with Intel CPUs for Linux SAP Deployment on ProLiant Servers. Session #3798. Hein van den Heuvel
 Hyper-Threading Performance with Intel CPUs for Linux SAP Deployment on ProLiant Servers Session #3798 Hein van den Heuvel Performance Engineer Hewlett-Packard 2004 Hewlett-Packard Development Company,
Hyper-Threading Performance with Intel CPUs for Linux SAP Deployment on ProLiant Servers Session #3798 Hein van den Heuvel Performance Engineer Hewlett-Packard 2004 Hewlett-Packard Development Company,
Predictable Timing Analysis of x86 Multicores using High-Level Parallel Patterns
 Predictable Timing Analysis of x86 Multicores using High-Level Parallel Patterns Kevin Hammond, Susmit Sarkar and Chris Brown University of St Andrews, UK T: @paraphrase_fp7 E: kh@cs.st-andrews.ac.uk W:
Predictable Timing Analysis of x86 Multicores using High-Level Parallel Patterns Kevin Hammond, Susmit Sarkar and Chris Brown University of St Andrews, UK T: @paraphrase_fp7 E: kh@cs.st-andrews.ac.uk W:
SMD149 - Operating Systems - Multiprocessing
 SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Overview. SMD149 - Operating Systems - Multiprocessing. Multiprocessing architecture. Introduction SISD. Flynn s taxonomy
 Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Distributed systems: paradigms and models Motivations
 Distributed systems: paradigms and models Motivations Prof. Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year
Distributed systems: paradigms and models Motivations Prof. Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year
OPEN MP-BASED PARALLEL AND SCALABLE GENETIC SEQUENCE ALIGNMENT
 OPEN MP-BASED PARALLEL AND SCALABLE GENETIC SEQUENCE ALIGNMENT Asif Ali Khan*, Laiq Hassan*, Salim Ullah* ABSTRACT: In bioinformatics, sequence alignment is a common and insistent task. Biologists align
OPEN MP-BASED PARALLEL AND SCALABLE GENETIC SEQUENCE ALIGNMENT Asif Ali Khan*, Laiq Hassan*, Salim Ullah* ABSTRACT: In bioinformatics, sequence alignment is a common and insistent task. Biologists align
Autonomic QoS Control with Behavioral Skeleton
 Grid programming with components: an advanced COMPonent platform for an effective invisible grid Autonomic QoS Control with Behavioral Skeleton Marco Aldinucci, Marco Danelutto, Sonia Campa Computer Science
Grid programming with components: an advanced COMPonent platform for an effective invisible grid Autonomic QoS Control with Behavioral Skeleton Marco Aldinucci, Marco Danelutto, Sonia Campa Computer Science
CS377P Programming for Performance Multicore Performance Multithreading
 CS377P Programming for Performance Multicore Performance Multithreading Sreepathi Pai UTCS October 14, 2015 Outline 1 Multiprocessor Systems 2 Programming Models for Multicore 3 Multithreading and POSIX
CS377P Programming for Performance Multicore Performance Multithreading Sreepathi Pai UTCS October 14, 2015 Outline 1 Multiprocessor Systems 2 Programming Models for Multicore 3 Multithreading and POSIX
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
INTERFACING REAL-TIME AUDIO AND FILE I/O
 INTERFACING REAL-TIME AUDIO AND FILE I/O Ross Bencina portaudio.com rossbencina.com rossb@audiomulch.com @RossBencina Example source code: https://github.com/rossbencina/realtimefilestreaming Q: How to
INTERFACING REAL-TIME AUDIO AND FILE I/O Ross Bencina portaudio.com rossbencina.com rossb@audiomulch.com @RossBencina Example source code: https://github.com/rossbencina/realtimefilestreaming Q: How to
Multiprocessors and Locking
 Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Università di Pisa. Dipartimento di Informatica. Technical Report: TR FastFlow tutorial
 Università di Pisa Dipartimento di Informatica arxiv:1204.5402v1 [cs.dc] 24 Apr 2012 Technical Report: TR-12-04 FastFlow tutorial M. Aldinucci M. Danelutto M. Torquati Dip. Informatica, Univ. Torino Dip.
Università di Pisa Dipartimento di Informatica arxiv:1204.5402v1 [cs.dc] 24 Apr 2012 Technical Report: TR-12-04 FastFlow tutorial M. Aldinucci M. Danelutto M. Torquati Dip. Informatica, Univ. Torino Dip.
Optimization Space Exploration of the FastFlow Parallel Skeleton Framework
 Optimization Space Exploration of the FastFlow Parallel Skeleton Framework Alexander Collins Christian Fensch Hugh Leather University of Edinburgh School of Informatics What We Did Parallel skeletons provide
Optimization Space Exploration of the FastFlow Parallel Skeleton Framework Alexander Collins Christian Fensch Hugh Leather University of Edinburgh School of Informatics What We Did Parallel skeletons provide
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
A Basic Snooping-Based Multi-processor
 Lecture 15: A Basic Snooping-Based Multi-processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes Stompa (Serena Ryder) I wrote Stompa because I just get so excited
Lecture 15: A Basic Snooping-Based Multi-processor Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2014 Tunes Stompa (Serena Ryder) I wrote Stompa because I just get so excited
Parallel Programming Principle and Practice. Lecture 7 Threads programming with TBB. Jin, Hai
 Parallel Programming Principle and Practice Lecture 7 Threads programming with TBB Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Outline Intel Threading
Parallel Programming Principle and Practice Lecture 7 Threads programming with TBB Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Outline Intel Threading
Biological Sequence Comparison on Hybrid Platforms with Dynamic Workload Adjustment
 2013 IEEE 27th International Symposium on Parallel & Distributed Processing Workshops and PhD Forum Biological Sequence Comparison on Hybrid Platforms with Dynamic Workload Adjustment Fernando Machado
2013 IEEE 27th International Symposium on Parallel & Distributed Processing Workshops and PhD Forum Biological Sequence Comparison on Hybrid Platforms with Dynamic Workload Adjustment Fernando Machado
Sequence Alignment with GPU: Performance and Design Challenges
 Sequence Alignment with GPU: Performance and Design Challenges Gregory M. Striemer and Ali Akoglu Department of Electrical and Computer Engineering University of Arizona, 85721 Tucson, Arizona USA {gmstrie,
Sequence Alignment with GPU: Performance and Design Challenges Gregory M. Striemer and Ali Akoglu Department of Electrical and Computer Engineering University of Arizona, 85721 Tucson, Arizona USA {gmstrie,
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology
 Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Parallel and Distributed Computing
 Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Region-Based Memory Management for Task Dataflow Models
 Region-Based Memory Management for Task Dataflow Models Nikolopoulos, D. (2012). Region-Based Memory Management for Task Dataflow Models: First Joint ENCORE & PEPPHER Workshop on Programmability and Portability
Region-Based Memory Management for Task Dataflow Models Nikolopoulos, D. (2012). Region-Based Memory Management for Task Dataflow Models: First Joint ENCORE & PEPPHER Workshop on Programmability and Portability
Intel Thread Building Blocks
 Intel Thread Building Blocks SPD course 2015-16 Massimo Coppola 08/04/2015 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
Intel Thread Building Blocks SPD course 2015-16 Massimo Coppola 08/04/2015 1 Thread Building Blocks : History A library to simplify writing thread-parallel programs and debugging them Originated circa
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Flexible Architecture Research Machine (FARM)
") Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
PCS - Part Two: Multiprocessor Architectures
 PCS - Part Two: Multiprocessor Architectures Institute of Computer Engineering University of Lübeck, Germany Baltic Summer School, Tartu 2008 Part 2 - Contents Multiprocessor Systems Symmetrical Multiprocessors
PCS - Part Two: Multiprocessor Architectures Institute of Computer Engineering University of Lübeck, Germany Baltic Summer School, Tartu 2008 Part 2 - Contents Multiprocessor Systems Symmetrical Multiprocessors
Algorithmic Approaches for Biological Data, Lecture #20
 Algorithmic Approaches for Biological Data, Lecture #20 Katherine St. John City University of New York American Museum of Natural History 20 April 2016 Outline Aligning with Gaps and Substitution Matrices
Algorithmic Approaches for Biological Data, Lecture #20 Katherine St. John City University of New York American Museum of Natural History 20 April 2016 Outline Aligning with Gaps and Substitution Matrices
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Exploring the Throughput-Fairness Trade-off on Asymmetric Multicore Systems
 Exploring the Throughput-Fairness Trade-off on Asymmetric Multicore Systems J.C. Sáez, A. Pousa, F. Castro, D. Chaver y M. Prieto Complutense University of Madrid, Universidad Nacional de la Plata-LIDI
Exploring the Throughput-Fairness Trade-off on Asymmetric Multicore Systems J.C. Sáez, A. Pousa, F. Castro, D. Chaver y M. Prieto Complutense University of Madrid, Universidad Nacional de la Plata-LIDI
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Out-of-Order Parallel Simulation of SystemC Models. G. Liu, T. Schmidt, R. Dömer (CECS) A. Dingankar, D. Kirkpatrick (Intel Corp.)
 A. Dingankar, D. Kirkpatrick (Intel Corp.)") Out-of-Order Simulation of s using Intel MIC Architecture G. Liu, T. Schmidt, R. Dömer (CECS) A. Dingankar, D. Kirkpatrick (Intel Corp.) Speaker: Rainer Dömer doemer@uci.edu Center for Embedded Computer
Out-of-Order Simulation of s using Intel MIC Architecture G. Liu, T. Schmidt, R. Dömer (CECS) A. Dingankar, D. Kirkpatrick (Intel Corp.) Speaker: Rainer Dömer doemer@uci.edu Center for Embedded Computer
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Dynamic Fine Grain Scheduling of Pipeline Parallelism. Presented by: Ram Manohar Oruganti and Michael TeWinkle
 Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
Threads. Raju Pandey Department of Computer Sciences University of California, Davis Spring 2011
 Threads Raju Pandey Department of Computer Sciences University of California, Davis Spring 2011 Threads Effectiveness of parallel computing depends on the performance of the primitives used to express
Threads Raju Pandey Department of Computer Sciences University of California, Davis Spring 2011 Threads Effectiveness of parallel computing depends on the performance of the primitives used to express
Programming assignment for the course Sequence Analysis (2006)
") Programming assignment for the course Sequence Analysis (2006) Original text by John W. Romein, adapted by Bart van Houte (bart@cs.vu.nl) Introduction Please note: This assignment is only obligatory for
Programming assignment for the course Sequence Analysis (2006) Original text by John W. Romein, adapted by Bart van Houte (bart@cs.vu.nl) Introduction Please note: This assignment is only obligatory for
GPU Accelerated Smith-Waterman
 GPU Accelerated Smith-Waterman Yang Liu 1,WayneHuang 1,2, John Johnson 1, and Sheila Vaidya 1 1 Lawrence Livermore National Laboratory 2 DOE Joint Genome Institute, UCRL-CONF-218814 {liu24, whuang, jjohnson,
GPU Accelerated Smith-Waterman Yang Liu 1,WayneHuang 1,2, John Johnson 1, and Sheila Vaidya 1 1 Lawrence Livermore National Laboratory 2 DOE Joint Genome Institute, UCRL-CONF-218814 {liu24, whuang, jjohnson,
Core Fusion: Accommodating Software Diversity in Chip Multiprocessors
 Core Fusion: Accommodating Software Diversity in Chip Multiprocessors Authors: Engin Ipek, Meyrem Kırman, Nevin Kırman, and Jose F. Martinez Navreet Virk Dept of Computer & Information Sciences University
Core Fusion: Accommodating Software Diversity in Chip Multiprocessors Authors: Engin Ipek, Meyrem Kırman, Nevin Kırman, and Jose F. Martinez Navreet Virk Dept of Computer & Information Sciences University
The benefits and costs of writing a POSIX kernel in a high-level language
 1 / 38 The benefits and costs of writing a POSIX kernel in a high-level language Cody Cutler, M. Frans Kaashoek, Robert T. Morris MIT CSAIL Should we use high-level languages to build OS kernels? 2 / 38
1 / 38 The benefits and costs of writing a POSIX kernel in a high-level language Cody Cutler, M. Frans Kaashoek, Robert T. Morris MIT CSAIL Should we use high-level languages to build OS kernels? 2 / 38
The SARC Architecture
 The SARC Architecture Polo Regionale di Como of the Politecnico di Milano Advanced Computer Architecture Arlinda Imeri arlinda.imeri@mail.polimi.it 19-Jun-12 Advanced Computer Architecture - The SARC Architecture
The SARC Architecture Polo Regionale di Como of the Politecnico di Milano Advanced Computer Architecture Arlinda Imeri arlinda.imeri@mail.polimi.it 19-Jun-12 Advanced Computer Architecture - The SARC Architecture
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Order Is A Lie. Are you sure you know how your code runs?
 Order Is A Lie Are you sure you know how your code runs? Order in code is not respected by Compilers Processors (out-of-order execution) SMP Cache Management Understanding execution order in a multithreaded
Order Is A Lie Are you sure you know how your code runs? Order in code is not respected by Compilers Processors (out-of-order execution) SMP Cache Management Understanding execution order in a multithreaded
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Intel Architecture for Software Developers
 Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software